
C-Vine Copula在不平衡数据上的应用
2021-09-03 06:58关红钧
沈阳大学学报(自然科学版) 2021年4期
关红钧,王 蕾
(1.沈阳大学 师范学院,辽宁 沈阳 110044;2.沈阳师范大学 数学与系统科学学院,辽宁 沈阳 110034)
分类问题是机器学习的主要任务之一,医疗诊断、用户检测、遥感图像分类和垃圾分类等都会用到分类算法[1-4].针对分类问题,已有很多学者提出多种经典算法,例如朴素贝叶斯和支持向量机等.高速发展的科技使获取数据的方式越来越简单,然而现实数据集的各类样本通常是不平衡的,总会有某一类明显多于其他类,形成不平衡数据集.传统分类算法默认各类别样本分布相对平衡,应用在不平衡数据上分类结果是偏的,影响后续分析决策.因此如何提高不平衡数据的分类精度已成为热点问题.
copula理论是Sklar[5]最先提出的,连接边缘分布和多元联合分布的函数就是copula函数.此后Joe[6]和Nelsen[7]进一步拓展完善copula理论,总结并介绍了常用copula族函数及其性质.Embrechts等[8]首次将copula理论应用到金融领域上.Bedford等[9-10]引入“Vine ”结构,建立R-Vine copula模型来应对多维数据带来的维数灾难.Aas等[11]提出了2种特殊Vine结构,即C-Vine(canonical Vine)和D-Vine(drawable Vine).Maugis等[12]阐述了Vine 结构的性质,研究了pair copula的选择方法和Vine 结构的算法.由于C-Vine和D-Vine 结构相对简单,且能够描述多维变量的相关结构,被广泛应用在金融问题的研究中.Dißmann[13]利用赤池信息量准则(AIC)确定R-Vine结果中的copula函数,以研究金融数据间的相关结构.Brechmann等[14]提出截断与简化高维Vine copula模型,并应用在财务数据中,结果证明该方法能够描述高维数据的重要相关结构.
为提高不平衡数据分类精度,本文提出了一种基于C-Vine copula的虚拟样本生成算法.首先,对不平衡数据的少数类构建C-Vine copula模型,得到条件分布函数和pair copula的类型及参数.然后,结合多元逆采样方法对少数类数据生成包含数据特征的虚拟样本,将虚拟样本与原始数据进行整合,得到平衡数据集.最后,利用传统分类算法对平衡数据集进行分类,对算法进行分析和验证.与SMOTE、Borderline-SMOTE和ADASYN相比,本文提出的算法在传统分类器上表现较好,能够提高分类器在不平衡数据上的分类性能.
1 预备知识
1.1 pair copula函数
Sklar定理是copula理论能够广泛应用的理论基础.根据Sklar定理可知,一个n维联合分布函数可以分解为n个边缘分布和一个n维copula函数乘积的形式,其中copula函数描述了变量间的相依结构,简化原有的多元函数建模问题.假设n维随机向量X=(X1,X2,…,Xn)的联合概率分布为F,边缘分布函数为F1(x1),…,Fn(xn),则存在一个copula函数C使得
F(x1,…,xn)=C(F1(x1),…,Fn(xn))
成立.边缘分布函数是连续函数时,copula函数C是唯一的.如果copula函数可微,X的联合密度函数可以表示为

(1)
式中,fi(xi)是Fi(xi)的密度函数(i=1,…,n),c是C的概率密度函数.令ui=Fi(xi),则有
n维随机向量X=(X1,X2,…,Xn)的联合密度函数表示为多个pair copula密度函数和边缘分布函数的乘积,写作
f(x1,…,xn)=f(xn)·f(xn-1|xn)·f(xn-2|xn-1,xn)·…·f(x1|x2,…,xn).
(2)
结合式(1)和式(2)可得:
f(x|v)=cxvj|v-j(F(x|v-j),F(vj|v-j))f(x|v-j),
式中,vj是向量v的一个分量,v-j是剔除vj后得到的向量,cxvj|v-j是pair copula函数,条件分布函数F(x|v)表示为
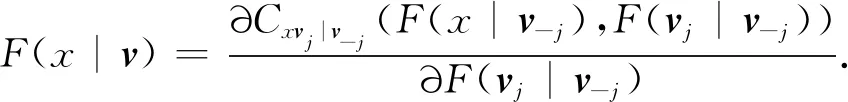
(3)
当v-j=∅,式(3)写作
1.2 C-Vine copula模型
copula函数在二元变量建模中发挥了重要作用,但在多维变量中,其待估参数的个数过多,导致维数灾难.而Vine copula函数能够克服上述困难,更加准确地描述多元变量之间的相关结构[15].Vine结构包括树、边和节点,每棵树由若干条边构成,每条边连接2个节点.一个n维Vine结构可表示为T=(T1,…,Tn-1),其中第i棵树Ti的边是树Ti+1的节点(i=1,…,n-1).C-Vine和D-Vine模型都可以在树状结构下分解随机变量的联合分布,是应用最广泛的2类Vine模型[16-17].本文采用C-Vine copula结构对数据进行建模.
C-Vine copula模型的联合密度函数可以表示为
C-Vine copula模型的条件分布函数可以表示为
本文对于C-Vine copula模型中心节点的选择及节点顺序,参考Aas[11]等提出的基于Kendall秩相关系数排序的方法进行判断.利用极大似然估计法对C-Vine copula模型的参数进行估计.根据AIC准则选择节点间pair copula函数类型.概率密度函数通过核密度方法得到.核密度方法是一种用于概率密度估计的非参数方法,对于n个独立同分布的样本x1,x2,…,xn,未知类样本x的概率密度估计值为
其中K(·)取高斯核函数,带宽h>0.
1.3 逆采样
逆采样(inverse sampling)是伪随机数采样的一种方法.在已知任意概率分布的分布函数时,利用该方法可以生成随机样本.假设F是上连续递增的分布函数,它的广义逆F-1表示为
F-1:(0,1)→,F-1(x)=inf{y∈:F(y)≥x}.
若随机变量U~U[0,1],那么F-1(U)有分布函数F.若F是X的分布函数,则F(X)~U[0,1],即X=F-1(U).
2 基于C-Vine copula的不平衡数据处理
2.1 C-Vine copula虚拟样本生成算法
Xs=(xs,1,…,xs,T)表示原始样本的少数类样本,其中s=1,…,n为n个变量,T表示少数类样本个数.首先,对原始样本的少数类样本Xs构建C-Vine copula模型,得到分布函数F、条件分布函数F2|1,F3|12,…,Fs|1,…,s-1和相应的copula参数.然后,生成m个服从均匀分布的随机数Uo(o=1,…,m),m由多数类样本与少数类样本的数量差决定,利用条件分布函数的逆函数,结合多元逆采样方法进行抽样,得到虚拟样本V=(V1,…,Vm)~F.
最后,将原始样本和得到的虚拟样本V进行组合,得到平衡数据集,利用平衡数据集训练分类器.
2.2 评价指标
传统分类器通常采用整体分类准确率和错误率作为评价标准,但是对于不平衡数据分类问题,这些标准无法准确评价分类结果.为此,学者们针对不平衡数据分类问题提出了合适的评价指标:G -mean(几何平均值)和F-measure(F值)等.本文选择G -mean、F-measure和Recall(查全率)来评价不平衡数据的分类情况.表1给出了二分类问题的混淆矩阵.

表1 混淆矩阵Table 1 Confusion Matrix
根据混淆矩阵可以得到查全率、查准率(Precision)、G -mean和F-measure.
式中,G -mean用来衡量分类器对于两类样本分类的平均性能,兼顾了多数类准确率和少数类准确率,比整体准确率更加适合评价不平衡数据的分类情况.F-measure比G -mean更加关注少数类分类性能,能够兼顾少数类的查准率和查全率,也被广泛应用在不平衡数据分类性能评价中,β表示调节Recall和Precision的系数,其取值通常为1[18].
3 实例分析
在KEEL存储库和UCI机器学习数据库选择了3个实际数据集进行实验,表2给出了数据集的基本信息.对于多类别的数据集,选择某一类作为正类,其余所有类别作为负类.实验中训练集和测试集按照7∶3的比例划分.

表2 数据集基本信息Table 2 Basic information of datasets
实验先处理不平衡数据集,利用SMOTE、Borderline-SMOTE、ADASYN和C-Vine copula虚拟样本生成算法得到平衡数据集,再用SVM和RPART两个分类器对平衡数据集进行分类.表3~表5分别给出了数据集在SVM和RPART上的分类结果,其中CVI表示C-Vine copula虚拟样本生成算法,BLSMOTE表示BorderLine-SMOTE虚拟样本生成算法.根据表3~表5可知,由CVI得到的平衡数据集在2个分类器上的分类结果优于其他方法.说明基于C-Vine copula模型生成的虚拟样本的质量好于SMOTE、Borderline-SMOTE和ADASYN所生成的样本质量.

表3 数据集1的分类结果Table 3 Classification results of dataset 1

表4 数据集2的分类结果Table 4 Classification results of dataset 2

表5 数据集3的分类结果Table 5 Classification results of dataset 3
4 结 论
本文提出了一种基于C-Vine copula的虚拟样本生成算法,以实现对不平衡数据分类精度的有效提高.该方法通过对少数类数据构建C-Vine copula模型,结合逆采样方法生成包含数据特征的虚拟样本,从而得到平衡数据集,对平衡数据集进行分类,得到分类结果.与其他方法相比,C-Vine copula虚拟样本生成算法能够有效提高不平衡数据分类的精度,为不平衡数据分类问题提供算法层面的解决方法.
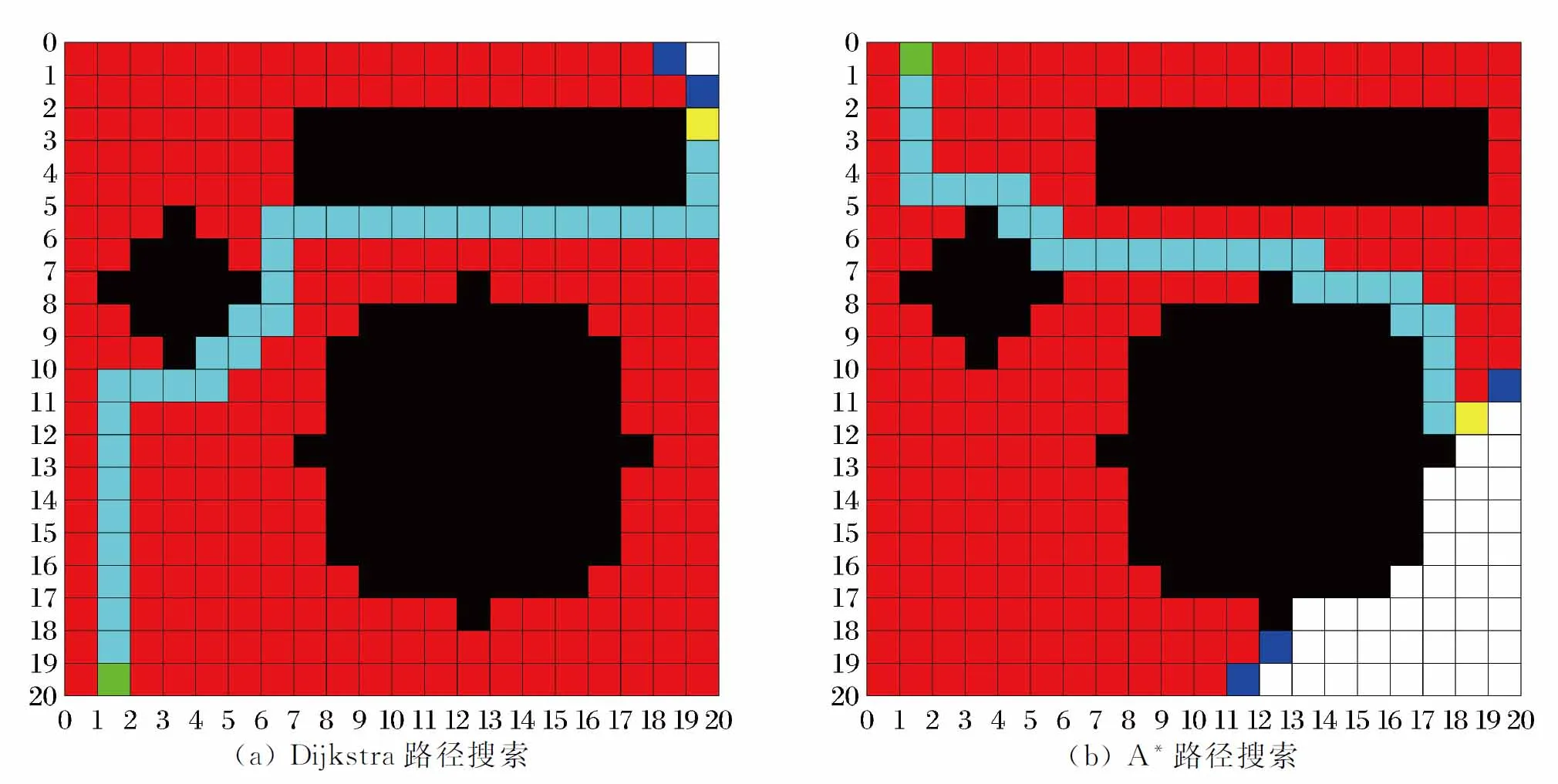
图2 Dijkstra算法与A*算法路径搜索Fig.2 Path search of Dijkstra and A* algorithm
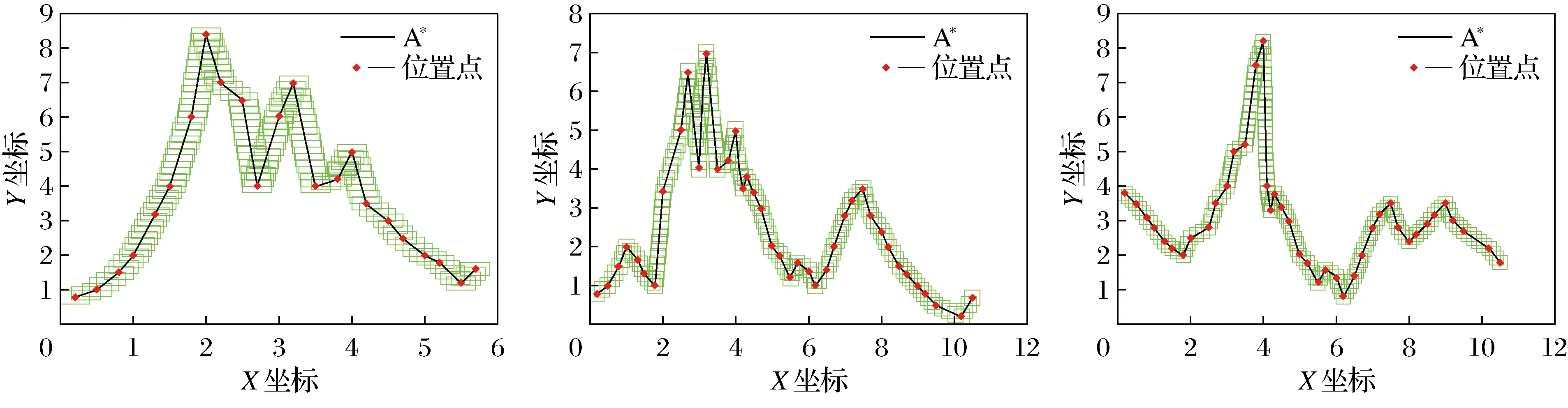
(a) A*搜索结果
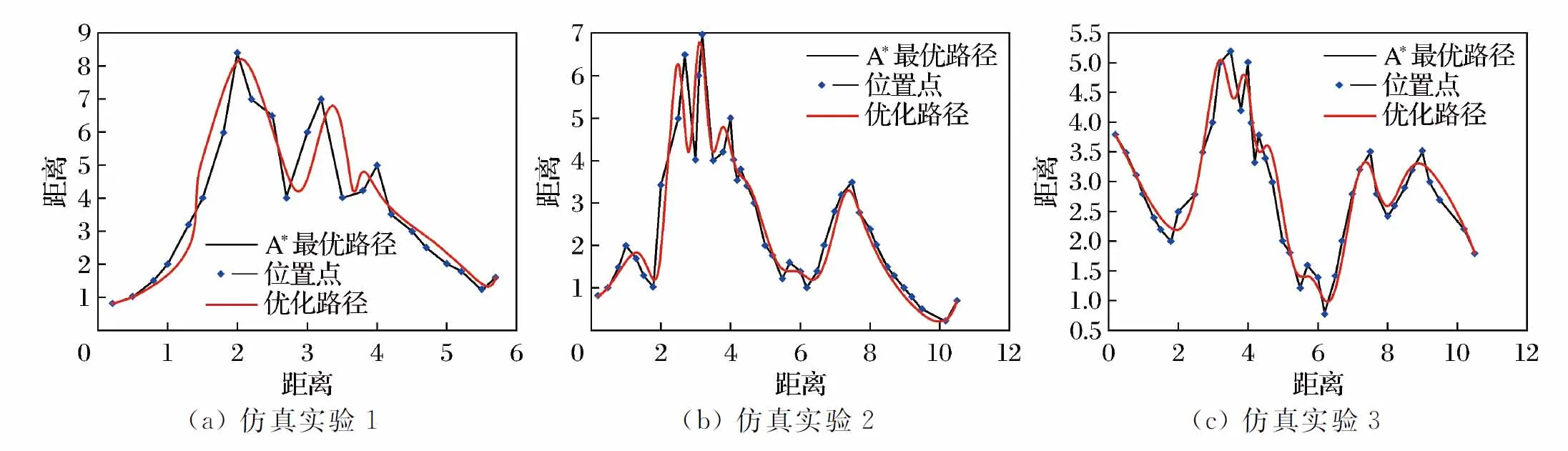
图7 最小化snap优化效果Fig.7 Minimum snap optimization graphics
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机应用与软件(2021年10期)2021-10-15
计算机系统应用(2021年2期)2021-02-23
小型微型计算机系统(2020年11期)2020-12-10
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
软件导刊(2017年4期)2017-06-20
