
协同视觉显著性检测方法研究进展综述
2021-09-07 00:47陈志武钱晓亮
计算机工程与应用 2021年17期
陈志武,成 曦,曾 黎,钱晓亮
郑州轻工业大学 电气信息工程学院,郑州450002
随着科技的发展与进步,大量的多媒体产品被广泛应用于日常生活,比如电脑、照相机、智能手机等产品,因此产生了海量的图像。在这其中,如何从海量图像中筛选人们所需要的部分,显得十分重要。作为计算机视觉的一个分支——协同显著性检测,是模拟人类视觉注意机制,检测一组相关图像中公共显著的目标区域,实现对图像的筛选和鉴别功能,大大减少了人力和存储的成本。此外,它还被广泛地应用于其他计算机视觉任务,如图像分割[1]、图像和视频的检索[2]、视频压缩[3]、目标检测[4]等领域。
在协同视觉显著性检测的研究中,研究者一直主要围绕两个关键性问题:一方面,获取单幅的视觉显著性特征(Intra-saliency);另一方面,挖掘一组相关图像间的相似性[5](Inter-saliency)。早期传统的协同视觉显著性检测方法,利用提取浅层特征对图像中每个像素或区域进行协同显著程度的打分,从而推理协同显著性的目标或区域[6],这些浅层的特征包括颜色直方图、梯度直方图、尺度不变特征转换描述符SIFT等手工特征和通过PCA、SPCA[7]、ICA[8]等算法产生的特征。后来研究人员发现,传统方法都存在一个共性问题:使用的浅层特征比较主观,而且并不能有效描述图像的信息,从而影响特征对后续组间显著性的推理,引起检测精度不佳的问题,尤其是当图像中存在复杂场景和前景与背景相似的情况,这一问题更加明显。近年来,由于深度学习的出现,协同视觉显著性检测得到快速发展,其检测精度有了很大提升,具体体现在这两个方面:其一,在特征方面,深度学习的方法可以利用卷积神经网络(Convolutional Neural Network,CNN)提取图像的深层特征,这种深层特征具有更全面描述图像的能力,从而解决传统方法浅层特征过于主观的问题;其二,在模型方面,深度学习促使视觉显著性检测领域产生大量优秀的CNN模型,此类模型能有效地解决协同显著性研究中的一个关键性问题,即获取单幅图像显著性特征,同时基于CNN模型的性能,在挖掘组间图像相似性方面有较好的性能。
基于以上现状,本文对现有流行的协同视觉显著性检测方法进行相关研究。根据提取的图像特征深浅程度,将其分为:采用浅层特征的方法(传统的方法)和采用深层特征的方法(基于深度学习的方法),针对这两类算法围绕协同显著性检测的关键性两个问题进行介绍、实验分析和总结。
本文通过特征层次和模型构建两方面去分析和总结协同显著性检测方法的性能,其主要的贡献如下:
首先,对现有的协同视觉显著性检测方法进行分类介绍、分析和总结。
然后,在两个数据库上,对流行的协同显著性检测方法进行定性和定量的实验对比,并进行分析。
最后,总结了现阶段协同视觉显著性检测方法存在的问题,提出了理论性的解决方案。同时,对未来工作进行展望。
1 相关工作
协同视觉显著性检测是视觉显著性检测的一个重要分支,视觉显著性检测[9]是凸显在一张图像中显著的目标区域,而协同视觉显著检测捕捉的是一组图像中共同显著的目标区域,通过对比发现协同显著性检测是一个更具有挑战性的机器视觉任务,具体的检测差异形式如图1所示。

图1 显著性检测和协同显著性检测的真值图对比Fig.1 Comparison of ground truth for saliency detection and co-saliency detection
协同显著性检测是衍生于显著性检测,并在不同时期赋予其不同的定义形式。最早期的视觉显著性是ITTI等[10]提出的,其定义是人眼注意机制的预测形式[11],其显著图是以显著程度量值化形式呈现的。随后视觉显著性检测视觉任务不断延伸,则出现了最早的协同视觉显著性检测[12],Jacobs等将其定义为:在几乎不变的场景中,去检测在两张图像中引起局部差异变化的同一显著目标。后又被定义为:在一对相似的场景图像中检测出共同显著的目标[8,13]。再经过多年的发展,研究者发现背景高度相似的要求限制了其适用性,而在不同的背景中更符合实际情况、并具有通用性。最后定义为,在一组相关图像中,检测共同显著的目标或区域[14]。
2 协同显著性检测方法的分析
针对已有的协同视觉显著性检测方法,根据特征形式差异,将其分为两大类:传统的方法和基于深度学习的方法,并对这两大类型方法进行详细的介绍和理论分析。
2.1 传统的协同显著性检测方法
传统的方法一般是基于浅层的特征进行检测,浅层的特征包括:颜色直方图、梯度直方图、SIFT等手工特征和通过人为设计算法提取的特征。为了更清晰地介绍传统方法,依据组间显著性的策略差异,传统的方法可再细分为:相似性对比方法、基于聚类的方法、基于秩分析的方法。这些传统的方法取得了不错的检测效果,并对后续的研究具有启发式的意义,具体介绍如下。
2.1.1 基于线性相似性对比的方法
在早期的协同显著性检测中,一般是通过计算一组相关图像间的手工特征相似性来描述组间图像的显著性。例如,Li等[13]提出最早线性相似性对比的方法来整合单幅和组间图像的显著性,其中的单幅显著性特征是利用三种视觉显著性的技术[10,15-16]来获取,而组间显著性是通过SimRank算法来计算图像特征层的节点距离产生的。后来,研究者发现这种方法表征组间显著性较弱。其中,Li等[14]对该线性融合的方法做了一些改进,他们采用金字塔特征间的两两相似度排序和最小生成树匹配来衡量组间图像的相似性。此外,为了更好计算一组相关图像间相似性,Li等[17]构思了一种单幅视觉显著性检测引导协同视觉显著性检测的方法,一方面通过已有显著性模型去获取图像的单幅显著性特征,另一方面通过不同查询排序的方案获取图像间相似性,从而提高协同显著性检测的精度。但是,其特征线索依赖早期的显著性检测模型,限制了其检测性能。此外,Liu等[18]构建了一种基于分层分割的模型,通过区域的直方图特征,更好地衡量各个区域的全局相似性。
2.1.2 基于聚类的方法
Fu等首次提出了一种基于聚类的检测方法[19],利用聚类思想有效地学习单幅图像的显著性和多幅图像间的显著性。在此模型中,他们采用对比性线索、空间线索以及一致性线索来衡量聚类的显著性特征,最终将单幅显著性和多幅图像显著性融合产生最终协同显著性图。这种聚类的思想不仅简单,而且有效地提高检测的精度。但是该方法严重依赖于自定义的手工设计线索,它们通常过于主观,因此不能很好地推广到实践中遇到的各种场景。
2.1.3 基于秩分析的方法
研究者发现一组相关图像中共同显著目标区域的直方图矩阵具有相似的低秩特征,可以来表征组间的显著性关系。于是,Cao等[20]提出了基于低秩矩阵近似和低秩矩阵恢复的方法,来衡量多种显著性线索的自适应权重,以突显一组图像中的共同显著区域。由于该方法特征是单尺度的,存在对图像表征能力不足的问题,使得在复杂的自然场景中无法捕捉到公共显著性目标。后来,Huang等[21]采取了一种新的改进策略,通过多尺度超像素的低秩分析检测出显著性目标区域,并利用自适应融合单幅显著性图来产生协同显著图。此外,Li等[22]分别利用低秩矩阵恢复和颜色直方图,去分别获取区域级的显著图和图像间一致性,引导像素级和区域级的相似度对比,从而得到协同显著性图。
上述三种类型的传统方法利用浅层特征和人工设计的先验知识,进行协同显著性推理,获得令人满意的检测效果。然而,这种传统的方法普遍存在一个共性问题[23-24],浅层的特征和先验知识线索往往是人工设计的、主观的,对图像的表征和推理能力不足,导致模型检测不稳定性的问题,有时甚至在比较复杂的场景中,模型检测可能会失效。
2.2 基于深度学习的协同显著性检测方法
基于深度学习的方法一般是利用CNN模型,学习一组图像中的单幅和组间显著性特征,再对两种特征进行融合,实现协同视觉显著性检测。由于基于深度学习的方法是通过CNN模型学习而获取的深层特征,因此,该特征具有更好描述图像信息的能力,弥补了传统的方法中浅层特征过于主观的缺点。此外,基于深度学习的方法依据在模型构建中,特征提取模块和推断协同显著性模块是否相互分离,可将它们分为:非端到端的方法和端到端的方法,具体的介绍如下。
2.2.1 非端到端的方法
非端到端的方法一般是将图像特征的提取模块和推断协同显著性目标模块分为单独的两个部分,构成是一个分步式检测的模式。下面对现有流行的非端到端的检测方法进行具体介绍。
基于深度学习的非端到端方法有以下两个特点:其一,利用CNN模型获取每幅图像的深层特征;其二,通过人为设计的先验知识(相似性计算、聚类以及图论等方法)去推理深层特征的组间显著性关系,最后融合单幅和组间显著性特征,去产生协同显著性图。例如,Zhang等[23]利用贝叶斯的方式去推理协同显著性目标,首先利用CNN模型分别在单幅图像和一组图像中提取边框级别的深度特征,然后通过贝叶斯方式计算单幅图像的特性和相似性、组间图像间的特性和相似性,来衡量图像的协同显著性得分,最后利用得分引导出超像素分割的协同显著区域。但是,由于采用人为设计的先验知识,对于组间显著性关系推理具有主观性,导致模型检测不稳定性的问题。后来,研究者在组间图像相似性计算的方面,提出了不同的改进策略。其中,Yao等[25]提出了一种基于两阶段多视点光谱旋转联合聚类的方法,通过结合多种互补特征的方式进行两阶段联合聚类,而且利用光谱旋转不变量来保证最终聚类指标矩阵的最优解,从而增强组间显著性的推导性能。而Zhang等[26]首次提出了一种自步多示例学习的模型,通过这种自步学习策略去模拟人类的学习机制,使检测模型更加稳健。对于图论的策略,Hsu等[1]通过基于图论的最优解问题,去互补迭代的优化协同分割和协同显著性检测性能,该迭代方式进行区域级的自适应显著性融合和目标分割,在两个互补任务之间传递有用的信息,通过优化迭代,参照目标的分割,逐步清晰化协同显著的各个区域,最后获得整个协同显著区域。此外,为了更好提高检测的精度,提出了两阶段的由粗到细优化策略,进行协同显著性检测。Zhang等[27]提出一种掩模引导和多尺度标签平滑的全卷积网络,实现协同显著性图像由粗到细的精化过程,这种网络既能更好地捕获公共显著目标,又能有效地抑制背景。Tsai等[28]采用一种新的两阶段策略,第一阶段,通过无监督的堆叠式自编码器来评估图像的前景一致性和前景、背景差异性,得到初步的协同显著性图;第二阶段,构建自训练卷积神经网络去解决初步检测图像的多尺度平滑问题,从而得到更清晰的协同显著性图。此外,Hsu等[29]通过无监督学习覆盖共同类别的图像来实现协同显著性检测,并提出了两种无监督损失函数来优化模型的性能。
对于非端到端的模型,采用先特征提取、后特征推理的两步骤方式,去挖掘组间的显著性,取得不错的检测效果。但存在着一个共性问题,特征提取模块和推断协同显著性模块是两个独立的过程,学习的特征未能定向地推理共同显著区域,导致模型的次优解问题。因此研究者对此得到启发,并进行了后续的相关改进。
2.2.2 端到端的方法
端到端的方法是特征提取模块和推断协同显著性模块整合到一起,进行共同训练的检测方法。相比于非端到端方法,此类方法具有更好的检测性能,下面介绍一下主流的端到端方法。
一般的端到端方法是基于全卷积构建的,通过注意力机制卷积、图卷积以及类别语义等方式来增强组间图像的显著性推断性能,并获得了较高的检测精度。最初的端到端模型是Wei等[30]提出的,他们构建了一种成组图像输入和成组输出的全卷积网络,其整个网络分为信息共享的两个分支,一个分支提取成组输入图像中每张的单幅显著性特征,另一分支挖掘成组输入图像的组间显著性特征,最后卷积融合产生协同显著性图。这种纯粹全卷积的端到端网络存在一个问题:协同显著性推理采用特征来自于整个图像的,而不是来自于公共显著目标区域,使得冗余的特征(非公共显著性目标)影响其推理效果。该方法具有很大启示作用,研究者在此基础上进行相关的改进。其中,有研究者利用图卷积来改进全卷积网络。例如,Jiang等[31]提出了一种结合图卷积和卷积学习来评估协同显著的框架,该框架通过自适应学习超像素的图像特征、结构和标记三种信息,进行协同显著性的评估。此外,为了更好地挖掘组间显著性特征,利用注意力机制卷积进行相关改进。例如,Gao等[32]搭建一种新的协同注意机制全卷积框架,一方面赋予公共显著目标区域较大的注意力权重,另一方面分配背景和干扰区域较小的注意力权重,去提高最终检测性能。Zhang等[33]搭建了基于注意力机制图聚类的自适应图卷积框架,首先通过图卷积网络获取图像内和图像间的特征关系,然后利用注意力机制图聚类的方法来无监督捕获公共显著目标,最后利用解码器产生协同显著性图。Li等[34]利用协同注意机制构建了一个RCAU(Recurrent Co-Attention Unit)的网络去逐步优化协同显著性检测过程。
后来研究者发现,组间显著性是由共同显著目标的类别语义决定的,而不是由颜色、纹理、形状决定的,所以将类别语义作为辅助监督信息去提高检测精度。其中,Zha等[35]提出了组间图像类别语义和深度视觉特征推导协同显著检测的方法,该方法首先利用一组相关图像具有相同类别的语义进行监督训练,然后将类别语义信息去引导多层次的深度视觉特征进行检测。Zhang等[36]提出了一种梯度引导协同显著性检测的框架,并通过拼图策略扩充标注样本,增强模型的泛化能力。Zhang等[37]构建了一种协同聚合与分布的网络,分别获取图像间的组间和个体语义信息,通过解码器进行协同显著性目标预测。Jin等[38]采用了一种内部显著性关联网络,首先通过现有的显著性检测方法提取显著性内部显著信息,然后采用关联融合模型描述每张图像内部特征,最后通过分类重组的自相关策略进行优化。Fan等[39]提出了CoEG-Net,采用协同注意投影策略来提高了模型的可扩展性和稳定性。Ren等[40]构建了一种基于协同特征提取和高低特征融合的模型,集成了目标图像的协同特征和多层次单个特征,利用单个图像内部信息来丰富协同特征。此外,Qian等[41]提出了基于双支流编码器生成式对抗网络挖掘intra-saliency和inter-saliency的之间关系,进行协同显著性检测。Tang[42]采用Transformers模型提高检测的稳定性,并通过对比学习方案来有效地区分公共显著目标和背景。
上述的端到端的方法中,Wei等最初提出经典的成组图像输入和成组输出的纯粹全卷积网络,具有启发式的意义。后续研究者发现,其推理共同显著目标的特征:不是来自于整个图像,而是来自于图像的显著性的区域。整个图像的特征具有冗余信息,会干扰检测的效果。于是,通过协同类别的语义、图卷积和注意机制的改进策略,去提取来自显著性区域的特征,从而提高检测的精度。
3 实验分析
将已有的协同视觉显著性检测方法在两个流行的数据库上进行主观和客观的实验评估,并进行定性分析。
3.1 实验设置
3.1.1 数据集
为了对算法进行全面的评估,目前协同显著性检测的数据集一共有5个,分别为:Image pair[13]、MSRC-A[43]、MSRC-B[43]、iCoseg[44]和Cosal2015[23]。但由于受算法公布结果和代码的限制,同时方便后续实验的对比,如表1所示,本文选择最流行的两个数据集:iCoseg和Cosal2015,下面对这两个数据集进行介绍。

表1 协同显著性数据集Table 1 Datasets of co-saliency
3.1.2 评价指标
iCoseg数据集一共有643张图像,其包含38组不同类别,图像标签是人工标注的像素级、二值化标签。此外,数据集的前景包含多个目标,且前景目标差异变化较小,背景简单而且相似。
Cosal2015数据集是由ILSVRC2014[45]和YouTube Video[46]的数据集筛选出来的图像组成,该数据集一共有2 015张图像,其中包含50张不同的类别,图像的标签也是人工标注的像素级、二值化的标签。在数据集的图像中,其前景包含一个或者多个共同显著性目标,内容变化较大;而且图像背景相对复杂,有些与前景相似,具有干扰性。因此该数据集是目前最具有挑战性的数据集。
为了更全面和有效地评估现有的算法,本文采用现在广泛使用的三种评价指标:F-measure[47-48]、S-measure[49]和MAE,三种指标的详细介绍如下。
F-measure是协同显著性检测中常用的衡量前景区域相似性的评价指标,它是一种图像的准确率和召回率的调和平均值,其中的准确率和召回率是利用自适应阈值法确定。F-measure的表达式为:

其中β为0.3[23],Precision和Recall表示准确率和召回率的值。本文采用自适应F-measure和最大值F-measure进行评估性能。
S-measure是应用于计算在预测图和真值图之间区域级和目标级的结构性度量,其可表示为:

其中,Sr和So分别表示在预测图中基于区域级的结构相似性和基于目标级的结构相似性,a为0.5[49]。
MAE是衡量预测图和真值图的像素级平均差值,其中预测图和真值都被归一化到[0,1],MAE可表示为:

其中,W和H分别表示为图像的宽度和长度,而F和G分别表示预测图和真值图。
值得注意的是:F-measure和S-measure的数值与检测效果成正比,而MAE数值与检测效果成反比。
3.1.3 实验细节
硬件配置:Intel®XeonE5-2650 v4@2.2 GHz×12 cores×2 CPU,NVIDIA TITAN RTX@24 GB×8 GPU,512 GB。
软件配置:按照已公开代码的默认参数进行设置,代码实现的软件平台如表2所示。
3.2 实验结果与分析
根据现有算法,对已公布代码或者检测结果的算法进行实验对比。如表2所示,一共17种算法,其中已公布代码的算法分别为CBCS[19]、ESMG[17]、SACS(-R)[20]、GICD[36]、TSEGAN[41]和ICNet[38],而已公布检测结果的算 法 分 别 为CSHS[18]、DARM[50]、RFPR[22]、LDAW[23]、ASPM[26]、IPTD[51]、AUM[52]、GW[30]、RCAN[34]、CSMG[27]、GCAGC[33]。
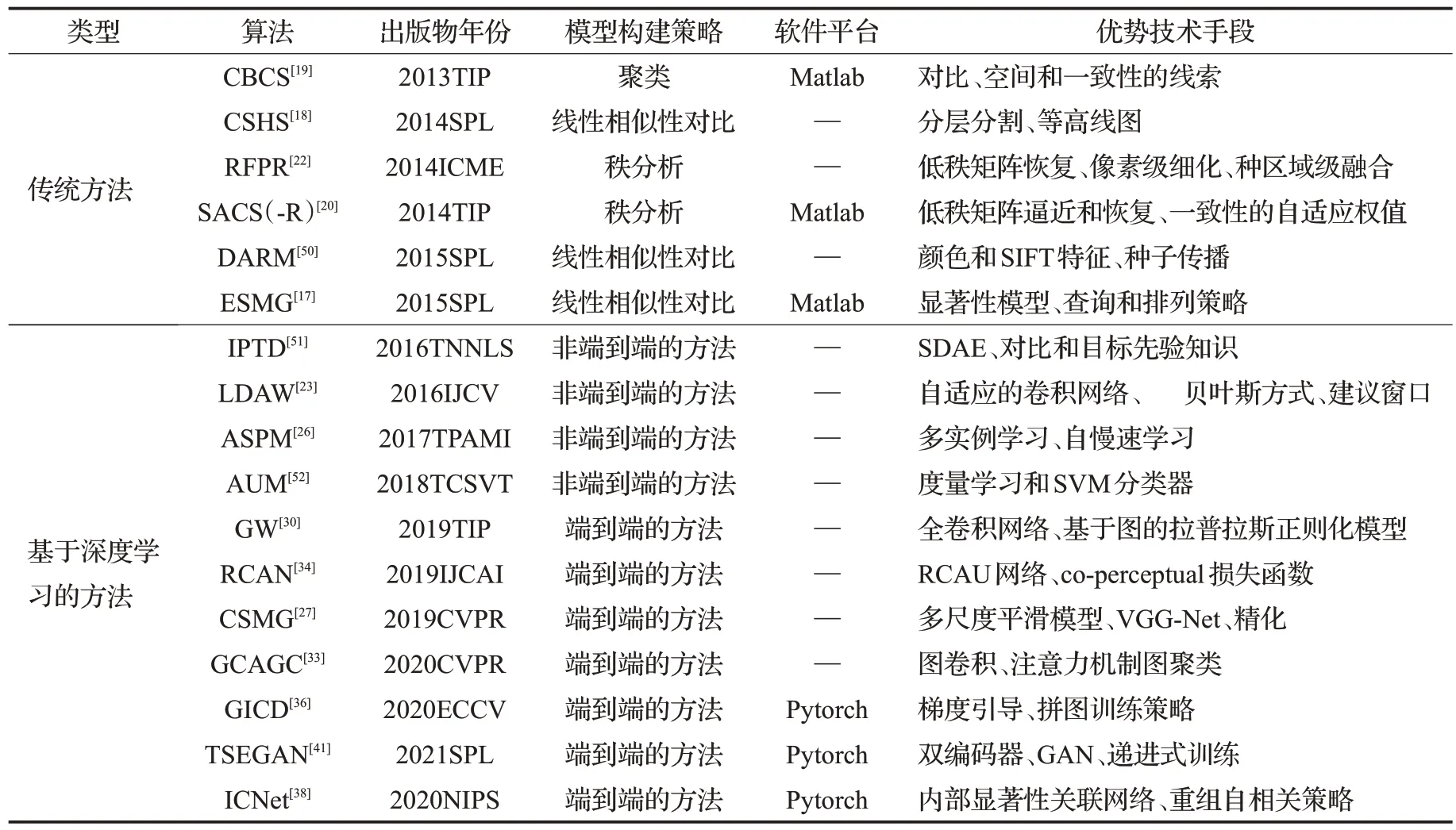
表2 对比的算法Table 2 Comparison algorithms
3.2.1 在iCoseg数据集上的实验结果与分析
将现有的流行算法在iCoseg数据集上进行主观和客观的对比。
在iCoseg数据集中,对14种流行算法进行主观对比,其中传统算法有7种,分别为CBCS、SACS、SACS-R、CSHS、ESMG、RFPR和DARM,基于深度学习的方法中,非端到端的算法3种,分别为IPTD、LDAW和ASPM;端到端的算法4种,分别为GCAGC、GICD、TSEGAN和ICNet。并由图2所示,展示了在iCoseg数据集上的三组检测结果,分别是:阿拉斯加棕熊、红袜队球员、风车。在前景和背景差异较大的红袜队球员和风车组中,端到端的方法检测效果最好,而非端到端的算法比传统方法在前景结构和边缘细节方面稍微强一点;但是在场景复杂的阿拉斯加棕熊组中,端到端的方法检测效果比较清晰,而另外两种类型的检测效果都不理想。

图2 在iCoseg数据集上的主观对比Fig.2 Subjective comparison on iCoseg dataset
此外,对上述的14种流行算法进行客观对比,如图3所示,深度学习的方法的自适应F-measure、最大F-measure和S-measure整体的值都比传统的方法稍微高一些,对于MAE而言,深度学习方法的值比传统方法的值低一些,再一次说明了基于深度学习的非端到端方法优于传统方法。

图3 在iCoseg数据集上的定量对比Fig.3 Quantitative comparison on iCoseg dataset
通过主观和客观实验分析可得:(1)基于深度学习的方法比传统方法性能好一些;(2)在基于深度学习的方法中,端到端方法比非端到端方法检测性能好。特别在背景复杂和前景、背景相似的情况下,更加展示了端到端方法检测性能的优越性。
3.2.2 在Cosal2015数据集上的实验结果与分析
将现有的流行算法在Cosal2015数据集上进行主观和客观的对比。
在具有挑战性的数据集Cosal2015上,文中展示了其中三组的结果,分别为飞机、苹果、斧子。对比的算法一共有13种,其中传统算法有4种,分别为ESMG、CBCS、SACS、SACS-R;基于深度学习的方法有7种,其中非端到端的方法有2种,分别为AUW和LDAW;端到端的方法7种,分别为GW、RCAN、CSMG、GCAGC、GICD、TSEGAN和ICNet。从图4中这三组的检测结果来看,基于深度学习的端到端方法检测最佳,基于深度学习的非端到端的方法次之,传统方法最差。此外,在苹果一组中,相比其他类型的算法,端到端的方法具有理想地区分前景和背景能力。例如,非端到端的方法在显著目标(苹果和柠檬)中无法区分公共显著的目标(苹果),而端到端方法GCAGC和ICNet能够区分出公共显著目标。

图4 在Cosal2015数据集上的主观对比Fig.4 Subjective comparison on Cosal2015 dataset
针对上述的13种流行算法进行定量对比,如图5所示,发现:从各种评价指标得分来看,基于深度学习的方法比传统的方法要好一些;在深度学习方法中,端到端的模型比非端到端的模型好。

图5 在Cosal2015数据集上的定量对比Fig.5 Quantitative comparison on Cosal2015 dataset
通过实验对比,并分析出以下两点:(1)再次验证了基于深度学习的方法整体优于比传统的方法,而在基于深度学习的方法中,端到端的方法比非端到端的方法检测效果更好;(2)在Cosal2015的评价指标得分整体比iCoseg差一些,说明了Cosal2015数据集比iCoseg数据集更具挑战性。
4 结语和展望
本文针对流行的协同显著性算法进行相关研究,一方面,根据采用特征类型的不同,将现有方法分为传统方法和基于深度学习的方法,并根据获取组间显著性策略和模型架构方式的不同,将两大类方法进行细分和介绍;另一方面,在两个公开的数据集上,对流行算法进行了主观和定量实验对比和分析。综合理论和实验分析,对现有方法进行了逐类分析和总结,如表3所示。此外,综合各类方法的表现,可得出以下两个结论:

表3 协同显著性检测方法的分类总结Table 3 Analysis of co-saliency detection methods
(1)基于端到端的方法检测性能优于其他类型的方法,是当前研究的主流。
(2)目前最佳性能的算法在Cosal2015数据集上的主要检测指标(S-measure)尚未达到90%,说明在公共显著目标的推理策略方面仍需突破性的研究。
虽然协同显著性检测方法近几年取得了不错的进展,但仍存在一些难点问题值得进一步研究。本文认为该领域后续可以在以下两个方面开展研究工作:
(1)针对目前协同显著性检测数据集的规模有限和人工样本标注的成本极高的问题,利用基于深度学习的弱监督和半监督的策略进行协同显著检测,来缓解当前样本的问题。比如,利用已公开带类别标签的数据进行弱监督的预训练,再用协同显著性的弱标签样本进行微调,最后进行协同显著性检测,通过弱监督方式降低对协同显著性像素级标签的依赖。
(2)缺乏一种适合协同显著性检测的评价指标,有效地衡量一组图像间协同显著性目标的关系。而当前的协同显著性检测评价指标(F-measure、S-measure、E-measure和MAE)都是针对显著性目标检测所设计的,只能对单幅图像进行显著性评估,未能有效地评估一组图像间公共显著目标的相似性。因此,如何为协同显著性检测设计合适的评价指标成为一个悬而未决的问题。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
电子制作(2019年24期)2019-02-23
西南交通大学学报(2018年5期)2018-11-08
北京航空航天大学学报(2018年1期)2018-04-20
中华皮肤科杂志(2018年4期)2018-01-22
China Geology(2018年3期)2018-01-13
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20
知识产权(2016年8期)2016-12-01
