
基于MLP神经网络的商品评论情感分析
2021-07-18 07:12江涛
电子制作 2021年12期
江涛
(广东理工学院信息技术学院,广东肇庆,526000)
本文研究对商品评论进行正负评价分类,希望通过准确的评价分类,让消费者可以快速地找出大众评价良好的产品,以减少信息取得成本,进而加速购买效率。分类结果也可以提供厂商作为产品在销售与决策上的依据,能更有效地掌握消费者的喜好,找出正确的产品发展方向,以提升产品品质,增加消费者购买的可能性,减少顾客流失,进而提高市场占有率。
本研究结合分词工具、词嵌入工具及MLP 深度学习方法,建构出产品评论的正负评价分类方法。首先使用断词工具将评论文本以词汇为单位做切割,使计算机可以更好的处理自然语言。接著用词嵌入工具将文本进行特征词向量的提取。最后,利用MLP 神经网络训练文本分类模型,对评论资料进行正负评价的分类。在实验的过程中,调整各项参数进行多次训练,并分析实验结果。
1 系统结构
系统架构如图1 所示,先将内含大量中文词汇的维基百科中文资料做预处理及断词,以此训练词向量模型。接著,将商品评论资料做预处理及断词,并基于已经训练好的词向量模型做特征词向量的抽取。最后,把整个资料集降维后分成训练资料集及测试资料集,以训练资料集训练分类模型,再以测试资料集验证模型成效。
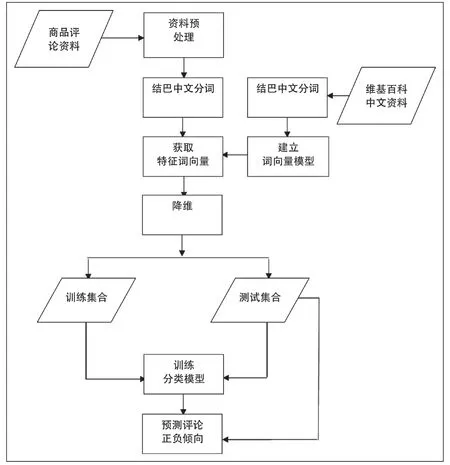
图1 系统结构
对于其中的几个重要的环节,在此做出必要的剖析。
■1.1 资料预处理
有了前述的基础资料,在分析算法之前,先对资料进行预处理,让资料在格式上比较标准一致,目的是让算法不会因为资料所产生的瑕疵而发生误判。
1.1.1 编码处理
编码可以分成地区编码及国际编码,UTF-8 是国际编码的一种,此编码系统对世界上大部分的文字系统进行了整理、编码,其中包含中文。因此,本研究将来源资料都先转换成 UTF-8 编码,使得计算机可以用更为简单的方式来处理文字。
1.1.2 去除干扰
进行机器学习时,一般会希望减少分析目标外的干扰(例如停用词、标点符号、特殊字元、转义字元等),以达到更高的准确率。本研究先对文本进行去除所有半角、全角符号,只保留字母、数字及中文字的处理。接下來去除停用词,为节省存储空间和提高搜寻效率,在处理自然语言数据之前或之后会自动过滤掉某些较无意义的字或词,这些字或词即被称为停用词(Stop Words)。
1.1.3 中文分词
中文的语句词汇是相连的,相较印欧语系等语言,词汇间并无空格,必须先将原始资料进行断词步骤,把词汇以意义为单位切割出來,能够达到更好的自然语言处理效果,帮助系统理解复杂的中文语言。本研究采用结巴分词工具,结巴分词算法是建立 Trie DAG,使用全切分方法,以统计模型计算出最佳结果;对于未知词(新词)则使用 HMM 模型计算辨识出来。
■1.2 词向量及特征提取
文字在经过分词后会形成一个词语集合,对于这些词语集合,机器学习算法无法直接使用,需要将它们转化成可以被机器学习算法识别的数值特征(由固定长度的向量表示之),然后再交给机器学习的算法进行操作,此转化过程,称为特征提取。由于特征词向量的提取是基于已经训练好的词向量模型,而中文维基百科是公认的大型中文资料库,因此本研究将从中文维基百科资料中训练出词向量模型,再以此词向量模型为基础,从前述已分词处理完的本文语料中提取特征词向量。
本研究使用 Word2Vec 做为训练词向量模型及特征提取的工具。在训练词向量模型时,选用语意分析效果较好的Skip-gram model,补足一般文件分类常欠缺的语意分析。本研究所使用的word2vec 词向量模型,是由维基百科提供开放下载的最新中文内容所训练而成,评论文本经过此模型,可将词汇转换成一个400 维度的特征词向量。
■1.3 降维
因为在原始的高维度向量资料中,包含有冗余信息以及噪音信息,在实际应用中会造成误差,并降低资料分析的准确率,同时海量的高维向量资料也导致演算法越來越慢。而通过降维,可以减少冗余信息所造成的误差,提高识别的精准度,并提高计算效率。
本研究的降维方法使用主成分分析(Principal Com ponents Analysis)缩写为PCA,是一种无监督式学习的降维演算法。PCA 将可能具有相关性的高维向量转换成线性无关的低维向量,即主成分(Principal Components),此低维向量数据集可保持原数据集中的对变异数贡献最大的特征。
■1.4 文本分类
许多深度学习方法可实现文本分类,本论文将研究有标准答案的监督式学习,使用多层感知机(MLP)深度学习方法进行文本分类,在实验过程中将尝试进行参数调教以得出更好的结果。
MLP 是一种前向结构的人工神经网路,每一层中可包含许多各自独立的神经元,这些位于同一层的神经元彼此之间并没有任何连接,但对位于上下两层的每一个神经元,都有相对的连接。也就是下层的每一个神经元,对上层的每一个神经元,都会学习到一个权重值,來表达上下两层神经元连接的强度。这个连接的强度,对于分类任务而言,可能是属于某一类别的独有特征。
MLP 的网络学习方式是采用监督式学习,网络的训练算法是由属于错误更正学习法则的反向传播算法来训练网络的键结值,也可以视为是最小均方法(LMS 算法)的一种推广。反向传播算法利用网络输出与目标之间的差异,计算损失函数相对于每一层网络参数的梯度值,再以梯度值修正参数,最小化损失函数。
2 实验与分析
本研究以GitHub 上 的 LSTM 情绪分析实验所使用到的淘宝网商品评论语料作为资料来源,此语料已预先完成正负向文本分类,并分割成训练资料集 17466 笔及测试资料集2632 笔,两个资料集的内容都是不重覆的。
本研究在实验 MLP 时,使用神经网路函式库 Keras 进行训练。本研究使用具有四层隐藏层的深层 MLP,各层神经元数量分别为 256、128、64、32,采用ReLU 激励函数,且在每个隐藏层后加入 dropout=0.5 以防止过拟合的状况发生。输出层为 1 个神经元的全连接层,采用 Sigmoid 激励函数。训练过程中优化器使用具有自适应学习速率的梯度下降算法(Adam),并尝试调整 epochs 及 batch size 以找出最佳参数值,如表1 所示,找出 epochs=100 和 batch size=16 为效果较好的数值,使得在训练语料中精确度最大值约 94%,实验结果如表2 所示。
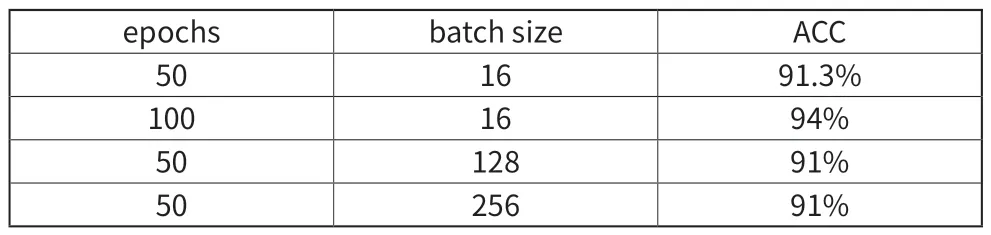
表1 MLP 参数调整与分类精确度的影响

表2 MLP 分类结果(混淆矩阵)
3 结语
本文针对商品评论的正负评价分类问题,设计基于深度学习的情感分析方法,使用 Word2Vec 做为词嵌入的方法,并使用PCA 降低资料维度,以减少冗馀信息所造成的误差,最后用MLP 深度学习方法进行文本分类实验。由实验结果得出的该方法文本分类的精确度较好,且不易受参数调整影响,是相对稳定且有效的分类方法。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
电子产品世界(2021年8期)2021-01-16
考试与评价·八年级版(2020年4期)2020-10-26
考试与评价·八年级版(2020年1期)2020-10-26
考试与评价·八年级版(2020年1期)2020-10-26
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
创新时代(2016年8期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
