
基于AAE的网络性能异常发现
2021-08-02 03:48王田丰胡谷雨彭冬阳
计算机技术与发展 2021年7期
王田丰,胡谷雨,王 睿,彭冬阳
(陆军工程大学 指挥控制工程学院,江苏 南京 210007)
0 引 言
为了确保良好的网络性能,需要对各个网络节点的吞吐量、延迟、丢包率等关键指标进行实时的监测和维护。这些指标在一定程度上反映了特定网络中用户的行为模式和网络的特性,具有动态性和周期性。网络中物理链路出现故障、网络遭受攻击导致故障等多方面的因素,都会导致网络出现异常,在这些监测的指标上也会有相应的异常体现。及时高效地发现网络指标的异常可以给网络运维人员赢得宝贵的时间来处理网络中出现的故障。
网络KPI(key performance indicator)异常检测(anomaly detection)问题可以抽象为时序序列异常检测问题,目的是为了发现不符合正常模式的序列段。有监督学习的方法[1-2]依赖准确的标注,而在实时的网络系统中,需要维护的指标数目多,并且数据都是实时产生的,数据量非常大,因此人工标注难以满足这一要求;无监督学习的方法不依赖于标注,在此问题上也有应用,但检测效果上仍不如人意。
为了解决这些困难,该文提出一种基于AAE[3](adversarial autoencoders)的无监督异常检测方法。目前,AAE被广泛应用在语音和图像生成领域,并取得很好的效果。在KPI异常检测场景下,用滑动窗把数据集切分成小样本,其中异常的窗口样本只占很小一部分。AAE模型在训练中学习到的是正常样本的数据分布模式。因此在异常检测阶段,正常样本能够被很好地编解码,重构误差很小,并且编码器输出的特征向量也更有可能被鉴别器识别为“正常”,综合两者判断是“异常”的概率比较低;而异常样本不符合正常模式,不仅重构误差大,而且编码输出的特征向量也更容易被鉴别器判为“异常”,总体上被判为“异常”的概率比较高。
该文的创新点总结如下:
(1)针对网络性能异常问题,提出了基于AAE的无监督的检测方法;
(2)针对原始数据部分缺失问题,引入了KNN算法进行数据填充,进一步提高了模型的检测精度;
(3)实验结果表明,AAE-AD在最优F分数指标,AUC指标上均优于其他的无监督检测算法;
(4)AAE和VAE两个模型理论上有一定的相似性,对于两个模型在检测性能上的差异,给出了合理的解释。
1 相关工作
通用异常检测技术的调研报告[4]给出了异常检测的定义和异常检测可遵循的原则,异常检测就是检测测试数据是否符合正常的数据分布,不符合正常数据分布的就被划分为异常,而且异常数据占比通常很小。许多新的方法被应用在网络异常检测领域[5],如集成学习[6]在网络异常检测中的运用解决了网络异常种类多、单一模型处理问题时局限性大的问题。
网络关键指标异常检测问题是网络异常检测问题的一个分支,属于时序序列异常检测。由于在网络监测系统中,记录的时序序列数据量非常庞大,人工难以给出满足有监督学习训练时需要的大量准确标注,因此这个问题往往在无监督学习范畴下解决比较合理。
自回归移动平均模型(autoregressive integrated moving average)是一种基于统计理论的无监督预测模型,结合了自回归模型(AR)和移动平均模型(MA)的优点,对于非平稳序列也能达到良好的预测效果。ARIMA模型在异常检测领域[7]也有广泛的应用,如孙建树[8]等人将ARIMA运用到水文时间序列异常检测问题中,取得了良好效果。
RNN和LSTM是最常用的两种深度时序序列预测模型,同时也是时序序列异常检测[9]的有效方法。一般在异常检测中,采用预测值与真实值差值的绝对值作为异常分值。其中,李洁等人[10]提出了基于RNN的多维时序序列预测算法;仇媛等人[11]提出了基于LSTM和滑动窗口的流数据异常检测方法。
生成模型是一种典型的无监督学习模型,在现在的图像和语音生成领域运用的非常广泛,在异常检测领域也衍生出一些可用的方法。变分自编码器(variational autoencoder,VAE)和生成式对抗网络(generative adversarial networks,GAN)是两种运用广泛且具有代表性的生成器模型。其中VAE[12]使用了变分推断技术[13-14],通过不断优化证据下界(evidence lower bound,ELBO)来使得自编码器在得到训练的同时,模型生成的样本空间分布能不断靠近先验分布,这里的先验分布一般假设为混合高斯分布;而GAN[15]模型分为生成器和鉴别器,通过交替训练生成器和鉴别器来使得生成器生成的样本越来越真实,同时鉴别器对于真假样本的鉴别能力越来越强,最终达到平衡。其中,VAE与双向领域算法结合成一个混合模型[16],在MNIST和CIFAR-10数据集上取得了较好的异常检测效果。余广民等人[17]综合论述了基于GAN的异常检测算法,同时GAN也被应用到视频异常检测场景[18]中。
但是笔者发现上述方法中,传统的有监督模型的性能依赖于大量的人工标签,而现有的无监督模型ARIMA、RNN、LSTM、VAE、GAN在网络数据集上的异常检测效果仍然不够好,难以满足业务上的需求。为此,提出了一种新的基于AAE的异常检测模型AAE-AD。这是一种无监督学习模型,适用于网络运维中人工标注困难的情境,该模型能够很好地学习到“正常”时序序列的特征空间分布,在针对网络KPI的异常检测中达到很好的效果。
2 AAE-AD模型介绍
2.1 AAE-AD数据预处理
网络监测器记录的网络数据往往长达数周。第一,不同时间段内的数值范围相差可能很大,并且往往带有噪声;第二,由于监测器故障或者人工操作失误,数据可能存在部分缺失。针对这两个问题,先对数据进行标准化处理,然后进行数据填充。数据标准化采用z-score方法,表示如下:
(1)
其中,μ为观测值序列X的均值,σ为X的均方差;数据标准化消除了奇异样本数据的影响,能够提高算法精度并加快算法的收敛速度。
缺失数据填充借鉴KNN[19]算法思想,基本流程如以下伪代码所示:
算法1:KNN填充空数据。
输入:原始观测值序列X';
输出:空值填充后的序列X''。
1:设置近邻数量k,计算空值区间集合M={(s1,e1),(s2,e2),…,(sq,eq)}
2:for (si,ei) inM
3:j=0
4:whilesi+j≤eido
5:找到与下标(si+j)最近的k个非空近邻下标,设为集合G
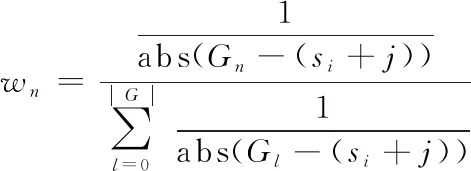

8:j=j+1
9:end while
10:end for
KNN填充算法中,首先获取所有的空值区间M={(s1,e1),(s2,e2),…,(sq,eq)},s代表区间起始点,e代表区间结束点,从X'[s]到X'[e]都是空值。算法的主要思想是利用坐标最近的k个点来计算填空值,其中邻居的影响与相隔的距离成反比,距离越近影响越大。算法第6行中,对各个邻居的影响力进行了归一化;第7行,对各个邻居的值进行加权求和,计算出填充值。
最后,采用滑动窗口方法将观测序列切分成固定长度的样本。模型训练中,每个长度为W的时间窗口为一个训练样本;异常检测中,也以时间窗口为基本单位。在实际的网络系统中,允许存在一定的时延,因此,只要选取合适的时间窗口,能够保证异常检测模型的实时性和实用性。
2.2 AAE-AD模型训练
整个AAE-AD框架分为模型训练和异常检测两部分。如图1所示,训练过程包含了对编码器、解码器和鉴别器的训练。

图1 AAE-AD模型的训练
编码器和解码器使用的是CNN网络,将一维数据变成二维数据使模型更好地学习到数据的空间分布特性,能够更好地进行特征提取和还原。编码器对训练样本进行特征提取产生特征向量,分别作为解码器和鉴别器的输入;解码器将特征还原后结合原始输入计算出重构损失,并对编码器和解码器参数进行更新;鉴别器结合编码器产生的特征向量和从混合高斯模型中采样出的向量计算出鉴别损失来更新鉴别器和编码器,这在提高鉴别器鉴别能力的同时,也使得编码器产生的特征向量越来越真实,最终能够达到混淆鉴别器的程度,两者达到一定的平衡。
2.2.1 自编码器网络的训练
自编码器网络实际上是一个信息压缩和还原的过程,编码器G1将高维数据向量x压缩成低维特征向量z,而解码器G2负责将低维特征向量z尽量还原回去。在编解码的过程中存在信息损耗,信息损耗越大,重构效果越差。自编码器的训练就是通过最小化重构损失来增强网络的信息压缩与还原的能力。这里采用均方差损失,所以自编码器平均损失函数可以表示为:
(2)
其中,xi是来自原始数据的样本。
2.2.2 对抗网络的训练
AAE中对抗训练的思想来自于GAN,可以看成一个两者博弈的过程。这里就是编码器部分G1与鉴别器D的博弈[20],训练的目标就是能够使G1编码结果越来越接近“真实分布”,即预设的先验分布p(z),同时使得鉴别器能够更好地区分特征向量到底是来自于编码器输出的特征向量还是采样自“真实分布”的向量。先验分布假设为混合高斯分布,因为混合高斯分布经过神经网络投射可以拟合任意的分布。总体优化目标可以作如下表示:
Ex~pdata(x)[log(1-D(G1(x)))]
(3)
鉴别器优化目标表示为:
(4)
编码器优化目标表示为:
(5)
其中,zi是采样自先验分布的向量,xi是来自原始数据的样本,n为样本数。
自编码器网络和对抗网络交替训练,训练过程如以下伪代码所示:
算法2:AAE-AD模型训练。
输入:训练样本集X;
输出:模型G1,G2,D。
1:对训练样本集X进行预处理,产生输入样本{x1,x2,…,xn}
2:for theqthepoch do
3:for theithsample do
4:将xi输入AAE-AD模型,产生编码器输出G1(xi),解码器输出G2(G1(xi)),鉴别器输出D(G1(xi))
5:计算lossA=mse(xi,G2(G1(xi))),使用Adam[21]优化器更新编码器和解码器参数
6:从混合高斯分布中采样出向量zi,产生鉴别器输出D(zi)
7:计算lossD=-logD(zi)-log(1-D(G1(xi))),使用Adam优化器更新鉴别器参数
8:计算lossG1=log(1-D(G1(xi))),使用Adam优化器更新编码器参数
9:end for
10:end for
2.3 AAE-AD异常检测
在网络训练结束后,模型中自编码器和鉴别器有相对独立的异常判断机制,如图2所示,模型的异常检测是将测试样本输入模型,结合模型的自编码器部分产生的重构误差和鉴别器部分产生的鉴别分值来对样本做异常判断的过程。

图2 AAE-AD模型的异常检测
在异常检测中,AAE-AD模型的判断依据是测试样本是否符合正常模式。自编码器通过训练学习到了样本空间X到特征空间Z的投射函数qφ(z|x)和特征空间Z到样本空间X的投射函数hφ(x|z),能够对符合正常模式的样本进行很好的编解码。因此,对于正常样本来说,经过自编码器网络计算出的重构误差较小,而异常样本的重构误差较大。对抗网络经过训练,编码器G1能够将符合正常分布的样本编码成能够混淆鉴别器D的特征向量,鉴别器D也往往认为这是“真的”;而异常样本难以被很好地编码,其编码出的特征向量会被鉴别器D判为“假的”。结合这两者给出的结果计算测试样本的异常分值,如果异常分值大于设定的阈值则被判为异常。
异常检测过程如以下伪代码表示:
算法3:AAE的异常检测。
输入:测试样本集X;
输出:测试样本异常分值S。
1:对测试样本集X进行预处理,产生输入样本{x1,x2,…,xn}
2:for theithsample do
3:将xi输入自编码器网络,输出G2(G1(xi)),计算s1=mse(xi,G2(G1(xi)))
4:将xi输入对抗网络,输出D(G1(xi)),记为s2=log(1-D(G1(xi)))
5:计算样本xi的总异常分值s=λs1+(1-λ)s2
6:end for
3 实验验证
3.1 实验数据集
实验数据集选自2018年AIOps的KPI异常检测竞赛中的8组KPI数据。网络监测设备的数据采样间隔单位是分钟,这8组数据的异常点已经由专业网络管理人员标出,因此这8组数据可以在实验中用来比较不同算法间的性能。表1中列出了各组数据的检测点数量、异常点数量和缺失点数量,其中F,G,H三组数据不包含缺失点。

表1 实验数据集
3.2 评价指标
F1分数是一种用来衡量分类模型性能的指标,兼顾了分类模型的精确率(precision)和召回率(recall),计算公式如下:
(6)
F1分数值越大表明分类性能越好,最优F1分数指的是取不同分类阈值时,数值最大的F1分数。
ROC曲线是根据一系列不同分类阈值,以真正例率(true positive rate,TPR)为纵坐标,假正例率(false positive rate,FPR)为横坐标绘制的曲线。AUC(area under curve)为ROC曲线下面积,AUC越大代表分类模型效果越好。
在实验中,异常检测的单位是窗口,每个窗口用该窗口中最后一个点作为记录点。数据集中已经给出真实的异常点,记包含异常点或者丢失点的窗口为“真实异常窗口”。预测结束以后,记异常分值大于阈值或者包含丢失点的窗口为“预测异常窗口”。通过改变异常判断的阈值,可以计算出最优F1分数并且绘制出ROC曲线,进而计算出AUC值。
3.3 实验参数设置
把每一个数据集都划分为三部分,前50%用于训练,中间30%用于验证模型损失,后20%用于异常检测。K代表了模型的特征空间维度,在训练中也是一个重要的参数。K取值太小会导致不同维度之间的相关性太高,特征空间的表示能力会变差,同时模型的训练也更容易过拟合。在经过反复的实验后,选取K=10。滑动窗口是训练和检测的基本单位,窗口长度W设置太大会增加过拟合的风险,设置过小会导致模型难以学习到数据的正常分布模式,在反复的实验中发现窗口大小W设置120较为合适。异常检测中,异常分值由自编码器和鉴别器的输出共同决定,设置λ为0.8,这也是在反复实验中获得的经验值,λ如何取值能够使得模型性能最佳也是后续的一项工作。
3.4 神经网络设置
模型分为三个子网络,分别是编码器网络、解码器网络、鉴别器网络。编码器网络中使用了4层神经网络,第一层为包含144个节点的全连接网络;第二层为通道数32,5*5卷积核的卷积层,使用LeakyReLU做激活;第三层为通道数64,5*5卷积核的卷积层,使用LeakyReLU做激活;第四层为节点数2K(K为特征维度)的全连接层。编码器输出为特征向量z的均值和标准差,使用重参数化技巧采样出特征向量z,分别作为解码器和鉴别器的输入。解码器使用4层神经网络,第一层为包含576个节点的全连接层;第二层为通道数64,5*5卷积核的反卷积层,使用LeakyReLU做激活;第三层为通道数为32,5*5卷积核的反卷积层,使用LeakyReLU做激活;第四层为节点数为W的全连接层。鉴别器使用三层全连接网络,节点数分别为128,128,1。优化器选择上,三个网络都使用了Adam优化器。
3.5 结果分析
3.5.1 模型间性能对比
如表2所示,在最优F分数指标上,AAE-AD模型(“0”值填充)在数据集A,B,C,E,F,G,H上都优于其他的无监督检测模型,性能提升分别为3.31%,14.06%,14.48%,13.58%,112.67%,356.19%,454.34%。可以看到,在F,G,H数据集上,异常点比较少,对于模型检测的精确度要求非常高,其他无监督算法的F分数普遍在0.2以下,效果非常不理想;而AAE-AD在这几个数据集上依然能保持良好的检测精度。在数据集D上,RNN,LSTM模型性能超过了其他的无监督模型,F分数分别为0.966和0.936。除了AAE-AD之外,VAE的性能在A,B,C,E数据集上普遍优于其他无监督模型,总体来说是一种次优的方案。ARIMA优点是不需要训练模型,能达到一定的精度,可见在对精确度要求不是很严格的应用场景中,可以采用ARIMA模型。

表2 最优F分数指标对比
如表3所示,在AUC指标上,AAE-AD模型(“0”值填充)在B,C,E,F,G,H数据集上都优于其他无监督检测模型,性能提升分别为3.21%,2.78%,1.43%,59.09%,50%,64.29%。在数据集A上,GAN模型表现最佳,AUC值为0.844;在数据集D上,RNN和LSTM模型超过了其他方法,AUC值分别为0.978和0.970。与最优F指标类似,VAE仅次于AAE方法。

表3 AUC指标对比
3.5.2 KNN填充与“0值填充”
因为数据集F,G,H不包含缺失值,所以仅在A~E数据集上对比了KNN填充与“0”值填充的性能差异。在最优F指标上,KNN填充方法在C,D,E三个数据集上提升了检测精度,在数据集A上没有变化,在数据集B上降了0.71%的精度;在AUC指标上,KNN填充方法在数据集D上提升了2.51%精度,在数据集B上降了0.60%的精度,其他三个数据集不变。由此,可以发现,KNN填充方法可以在一定程度上提高AAE-AD模型的检测精度,是一种有效的缺失值填充方法。
3.5.3 AAE与VAE性能差异分析
AAE模型与VAE模型在模型训练中存在一定的相似性。其中AAE通过对抗训练的方式来约束特征空间的向量分布;而VAE通过KL散度的约束来实现这一点。在图像分类任务中,VAE的特征空间分布存在空隙[3],而AAE的特征空间结合非常紧密;在本实验中也发现了类似的现象。为了使特征空间更直观可见,将特征维度设为2,在其他训练参数相同的情况下,两者的特征空间如图3所示。
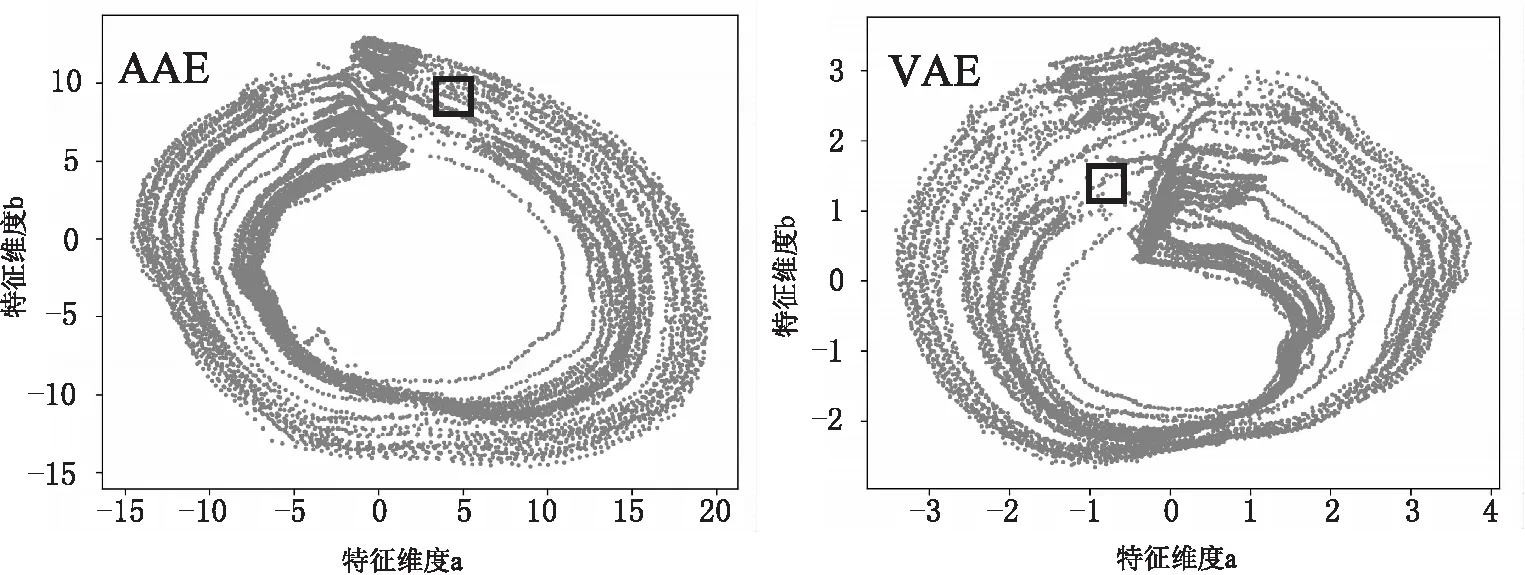
图3 AAE与VAE特征空间对比
其中两图中黑框区域为相同时间区域对应的特征空间,AAE中此区域点分布密集而均匀,而VAE在此区域的分布较为零散;采样了其中的一个点,分别用AAE和VAE进行编码解码,结果如图4所示。可见,在特征空间离散区域,VAE对样本的重构效果并不好,容易把正常点判成异常点,从而影响整体的检测精度,这也是VAE检测性能低于AAE的主要原因。

图4 AAE与VAE重构效果对比
4 结束语
针对网络性能异常发现任务中检测精度不够高的问题,提出了AAE-AD模型,其中使用了KNN作为缺失值填充的方法。实验结果表明,AAE-AD模型在异常发现任务中性能普遍优于现有的其他无监督检测模型;其中KNN缺失值填充技术能进一步提升AAE-AD的性能。
后续工作包括两方面,一是AAE-AD模型对参数敏感,如窗口大小W,特征空间维度K,异常分数计算系数λ,需要进一步探讨参数变化和模型性能的定性关系来提高模型训练的效率;二是尝试将AAE-AD模型运用在多维时序序列异常检测中,以提升它的实用性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
中学生理科应试(2021年11期)2021-12-09
数字技术与应用(2021年1期)2021-03-24
数学学习与研究(2018年15期)2018-11-12
领导决策信息(2018年16期)2018-09-27
科技与创新(2017年5期)2017-03-28
数学学习与研究(2017年3期)2017-03-09
电脑知识与技术(2016年22期)2016-10-31
计算技术与自动化(2014年1期)2014-12-12
西南学林(2011年0期)2011-11-12
