
多层导电结构缺陷位置和尺寸的无损估计方法研究∗
2021-08-27 05:19莹金合丽陈友荣刘半藤任条娟
传感技术学报 2021年5期
周 莹金合丽陈友荣∗刘半藤任条娟
(1.浙江树人大学信息科技学院,浙江 杭州 310015;2.常州大学计算机与人工智能学院,江苏 常州 213164)
多层导电结构被广泛的使用在飞机、核电站、铁轨等制造中,是重要的工业制造材料。在长期使用过程中,多层导电结构可能会受到疲劳荷载、撞击和挤压等一些外力因素,导致其铆钉连接处出现裂纹缺陷,从而可能会影响多层导电结构使用的安全性,造成经济的损失,甚至对生命造成威胁。因此需要评估多层导电结构的使用安全性,即需要检测出裂纹的位置和定量分析裂纹,估计裂纹的尺寸,从而进行针对性的维护。目前,常用的多层导电结构电涡流无损检测技术包括脉冲涡流、常规电涡流、远场涡流等检测技术[1]。相较于常规电涡流、远场涡流等其他电涡流检测技术,脉冲涡流检测技术在频域具有更丰富的信息,并且能够有效降低趋肤效应和提离效应的影响[2-3]。因此可选择脉冲涡流检测技术对多层导电结构进行检测,获得和分析可以穿透多层导电结构的脉冲涡流信号,从而估计出缺陷位置和尺寸。
目前,国内外有部分学者侧重于研究基于脉冲涡流的多层导电结构缺陷检测方法,从而估计出缺陷位置,如文献[4]采用Rihaczek分布分析信号的频域特征,并结合时域特征,采用主成分分析提取特征确定多层导电结构中缺陷的分布;文献[5]采用主成分分析法对特征进行删选,再采用Fisher线性判别法区分第三层表面和亚表面的缺陷;文献[6]采用主成分分析法对特征进行删选,再采用支持向量机区分第一层和第二层的表面和次表面缺陷。但是目前文献[4-6]只针对单层、某一层或两层导电结构的表面或亚表面的缺陷位置进行研究,较少研究三层导电结构各层存在缺陷的情况。另一部分学者通过电涡流检测,估计多层导电结构中某一层的缺陷尺寸,如文献[7]利用不同的脉冲宽度的激励信号检测多层导电结构,并提取相应脉冲涡流检测信号的频率分量作为特征,说明该特征能够在一定程度上体现缺陷尺寸的变化情况。虽然该文献提取的特征能够反应出尺寸信息,但是没有具体对缺陷尺寸做出定量分析;文献[8]通过有限元方法对多层导电结构隐藏的腐蚀缺陷进行定量分析;文献[9]采用主成分分析和聚类算法对多层导电结构的第二层缺陷进行定量分析。但是文献[8-9]只对某一层存在的缺陷尺寸进行定量分析。此外文献[7-9]都没有综合考虑缺陷位置与尺寸的问题,因此另一小部分学者同时综合研究缺陷位置与尺寸估计问题,如文献[10]采用基于信息散度指数的投影追踪,提取信号特征用于对缺陷进行定位与定量。但是该文献采用信息散度指数的投影追踪对特征进行降维时,容易受到冗余、无效特征的影响,导致根据降维得到的新特征对缺陷进行定位与定量分析的效果较差。此外文献[4-6]和[9]提出的主成分分析法是一种无监督的特征提取方法,没有很好的利用特征的先验知识进行识别。
综上所示,针对目前学者较少涉及三层导电结构下的缺陷位置和尺寸分析、只对某一层存在的缺陷尺寸进行定量分析,降维算法效果较差等问题,因此提出一种多层导电结构缺陷位置和尺寸的无损估计方法(nondestructive estimation method of defect location and size for multilayer conductive structure,NEM)。NEM算法提取脉冲涡流检测信号的时域特征,利用傅里叶变换和希尔伯特黄变换分析脉冲涡流检测信号的频域和瞬时频域,并提取频域、瞬时频域等特征,最终共获得47个特征参数。提出基于AIC+Fisher的特征降维方法,寻找最优的特征降维维度,从而减少特征冗余,更好表征缺陷类型,提高分类器的识别精度和效率,最后利用支持向量机(SVM)构造分类器,采用粒子群算法对分类器模型参数进行寻优,从而提高训练速度和精度。最终对降维后的特征集进行训练,识别多层导电结构缺陷位置和尺寸。NEM算法可提高缺陷位置和尺寸识别的查准率和查全率,降低缺陷尺寸识别的误差。
1 理论方法
1.1 特征提取
脉冲涡流检测信号包含了被测试件的信息,不同的信号特征表征不同的被测试件的结构信息,若多层导电结构存在缺陷会导致磁感应强度变化,从而导致检测到的脉冲涡流检测信号会对缺陷有一定的反映,电压出现不同的波峰,因此从时域中分别提取峰值、峰值时间和过零点时间三个特征。如图1所示,其中,峰值是指激励信号的上升沿和下降沿同时检测到瞬态响应信号的最大电压幅值,过零点时间是指从激励信号的上升沿或下降沿开始到瞬态响应信号电压幅值降为零的时间间隔,峰值时间是指从激励信号的上升沿或下降沿开始到电压峰值的时间间隔。令脉冲涡流检测信号幅值函数为f(t),则峰值为max[f(t)],令到达峰值的时间点为tfmax,寻找tfmax之前最后一个令f(t)=0的时间点为t1,寻找到达tfmax之后第一个令f(t)=0的时间点为t2,则过零点时间=t2-t1,峰值时间=tfmax-t1。

图1 时域特征
此外脉冲涡流的激励信号有丰富频率成分,因此脉冲涡流检测信号频域包含大量反映多层导电结构试件信息的特征,因此采用傅里叶变换和希尔伯特黄变换对脉冲涡流检测信号的频域和瞬时频域进行分析,并提取频域、瞬时频域特征。即通过傅里叶变换将时域脉冲涡流检测信号变换为频域信号F(wh)。从F(wh)中分别提取能反映脉冲涡流渗透多层导电结构深度特征的当频率等于激励频率时的频谱幅值(基频分量)、当频率等于二到十二倍激励频率时的频谱幅值(二次到十二次的谐波分量)。

式中:F(wh)表示wh的频域信号,wh表示第h次谐波分量对应的频率值,ζ表示虚数。选择2.5 kHz,5 kHz,7.5 kHz,10 kHz,12.5 kHz,15 kHz,17.5 kHz,20 kHz,22.5 kHz,25 kHz,27.5 kHz,30 kHz的频率,共12个点。
利用希尔伯特黄变换分析信号的瞬时频域[11-12],首先采用经验模态分解方法将脉冲涡流检测信号分解成多个本征模态函数,采用式(2)对前四个本征模态函数进行希尔伯特变换后得到分别利用式(3)~式(6)计算前四个本征模态函数的瞬时幅度、瞬时相位、瞬时频率和边际谱,并提取本征模态函数均值、瞬时相位的方差、瞬时频率的方差、瞬时幅度的方差和边际谱的带宽、方差、面积、最大值等特征。

式中:cd(τ)表示第d个本征模态函数,表示第d个本征模态函数经过希尔伯特变换后的函数。
通过式(3)计算第d个本征模态函数的瞬时幅度ad(t):
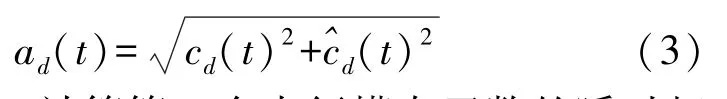
通过式(4)计算第d个本征模态函数的瞬时相位θd(t):

通过式(5)计算第d个本征模态函数的瞬时频率wd(t):

通过式(6)计算第d个本征模态函数的边际谱H(wd):

式中:Re()表示取实数。
1.2 基于AIC+Fisher的特征降维
1.1节中提取的脉冲涡流检测信号特征没有利用不同缺陷类型样本特征分布的先验知识,所提取的特征包含冗余信息,导致计算量变大,并且可能淹没重要信息。考虑到Fisher降维是一种有监督的特征降维方法,可以合理利用先验知识选取最佳投影方向对特征进行投影,降低特征维度,使得到不同缺陷的新特征样本点之间的距离变大,相同缺陷的新特征样本点之间的距离变小,提高缺陷分类的准确率。但是Fisher降维能确定特征维度的投影方向,而无法确定最优降维维度,无法保证SVM分类精确度的同时保证SVM的分类效率。因此选择赤池信息准则[13](Akaike Information Criterion,AIC)评估Fisher降维后的特征数据的优良性,从而确定最优降维维度。具体原理如下:
假设需要分类的类别数量为C,输入47个维度的脉冲涡流检测信号特征,各类样本的数量为mj。通过式(7)和式(8)计算特征样本类内散度矩阵S W和类间散度矩阵S B:

式中:x ji表示第j类类别的第i个样本,mj表示第j类类别的样本数量,u j表示第j类类别的样本均值,表示全部样本均值,pj表示第j类类别的先验经验;
通过Fisher的降维准则J(WK)可将信号特征降到K维:

式中:W K={w1,w2,…,wK}表示每种特征的投影方向。
利用式(10)计算每个K维样本的类内偏差

式中:Di表示样本i的类内偏差,表示降维后样本i的第k维特征值,表示降维后样本i所属类中心的第k维特征值。
根据概率分布理论,考虑到样本特征的类内偏差服从高斯分布,得到偏差的极大似然估计函数,可表示为:

式中:Γ表示极大似然估计函数,n表示样本总数量,u∗表示期望值,σ2表示标准方差。
同时,考虑特征维度会影响SVM算法时间复杂度,因此将特征降维维度K作为AIC需要考虑的独立参数量,构造AIC公式,可表示为:

式中:λ表示独立参数系数。AIC值越小,所提取的特征越好。因此通过式(9)~式(12)分别计算1-47维的AIC值,提取使AIC值最小的投影维度下的特征集,进行多层导电结构缺陷位置和尺寸的估计。
1.3 支持向量机
相较于其他分类算法,由于SVM分类算法是基于最小化经验风险的原则,具有良好的泛化能力和不易过拟合等优点,同时由于需要训练的特征是多维和线性不可分,因此本文采用基于高斯核的SVM分类算法构建分类器[14],即首先利用SVM分类算法构造4个分类模型SVM-0L,SVM-1L,SVM-2L,SVM-3L分别用于识别多层导电结构无缺陷、第一层缺陷、第二层缺陷和第三层缺陷等情况,如表1所示。然后构造6个分类模型SVM-2S,SVM-3S,SVM-4S,SVM-5S,SVM-6S,SVM-7S,分别用于检测尺寸为2 mm、3 mm、4 mm、5 mm、6 mm和7 mm的缺陷,如表2所示。其中表1和表2中的“1”表示识别结果为正类样本,“-1”表示识别结果为负类样本。以构建识别SVM-1L分类模型为例,将第一层缺陷特征样本作为正类样本,其他缺陷特征样本作为负类样本。利用如下模型对降维后的数据进行训练,采用粒子群算法方法对惩罚因子和高斯函数核等参数进行寻优,计算得到最优Lagrange乘子解参数,并利用获得的参数构建分类模型,用于估计缺陷位置和尺寸。

表1 缺陷位置分类模型

表2 缺陷尺寸分类模型

式中:Q(α)表示分类模型,αi,αl分别表示第i和l个Lagrange乘子,yi,yl分别表示第i和l个样本标签,yi,yl∈{-1,1},Mj表示j类缺陷的特征数量,Φ(xi,xl)表示高斯函数,表示惩罚因子。
2 方法实现
如图2所示,具体实现步骤如下:

图2 方法流程图
步骤1 初始化k=1,Kyu=47和λ等参数,并读取脉冲涡流检测信号的训练样本;
步骤2 将输入的脉冲涡流检测信号转化为时域,提取峰值、峰值时间和过零点时间共3个时域特征;
步骤3 对时域信号进行傅里叶变换,提取基频分量和二次到十二次谐波分量,共12个频域特征;
步骤4 利用经验模态分解算法分解时域信号,得到多个本征模态函数;
步骤5 对前四个本征模态函数进行希尔伯特变换,计算每个本征模态函数的瞬时相位、瞬时频率和边际谱,并提取前四个本征模态函数的均值、瞬时相位的方差、瞬时频率的方差、瞬时幅度的方差和边际谱的带宽、方差、面积、最大值等共32个特征参数。
步骤6 利用Fisher将上述提取的特征降到k维;计算和记录k维维度对应的AIC值,k=k+1,判断k是否大于阈值Kyu。如果是,则跳到步骤七,否则重新返回步骤六。
步骤7 获得AIC值最小对应的Fisher投影维度Kbest,提取Kbest维度投影下的特征集;
步骤8 根据位置和尺寸分类类型,按照1.3节方法分别构建相应的分类器,并利用样本集对分类器进行训练,同时采用粒子群算法对分类器的惩罚因子和高斯函数核参数进行寻优,获得分类器的模型参数;
步骤9 输入待估计的脉冲涡流检测信号,从时频和频域上提取47维特征,并采用Fisher投影成Kbest维特征。根据处理后的特征,先采用训练好的位置分类器进行缺陷位置估计,再采用训练好的尺寸分类器进行尺寸大小估计,并输出缺陷的估计位置和尺寸。
3 检测实验与分析
3.1 实验数据和参数
首先分别在三层导电结构的每一层中制造具有2 mm、3 mm、4 mm、5 mm、6 mm和7 mm缺陷的试件和无缺陷试件,共19个试件。采用自制脉冲涡流检测设备对上述19个试件进行检测,获得每一种有缺陷试件的200组脉冲涡流检测信号数据和无缺陷350组脉冲涡流检测信号数据,且每组具有2 000个采样数据。
采用MATLAB软件进行实验仿真。在实验中,令降维维度阈值Kyu为47,系数λ为0.6,并根据三层导电结构缺陷位置或缺陷尺寸的识别结果,计算查全率、查准率和平均误差值等算法性能指标。其中,令Zj表示测试集中第j类的待识别的元素数量,vj表示j类型正确识别的元素数量,bj表示识别为j类型的元素数量。则查全率F1定义为类型正确识别的元素数量占总元素数量的百分比,即:

查准率F2定义为类型正确识别的元素数量与识别为该类型元素数量比值的平均值,即
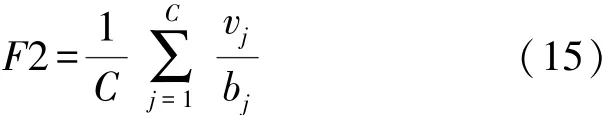
平均误差值R定义为识别出元素缺陷尺寸与真实该元素缺陷尺寸的平均误差,即:

式中:si表示第j类的第i个元素的真实缺陷尺寸,s′i表示第j类的第i个元素的识别出的缺陷尺寸。
3.2 实验效果分析
3.2.1 参数λ对算法的影响
选择式(12)中λ分别为0.5,0.6,0.7,0.8,0.9,1,1.1,1.2,1.3,1.4,1.5和4.1节中参数,提取包括缺陷位置所对应的脉冲涡流检测信号时频域中的47个特征值,计算其AIC值,得到不同λ值和维度下的AIC值,并利用SVM分类器分别对最佳特征维度下Fisher降维后的特征参数进行训练和识别,获得训练识别时间和识别查全率。
首先,分析不同λ值和维度对AIC值的影响。如图3所示,随着特征维度的增大,同一个λ值下的AIC值先下降,到达最小值后开始上升,即同一个λ值下的AIC值变化曲线都存在最小AIC值,其对应的特征维度为Fisher的最优降维维度。随着λ的变大,时间复杂度对AIC值的影响增强,查全率对AIC值的影响减弱,从而导致其对应AIC值变化曲线中的最小AIC值对应的Fisher的最优降维维度变小。

图3 不同λ值和维度下的AIC值
如图4所示,随着λ的增加,AIC更侧重于考虑算法的时间复杂度,使得AIC值变化曲线中的最小AIC值对应的Fisher最优降维维度变小,从而使得训练时间逐渐变短。但是当λ=<1.1时,由于最优降维维度变小,导致输入模块的特征参数信息变少,部分缺陷没有识别正确,因此随着λ的增加,查全率变小,当λ>1.1时,由于当前选择的降维维度更适合当前数据,少量原来识别错误的数据重新被正确识别,因此随着λ的增加,查全率略微提高1%。总之,考虑到当λ=0.6时,训练时间为18 min在可接收的时间范围内,其查全率为96.93%,相对较高,因此在后续的实验中,选择λ=0.6。

图4 λ变化下的训练时间和查全率
3.2.2 缺陷位置识别实验分析
选取350×2000个无缺陷信号数据、每一层选取2 mm、3 mm、4 mm、5 mm、6 mm和7 mm各50×2 000个有缺陷试件的信号数据作为缺陷位置识别的数据集。对该数据集提取2.1节所述的47维特征,并采用基于AIC+Fisher的特征降维方法,获得最优降维维度为19维,获得无缺陷、第一层缺陷、第二层缺陷和第三层缺陷四种位置类型降维后的特征参数,并以前三维特征分布为例说明所提取特征的有效性。如图5所示,基于AIC和Fisher的特征降维方法可提取无缺陷、第一层缺陷、第二层缺陷和第三层缺陷的特征,且其前三个特征相对聚集,能明显体现不同缺陷位置下的脉冲涡流检测信号对缺陷位置的反映,因此NEM所提取的特征能够较好的表征缺陷位置,但是无缺陷、第二层缺陷和第三层缺陷的特征之间存在一定的重叠,需要更多特征参数和SVM进行进一步区分。
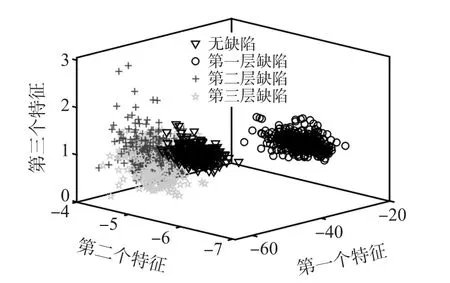
图5 缺陷位置识别时降维后前三个特征分布图
对数据集中数据进行特征提取和降维,获得特征数据集,并设计由随机抽取每种类型的100%、90%、80%、70%和60%的特征数据构成的R1、R2、R3、R4和R5五组训练样本集。测试集由全部特征数据集构成。同时,选择NEM、SVM47、AF_F、Fisher47和AF_R共5种识别方法对R1、R2、R3、R4和R5五组训练样本集进行训练,对其测试集进行缺陷位置识别,并计算查全率和查准率。其中,SVM47是采用SVM算法作为分类器,直接对特征提取后的47维特征进行训练和识别;AF_F是根据基于AIC+Fisher选择的最优降维参数下的特征参数,采用Fisher作为分类器,对缺陷进行识别;Fisher47是采用Fisher作为分类器,直接对特征提取后的47维特征进行训练和识别;AF_R是根据基于AIC+Fisher选择的最优降维参数下的特征参数,采用径向基神经网络(RBF)作为分类器,对缺陷进行训练和识别。
如图6所示,随着训练集中训练样本的减少,SVM47、AF_F和Fisher47的查全率变化幅度较小,且始终小于87%,而NEM和AF_R的查全率虽然随之降低,但是这两个算法的查全率始终大于90%,且NEM的查全率下降幅度较少。同时,不管训练样本如何变化,NEM的查全率始终大于SVM47、AF_F、Fisher47和AF_R。这是因为:NEM采用AIC+Fisher合理利用先验知识寻找缺陷位置与特征之间的映射关系,获得权衡准确率和算法时间复杂度的最优降维特征,并在选取的最佳投影方向对特征进行投影,从而获得能较好表征缺陷位置特点且去除冗余的特征数据。这些特征数据中,不同缺陷的特征点之间的距离较大,相同缺陷的特征点之间的距离较小,有利于支持向量机(SVM)进行分类,从而较多的识别出正确的缺陷位置。而Fisher47和AF_F分别采用Fisher分类方法对47维和最优降维维度下数据进行分类,其直接识别效果较差。SVM47直接对47维特征数据进行分类,其特征数据存在较多冗余,较难选择好分类参数。AF_R采用RBF对最优降维维度下数据进行分类,但是SVM算法构造分类器对特征的拟合性较好且适用于较少的训练样本,因此NEM略高于AF_R,且随着训练样本数量的下降,两者差距更明显。

图6 缺陷位置识别的查全率比较
如图7所示,NEM的缺陷位置识别的查准率大于SVM47、AF_F、Fisher47和AF_R,且随着训练样本数量的下降,NEM的查准率下降幅度不大。这是因为:NEM能寻找到降低特征冗余且较好表征缺陷位置的特征数据,并采用SVM设计了缺陷位置识别的分类器,从而正确识别出4种类型的数据,且无缺陷识别为有缺陷的数量较少,从而提高了NEM的查准率。而SVM47和Fisher47没有进行特征降维,Fisher的分类效果较差,训练集样本较少的情况下RBF分类效果也较差。

图7 缺陷位置识别的查准率比较
3.2.3 缺陷尺寸识别实验分析
每一层选取2 mm、3 mm、4 mm、5 mm、6 mm和7 mm缺陷尺寸。每一层每一类缺陷尺寸选择200×2 000个信号数据,共18×200×2000个信号数据作为缺陷尺寸识别实验的数据集。对该数据集提取2.1节所述特征,并根据AIC值得到一到三层Fisher最优降维维度分布为15维、20维和21维。以第一层的6种缺陷尺寸类型缺陷降维后的前三维特征分布为例,说明所提取特征的有效性。如图8所示,不同尺寸下的缺陷特征相对聚焦,能体现不同尺寸缺陷下的脉冲涡流检测信号对缺陷尺寸的反映,且2 mm、3 mm和4 mm的缺陷特征与5 mm、6 mm和7 mm的缺陷特征区别明显。但是2 mm、3 mm和4 mm的缺陷特征之间存在一定的重叠,5 mm、6 mm和7 mm的缺陷特征之间存在一定的重叠,这需要更多特征参数和SVM进行进一步区分。

图8 降维后第一层不同缺陷尺寸下的前三个特征分布图
对缺陷尺寸识别实验的数据集中数据进行特征提取和降维,获得特征数据集,并设计由随机抽取每种类型的100%、90%、80%、70%和60%的特征数据构成的R6、R7、R8、R9和R10五组训练样本集。测试集都由缺陷尺寸识别实验的全部特征数据集构成。同时,选择NEM、SVM47、AF_F、Fisher47和AF_R共5种识别方法对R6、R7、R8、R9和R10五组训练样本集进行训练,对测试集进行缺陷尺寸识别,并计算各个算法的查全率、查准率和平均误差值。
如图9所示,随着训练样本数量的下降,NEM、AF_R、SVM47和AF_F的查全率随之下降,Fisher47的查全率基本变化不大。但是NEM的查全率受训练样本数量的影响较小,其始终高于SVM47、AF_F、Fisher47和AF_R。这是因为:NEM根据缺陷尺寸数据的特点,采用AIC+Fisher算法,去除冗余特征,获得最优降维维度。同时,NEM提取出针对缺陷尺寸识别的有效特征参数,并采用对特征拟合性较好的SVM方法设计6个分类模型,可有效识别出缺陷尺寸。而AF_R、SVM47和AF_F存在节3.2.1中所述的相同缺点,因此NEM的查全率最高,且随着训练样本数量的下降,其下降幅度较小。

图9 缺陷尺寸识别的查全率比较
如图10所示,随着训练样本数量的下降,NEM、AF_R、SVM47的查全率随之下降,AF_F和Fisher47的查全率基本变化不大。但是NEM的查全率受训练样本数量的影响较小,其始终高于SVM47、AF_F、Fisher47和AF_R。这是因为:NEM提取的特征能很好表征缺陷尺寸,且设计了合理的SVM分类器,即使在训练集较少的情况下,仍能较好分类对应缺陷尺寸,其查全率受样本数量影响较少。
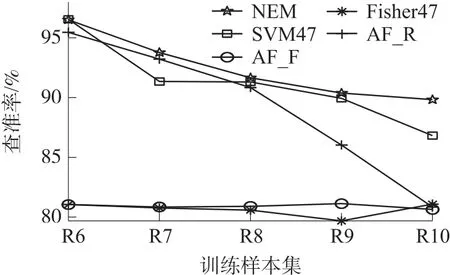
图10 缺陷尺寸识别的查准率比较
如图11所示,不管训练样本数量如何变化,NEM的缺陷尺寸识别的平均误差值始终小于SVM47、AF_F、Fisher47和AF_R。这是因为:NEM能较好的识别出各个缺陷的尺寸类型,其查准率和查全率都是最高,且个别识别错误的缺陷,其识别出的缺陷尺寸在其实际缺陷尺寸的附近,这降低了NEM的缺陷尺寸识别的平均误差值。SVM47、AF_F、Fisher47和AF_R的查准率和查全率都不是最优的,其缺陷尺寸识别的平均误差值较大。

图11 缺陷尺寸识别的平均误差值比较
4 结束语
提出一种多层导电结构缺陷位置和尺寸的无损估计方法(NEM),能够有效对多层导电结构缺陷位置和尺寸进行识别。首先,NEM将脉冲涡流检测信号转换为时域信号,分析时域信号并提取特征,然后利用傅里叶变换和希尔伯特黄变换分析脉冲涡流检测信号的频域和瞬时频域,并提取47维特征。接着提出基于AIC和Fisher的特征降维方法,去除冗余特征,提高分类器的训练速度,并采用SVM构造分类器,可避免数据过拟合的问题,提高识别精度。最后,给出实验数据和参数,仿真分析参数λ对算法的影响,比较缺陷位置识别和缺陷尺寸识别下的NEM、SVM47、AF_F、Fisher47和AF_R的性能。
实验结果表明:NEM能够适用于多层导电结构的缺陷位置识别和缺陷尺寸识别,从而提高识别的查全率和查准率,降低缺陷尺寸识别的平均误差值,优于SVM47、AF_F、Fisher47和AF_R等方法。但是NEM采用基于粒子群参数寻优的SVM进行分类,其分类速度相对较慢,因此下一个阶段目标是研究适用于大规模数据的分类方法。
猜你喜欢
车主之友(2022年4期)2022-08-27
装备制造技术(2020年11期)2021-01-26
海峡姐妹(2019年12期)2020-01-14
现代电子技术(2018年20期)2018-10-24
通信电源技术(2018年5期)2018-08-23
现代情报(2018年11期)2018-01-07
火控雷达技术(2016年1期)2016-02-06
汽车科技(2014年6期)2014-03-11
燕山大学学报(2014年1期)2014-03-11
组合机床与自动化加工技术(2014年10期)2014-03-01
