
有遮挡环境下的人脸识别方法综述
2021-09-07 00:47徐遐龄田国辉于文娟肖大军梁陕鹏
计算机工程与应用 2021年17期
徐遐龄,刘 涛,田国辉,于文娟,肖大军,梁陕鹏
1.国家电网公司华中分部 华中电力调控分中心,武汉430077
2.南瑞集团(国网电力科学研究院)有限公司,南京211106
3.北京科东电力控制系统有限责任公司 研发技术中心,北京100192
人脸识别是通过抽取并对比分析人脸视觉特征信息进行身份鉴别的一种方法。具有可靠、操作简单和无接触等特点,已经成为生物识别领域活跃技术之一。由于深度学习技术在图像处理领域展示出了良好的建模和自动特征抽取能力,使得基于深度学习开展人脸识别相关问题的研究得到了广泛关注并取得较大进展[1]。尽管如此,多数人脸识别模型和算法大多仍是在受限条件下执行的,在遇到光线和姿态变化、图像分辨率低、存在遮挡等场景时的识别准确率仍需要进一步提高。例如,现实环境中采集到的人脸图像通常是多变的,微笑、愤怒、被口罩、墨镜、帽子等物体遮挡,人脸特征的位置也会随之改变,造成人脸固有结构缺失。特别是受新型冠状病毒肺炎疫情影响,关于口罩遮挡人脸识别和检测分析更是近期热门的研究方向。人脸关键特征的提取和对比是人脸识别算法的关键,特征是否完整非常关键,遮挡会造成特征损失、含有噪声和局部混叠等问题,阻碍人脸识别算法做出准确的决策。本文聚焦遮挡环境下基于深度学习技术的人脸识别方法的研究进展,针对存在遮挡导致的特征提取困难、模型复杂、数据集不够丰富等问题,介绍了基于深度学习技术的人脸识别常用模型和算法,对比分析了不同算法的基本原理、性能评价以及存在的问题,探讨了未来可能的发展方向。
当人脸在清晰可见、无遮挡环境之中,在深度学习技术和大量数据集支持下,其特征提取较为容易;如果遭到部分遮挡,不仅是被遮挡区域的特征会受到影响,整个脸部特征的提取都会受到影响。目前,减少未被遮挡区域的特征所受影响和修复被遮挡区域的固有特征是两种常用思路,它们分别从突出图像中的人脸区域和弱化图像中的非人脸的背景区域出发开展研究,并尽量扩大用于模型训练和测试的数据集来提高识别效果,下面进行详细介绍。
1.1 有效利用未被遮挡的人脸特征
当发生人脸信息遮挡时,可通过利用人脸其他未被遮挡部分的特征来辅助完成遮挡人脸特征提取,即根据被遮挡区域的邻域信息来补充、恢复和预测缺失区域的图像内容,再进行特征提取。常用的方法如下。
(1)提取人脸的属性特征
Yang等[2]聚焦人脸属性解决遮挡人脸检测的问题,提出了Faceness-Net模型并设计了一组属性感知的深度网络,如图1所示。算法首先抽取人脸局部特征,然后从局部到整体得到人脸候选区域,再对人脸候选区域进行识别。其特点是对各局部特征进行共享,对人脸属性特征进行分类提取,故当某部分被遮挡时,其他部分仍可被精确定位,网络参数量降低了83%,整体性能提升了近4个百分点,网络的稳定性较高,对环境有较强的应对能力,能够检测具有较大姿态变化的人脸,在性能、运行速率、召回率、平均精度等方面有优势。但是,模型需要的条件是人脸图片比较清晰,这样会减少训练难度,增强模型的稳定性。当被遮挡面积较大或人脸图片不够清晰时会对人脸评分带来困难,影响识别效果。

图1 Faceness-Net模型Fig.1 Faceness-Net model
(2)增强人脸可见区域特征
Wang等[3]采用Anchor策略和数据增强策略,构建了融合注意力机制的人脸识别网络FAN(Face Attention Network),如图2所示。在模型训练时,基于人脸尺寸为特征金字塔不同位置的特征图设置不同的注意力机制,即在RetinaNet的anchor上增加了Attention函数,通过多尺度特征提取、多尺度Anchor、基于语义分割的多尺度注意力机制,隐式地学到遮挡区域的人脸,提升了对于遮挡人脸的检测效果。训练的条件是数据集中人脸区域和遮挡区域的特征是混合在一起的。这样就会使得注意力机制会同时将人脸特征和人脸区域中包含的遮挡特征同时增强,且基于尺寸划分不同的注意力图的方法,并不能保证人脸被划分到合适的特征图上去,从而影响识别效果。

图2 FAN网络模型Fig.2 FAN network model
(3)改进损失函数强化特征
研究者针对基于深度模型开展人脸识别任务设计了一系列的损失函数,使得人脸识别得到更好的效果。例如,CenterLoss是通过Softmax[4]和L2范数[5],增大类间距离且同时减小类内距离,有利于预测值和真实样本之间误差减小。Liu等[6]提出了一种损失函数Angular Softmax实现在超球面上不同类别特征间的分离和同类别特征间的聚合。Liu等[7]提出了Arcface直接在角度空间中来最大化类内距离。Opitz等[8]设计了Grid Loss损失函数来综合局部和整体信息对分类的作用,增强了检测模型对遮挡的鲁棒性。如图3所示[8],该方法采用分块处理的思想,将人脸特征图分成若干网格,将每一网格的损失与整张图的损失求和作为总体损失函数,以强化每一网格的特征辨识性。实验结果表明:使用Grid loss函数可有效提升有遮挡环境下人脸的识别效果,在小样本训练时有更好的表现,训练难度不大,未产生大量额外的时间代价,可用于实时检测,稳定性较高;不足之处是仍存在难以应对大幅度姿态变化的问题,训练难度大,模型稳定性不高,且受损失函数的影响比较大。

图3 Grid LossFig.3 Grid Loss model
1.2 基于特征融合的方法
1.2.1 基于上下文信息融合的特征抽取
考虑到人脸的出现一般与身体其他部位相关联,Zhu等[9]利用人体上下文信息来辅助完成人脸识别,提出结合上下文的多尺度区域卷积神经网络CMS-RCNN(Contextual Multi-Scale Region-based CNN),如图4所示。CMS-RCNN提供了一种将全局和局部上下文信息相融合的方法,同时关注人脸区域的特征和人脸上下文信息,对多层特征图上的特征进行融合,形成一个长特征向量用于后续的分类,该类方法的识别准确率较高,不足之处在于各部分的特征权重分配和整合存在难点,速度较慢,也会影响模型的稳定性。虽然可以通过减少region的数量或降低输入图像的分辨率等方式提升速度,但效果并不明显。
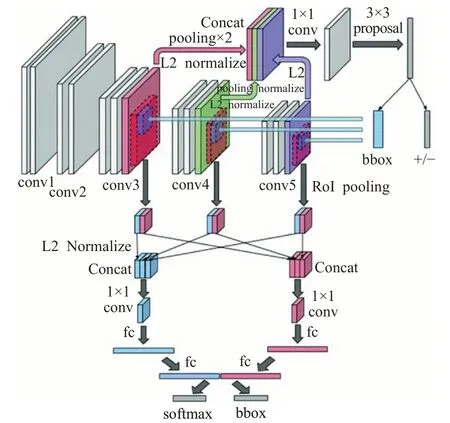
图4 CMS-RCNN模型Fig.4 CMS-RCNN model
2018年,Tang等[10]为更充分利用上下文信息,提出了人脸检测框架PyramidBox,如图5所示,PyramidBox采用基于锚点的上下文信息辅助方法来学习较小范围内的、模糊的和受遮挡的人脸的上下文特征;设计了一种底层金字塔网络来更好地融合上下文特征;提出了一种上下文敏感的预测模块(Context-sensitive Prediction Module,CPM),从融合的特征中学习到更准确的人脸位置信息和分类信息。同时,结合感受野模块(Receptive Field Block,RFB)[11]的特征增强(Feature Enhance Module,FEM)来更好地融合文本特征和人脸特征。由于FEM采用自顶向下的层间信息融合,在广度和深度方面可学习到更为有效的上下文和语义信息。在Wider Face验证集和测试集的结果表明提升了性能。该模型的稳定性是比较好的,采用融合特征也大大减少了特征位置对分类带来的影响。不足之处在于,当遮挡范围较大时,特征提取的效果会受到影响,且在一定程度上增加了模型训练的时间,模型训练的难度加大。

图5 PyramidBox框架Fig.5 PyramidBox framework
Zhu等[12]提出了有遮挡环境下的人脸关键点检测的自适应深度网络ODN(Occlusion-Adaptive Deep Networks),如图6所示。在该模型中,高层特征在每个位置的遮挡概率由可以自动学习人脸外观和形状之间关系的蒸馏模块(distillation module)来推断。遮挡概率被当作高层特征的自适应权重。同时,该方法利用低阶学习模块学习共享结构矩阵来恢复丢失的特征并去除冗余特征。首先,将残差学习块的特征图输入到几何觉察模块和蒸馏模块中,分别捕获几何信息并获得未被遮挡的特征表示。然后,将这两个模块的输出组合起来作为低阶学习模块的输入。蒸馏模块通过自动学习人脸外观和人脸形状之间的关系,推算出高层特征在每个位置的遮挡概率,作为高层特征的自适应权重,用来减少遮挡产生的影响并获得清晰的特征表示。由于需要采用推断的方法获得遮挡概率,使得高层特征的自适应权重的调整变化比较大,模型训练难度增加,稳定性也表现得比较弱。

图6 ODN框架Fig.6 ODN framework
1.2.2 多模态生物特征融合的方法
近年来一些多模态融合的深度神经网络模型也被提出[13-15]来应对复杂的外部环境造成的识别困难,通过设计融合算法将不同的生物特征进行有机结合,如掌纹与人脸特征相融合、指纹与声纹特征相融合、虹膜与指纹特征相融合等,以弥补单模态生物识别技术的安全风险。融合特征提取方法可以针对不同图像区域之间、多个特征提取方法之间以及多分类器之间的融合。肖珂等[16]采用梅尔频率倒谱系数的方法提取声纹特征,运用卷积神经网络提取人脸特征,再通过加权融合算法将它们融合。Liu等[17]提出了ConGAN来学习多模态数据的联合分布应用于人脸多属性图像和彩色深度图像。王卫民等[18]将多种卷积神经网络模型如ResNet、InceptionV3和VGG19提取的特征进行融合,并将融合后的特征应用到人脸识别中,据此训练出特征融合网络模型的网络参数,最后利用计算求出的阈值来区分类别。该模型的训练条件是要在线下特征提取,用Keras建模框架把多CNN特征融合方法建模并用数据集训练,训练集迭代1 000次,精度超过98.2%。Soodeh等[19]提出改进的退化条件下的人脸识别算法,使用极限学习机和稀疏分类器并将它们的输出进行融合,以获得最佳的识别率。Li等[20]提出了一种C2D-CNN(二维主成分分析-卷积神经网络),将从原始像素学习到的特征与CNN学习到的图像特征相结合,进行决策级融合,提高了人脸识别的性能。张琪[21]提出了虹膜与人脸和眼周融合的方法,基于加权加法对虹膜和人脸进行了融合,在特征层基于卷积神经网络对虹膜和眼周进行了自适应加权融合,在CASIA-Iris-M1-S2和CASIA-Iris-M1-S2两个库上进行,获得了比单模态识别更好的性能,优于直接将特征层串接融合、分数层加权加法的融合方法,且占用的存储空间较少、计算效率较高。Koo等[22]提出了一种基于面部和人体的多模态生物识别方法,并使用VGG-16和ResNet-50的网络结构来识别部分身体和不规则的人脸。但其网络结构需要通过增加网络层数来实现特征表示,导致其训练过程比较复杂,训练难度增大。
尽管目前有大量多模态融合的方法被提出用于进行人脸识别,它们仍需要进一步改进,尤其是在增强融合信息的判别性、减少信息的冗余性、跨层级融合以及动态融合等方面进行提升。模型的整体训练成本会增加,训练难度也随之提升。
1.3 对遮挡区域的特征修复和补全
深度学习方法可以通过不断学习图像的特征加深对图像的了解,围绕局部和整体两个方面对图像进行修复,增强内容纹理处理的连贯性,缓解大块缺失区域引发的修复困难。
Ge等[23]提出了局部线性嵌入式卷积神经网络LLECNN(Locally Linear Embedding CNN),探索使用人脸以外区域的信息对遮挡区域的特征尝试修复和补全的方法。如图7所示[23],它由大量图片构成人脸字典和非人脸字典训练出的最近邻来细化描述符,对遮挡造成的遮挡人脸信息进行补全和特征恢复,同时抑制特征中的噪声信息。Proposal Module级联了两个CNN网络,用于生成人脸候选区域及特征提取。候选区域的生成使用了P-Net,由三个卷积层和一个Softmax层组成。考虑到遮挡人脸检测难度较大,模型的训练条件是设置了较低的阈值,以生成较多人脸候选区域。然后,Embedding Module通过查字典的方式将被遮挡的特征区域及其特征恢复出来,并抑制特征中的噪声信息。Verification Module利用被修复的人脸特征进行人脸区域验证,同时对人脸位置和尺度的微调。该网络模型在遮挡数据集MAFA上的表现突出。但是,由于MAFA数据集对每个人脸还标定了多个属性,如mask type、occlusion degree,该模型目前尚未给出这些结果,模型的稳定性还在持续改进中。

图7 LLE-CNN模型Fig.7 LLE-CNN model
Chan等[24]提出了结合卷积神经网络与局部二值模式(Local Binary Patterns,LBP)的特征提取网络PCANet。该网络提供局部零均值化预处理以及PCA滤波器功能来提取主成分特征,并过滤图像中的遮挡。但当遮挡面积较大时,所得到的整体特征就会分布于为零值附近。李小薪等[25]提出局部球面规范化(Local Sphere Normalization)方法,并将其嵌入到PCANet的前两个卷积层之后,使局部区域特征值都位于同一个球面上,以此增强小特征值的作用,抑制较大特征值的影响,实现特征均衡化。模型对光照变化和遮挡等具有较强的鲁棒,不足之处在于较高的维度下,LSN的嵌入会影响PCANet模型的运行时间,且当遇到识别难度越高的测试集时,平均的运行时间会变大。
徐迅等[26]针对深度神经网络模型参数过多而容易引发过拟合等问题,结合GoogleNet和ResNet网络提出了Inception-ResNet-v1M模型,利用Triplet Loss损失函数学习人脸特征,以强化特征间的可区分特性,使得模型对遮挡、表情变化、姿态角度变化等干扰因素具有一定的鲁棒性。模型在遮挡率为20%~30%时,识别率能够达到98.2%。然而,当遮挡率大于30%的情况下,模型的效果受到很大影响。
Cai等[27]提出了基于半监督学习的遮挡感知生成对抗网络(OA-GAN)。通过对抗迁移的方式,将配对数据条件下学习的人工合成遮挡修复模型迁移到人脸自然遮挡修复任务中。如图8所示[27],发生器由遮挡感知模块和人脸修复模块组成。遮挡感知模块对带有遮挡的图片进行预测,得到一个遮挡掩码,这是该模型得以运行的前提条件。然后,将遮挡掩码与带有遮挡的人脸图像一起输入到发生器中,用于去除人脸的遮挡信息。另一方面,通过鉴别器中存在的对抗性损失来区分真实无遮挡的图像和通过去遮挡恢复后的人脸图像,以及属性保留损失,确保去遮挡的图像保留了原图像的属性。修复模块则采用非遮挡特征映射的编解码器体系结构,生成遮挡区域的纹理,来从输入的人脸图像恢复遮挡区域和非遮挡区域的合成人脸图像。鉴别器用于判断恢复后的人脸真伪,以及是否能够维持原人脸图像中包含的属性。由于该模型设计了一种交替训练的方法,实现了更好的网络收敛,减少了模型的训练难度。该方法在CelebA训练集中达到了较好的识别效果。

图8 OA-GAN模型Fig.8 OA-GAN model
Song等[28]根据人体的视觉系统注意力机制具有忽略被遮挡区域的性质,提出了基于掩膜的学习策略,来处理人脸识别中的特征损失,挖掘人脸遮挡区域和人脸特征的对应关系,并禁止被遮挡区域的特征参与相似度比对。作者设计了PDSN(Pairwise Differential Siamese Network)网络结构,如图9所示[28],由CNN主干网和掩膜生成器分支组成,CNN主干网负责提取人脸特征,掩膜生成器分支则输出布尔量掩膜特征,力争使经过掩膜处理后的特征尽可能相似,来保证识别的准确率。PSDN网络通过采集有遮挡和无遮挡人脸对在顶层卷积特征上的差异来建立掩膜字典,从而记录并学习得到被遮挡区域和受损特征之间的关系。当处理有遮挡的人脸图像时,从掩膜字典中选取关联项加以合并,并与提取人脸特征相乘,以消除特征损失的影响。其中,对人脸识别贡献小的特征给予更大的损失值,将遮挡人脸与未遮挡人脸间的特征差异作为评价特征元素是否被破坏的标志,使掩膜生成器更关注于被遮挡的区域。目前存在的问题是,由于掩码未知,只能保存最后的卷积层特征,因此对于大批量图像,特征占用空间大高。另外,比对速度较慢,除了比对时要计算相似度,还要进行特征提取过程,增加了模型训练的难度和时间成本。

图9 PSDN网络Fig.9 PSDN network
连泽宇等[29]针对复杂遮挡条件下人脸检测精度低的问题,提出了一种基于掩膜生成网络的遮挡人脸检测方法,通过屏蔽掉由局部遮挡引起的人脸特征元素损坏来提高检测精度。模型训练过程及相关条件是:首先,预处理人脸训练集,将训练人脸划分为25个子区域,并为每个子区域分别添加遮挡。接着,将一系列添加遮挡的人脸图像和原始人脸图像作为图像对,依次送入掩膜生成网络进行训练,以生成对应各个遮挡子区域的遮挡掩膜字典。然后,通过组合相关字典项生成与检测人脸遮挡区域对应的组合特征掩膜,并将该组合特征掩膜与检测人脸深层特征图相点乘,以屏蔽由局部遮挡引起的人脸特征元素损坏。在AR数据集和MAFA数据集上的实验结果表明,该方法在保持训练时间损耗低的同时,提高了检测的准确性。如何将算法扩展为三维遮挡人脸检测算法是作者正在研究的问题。
Dong等[30]提出了两阶段的遮挡识别模型,如图10所示,不同于通过一个生成对抗性网络来消除遮挡的做法,网络由两个生成器(即G1和G2)和两个鉴别器(即D1和D2)组成。其中G1用于分离遮挡(合成遮挡的图像),合成器G2用于合成去遮挡的图片,即G1首先分离出遮挡,再将其作为G2的输入来生成更精确的未遮挡图像。实验结果表明,合成的遮挡图像和去遮挡基本互补,合成的无遮挡图像与G1合成的遮挡高度相关,在PSNR(峰值信噪比)和SSIM(结构相似性)中都获得了更高的分数。由于采用两阶段处理的方法,会产生更多的时间开销,增加了训练成本。

图10 两阶段遮挡感知的GANFig.10 Two stage occlusion-aware GAN model
1.4 基于生成对抗网络的方法
由于生成对抗网络技术(Generative Adversarial Networks,GANs)在机器学习任务中获得了较好成果,由此也衍生出了基于GAN的生成模型,用于解决遮挡人脸图像修复问题。
Chen等[31]提出了对抗性有遮挡感知人脸检测器(Adversarial Occlusion-aware Face Detector,AOFD)。它基于生成对抗网络生成了大量遮挡人脸的样本,来扩充训练数据集,利用上下文信息来分割遮挡区域,通过分割的掩膜屏蔽遮挡区域对人脸特征的影响。由于AOFD是利用多阶段目标检测框架,该方法在一定程度上制约了检测速度,在训练条件上需要生成大量的遮挡样本,也增加了模型所需的训练时间和训练难度。
Zhang等[32]充分利用人脸周围信息训练GAN网络,提出了基于上下文信息的生成对抗网络(Contextual based Generative Adversarial Network,C-GAN),其生成网络由上采样子网和优化子网构成。其中,将低分辨率图像转为高分辨率图像并加以输出是由上采样子网完成的,人脸-非人脸、真实图像-虚假图像的鉴别是由鉴别网络完成,人脸的边框检测由回归子网进行完善。该模型适用于高分率图像的检测,否则需要对低分辨率进行采样,增加了模型训练的时间。
Najibi等[33]提出了SSH,通过滤波器对上下文信息建模,构建了选择性细化网络SRN(Selective Refinement Network)[34],如图11所示[33]。该网络将VGG网络的卷积层输出分为三支,每个分支的检测和分类流程都相似,通过分析不同尺度的特征图,完成多尺度的人脸检测,以优化检测性能,提升检测精度。然而,由于中间层的输出特征没有足够的辨别能力,需要对添加的分支进行足够的训练,这就加大了训练的难度,也增加了训练的时间。

图11 SRN网络Fig.11 SRN network
Zhang等[35]优化了SRN算法,产生改进的选择性细化网络(Improved Selective Refinement Network,ISRN)。Li等[36]基于PyramidBox模型,采用平衡数据锚采样策略(Balanced Data Anchor Sampling)、密集上下文模块(Dense Context Module)和多任务训练(Multi-task Training)得到PyramidBox++模型。ISRN检测到900张人脸,PyramidBox++检测出916张,算法在不损失速度的情况下提高了应对复杂人脸的检测精度。仅对小尺度人脸增强效果比较明显,模型的稳定性不够高,当逐渐增加人脸的尺度时,模型的训练难度增加,训练所需的时间也随之增长。
Pathak等[37]结合上下文,提出了一种编码器-解码器架构(Context Encoder-Decoder),来学习图像特征并生成图像待修补区域对应的预测图。如图12所示[37],损失函数由两部分组成:编码解码器部分的图像内容约束损失和GAN部分的对抗损失。其中的上下文编码器是一个AlexNet,GAN网络将编码器学习到的特征与原始特征对比,通过生成模型和判别模型相互促进,使得补全后的图像更具有真实性。由于模型仅判断修复区域的图像的真实性并不能保证修复区域和已知区域的一致性,当缺失区域形状多变时,会造成修复区域边界像素值的不连续性,产生模糊或不真实信息,这说明模型的稳定性不够高。作者后来通过增加边缘区域的权重值使得这个问题得到一定程度的解决。

图12 Context Encoder-Decoder网络结构Fig.12 Context Encoder-Decoder network
Song等[38]为了在修复过程中充分使用人脸特有结构的几何先验信息,提出了FCEN(Geometry-aware face completion and editing)模型,它利用人脸关键点热力图与分割图学习几何感知的人脸修复模型。如图13所示,其中关键点热力图由几个关键点组成,分割图由眼睛、鼻子、嘴巴、头发、背景等构成,不同的部件用不同的像素值表征。FCEN模型首先根据遮挡的人脸图像推理其对应的关键点热力图与分割图;然后将拼接后的遮挡图像、关键点热力图与分割图作为修复模型的输入,去生成遮挡区域的内容;最后在判别部分加入全局与局部判别器,促进生成人脸的视觉逼真感与整体连贯性。同时采用低秩损失函数来提高人脸修复模型对非规则遮挡物的修复性能。由此可以看出,该模型训练需要的条件是:首先获得人脸特有结构的几何先验信息才能开始修复,且构建热力图等使得模型的训练也有一定的难度。

图13 FCEN模型Fig.13 FCEN model
Nazeri等[39]提出一种由边缘生成器与图像修复网络组成的两阶段对抗模型Edgeconnect。如图14所示,边缘生成器恢复缺失区域的边缘轮廓,修复网络将恢复后的边缘图作为先验填充缺失区域,从而合成更精细的纹理与细节描述。然而,在实际的测试案例中,EdgeConnect并不能做到百分百还原真实的边缘信息,模型训练存在一定的难度,因为边缘生成模型有时无法准确地描绘高度纹理化区域中的边缘,或者当图像的大部分缺失时,就无法生成相关边缘信息的修复结果。研究者正在通过改善边缘生成系统,将该模型扩展到高分辨率修复应用之中。
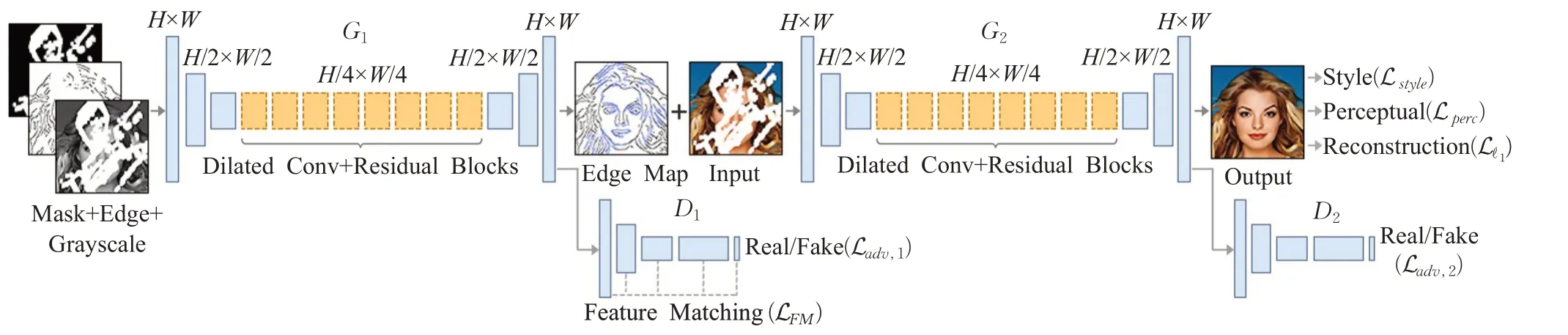
图14 Edgeconnect模型Fig.14 Edgeconnect model
武文杰等[40]为缓解遮挡部位与遮挡大小的限制,或修复后人脸图像不够连贯等问题,提出了改进的Wasserstein生成对抗网络方法。它将卷积神经网络作为生成器模型,并在对应层间加入跳跃连接来增强生成图像的准确性。在判别器中引入Wasserstein距离进行判别,并引入梯度惩罚来完善判别器。在CelebA人脸数据集与LFW人脸数据集上进行实验,结果表明该方法的修复效果良好。与通过引入额外的构建模块导致更多的网络参数,从而增加GPU内的方法不同,该方法通过加入跳跃连接的方法降低训练的难度,提升了性能。
1.5 轻量化网络模型
前面介绍的有遮挡环境下的人脸识别产生的较好的识别效果,多数是建立在大型深度卷积网络模型之上的,这需要大量的计算资源和性能高的处理器支持。在识别精度得到提高的同时,随之而来的就是效率问题,特别是不利于将模型移植到移动和嵌入式设备中使用。 效率问题主要是模型的存储和模型进行预测的速度问题。保存多层网络的大量权值参数对设备的内存要求很高,且在实际应用中,往往要求响应速度是毫秒级别,这就要求提高处理器性能,或者减少计算量。为了应对这些问题,调整深度神经网络结构和参数,使模型在速度和精度上取得平衡,在不显著降低模型性能的同时如何对深度网络进行模型压缩和加速成为了一个新的研究热点,出现了轻量化网络模型。轻量化模型设计的主要思想在于设计更高效的网络计算方式(主要针对主干网卷积),在减少网络参数的同时,不损失网络性能。构造轻量化神经网络的要求是参数少、速度快和精度高,以此模型训练的难度。
SqueezeNet(design strategies for CNN architectures with few parameters)[41]模型,如图15所示,使用1×11×1卷积代替3×33×3卷积,参数减少为原来的1/9;通过squeeze layers减少输入通道数量,将欠采样操作延后,给卷积层提供更大的激活图,保留了更多的信息,可提供更高的分类准确率。从模型结构上来看,SqueezeNet的核心为Fire模块,输入层先通过squeeze卷积层进行维度压缩,然后通过expand卷积层进行维度扩展。它在ImageNet数据集上获得了AlexNet(参数量为6 000万)级别的准确度,而网络参数减少了98%。结合模型压缩技术,不降低检测精度的同时,将原始AlexNet模型压缩至原来的1/500。模型产生较好效果的条件是要求数据集具有较好的平衡性,否则影响模型的稳定性。当数据集样本不平衡时,会影响分类结果。同时,需要权衡好两种卷积核的比例,这是模型在体积和精度之间选择的条件。

图15 SqueezeNet的Fire模块结构Fig.15 Fire module of SqueezeNet
Google提出的移动端模型MobileNet[43]采用了深度级可分离卷积(depthwise separable convolution),分解为两个更小的操作:depthwise convolution和pointwise convolution。标准卷积中卷积核是用在所有的输入通道上,而depthwise convolution则不同,它针对每个输入通道采用不同的卷积核,一个卷积核对应一个输入通道,pointwise convolution是普通的卷积,只不过其采用1×1的卷积核。Depthwise separable convolution首先采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,大大减少了计算量和模型参数量,模型训练难度不大,有较好的稳定性。MobileNet V1模型在细粒度识别中达到了Inception V3的效果,并且减少了计算量和尺寸。不足之处是损失了一定的精确性。
MobilefaceNets衍生于MobileNet V2,被认为是拥有工业级精度和速度的一种轻量级人脸识别网络,模型大小只有4 MB,专为人脸识别任务设计。它从三个方面改进了MobileNet V2。一是针对平均池化层,采用了可分离卷积代替平均池化层。二是针对人脸识别任务,采用ArcFace的损失函数进行训练。三是针对网络结构,通道扩张倍数变小,使用Prelu激活函数代替relu激活函数,以此减低模型的训练难度。在LFW人脸识别训练集的测试结果表明,模型训练难度不大,稳定性好,MobilefaceNets明显准确率更高,速度更快,体积更小。
ShuffleNet[44]使用逐点群卷积和通道混洗的方式降低计算成本,实现了比MobileNet V1更高的效率。ShuffleNet V2使用了Channel-Split模块,使得模型的性能进一步提高。模型如图16所示。模型的不足之处在于会产生边界效应,即某个输出channel仅仅来自输入channel的一小部分,对完整性和模型的稳定性有一定的影响。
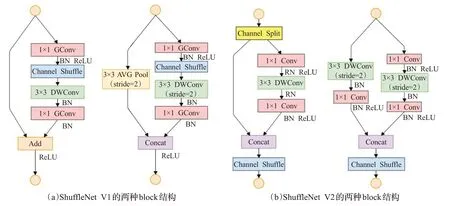
图16 ShuffleNet模型Fig.16 ShuffleNet model
张典等[45]提出了一种深度卷积神经网络模型Lightfacenet,目标也是构造轻量化神经网络单元,缓解深层的神经网络带来的参数冗余和计算量大的问题,降低模型的训练难度。它将深度可分离卷积、逐点卷积、瓶颈结构和挤压与激励结构相结合,再通过改进的非线性激活函数进一步提高网络识别的准确性。该模型在LFW数据集上达到了99.50%的准确率。非线性激活函数的选择是影响模型的一个条件。
徐先峰等[46]提出的IMISC-NN由一对结构相同、权值共享的CNN组成的孪生卷积神经网络构成,引入Inception模型来提取更加丰富的人脸特征,同时使用循环学习率优化策略来加快训练速度,用较少的全局循环可找到最优的学习率,降低了相同识别率所需要的迭代次数,减小了训练成本和难度,具有较好的收敛性。在CASIA-webface和Extended Yale B标准人脸数据库进行了训练与测试,能够达到较高的识别精度。但是,适用条件是目前仅适用于解决非限定性条件下的小规模数据集的人脸识别,说明模型的稳定性不高。
申建坤等[47]精简了原始的MobileNet V2网络结构,去除了原始网络中的残差块,来减少网络的卷积层数和网络的参数量。通过降低残差结构中的扩张系数,修改在通道扩张为并行扩张的方式,使网络具有较小的内存访问成本,增加实际的运行速度。最后,采用了空间可分离卷积与深度可分离卷积特征进行融合的方式,使二者在特征上可以进行相互弥补,提高识别精度。同时,改变了损失函数,将Softmax loss改变为Arcface,通过增加对网络的约束能力使得网络提取的特征更加具有可分性和鲁棒性,增加了模型的稳定性,同样训练条件下网络模型尺寸降低为2.3 MB,LFW的测试精度为99.53%,模型速度是MobileNet V2的5倍,训练难度进一步降低。
总的来看,基于深度学习的遮挡人脸检测算法在处理背景复杂、姿态多变的自然场景人脸检测问题方面具有优越性,在修复图像的真实性上都有较好表现,然而同样面临网络训练困难、训练的稳定性较差的问题。如何在不影响GAN网络收敛的情况下促使特征提取顺利进行,实现人脸去遮挡任务和人脸特征提取任务,是一个难题。另外,如何设计更有效的损失函数,使其能够精准指引训练进程、生成多样化样本仍是需要继续深化研究的问题。同时,面对新的移动和应用场景提供更好的模型,也是一个值得关注的方面。上述相关方法的分析对比如表1所示。

表1 相关模型比对Table 1 Comparison of related models
2 遮挡人脸检测常用数据集
一个数据完备、变化多样、标注良好的遮挡人脸数据集是测试和提升模型性能的基础。目前通用人脸数据集较多[48-50],然而针对遮挡人脸问题设计的数据集仍不够丰富。开源数据集有FDDB(Face Detection Data Set and Benchmark)[51]、AFW(Annotated Faces in the Wild,AFW)、AFLW、Wider Face[52]、300W(300 faces inthe-wild challenge)、MAFA和COFW[53]等。其中,FDDB、AFW、AFLW和300W是自然场景下的人脸数据集,场景比较丰富,适用于遮挡人脸检测问题,WiderFace、MAFA、COFW则是特别标注了人脸遮挡属性的数据集。下面逐一介绍。
(1)FDDB是人脸检测数据集和基准测试集,是一个关于人脸区域的数据集,用于研究非约束环境下人脸检测问题。数据集含2 845张图片,包含了大量遮挡、分辨率低、姿态各异等情况,并提供单独评分和连续评分两种评分方式。不同算法的评分值通过ROC曲线直观进行比较。
中国水利:我国粮食生产实现“十连增”,农田水利基础设施作用功不可没。请您谈谈今年农田水利建设开展的情况。
(2)AFW是早期为测评模型在自然场景下检测能力而提出的数据集,标注了矩形边界框,6个关键点及3种姿态变,仅有205张图片。由于数据量较小,常被用作测试集。
(3)AFLW数据集包含21 997张人脸和拍照环境变化较大的图片,数据丰富,用椭圆框、矩形框等进行了清晰的标注。
(4)300W数据集是一个人脸关键点检测数据集,并用于300W Challenge挑战赛的基准测试。由于数据来源多样,模型的泛化能力较好,已得到使用广泛。它包括AFW、LFPW、HELEN和IBUG四个数据集,人脸图像样本均为不受约束环境中采集得到的。每个人脸图像标记有68个关键点,训练集含3 146张图像。
(5)Wider Face数据集是从数据集Wider中选取了32 203个图像并进行了人脸标记,分为61个类。每一类别的训练、验证和测试集比例都是4∶1∶5。该数据集含有姿势和遮挡度变化较大的样本,且变换比较复杂,是目前开源数据集中检测难度大,数据多样性高的数据集之一。
(6)COFW数据集来自美国加州理工学院,是规模较小的遮挡检测数据集,包含1 852张含遮挡的注释人脸。其中训练集包含1 345张包未含遮挡的图片,测试集包含507张包含遮挡的图片,平均遮挡率约23%,其中329张图片被遮挡的点位超过30%,属重度遮挡,剩余的178张则是轻微遮挡。
(7)MAFA数据集由30 811个无遮挡和35 806个有遮挡图像构成,有多种不同的遮挡尺度,是目前专门用于人脸遮挡的数据集。数据集被人工标注了6种属性,分别是人脸位置、眼镜位置、遮挡位置、面孔朝向、遮挡程度和遮挡类型(单一颜色的人造遮挡/具有复杂纹路的人造遮挡物/人体遮挡及混合遮挡),可用于构建基于深度学习的复杂的遮挡人脸识别数据集,以及对模型的训练和优化中。
(8)WFLW[54]是基于Wider Face的一个用于人脸关键点检测的数据集,用于评估检测算法对大角度姿势、严重遮挡和复杂表情下的鲁棒性。训练集由7 500张标记有98个关键点的人脸图像构成,测试集含6个类别(姿态、表情、光照、化妆、遮挡、模糊子集),共2 500张图像。图像间在表情、姿势和遮挡方面差异较大。
常用人脸识别遮挡数据集信息如表2和表3所示。

表2 常用人脸识别遮挡数据集描述Table 2 Description of occlusion data sets for face recognition

表3 常用人脸识别遮挡数据集采样参数Table 3 Sampling parameters of occlusion data sets for common face recognition
3 常用评价指标
评估指标主要用于评估人脸识别模型的好坏,即评估训练好的模型在测试集中的准确率。较为常见的评估指标有:召回率、误识率、准确率、精准率以及ROC曲线等。
在二分类问题中,数据集的所有样本可以被分为两类,即正类(positive)和负类(negative)。当样本输入一个分类器后,会有以下四种情况:该样本属于正类且分类器也将该样本预测为正类,称为TP(True Positive);该样本属于负类但分类器将该样本预测为正类,称为FP(False Positive);该样本属于负类且分类器也将该样本预测为负类,称为TN(True Negative);该样本属于负类但分类器将该样本预测为正类,称为FN(False Negative)。表4列出了二分类的所有预测结果。TP+FP+TN+FN=样本总数。

表4 二分类预测结果Table 4 Prediction results of two types classification
准确率(Accuracy)是指在所有样本中可以被分类器正确分类的样本数量所占的比例。一般是用来评估模型的全局准确程度,定义如式(1):

精准率(查准率,Precision)是指当样本被分类器分类为正类时,其中确实为正类的比例。在人脸识别中,该指标越高说明误检越少,定义如式(2):

误识率FAR(False Accept Rate)或称为假正类率,指分类器将负类样本误判为正类样本的比例,定义如式(3)。FAR越低,人脸假冒者被接受的可能性越低,系统安全性越高。因此,它是衡量算法不正确接受,即无效输入的百分比。

召回率(查全率,Recall)指分类器分类正确的正类样本与所有实际为正类样本的比例,定义如式(4):

真正类率TPR(True Positive Rate)指正类样本被分类器正确分为正类的比例,定义如式(5):

真负类率TNR(True Negative Rate)指负类样本被分类器正确分类为负类的比例,定义如式(6):

假负类率FNR(False Negative Rate)指负类样本被分类器错分为正类的比例,定义如式(7):

为了能够评价不同算法的优劣,在Precision和Recall的基础上提出了F1值的概念,用来综合评价精准率和召回率。定义如式(8):

ROC曲线(Receiver Operating Characteristic Curve,ROC曲线,受试者工作特征曲线)。ROC曲线以FPR为横坐标,TPR为纵坐标所绘的坐标图。越好的分类器,ROC曲线就应该尽可能靠近图形的左上角。在人脸识别场景下,通常用它来评估模型的误识别水平。
AUC(Area under Curve)被定义为ROC曲线下的面积,介于0.1和1之间,作为数值可以直观地评价分类器的好坏,值越大越好。由于ROC曲线并不能清晰地说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好,正确率越高,因此常常使用AUC值作为评价标准。
如图17所示,红线(实线)是ROC曲线,黄色区域(阴影部分)表示AUC。

图17 ROC曲线和AUC区域Fig.17 ROC curve and AUC region
混淆矩阵又称误差矩阵,是一个全面评估模型的常用手段。把每个类别下,模型预测错误的结果数量或比例,以及错误预测的类别和正确预测的数量或比例都在同一个矩阵中显示出来,可方便直观地评价模型分类结果。
4 总结与展望
4.1 总结
基于深度学习的有遮挡人脸识别方法通过构建合适的深度网络结构和上下文相关信息的支持,并结合数据增强、锚框设计和损失函数设计等,对姿态变化和局部遮挡有较好的处理能力,在高速硬件的支持下算法检测速度和准确率亦可得到较大提升,有较好的环境适应性和鲁棒性。其不足之处在于:复杂的深度网络结构和过多的网络参数会导致遮挡人脸识别的计算量较大,训练难度加大,算力要求较高,相关测试数据集亟需扩充。
4.2 展望
(1)加强对基于深度学习的基础模型框架的创新及优化,支持更多移动端和嵌入式应用。这包括设计轻量型网络架构,发展高效的训练算法,使其能够部署在低成本、低功耗和低计算量移动设备、嵌入式设备的处理平台上,降低对硬件设备的要求。一是可以通过对训练好的复杂模型进行压缩得到小模型;二是直接设计小模型并进行训练和调优。
(2)优化损失函数,增加模型的稳定性。设计优良的损失函数,来最大化实现类内特征的聚合与类间特征的离散,以提升网络对于特异性特征向量的建模能力,减少模型收敛过程中的震荡,使收敛过程更加稳定。
(3)利用多模态生物特征,推进多特征、多模型、多算法的有机结合。持续探索人体生理特性(如指纹、指静脉、人脸、虹膜等)和行为特征(如笔迹、声音、步态等)的融合,充分发挥不同的生物识别技术在精度、稳定性、识别速度、便捷性方面的优势。一方面是加强对抗神经网络、注意力机制和多种信息融合等方面的探索,在保证检测精度的同时降低模型训练难度,更好地提升算法的鲁棒性。另一方面探索更精细的模态数据特征表示,使得多模态数据在语义空间上实现更好的信息交流。
(4)构建用于遮挡人脸检测的专门数据集和评测标准,以优化模型的训练,提高模型精度、鲁棒性和实时性,形成数据量大且具有姿势、光照、遮挡、尺寸等复杂变化的标注和属性准确描述的数据集也是未来的重要工作之一。由于包含遮挡等复杂场景的数据集不可能包含所有场景,故可结合半监督、无监督或迁移学习方法来进行探索。
(5)推进3D人脸识别研究,加强三维人脸数据集的建设。充分利用其稳定的空间几何信息,减少人脸在识别阶段因光照、视图的变化而导致的结果偏差。
猜你喜欢
作文中学版(2022年1期)2022-04-14
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年31期)2020-06-01
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2018年1期)2018-04-20
奇闻怪事(2014年5期)2014-05-13
