
基于动作预测与环境条件的行人过街意图识别*
2021-08-12 08:14范福成杨吉成蔡英凤
汽车工程 2021年7期
杨 彪,范福成,杨吉成,蔡英凤,王 海
(1.常州大学微电子与控制工程学院,常州 213016;2.常州大学计算机与人工智能学院,常州 213016;3.江苏大学汽车工程研究院,镇江 212013;4.江苏大学汽车与交通工程学院,镇江 212013)
前言
伴随社会的发展,汽车保有量不断增加,给人们的生活与出行带来了极大的便利。其中,无人驾驶因其稳定、高效、可连续工作的优点,在军事作战、城市反恐、应急救援、无人清扫、智慧物流等方面呈现出广阔的应用前景。以本次爆发的新冠疫情为例,利用无人驾驶车辆运输抗疫物资,可以有效减少人员接触,降低疫情传播风险。但是,城市交通环境的复杂性给无人车的可靠运行带来了挑战。在有人驾驶情况下,2018年全球有135万人死于道路交通事故,其中行人与非机动车驾乘者占26%[1];美国高速公路安全管理局发布的统计数据显示2018年美国的行人死亡数目为6 283人[2];我国2017年道路交通运输安全发展报告显示,2016年我国有超过6万人死于机动车交通事故,其中行人约占2成[3]。可以预见,未来大量运行于城市道路环境的无人车也将面临如何避免人车冲突这一智能交通领域(ITS)的重要问题。
为了避免人车冲突,研究者提出了基于物理的运动模型[4]、基于机动的运动模型[5]和基于交互感知的运动模型[6]来预测人车冲突风险。其中,准确感知无人车周围的交通环境[7]是实现准确的人车冲突预测的关键。基于此目的,研究者在无人车上加装了超声波雷达、激光雷达、摄像头等传感器,用于感知车辆周围环境,尤其是检测或跟踪车辆前方的行人。Song等[8]提出一种基于注意力机制的尺度自适应柱网络,用于从三维点云数据中准确定位无人车前方的行人目标;种衍文等[9]引入四方向特征结合级联分类器进行粗检测,然后使用熵梯度直方图特征结合支持向量机进行细检测;Tian等[10]使用深度卷积网络分别检测行人的不同部分并进行综合;Mao等[11]将时变通道、深度通道等特征送入Faster⁃RCNN框架,增强了待检测行人的区分度;刘国辉等[12]结合VGG模型与在线观测技术,实现了对车辆前方目标的准确跟踪。上述方法可以有效防止人车冲突,但是,仅仅以低层面的路侧行人检测或跟踪结果作为预测人车冲突的基础,会导致无人车的频繁制动、降速、甚至停车,影响乘客的驾乘体验。
近年来,随着智能网联汽车的兴起,汽车在搭载先进传感器、控制器、执行器的基础上,融合现代通信和网络技术,实现人、车、路、后台等智能信息的交换共享,有助于实现安全、舒适、节能、高效行驶。对于智能网联汽车而言,如何利用智能化的感知技术,避免人车冲突是实现其它功能的前提。人车冲突集中发生于车辆与过街行人之间,因此高层面的行人过街意图引起了研究者的广泛关注:如果能够准确识别车辆前方行人有过街意图,则应该控制车辆减速而防止碰撞事件发生;如果判断行人无过街意图,车辆可按照原速通过,既提升了无人车的驾乘体验,也提高了行车效率。
行人的过街意图受到多种因素的影响[13],包括交通场景、交通流量、天气等外部因素,以及行人的性别、年龄、等待时间等内部因素。受益于计算机视觉技术的发展,研究者通过分析路侧行人的行为来预测其是否有过街意图。针对运动的行人,Christoph等[14]结合动态高斯系统与多模态交互卡尔曼滤波实现行人轨迹预测;Gu等[15]引入动态贝叶斯网络实现行人轨迹预测;Lee等[16]提出一种基于深度统计逆最优控制的递归神经网络自编码结构学习车辆前方行人和其他车辆的轨迹信息;Shen等[17]提出了一种基于逆强化学习的可迁移行人轨迹预测策略。在准确预测行人轨迹的基础上,可以有效估计碰撞时间,从而指导无人车做出规避动作。针对非运动的行人,研究者通过识别行人的特定动作,如挥手、迈腿、凝视等,预测行人的过街意图。为了识别特定动作,研究者往往需要事先检测人体的骨骼点[18]。譬如,Fang等[19]利用检测出的骨骼点之间的距离和角度判断行人是否有过街意图,Quintero等[20]在三维空间检测人体骨骼点,并基于骨骼点信息识别行人的静止站立、起动、行走和停止动作。
相比于运动行人的过街意图识别,非运动行人由于不存在显著的运动性,其过街意图识别较为困难。尽管通过人体骨骼点检测可以判断行人过街前的动作,进而预测其过街意图。但是,受限于复杂环境、人车距离、局部遮挡等因素,较难准确检测人体骨骼点,进而降低了动作识别的精度。同时,行人过街意图与其所处交通环境密切相关,仅仅进行行人检测、跟踪、轨迹预测与动作识别,缺乏对上下文语义信息的考虑,较难准确识别行人意图。
针对上述问题,本文中提出了一种融合场景条件因素的端到端深度神经网络,实现了行人意图的准确识别。针对复杂情况下难以准确检测行人骨骼点的问题,设计了一种改进的卷积自编码网络,以生成式策略预测视频中的行人行为,同时利用深度神经网络强大的表征能力学习行人未来动作编码。同时,针对影响行人过街意图的外部因素,如行人周围的局部交通场景、人车距离和车速等,本文中引入了E⁃NET网络进行局部场景理解,引入注意力机制改进的GRU(门限递归单元)编码车速和人车距离信息,并将得到的信息与动作信息进行融合,从而准确预测行人过街意图。
综上,本文的主要贡献可归纳为:(1)针对行人过街意图受到主客观因素影响的特点,提出了一种融合场景因素的端到端深度神经网络,实现行人意图的准确识别;(2)针对复杂环境下较难准确提取行人骨骼点、导致难以识别其动作的问题,提出了一种基于先验可学习视频预测的动作信息编码网络,在预测行人未来动作的同时实现未来动作编码;(3)针对交通场景对行人过街意图的影响,引入轻量级E⁃NET网络实现行人周围局部交通场景的实时语义理解;(4)针对车速、人车距离对行人过街意图的影响,使用GRU进行信息编码,并引入注意力机制使GRU更加关注车速的突然改变。最后,在JAAD与PIE两个公共数据集上进行算法评价,结果表明本文算法具有较高的准确性,同时,实车测试也展示了算法在变化光照条件下的鲁棒性。
1 算法理论基础
1.1 变分自编码器
Kingma等提出的变分自编码器(variational auto⁃encoder,VAE)[21]是一种无监督学习模型。VAE结构框图如图1所示,VAE由编码器和解码器组成,其基本思想是:假设输入数据集X中的样本相互独立,通过编码器生成服从正态分布的隐变量Z,然后通过解码器重构生成数据集X,并使X尽量接近X。编码器和解码器由神经网络组成,同时,引入两个神经网络生成隐变量Z的均值μ=f1(x)和对数方差logσ2=f2(x),由于方差是非负的,而使用对数方差后可正可负,运算更加方便。编码器得到的后验分布函数为qΨ(z|x);解码器得到的真实后验分布函数为Pθ(z|x),并使用KL散度度量两者之间的距离,通过损失函数来优化VAE模型参数,损失函数如下:


图1 VAE结构框图
1.2 E⁃NET网络
语义分割是计算机视觉领域的关键问题之一。对于运行中的无人车,语义分割可以帮助其理解复杂的交通场景,并从场景中推测出轨迹规划、避障等任务所需的知识。随着深度学习的发展,研究者提出了诸如FCN[22]、UNET[23]和SegNet[24]等模型,取得了远超传统分割算法的优异表现。但是,上述模型的计算量较大,较难实时运行。本文中引入一种轻量级卷积神经网络E⁃Net[25],对行人周围的局部场景进行语义分割,从而编码局部交通场景信息,如图2所示。
如图2(a)所示,E⁃Net网络包括6种模块,分别是初始化模块和5种瓶颈模块。初始化模块的网络结构如图2(b)所示,图2(c)所示为常规、下采样、上采样、膨胀、非对称5种瓶颈模块的网络结构。通过不同种类瓶颈模块的配合,实现了对图像全局信息的编解码,进而实现对交通场景的语义理解。

图2 E⁃Net结构框图
1.3 门限循环单元
门限循环单元(gated recurrent unit,GRU)[26](见图3)是循环神经网络(recurrent neural network,RNN)[27]的一种变体,相比于长短时记忆网络(long⁃short term memory,LSTM)[28],GRU可以在更少计算量的前提下获得更好的表现。
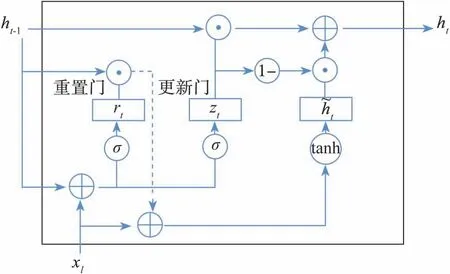
图3 GRU单元结构
如图3所示,每个GRU由控制信息传输的更新门和重置门组成。其中,t为时间步长,t时刻下更新门接收当前输入向量和前一时间步的单元状态,通过激活函数处理,帮助GRU控制当前状态需要从前一时间步状态中保留的信息量以及从候选状态中接受的信息量。重置门和更新门的处理类似,用于控制候选状态对前一时间步状态的依赖,使GRU能够自适应地忘记或重置当前的信息。因此,GRU能够有效地捕捉输入序列的长期和短期的依赖关系,更适用于解决动态识别任务。假设GRU网络的输入量为X=(x1,x2,...,xn),其中各变量的关系如下:

式中:x t表示当前时刻的输入;W rx、W zx、W hx、W rh、W zh和W hh为可学习权重矩阵;r t和z t分别表示重置门和更新门权重;h t-1和h t分别表示前一时刻和当前时刻的隐藏层状态;ht表示当前时刻新的记忆;σ为sigmoid(·)函数,tanh(·)为双曲正切激活函数;b r、b z和b h分别表示重置门、更新门和新记忆中的偏差项。
1.4 注意力机制
注意力机制(attention mechanism)借鉴了人类视觉方面的选择性注意特点,即人类快速地扫描全局图像,可以获得需要重点关注的目标区域,进而从该区域获得目标细节信息,抑制无用信息。针对序列数据,注意力机制可以为序列特征分配不同的权重,并通过概率分配的方式自动提高模型对重要特征的关注程度,从而在不增加计算与储存成本的前提下,增加对序列数据处理的准确性。
本文中需要处理车辆速度与人车距离,将注意力机制引入GRU模块构成AGRU(attention⁃GRU),可以突出车辆加减速以及人车距离突然变短等关键信息,改善行人过街意图识别结果。图4为AGRU的结构,其中,t表示从1到n的时刻信息,x t表示GRU模块的输入,h t对应t时刻AGRU模块的隐藏层输出,αt表示通过注意力机制计算得到的关于时序特征的注意力概率分布,y表示AGRU的输出,由各时刻特征加权得到。

图4 AGRU结构图
αt与y的计算公式如下:

式中:W w和b w为tanh(·)的可学习参数与偏置;W A为AGRU的可学习参数。
2 行人过街意图识别算法
2.1 算法概述
本文中致力于识别行人过街意图,即判断在路侧等待的行人是否有穿越马路的意图,进而帮助车辆更好地理解交通场景。图5为本文中提出的多源信息融合识别网络(multi⁃source information fu⁃sion based recognition network,MIFRN)。MIFRN通过综合考虑行人动作、周围局部交通场景、车辆速度和人车距离,来解决行人穿越/不穿越这个分类问题。首先,引入YOLOv4[29]进行行人检测,并通过Yamaguchi[30]等提出的单目相机自运动估计算法进行自运动补偿,并将20帧内没有发生明显位移的行人目标作为感兴趣目标,即路侧等待的行人。然后,将感兴趣目标送入MIFRN,并扩展其最小外接矩形(如图5红色矩形框所示),得到周围局部交通场景(如图5黄色矩形框所示),同时将车速和人车距离(车辆近似位于图像底部中点)送入MIFRN。具体扩展方法是保证红、黄矩形框中心对齐的前提下,将红色矩形框的宽度和高度分别按照经验值扩大5倍和2倍。MIFRN包含3个主要模块:①基于E⁃NET的轻量级场景语义理解网络,用于编码局部交通场景;②基于先验可学习视频预测的动作信息编码网络,用于编码行人未来动作信息;③基于注意力机制加权的GRU时序数据处理网络,用于编码车辆速度和人车距离。最后,引入双向GRU进行信息的深度融合,并将融合结果送入多层感知机以获取行人穿越/非穿越概率。下面将分别介绍MIFRN的主要模块。

图5 多源信息融合识别网络MIFRN整体框图
2.2 行人未来动作信息编码
行人穿越马路前,往往伴随迈步、挥手、注视来车等动作。当车辆驾驶员捕捉到这些行为,就可以提前减速让行,避免人车碰撞。因此,准确理解路侧行人的动作,对于识别其过街意图至关重要。前期研究集中于检测行人的骨骼点,进而设计不同的动作模式。但是,拍摄距离、角度与光照、环境等因素可能导致无法准确检测行人骨骼点,进而较难准确理解其行为。
本文中引入深度神经网络编码行人动作信息,基于多任务学习范式,提出了一种基于先验可学习视频预测的动作信息编码网络,即通过训练生成式模型预测行人未来动作,并从中编码未来动作信息。为了更好地生成行人未来动作,会迫使网络更加关注行人动作线索,从而提高了未来动作编码的准确性。
图6所示为动作信息编码网络结构。在获得视频当前帧Xt的前提下,网络可预测视频下一帧Xt+1。本文中采用3个相互独立的VGG16网络作为编码器,为了加速收敛,利用ImageNet对网络进行了预训练。考虑到动作的时序性,引入GRU模块挖掘动作编码的时域关联。在训练阶段,引入视频下一帧的真实值Xt+1作为监督信息。图中,GRU2从Xt中预测隐变量Z,GRU1从Xt+1中预测隐变量中包含真实值Xt+1的信息。通过最小化Z和之间的KL损失,可以迫使GRU2学习如何从Xt中预测包含真实值Xt+1信息的隐变量Z。在解码阶段,将Z与编码器3的输出拼接后,送入GRU3进行时序处理,并将处理后的结果送入解码器,解码器输出t时刻的预测值,Xt+1与之间的重构误差可用于评价网络预测的准确性。解码器由编码器中VGG16网络的镜像翻转构成,并将下采样池化模块替换为上采样膨胀卷积模块。所有的GRU采用单层结构,隐含层神经元个数为64。本文将GRU3的输出结果作为t时刻的行人未来动作编码Ψt,相比于对当前动作编码,对未来动作的编码能够更好地反映行人意图。

图6 基于先验可学习视频预测的动作信息编码网络结构
2.3 局部交通场景理解编码
行人穿越行为通常发生在有交通信号灯、斑马线和行人指示标志的路口,准确理解行人周围的局部交通场景,对于判断其是否会穿越有较大帮助。基于深度学习在语义分割领域的成功,本文中引入轻量级的E⁃NET网络实现场景理解。为了加速拟合,在KITTI语义分割数据集上对E⁃NET网络进行了预训练。训练后的E⁃NET网络在下采样过程中可以获取局部交通场景的深度编码,这种编码尽管丢失了部分场景细节信息,但是能够保留局部交通场景的道路、建筑物、树木等主要语义信息,从而保证MIFRN能够更好地理解行人所处的局部交通环境。E⁃NET网络结构如图2所示,由于本文中只需要编码局部交通场景,因此仅保留E⁃NET网络的前4个模块,删除了上采样模块。假设t时刻输入的局部交通场景为St,则对St的编码如下:

式中:f(·)表示预训练后的部分E⁃NET网络;Ws表示网络的可学习参数。
2.4 车速、人车距离编码
当来车速度过高、或者人车距离过近时,行人往往会放弃穿越,转而等待车辆通过。因此,准确编码车速和人车距离可以提高行人过街意图识别的准确性。本文中引入GRU模块高效地编码车速与人车距离。同时,考虑到极端情况(如车辆突然加速、人车距离突然缩短等)对行人过街意图的影响较大,本文中引入注意力机制,设计了基于注意力机制加权的AGRU,分别对车速和人车距离进行编码。假设车 速 和 人 车 距 离 序 列 分 别 是V t={v1,v2,...,vt}和D t={d1,d2,...,d t},则车速和人车距离在t时刻的编码结果分别为

式中:AGRUV(·)和AGRUD(·)表示两个独立的GRU时序数据处理网络;W V和W D分别是AGRUV(·)和AGRUD(·)的可学习参数。
2.5 多源信息融合和行人过街意图识别
对于t时刻行人运动信息编码Ψt、场景语义编码φt、车速与人车距离编码ΦVt与ΦDt,常用融合方法是直接拼接。但是,直接拼接较难获取不同编码信息之间的深层关联。本文中引入基于双向GRU的信息融合模块,将4种编码组合成序列I t=[Ψt,φt,ΦVt,ΦDt],并将I t送入双向GRU,双向GRU的输出作为融合结果:

式中:BiGRU(·)表示双向GRU网络;W Bi表示网络的可学习参数;O t表示t时刻的融合编码向量,维度为64。这种融合方式有利于挖掘不同编码信息的深度关联,从而提高行人意图识别的准确性。
为了从O t中推测行人过街意图,本文中引入了多层感知机,感知机中每层的神经元个数分别为64、32、16和2。最后,将输出通过Softmax函数归一化,得到行人穿越/非穿越的概率。
2.6 损失函数设计
本文中采用多任务学习范式,网络在识别行人意图同时,可以预测行人的未来动作。总的损失函数包括:(1)分类损失Lc;(2)重构损失LG;(3)KL损失LKL。
(1)分类损失Lc:本文中将行人过街意图识别当做分类问题处理,考虑到行人个体的差异,识别有难有易。因此,引入了焦点损失函数(focal loss)代替二值交叉熵损失函数,Lc定义如下:

式中:Yi表示样本i的真实标签,0表示负样本,1表示正样本;Pi表示网络输出的行人过街意图的预测概率。超参数α用于控制正负样本的比例,按经验值设为0.5;超参数γ用于缓解难易样本问题,按文献[21]设为2。
(2)重构损失LG:该损失用于衡量动作预测与真实结果的差异,本文中采用L2损失作为重构损失LG,定义如下:

式中:Xt为t时刻的真实值为t时刻网络的输出值。
(3)KL损失LKL:该损失用于衡量动作信息编码网络训练阶段中潜变量Z与Z之间的分布差异,通过降低该损失,可以使分布Z与Z接近。本文中引入KL散度来计算LKL,定义如下:

在得到上述3个损失函数的前提下,总的损失函数如下:

式中权衡参数κ与β通过交叉验证分别设置为0.1与0.5。
3 实验结果与分析
3.1 数据集与衡量指标
(1)JAAD[31]。JAAD数据集常用于研究交通参与者的行为。该数据集包括346段5-15 s的高分辨率视频片段,每个片段中都包含城市环境下的不同驾驶场景。数据集中提供了行人的标注信息,标注的行人类型包括:沿路侧行走的行人、路侧等待的行人、正在穿越马路的行人等。考虑到识别行人过街意图的目的,从JAAD数据集中选取了158个穿越行人样本和79个非穿越行人样本。
(2)PIE[32]。PIE数据集常用于研究行人意图,其规模大于JAAD数据集。PIE使用车辆在不同街道结构、不同群体密度地区采集了1 842段位于路侧的行人数据。所有数据都采于白天、能见度高的场合,因此可以较好地分析行人行为。考虑到识别行人过街意图的目的,从PIE数据集中选取了516个穿越行人样本和852个非穿越行人样本。
3.2 时域数据增益
JAAD和PIE数据集提供了分析行人过街意图的样本,但是,仍然存在两个问题:(1)样本量偏少,尽管PIE数据集的1 368个样本远大于JAAD数据集的237个样本,但仍然无法满足深度神经网络训练的需要;(2)正负样本不均衡,JAAD数据集中穿越行人与非穿越行人样本的比例约为2∶1,PIE数据集中这个比例约为1∶1.6。
为了缓减这两个问题,本文中引入了时域数据增益,步骤如下。
(1)对于穿越行人样本,以其开始穿越时刻(开始迈腿或摆手的瞬间)为界,向前、后各取12、11帧,总计获得24帧数据。
(2)对任意24帧数据进行时域增益,即以2帧为间隔在时域上连续采样长度为16帧的序列,最后可获得1-16、3-18、5-20、7-22、9-24共5个序列,且每个序列中都包含开始穿越时刻(即第13帧)。数据增益后,可分别从JAAD和PIE数据集中提取出790和2 580个穿越行人样本。
(3)对于非穿越行人样本,考虑正负样本间的均衡,以行人可以清晰观测为准,从JAAD数据集中的每个非穿越行人序列中连续采集34帧数据,从PIE数据集中连续采集20帧数据,并分别以2帧为间隔在时域上进行增益。最后,可分别从JAAD和PIE数据集中提取出790和2 556个非穿越行人样本。
(4)对于增益后的JAAD与PIE数据集中的穿越/非穿越行人样本,以5-折交叉验证的方式确定训练集与测试集,并采用正确率Acc(Accuracy)指标进行评价,Acc计算公式如下:

式中:P和N分别表示总的穿越样本与非穿越样本数目;TP和TN分别表示正确识别的穿越样本与非穿越样本数目。
3.3 实验细节设置
本文中所采用的实验平台搭载了两块英伟达1080ti显卡和一块英特尔I9 CPU,实验环境为Ubuntu系统、Pytorch框架。行人动作序列的尺寸为128×128像素,局部交通场景的尺寸为320×320像素。本文中使用Adam优化器训练网络,总的训练批次数目为300,初始学习率设置为0.01,并每隔100批次将学习率除以10。
3.4 销蚀实验
本文工作的贡献之一是提出一种多源信息融合识别网络MIFRN识别行人过街意图,除了从行人动作中识别其穿越意图,MIFRN还能够融合行人周围的局部交通场景、车速、人车距离等线索,做出综合决策。为了评价网络中不同信息的作用,本文中分别在JAAD与PIE数据集上进行了销蚀实验,结果如表1所示。从表中不难看出,行人动作中包含其是否准备穿越的主要信息,局部交通场景信息可以作为行人动作的重要补充,车速、人车距离也能够在一定程度上提高行人过街意图识别的准确性。

表1 MIFRN网络销蚀实验
3.5 行人过街意图定量分析
行人过街意图识别是智能交通系统与无人驾驶领域的热点话题之一。但是,大量研究通过分析行人的历史轨迹判断其是否有过街意图,忽略了行人的外表与动作。本文中着眼于识别行人开始穿越的动作,结合交通场景、车速、人车距离,准确识别行人过街意图。为了展示本文方法的有效性,选取了如下方法进行对比:
(1)文献[33]中提出的一种基于AlexNet网络的行人过街意图识别方法;
(2)文献[34]中提出的一种双通道卷积神经网络识别行人过街意图的方法;
(3)文献[19]中基于人体骨骼点检测结果识别行人动作,进而判断其过街意图的方法;
(4)文献[35]中引入图卷积神经网络处理人体骨骼点之间的关联,提高了行人动作识别的准确性,进而能够更好地识别行人过街意图的方法;
(5)文献[36]中提出的一种基于时空关联推理的方法,通过图模型建模行人与车辆的关系,从而识别行人过街意图。
本文中在JAAD和PIE数据集上以相同设置对比了算法性能,用于比较的算法采用了相应工作中的默认设置。表2和表3分别给出了本文算法与主流算法在JAAD和PIE数据集上的比较结果。从表中不难看出,基于骨骼点的行人意图识别算法性能优于早期的AlexNet网络和双通道卷积神经网络,弱于近期提出的基于时空性关联推理的方法[36]。本文算法由于引入了行人未来动作信息编码,同时综合考虑了局部交通场景、车速和人车距离,在两个数据集上都取得了最优的效果。

表2 与主流算法在JAAD数据集上算法性能比较

表3 与主流算法在PIE数据集上算法性能比较
3.6 行人过街意图定性分析
本文中提出了一种基于视频预测的动作信息编码网络,在预测行人未来动作的同时,生成其未来动作编码,该编码中包含了行人的过街意图。因此,行人未来动作生成的优劣决定了编码是否准确,进而关系到能否准确识别其过街意图。图7和图8展示了JAAD和PIE数据集中一些行人样本的未来动作生成示例。图中蓝色方框表示观测的10帧动作序列,红色方框表示生成的10帧未来动作。由于行人未来动作的不确定性随着观测时间的推移而增加,因此红框中后端图像的生成质量劣于前端图像。对于图7和图8中,(a)、(b)为未穿越行人样本,(c)、(d)为穿越行人样本。不难看出,本文算法能够描述行人的未来动作,如果行人没有穿越马路,则生成数据中不包含明显的抬腿、挥手等动作;反之,生成数据中通常包含腿部动作,揭示了行人即将穿越。

图7 JAAD数据集行人未来动作生成示例

图8 PIE数据集行人未来动作生成示例
利用图像信息识别行人过街意图的主流方法是检测行人骨骼点,在此基础上识别行人动作,进而判断其是否准备过街[19]。但是,骨骼点检测对行人图像的清晰度有一定要求。在实际交通场景下,人车距离、遮挡、光线、行人穿着等因素都会对骨骼点检测产生影响,导致误检或漏检。图9和图10分别给出了JAAD和PIE数据集中骨骼点检测失败的例子。对于任意子图,上一行表示行人观测序列,下一行表示骨骼点检测结果。图9(a)和图9(b)中由于行人的姿态、穿着等因素,无法准确检测其骨骼点,进而无法利用骨骼点信息判断行人是否准备过街。使用本文方法,在仅使用行人未来动作编码的前提下,得到图9(a)和图9(b)中行人不穿越、穿越的概率分别为0.788和0.836。图10(a)和图10(b)中部分帧可以检测到完整的行人骨骼点,但是其它帧存在误检、漏检,导致较难识别行人过街意图。仅使用本文中提出的未来动作编码,得到图10(a)和图10(b)中行人不穿越、穿越的概率分别为0.822和0.858。由此可见,本文方法能够在复杂交通场景下鲁棒地识别行人动作信息,进而结合场景条件,更好地识别行人是否具有过街意图。

图9 JAAD数据集行人骨骼点检测失败案例

图10 PIE数据集行人骨骼点检测失败案例
3.7 实车实验效果
为了验证所提算法的有效性,本文中将JAAD与PIE数据集进行了整合,在整合后的数据集上训练模型,并进行了实车实验。图11为实车实验平台“江大智能行”号无人驾驶汽车,该平台集成了智能车感知、地图、规划决策、控制等无人驾驶的基本功能,使用了基于CORS差分技术的GPS与IMU结合的定位系统,并具有由一台velodyne 64线激光雷达、两台ibeo4线激光雷达、一台Delphi毫米波雷达、一台SICK单线激光雷达和两台Gige融合工业相机构成的智能感知系统,其数据处理功能由研华ARK-3 500工控机完成。本次实车实验主要利用了“江大智能行”号的图像采集能力与数据计算能力,实验全程由驾驶员进行操作。图12为两台Gige融合工业相机安装效果图。

图11 “江大智能行”号无人驾驶汽车

图12 车载工业相机安装效果图
图13为本文算法的实车测试结果,其中,上、下图分别展示了3个穿越、非穿越行人样本。MIFRN在输出行人穿越、非穿越概率前使用了Softmax激活层进行标准化处理,因此对于每个样本,其穿越概率与不穿越概率之和为1。为了更清晰地展示行人是否穿越,图13以红色矩形框标记穿越行人,以绿色矩形框标记非穿越行人,并在矩形框顶端附注可能性较大的行为对应的概率值(与矩形框同色)。

图13 实车测试结果
从图中可见,当检测到行人周围有红绿灯、斑马线等交通标识,且行人未来动作中存在抬腿、挥手等可能时,行人有较大的概率穿越;当行人没有任何穿越动作的前兆,且场景中无任何交通标识的情况下,行人有较大概率等待车辆通过。从结果中不难看出,本文算法可以在较大范围光照变化下比较准确地检测行人是否有穿越意图,且对行人的模糊外表有一定鲁棒性,克服了基于骨骼点的行人穿越意图判别中较难准确提出骨骼点信息的不足。
4 结论
本文提出了一种多源信息融合识别网络MIFRN用于识别行人过街意图。MIFRN包含一种基于先验可学习视频预测的动作信息编码网络,可以在预测行人未来动作的同时,生成其未来动作信息的编码,克服了恶劣环境下无法准确检测行人骨骼点的弊端,更加鲁棒地理解行人行为。为了进一步提高行人过街意图的识别准确率,MIFRN引入轻量级的E⁃NET网络编码行人周围的局部交通场景,引入注意力加权的GRU模块编码车速和人车距离,并引入双向GRU多源信息的深度融合。相比于其它主流算法,MIFRN在JAAD和PIE数据集上都取得了最佳性能,在实车实验中也表现出不俗性能。
本文中提出的MIFRN可用于无人驾驶领域的复杂场景感知,通过感知路侧行人的过街意图,可以更好地规划无人车的未来运行轨迹。同时,MIFRN也可用于有人驾驶车辆的ADAS系统,从而为行人防碰撞提供更好的决策依据。尽管MIFRN在公共数据集上取得了较好表现,但仍存在以下问题:(1)计算开销大,MIFRN需要利用YoloV4进行目标检测,然后同时编码行人未来动作、局部交通场景、车速和人车距离,所需要的计算资源较大,较难应用于智能边缘设备;(2)MIFRN主要依赖路侧行人的动作信息识别其过街意图,对于无征兆的行人突然穿越,识别表现较差。因此,后续工作将主要集中在:(1)通过压缩、精简模型,改善算法的实时性能,从而满足智能边缘设备的算力需求;(2)深入研究行人过街意图和人车冲突决策的内在机理,从而在机理上更好地避免人车冲突。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国典型病例大全(2022年7期)2022-04-22
意林(2021年5期)2021-04-18
海峡姐妹(2020年8期)2020-08-25
E动时尚·科学工程技术(2019年4期)2019-09-10
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
电影新作(2014年2期)2014-02-27
中国计算机报(2009年27期)2009-04-27
中小企业管理与科技·上旬刊(2009年10期)2009-01-20
