
基于BERT的混合神经网络实体识别方法
2021-08-27 06:38王卫红吕红燕曹玉辉
计算机技术与发展 2021年8期
王卫红,吕红燕,曹玉辉,霍 峥
(河北经贸大学 信息技术学院,河北 石家庄 050061)
0 引 言
随着社会信息化进程的飞速发展,信息呈爆炸式增长,各类数据海量存在,其中文本数据也不例外。而文本数据中常常包含了大量有价值的信息,尤其是文本中的实体是句子的主体,包含了丰富的语义信息,因此命名实体识别任务在文本数据的理解与处理过程中具有非常重要的意义。除此之外,命名实体识别是信息抽取中的基础任务,而信息抽取是知识图谱构建中的重要步骤。近几年来,知识图谱的发展使得命名实体识别工作更为重要[1]。
命名实体识别[2]旨在识别出文本中的专有名词并将其划分到相应的实体类型中。其中常见的命名实体包括人名、地名、机构名等。命名实体技术从开始发展至今,可以将其分为三大阶段,基于词典和规则的方法、基于传统机器学习和基于深度学习的方法、现在热门的注意力机制和图神经网络等方法应用于命名实体识别中。命名实体识别技术发展得越来越成熟。早期的基于规则的命名实体识别方法主要是通过人工来构建规则库,再从文本中寻找匹配这些规则的字符串从而识别出文本中的命名实体。这种方法在特定的语料上可以获得较高的识别效果,但是不具有通用性,迁移能力较差,而且规则库的构建需要大量的人力,耗费时间长。
随着机器学习在自然语言处理领域的兴起,命名实体识别的研究逐渐转向基于统计机器学习的方法,主要分为两种思路,一种是先识别出命名实体的边界,然后将命名实体进行分类,另一种是序列化标注方法[3-4]。序列化标注方法是目前最为有效,也是最为普遍的一种命名实体识别方法。近年来,基于神经网络模型的深度学习技术不断发展,成为机器学习领域新的热潮。各类神经网络模型被用到命名实体识别的研究中。
文中提出的基于BERT模型的混合神经网络实体识别方法结合预训练语言模型的同时充分利用各类神经网络的优势,来获取句子、实体中更加丰富的语义信息,以提高命名实体识别的有效性和通用性。
1 相关研究
命名实体识别任务在1991年第一次被提出,之后在很多会议中将其作为评测任务,例如MUC-6、MUC-7、CoNLL-2002、CoNLLC-2003等会议。许多学者对命名实体识别任务进行研究。
近些年来,命名实体识别常常被看作是序列标注问题,在标注语料上进行监督学习。早期,经典机器学习分类模型被成功地用来进行命名实体的序列化标注,而且获得了较好的效果,如条件随机场CRF[5]、最大熵ME[6]和最大熵马尔可夫模型MEMM[7]等。Collobert等学者[8]在2011年首次将神经网络应用于命名实体识别任务中,提出了基于神经网络的命名实体识别方法。此后,随着深度神经网络的发展,越来越多的学者将神经网络模型运用到命名实体识别任务中。GUL Khan Safi Qamas等[9]提出了一种基于深度神经网络、结合长短时记忆和注意力机制的命名实体识别方法,提高了命名实体识别的准确率。N. Bölücü等[10]将双向LSTM-CNN模型进行了扩展,添加了句法和词级特征,并通过实验证明了在不进行特征工程的情况下,改进后的模型优于基线模型。Peng N等[11]提出将LSTM与CRF相结合应用于命名实体识别任务中,并通过实验证明了该方法的有效性。X. Yang等[12]利用BiLSTM结合CRF来获取单词表示,将其用于生物医学领域的命名实体识别,并通过实验证明了该方法在生物医学领域的有效性。BiLSTM-CRF模型在很多领域的命名实体识别任务中都取得了不错的效果,因此,许多学者在该模型的基础上进行改进。例如,Q. Zhong等[13]在该模型的基础上加入了注意力机制,提高了命名实体识别任务的准确率。谢腾等[14]利用BERT模型生成基于上下文的词向量作为BiLSTM-CRF的输入进行中文实体识别并取得了较好的效果。赵平等[15]将BERT+BiLSTM+CRF(简称BBC)深度学习实体识别模型应用于旅游领域的文本,提高了旅游领域中实体识别的准确率。刘宇鹏等[16]针对中文命名实体识别提出了一种基于BiLSTM-CNN-CRF的方法,真正意义上的端到端的结构,自动获取基于字符级别和词语级别的表示,并在人民日报和医疗文本数据上进行了验证。此外,还有一些学者在神经网络模型基础上引入部首嵌入[17]、顺序遗忘编码[18]或者是笔画ELMo和多任务学习[19]等,实体识别效果均略有提升。
随着预训练语言模型的发展,越来越多的研究者将其用于命名实体识别的工作中,目前BERT模型[20]在各类自然语言处理任务中相较与其他预训练语言模型效果相对较好,而且应用较为广泛。M. Zhang等[21]在BiLSTM-CRF模型中加入了BERT模型用于中文临床文本中,取得了良好的效果。Fábio Akhtyamova L[22]将BERT应用到西班牙生物医学领域中的命名实体识别任务,并且取得了不错的效果。王子牛等[23]针对传统机器学习算法对中文实体识别准确率低等问题,提出了将BERT模型和神经网络方法结合进行命名实体识别,并通过实验证明了该方法提升了实体识别的准确率、召回率和F1值。李妮等[24]利用BERT模型获取句子中丰富的句法和语法信息,并针对其训练参数过多,训练时间过长的问题,提出了一种基于BERT-IDCNN-DRF的中文命名实体识别的方法,并在MSRA语料上证明了该方法优于Lattice-LSTM模型,且训练时间大幅度缩短。
综上所述,命名实体识别的现有研究中缺乏充分利用各类神经网络及预训练语言模型的优势来进行实体识别任务。
文中的组织结构:第2节介绍了基于BERT模型的混合神经网络实体识别方法的模型架构并对各层原理或者结构进行说明解释;第3节在两个数据集上进行实验,比较不同方法的准确率、召回率和F1值,证明文中方法在命名实体识别任务中的有效性和通用性;第4节对全文进行总结并提出下一步工作方向。
2 基于BERT模型的混合神经网络实体识别方法
2.1 模型架构
文中提出了基于BERT模型的混合神经网络实体识别方法,其模型架构为BERT+CNN+BiLSTM+Attention+CRF,如图1所示。
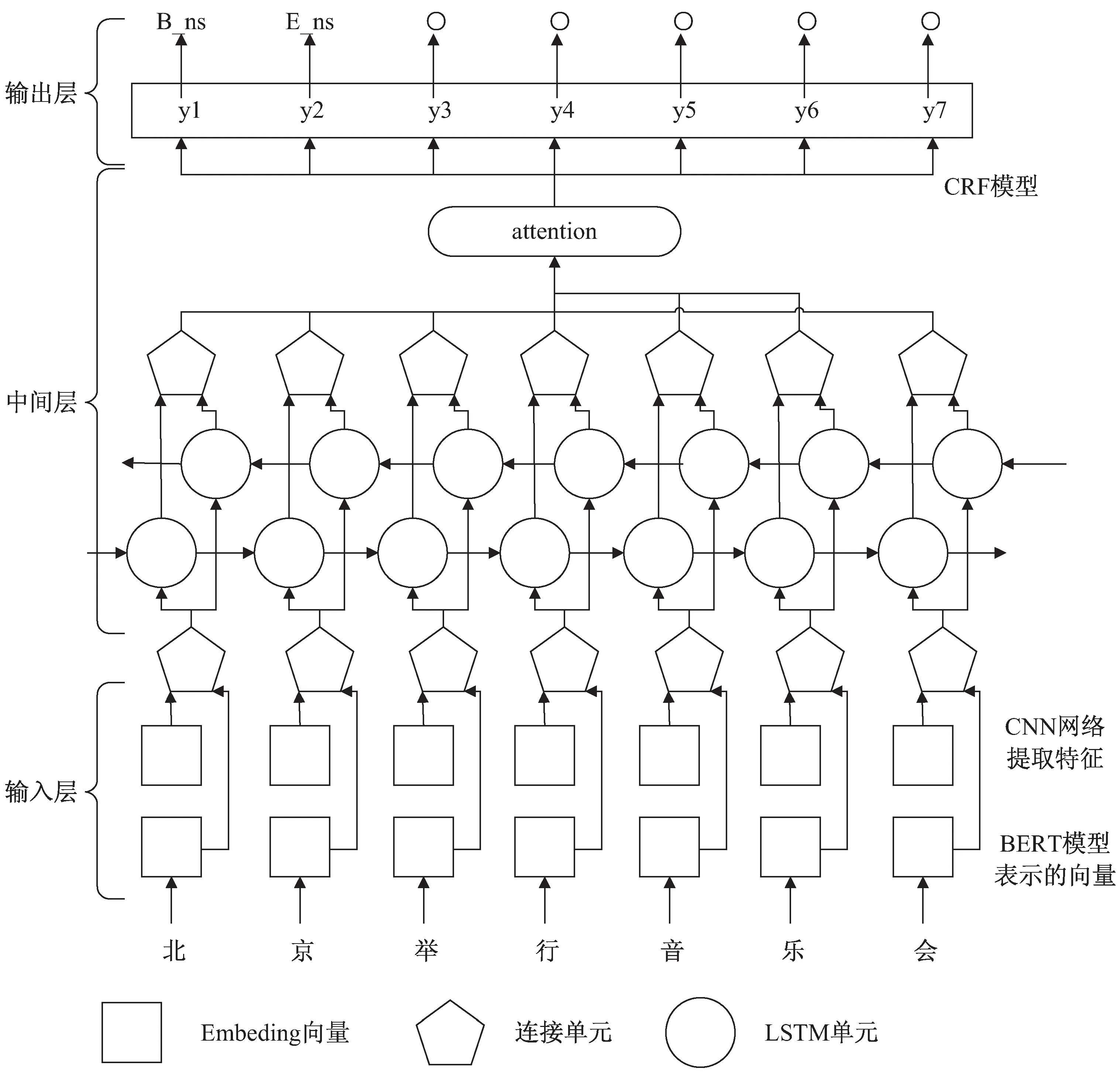
图1 模型架构
首先是输入层,由BERT模型和CNN神经网络模型构成,BERT模型训练基于字级别的字向量表示,CNN神经网络模型提取文本语义特征,将两者结合作为下一层的输入向量。然后是由带有注意力机制的BiLSTM模型组成的中间层。最后是输出层,使用的是CRF模型来解码序列标签,从而得到全局最优标注序列。
2.2 基于BERT模型的向量表示
基于BERT模型的向量表示能够表达句子丰富的句法和语法信息,在自然语言处理领域中有着十分广泛的应用。BERT模型是近几年来刚刚被提出与应用的,是预训练语言模型中表现较为突出的一个。BERT模型是综合GPT和ELOM两个模型各自的优势构造出来的,采用了双向Transformer进行编码,充分利用字两侧的文本信息,能够动态生成字级别和词级别的语义向量,具有很强的语义表征优势。BERT模型的本质是通过在海量的语料基础上运行自监督学习方法为单词学习一个好的特征表示,可以根据任务微调或者固定之后作为特征提取器。此外,BERT的源码和模型已经开源。BERT模型的网络结构如图2所示。由已有研究可知,BERT模型在命名实体识别任务中具有良好的表现。文中方法利用BERT预训练语言模型将文本训练为句子向量作为输入层的一部分。
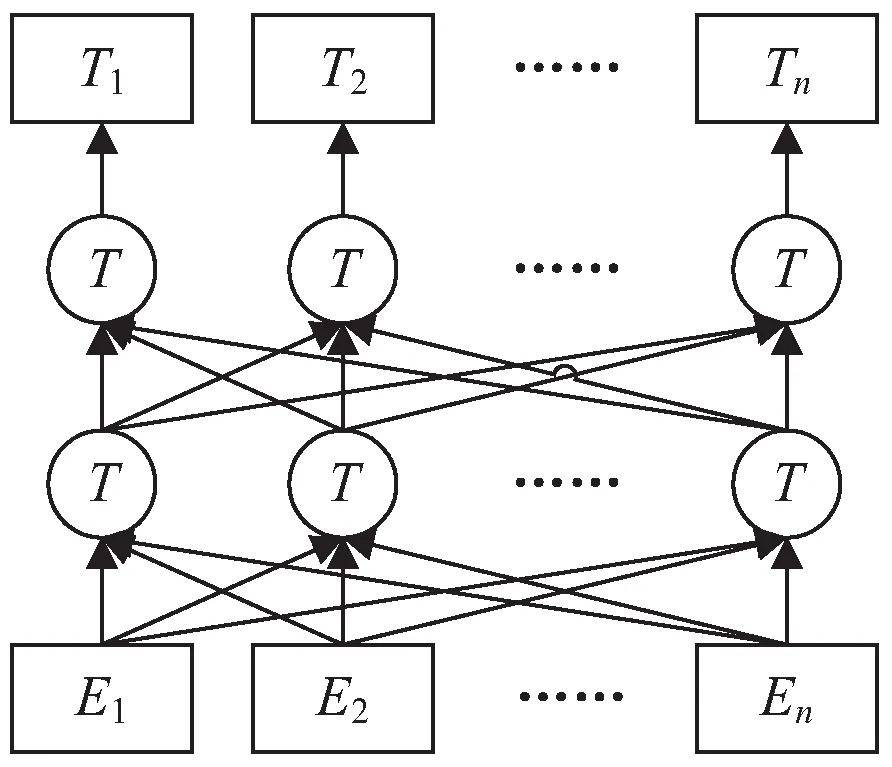
图2 BERT模型的网络结构
2.3 基于CNN网络的特征提取
CNN网络的主要特点是它强大的卷积层能够获取足够丰富的特征。经典的CNN最开始主要应用于图像分类中,并且在图像分类领域取得了较好的成果。如今,经过学者们的不断研究与探索,慢慢地将CNN应用于自然语言处理中,例如命名实体识别、文本分类和自动摘要等工作。CNN网络中的卷积层和池化层具有强大的特征提取和选择能力,能够防止过拟合,对特征进行降维。文中在卷积层中通过不同数量的过滤器和不同大小的卷积窗口进行卷积运算。池化层使用的是Max Pooling操作抽取出卷积层中最具有明显特征表征,从而得到基于CNN网络的文本特征向量,同样作为输入层的一部分。
2.4 基于注意力机制的BiLSTM网络
随着自然语言处理领域的不断进步和发展,LSTM神经网络模型应用于自然语言处理领域有较好的表现。与传统的RNN网络结构相比,LSTM增加了输入门、遗忘门和输出门三个门结构,能够更好地提取有用的信息。LSTM单元结构如图3所示。
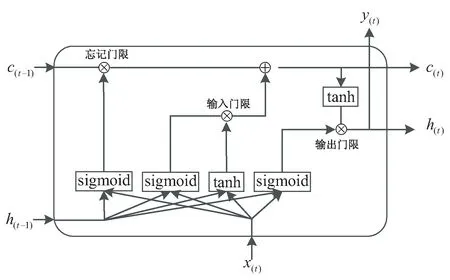
图3 LSTM单元结构
单向的LSTM只能获取一个方向的信息,但是在自然语言处理中充分利用上下文信息十分重要,双向LSTM网络,即BiLSTM应运而生。在命名实体识别任务中文本的上下文信息同样重要,因此,文中提出的基于BERT的混合神经网络实体识别方法中使用的便是BiLSTM网络模型结构。
注意力机制最开始被提出是应用于机器翻译问题中的,现在已经成为神经网络研究中的一个十分重要的研究领域。在神经网络结构中引入注意力机制能够自动学习权重用来捕捉编码器隐藏状态和解码器隐藏状态的相关性,从而提高神经网络模型的效果。注意力机制被广泛应用于各种不同类型的深度学习任务中,如自然语言处理、图像识别以及语音识别等任务。当然,在自然语言处理的子任务命名实体识别中,注意力机制的引入也同样会起到一定的效果。
文中实体识别方法的中间层使用的就是基于注意力机制的BiLSTM网络,将上述基于BERT模型的字符级向量和基于CNN网络提取的特征连接作为基于注意力机制的BiLSTM网络的输入向量。
2.5 基于CRF的输出层
基于CRF的输出层可以在最终的预测标签中添加一些约束,弥补BiLSTM无法处理相邻标签之间依赖关系的缺点,以确保最终的预测标签是有效的。这些约束可以由输出层的CRF在训练过程中从训练数据集自动学习。给定观察序列X时,某个特定标记序列Y的概率可定义为:
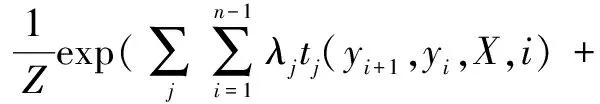
其中,tj(yi+1,yi,X,i)是定义在观测序列的两个相邻标记位置上的转移特征函数,刻画相邻标记变量之间的相关关系以及观测序列对它们的影响;Sk(yi,X,i)是定义在观测序列的标记位置i上的状态特征函数,刻画观测序列对标记变量的影响,λj和μk为参数,Z为规范化因子。
3 实验与结果分析
3.1 数据集和标注方法
文中实验数据使用的是1998年《人民日报》语料数据集和MSRA语料数据集两个公开数据集,《人民日报》语料数据集中共有19 484个句子、52 735个实体。MSRA语料数据集中共有28 100个句子、80 884个实体。对两个数据集中的人名(PER)、地名(LOC)和机构名(ORG)实体进行识别,其中训练集与测试集之比为8∶2。两个数据集信息如表1所示。
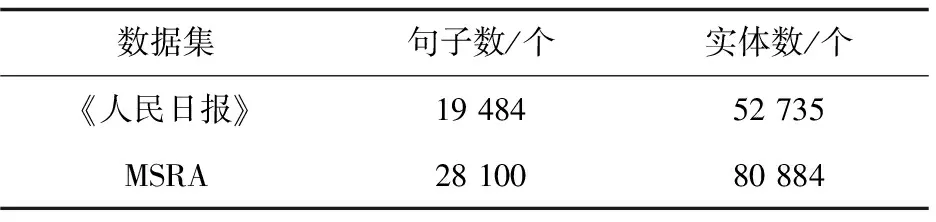
表1 数据集信息
常见的序列标注方法有很多种,例如Markup标注法、BIO标注法和BIEO标注法等。文中使用的标注方法是BIEO标注法,其标注字母代表含义如表2所示。

表2 BIEO标注法含义
3.2 参数设置和评价指标
文中使用的BERT预训练语言模型采用的是BERT-Base,相关参数设置如表3所示。
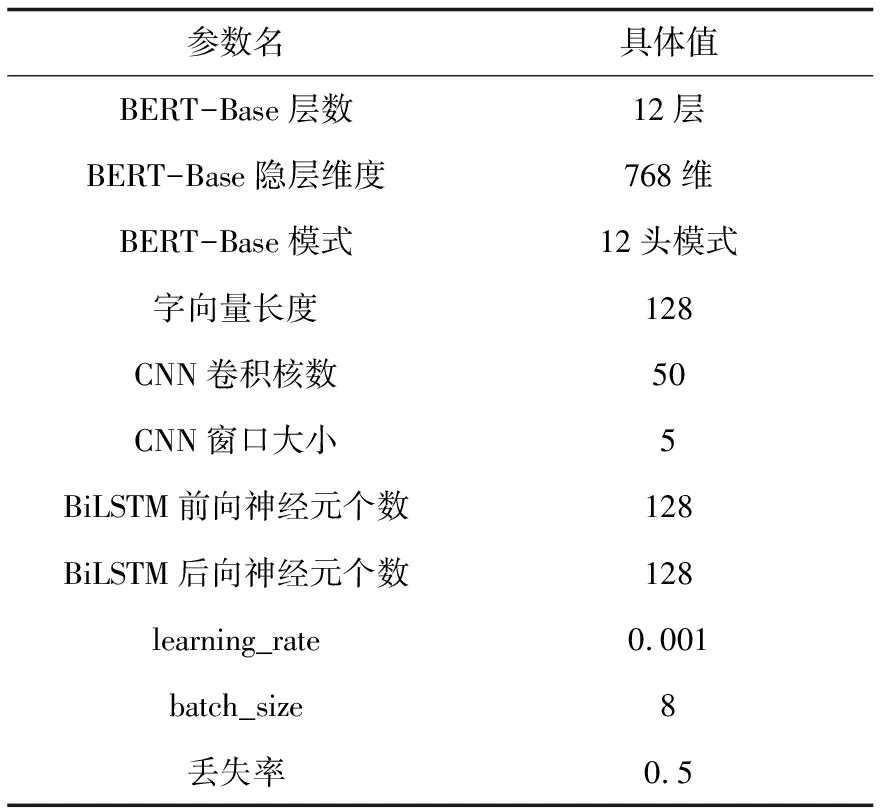
表3 相关参数设置
采用准确率(Precision,P)、召回率(Recall,R)和F1值(F1-score)三个指标来衡量实体识别模型的效果。三个评价指标的计算公式如下:
其中,RER表示正确识别出的实体数,AER表示实际识别出的实体数,AE表示实际实体总数。
3.3 实验结果分析
为了验证文中提出的基于BERT模型的混合神经网络实体识别方法的有效性,将该方法与BiLSTM-CRF、LSTM-CNNs和CNN-BiLSTM-CRF三种命名实体识别的方法在《人民日报》和MSRA两个数据集上进行了对比实验,比较四种命名实体识别方法的准确率、召回率和F1值。
首先为了确定合适的迭代次数,采用四种方法分别在两个数据集上进行了50次迭代,四种方法的F1值与迭代次数的关系如图4和图5所示。四种方法在两个数据集上均在20次迭代前后出现最高的F1值。此外,可以看出文中提出的基于BERT模型的混合神经网络实体识别方法在这两个数据集上的F1值均高于其他三种方法,具有良好的表现。
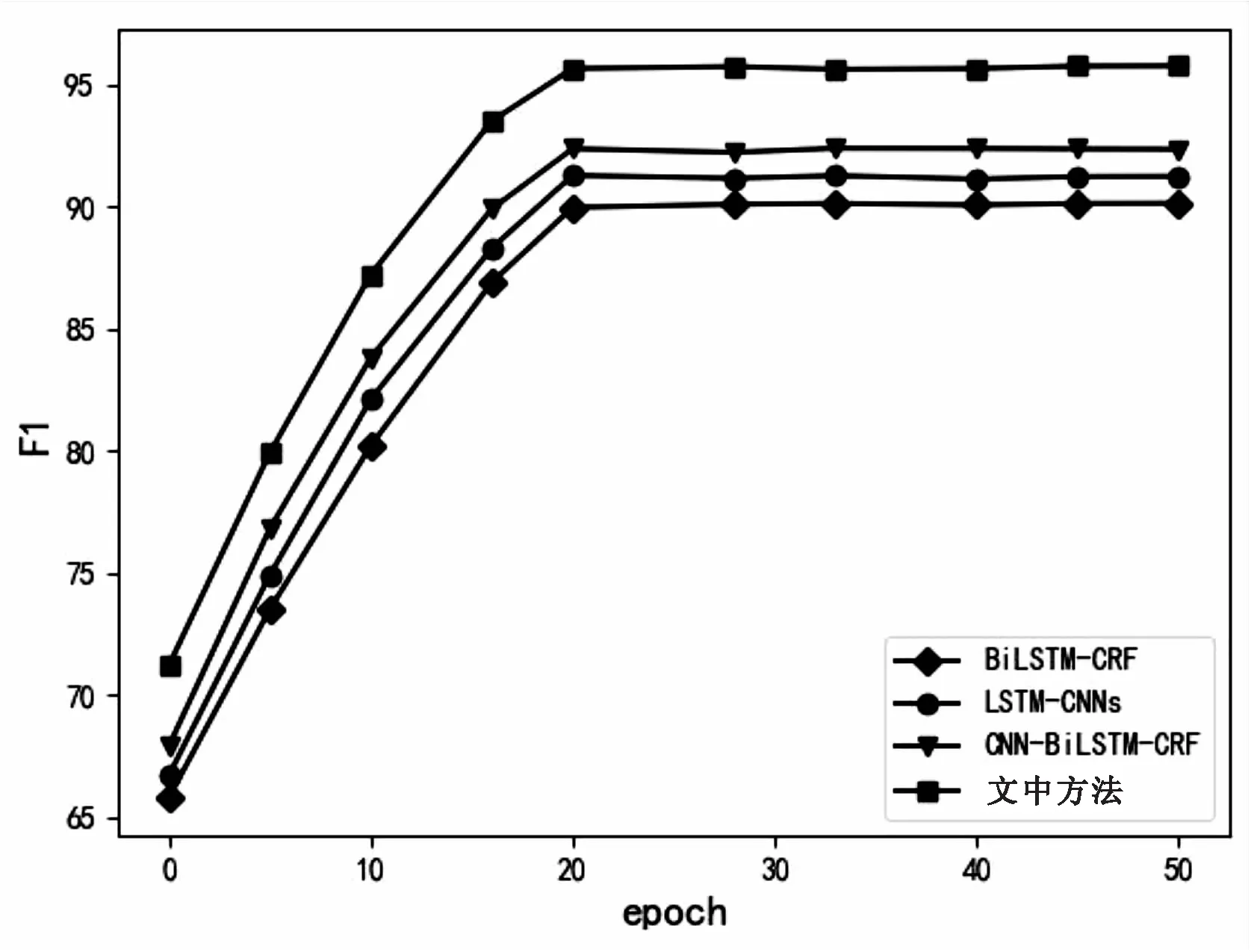
图4 《人民日报》语料数据集上F1与迭代次数关系
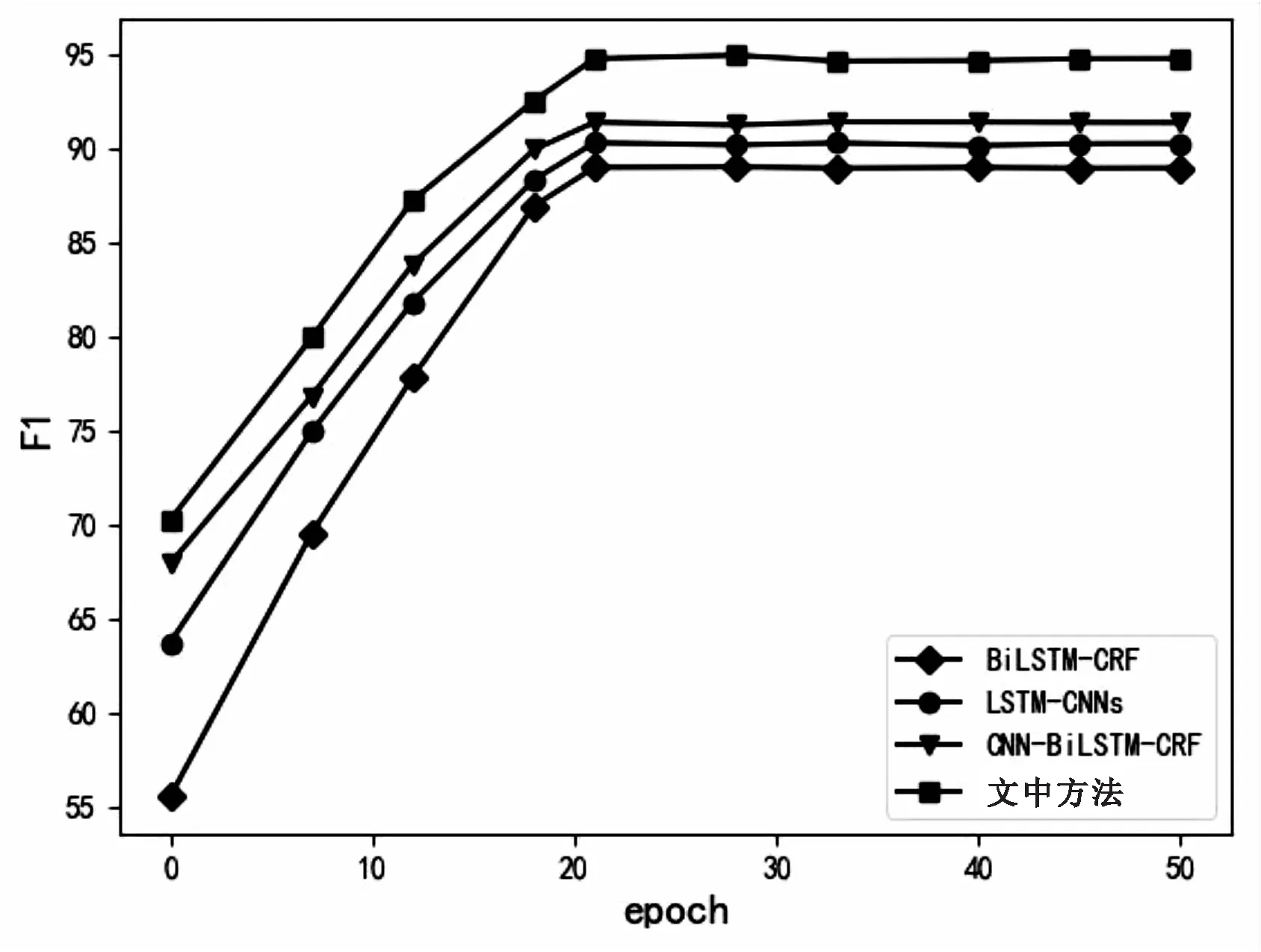
图5 MSRA语料数据集上F1与迭代次数关系
通过上述实验对比,将迭代次数设为23次,将四种方法在两个数据集上进行实验,对比其准确率、召回率和F1值,实验结果如表4和表5所示。
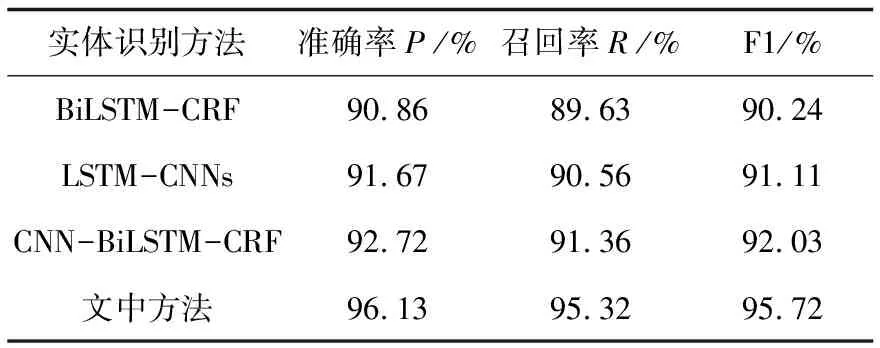
表4 《人民日报》语料数据集
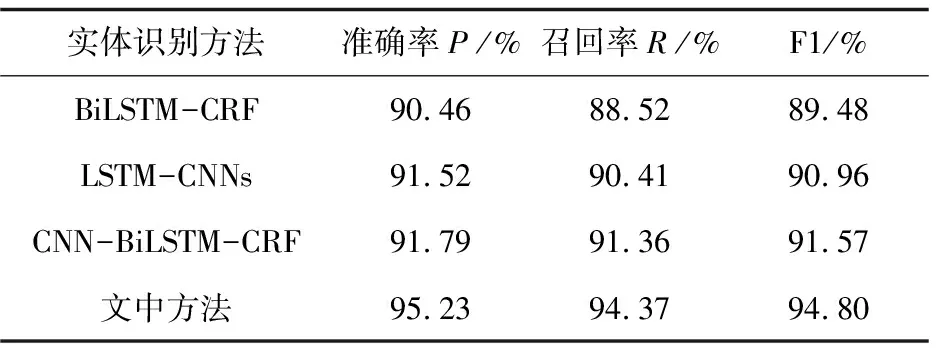
表5 MSRA语料数据集
从表4和表5可以看出,文中提出的基于BERT模型的混合神经网络实体识别方法在准确率、召回率和F1值上均优于其他三种方法。在《人民日报》语料数据集上,文中方法的F1值比BiLSTM-CRF方法高出大约5.5%,比LSTM-CNNs方法高出大约4.6%,比CNN-BiLSTM-CRF高出大约3.7%。在MSRA语料数据集上,文中方法的F1值比BiLSTM-CRF方法高出大约5.4%,比LSTM-CNNs方法高出大约4%,比CNN-BiLSTM-CRF高出大约3.2%。由此可见,文中提出的基于BERT模型的混合神经网络实体识别方法具有一定的有效性和通用性。
4 结束语
为了更好地解决命名实体识别方法中语义分析不足及准确率较低的问题,结合预训练语言模型和各类神经网络的优势及特点,提出一种基于BERT模型的混合神经网络实体识别方法。充分运用了BERT模型、CNN网络、注意力机制以及BiLSTM-CRF模型的优势,更加充分地提取文本的语义信息,丰富其文本特征,进行命名实体识别任务。最后分别在两个数据集上证明了提出方法的有效性和通用性。后续将进一步针对如何获取更多文本特征方面进行研究。
猜你喜欢
军事文摘(2022年18期)2022-10-14
现代计算机(2021年33期)2022-01-21
计算机研究与发展(2022年1期)2022-01-19
金桥(2021年5期)2021-07-28
华人时刊(2020年21期)2021-01-14
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
东方女性(2018年3期)2018-04-16
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
