
面向网络文本的BERT 心理特质预测研究
2021-08-07 07:42贾甜远
计算机与生活 2021年8期
张 晗,贾甜远,骆 方,张 生,邬 霞,4+
1.北京师范大学 人工智能学院,北京 100875
2.北京师范大学 心理学部,北京 100875
3.北京师范大学 中国基础教育质量监测协同创新中心,北京 100875
4.智能技术与教育应用教育部工程研究中心,北京 100875
随着信息时代的飞速发展,利用网络平台进行学习、工作、娱乐、社交等活动已经成为人们日常生活中必不可少的一部分,极大地丰富了人们表达自我、记录思想和交流沟通的方式。在互联网中的海量数据中,非结构化文本与信息数据占据了很大一部分,用户的文本信息往往是其在自然状态而非测试状态下的真实表达。研究表明,个体所使用的语言文本往往在一定程度上反映着其心理状态或某些特质倾向[1-2],例如羞怯特质(shyness)、合作性特质(cooperativeness)、完美主义特质(perfectionism)、焦虑特质(anxiety)等。这些心理特质的差异会对一系列的个人行为(如个人决策、职业能力等)产生多重影响[3-4],通过对心理特质进行分析评价和持续监测能够帮助深入了解心理状态和人格特质,在发展过程中发现行为变化中所存在的问题和原因并及时加以解决。因此,对网络文本数据进行分析,可以为预测心理特质提供非常有用的参考价值,弥补传统的心理测量方法易受应试动机等因素影响的缺陷。
近年来,深度学习[5]相关技术在计算机视觉、模式识别、自然语言处理等领域得到了广泛应用[6-8],因其在很大程度上避免了传统文本分类方法中存在的诸多问题,所以也越来越多地应用于文本挖掘。具体来说,深度学习能够将文本数据转换为适合神经网络处理的格式来有效进行文本表示,并通过特定的神经网络结构自动获取关键特征进而避免了人工特征工程的复杂过程,从而在大规模文本分类及情感分析领域中表现出了很好的性能,进一步提高了模型分类的精度[9-10]。尤其是2018 年出现的深度神经网络语言模型BERT(bidirectional encoder representations from transformers)[11],它采用多头注意力机制[12],不仅能够准确提取字符级别和词级别的信息,而且可以充分捕捉句内关系和句间关系,具有很强的模型泛化能力和鲁棒性,在包括文本分类在内的多种自然语言处理任务中都表现出优异的模型性能[12-15]。
本文针对网络文本数据,提出了基于BERT 的心理特质预测模型,主要贡献如下:
(1)将BERT 语言框架应用于心理特质预测,利用BERT 双向训练的模式及Transformer 的编码模块挖掘更加完整的上下文语义特征和更长距离的上下文依赖关系,解决了心理特质语义特征的增强向量表示的问题。
(2)在下游分类任务中分别采用BERTBASE模型的全连接层和基于集成学习原理的随机森林算法作为两种分类器,避免分类器多样性较差而造成的分类准确率受限、模型性能欠佳等问题。
1 相关工作
在针对大五人格特质预测的研究中,以往采用的文本挖掘方法大多依赖于传统的机器学习算法。例如,Kwantes 等[16]在2016 年利用潜在语义分析的算法对被试所写的关于在特定场景中自我感受的文章进行内容处理,并结合被试的量表信息,实现了包括开放性、外倾性、神经质性/情绪稳定性在内的三种人格特质预测。近年来,基于深度学习的神经网络结构在文本挖掘领域的应用使得心理特质与人格预测研究有了进一步突破,主要采用的网络结构包括经典的卷积神经网络(convolutional neural networks,CNN)、循环神经网络(recurrent neural network,RNN)及其对应的网络结构变种。例如,Wei 等[17]在2017 年提出了一个用于预测微博用户个性特征的异构信息集成框架,通过收集用户的语言文本数据、头像、表情和互动模式等异构信息,采用CNN 的改进结构Text-CNN、Responsive-CNN 以及词袋聚类等多种不同的策略来进行语义表示和特征提取,不仅很好地实现了开放性、尽责性、外倾性、宜人性以及神经质性这五种人格的预测,而且表现出了优于其他传统模型的性能。Majumder等[18]提出了一种基于CNN 从文章中提取大五人格特征的模型,将文章中的句子输入到卷积滤波器中得到N-Gram 特征向量形式的句子模型,在大五人格预测实验中也表现出了良好的模型性能。
由此可见,深度学习的神经网络算法在基于文本挖掘的情感分析及心理特质预测研究中具有明显的可行性及有效性。但需要指出的是,上述研究所建立的情感分析及心理特质预测模型,大多是基于经典的神经网络算法,这些网络结构本身的限制在很大程度上会使模型性能受限。而深度学习领域的更新迭代速度之快使得许多广泛应用于文本分类的神经网络算法出现了更加完善的改进结构及变种形式,尤其是近几年提出的注意力机制以及BERT 语言模型,在包括句子级和词条级在内的11 项自然语言处理任务中都表现出了超越其他技术的效果[11,19],对文本分类任务的提升效果也极为显著。但是这些最新的网络结构及算法改进往往仅在自然语言处理领域得到了较大范围的应用,并未引入心理特质预测研究中。因此,本文基于注意力机制的原理,利用BERT 算法并对其下游结构进行微调,构建基于BERT 的文本分类模型,用于实现羞怯、合作性、完美主义、焦虑这四种心理特质的预测。
2 基于BERT 的心理特质预测模型设计
2.1 BERT 算法基本原理
BERT 可译为“来自变换器的双向编码器表示”,由Google 在2018 年年底提出,本质上是一种基于Transformer 架构且能够进行双向深度编码的神经网络语言模型[11-12]。在BERT 内部组成结构中,最为关键的部分是Transformer 的解码模块。Transformer 由编码器(Encoder)和解码器(Decoder)两部分组成,Encoder 用于对输入的文本数据进行编码表示,Decoder 用于生成与输入端相对应的预测序列;由于BERT 作为语言表示模型使用,仅采用了Transformer的Encoder 而未使用Decoder。BERT 之所以能在文本分类、阅读理解、语言翻译等各类自然语言处理任务中都表现出极强的模型泛化能力和提升效果,关键在于其利用自注意力(self-attention)机制的原理,并引入掩蔽语言模型(masked language model,MLM)和下一句预测(next sentence prediction,NSP)两种策略对不同层的上下文联合处理来进行双向深度预训练,以此缓解单向性约束问题,这在以往常用的语言表示模型中是无法实现的。所谓MLM,简单来说,类似于完形填空的过程,指的是将句子中的词按照随机的形式进行遮蔽(Mask),然后依据上下文语义信息对其进行预测,被遮蔽的词在大多数情况下(80%)将被替换为[MASK]标签,在其他情况下分别替换为随机词(10%)或保留该词不做替换(10%),通过这种Mask 操作使得每个词的关注度得到提高;NSP 则是根据句子之间的依赖关系对下一个句子进行预测,在句首和句末分别插入[CLS]和[SEP]标签,通过学习句间语义相关性判断某个句子是否为输入句子的下一句,按照50%的概率进行匹配,适用于问答任务或推理任务的过程。
在BERT 框架的实现过程中,主要包括预训练和微调两部分。在预训练过程中,BERT 针对不同的任务对未标记的数据进行训练;在微调阶段,先利用预训练的参数对BERT 进行初始化之后,再结合下游具体任务的标记数据实现对所有参数的微调过程。正是由于BERT 的预训练与下游任务结构之间没有太大差别,BERT 具有跨不同任务之间的通用架构。
2.2 模型基本思想
本文基于BERT 模型,分别采用BERTBASE模型的全连接层和经典的随机森林(random forest,RF)算法作为分类器,构建了BERT-B 和BERT-RF 心理特质分类模型,将四种心理特质预测任务转化为基于BERT二元分类的多标签文本分类任务。模型的基本思想是利用BERT 本身所具有的MLM 对词预测以及NSP对两个句子是否有上下文关系进行分类的两种策略使模型能够在更大程度上根据上下文语义实现词的预测,提高纠错能力。且Transformer 的Encoder 捕获更长距离的上下文依赖关系,通过双向训练的模式使得模型对语义信息特征的获取更加全面和高效。此外,考虑到心理特质是一种较为复杂的内隐特征,不同的分类器构造可能会影响分类结果的精度,因此,在下游分类任务中分别采用BERTBASE模型的全连接层和经典的随机森林算法作为两种不同的分类器,丰富模型的多样性,并对模型结果进行对比分析,寻找预测精度更高的心理特质预测模型。由于四种心理特质所对应的标签之间不存在明显的相互依赖或排斥的关系,分别针对每一种心理特质训练一个相应的二分类模型。
基于BERT 的两种模型整体框架结构如图1 所示。在完成文本数据预处理后并将句子长度裁剪为512个字符以内后,首先进入嵌入层(embedding layer)将句子按字分割,把单个字符转化为词向量表示的形式;然后将嵌入操作后的结果送入Transformer 的Encoder 层,每 个Encoder 层 由Self-Attention 层 和Self-Output 层、Intermediate 层、Output 层组成,其中Self-Attention 由Query、Key、Value 三个全连接层组成;接着将最后一层Encoder 的第一个字符[CLS]的字向量经过池化层(Pooler),经由tanh 函数处理后得到整个句子的句向量表示;最后将携带强语义表示的句向量送入分类层,其中,BERT-B 模型和BERTRF 模型分别采用BERTBASE的全连接层和RF 算法两种方式作为四种心理特质类别的分类器,分别得到每个类别的分类结果,完成对四种心理特质的预测。
2.3 模型构建
基于BERT 的BERT-B 模型与BERT-RF 模型构建过程主要包括如下步骤:
(1)BERT 输入表示。由于本研究所采用的数据为中文文本,故将单个汉字直接作为细粒度的文本语义单位。每个字的输入表示由其对应的token embedding、segment embedding 和position embedding三个嵌入加和构成。其中,token 表示词/字,token embedding 即为词/字向量表示word embedding,根据字向量表的查询结果将一个token 表示为一维向量的形式;segment 表示部分/段,segment embedding 即为区分字/词的语义属于哪个句子的向量表示,判断一个token 属于左(EA)右(EB)两边的哪一个segment,此处输入的文本数据为句子而非句对,故只有EA 没有EB;position 表示位置,position embedding 即为位置向量表示,根据词/字在文本中所对应的特定位置和顺序,每个token 都被赋予一个携带了其自身位置信息的向量编码表示。最后将以上3 个embedding 相加即得到了BERT 的线性序列输入表示。图2 展示了BERT 输入的嵌入处理可视化表示形式,其中,句首加入的特殊字符[CLS]代表句子的开始,用于下游的文本分类任务;句末的[SEP]表示分割符,使得序列中被打包的句子分隔开来。

Fig.1 Framework of prediction models for psychological traits based on BERT图1 基于BERT 的心理特质预测模型框架结构

Fig.2 Embedding example of input图2 模型输入表示的嵌入处理示例
(2)Encoder 注意力计算。为了挖掘输入文本中句子内部的字词间语义相关性及依赖程度,增强文本序列编码的语义表示,采用Self-Attention 机制,将文本序列表示为由每个字的查询(Query)以及一系列的键值对
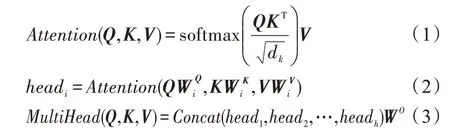
其中,W为线性变换的参数,每进行一次线性变换,W值也会随之变化。
(3)BERT 输出处理。将最后一层Transformer的Encoder 中第一个字符[CLS]的字向量经过池化操作和tanh 函数处理,即可得到融合了全文字词相关性及全面语义信息的整个句子向量输出表示,将其存储以实现下游的文本分类任务。
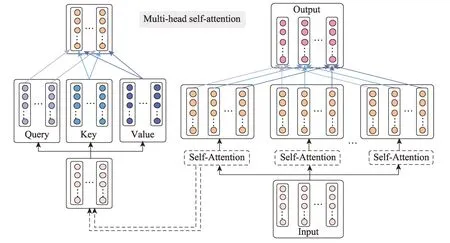
Fig.3 Framework of multi-head self-attention图3 多头自注意力机制框架
(4)分类预测。在分类任务中,考虑到不同分类器的选择可能会导致分类精度的差异,而且有研究针对179 种分类算法分析后发现基于集成学习的RF是分类效果最好的算法之一[20],因此分别采用经典的机器学习算法RF 作为一种强分类器,以及深度学习算法中普遍使用的全连接层作为另一种分类器,比较两者基于BERT 增强语义向量表示的分类结果。
3 实验与结果
3.1 样本数据描述
本研究的被试为教育资源共享与在线互动学习网站“教客网(https://jiaoke.runhemei.com/)”的2 660名小学生用户(男生1 380 名,女生1 280 名),年龄在5~14 岁之间(平均年龄为8.55 岁),来自全国不同省市的26 所学校。其中,702 名学生来自甘肃省酒泉市的7 所学校,1 844 名学生来自辽宁省大连市的18 所学校,108 名学生来自四川省成都市的1 所学校,6 名学生填写的地区及学校信息不详。被试人口学特征如表1 所示。

Table 1 Democratic characteristics of subjects表1 被试人口学特征
对以下小学生用户自2013 年6 月1 日至2018 年1 月18 日在教客网上发布的所有博客日志、评论回复等在线文本进行数据爬取和收集,共得到160 154 篇文本。针对文本数据,按照“正常”“无意”“短无”“短意”“重复”五类标准进行数据清理,各标准的内容范围如表2 所示。对“正常”“短意”两类标准下的文本予以保留;其他标准下的文本直接剔除。最后得到“正常”“短意”标准下的有效文本为88 659 篇,共计132 323(13 万)条完整语句数据。
针对羞怯、合作性、完美主义以及焦虑四种心理特质,基于北京师范大学心理学部相关专业研究人员确定的对应上述四种心理特质行为表现的常见词语,进一步筛选符合相应心理特质的关键词共386个,其中羞怯特质包含97 个关键词,合作性特质包含116 个关键词,完美主义特质包含71 个关键词,焦虑特质包含102 个关键词。将得到的关键词分别与13万条数据进行匹配,若句子中出现某种心理特质所对应的关键词,则该条句子的此类特质标记为正类1,否则为负类0。通过标签匹配,使得每条句子带有4 个标签,即代表四种心理特质。

Table 2 Criterions for data cleaning表2 数据清洗标准
3.2 实验设置
通过Pandas 对语料数据进行处理,将句子长度裁剪为512 个字符以内,并将句子按字分割后转化为词向量形式,完成词嵌入后进入12 个Encoder 层进行多头注意力计算,再将最后一层Encoder 的第一个字符[CLS]的向量(768 维)经过池化层操作,经由tanh函数处理得到整个句子的句向量表示,最后分别利用BERT-B 模型的全连接层和BERT-RF 模型的RF 分类器对携带强语义表示的句向量进行分类,得到每种心理特质的分类结果。由于针对四种心理特质分别训练了4 个分类器,本质为4 个二分类任务,故将softmax 函数直接改为sigmoid 函数。选取0.5 作为分类阈值,概率小于0.5 为负类(标为0),大于等于0.5为正类(标为1),分别得到每个标签的分类结果进行输出。基于BERT-B 和BERT-RF 的心理特质分类预测模型的主要参数设置如表3 所示。
此外,将其他经典的深度学习算法CNN、RNN 的变种双向长短期记忆(bidirectional long short-term memory,Bi-LSTM)网络与注意力机制(attention)结合后的模型CNN-Attention、Bi-LSTM-Attention 应用于本数据集进行验证,以进一步说明本模型的性能优势。
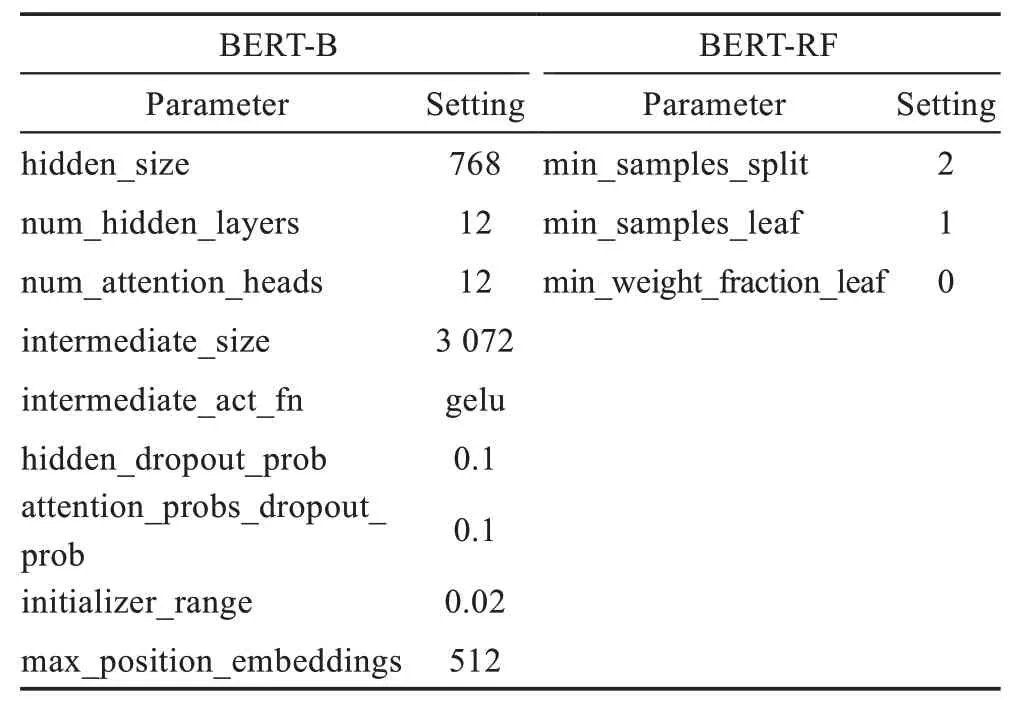
Table 3 Parameters setting based on BERT表3 基于BERT 模型的主要参数设置
3.3 模型评价指标
对于分类模型而言,以二分类为例,假设只有0和1 两类,最终的判别结果有四种情况:真正(true positive,TP),即被模型预测为正的正样本;假正(false positive,FP),即被模型预测为正的负样本;假负(false negative,FN),即被模型预测为负的正样本;真负(true negative,TN),即被模型预测为负的负样本。本研究在实验中结合预测结果和实际结果,得到TP、FP、FN 和TN 的数量,选择如下6 个指标对模型性能进行评价。
(1)准确率(Accuracy)。分类正确的样本占总样本个数的比例,其计算公式为:

(2)精准率(Precision)。模型预测为正的样本中实际也为正的样本占被预测为正的样本的比例,其计算公式为:

(3)召回率(Recall)。实际为正的样本中被预测为正的样本所占实际为正的样本的比例,其计算公式为:

(4)F1分数(F1score)。精确率和召回率的调和平均值,其计算公式为:

(5)ROC 曲 线(receiver operating characteristic curve)。通过计算出TPR 和FPR 两个值,分别以它们为横、纵坐标作图得到ROC 曲线。ROC 曲线在坐标系中的位置越接近于左上方,则说明分类模型的性能越好。
(6)AUC(area under curve)。ROC 曲线下的面积,取值范围为[0,1]。之所以使用AUC 值作为模型表现的评价指标之一,是因为有些情况下仅凭ROC曲线无法清楚判断不同分类模型的优劣。通过AUC值使得ROC 曲线的表现得以量化,AUC 值越大,代表与之对应的分类模型效果越好。
3.4 实验结果及分析
将13 万条文本数据划分为独立的三部分,其中,12 万条作为训练集,用于训练分类模型的参数;5 000条作为验证集,用于检验训练过程中模型的状态及收敛情况并调整超参数;5 000 条作为测试集,用于评价模型的泛化能力。选取准确率、精准率、召回率、F1分数、ROC 曲线和AUC 值6 个指标,分别对模型表现做出评价。
对于羞怯、合作性、完美主义、焦虑四种心理特质的分类预测表现,BERT-B 模型和BERT-RF 模型的准确率、精准率、召回率及F1值表现如表4 所示。从表4 中可以看出,BERT-RF 模型对于羞怯、合作性、完美主义、焦虑四种心理特质的分类预测都取得了较为理想的效果,每种心理特质所对应的准确率、精准率、召回率及F1值都在0.97~0.99 之间;其中对于羞怯特质的分类预测效果最为突出,4 个指标都高于0.98。对比发现,相对于BERT-RF 模型,BERT-B 模型对于四种心理特质的分类预测表现则更加显著,每种心理特质所对应的准确率、精准率、召回率以及F1值全部高于0.98,尤其是对于合作性特质和羞怯特质的预测所有指标都高达0.99 以上,模型表现非常优秀。
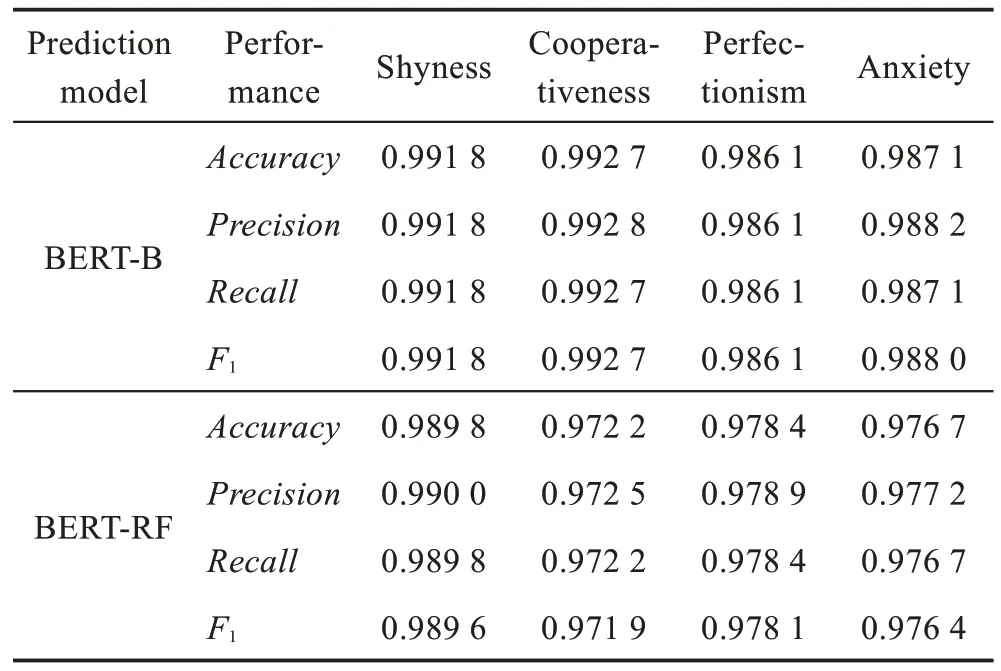
Table 4 Performance of predicting four psychological traits表4 四种心理特质分类预测的表现
将CNN-Attention 及Bi-LSTM-Attention 两种经典的深度学习模型应用于本数据集,与本文基于BERT 构建的两种模型在心理特质分类预测的平均表现进行对比,得到结果如图4 所示。对四种心理特质预测的平均准确率、平均精准率、平均召回率及平均F1值,Bi-LSTM-Attention 模型表现在0.71~0.79 之间,CNN-Attention 模型表现在0.80~0.96 之间;而BERT-B 和BERT-RF 模型的对应指标均在0.97~0.99之间,明显优于其他两种深度学习模型的整体预测效果。由此可见,相较于其他两种经典的深度学习模型,本文基于BERT 构建的心理特质分类模型的性能表现更胜一筹。

Fig.5 ROC and AUC of BERT-B and BERT-RF图5 BERT-B 模型与BERT-RF 模型ROC 曲线及AUC 值
为进一步对基于BERT 的BERT-B 和BERT-RF心理特质分类模型性能做出对比和评价,图5 按照从左到右、从上到下的顺序依次展示了BERT-B 模型和BERT-RF 模型在羞怯、合作性、完美主义、焦虑四种心理特质分类预测中所对应的ROC 曲线及其AUC值。如图5 所示,BERT-B 模型和BERT-RF 模型的ROC 曲线都位于坐标系的左上方,且AUC 值基本都在0.99 左右,说明两个模型的分类效果都不错。通过进一步比较后发现,相对于BERT-RF 模型来说,BERT-B 模型在羞怯、合作性、完美主义、焦虑分类预测中的ROC 曲线明显更靠近坐标系的左上角,而且其每种心理特质所对应的AUC 值也都更大;尤其是在羞怯特质中的表现,BERT-RF 模型的AUC 值为0.982 2,BERT-B 模型的AUC 值为0.998 5,尽管两个模型效果都相当不错,但BERT-B 模型的表现仍然优于BERT-RF 模型。
通过对上述结果的分析,初步推断BERT 下游分类任务由分类器的不同所产生的分类精度差异,可能是由于BERT 模型框架依赖于深度学习的神经网络结构,而随机森林作为一种传统的机器学习算法与神经网络的学习方式不同,在加入BERT 下游分类任务层时可能会出现由于内部算法原理不同所导致的模型架构差异较大而影响分类精度。因此,本研究在BERTBASE下游结构中添加全连接层所构建的BERT-B 模型更加适于网络文本的心理特质预测。
4 结束语
本文基于BERT 构建了BERT-B 和BERT-RF 两种网络文本心理特质预测模型,通过双向训练的模式使模型能够在更大程度上获得完整的上下文语义特征,利用Transformer 的Encoder 捕捉更长距离的上下文依赖关系;在下游分类任务中分别采用BERTBASE模型的单层神经网络结构和经典的随机森林算法作为两种不同的分类器,都表现出了较为理想的分类预测效果。与经典的深度学习模型CNN-Attention 和Bi-LSTM-Attention 的结果对比后进一步验证了本研究所提出模型的有效性。从平均表现来看,BERT-B和BERT-RF 两个模型的平均准确率、平均精准率等各项指标都在0.97 以上,结合多项指标可以看出BERT-B 模型的平均效果强于BERT-RF 模型。就部分而言,BERT-RF 模型在羞怯特质中表现最好,准确率和精准率都大于0.98,在合作性、完美主义及焦虑特质的分类预测中准确率及精准率也都在0.97~0.99之间;BERT 模型对于合作性和羞怯两种特质的分类预测准确率和精确率高达0.99 以上,对完美主义和焦虑两种特质的分类预测准确率均高于0.98,而且BERT-B 模型的ROC 与AUC 表现也比BERT-RF 更好。由此可以得出结论,相对于BERT-RF 模型,BERT-B 模型的平均表现以及在每种心理特质的分类预测表现都更为出色。构建不同的心理特质预测模型,同时对其他相关心理特质或人格倾向的预测模型研究具有一定的参考价值。
从模型算法角度来看,对于四种心理特质的预测任务本质上为文本的多标签分类任务。考虑到心理特质本身是一种极为复杂的内隐特征,尽管目前来看本研究所预测的羞怯、合作性、完美主义、焦虑四种心理特质所对应的四种标签之间并不存在明显的相互依赖关系,但是仍然无法完全排除这一可能性,因此这种做法无法避免不同标签之间相互影响的风险。在后续研究中,可以考虑直接利用多标签输出的方式进行建模。
猜你喜欢
社会科学战线(2022年8期)2022-10-25
北京航空航天大学学报(2022年8期)2022-08-31
心理学报(2022年7期)2022-07-09
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
福建基础教育研究(2019年12期)2019-05-28
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
