
基于Rényi熵的q-指数分布及其可靠性分析应用
2021-08-04 03:45王敏夷白颖利汪东敏李西峰谢永乐
电子科技大学学报 2021年4期
谢 暄,王敏夷,白颖利,汪东敏,李西峰*,谢永乐
(1. 电子科技大学自动化工程学院 成都 611731;2. 中国空间技术研究院通信卫星事业部 北京 海淀区 100094;3. 四川慧龙科技有限责任公司 成都 610041)
随着集成系统复杂性的日益增加,系统建模和可靠性保证面临越来越大的挑战。在可靠性分析的各种场景中,虽然指数分布模型已被较广泛地用于建立系统寿命模型[1],但由于指数分布的风险函数是恒定的,因此直接将指数分布用于描述系统寿命,存在无法描述损伤过程和无法准确反映故障累积效果的问题,最典型的例子是将指数分布简单应用于描述人类死亡率和电子设备生命周期,效果不够理想。对这类过程,通常需要采用具备浴盆特征的风险函数所对应的寿命分布来准确描述。韦伯分布作为指数分布的概括,以及它的带有浴盆型风险函数的扩展得到了重视,并被广泛应用于许多领域[2-4]。
目前关于指数分布推广的研究,主要集中在广义韦伯分布的累积分布函数的参数加法上。大多数情况下,这些韦伯类型的一般化是通过简单的参数加法技术来实现的。此方法一般除保留了原有的参数,还引入了一些新的参数,使得模型对寿命数据的拟合,多数情况下优于没有新参数的模型。
基于参数加法,文献[5]提出了四参数广义指数模型,称为广义指数化线性指数分布。结果表明,这一扩展可以导出一系列指数型分布,如指数化韦伯分布。结合韦伯分布和改进的五参数韦伯分布,文献[6]提出了一种修正的韦伯分布扩展。基于此,文献[7]又提出了一个离散五参数修正型的韦伯分布,并发现基于这种分布的离散数据拟合胜过其他3个修正的韦伯模型。
尽管韦伯推广在寿命模型中具有良好的效果,但由于参数估计过程复杂,参数物理意义不明确(至少这些参数在这些广义的分布中,不能直接指示系统的当前状态),限制了韦伯推广的应用[8-10]。
本文提出了一种广义双参数指数分布,它可以作为可靠性分析的基础,例如浴盆型风险函数的构造和有用寿命预测。与传统的参数加法不同,本文用最大熵原理得到广义指数分布。从物理角度看,这种广义分布的主要优点是两个参数都具有明显的物理意义。一个参数具有分形意义,表示系统的稳定程度;另一个参数则与系统的平均行为密切相关。两个参数均可以用来刻画系统的性能。
1 q-指数分布模型
1.1 一般化的指数分布
基于Rényi熵,可以通过最大熵方法,得到广义指数分布:
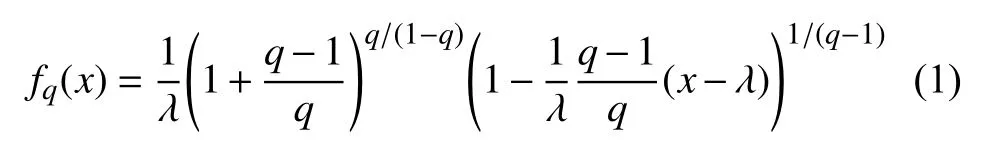
式中,q是分形参数;λ是分布的期望值;q和λ都是非负的。根据参数q和λ的值,概率密度函数fq会有不同的形态。图1所示为不同的参数q时固定均值λ下的fq形态。可以看出q-指数分布是单峰分布,也是右偏分布。因此,q-指数分布可以被考虑用于对寿命相关的可靠性分析。
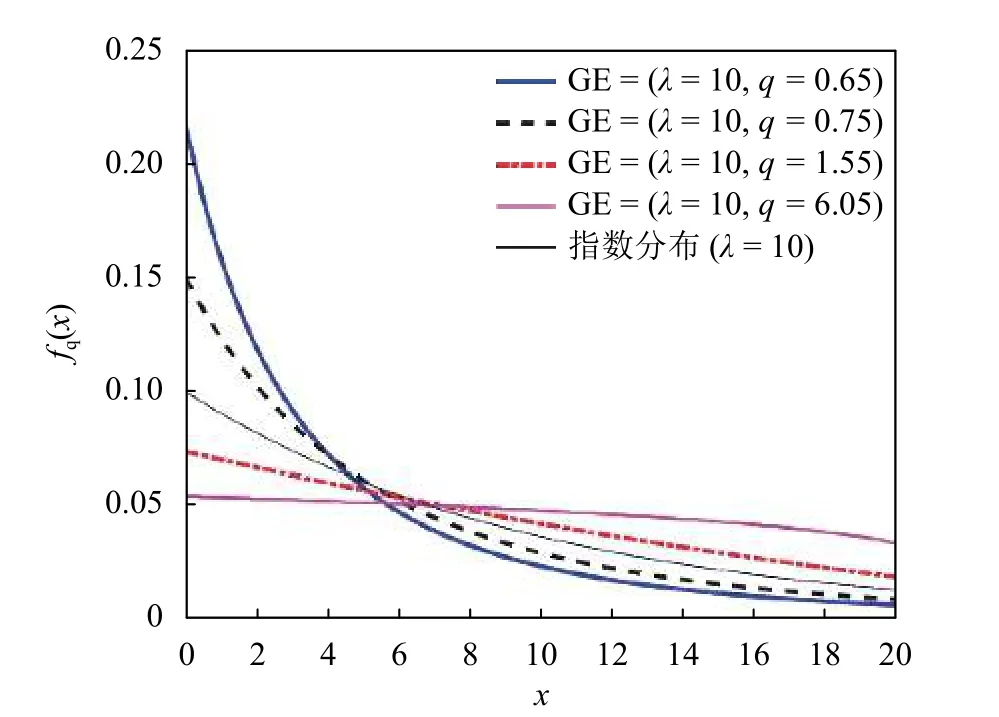
图1 q-指数分布fq(x)
计算可得,q-指数分布的累积分布函数是:
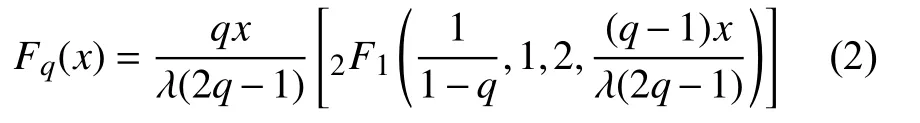
式中,2F1是高斯超几何函数。
1.2 特殊衍生分布
下面将给出q-指数分布的两个主要的衍生分布,它们在生存分析、压缩感知、剩余使用寿命预测和其他的可靠性相关领域有潜在实用价值。
首先,当q→1时,该分布简化为均值为λ的指数分布:

其次,使用式(1)可以得到一个广义的q-拉普拉斯分布:
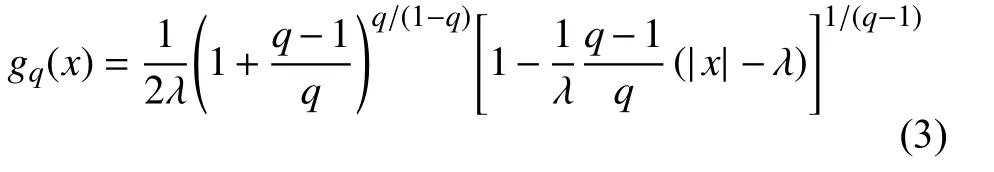
图2显示了不同参数值q和固定λ值(λ=10)的广义拉普拉斯分布。拉普拉斯分布在压缩感知领域起到了重要作用[11-13],这里衍生出的拉普拉斯分布在统计信号处理和机器学习领域具有潜在应用价值。
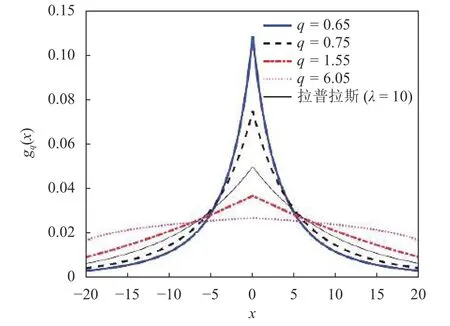
图2 不同参数q下的q-拉普拉斯分布gq(x)
2 模型性质
2.1 q-指数分布的风险函数
生存函数是表示一系列事件的随机变量函数,通常用于表示一些基于时间的系统失败或死亡概率。假设T表示产品使用寿命,其分布函数为F(t),那么该产品寿命大于t的概率为:
S(t)=P(T>t)=1-F(t)
式中,S(t)被称为生存函数。在此基础上,可用风险函数刻画已有效使用到t时刻的产品,在[t,t+Δt]极短时间内“死亡”的风险:
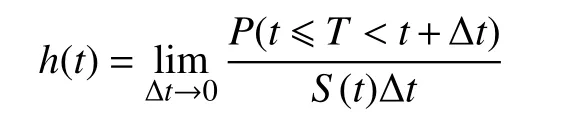
据此计算可得q-指数分布的生存函数:
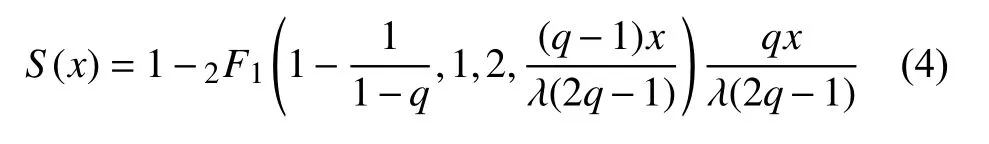
风险函数:
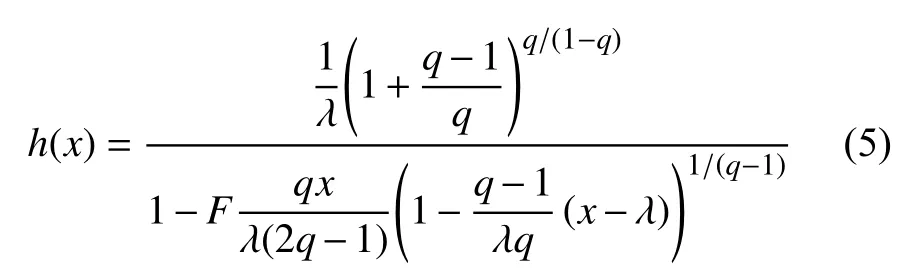
图3为具有不同参数值的风险函数图像,可以看到风险函数具有许多不同的形状,q-指数分布中当q>1,显示递增特性;当q<1,显示递减性。
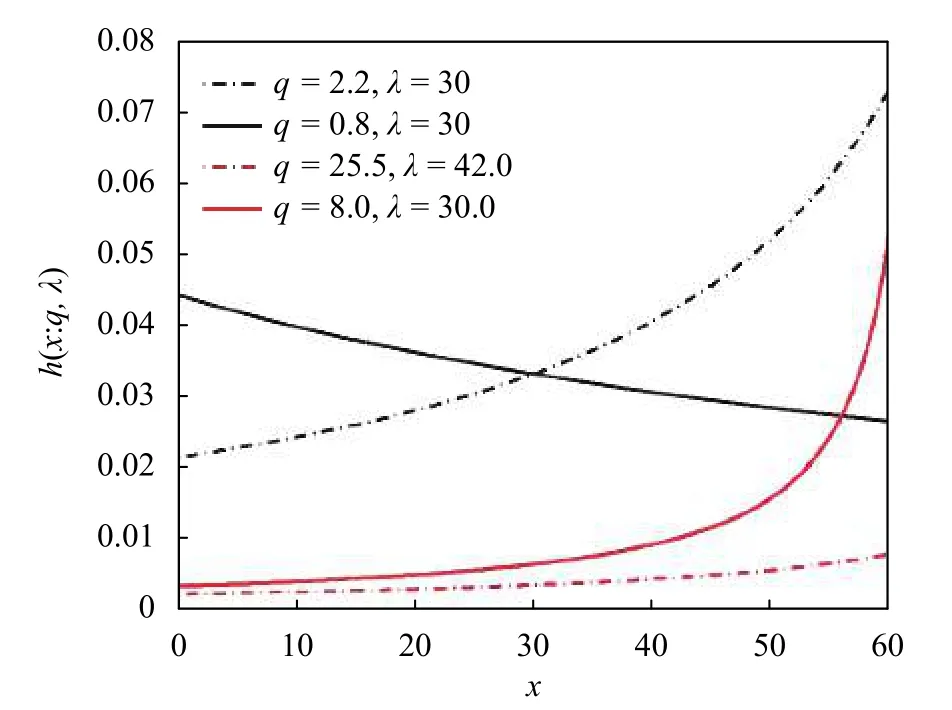
图3 q-指数分布的风险函数
注意到q-指数分布的风险函数呈现多态性,其中部分具有澡盆特征。可根据实际使用环境,选择恰当的q-指数建模风险过程,从而可以提高寿命估计精度。
2.2 q-指数分布的矩
q-指数分布fq的均值是λ,方差是:
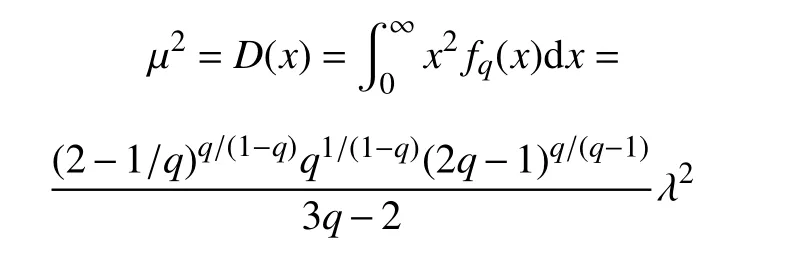
可以得到分布的k阶矩为:
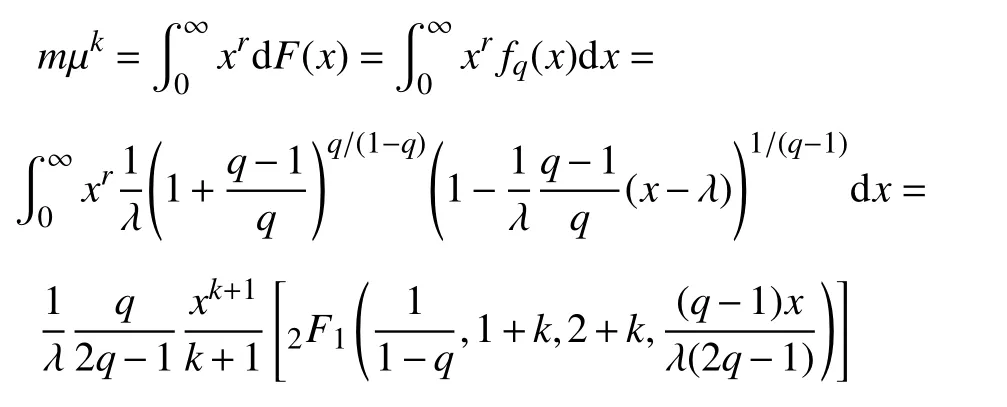
式中,k表示分布的k阶矩。
3 参数估计
为了在不同场景下选择恰当的参数,这里给出两种估计q-指数分布中参数的方法:最大似然估计法(maximum likelihood estimation,MLE)和信息似然估计法。最大似然估计法适用于满足高斯分布的数据集,信息似然估计法适用于高斯和非高斯分布的数据集。
3.1 最大似然估计
根据式(1),建立对数似然函数:
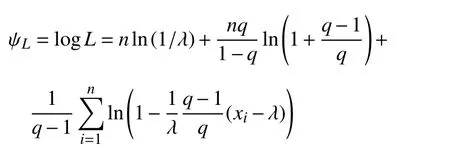
然后有:
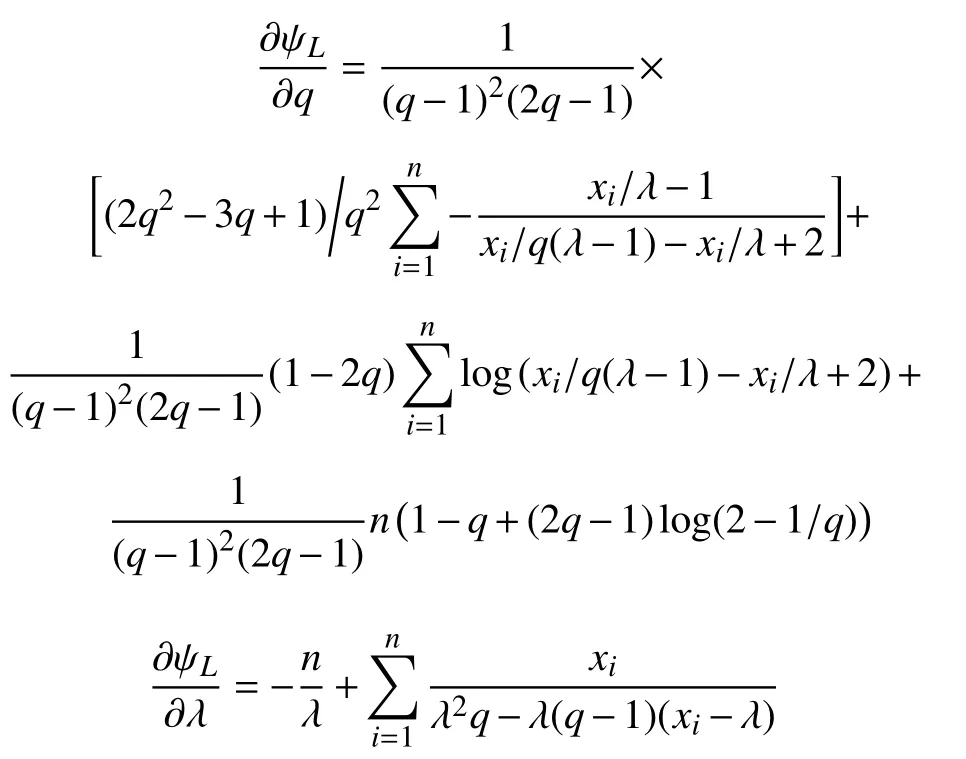
q和λ可以通过求解方程组(6)获得:
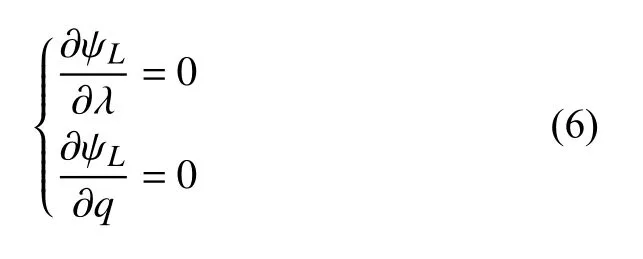
3.2 信息似然估计
另一个估计Rényi信息未知参数的方法,将信息论和谱估计相结合,可在最小先验的条件下,取得经验风险最小的参数估计值[14]。具体步骤如下:
首先,已知Rényi信息频谱定义为:
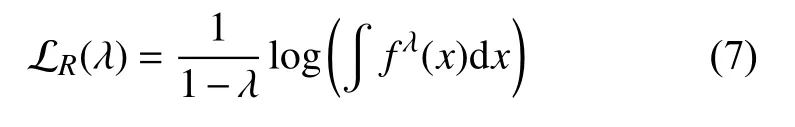
当λ →1,
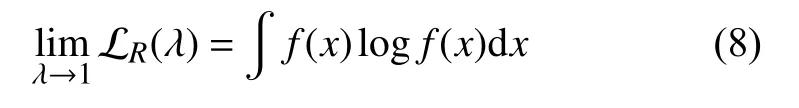
Rényi信息频谱趋向于香农熵。
同时,Rényi信息的频谱梯度被定义为:

式中,D(·)是随机变量x的方差。
令φf:=-2LR(1)
一方面,将式(1)中的fq代 入式(9)计算φf,根据文献[13]可得:
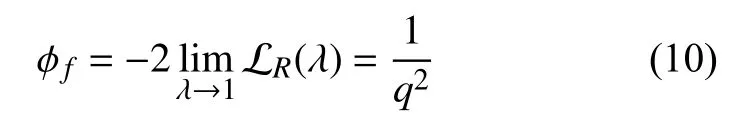
另一方面,使用核方法估计 φf。具体而言,φf可以通过核方法计算如下:

式中,
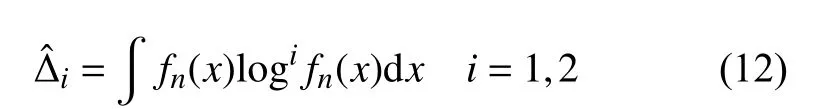
fn(x)是为无参数内核密度估计量,定义为:
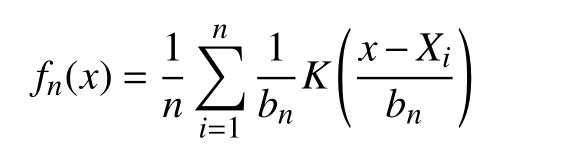
假设K(·)为有界变分的概率密度函数(核函数),其支撑集位于部分有限区间。Xi是随机变量X的样本。设bn为满足以下收敛条件的序列:
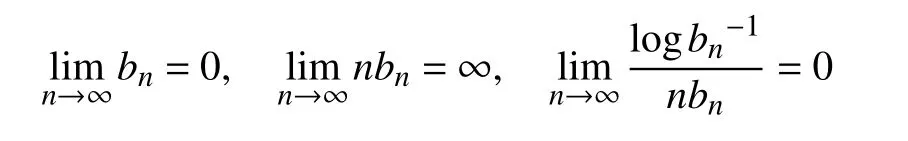
比较式(10)和式(11),式(1)中的参数q可以通过求解式(13)得到:

4 数据分析
本文使用了3个与可靠性相关的实验去评估q-指数分布在可靠性分析中的有效性,包括白血病病人生存期分析、设备寿命预测以及锂电池寿命预测。
第一个数据集是40个白血病病人的生存期数据[15],它具有不断增加的风险率。第二个数据集来自50个组件的样本[16],具有浴盆型风险的风险率。利用K-S统计量评估了q-指数与上述两个著名数据集的拟合结果,并计算出赤池信息准则(AIC)值和贝叶斯信息准则(BIC)值,用于比较它和其他广义指数分布的拟合优越度。第三个实验建立了关于3组锂电池的容量退化模型,与普通指数分布的结果相比,利用q-指数分布可以得到更准确的剩余寿命预测结果。
4.1 白血病病人生存期
该数据集由文献[15]给出,数据源自沙特阿拉伯卫生医院部门,如表1所示。它记录了40名白血病患者的生命周期。

表1 40名白血病患者的生存期
基于双参数模型的生存函数经验估计如图4所示,图5描述了模型的经验和拟合风险函数。同时,由于该数据集所示患者死亡风险是随时间上升的,因此,韦伯分布、线性失效率分布(linear failure rate distribution, LFR)和q-指数分布均可作为数据拟合的候选者。为了判断上述哪个密度函数更适合数据拟合,用MLE方法对3种模型参数进行了估计,如表2所示。然后利用几种不同的测试统计测度对拟合结果进行了评估。

表2 白血病数据集各模型参数的MLE值
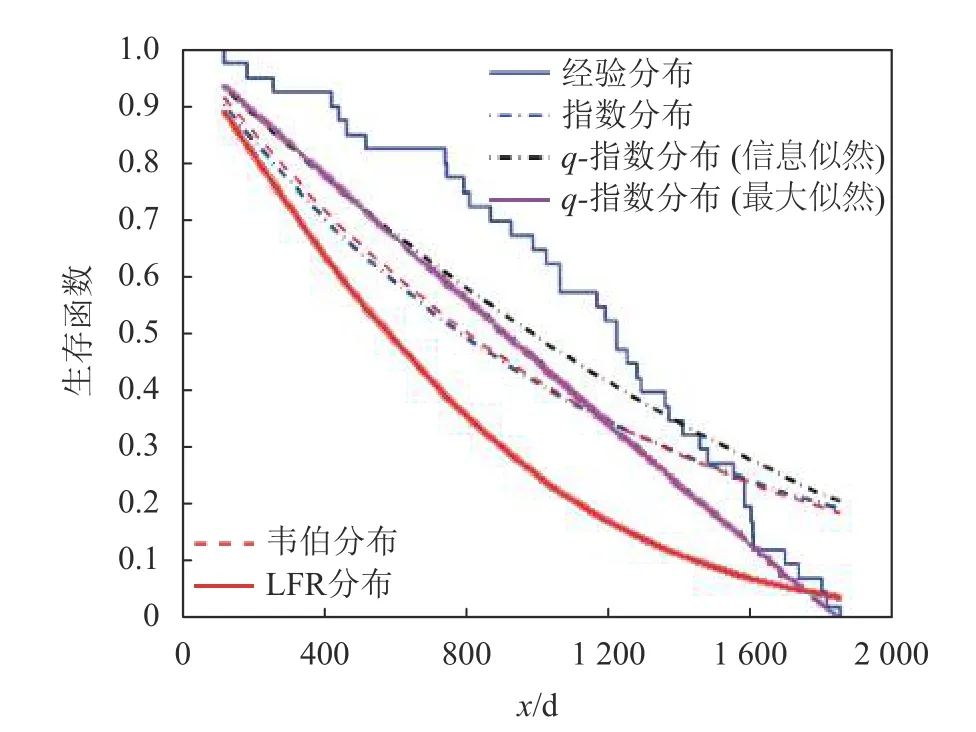
图4 白血病数据集的生存函数
由统计学可知,K-S值表示分隔程度,一般大于0.2即表明模型具有良好的分隔性能。由表3可知,q-指数分布与韦伯分布、指数分布和LFR分布的K-S均有良好分隔能力。同时,由表3列出的对数似然函数值可知,q-指数分布与韦伯分布、指数分布的最大似然函数值均在相近水平,所以q-指数分布可以充分利用先验信息获得对未知参数的最大似然估计。

表3 白血病数据的对数似然函数值和K-S
根据统计学原理,p值是判断原假设是否成立的依据,一般认为p>0.05,说明两组样本无统计学差异。由表4可知,q-指数分布与韦伯分布的p值在相近水平,q-指数分布具备描述寿命分布的能力。同时,通过计算AIC或者BIC值,相比指数分布、韦伯分布和LFR分布,不难发现q-指数分布具有更小的AIC或BIC值,因此q-指数分布具有更好的寿命数据拟合性。
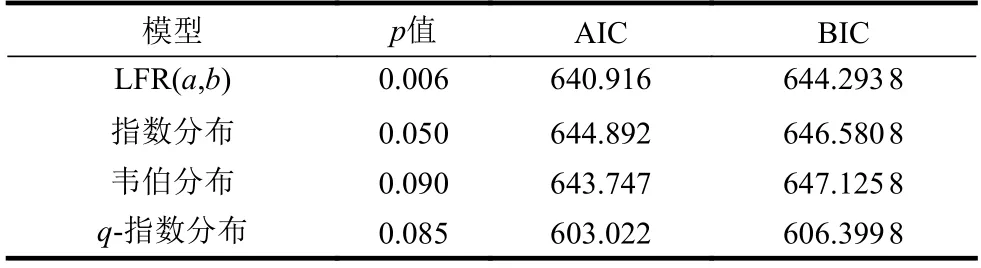
表4 白血病数据集各模型的p值、AIC和BIC
4.2 元件寿命数据
如表5所示,这是由文献[17]提供的50台设备的寿命数据,已有研究人员利用韦伯分布[18-21]、指数分布[5]、LFR分布[22]分析了这个数据集。表6给出了所使用的每个分布参数的MLE估计值。图6和图7分别给出了设备数据集的经验参数生存函数以及风险函数。
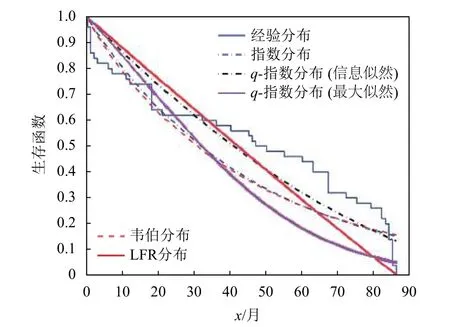
图6 Aarset数据集的生存函数
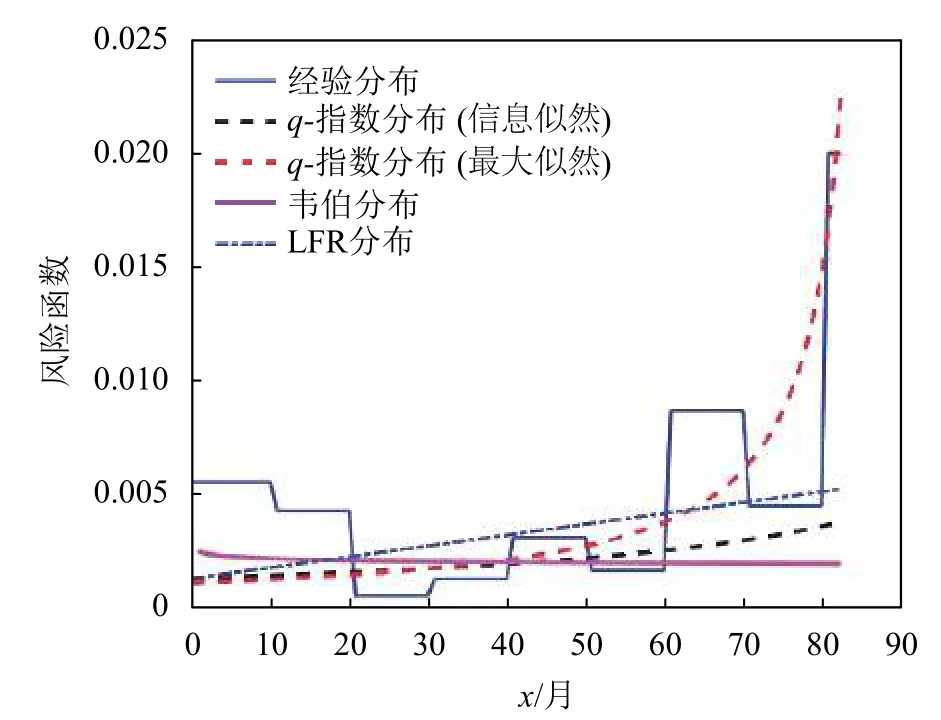
图7 Aarset数据集的风险函数
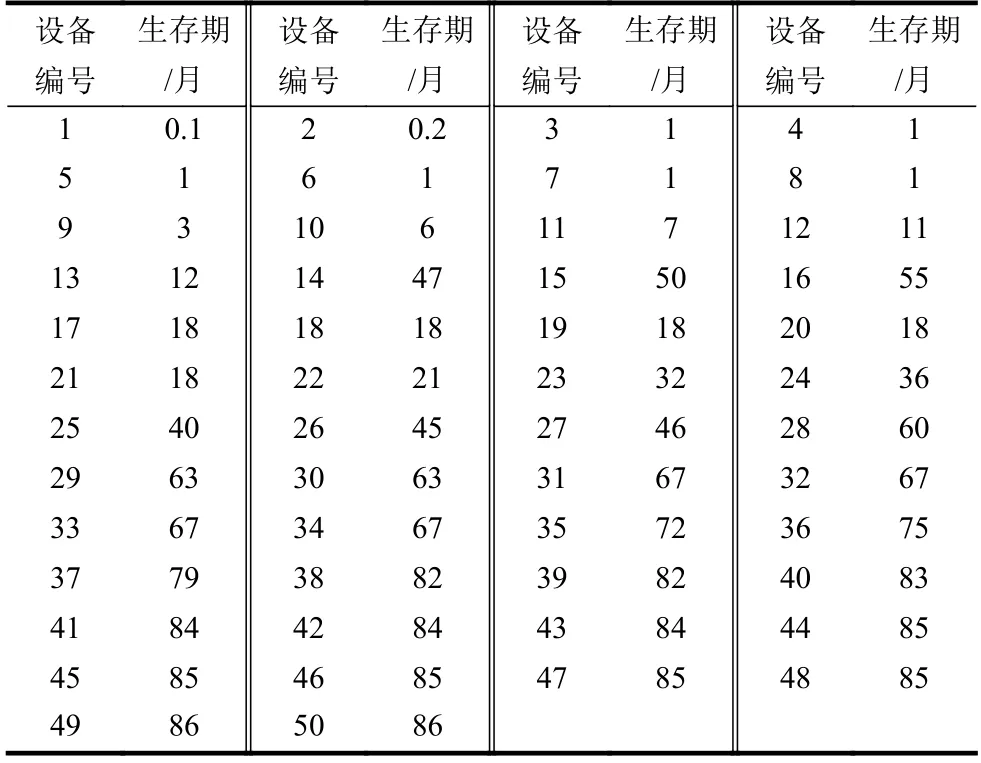
表5 50台设备的生存期

表6 设备时间数据集各模型参数的MLE值
已知Aarset数据集的风险函数具有浴盆形状。不失一般性和为了分析简便,本文只专注风险函数中单调递增部分,使用双参数分布来近似风险函数。为了进行参数比较,使用似然检验去对比原假设和备选假设。此外,利用AIC[23]在多个模型中选择最优模型。最适合数据拟合的模型应具有最低的AIC。表7和表8给出了对数似然函数值、KS值、p值、AIC和BIC值[24]。
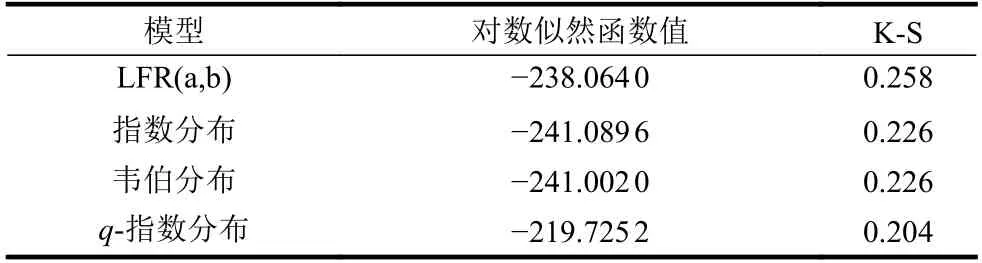
表7 设备时间数据集各模型的对数似然函数值和K-S值

表8 设备时间数据的P值,AIC和BIC
对于Aarset数据集,由表7可知q-指数分布的K-S值大于0.2,所以具备良好的分隔能力。由所列对数似然函数值可知,q-指数分布与韦伯分布、指数分布的对数似然函数值在相近水平,说明q-指数分布亦可以充分利用先验信息获得对未知参数的最大似然估计。
由表8知,q-指数分布的p值大于0.05,因而具备描述Aarset数据集的能力。同时,可以看出q-指数分布在本文所提到的所有分布中具有最小的AIC和最小的BIC值。这说明在所列分布中,q-指数分布能够最好地拟合本数据集。
4.3 锂电池寿命预测
估计剩余使用寿命(remaining useful life,RUL)有助于降低实际系统中发生灾难性事件的概率[25]。为了研究所提出的q-指数分布的有效性,本文采用美国宇航局(NASA) Prognostics公司(PCoE)的3个电池数据集来预测锂电池的剩余使用寿命。在该数据集中用电池容量来表征寿命,容量越低,剩余寿命越少。
3组电池(即蓄电池005、蓄电池006和蓄电池018)属于同一类型,通过在室温下工作在3种不同的状态下(充电、放电和阻抗)进行加速老化试验[26]。这种电池的额定容量是2 Ah,当电池容量减少到额定容量的70%(从2 Ah减少到1.4 Ah)时,电池就会达到使用寿命终止(EOL)标准,容量数据如图8所示。
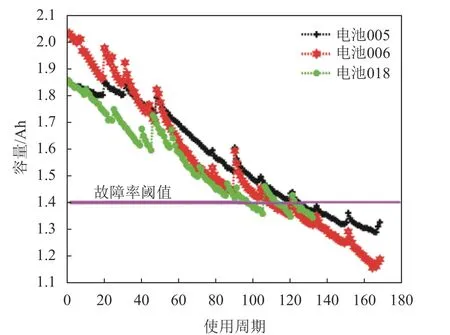
图8 NASA PCoE的电池容量数据
容量退化过程可用状态空间模型来描述:
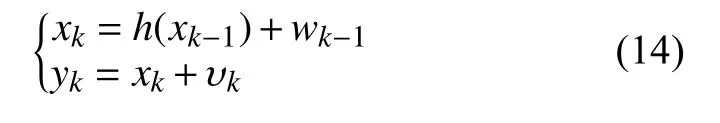
式中,xk表示k周期的真实容量值;yk表示k周期的预测值;wk-1表 示环境的扰动;υk表示观测噪声。
分别采用指数分布和q-指数分布作为h(xk)来描述容量状态转换,采用粒子滤波算法[27]自适应地确定预测容量值,并使用最大似然法确定指数分布和q-指数分布的相应参数。
由粒子滤波基本原理可知,按照频率派的概率观点[24],这里剩余寿命预测的概率分布可以通过对粒子滤波每个周期间隔内的粒子个数计数得到。间隔内粒子数越多,说明该区间代表大多数情况下的寿命长度。
在电池005实验中,共有168个循环样本,分别用前60个、80个和100个样本点训练粒子滤波器,设定粒子滤波预测的起始时间分别为T=60、80、100。当起始点T=100时,RUL的分布直方图和RUL预测结果如图9、图10和表9所示。其中,图9b使用参数q=1.001。
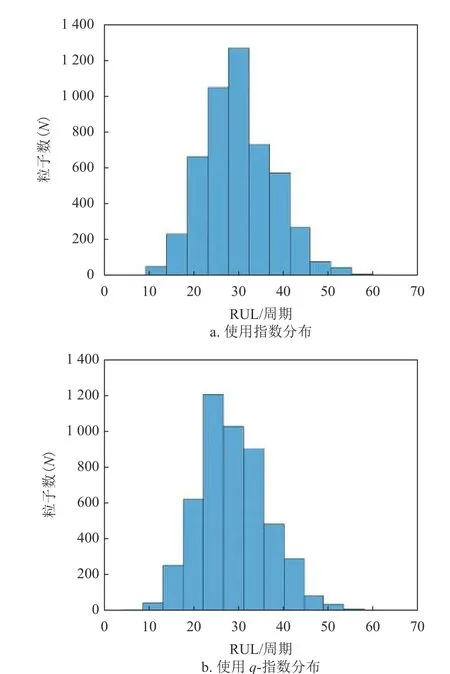
图9 电池005的RUL直方图
此外,为了定量评价预测精度,将预测误差定义如下:
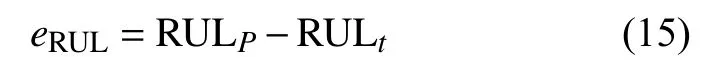
式中,RULP表示预测的周期数;RULt表示真实的周期数。
如图10(其中q=1.001)所示,电池005的真实寿命周期的结束数为124,使用q-指数分布相对能更好地拟合实际值。根据表9,在指数分布假设下,在起始预测点T=60时,粒子滤波算法预测的寿命周期数为152。根据上述定义,指数分布模型预测误差为:
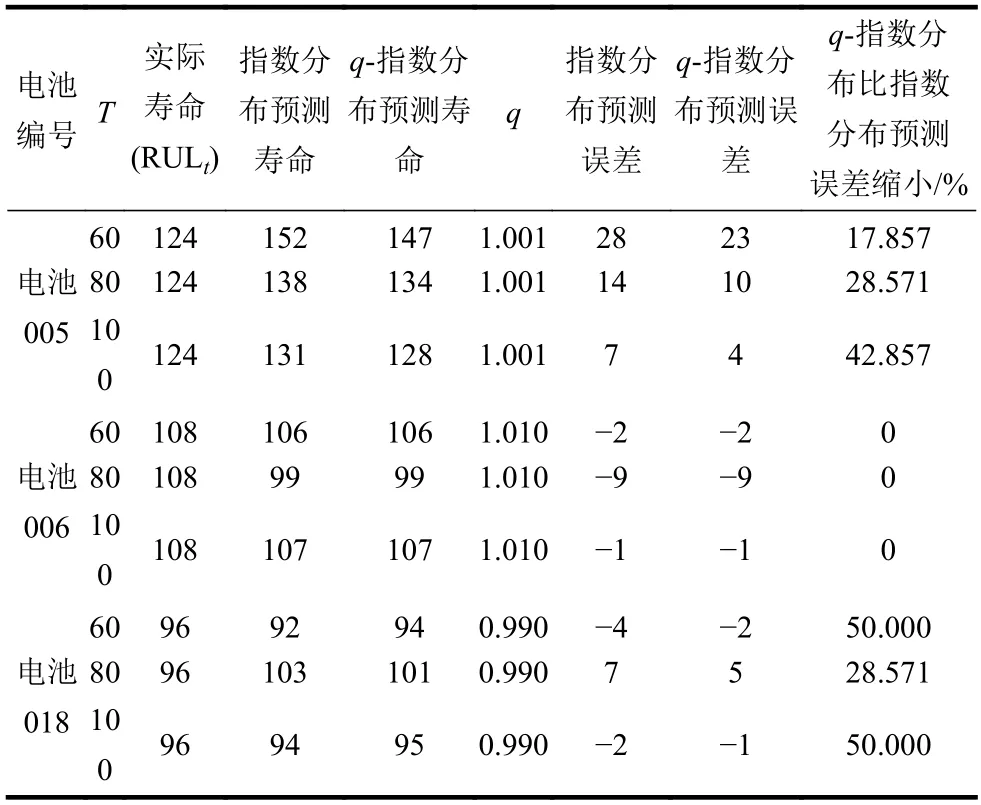
表9 不同起始点T下锂电池的RUL预测结果
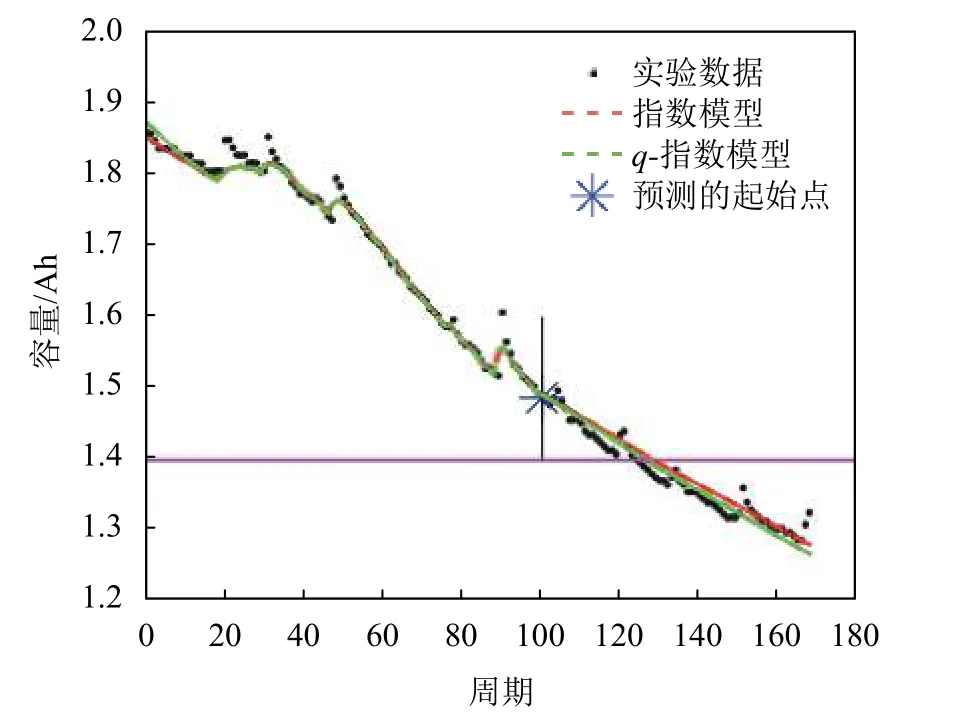
图10 电池005在起始点T为100的RUL预测结果
eRUL=RULp-RULt=152-124=28
同样以T=60为起始预测点,q-指数分布在q=1.001的情况下,预测误差为23,小于指数分布假设的结果。因此,提出的q-指数分布辅助粒子滤波算法对电池005的剩余使用寿命有更准确的估计。
同理,观察图11(其中q=1.010)与图12(其中q=0.990)中电池006和电池018的结果,结合表9,发现对于电池006而言,真实寿命周期的结束数为108,而在指数分布假设下,在起始预测点T=60、80、100时,使用q-指数分布获得预测结果均与指数分布的相同,说明基于q-指数分布的粒子滤波方法至少可以获得和指数分布假设下一样的估计精度。

图11 电池006在起始点T=100的RUL预测结果

图12 电池018在起始点T = 80处的RUL预测结果
对于电池018而言,真实寿命周期的结束数为96,在指数分布假设下,在起始预测点T=60时,预测的寿命周期数为92,预测误差为-4。而q-指数分布在q=0.990的情况下,如表9所示的同一点的预测误差为-2,误差预测减小了50%。对于T=80和T=100的起始预测点,使用q-指数分布均可取得更准确的效果。
5 结 束 语
本文基于最大熵方法,通过计算均值约束下最大Rényi熵,得到一种新的广义指数分布:q-指数分布。本文对q-指数分布的统计特性进行了分析,并给出了均值和各阶矩的解析公式。为了便于应用于可靠性分析,给出了基于q-指数分布可靠性的预测模型及对应的生存函数和风险函数的解析表达式。指出可采用了两种方法:极大似然估计法和信息似然估计法进行双参数估计。最后,结合医学白血病患者寿命数据集、设备元件寿命数据集及锂电池剩余寿命数据集进行了验证,通过与韦伯分布、指数分布等常用寿命预测分布对比,验证了q-指数分布的有效性和估计精度的优良性。下一步将挖掘q-指数分布在复杂系统建模中的高效应用。
猜你喜欢
青少年科技博览(中学版)(2022年6期)2022-08-31
中老年保健(2021年8期)2021-12-02
小哥白尼(神奇星球)(2021年12期)2021-03-08
作文评点报·低幼版(2020年3期)2020-02-12
华人时刊(2018年17期)2018-12-07
奥秘(2017年12期)2017-07-04
大学数学(2016年5期)2016-12-19
安庆师范大学学报(自然科学版)(2016年3期)2016-11-01
高师理科学刊(2016年1期)2016-10-13
太空探索(2014年4期)2014-07-19
