
基于分割的实时自然场景文本检测
2021-07-18 07:12付明辉
电子制作 2021年12期
付明辉
(北方工业大学城市道路交通智能控制技术北京市重点实验室,北京,100144)
1 文本检测模型
图1 为本文提出方法的总体框架.本文将主干网络MobileNetV3 进行适当地修改,提高了网络提取特征的能力。其次,采用更加高效的分割头。分割头主要包括残差增强型的FPN 模块和自适应特征融合模块。如图1 所示,对于FPN 结构来说,越深层的特征意味着更多的通道数,但是各层特征进行融合时都是自顶向下传播,所以顶层特征为了势必会减少更多的通道数,最高层的特征往往会丢失更多的信息,所以为了保留更多的上下文信息,在FPN 中加入残差增强模块,保留更多的深层特征.最后利用自适应特征融合模块对各层特征进行自适应融合,得到最终的分割特征.利用特征F 对概率图(P)和阈值图(T)进行预测,根据可微二值化模块(DB[3])将概率图和阈值图结合得到二值图(B′),自适应预测每个位置的阈值。最后通过边界框形成从近似二值图中获得文本的检测框。
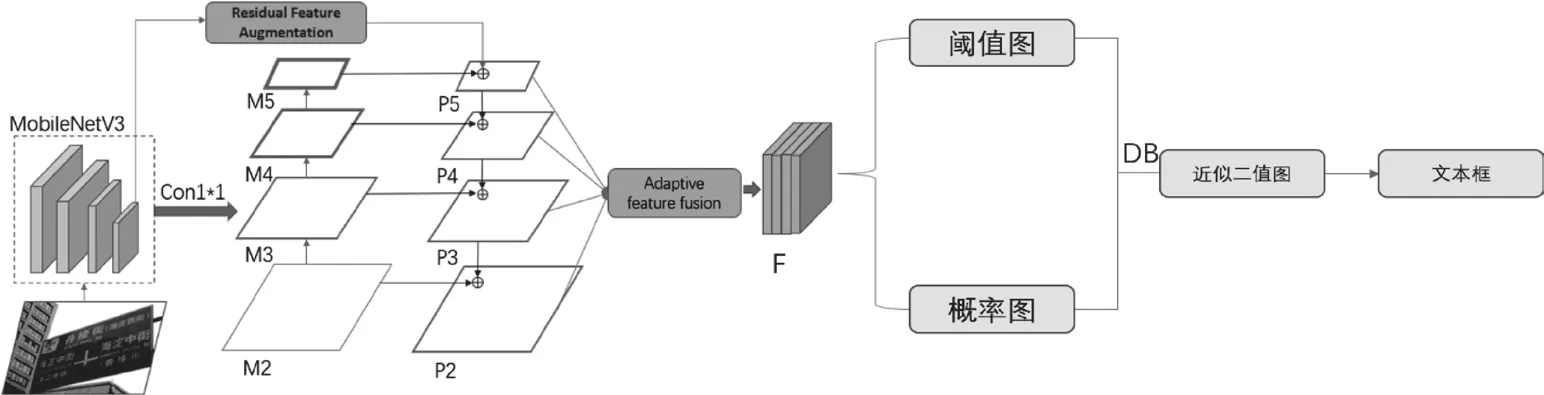
图1 总体网络结构图
■1.1 MobileNetV3 网络的轻量化
MobileNetV3 的主要组成模块包括深度可分离卷积和SE 模块,本文将MobileNetV3 里SE 模块[4]替换为更加轻量级的SA 模块。SE 模块是一个通过压缩和激发的方式寻找图像通道之间的相互依赖关系,并自适应的重新校准通道特性响应,从而提高任务的准确率。但是对于自然场景文本检测任务来说,输入图像的大小为640×640,很难用SE模块估计通道特征响应,精度提高有限。同时带来了巨大的参数量。
■1.2 残差特征增强
在FPN 结构中,M5 层属于深层特征具有很多的通道信息,但是在自顶向下的融合过程中,由于减少了特征通道必然会导致上下文信息的丢失。图像的上下文语义信息对于分割网络有着至关重要的作用,残差增强模块(Residual Feature Augmentation),通过向原始分支注入不同的空间上下文信息,利用空间上下文信息减少M5 在向下传播过程中通道的信息损失,提高金字塔的特征的性能。
本次实验中,首先在尺度为S 的C5 上使用比率不变自适应池化,分别产生0.1×S、0.2×S、0.3×S 大小的上下文特征,然后通过1×1 卷积将三个尺度大小的特征图的通道数变为256。最后通过双线性插值上采样成尺度S,如图2(a)通过自适应空间融合ASFF 模块自适应组合这些上下文信息。由ASFF 生成M6以后,M6 就具有多尺度的上下文信息,通过与M5 求和为特征金字塔注入多尺度上下文信息,自顶向下与底层特征相融合。
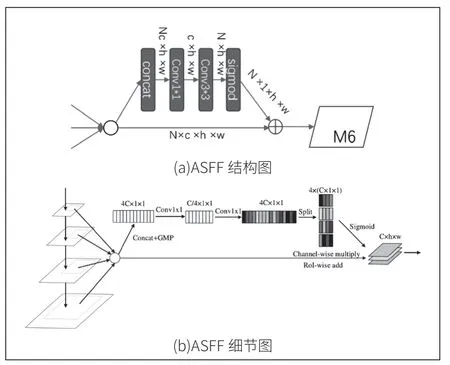
图2
■1.3 自适应特征融合(ASFF)
其网络结构图2 所示,ASFF 仅由两个卷积层组成,参数量相对也比较少。采用数据驱动的方式对不同层次的特征进行融合,通过网络学习空间过滤冲突信息的方法来抑制不一致性,可以提高特征尺度的不变性。在FPN 的残差特征增强模块中也用到了ASFF,其如下所示:
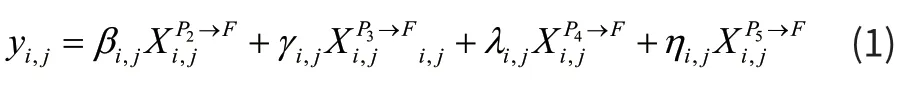
其中yi,j表示通道中输出特征映射的第(i,j)个向量,是由网络自适应学习的四个不同层次的特征映射到总的特征图F 的空间重要性权重矩阵,并且有对不同层次的特征图生成不同的空间权重图,最后通过加权融合生成分割网络用来预测阈值图和概率图的特征图F。
■1.4 可微二值化模块(DB)
根据分割网络生成的概率图P∈RH×W,其中H 和W 分别表示输入图像的高度和宽度,要将概率图转化为二值图P∈RH×W,二值化函数是至关重要的,标准二值化函数如公式(2)所示,值为1 的像素被认为是有效的文本区域。

其中,t 为设定的阈值,(i,j)表示图中的坐标点。
式(2)为标准二值化函数,是不可微的,所以不能随着分割网络而优化。为了解决二值化函数不可微的问题,本文使用公式(6)进行二值化:
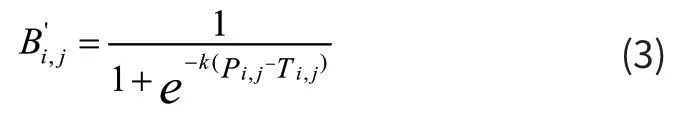
其中B′是近似二值图,T 是从网络中学习的自适应阈值图,K 是放大系数,在训练过程中,K 的作用就是在反向传播中放大传播的梯度,这对于大多数的错误预测区域的改善是比较友好的,有利于产生更显著的预测。本文设置K=50,该近似二值化函数与标准二值化函数相似,且具有可微性,可以在训练期间随分割网络进行优化。可微二值化可以自适应设定阈值T,这样的方法不仅能够很好地区分前景和背景,而且可以分离出连接紧密的文本实例。
■1.5 标签生成
可微分的后处理方式,必须生成概率图与阈值图对应的标签,输入图像内的文本区域可以看做一个多边形,并用一组线段描述为:

其中,n为顶点个数,k为放大倍数,对于不同类型的文本图像顶点个数会不一样,弯曲文本的一般设置为16 个定点,其余为4 个定点。然后使用Vatti 裁剪算法,将G收缩偏移量D后变成Gs,偏移量D的计算方式如下:

其中,r为收缩系数.阈值图标签的生成过程与概率图相似,将G扩展偏移量D后变成Gd,Gs与Gd之间的区域为文本区域的边界,通过计算到G中最接近的线段的距离来生成阈值图的标签。
■1.6 损失函数
损失函数由概率图的损失Ls、阈值图的损失Lt以及二值图的损失Lb三部分组成,具体如下所示:

根据对应损失的数量级,α和β分别设定为1 和10。
本文对概率图损失函数和二值图损失函数应用二元交叉熵损失(BCE)。并且为了克服正负样本不平衡的问题,在BCE 中采用了hard negative mining 采样方法。
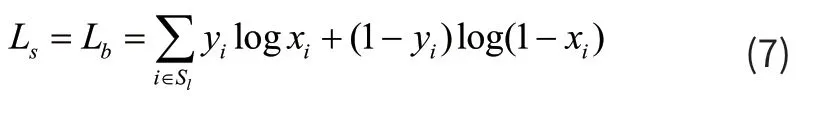
其中Sl为采样集,正负样本的比例为1:3。
Lt为扩展多边形Gd内侧预测值与标签值之间的L1距离之和,具体如下:

其中Rd为拓展多边形Gd内像素的一组索引,y*是阈值图的标签。
2 实验结果
■2.1 训练细节
本文采用Adam 优化器训练模型,并采用余弦学习率衰减作为学习率调度,初始学习率为0.001,训练批次大小为8。本文的文本检测模型在Synth Text 数据集进行预训练,然后在ICDAR2015 和Total-Text 数据集上进行微调。对训练数据采用在(-10°,10°)范围内随机旋转角度、随机裁剪和翻转的方式进行数据增强,所有的图片都重新调整为640×640。实验的设备使用两台GTX2080 在linux 系统下进行实验。
■2.2 检测结果评估
本文在多方向文本数据集ICDAR2015 和曲线文本数据集Total-Text 上进行了测试,主要考虑3 个性能参数:准确率(P)、召回率(R)以及综合评价指标(F),评估该模型的检测性能。
ICDAR2015 数据集是一个包含多方向的文本数据集。从表1 可以看出,与速度最快的EAST 算发相比,本文提出的基于轻量级骨干网络的检测模型,在速度上比之快上大约4.5 倍,并且在性能上也比之高7.6%。虽然本文提出的方法不能达到最优的效果,但是在速度上有着其他算法难以企及的优势。其原因在于引入了DB 模块,将复杂的后处理加入到网络的训练过程中,降低了模型的开销。
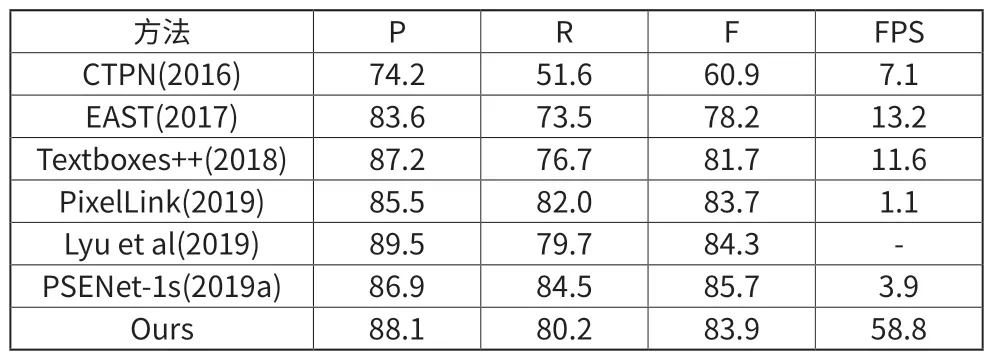
表1 ICDAR2015上的检测结果
本文的检测模型在Total-Text 模型上的表现也具有竞争力。在模型的检测精度(P)上相比于PSENet 要高1.2%,最明显的优势还是速度比其它算法更快,比之快了15倍左右。
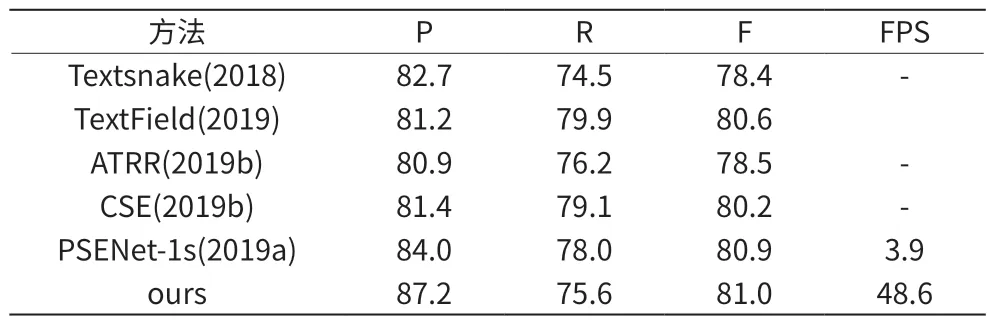
表2 Total-Text上的检测结果
3 结论
本文提出的基于轻量级网络MobileNetV3 的文本检测模型,模型中为了提高对模型对特征使用效率,在FPN 结构中加入残差增强模块和特征自适应模块,并且引入能够参与网络训练的可微二值化模块。整个模型既保证了特征提取的质量,同时因为本身属于轻量级网络,在速度和精度方面达到了很好的平衡,残差增强模块中使用了特征增强模块,且本身给模型的带来的开销几乎为零,可微二值化模块显著的提高了文本检测的性能。整个模型在数据集上的表现可以与其余的一些先进方法相媲美,但是自然文本检测领域还有很多的挑战,未来对于弯曲文本的检测还需要想办法提高。
猜你喜欢
心理学报(2022年9期)2022-09-06
现代电子技术(2022年11期)2022-06-14
成都信息工程大学学报(2022年2期)2022-06-14
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
现代计算机(2021年10期)2021-05-28
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
理科考试研究·高中(2016年9期)2016-05-14
