
随机特征映射的四层神经网络及其增量学习
2021-07-22 17:02王士同
计算机与生活 2021年7期
杨 悦,王士同
江南大学 人工智能与计算机学院,江苏 无锡 214122
随着人工智能研究的复兴,许多机器学习算法大展头角,推动着人工智能研究的发展。其中多层结构的神经网络已经应用于许多领域,并在许多应用中取得突破性成果[1-3],比如卷积神经网络(convolutional neural networks,CNN)[4]、反向传播神经网络(back propagation,BP)[5-6]、极限学习机(extreme learning machine,ELM)[7-8]、模糊神经网络(neuro-fuzzy netwoks,FNN)[9]以及宽度学系统(broad learning system,BLS)[10-13]。CNN 结构是一种多层神经网络,通过卷积和池化操作进行特征提取和适当的权重调整。CNN 及其变体已成功地在各种数据集测试中实现了非常高的识别率。尽管这种深层结构非常强大,但由于大多数网络都涉及大量超参数和复杂结构,其训练过程非常耗时。此外,这种复杂性使得从理论上分析深度结构很困难,为了获得更好的精度,大多数工作涉及大量参数传递或堆叠更多的层数。另外,基于梯度下降[14]的算法也被广泛应用于训练神经网络,如BP 神经网络利用误差的反向传播来调整网络的权值。然而,这样的网络结构在训练过程中若选择了不恰当的步长会导致训练失败:步长过小会容易导致训练陷入局部最小值,或训练过程非常耗时。如果训练陷入局部最小值,将导致训练永远达不到期望的收敛状态,以至导致训练失败;步长过大会使得寻解不仔细而得不到最优解。
随机向量功能链路神经网络(random vector functional-link neural network,RVFLNN)[15-16]提供了另一种代表性的方法来学习神经网络中的参数。它基于功能链路神经网络(functional-link neural network,FLNN)[17]的框架,与传统的单层神经网络一样,FLNN 通常依赖于反向传播算法来迭代地训练所有参数。随着隐层数量的增加,这种参数学习方法会存在局部最优、耗时大和收敛慢等问题。RVFLNN为了克服这些缺点,提出了具有随机权重的FLNN,其中输入权重在恰当的域中随机生成,并且训练过程不需进行反复迭代。Igelnik 和Pao[16]以及Pao 和Takefuji[17]对RVFLNN 在训练速度方面的优势及其在一般前馈网络上的泛化特性给出了经典的数学讨论。
近几年提出的ELM 算法和BLS 算法都是简单高效的单隐层前馈神经网络,算法在没有堆叠层结构的情况下,设计的神经网络能够广泛地扩展神经节点,并且在需要增加隐藏节点或者输入数据不断进入网络时递增地更新神经网络的权重。在结构上,ELM 是具有单隐层的三层神经网络,它的隐藏层取自整个原数据集特征域,对其进行非线性特征映射;BLS 包含两个隐藏层,需进行两次特征映射生成特征节点和增强节点,第二层隐藏层包含了原数据特征域的映射特征及其增强节点。ELM 和BLS 算法的核心思想是随机选取网络的输入权值和偏置,在训练过程中保持不变,仅需要优化隐层神经元个数。网络的输出权值则是通过求解Moore-Penrose 广义逆运算得到。相比于其他传统的基于梯度下降的前馈神经网络学习算法,这种训练方法具有实现简单、学习速度极快和人为干预较少等显著优势。
为了保持网络在训练速度上的优势,并且优化算法的结构,本文提出了基于随机映射特征的四层神经网络(four-layer neural network based on randomly mapped feature,FRMFNN)模型,包含输入层、第一层隐藏层、第二层隐藏层和输出层。其中,第一层隐藏层为特征映射层,在第一层隐藏层中对输入的原始特征做了稀疏化处理以获得更好的数据特征,然后在第二层隐藏层中对原始特征域的稀疏化特征[18]进行再次随机映射。
1 基于随机映射的四层神经网络
1.1 网络模型
基于随机映射的四层神经网络提供了一种不需要负反馈迭代训练的神经网络模型,其基于RVFLNN模型,而区别于RVFLNN 的是它不直接用输入节点来构建隐藏节点而是先把输入节点映射成一系列的特征节点,再对特征节点进行再次随机映射。在随机映射网络中,输入数据通过一系列的特征映射传输至第一个隐藏层存储为随机特征,这些随机特征再通过非线性激活函数进一步映射形成第二层隐藏层节点;然后,第二层隐藏节点再传输到输出层。其中,输出层的权重则是通过求解Moore-Penrose 广义逆[19]运算得到最小范数最小二乘解确定。另外,模型还开发了增量学习算法,用于动态地更新系统,扩展网络。
基于随机映射的四层神经网络(FRMFNN)模型是如图1 所示的一个四层网络,设训练样本数为N,特征数为d,类别数为c,则训练集为{(X,T)|X∈ℝN×d,T∈ℝN×c},其中X=[x1,x2,…,xd]为输入向量,T=[t1,t2,…,tc]为对应的输出向量。原始输入数据X经过随机映射后组成n组随机特征,这n组随机映射特征组成第一层隐藏层,其中的特征映射函数为ζi,i=1,2,…,n。记原始输入数据矩阵为X=[x1,x2,…,xd]∈ℝN×d,于是第一层隐藏层中第i组映射特征为。其中是随机生成的权重和偏置矩阵,用于连接输入层到第一层隐藏层中第i组特征节点。
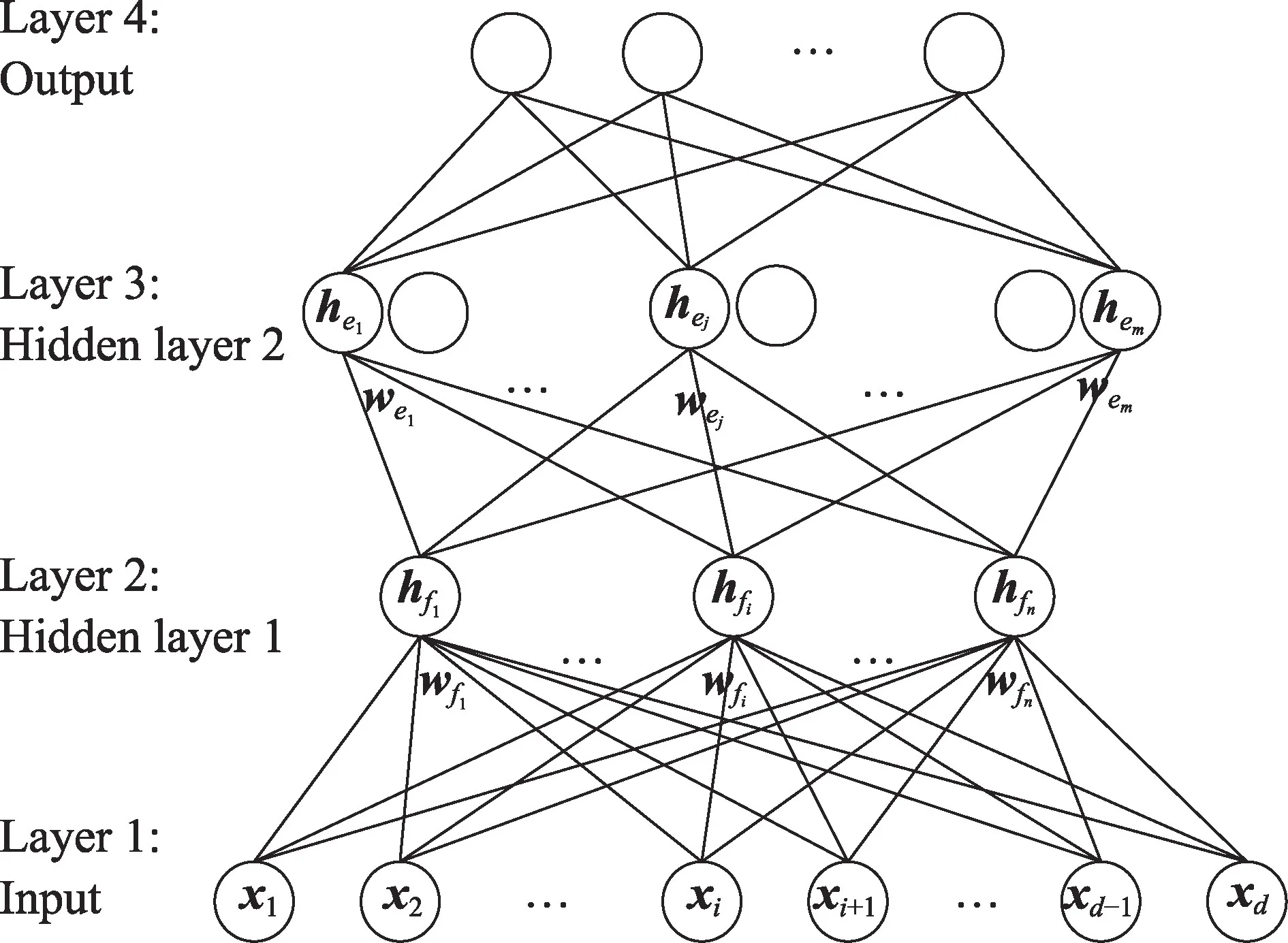
Fig.1 Frameworks of four-layer neural network based on randomly mapped feature图1 基于随机特征映射的四层神经网络结构
定义
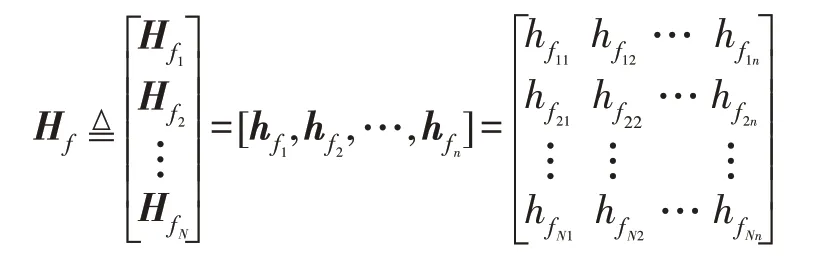
表示第一层隐藏层中N个训练样本的n组映射特征节点集合,然后把Hf传输到第二个隐藏层。
由于模型的特征是随机选择的,为了克服随机性,获得输入特征的稀疏化表达,在第一次随机映射时利用稀疏自动编码器[20-22],应用线性逆问题对随机生成的初始权重矩阵wf进行微调,使用X来解决优化问题[23]:

式(1)中的问题可以等价为下列一般性问题:

上述优化问题可以通过下列迭代步骤解决:
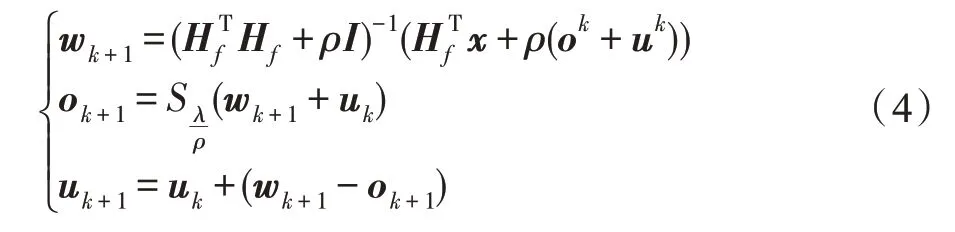
其中,ρ>0,S是软阈值运算符,定义为:
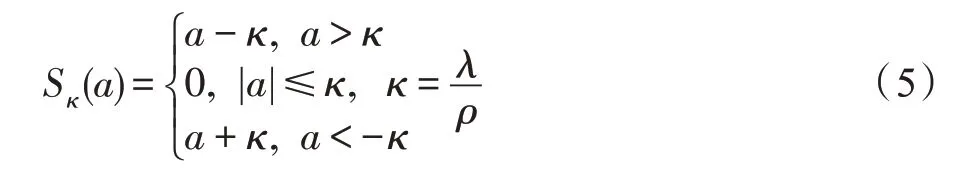
经过稀疏处理,降低了特征表示的复杂度,减少了系数参数,可以充分发挥数据所含有的信息,去掉数据信息的冗余部分,达到最大化利用数据,并且加快模型训练速度。

在建立模型时,每一组映射的函数ζi(⋅)和gj(⋅)可以选择不同的函数。为了不失一般性,在下文中ζi(⋅)和gj(⋅)的下标i和j将被省略。于是,基于随机映射的四层神经网络的数学模型被表示为:

1.2 基于随机映射特征的四层神经网络的函数逼近能力
本节将讨论基于随机映射特征的四层神经网络的通用逼近能力。根据本节中定理1,对于任何定义于标准超立方体Id=[0;1]d⊂ℝd上的连续函数f∈C(Id),具有非恒定有界特征映射ζ(⋅)和激活函数g(⋅)的随机映射特征网络可以等价地表示为:


其中,Wf、和be、bh取自上述所给的概率密度。因为特征映射函数ζ是有界的,所以显然复合后的函数g(ζ(x))是有界可积的,并且无限可微,上述结论的详细理论依据可见文献[24]。这样,上述问题可以转化为单层前馈神经网络(single-hidden layer feedforward networks,SLFNs)的通用逼近能力:
定理2如果激活函数无限可微,权重和偏置向量w和b依连续概率随机选取,那么具有n个隐藏节点的SLFNs 能以零误差逼近n个不同样本。此定理在文献[25]中已给出详细证明。
根据上述定理,对于任意光滑函数fs∈L2(χ),存在一个系列,对于∀ε>0,有。而根据定理1 证明,函数f是连续可微的光滑函数。
因此,
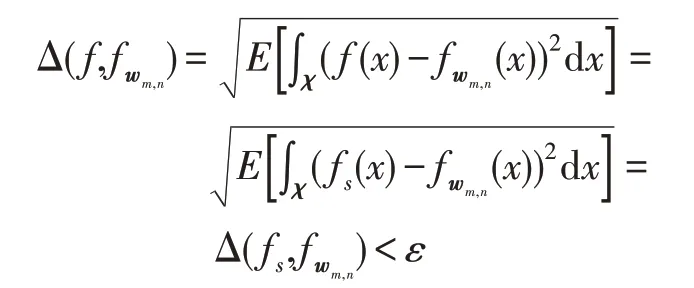
因此,定理2 成立,可以得出结论:

证明成立。
1.3 FRMFNN 基本算法
基于以上结论,可以提出FRMFNN 的基本算法,算法的实现步骤如算法1 所示。
算法1FRMFNN 基本算法


FRMFNN 算法的时间复杂度主要包括四个部分,分别对应上述算法过程中的四个步骤。在步骤1中时间复杂度集中于第一层隐藏节点的计算,其时间复杂度为O(Ndn)。同样,步骤2 中第二层隐藏节点的计算的时间复杂度为O(Nnm),其中N为输入训练样本数,d为输入样本特征维数,n为第一层隐藏节点数,m为第二层隐藏节点数。在步骤3 中,计算伪逆时,当m≤N,即隐层节点数小于训练样本个数,此时时间复杂度为O(m2N);而当训练样本数小于隐层节点个数,即m>N时,伪逆计算的时间复杂度为O(N2m)。在步骤4 中,计算输出权重的时间复杂度为O(mNc),其中,c为目标类别数。

1.4 四层随机映射网络与宽度学习系统
本文提出的基于随机映射特征的四层神经网络(FRMFNN)结构与前面提到的宽度学习系统(BLS)都是基于随机功能链路神经网络(RVFLNN)的结构,生成一系列的随机权重,对原始数据特征进行随机特征映射。不同的是,BLS 把随机特征进行再次映射转化为增强节点后,把特征映射节点Zn和增强节点Hm结合起来,传输到输出层Y中,如图2 所示。而本文提出的FRMFNN 输入数据通过一系列的特征映射转化成随机特征,这些随机特征通过非线性激活函数进一步连接到隐藏层后,随机特征节点和隐藏节点不再结合到一起传输到输出层,而是隐藏节点直接传输到输出层。这样,网络剔除了特征传输过程中的冗余部分,结构更加简单,并且具有良好的分类和回归特性。
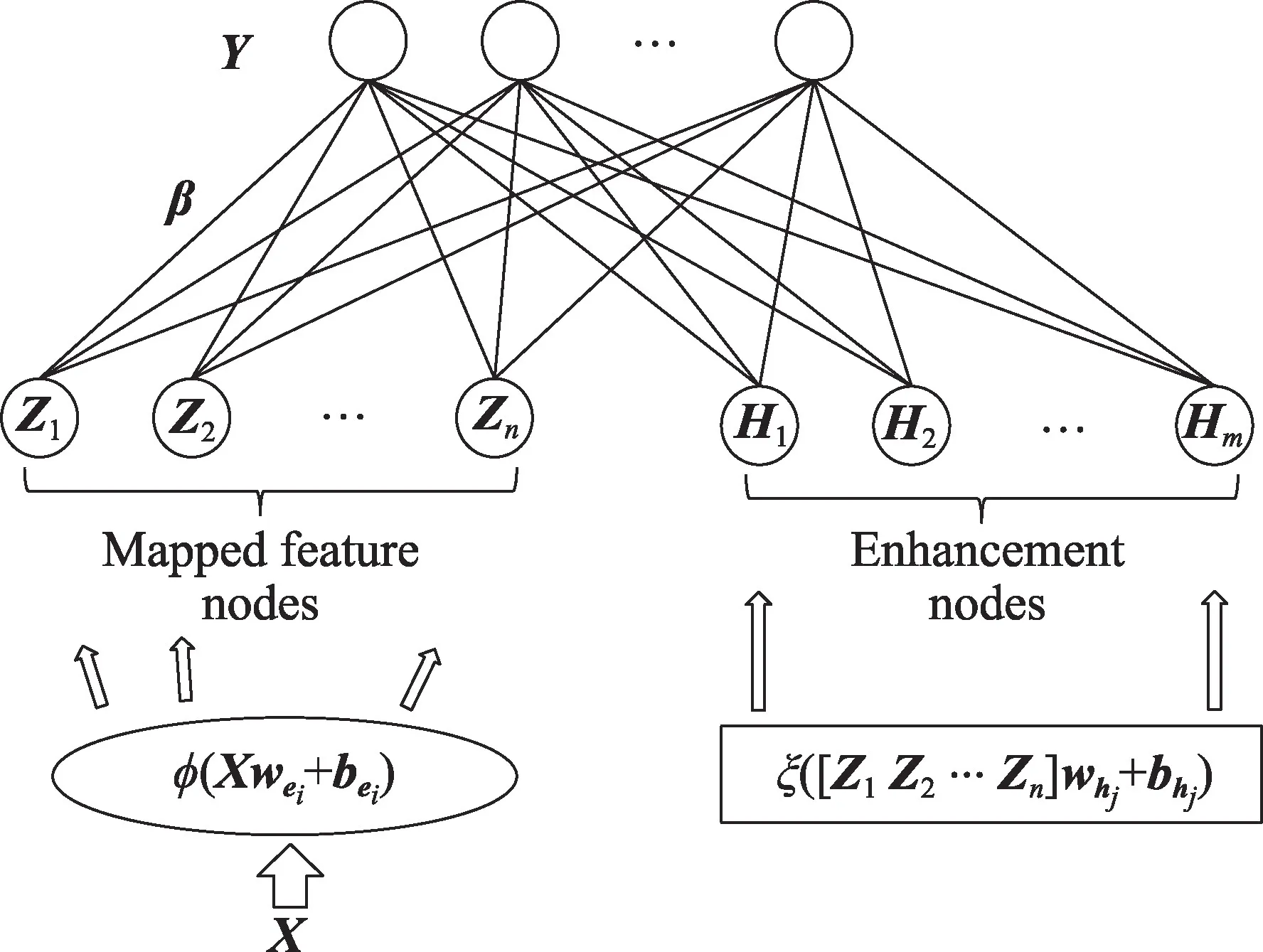
Fig.2 Framework of typical BLS图2 典型宽度学习系统的模型框架
2 FRMFNN 的正则化训练及增量学习
2.1 网络输出权重的快速学习及其正则化
给定N个训练样本{X,T},特征域X∈ℝN×d,目标域T∈ℝN×c,设FRMFNN 网络第一层隐藏层具有n个隐藏层神经元,其特征映射函数为ζ(⋅),第二层隐藏层中具有m个隐藏层神经元且激活函数为g(⋅),则网络的数学模型表示为:

上述伪逆快速学习算法是线性方程组的最小二乘估计,是一个基于经验风险最小化原理的学习过程,其目标是在训练误差最小的情况下获得输出权值,训练出的模型容易产生过拟合现象,而正则化理论可以有效地解决这个问题。在正则化方法中,将一项L2惩罚项加入到损失函数中,这成为了L2正则化,它也被称为岭回归(ridge regression)[26],由此下列优化问题成为求解伪逆的另一种方法:

设需要被最小化的目标函数如下:
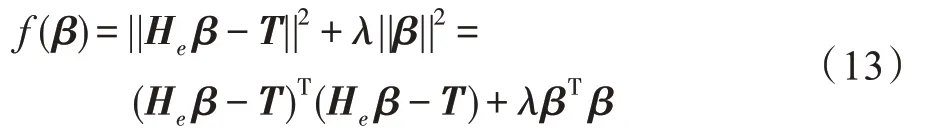
对β进行微分可以得到:
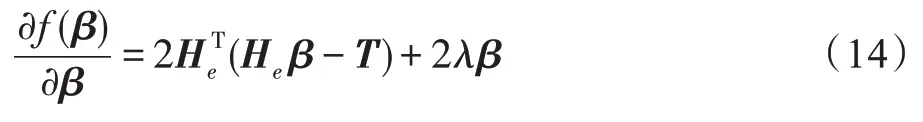
让梯度为0,可以得到:
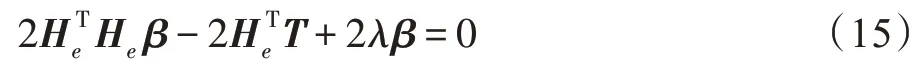
易得:

于是可得:

其中,当m≤N时,即隐层节点数小于训练样本个数,此时I为m×m维单位矩阵;而当训练样本数小于隐层节点个数,即m>N时,利用Woodbury 公式可以等价地求出,此时I为N×N维单位矩阵,显然这种情况下计算N×N维逆矩阵要比计算m×m维逆矩阵高效得多。这样,就可以快速地求出网络的输出权重。
2.2 增量学习算法
在很多情况下,网络的输入数据和网络的神经元个数不是恒定不变的,在动态变化的环境中,或者当网络的输出精度不足时,可以增加输入训练样本或者增加网络的各隐藏层节点数来增加网络输出精度,很多传统的神经网络在增加了新的节点或者训练样本后,需要对网络的权重进行重新训练,这样的过程非常耗时,而FRMFNN 算法可以进行快速的增量学习,当网络中新增加训练样本或者特征节点、隐藏节点时,不需要对整个网络进行重新训练,而仅需对新增部分对应的权重进行训练即可,大大节省了网络的训练时间。下面对FRMFNN 的三种增量学习形式进行讨论。
2.2.1 第二层隐藏节点的增量

其中,
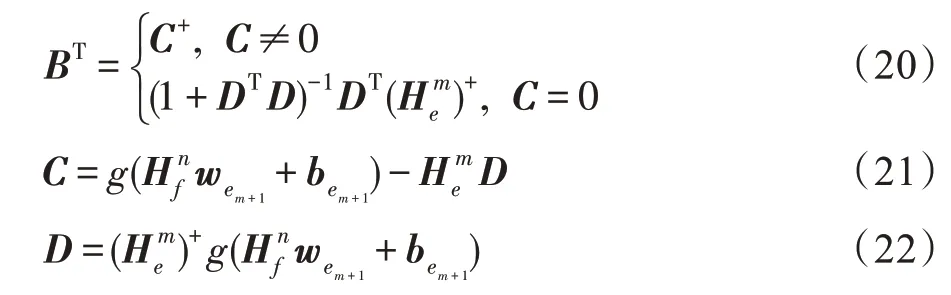
所以,

从上述公式可以看出,增加增强节点后只需要计算新增部分的权重而不需要重新计算整个的权重,使网络能够快速学习。具体算法过程详见算法2。
算法2FRMFNN 增量算法:第二层隐藏节点的增量
输入:原始网络中的最终连接权重β,第一层隐层Hf和第二层隐层He以及伪逆(He)+,训练样本标签T。


上述增量算法的时间复杂度包括四部分,分别对应上述四个步骤,设N为输入训练样本数,d为初始输入样本特征维数,p为新增第二层隐藏节点个数,n为第一层隐藏节点数,m为第二层隐藏节点数,c为目标类别数。步骤1 中时间复杂度集中于隐藏层新节点的计算,为O(Nnp),步骤2 中更新第二层隐藏层输出矩阵的时间复杂度为O(1),步骤3 中计算更新后的第二层隐藏层输出矩阵的伪逆的时间复杂度为O(3mNp+2p2m+Nnp),步骤4 中计算输出权重的伪逆的时间复杂度为O((m+p)Nc)。于是此增量算法时间复杂度为O(Nnp+1+3mNp+2p2m+pnN+(m+p)Nc)。由于通常情况下新增隐藏节点数量p≪N,p≪m,p≪n且c≪N,因此算法时间复杂度为O(Nnp+mNp+pnN+mNc) 。而如果选择对网络进行重新训练,每一次重新训练的时间复杂度为,化简后为,而由于p≪N,p≪m,p≪n且c≪N,显然重新训练的时间复杂度将远大于增量学习算法的时间复杂度。
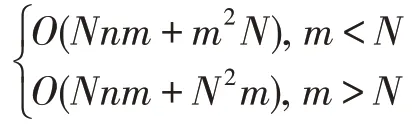
2.2.2 第一层隐藏节点的增量
当模型精度不够时,可以往网络第一层隐藏层中增添新的特征节点,多提取一些有用特征。在FRMFNN 中实现新特征映射的增加非常方便,并且可以通过增量学习算法容易地训练新的连接权重,类似于上述添加新的隐藏节点。
设原FRMFNN 网络第一层隐藏层中有n组隐藏节点,第二层隐藏层中有m组隐藏节点,需要在网络中增加第n+1 组隐藏节点,定义为:
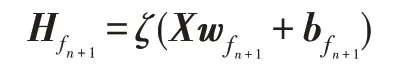
则其所连接的第二层隐藏层节点的输出为:
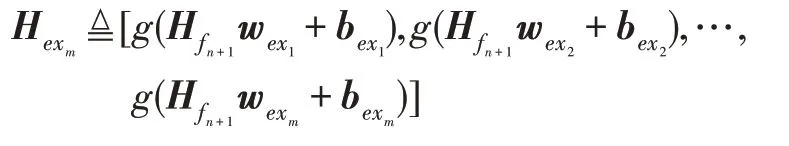

其中:
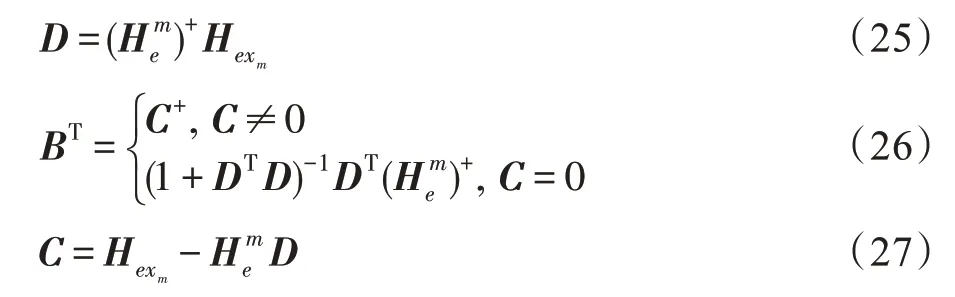
于是,更新后的权重为:
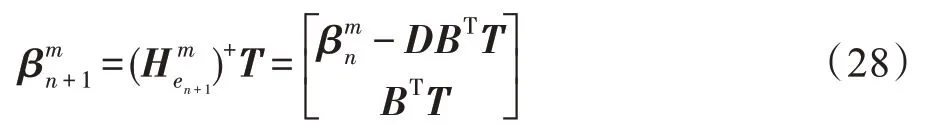
具体算法过程详见算法3。
算法3FRMFNN 增量算法:第一层隐藏节点的增量
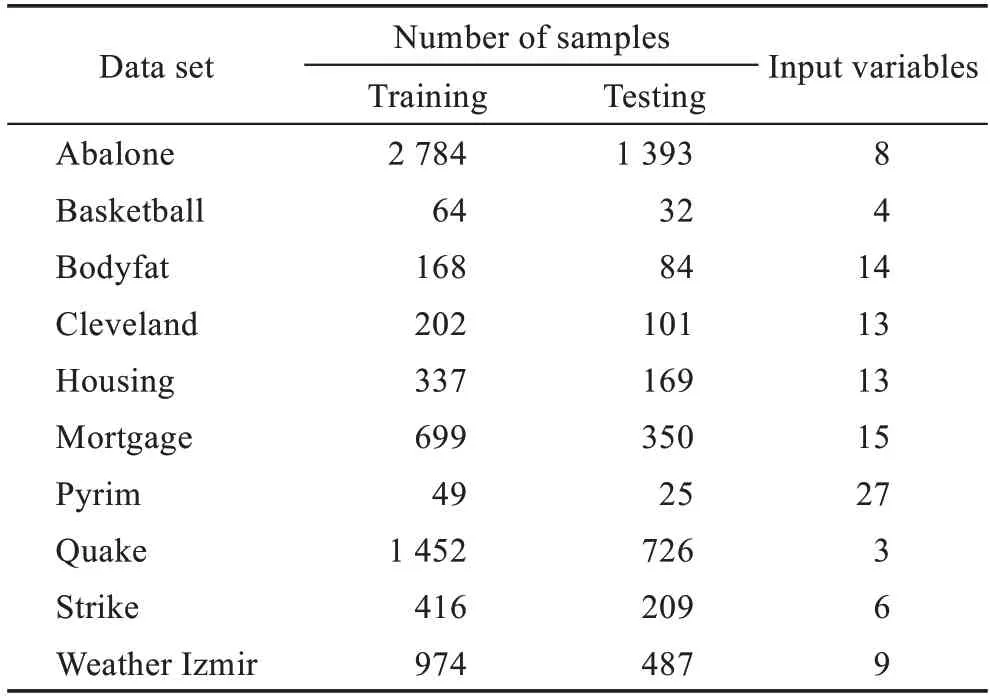
输入:原网络中的网络权重β,第一层隐层Hf和第二层隐层He以及伪逆(He)+,训练样本标签T。

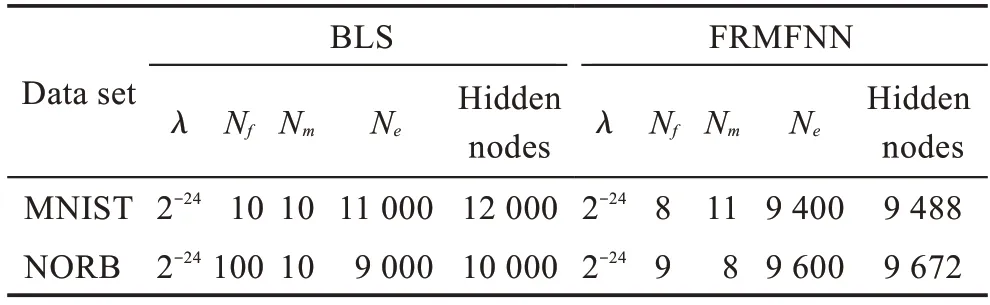
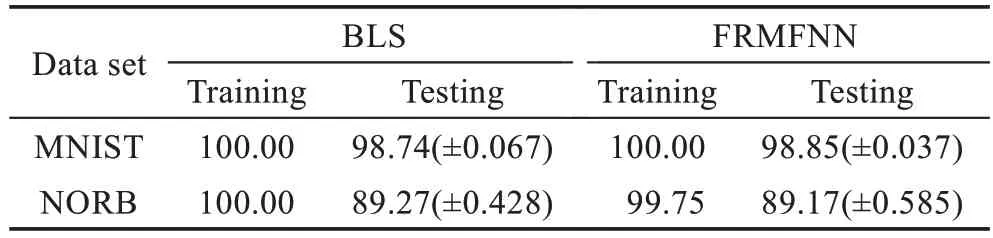
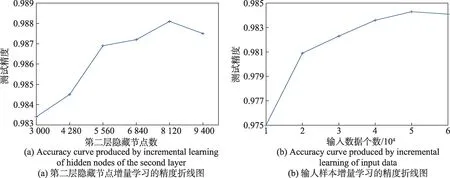
上述增量学习算法时间复杂度主要包括上述四部分,假设增加1 组第一层隐藏节点,设N为输入训练样本数,d为输入样本特征维数,n为第一层隐藏节点数,m为第二层隐藏节点数,c为目标类别数,k为新增的第一层特征映射节点所对应的第二层隐藏节点数。此时步骤1 中的时间复杂度为O(nd),步骤2中计算新增节点对应的第二层隐藏层节点的时间复杂度为O(Nk),步骤3 中计算第二层隐藏层新输出矩阵的伪逆的时间复杂度为O(3mkN+2k2m),步骤4 中计算连接权值的时间复杂度为O((m+k)Nc)。综上所述,第一层隐藏节点的增量算法的时间复杂度为O(nd+Nk+3mkN+2mk2+(m+k)Nc)≈O(mNk+mNc) 。而重新训练整个网络的时间复杂度为,一般情况下,1 2.2.3 输入数据的增量 在实际应用中,训练数据集并不是一次性获取的,当一些新的训练数据加入到网络中时,就需要动态更新网络的输出权重,传统的神经网络结构通常使用的方法是重新训练整个训练集,这样会对已经计算过的数据进行重新训练,这个过程会浪费大量的时间。在FRMFNN 网络中,只需要更新新增的样本部分及其对应的映射特征节点和隐藏节点的权重就可以适应新的训练集,不仅减少了时间的消耗,还能更好地满足实际应用。详细过程如下: 记{Xa,Ya}为新增的训练数据,则由Xa映射的特征节点为: 则新输入数据的第二层隐藏层的输出矩阵为: 更新后的网络的权重可以通过下式计算: 其中, 同样,增加新的输入数据后的网络只需计算包含Hea部分的权重,大大节约了计算时间。具体算法过程详见算法4。 算法4FRMFNN 增量算法:增加训练样本Xa 输入:新增训练样本{Xa,Ya},原网络中的网络权重β,第一层隐层Hf和第二层隐层He以及伪逆(He)+,初始样本标签。 上述增量学习部分的算法复杂度主要包括三部分,对应上述三个步骤。假设新增a个训练样本,并设N为输入训练样本数,d为输入样本特征维数,n为第一层隐藏节点数,m为第二层隐藏节点数,c为目标类别数,则在步骤1 中计算新输入样本的对应第一层隐藏层节点的时间复杂度为O(adn),步骤2 中计算对应新增第二层隐藏层的时间复杂度为O(anm),步骤3 中更新网络输出权重的时间复杂度为O(a2N+2m2N+amN+2amc),c≪N,m,n,因此,输入数据增量算法时间复杂度为O(adn+amn+a2N+2m2N+amN),而重新训练网络的时间复杂度为由上述分析可以看出,所提算法的时间复杂度只与训练样本的数据量和其隐藏节点数有关,如果增加的样本数远大于原始的样本数,则理论上会增大算法的时间复杂度。但是在实际应用中这种情况并不多见。如果增加的训练样本数没有原始样本数多,则对算法的时间复杂度没有影响。可见在实际情况中,应用增量算法的时间复杂度将比多次重新训练网络的复杂度要小得多。 为了检验基于随机映射特征的四层神经网络(FRMFNN)的函数逼近性能,本章在大量的回归和分类数据集上检验其网络的函数逼近效果,并对比了宽度学习系统的分类和回归模型。为保证实验结果的真实准确,每个数据集对应的分类及回归实验都进行了10 次实验,然后计算其平均值和标准差作为最终结果。对于分类问题,本文采用常用的准确率(accuracy)作为衡量指标;对于回归问题,采用均方根误差(RMSE)评估算法的预测性能。 本文所有实验均在同一环境下完成,采用在Windows 10 环境下搭建系统,计算机处理器配置为Intel®CoreTMi3-4150 CPU@3.5 GHz,内存4 GB,主算法在Python3.7 中完成。在实验中,岭回归的正则化参数λ通过网格搜索从{2-24,2-23,…,225}中确定,在生成初始权重时可以选择任意的随机分布,如高斯分布、均匀分布等。在实验中,由于对于初始特征是毫无了解的,因此对于特征的随机选择应该是不具有偏向性的,对于每一个特征的选择机会都应该是均等的,故实验中初始权重和偏置,i=1,2,…,n,j=1,2,…,m,抽取自[-1,1]的标准均匀分布。在建立第二层隐层时,选用Sigmoid 函数作为激活函数。 本节实验从国际通用的加州大学欧文分校的UCI 数据库[27]中选择了10 个回归数据集,它们分为3类:小尺寸低维度、中等尺寸中等维度、大尺寸低维度。表1 列出了数据集的详细信息。这些数据将用于比较FRMFNN 模型和BLS 模型。 Table 1 Details of UCI data sets for regession表1 UCI回归数据集的详细信息 模型的参数对于回归模型是否具有良好性能具有很大影响,因此为了进行公平的对比,需要选择合适的参数。对于BLS 模型和FRMFNN 模型的3 个参数:第一层隐藏层映射特征节点个数Nf,映射组个数Nm,第二层隐藏层隐节点个数Ne使用网格搜索分别从[1,10],[1,30],[1,200]范围内搜索,搜索步长为1。各模型参数的设置详见表2。 表中每个数据集从10 次运行结果中选择最佳结果,并计算10 次结果的平均值与标准差,所对应的每个模型的均方根误差(RMSE)在表3中给出。由表2、表3 可以看出,FRMFNN 在10 个函数逼近数据集上的回归测试精度与BLS 模型相近,而在模型结构上,FRMFNN 在训练过程中需要的隐节点总数比BLS 要少得多。充分证明了FRMFNN模型的函数逼近能力。 本节使用了MNIST 手写数字数据集[28]、NORB数据集[29]和3 个UCI 分类数据集对FRMFNN 模型的分类性能进行了检验,并与BLS 模型在相同的数据集上进行了比较。 3.2.1 MNIST 数据集和NORB 数据集 在本小节中,在经典的MNIST 手写数字图像和NORB 数据集上进行了一系列实验。MNIST 数据集包括70 000个手写数字,这些数字被划分为包含60 000个样本的训练集和10 000 个样本的测试集。每个数字由尺寸为28×28 像素的灰度图像表示。NORB 数据集相比MNIST 更加复杂,共有48 600 个图像,每个图像具有2×32×32 像素。NORB 包含50 个不同的3D玩具物体的图像,这些物体属于5 种不同的类别:动物、人类、飞机、卡车和汽车。采样对象在不同光照条件、高度、方位上成像,其中训练集包含25 个物体(每类5 个)共24 300 幅立体图像,测试集包含其余25个物体的24 300 幅图像。 为了测试FRMFNN 模型在分类数据集上的准确性和效率,在本文的实验中,使用网格寻优寻找最优参数。在BLS 网络模型中,对于MNIST 数据集由总共10×10 个特征节点和1×11 000 个增强节点构成,对于NORB 数据集由100×10 个特征节点和1×9 000 个增强节点组成。FRMFNN 模型的3 个参数:随机映射特征个数Nf,映射组个数Nm,隐藏节点个数Ne,通过网格搜索分别从[1,20],[1,20],[5 000,15 000]中搜索,Nf和Nm的搜索步长为1,Ne的搜索步长为100。各模型的参数设置详见表4。 Table 3 RMSE comparison of BLS and FRMFNN on data sets for regression表3 BLS 和FRMFNN 用于回归数据集的均方根误差比较 Table 4 Parameter settings of BLS and FRMFNN for MNIST and NORB data sets表4 用于MNIST 和NORB 数据集的BLS 和FRMFNN 的参数设置 分类实验结果在表5 中显示。可见,FRMFNN模型对于MNIST 数据集仅需要8×11 个和9 400 个隐藏节点,并且分类精度比BLS 模型更高;而对于NORB 数据集FRMFNN 模型在达到与BLS 模型相似的分类精度时仅需要9×8 个和9 600 个隐藏节点。两个数据集中FRMFNN 模型结构都比BLS 简单,参数规模更小,有力地证明了FRMFNN 的有效性。 3.2.2 UCI数据集 本小节中选取了3 个UCI 数据集,随机选取数据集70%的样本作为训练集,剩余部分作为测试集,数据集的详细信息在表6 中列出。在实验过程中通过网格寻优法来寻找各个数据集对应FRMFNN 的3 个参数:特征节点个数Nf,映射组个数Nm,增强节点个数Ne,通过网格搜索分别从[1,20],[1,20],[500,12 000]中搜索,Nf和Nm的搜索步长为1,Ne的搜索步长为100,寻优结果在表7 中显示。各个数据集的分类准确率实验结果在表8 中显示。 Table 5 Accuracy comparison of BLS and FRMFNN on data sets for classification表5 BLS 和FRMFNN 用于分类的数据集的准确率比较 % Table 6 Details of UCI data sets for classification表6 UCI分类数据集的详细信息 Table 7 Parameter settings of BLS and FRMFNN for UCI data sets表7 用于UCI数据集的BLS 和FRMFNN 的参数设置 Table 8 Classification accuracy comparison of BLS and FRMFNN for UCI data sets表8 BLS 和FRMFNN 用于UCI数据集的分类准确度比较 % 从表8 中可以看出相比于BLS,FRMFNN 在3 个数据集中Robot Navigation 数据集的测试精度与BLS相当,Letter 数据集和USPS 数据集的测试精度都略高于BLS,并且FRMFNN 中的隐节点数相比BLS 要少,从参数规模和分类精度上显示了FRMFNN的优势。 本节将通过在MNIST 数据集上的一系列实验,并与ELM 的两个增量模型I-ELM 和OS-ELM 进行对比来验证增量学习算法的有效性。使用3 种不同的初始网络来测试增量学习: (1)增加第二层隐藏节点数,设置初始网络结构第二层由8×11 个映射特征节点,第三层由3 000 个隐藏节点组成,然后每次动态地向网络中第二层隐藏层中增加1 280 个隐藏节点,增加5 次,达到9 400 个隐藏节点,并与I-ELM 增量模型实验对比,每一次更新结果在表9 中列出。 Table 9 Classification accuracy of I-FRMFNN and I-ELM using incremental learning表9 I-FRMFNN 和I-ELM 增量学习分类精度 (2)增加第一层隐层的特征节点数,其对应的第二层隐藏节点也需要随之增加,在这里使用3 个动态增量来进行动态增量学习:①第一层隐层特征节点;②新增特征节点对应的第二层隐藏节点;③新增的第二层隐层节点。设置初始网络结构第一层由8×7个特征节点,第二层隐藏层由5 400 个隐藏节点组成,然后每次动态地向网络中第一层隐藏层中的特征节点由8×7 个增加4 次,达到8×11 个,每次所增加的特征节点所对应增加的第二层隐层节点数目为250,每次额外增加的隐节点数为750,最终达到9 400个,每一次更新结果在表10 中列出。 ^qUxJg$cf6532179d12d99fb699a7a04fac298140459fca4 (3)增加训练样本数,初始网络取MNIST 数据集中的前10 000 个训练样本进行训练,然后应用增量学习算法,每次动态地向网络中添加10 000 个输入样本,直到60 000 个训练样本都被输入。测试网络中的参数设置为第一层隐藏层8×11 个特征节点和第二层隐藏层5 000 个隐藏节点,并在相同模型参数下与OS-ELM 模型进行对比实验,每一次更新结果在表11 中列出。 Table 11 Classification accuracy of I-FRMFNN and OS-ELM using incremental learning表11 I-FRMFNN 和OS-ELM 增量学习算法分类精度 在实验中本文选取了和FRMFNN 模型类似的基于随机特征选取的ELM 增量模型进行对比实验:增加隐藏节点的I-ELM 模型和增加输入数据的OSELM 模型。为了保证公平性,选取了和FRMFNN 相同的参数规模,I-ELM 在线序列学习模型隐藏节点参数逐个增加到3 000,OS-ELM 初始网络取MNIST 数据集中的前10 000 个训练样本进行训练,每次动态地向网络中添加10 000 个输入样本,直到60 000 个训练样本都被输入。每次增量的实验精度变化在图3 中显示,其中图3(a)显示第二层隐藏节点的增量实验精度变化,图3(b)显示输入样本的增量实验的精度变化,可以看出FRMFNN 模型经过增量学习的结果与其一次性训练的结果相比非常接近,每一次增量学习增加隐藏节点或者增加训练样本,对于网络的输出精度的提高比较稳定,而由于参数随机性的问题会有所波动,但整体在提高。并且,每一次增量学习训练耗时非常短,而若对网络进行重新训练,随着隐藏节点或训练样本的增加,每一次重新训练的时长也在增加,根据表中所得实验结果,可以看出对网络进行增量学习的训练时间比多次重新训练网络的耗时少得多。而I-ELM 和OS-ELM 增量模型的训练非常耗时,在分类精度上增量算法所得精度也不如一次训练的结果。以上实验结果充分表明了增量学习算法的有效性和优势。 Fig.3 Accuracy variation curves of incremental learning图3 增量学习精度变化图 针对数据的分类和回归问题,本文提出了一种基于随机特征映射的四层神经网络并提出了它的增量学习算法。该算法通过改进功能链路神经网络,其各层隐层权重都是通过标准均匀分布随机生成的,并且在第一层隐藏层中对输入特征做了稀疏化处理,最后利用岭回归算法求伪逆计算出最终输出权重。在训练过程中可以动态地对网络进行增量学习,向网络中添加特征节点和隐藏节点或者输入新的训练样本而不需要对全部网络权重进行重新训练。文中将提出的算法应用于常见的分类和回归数据集中做了大量实验,并与BLS 和ELM 的增量算法进行了对比。实验结果表明:FRMFNN 模型拥有比宽度学习等神经网络模型更简单的模型结构和更小的参数规模,并且可以在各分类和回归数据集上取得和目前BLS 模型相当的结果,在增量学习中的表现不论从训练速度还是分类精度上,都优于I-ELM和OS-ELM 模型,显示了FRMFNN 模型的优势。下一步将对随机映射神经网络的各种结构进行更加深入的研究,对其在增量学习时随机映射的稳定性提出更好的解决办法。

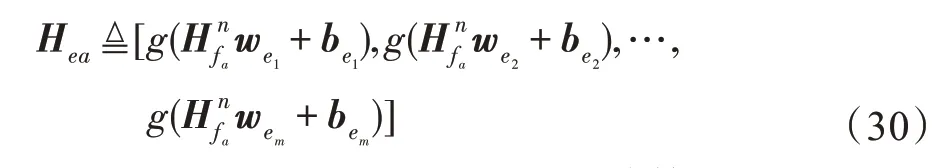
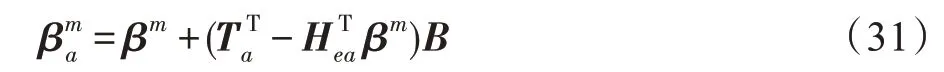


3 实验及结果分析
3.1 回归
3.2 分类

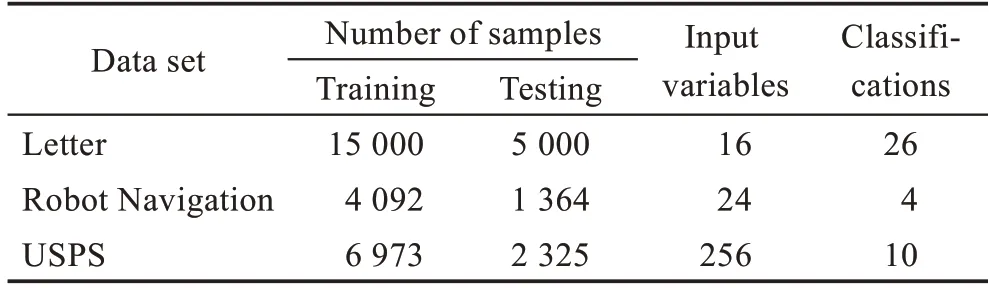
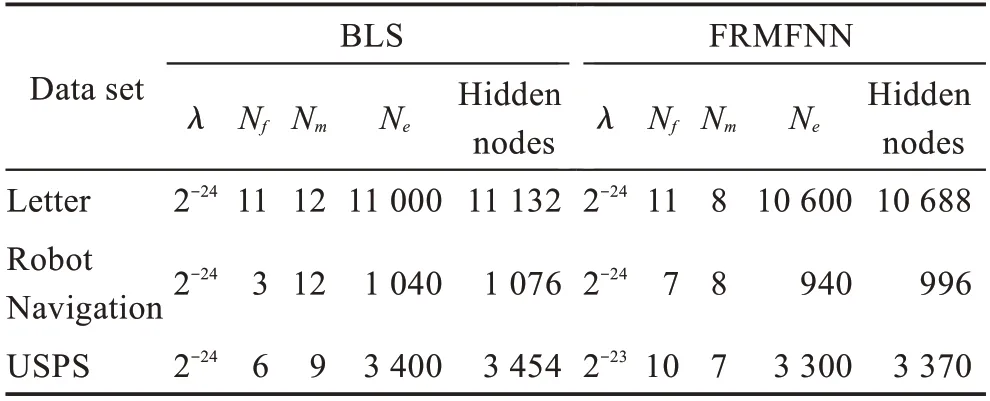

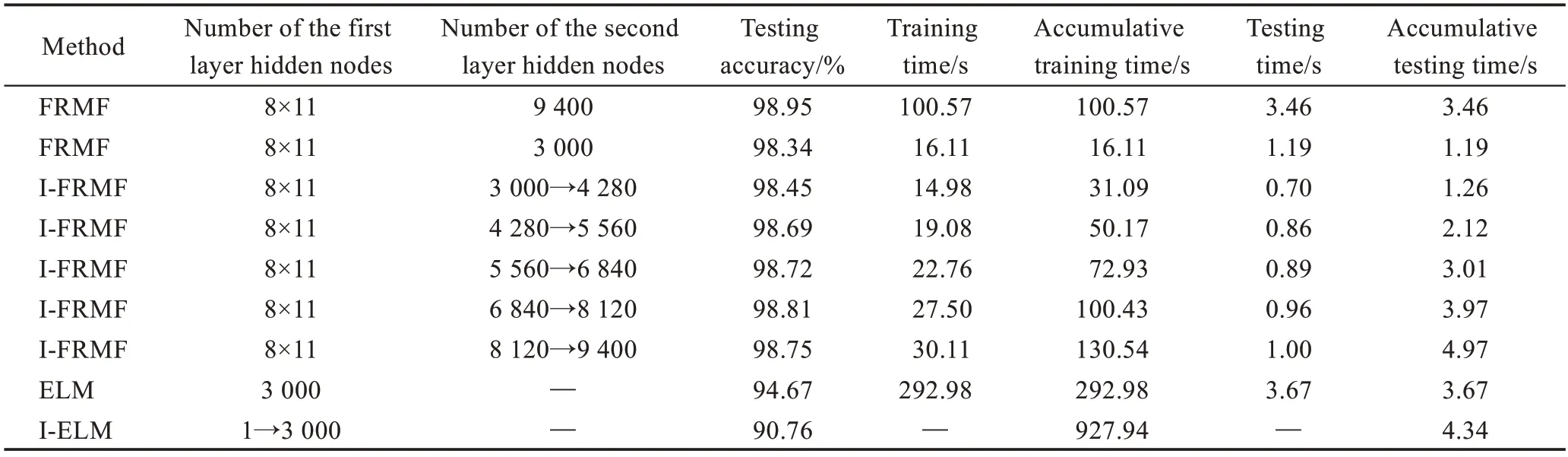
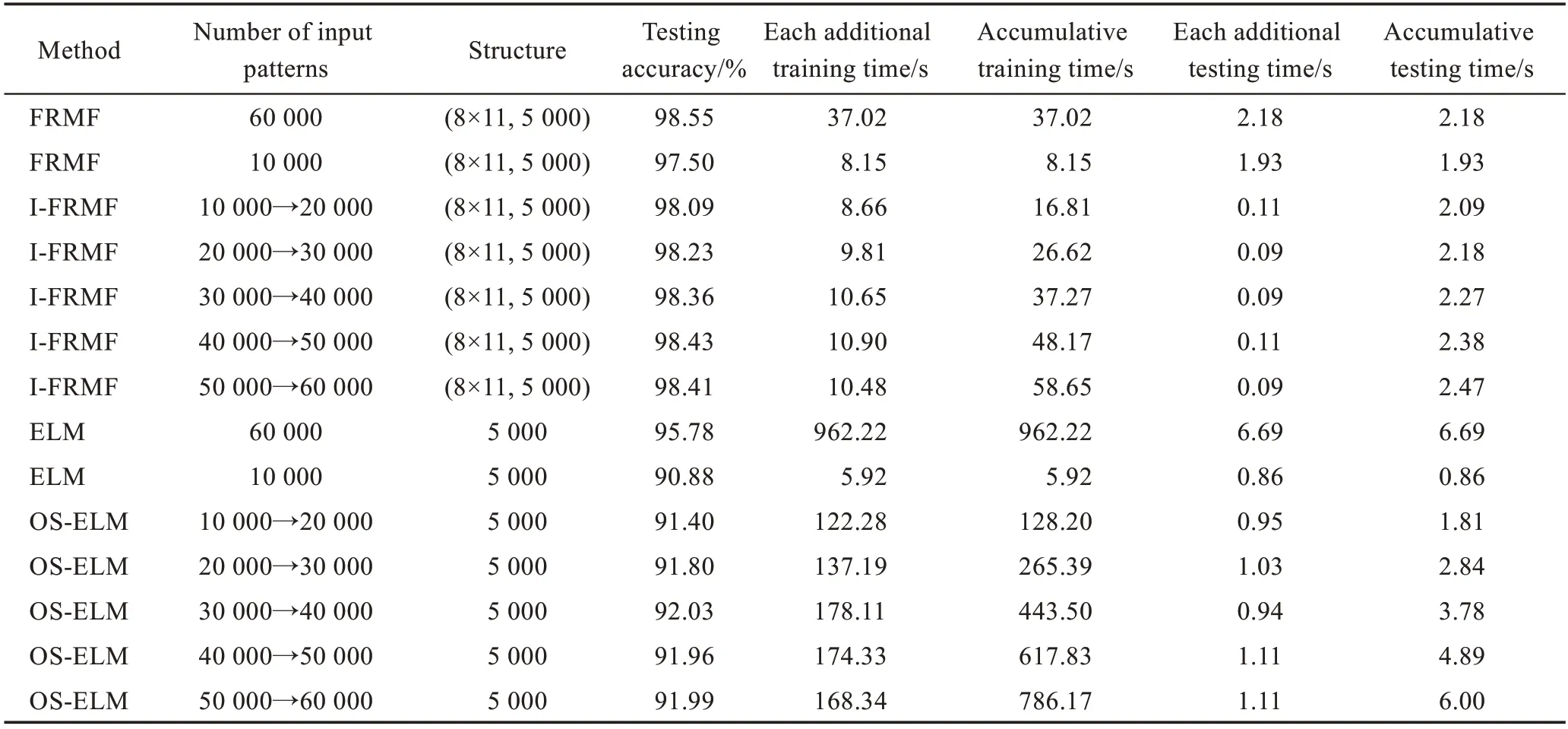
3.3 增量学习
4 结束语
猜你喜欢
北京大学学报(自然科学版)(2022年4期)2022-08-18
舰船科学技术(2022年11期)2022-07-15
北京航空航天大学学报(2022年5期)2022-06-06
中国教育信息化·高教职教(2022年4期)2022-05-13
财会月刊·下半月(2022年4期)2022-04-25
当代陕西(2022年6期)2022-04-19
社会科学战线(2022年2期)2022-03-16
煤气与热力(2022年2期)2022-03-09
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
