
智能化作战任务规划需求分析
2021-08-26 09:09马悦,吴琳,许霄,刘昀
指挥控制与仿真 2021年4期
马 悦,吴 琳,许 霄,刘 昀
(1.国防大学,北京 100091;2.中国人民解放军31002部队,北京 100091)
现代战争对指挥决策的精度、速度和强度提出了更高的需求,而指挥员及参谋机构在脑力、体力和反应力方面难以承担重任。作战任务规划采用科学方法和计算机工具,为实现科学化和精确化作战指挥提供了有效途径。近年来,人工智能技术不断实现群体性突破,为实现作战任务规划注入了新鲜血液。尤其是诸多智能博弈系统在边界和规则确定的游戏对抗中取得了显著成绩,不仅极大地推动了认知智能发展,更为军事决策智能指明了探索方向。例如,Deep Mind相继推出围棋Alpha Go系列AI系统,成功解决了有限状态零和完全信息两人博弈问题[1-3];美国卡耐基梅隆大学开发了Libratus系统[4]和Pluribus系统[5],突破了多人游戏智能博弈的壁垒。继围棋、德州扑克等序贯博弈之后,以实时策略游戏为代表的同步博弈问题成为研究热点,Deep Mind在2019年公布的Alpha Star[6],对开发具有安全性、鲁棒性和实用性的通用AI系统具有重要意义。
本文通过梳理作战任务规划的基本概念、关键内容和研究现状,分析了现有模型方法在满足军事需求和应对战争复杂性方面存在的局限性,提出了利用智能方法辅助作战任务规划的必要性,并基于分层决策、知识引导和效果作战等理论构建了智能规划框架,为如何提高复杂战场环境下作战任务规划的全局优化能力和泛化适应能力提供借鉴。
1 作战任务规划的概念及内容
作战任务规划(Operation Task Planning)是在作战资源和作战规则等诸多约束条件下,以实现作战意图为目的,运用科学规划方法和计算机工具对作战行动进程、作战任务安排、力量资源使用和部队协同行动等进行筹划设计的过程[7-11]。如图1所示,战前的作战任务规划用于辅助生成作战方案计划,指导部队执行作战任务;战时的作战任务规划与指挥控制密切关联,辅助方案计划的动态调整或重新生成,以应对种种不确定性因素。
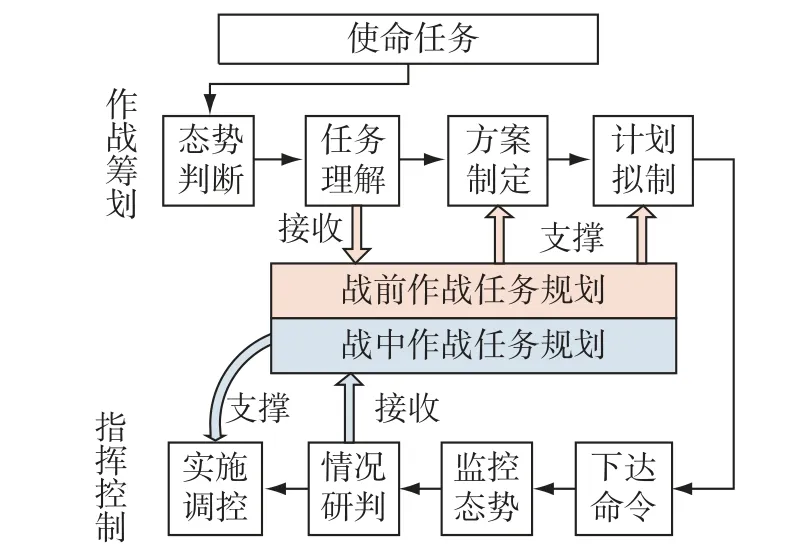
图1 作战任务规划的作用
作战任务规划对上接收作战意图和作战构想,对下为所属力量规划目标和行动,其内容及边界如图2所示,主要包括:1)明确作战任务,通过分析确定需要执行的作战任务及相应的协同保障事宜,形成作战任务清单;2)生成任务序列,充分认识作战过程中可能遭遇的种种情况,设计作战行动或作战任务流程,为力量资源分配和部队协同动作提供依据;3)合理分配资源,实现作战任务与作战资源的动态映射,主要解决资源转移、资源冲突和效益最大化等问题;4)协调作战行动,在明确作战任务及其执行单元、所需资源、完成时间和空间位置后,通过协调作战行动,使各种作战力量相互配合、优势互补、效果衔接,从而形成有机整体。

图2 作战任务规划的内容及边界
2 作战任务规划的智能化需求
作战任务规划是一个迭代优化的过程,传统方法难以同时满足任务规划的长程性、对抗性、适应性和成长性需求,战争的高度复杂性增大了规划难度。因此,迫切需要采用智能化手段来解决重难点问题。
2.1 传统方法的局限性
作战任务规划相关研究主要分为两方面,如图3所示。一是规划模型研究,包括数学解析模型[12-13]、概率网络模型[14-16]、分层网络模型[17-19]、资源调度模型[20]、动态决策模型[21-22]和多智能体模型[23-24];二是求解方法研究,包括空间搜索方法[25-27]、遗传进化方法(如遗传算法、差分进化算法等)[28-31]、仿生物学方法(如蚁群算法、粒子群算法等)[32-36]、市场机制方法(如合同网协议、拍卖法等)[37-39]、智能规划方法(如基于有限状态机规划、基于分层任务网络规划和基于行为树规划等)[40-41]和深度强化学习[6]。
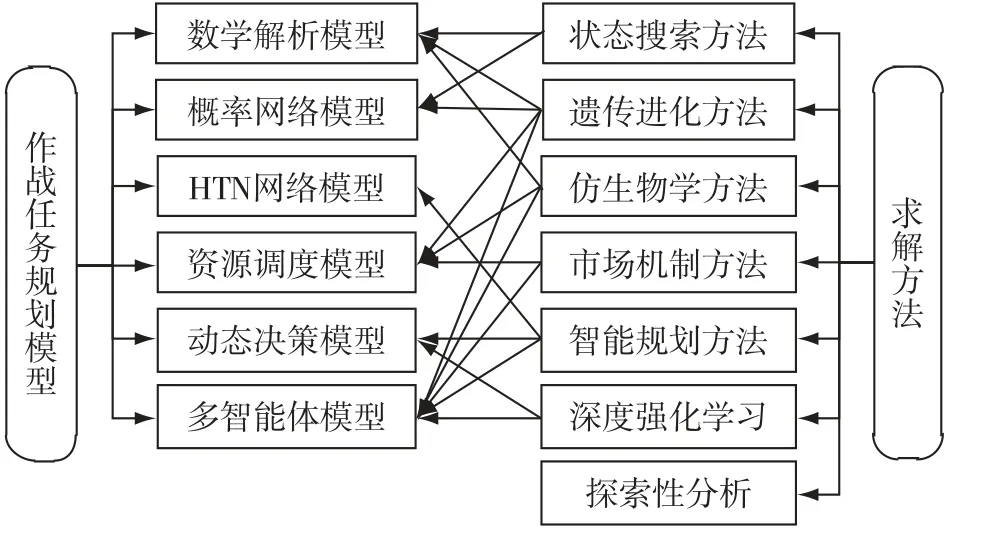
图3 模型构建与求解方法
上述研究虽各有成功案例,但均存在一定缺陷:
1)模型对问题描述不够全面。如数学解析模型只适用于静态的宏观或微观问题;概率网络模型侧重于描述作战行动之间的因果关系;层次网络模型侧重于描述任务之间的层次关系;资源调度模型侧重于描述作战任务与作战力量及资源之间的匹配关系,常被嵌入其他模型使用;而智能规划模型侧重于动作的选择与寻优,缺乏对长期利益的考虑。
2)模型构建的复杂性较高。如概率网络中存在大量条件概率需要人工定义,模型构造难度大,问题求解效率低;层次网络模型构建质量决定了智能规划的好坏,且难以在动态复杂问题中表现出智能;有限状态机和行为树对知识依赖性高,模型构造和维护的难度随问题规模增大呈指数级增长,难以满足敏捷开发的要求;合同网协议存在大量协同规则,需要相关领域专家和模型设计人员共同定义。
3)求解算法本身存在缺陷。如状态空间搜索方法,当采用深度优先时可能无法求解,而采用广度优先时,搜索空间将呈指数级增长;进化算法存在收敛过早、迭代时间长、求解精度不高等缺陷,算法参数较为复杂且初始值对最终解的影响较大;蚁群算法的参数敏感性高、解的多样性和准确性之间存在矛盾、容易陷入局部最优或发生搜索停滞;粒子群算法全局搜索能力弱、可信度低且需较高的时间复杂度才能得到较优解;市场机制法在全局寻优过程中,当协商通信量较大时,由于协调机制有效性低,容易导致整体利益与个体利益产生冲突;智能规划大多用于产生反应式行为,无法展现复杂态势下符合人类认知机理的高级决策智能行为。
2.2 作战任务规划难点
战争是交战双方的动态博弈,时刻受诸多不确定性因素的影响。作战任务规划要在“知己知彼”的基础上,始终围绕军事使命展开任务流程、资源使用和行动协同的筹划设计,并能根据战局发展进行调整。而当前规划模型和求解方法的研究成果还难以满足军事应用需求,作战任务规划需要着重把握以下要点。
1)实现动态对抗条件下的有效规划
在动态对抗条件下,战争中的诸多不确定性因素随之而来,战场信息的不完全/不完美、敌方威胁评估和意图识别的模糊性等时刻存在。目前,大多数研究通常仅从自身任务完成效果、时间限制、效益最大化等角度来构建作战任务规划的最优化问题,将对手视为静态的、非智能的被动防御目标,忽略了动态博弈的本质特征——作战双方的策略高度关联、相互制约,从而导致方案计划在现实条件下失效。因此,必须贴近军事对抗博弈实际,基于双方作战模式考虑敌方作战意图及行动对完成任务造成的威胁,探索在动态对抗中研究作战任务规划的新方法,更加有效地实现作战力量的聚合与解聚。
2)实现面向战役使命的全局优化
战役级作战任务规划的决策周期长、动作空间大、态势复杂多变,极易导致规划结果局部最优和泛化能力弱等问题。针对作战任务与作战效果之间的关系,当前研究或是采用Petri网、贝叶斯网以及影响网等概率网络方法生成详细的战前作战方案计划,或是基于智能规划方法进行反应式规划。两种方式都难以满足实际作战对“瞄准目标、灵活指导”的需求。首先,由于战争系统复杂性和小概率意外事件不可“穷举”,导致难以生成详细精确的作战方案计划[42];其次,战前周密的任务规划虽然能在直观上细化每个阶段的作战行动,但无疑增加了未来不适应性的风险,各种不确定性因素将导致其失效,从而增加了调整甚至重新规划的开销,同时也容易禁锢指挥员的思维;第三,反应式规划难以满足作战指挥对战争设计、指挥艺术性和长程规划的要求,我们期望兵棋系统中的“智能指挥员”能像Alpha Go一般,面对复杂变化的“棋盘”,可以预测往后每一步“落子”产生的效果,从而能够面向更全局、更长久的目标进行筹划,体现各领域各层级的协同性以及指挥员的指挥艺术性。
3)提高应对不确定性因素的适应能力
针对不确定性因素问题,当前研究可分为预测式和反应式两种方案。预测式方法旨在增加作战任务序列的鲁棒性,以实现对影响因素的不敏感。但是,预测式方法中冗余的判断条件和作战行动会带来过大的执行代价;鲁棒性优化是在一定约束条件下增大行动方案完成预期目标的概率,而非更加有效地完成使命任务,这与实现长程规划不相符。反应式方法旨在持续保持对战场态势和意外事件的监控识别,以实现方案计划的实时动态调整,相对鲁棒性优化而言,该方法执行成本小、实施灵活。然而,反应式方法不符合实际作战要求,作战任务规划主要用于为部队执行任务提供参照标准,确保任务部队有充足的时间进行准备,频繁调整将导致部队疲于奔命,陷入被敌人“牵着鼻子走”的困境。因此,作战任务规划的适应性既不是反应式规划也不是鲁棒性优化,而是根据战场态势感知、敌方意图识别和威胁评估的动态监控情况,对基线方案进行调整,响应意外情况并确保战局发展朝向既定战役目标。
2.3 智能方法需求
现有模型方法的局限性、联合作战的军事需求以及战争的复杂性,对采用智能化手段辅助作战任务规划提出了迫切需求。
1)战争充满迷雾和不确定性,迫切需要采用智能化手段认知战场态势、推测敌方意图和记忆敌方策略。由于预警范围和侦察注意力受限,只能从战场环境中获取部分信息,敌方行动策略和作战企图无法完全知晓。战争信息的高度不确定性,导致基于先验知识推理未知领域的方式难以奏效;信息的缺失导致以求解局部最优来获取全局最优的方式无法完成策略回溯。指挥员需要在一个非完全信息环境下进行决策,必须具备高效准确的侦察、探索、记忆和推测能力。
2)军事博弈对抗持续、激烈且非零和,迫切需要采用智能化方法构建动态决策模型、迭代更新方案计划和优化多目标作战评估体系。战争节奏紧张,局势变幻莫测,虽然可将动态连续决策过程离散为更精细的时间片段,然后采用轮次博弈的静态解决方法,但以离散方式进行抽象建模,必然需要解决时间尺度、模型精度和求解复杂度之间的矛盾。作战指挥不仅要考虑作战目的和战场态势,还要持续判断敌方企图和战法,反复迭代更新方案计划,巧妙利用佯装行动诱骗敌方,以掌握战争主动权。军事博弈的多方参与和政治、经济、军事及外交利益的平衡,导致难以依靠单一指标的价值网络,来评价这种模糊、复杂、稀疏及非零和的博弈收益。
3)作战指挥的决策空间大,难以依靠遍历求解或模拟仿真等方法进行求解,需要采用智能化方法降低决策空间维度和寻找策略均衡解。指挥员的每次决策都会涉及任务类型、执行单位、执行空间和时间的选择,不同作战单位和作战行动之间的时间协同、效果协同和任务协同进一步增大了策略空间。此外,多方博弈增大了达成纳什均衡的难度,多军兵种参战增加了协同难度,策略之间相互克制和历史遗忘特性明显。而战争规则的多样性、创新性和复杂性,进一步增大了状态策略空间的规模和纳什均衡的求解难度。
4)联合作战具有大空间作战和多领域融合的特性,迫切需要采用智能化方法解决指挥决策在时间、空间和事件上的推理问题。现代作战方式已从传统的由外及内逐层消灭敌人的线性作战,转变为集中全域力量进行全纵深整体打击的非线性作战。战争中事件因果关系错综复杂,通常难以在短时间内呈现,作战方案计划的制定要重点研究作战行动与作战效果之间的非线性关系。策略学习应具有记忆功能,以判断什么样的行动产生了好的效果、什么样的策略更具有获胜的可能性,从而在不断对抗中实现成长。
3 作战任务智能规划框架
3.1 理论依据
1)模拟人类思维进行分层决策
战争的非透明性和不确定性,使得作战指挥过程极其复杂,模拟人类思维流程进行分层决策和多尺度规划,将复杂问题分解为若干子问题,从而降低求解难度。上层策略为下层规划目标,而下层策略执行支撑上层规划,如高层策略关注战役全局问题、底层策略聚焦短期利益、即时策略控制当前反应式动作。
在当前技术条件下,完全依赖机器存在可解释性差、输出不可控等问题,分层决策框架下实现人机融合决策是提高决策合理性和适用性的有效方法。智能机器能够提高决策速度,而以人类战法思想牵引机器智能的策略生成,能够适应不同想定和不同应用场景。人机融合决策有两种实现形式。一是分层融合,低层决策采用传统运筹学、贝叶斯网络、机器学习等方法;中间层级决策采用不同程度的人机协作决策,重点研究人机协作的时机、场合和方式等;而高层级指挥决策需要由指挥员及参谋机构完成。二是分时机融合,指挥决策是一个滚动迭代、不断优化的过程。人与机器在各环节都有擅长与不足之处,如机器善于快速运筹计算和基于数据挖掘关联关系,人善于基于因果关系进行非即时反馈决策。
2)基于知识规则提高决策效率和质量
人类在解决问题时更倾向于遵循成熟规则。当前,机器还难以模仿人类大脑的复杂学习能力,智能博弈水平需要漫长的成长过程。充分利用军事领域专家的经验知识和兵棋系统对抗演习的历史数据,可以避免让机器从零学习而进行过长时间的探索,同时也对决策过程有更好的解释。
传统基于知识的专家系统,利用人类经验和专家知识,便可解决各领域的复杂问题。在深度学习盛行之后,基于知识规则的智能技术依旧取得了不凡的成绩。例如,东京大学日麻AI系统利用9.6万多条规则进行监督学习,达到了专业六段水平[43];韩国三星的赛达(SDS AI Data Analysis,SAIDA)系统完全凭借职业玩家规则知识,在2018年第八届星际争霸智能挑战赛中获得第一[44]。即便融合了深层神经网络的AlphaGo和Alpha Star,依然需要在预训练中使用大量人类对局数据进行模仿学习。虽然Alpha Zero和Muzero能够完全通过自主学习实现成长[45],但围棋游戏与战争对抗存在天壤之别,难以直接应用于军事领域。当前强化学习还难以实现从基本策略中总结出高层策略,现有的条令条例、作战规则等大量知识可转化为知识网络以引导AI系统。
3)面向使命任务的基于效果作战
战役所期望达到的作战效果,就是战役所确立的终止态势,可描述为一组态势指标。指挥员在下达作战任务时,既要考虑能否应对当前敌方威胁,又要考虑能否为完成最终作战使命提供较大贡献。因此,需要综合分析我方行动、敌方威胁和作战效果之间的影响关系,以确保作战任务规划能够促成期望态势。
基于效果作战研究“从效果到任务以及任务对效果的支持”,实际是基于目标分解的逆向规划,将目标分解为具体预期的效果,不仅体现了作战的非线性,而且能够表达作战的不确定性。目前,大多数文献主要采用贝叶斯网络、影响网、影响图等技术开展研究,虽然能够形式化地描述作战任务与作战效果之间的不确定影响关系,但是一般只关注作战任务或作战行动的即时作战效果及实现概率,而对长远作战效益的讨论较少。这相当于将整个作战计划机械地割裂为若干阶段,通过简单叠加各阶段的最优来寻求全局最优。近年来,基于效果作战的理论产生很大争议,反对者认为战争充满了不确定性,要准确预测某一行动的效果在逻辑上是不可能的,忽视了战争系统的不可预测性。但是,美军《Joint Publication 5-0:Joint Planning》[46]将“作战效果”作为作战行动方案(Course of Action,COA)生成链中的5大要素之一,从而将COA的生成过程统一成一个逻辑整体,每一作战阶段都需要确定对上一作战阶段的支撑效果,以及对最终战役目的的支持程度,正是体现了长期与短期收益、全局与局部收益的权衡。
4)任务式指挥提高决策的灵活性和适应性
任务式指挥是集中指挥与分散指挥的结合。集中指挥体现在将指挥信息、行动指向和作战效果集中在统一意图上,指挥官的精力不再受任务执行细节的牵扯,而聚焦于统筹全局和把握作战关键环节;分散指挥体现在作战力量分散部署、作战决策分散实施和作战过程分散控制,各级部队在一定权限内充分发挥主动性来自主行动[47]。任务式指挥为实现决策智能提供了很好的借鉴。首先,智能决策的本质在于进行权衡和选择,而不是拟制周密的方案计划,作战任务规划是一个贯穿作战始终的螺旋升级优化的过程。战争中态势瞬息万变,预测中的小概率“灰犀牛”事件和不知缘由的“黑天鹅”事件往往成为突发意外,各种不确定性因素将导致战前周密计划不适用。其次,智能决策的核心是科学分析和任务协调,而不是实时进行临机规划或频繁进行重规划,作战任务规划的适应性是围绕基线预案在战役目标保持不变的情况下对所有子任务进行联动协调。根据复杂系统理论,涌现可以在局部感知计算、多智能体非线性交互等简单条件下产生,从而实现灵活性、非机械性和创造性。因此,作战任务智能规划可采取以下基本思路:通过战前规划形成基线预案,粗粒度的基线预案为动态调整设置了方向和限制,战时根据实时态势对作战任务进行联动的协调控制。
3.2 智能框架设计
本文对文献[42]中提出的“局部优化+全局平衡+控制调度”智能决策思路进行拓展,引入领域知识进行引导,将自顶向下的规划和自底向上的决策相结合,构建“知识引导+全局平衡+协调控制+局部优化”的作战任务智能规划框架,如图4所示。智能规划框架旨在通过“集中规划和分布决策”的方式,提高作战任务规划的全局优化能力和泛化适应能力,满足在动态对抗条件下的有效性和复杂环境中应对不确定性因素的适用性。

图4 作战任务智能规划框架
知识引导主要完成领域知识的形式化描述和作战任务的智能推荐,为作战任务规划提供支撑。利用军事领域知识和演习历史数据构建事理图谱,而后基于事理图谱设计智能推荐算法,实现针对敌方行动意图和任务执行效果遇阻的作战任务推荐。实际是为作战任务序列的不确定性推理进行策略空间约简,为后续研究作战任务与作战效果关系降低复杂度。
全局平衡,主要完成作战任务序列规划,为作战任务分布式执行提供基线方案,规范方案动态调整的范围,确保战局始终朝向终止态势。模仿指挥员观察、判断、决策和执行的思维过程,以战役作战任务为规划对象,将作战任务规划过程转换为马尔科夫决策过程,采用静态策略求解算法,得到最优“动作”序列。这种“集中式规划基线方案,而后交由下层任务智能体执行”的思路,模拟了“任务式指挥”的军事思想。
协调控制主要完成对作战任务落地执行的协调控制,通过作战任务在时间、空间、力量配属和效果上的协同,完成基线方案规定的作战任务安排。作战任务协调是衔接作战任务序列与作战任务执行的关键,通过上层规划引导下层智能体的非线性交互实现智能涌现。下层任务智能体接收上层指定的任务后,通过分布式协作决定“在何时(When)于哪里(Where)如何(How)协同完成,并确定具体执行单元(Who)”。在实时战场态势下,多智能体通过协商机制来确定任务执行的“作战单位、时间、位置和资源”,从而实现任务协同、目标协同和行动协同。智能的涌现,正是体现在多任务智能体在不同战场态势和威胁情况下的“动作”协同上,而这里的“动作空间”是<单位,时间,位置,资源>的联合空间。
局部优化主要基于智能体理论构建任务智能体,将战术层作战行动映射为任务智能体可执行动作,采用经典运筹学方法优化底层动作策略。任务智能体的构建,一方面能够保证作战任务序列方案落地为具体动作,另一方面能够简化高层策略寻优的“动作”和“状态”空间,从而将智能决策重点聚焦于战役层作战任务序列规划和作战行动协调控制策略的优化。
学习机制主要通过深度强化学习不断优化策略。学习主要体现在三方面:一是通过学习优化“威胁-任务”的因果关系,从而实现作战任务推荐;二是通过学习确定作战任务之间的转移概率;三是通过学习提升多智能体协同策略的泛化性。强化学习通过“试错”进行反复训练和学习,理论上可以不依赖于任何知识。深度学习具有强大的非线性表示能力,利用多层神经网络能够从海量数据中逐层抽象特征、学习经验知识。深度学习与强化学习结合后,深度学习提供了学习基准,保证了前期策略探索在有监督下进行,强化学习在训练过程中根据奖惩不断提升策略水平,实现了高效的策略优化。
4 结束语
本文讨论了作战任务规划的基本概念、主要内容及边界,分析了传统方法的局限性和智能化需求,详细阐述了相关理论基础,并依此构建了智能规划框架。虽然当前机器还难以模仿人类大脑的复杂学习能力,智能水平需要漫长的成长过程。但是,通过经验知识引导减少搜索空间,模拟人类思维分层决策降低问题难度,基于效果分析提高全局优化能力,利用多智能体协作实现智能涌现,可为实现智能化作战任务规划提供借鉴及参考。
猜你喜欢
建材发展导向(2022年2期)2022-03-08
房地产导刊(2021年6期)2021-07-22
文苑(2018年23期)2018-12-14
决策(2018年8期)2018-12-10
决策(2018年11期)2018-11-28
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
文苑(2018年21期)2018-11-09
决策(2018年10期)2018-11-07
领导决策信息(2018年16期)2018-09-27
