
新型农村社会养老保险政策的减贫及再分配效应
2021-08-12 04:41洪丽尹康
社会保障研究 2021年3期
洪 丽 尹 康
(1 武汉大学社会保障研究中心/政治与公共管理学院,湖北武汉,430072;2 湖北经济学院经济与贸易学院,湖北武汉,430205)
一、引言
2009年9月,国务院发布了《关于开展新型农村社会养老保险试点的指导意见》。“逐步缩小城乡差距、改变城乡二元结构、推进基本公共服务均等化”和“实现广大农村居民老有所养、促进家庭和谐、增加农民收入”是新型农村社会养老保险制度的主要目标。那么,新型农村社会养老保险(简称“新农保”)从2009年开始试点至2012年基本实现全覆盖,其制度效应如何?本文关注和考察新农保对减贫和收入分配的影响程度。研究对了解我国养老保险政策的收入调节作用,进一步优化社会保障制度,推进乡村振兴,治理相对贫困,实现城乡统筹发展具有重要的意义。
收入再分配功能是政府介入养老保险业务的主要理由之一[1],世界上绝大多数国家建立了以优化收入分配格局及免除老年人生存风险为目标的社会养老保险制度。以往关于养老保险制度收入再分配效应的理论研究侧重分析现收现付、完全积累制等不同养老保险模式的收入再分配效应[2-6],通常采用微观精算模型[7-11],以及一般均衡分析[12]、宏观定量分析[13-14]等方法,具体测算某个养老保险体系对收入分配影响的大小。
新农保带有其他养老保险模式的共性,也有其特殊性。近年来很多研究从不同角度对新农保的政策效果进行评估,例如,新农保对农村家庭消费和储蓄的影响[15-17],新农保对农民居民劳动供给的影响[18-23],新农保对老年人健康的影响[24]。
在衡量和评估新农保政策收入再分配效应的文献中,主要采用以下几种方法:一是采用局部均衡分析方法,通过构建精算模型,度量参保人净受益规模,对新农保收入再分配效应进行仿真模拟测算[25-27];其二,在一般均衡的框架下通过构建两期叠代模型,对新农保制度的收入再分配效应进行定量化模拟[28];其三,利用微观调查数据和CHARLS等数据库,采用多元回归、离散选择模型以及工具变量法等多种计量模型对新农保的减贫、收入再分配效应进行实证检验[29-38]。
由于具体研究对象和内容、研究方法、数据使用存在差异,已有关于新农保减贫和再分配效应的研究存在分歧:有的研究认为,新农保能够在一定程度上促进贫困缓解、缩小农村居民收入差距;有的研究认为,新农保的减贫增收效应比较有限[39]。
本文基于中国健康与养老追踪调查(CHARLS)数据库中2008年甘肃、浙江两省的预调查数据以及2012年这两省的追踪调查数据,采用双重差分倾向得分匹配法(DID-PSM),分年龄组考察是否参加新农保对农户家庭收入、家庭人均收入、个人收入等指标的影响,并分别计算2008年和2012年实验组(参保组)和对照组(未参保组)的基尼系数,从微观层面对新农保政策的减贫及再分配效应进行实证分析。与已有文献相比,本文的贡献主要体现在以下两个方面:第一,本文结合双重差分法和双重差分倾向得分匹配法来识别新农保政策对收入分配的因果效应,对公共政策实施效果的实证研究有参考借鉴价值;第二,本研究有助于了解新农保制度的受益分布及效应大小,为检验新农保政策实施效果和调整方向提供了经验证据。
二、实证策略与计量模型
(一)双重差分法(DID)
客观评价某项政策实施的效果,可采用基于自然实验或随机实验进行因果关系评估的方法——双重差分法(Difference-in-Difference,DID)。双重差分法最早由Ashenfelter 和Card提出[40],应用于政策效果的评价,其基本思路是选择一个不实施政策的对照组(也称控制组)和一个实施政策的实验组,通过对实验组和对照组政策前后某项指标的变化量进行差分,来剔除时间趋势和固定效应的干扰,得到政策对实验组的净影响。
新型农村社会养老保险制度自2009年开始试点实施,可将其视为在农村地区进行的一项政策试验。对新农保政策的减贫及再分配效应进行因果效应评估,可采用双重差分法。
设定双重差分方法的基准回归模型如下:
yit=α+β1Treati·timet+β2Treati+β3timet+γZit+εit
其中,i代表样本个体,t代表时期或年份,yit为要考察的结果变量,Treati为政策变量(如果个体i参加新农保,Treati=1;否则,Treati=0),timet为时期变量(当时间为新农保政策实施后,timet=1;当时间为新农保政策实施前,timet=0),Z代表一系列控制变量,也称为协变量。
通过差分发现,未参保的对照组在新农保实施前后y的变动为β3,可以将β3理解为时间趋势的影响;参保实验组在新农保实施前后y的变动为β1+β3,去掉时间趋势的影响可以得到政策净效应β1。也就是说,交互相Treati·timet的系数β1度量了新农保实施的净效应(Average Treatment Effect on the Treated,ATT)。
因此,可以将样本按年龄分为60岁及以上和60岁以下的子样本,以农户收入为应变量yit,对不同子样本估计模型中的系数β1加以对比,从而评估新农保带来的减贫及代际收入分配效应。
新农保通过改变居民的收入排序对收入分配产生影响。基于双重差分的思想,分别计算实验组与对照组在政策实施前(2008年)和实施后(2012年)的基尼系数,用实验组基尼系数的变动减去对照组基尼系数的变动可以直观地看到新农保政策的收入再分配效应。
值得注意的是,应用双重差分法的一个前提是实验组和对照组存在共同趋势,即参与新农保的个体和未参与新农保的个体在没有实施新型农村社会养老保险政策的情形下,收入的变动趋势或收入差距的变动趋势不存在系统性差异。或者说,应用DID方法的一个前提要求为是否进入实验组是随机产生的。但是否被定为新农保政策试点地很可能不是随机产生的,进一步来说,在新农保试点地区,参加新农保遵循自愿原则,参加新农保、进入实验组是居民自我选择的结果,参保组与对照组成员的初始条件可能并不完全相同,存在由选择性偏误带来的内生性问题。双重差分倾向得分匹配法(Difference in Differences-Propensity Score Matching,DID-PSM)则可以有效解决这一问题,使DID方法满足共同趋势假设。为了克服是否参加新农保不同样本之间的系统性差异,降低DID估计的偏误,本文将进一步采用双重差分倾向得分匹配法(DID-PSM)来估计新农保政策的收入再分配效应,这也等同于从侧面进行稳健性检验。
(二)双重差分倾向得分匹配法(DID-PSM)
双重差分倾向得分匹配法(DID-PSM)的思想源于匹配估计量(PSM),其基本思路是在未参加新农保的对照组中找到某个样本j,使j与参加新农保的实验组中的某个样本i的可观测变量尽可能相似(匹配),即Xi≈Xj。当样本的个体特征对是否参加新农保的作用完全取决于可观测的控制变量时,个体j与i参加新农保的概率相近,二者便能够相互比较;若个体选择是否参保还取决于不可观测变量,但这些不可观测变量不随时间而变化,而且可以形成面板数据,则可使用双重差分倾向得分匹配法(DID-PSM)。
双重差分倾向得分匹配法(DID-PSM)由Heckman等提出并发展起来[41],假设有两期面板数据,DID-PSM方法通过先匹配,找到具有可比性的对照组和实验组,进而通过双重差分得到政策实施的净效应ATT, ATT可表示为:
其中,T表示参保实验组或处理组(treat group),C表示未参保对照组或控制组(control group);t1代表新农保实施后,t0代表新农保实施前;i表示参保组第i个个体,j表示未参保组第j个个体;yTt0i和yTt1i分别表示参保组个体i参保前后的收入,yCt0j和yCt1j分别表示未参保组个体j在新农保政策实施前后的收入;w是用PSM中的核匹配法计算出的权重;N1表示匹配成功得到的样本数。
双重差分倾向得分匹配法(DID-PSM)的优点在于它可以控制不可观测但不随时间变化的组间差异,可以帮助解决双重差分法中实验组与对照组在受到新农保政策影响前不完全具备共同趋势假设所带来的问题。
三、数据来源及描述性统计
(一)数据来源及样本处理
本文使用的数据来自中国健康与养老追踪调查(China Health and Retirement Longitudinal Study,CHARLS)。CHARLS是由北京大学国家发展研究院主导的全国家户调查,调查对象是随机抽取的我国45岁及以上居民。CHARLS数据是我国目前唯一的以中老年人为调查对象的具有全国代表性的大型家户调查数据。
CHARLS数据库目前包括2008年两省预调查数据、2011年全国基线调查数据、2012年两省追踪调查数据、2013年全国追踪调查数据和2015年全国追踪调查数据。新农保从2009年开始试点,故本文选取2008年(政策实施前)和2012年(政策实施后)两期面板数据,分别通过双重差分法(DID)和双重差分倾向得分匹配法(DID-PSM)来评估新农保的政策效应。CHARLS团队在2008年选取了经济欠发达的甘肃省和经济发达的浙江省进行预调查,预调查样本来自32个县/区的95个社区/村庄,涉及1570户家庭中的2685个人;2012年调查团队对这两个省又进行了追踪调查,样本涉及1408户家庭中的2379个人。
在对数据进行处理时,本文首先选择2012年实行新农保的社区样本,筛选掉有缺失值的个体,并删除两个年份的收入极端值,然后再匹配两个年份的平衡面板数据。这样进行数据处理后,得到样本个体总数为2004个,2012年实验组样本472个,对照组样本1532个。其中,60岁及以上参加新农保的样本有264个,60岁以下参加新农保的样本有208个;60岁及以上未参加新农保的样本有810个,60岁以下未参加新农保的样本有722个。
(二)变量的选取及描述性统计
1.变量选取
(1)因变量农村居民的收入是本文研究的核心问题。本文选取的因变量包括家庭总收入、家庭年人均收入、个人收入三项指标。家庭总收入或家庭年人均收入通过家庭所有成员的工资收入、农业收入、自雇经营收入、转移收入来衡量,其中家庭农业收入、自雇经营收入以及转移收入以家庭为单位;个人收入计入了样本个体的工资收入、转移收入以及以家庭为单位统计的农业收入、自雇经营收入、转移收入平均到个体的收入。回归时各收入变量取自然对数形式,如果收入为0或为负值,定义对数值为0。通过对比不同收入指标所受的影响的大小,可以间接验证估计结果的可靠性。
(2)自变量
本文的自变量为“是否参加了新农保”。个体若参加了新农保,自变量取值为1;若个体未参加新农保,则自变量取值为0。
(3)控制变量(协变量)
参加新农保以自愿为原则,并非强制。是否参加新农保会受到个人、社会特征的影响。近几年的研究表明,新农保参保行为受到年龄、教育程度、身体健康等因素影响。参考Galiani、张川川等的相关研究[42-43],同时考虑到调查数据的可得性,本文将性别、年龄、受教育程度、婚姻状况、家庭人口规模、户口类型、地区类型、省份纳入控制变量组。此外,考虑到“是否享有其他类型的养老保险”会干扰新农保政策的识别效果,故将“是否参加其他养老保险项目”也纳入控制变量组。在实证分析中,这些控制变量作为协变量参与回归。
2.描述性统计分析
(1)全样本
表1对全样本各个变量的统计特征进行了描述性统计,包括因变量(家庭总收入、家庭年人均收入、个人收入)、自变量(是否参加新农保)、控制变量(性别、年龄、婚姻状况、受教育程度、户口类型、家庭人口规模、省份、地区类型、是否参加其他养老保险项目、孩子数量等)。
从表1可以看出:在所有样本中,2008年实验组的家庭总收入、家庭年人均收入和个人收入都远低于对照组;2012年实验组和对照组的各项收入水平较2008年都有大幅提升。而从控制变量来看,实验组和对照组的性别、年龄、婚姻状况等变量差距不大,一定程度上可以控制这几个变量对个体行为的影响。实验组的受教育程度略低于对照组,家庭人口和孩子数量略多于对照组,一定程度上反映了参加新农保的人口受教育程度相对更低、家庭人口和孩子数量相对更高。从省份和地区类型来看,实验组多集中在甘肃省(占比72%)、村庄或乡中心区(占比82%);对照组中约有60%的人口分布在浙江省,实分布在村庄或乡中心区的人口仅占38%。从参加其他养老保险的情况来看,实验组参加其他养老保险的比例很小,对照组参加其他养老保险的人在2008年约占20%,2012年上升接近36%。
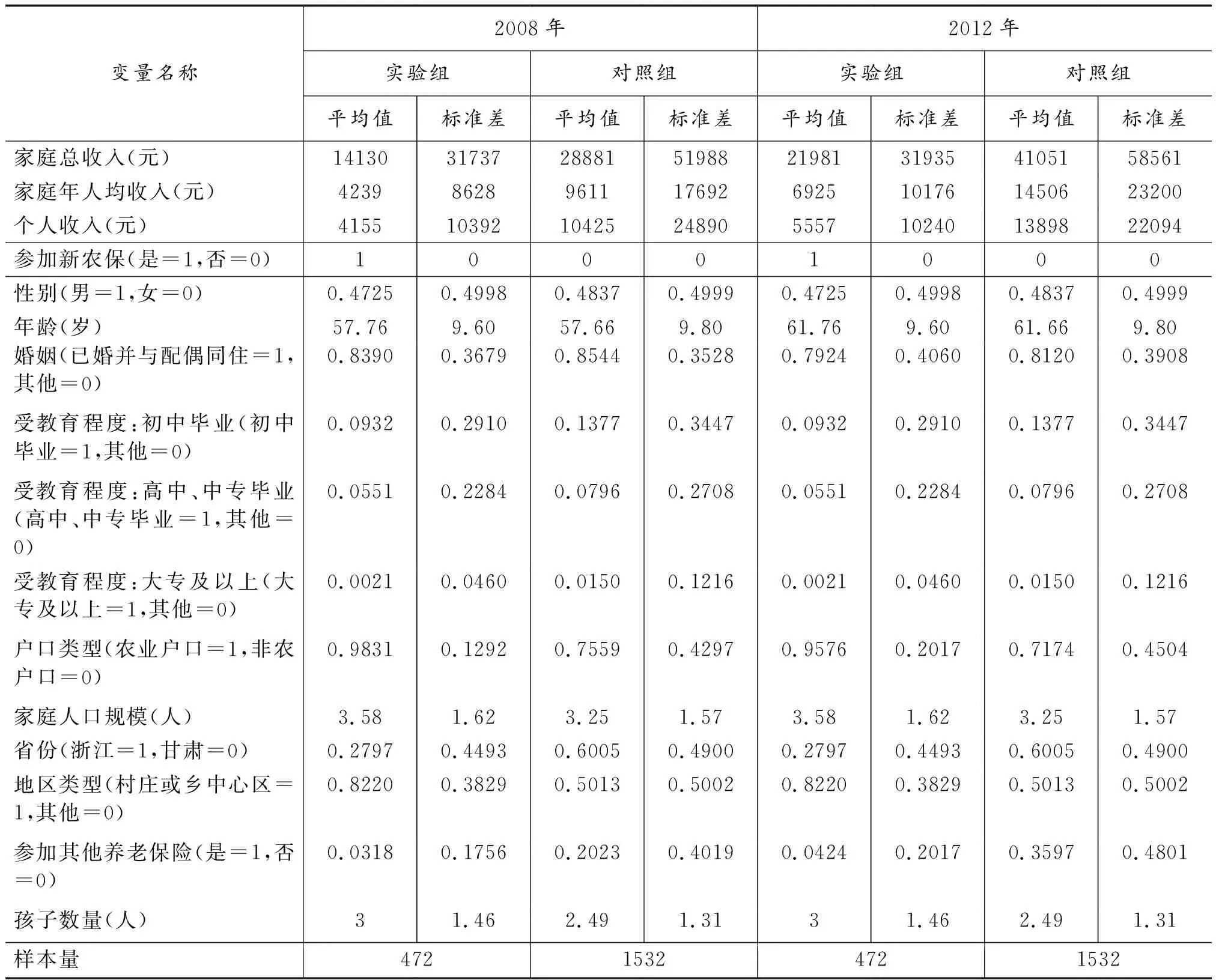
表1 变量描述性统计(全样本)
(2)分年龄子样本
表2分别对2012年60岁及以上和60岁以下(45~59岁)的分年龄子样本的各个变量进行了描述性统计。
从60岁及以上人口样本中可以得到以下发现。家庭总收入平均值为30546元,参加新农保的实验组家庭总收入平均值仅为19405元,远低于未参加新农保的收入水平;在家庭年人均收入和个人收入方面,也是参加新农保的实验组远低于未参加新农保的对照组。在其他方面,由于新农保遵循自愿原则且处于扩面阶段,仅24.58%的人参加了新农保;男性占比52.5%,样本平均年龄约69岁,在参保和未参保的样本中性别、年龄的分布都比较均衡; 已婚并与配偶同住的占比73.56%,其中,参保群体这一比例略低于未参保群体;参保人口的受教育程度平均低于未参保人口;而参保人口的家庭人口规模和孩子数量则要高于未参保组;分布在浙江省的占比51%,其中参保的实验组中分布在浙江的样本仅占比28%,未参保的则有59%分布在浙江省;从地区类型来看,参保人群大多分布在村庄或乡中心区;有21.6%的人参加了其他养老保险,参同时加新农保和其他养老保险的仅有1.5%,未参加新农保的人群中有28%参加了其他养老保险。
60岁以下人口样本描述性分析如下。家庭总收入平均值为43505元,家庭年人均收入平均值为15194元,个人收入平均值为13156元;参加新农保的实验组家庭总收入、家庭年人均收入、个人收入远低于未参加新农保的各项收入水平。在其他方面, 22.37%的人参加了新农保,略低于60岁及以上人口的参保水平;男性占比43%,样本平均年龄约53岁,在参保和未参保的选择中性别、年龄的分布也都较均衡;已婚并与配偶同住的占比89%,其中,参保群体这一比例略高于未参保群体;参保人口的受教育程度略低于未参保人口;参保人口的家庭人口规模和孩子数量则高于未参保组;分布在浙江省的占比53%,参保的实验组中分布在浙江的仅占27.88%,近72%分布在甘肃省,未参保的则有约61%分布在浙江省;从地区类型来看,参保人群大多分布在村庄或乡中心区;有36.45%的人参加了其他养老保险,既参加新农保又参加其他养老保险的仅占比7.69%,未参加新农保的人群中有44.74%参加了其他养老保险。
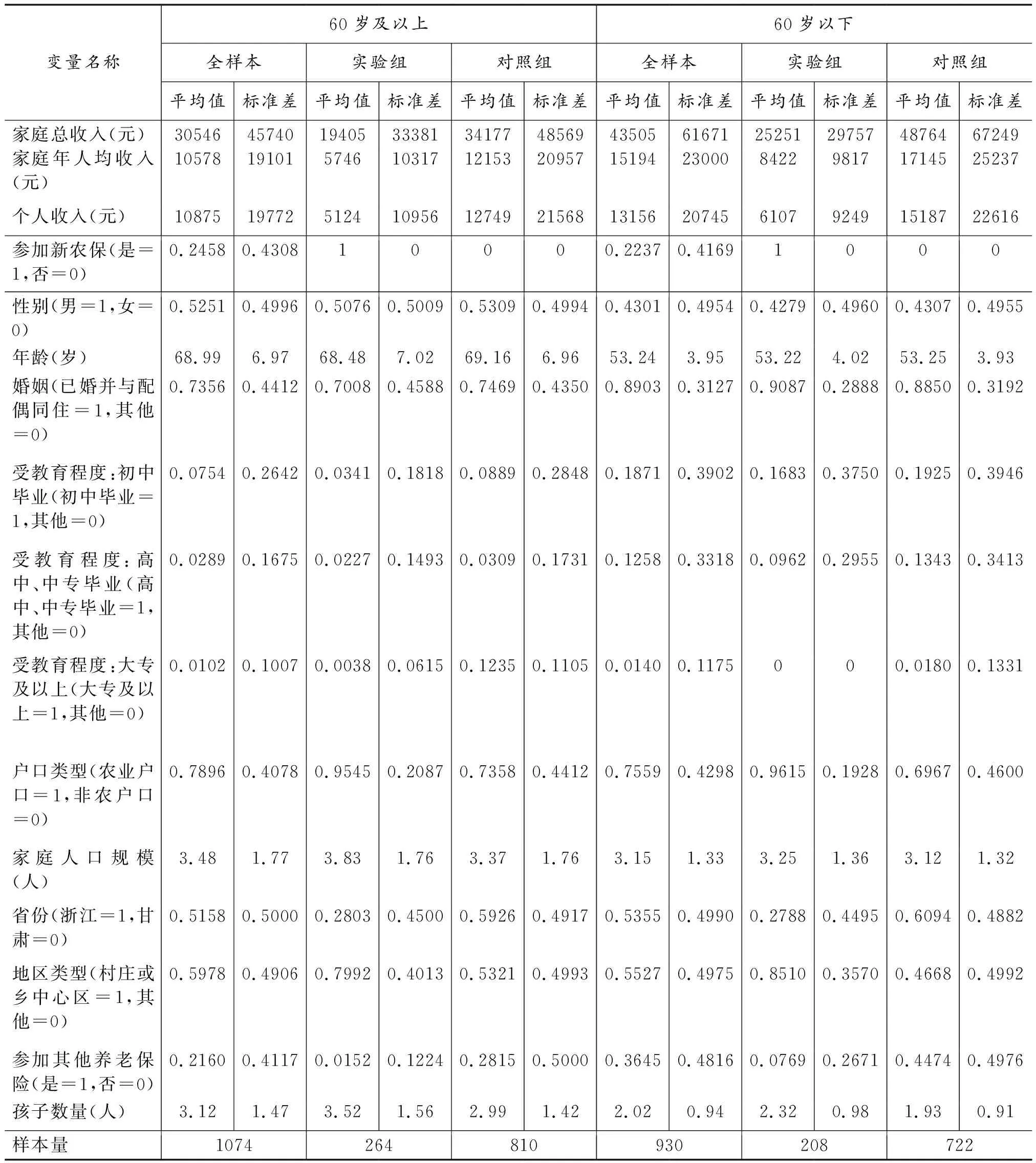
表2 变量描述性统计(2012年分年龄子样本)
四、实证结果与分析
(一)DID估计结果
如前所述,采用双重差分法(DID)估计新农保的减贫及再分配效应有两种做法:其一,按年龄将总样本分为两个子样本(60岁及以上和60岁以下),以农户收入为应变量yit,对不同子样本估计模型中的系数β1加以对比,来评估新农保的减贫及代际收入分配效应;其二,基于双重差分的思想,直接计算实验组与对照组在政策实施前(2008年)和政策实施后(2012年)的基尼系数,用实验组基尼系数的变动减去对照组基尼系数的变动得到新农保政策的收入再分配效应。第二种方法更简洁、更直观,本文直接列出采用第二种方法并基于家庭人均收入计算的新农保政策的收入再分配效应,结果如表3所示。
从表3可以看出,无论是从总样本来看,还是从分地区的子样本和分年龄的子样本看,参加新农保给农村居民的收入带来正向的再分配效应,新农保制度的实施具有均等收入分配的总效应。首先,从总样本来看,参加新农保带来的收入再分配效应使基尼系数下降了3.7个百分点。参加新农保的样本2012年的基尼系数为0.602,2008年的基尼系数为0.667;未参加新农保的样本2012年的基尼系数为0.577, 2008年的基尼系数是0.605。用参保的实验组基尼系数的变化减去未参保的对照组基尼系数的变化,可知参加新农保带来的收入再分配效应使基尼系数下降了3.7个百分点。其次,从分地区的子样本来看,浙江省参加新农保带来的收入再分配效应远大于在甘肃省的效应。在浙江省的子样本中,2012年参保的实验组基尼系数为0.483,2008年为0.568,2012年未参保的对照组基尼系数为0.525,2008年为0.548,浙江省子样本参保形成的收入再分配效应使基尼系数下降了6.2个百分点;在甘肃省的子样本中,2012年参保的实验组基尼系数为0.597,2008年为0.612,2012年未参保的对照组基尼系数为0.589,2008年为0.593,甘肃省子样本参保形成的收入再分配效应仅使基尼系数下降了1.1个百分点。再次,从分年龄子样本来看,参加新农保使60岁及以上老年群体收入差距下降的更多。2012年60岁以下参保的实验组的基尼系数为0.546,2008年为0.621;2012年60岁以下未参保的对照组的基尼系数是0.525,2008年为0.569。2012年60岁以下样本参保带来的收入再分配效应使基尼系数下降了3.1个百分点。在60岁及以上的样本中,参加新农保的实验组2012年的基尼系数是0.635,2008年的基尼系数为0.693;而未参加新农保的对照组2012年的基尼系数是0.620,2008年的基尼系数为0.619。2012年60岁及以上老年群体参保带来的收入再分配效应使基尼系数下降了5.9个百分点。对比2012年60岁以下和60岁及以上子样本参加新农保的基尼系数变化净效应可以发现,参保使60岁及以上老年群体收入差距下降的更多。
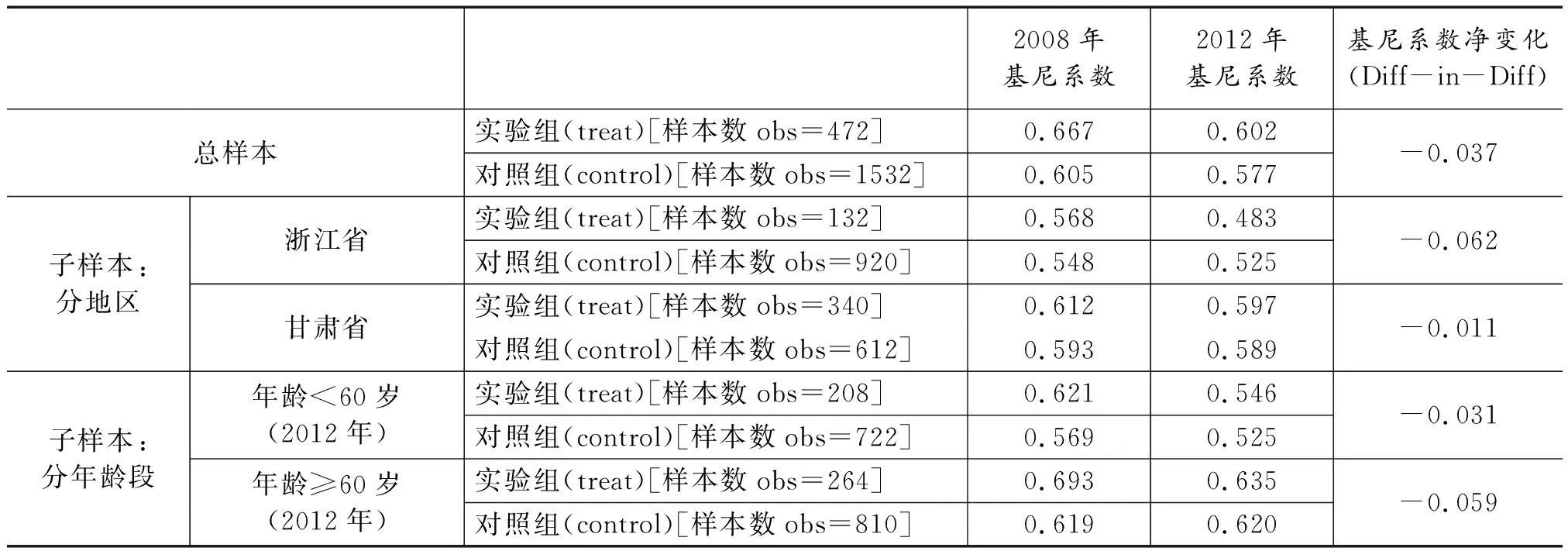
表3 2008年和2012年农村基尼系数
双重差分模型(DID)的实质是使用实验组干预前后结果变量的变化减去对照组干预前后结果变量的变化,得到干预的估计效果。本文通过对比参保前后实验组和对照组的基尼系数变化,直观地看到参加新农保带来的收入再分配效应。不过,参保组与未参保组在基础特征上可能存在差异,为保证所比较的两组具有可比性,下文将运用双重差分倾向得分匹配法(DID-PSM)进一步估计参加新农保带来的减贫及收入再分配效应。
(二)DID-PSM估计结果
表4中(1)列~(4)列展示了以家庭人均收入(取对数)为被解释变量,采用双重差分倾向得分匹配法估计的参加新农保对60岁及以上子样本和60岁以下子样本个体收入的影响。对比(1)列和(3)列的估计结果可以发现,参加新农保使60岁及以上老年群体收入上升33.1%,使60岁以下群体收入上升17.2%, 60岁及以上老年群体收入增长较60岁以下群体收入增长更多,但是该结果在统计上不显著。这也表明:新农保的实施在一定程度上产生减贫效应和正向代际收入分配效应,只是这些效应作用有限。
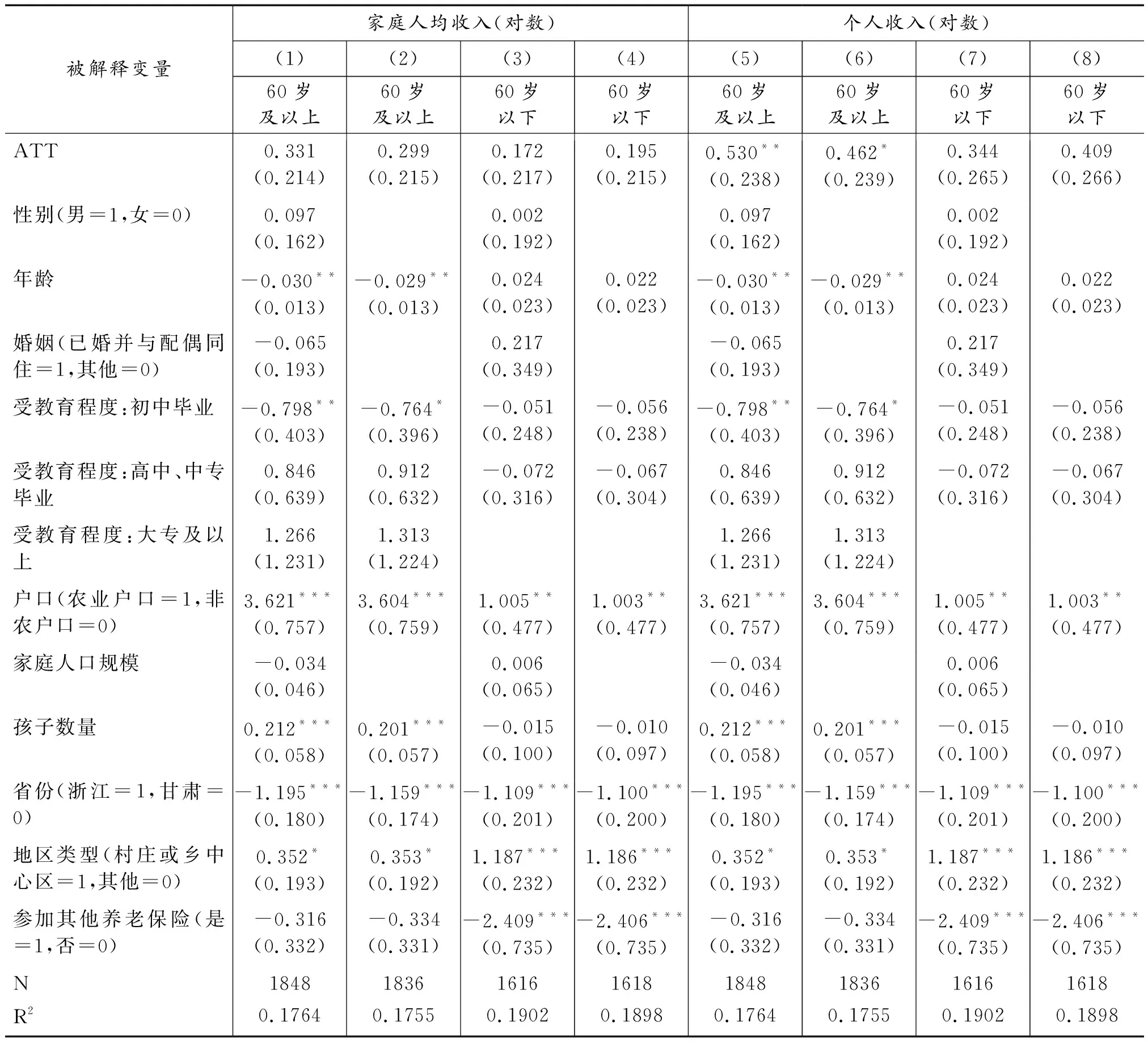
表4 分年龄子样本参加新农保对个体收入的影响:DID-PSM估计结果
进一步观察(2)列和(4)列的估计结果。相比(1)列和(3)列,(2)列和(4)列剔除了性别、婚姻、家庭人口规模三个协变量,参加新农保使60岁及以上群体收入上升29.9%,使60岁以下群体收入上升19.5%,但该结果在统计上也不显著。背后的含义和(1)列和(3)列的分析结果类似,新农保的实施在一定程度上产生减贫效应和正向代际收入分配效应,但这些效应并不明显。
表4中(5)列~(8)列展示了以个人收入(取对数)为被解释变量的估计结果。对比(5)列和(7)列的估计结果可以发现,参加新农保使60岁及以上老年群体收入显著上升53%,使60岁以下群体收入上升34.4%,不过后者在统计上不显著。这表明,新农保的实施使首要目标群体的收入显著提升,并在一定程度上使60岁以下群体的收入有所提升。这也从侧面反映出新农保的实施一定程度上带来正向的代际收入分配效应。相比(5)列和(7)列,(6)列和(8)列剔除了性别、婚姻、家庭人口规模三个协变量,结论基本保持稳定,参加新农保使60岁及以上老年群体的收入显著上升,但对60岁以下群体的收入的提升作用尚不明显。
综合来看,新农保的实施使60岁及以上老年群体收入显著上升,一定程度上产生减贫效应和正向代际收入分配效应。
为了保证 DID-PSM结果的有效性,本文检验了匹配前后各变量在参保组和对照组的分布是否变得更加平衡,协变量的均值在参保组和对照组之间是否有差异。检验结果发现,各变量在参保组和对照组的分布更加均衡,且协变量的均值也不存在差异。因而本文的估计方法是合适的。
比较DID和DID-PSM两部分的估计结果可以发现,尽管两种方法估计的结果在理解上有所不同,但是基本结论是一致的,即新农保的实施在一定程度上有减贫和收入再分配效应,本文的研究结论具有稳健性和可靠性。
五、结论
本文使用中国健康与养老追踪调查(CHARLS)数据库中2008年甘肃、浙江两省预调查数据和2012年甘肃、浙江两省追踪调查数据,采用双重差分法(DID)和双重差分倾向得分匹配法(DID-PSM)估计了新农保政策的减贫及再分配效应,结果均显示新农保在一定程度上有减贫、均等收入分配及缩小收入差距的效应。
采用双重差分法(DID)对比参保的实验组和未参保的对照组基尼系数的变化本文发现,无论从总样本来看,还是从分地区和分年龄的子样本看,新农保的实施都使基尼系数下降。其中,在浙江省参加新农保带来的收入再分配效应远大于在甘肃省参保的效应,60岁及以上老年群体参加新农保相比60岁以下的群体收入差距下降的更多。采用双重差分倾向得分匹配法(DID-PSM)进一步研究发现,新农保的实施起到了缓解农村老年贫困、改善收入分配的作用,但是作用效果还比较有限,原因主要在于新农保的保障水平较低。
因此,本研究提出如下建议:第一,逐步提高农村居民养老保障水平,充分、有效发挥农村养老保险的减贫及再分配效应。2014年新农保与城镇居民养老保险合并,城乡居民养老保险建立,但农村居民的养老保险缴费档次和养老金待遇水平仍远远低于城市居民。要缓解相对贫困、实现乡村振兴、促进城乡统筹发展,应巩固和提升农村养老保险制度的实施效果。一方面,要逐步提高农村居民养老金待遇,通过增加基础养老金等措施提升农村养老保障水平;另一方面,强化地方财政补贴与缴费档次挂钩的激励机制,鼓励农村居民多缴费。第二,实现完善农村养老保障政策与巩固脱贫攻坚成果的有效衔接。对于农村返贫人口、弱势群体等养老保险缴费困难群体,地方财政可根据其相对贫困程度,代缴部分或全部保费,以巩固脱贫攻坚兜底保障成果。
猜你喜欢
江苏安全生产(2022年9期)2022-11-02
今日农业(2021年15期)2021-11-26
今日农业(2021年14期)2021-11-25
中国外汇(2019年7期)2019-07-13
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
中国证券期货(2017年3期)2017-03-30
中国证券期货(2017年3期)2017-03-30
中国卫生(2014年7期)2014-01-22
中国卫生(2014年12期)2014-01-22
