
基于泰勒公式的网络结构超分辨率算法
2021-08-07 14:22胡声辉杨晓敏
现代计算机 2021年17期
胡声辉,杨晓敏
(四川大学电子信息学院,成都 610065)
0 引言
图像超分辨率的目标是从低分辨率图像中获取信息来重建高分辨率图像。图像超分辨率广泛的应用于多个领域,如:医学图像处理、人脸识别、高清图像生成等。实际上,图像超分辨率是一个不适定问题,这意味着他存在着不止一种方法来重建高分辨率图像。大体的有三种方式,基于重建的方法,基于重建的方法和基于学习的方法。
近年来,深度学习发展迅速,基于此方法的图像超分辨率也得到了很好的效果。董超等人[1]参考了稀疏表示和字典学习的方式,第一次提出了一个三层的端到端卷积神经网络结构来处理图像超分辨率任务,这种方式比传统方法操作更简便,图像处理效果更好。自此,图像超分辨率努力地方向被吸引到了提高卷积神经网络的性能。之前工作把大部分精力放在了通过引入更多的参数并加深网络的深度来提高图像的精度中,缺忽略了网络模型所占用的计算资源。网络计算量和存储量的增加导致了训练难度的剧增,并且如此规模网络的网络很难应用到实际的应用场景中。其次,之前的研究都将网络的每一层来处理由上一层传递过来的所有的图像结构和特征的信息流,都没有区分不同的频率信息。而实质上,不同频率的图像信息有对应的纹理和结构,应该得到不同的处理。泰勒展开公式指出可以用函数在某一点的各阶导数值做系数构建一个多项式来近似表达这个函数,这与图像频带的分布及处理非常相似。因为图像也可以用数个主要的频带来近似的表示,并且处理图像只需处理这几个频带的图像信息。在这篇文章中,我们引入了泰勒展开公式的结构来构建我们的网络模型。而基于泰勒公式的网络模型由数个处理对应频带信息的模块组成,以此来逐渐恢复分层次的图像信息流。
图像信息流在经过不同模块的处理后精度虽然会提高,但信息会有所损失,所以必须得由之前模块的信息作为补充来修正信息流。密集连接可以解决这一困扰并且得到很好的效果图像,模型泛化能力和表征性能都得到明显提高。
1 算法实现
1.1 算法描述
在本节中,我们在频域中处理图像的方法与泰勒公式之间建立了联系,并将此概念应用于卷积神经网络结构设计中。
通常来说,一幅图像可以由不同频率的特征信息所组成的。换句话说,一幅自然图像可以被分解成一系列不同频带的图像信息。实际工作中也是类似的处理,将图片信息分成多频带信息,然后用不同的方式分别处理对应的频带信息。在图像融合领域中的研究[2]和超分辨率领域中的研究[3]表明,分别处理分解后的频带信息流可以得到很好的效果。这种处理模式与泰勒展开公式中,将原函数微分并分解至各阶导数的加权和的形式非常类似,我们可以从这种结构中获得设计网络的灵感。泰勒公式具体如下表示:
事实上,我们不可能照顾到所有频带的信息流,在大多数情况下,研究或者工程都仅处理主要的频带信息而忽略那些对结果影响不大的超高频信息。同样泰勒展开公式也可以应用于获得实际情况的近似值,如下列公式描述的那样,可以逐渐增加阶次N以逼近函数的真实值。
泰勒展开公式传递出了一个理念函数值可以由分解出来的各阶导数的加权和来表示。而在实际处理中,我们仅取前面几阶导数的加权来获得近似值P(x)。而o((x-x0)n)可以表示为函数的误差,这个误差的大小取决于所取的阶数N的大小来决定,随着N的增大,误差必然会随之减小。显然,在泰勒展开公式和图像频域处理之间存在着的联系。每一阶导数对应着一个频带信息,而近似值P(x)与处理之后的图像对应。如果我们将超分辨率卷积神经网络看成一个函数,那么我们就可以应用上述公式的理念来构建卷积神经网络模型。一般来说,我们可以通过将第一次处理的图像与原图像相减的方式获得补充的高频图像信息,之后将得到的高频信息图像当作基础图像,并再次处理它。之后重复数次之前的操作并得到更高频率的图像信息。最后将原图像与得到的各个高频率图像相加当作输出图像。反向投影第一次用在图像超分辨率领域是在DBPN[4]一文中,实际上这种方式是通过图像上采样与下采样获得残差信息,并将此加以利用。而EBRN[3]利用反向投影所产生的残差信息当作高频信息,并逐渐产生更高频的图像分量。但这种方式在高分辨率空间处理信息,增加了更多的参数量和计算量。实际上,在低分辨率图像中滤波器已经具备很强的泛化能力了,因此我们构建基于泰勒公式的网络模块(TF-Inspired Block,TIB)仅在低分辨率空间处理信息流就可以模拟图像的频域处理操作。这个模块的组成参见图1,模块的功能由函数fTIB,n表示。TIB的函数表达式如下:
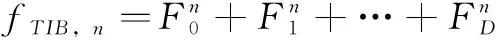
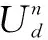
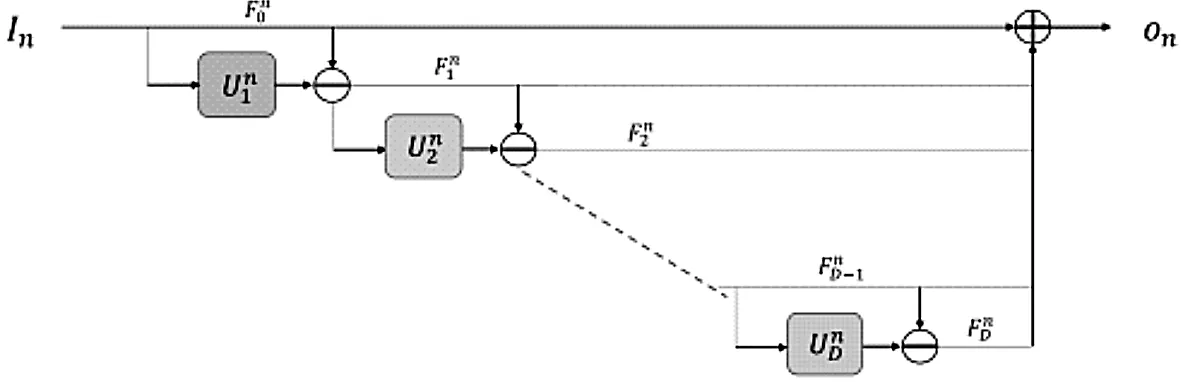
图1 TIB模块结构示意图
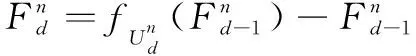
1.2 基于泰勒公式的网络结构的整体框架
模块TIB在基于泰勒公式的网络结构起着补充高频信息的关键性作用。我们假设训练整个网络以达到能使图像从低分辨率图像映射到高分辨率图像的能力。为了达到这一目标,整个网络需要多个模块去逐渐处理信息流来提升整个网络的性能。这些模块一般是以串联的方式连接,但这种连接方式会导致信息流逐渐损失并加大了训练难度。串联模式下,模块之间可采用跳跃连接的方式将之前准确的信息流传递直接传递到后面的模块帮助修正信息流。特别来说,密集连接也就是多个跳跃连接将所有模块用的滤波器连接的方式,提取并融合特征和结构信息,这极大提高了信息的利用率。在本文中,我们提出的基于泰勒公式的模块密集连接,这种模块群可以使我们的网络性能有最优的表现。
从图2中可见,整个网络由三个部分组成:特征提取模块(Feature Extraction Block,FEB),处理功能模块:基于泰勒公式的网络模块群(TF-Inspired Dense Blocks,TIDB),上采样重建模块(Reconstruction Block,RB)。首先图像信息流分为两路,其中一路直接进行原始图像上采样,另外一路经过学习得到低分辨率图像到高分辨率图像所缺少的残差信息,称为残差图像。整个网络模块中我们都使用PreLU作为激活函数,Conv(s,m)表示一个卷积滤波器,Deconv(s,m)表示反卷积滤波器,其中表示卷积滤波器的尺寸,表示卷积层数。ILR、OSR分别表示处理功能模块TIDB的输入和输出,In、On则表示第n个TIB模块的输入和输出。FEB模块提取的原始低分辨率图像ILR中的特征结构信息,输出为O0。RB模块由一个反卷积滤波器Deconv(k,m)和一个Conv(3,m)组成,并且每个滤波器后都有一个激活函数保证非线性映射能力。Deconv(k,m)中的k根据所需要的上采样的倍数因子决定。倍数因子为2到4倍时,k的取值相应为6到8。最后将原始图像上采样对应倍数后的图像与学习的得到的残差图像相加就得到了所需的超分辨率图像。
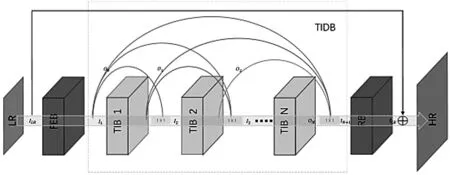
图2 网络整体框架
2 实验结果
本文参考文献[5],使用含有800张训练样本图的DIV2K数据集作为我们的训练数据集,采用双三次插值的方法将原高分辨率图像下采样至低分辨率图像,并且都使用与文献[6]一致的方式增广所有的图像。本文分别在5个标准数据集:Set5、Set14、B100、Urban100、Manga109等上采用峰值信噪比(Peak Signal-To-Noise Ratio,PSNR),结构相似性指数(Structural Similarity Index,SSIM)两个客观指标在RGB通道上来验证我们的超分辨率结果。
本次实验中将模块的参数设置为N=4,D=3,同时模块之间采用密集连接进一步提升模型的性能,通过数种客观指标及可视化的评估以证明所提出算法模型的优秀性能。本实验中我们对比了近些年来4种典型的基于卷积神经网络的图像超分辨轻网络模型算法,这4种算法是:DRRN、MemNet、CARN,OISR-RK2-s。本文提出的基于泰勒公式的网络结构超分辨率算法(TIDN)在本实验中与上述4种算法分别在2、3、4倍图像放大系数基础上对比网络的性能以及所需的参数量和计算量的大小。实验将从客观指标和视觉感知两方面进行对比。
表1是各个算法在5种验证集下的客观指标所取得的值。其中PSNR和SSIM的数值越大表示图像效果越好,算法越优越。在相同的图像表现前提下,算法所占用的参数量和计算量越小越好。从表1可以看出,文中所提的基于泰勒展式的网络结构超分辨率算法确实能有效地对低分辨率图像信息进行更好地提取和补充高分辨率信息。
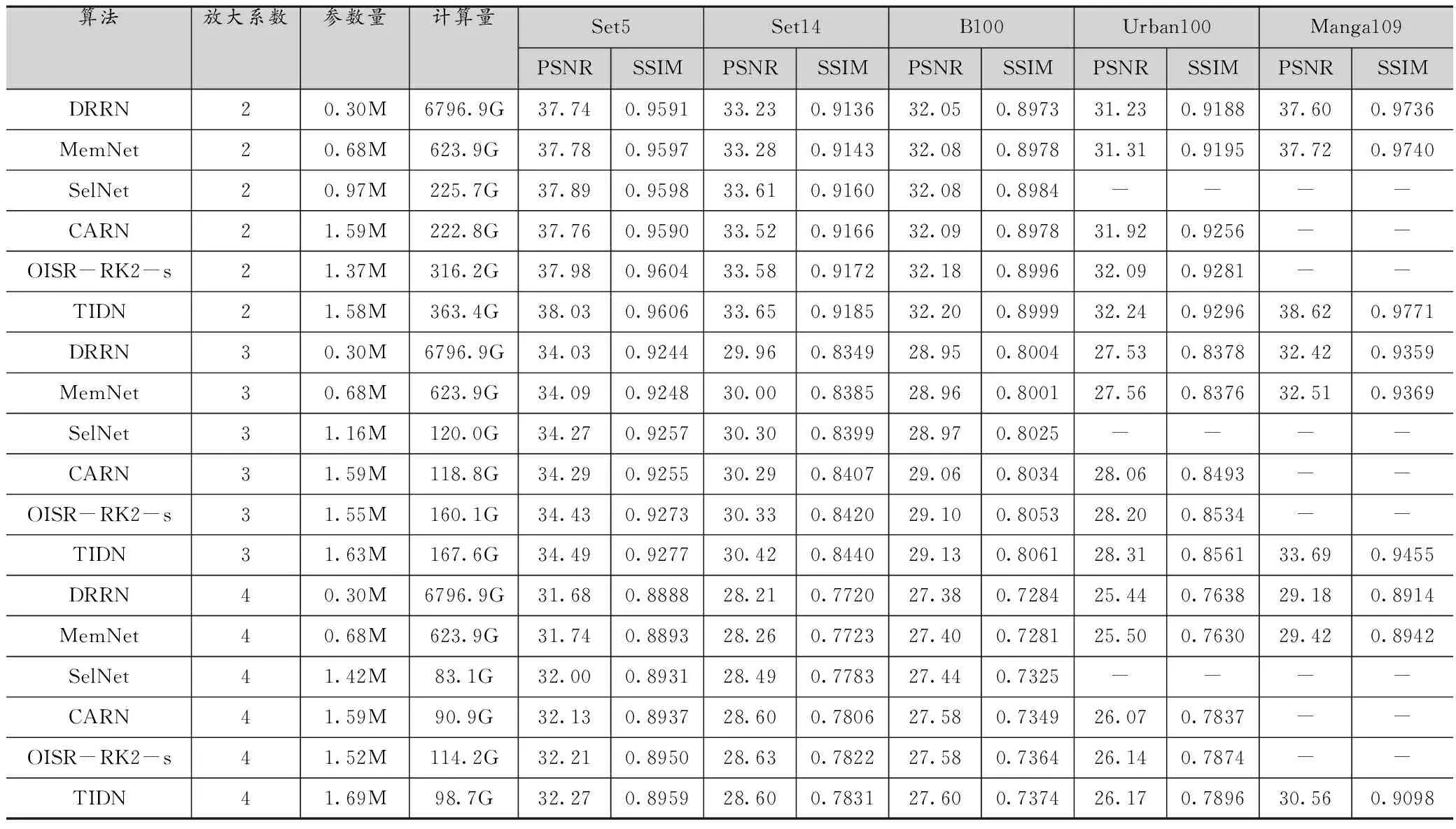
表1 客观指标对比结果
从图3中可以看出我们的算法得出的超分辨率图像在结构性的纹理修复细节上比其他4种算法能力更强,恢复出的图像细节的结构更接近原始图像。这表明了我们提出的网络算法的优越性。

图3 对比实验4倍放大的细节表现
4 结语
本文基于泰勒公式提出了超分辨率网络模型,这种模型具有强大的性能,能渐进地处理图像的细节。我们的网络结构仍有改进的空间,在保证网络泛化性能前提下,继续降低参数使用量以确保模型的优越性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
数理报(学习实践)(2021年5期)2021-04-07
——以微信朋友圈为例
记者观察(2021年32期)2021-02-11
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
商场现代化(2016年26期)2016-11-21
商(2016年16期)2016-06-12
发明与创新·中学生(2016年8期)2016-05-14
科教导刊(2016年9期)2016-04-21
