
一种基于特征表达的无人机影像匹配像对提取方法
2021-09-13 02:26任超锋赵丽华
科学技术与工程 2021年24期
杨 帅, 任超锋,赵丽华
(长安大学地质工程与测绘学院,西安 710054)
随着航空摄影测量、计算机视觉、传感器技术的快速发展,无人机(unmanned aerial vehicle,UAV)在获取影像的过程中机动灵活且成本较低[1],能够快速获取高分辨率的影像[2],在测绘地理信息、防灾减灾、农业估产、水利电力、交通等方面发挥重要作用[3]。如何快速、准确获取影像具有重叠区的潜在匹配像对,成为制约无人机影像三维重建完整性及效率的瓶颈问题。
基于内容的图像检索(content-based image retrieval,CBIR)方法在信息检索、数据查询、语音识别、图像分类、知识产权、视频分析和搜索引擎等领域具有广阔的应用前景[4]。而影像匹配作为三维重建最基础的环节,是实现无人机影像自动化处理的前提[5-6]。在传统的摄影测量数据处理流程中,必须首先已知相机的标定参数和规则的航带信息,以此进一步获取影像之间的匹配关系。而在计算机视觉领域,利用CBIR方法可以无须已知相机的标定参数和航带信息等先验信息,仅需要对图像进行处理即可获取影像之间的匹配关系,极大地简化了对无定位定姿系统(positioning and orientation system,POS)数据、影像排列不规则和数据量庞大的无人机影像数据处理流程。CBIR方法因其在数据处理过程中检索效率高、无须人工进行干预以及自动化处理水平高等优势,极大了提高航带自动重构和场景三维重建的效率,从而能够有效降低各种人力物力财力的投入,在滑坡地质灾害监测、三维城市建模、古文物建筑保护领域中得到广泛应用。
在影像匹配像对选择方面,文献[7-8]采用穷举法,利用互联网图片数据集上对影像进行两两遍历匹配,实现了一日之内构建罗马。穷举法时间复杂度最为可靠,但在处理海量无人机影像数据时计算量过于庞大且大多是无效计算,不具备实用性。闫利等[9]、李劲澎等[10]、姜三等[11]利用影像的POS数据、相机姿态参数和测区地面平均高程等先验知识,计算每张影像投影至地面的脚印图并粗略估计影像之间的重叠度,然后通过构建影像之间的关系图,获得影像初始匹配像对。由于该类方法计算量小,且对常规数据获取方式具有较好的适应性,因此是目前低空无人机影像匹配像对提取的主要方法。但是,由算法原理可知,该类方法高度依赖先验知识的准确性,必须提前获取测区的高程信息。当测区地形起伏较大,地形是高山、峡谷或者采用仿地、贴近飞行方式时,该类方法便无法准确地计算影像之间的相关性。任超锋等[12]利用影像初始地理位置信息,计算当前影像与其相邻影像的地理位置关系,进而采用固定阈值范围内的像对进行匹配,在一定程度上提高了匹配的可靠度和效率。但是,使用固定数目或固定比例的图像选择策略依然会导致大量的冗余匹配。Jiang等[13]提出了一种自适应词汇树检索算法,通过分析图像之间的拓扑连接结构并分析影像相似性的得分分布来获取影像之间的匹配关系,在一定程度上解决了倾斜无人机影像的匹配像对选择问题。
针对上述问题,利用提供了无人机影像位置信息的POS数据并通过对影像检索结果的相似性得分分布进行研究与分析,对常规的词汇树算法进行相应地改进,提出了基于空间距离加权的词汇树检索算法来实现有效的匹配像对选择。
1 算法原理
1.1 算法设计流程
本文算法设计流程如图1所示。①根据文献[14]的方法,利用SiftGPU算法快速地对一组原始的无人机影像进行尺度不变特征转换(scale-invariant feature transform, SIFT)特征的提取并组成SIFT特征向量集合;②对SIFT特征向量集合进行词汇树[15]构建;③检索所有影像,计算检索影像之间的相似性得分因子;④根据影像的POS数据计算反距离权重因子然后与相似性得分因子组合计算综合权重因子;⑤根据综合权重因子降序排列并自适应设置查询深度阈值,将阈值之前的查询影像与当前影像组合作为最终影像匹配像对。

Vi为视觉词汇;TF-IDF为词频-逆文本频率;IS为倒排索引权重因子;C为相似因子;W为权重因子
1.2 分层词汇树的构建
如图2所示,分层词汇树是通过分层K-means算法构建的树型索引结构。通过上述步骤得到的特征向量集合并对其进行构树,即利用K-means算法将特征向量集合划分为k个组,每组由特征向量集合中距离该组聚类中心最近的描述子组成。然后将该过程递归地应用到每组描述子向量中,从而将其划分为新的k个组,每层都重复上述过程,直至达到词汇树深度d。k的经验值一般取10[16-17]。

图2 分层词汇树示意图
1.3 影像检索
在词汇树中进行影像检索时,使用词频-逆文本频率(TF-IDF)[15]对影像进行加权计算。具体计算公式为
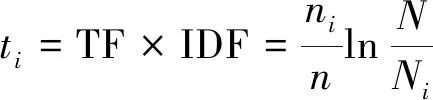
(1)
式(1)中:ti为第i个单词的权值;词频(term frequency,TF)表示某个视觉单词在影像中出现的次数,次数越多表示该视觉单词越重要;逆文本频率IDF为影像总数量和包含该单词的影像数目比的对数,是该单词重要性的度量;ni为查询影像包含视觉单词i的影像数量;n为查询影像包含所有视觉单词的影像数量;N为影像总数量;Ni为影像数据集中至少有一个包含视觉单词i的图像数量。
当词汇树创建完成后,每张影像则可以表示为加权后不同视觉单词的组合。为了测量两张影像视觉单词向量q和d之间的相似性,通过构建检索数据库,采用影像检索系统中的倒排索引方法,对不同的视觉单词计算对应权重ω,然后采用式(2)计算其相似性得分因子s(q,d)。
(2)
1.4 综合权重因子
如图3所示,空间距离上越近的影像具有重叠区的可能性越高,若将影像之间的空间距离作为影响因素参与评价,则可大大提高两者之间的相关性。

图3 反距离权重因子

(3)

(4)
1.5 查询深度阈值
查询深度是指以综合权重因子为依据,在影像集合中查询出与当前影像相似性最高的前Q′张影像,组成待匹配像对,如图4所示。
图4中,查询影像Vi与查询深度Q共组成Q′对像对进行匹配。实际处理过程中Q过小会造成漏检,而Q过大则会引入大量无效匹配像对,降低匹配效率。因此。采用查询深度阈值的方式对查询深度进行分割,仅将阈值前的影像与查询影像组成匹配像对进入匹配环节。阈值计算公式为

图4 查询深度阈值
(5)
式(5)中:以类间方差最大为原则,将查询深度Q内的影像分为前景与背景两部分;N1为属于阈值t之前的影像数量;w1为属于前景的影像频率;w2为属于后景的影像频率;μ1为阈值t之前影像的综合因子平均值;μ2为阈值t之后的影像综合因子平均值;g为前景影像与背景影像之间的类间方差。
在查询深度内,类间方差最大对应的位置即为查询深度阈值,可表示为
(6)
式(6)中:g(t*)为查询深度因子;t为初设查询阈值。
1.6 检索评价指标
通过查准率Pprecision和查全率Rrecall评价该算法的准确性和完整性。通过特征提取时间和影像检索平均时间评价算法的效率。查准率通过计算查询深度内正确的查询影像N与查询深度Q的比值构成。查全率则通过计算查询深度内正确的查询影像N与穷举法匹配中得到的所有正确影像数量M比值构成,可分别表示为
(7)
(8)
2 实验与结果分析
2.1 实验数据
为了检验本文算法的效率与适用性,分别对不同地形地貌的无人机影像数据进行试验。如表1所示,记录了5组试验无人机数据集的详细信息。
数据A为江西省黄背村的无人机影像,地形以山地丘陵地为主。数据B为贵州省鸡场镇坪地村岔沟组的山体滑坡无人机影像,数据采用变高方式获取,地形以高山地形为主。数据C为贵州省鬃岭镇滑坡无人机影像,数据采用等高与贴近摄影两种方式获取,其中滑坡体采用贴近方式获取。数据D为甘肃省盐锅峡镇的单相机影像数据,飞行航线以折返方式模拟双相机,地形以平原为主。数据E为陕西省高明乡平罗王村的五相机倾斜影像,地势平坦地形起伏较低。
本文算法的采用Visual Studio C++2015的OpenCV 3.2计算机视觉库,基于Windows 10 64位操作系统进行算法编写。电脑配置为CPU i7-8700 3.2 GHz,内存64G DDR4,硬盘256G SSD,显卡为NVIDIA RTX 2080 8 G。
2.2 特征提取结果分析
分别利用OpenCV SIFT算法和SiftGPU算法对4组(每组200张)不同分辨率无人机影像进行特征提取耗时统计实验。从表2可知,经过图形处理器(graphics processing unit,GPU)优化的特征提取时间有了明显缩短,加速比达到2~36倍,且影像分辨率越高,加速比越大。原因是SIFT算法提取特征的多量性、特征向量的高维性以及算法本身的复杂度较高,在CPU上实现的SIFT算法处理速度慢,利用SiftGPU算法提取图像特征则可以大大提高计算效率。同时,SIFT算法提取单张原始的无人机影像特征点数量都超过上万,而过多的特征点必将极大增加后续构建词汇树的时间,降低了影像检索效率。

表2 不同影像分辨率SIFT特征提取平均耗时
2.3 匹配像对提取结果分析
设置每张影像提取的特征点数量为1 000。构建词汇树每层聚类中心数量k取10,构树深度d取5。构建词汇树的影像从数据集中随机提取,其数量设置为影像总数的20%,且最大影像数量不超过500幅。然后依次对表1中的5组影像进行构树检索实验。构树完成后,如图5所示,依次对5组数据集中的查询影像进行检索实验,得到查询影像的待匹配像对。

分辨率:1 269×842

表1 试验无人机数据集
图6展示了5组数据集中部分影像检索结果前20幅。从检索结果来看,数据集B、数据集C和数据集E前20幅影像均为正确影像。数据集A和D中前20幅影像共检索得到正确影像分别为14幅和12幅,错误影像6幅和8幅。其中,数据集A中影像重叠率不够导致查询阈值设置过大,故检索出较多错误影像。因SIFT算子不具备完全仿射不变性,故对数据集D(倾斜影像)的检索结果不理想。

黄色框为查询影像;红色框为错误检索影像;其余为正确影像;分辨率:1 269×791
2.4 匹配像对提取完整性分析
如图7、图8所示,分别利用SIFT、SURF[16]、ORB[17]和SiftGPU算法对表1中的5组数据集进行词汇树构树,计算查询影像的查准率和查全率。
从图7、图8可以看出,5组数据集查准率与查全率基本呈反比关系,查准率提高,则查全率下降。表1中的5个测试数据集,从数据类型方面可分为两类:正射类型、倾斜类型。其中,数据集A、B为正射类型,数据集C、D、E可归为倾斜类型。在对正射类型影像进行检索时,本文算法计算查询影像的查准率和查全率基本与SIFT算法和ORB算法相当且均高于SURF算法。在对倾斜类型影像进行检索时,本文算法计算查询影像的查准率和查全率与SIFT算法依然表现最好,ORB算法其次,SURF算法最低。原因是SIFT算法在一定程度上对影像抗仿射不变性表现高于其余两种算法。
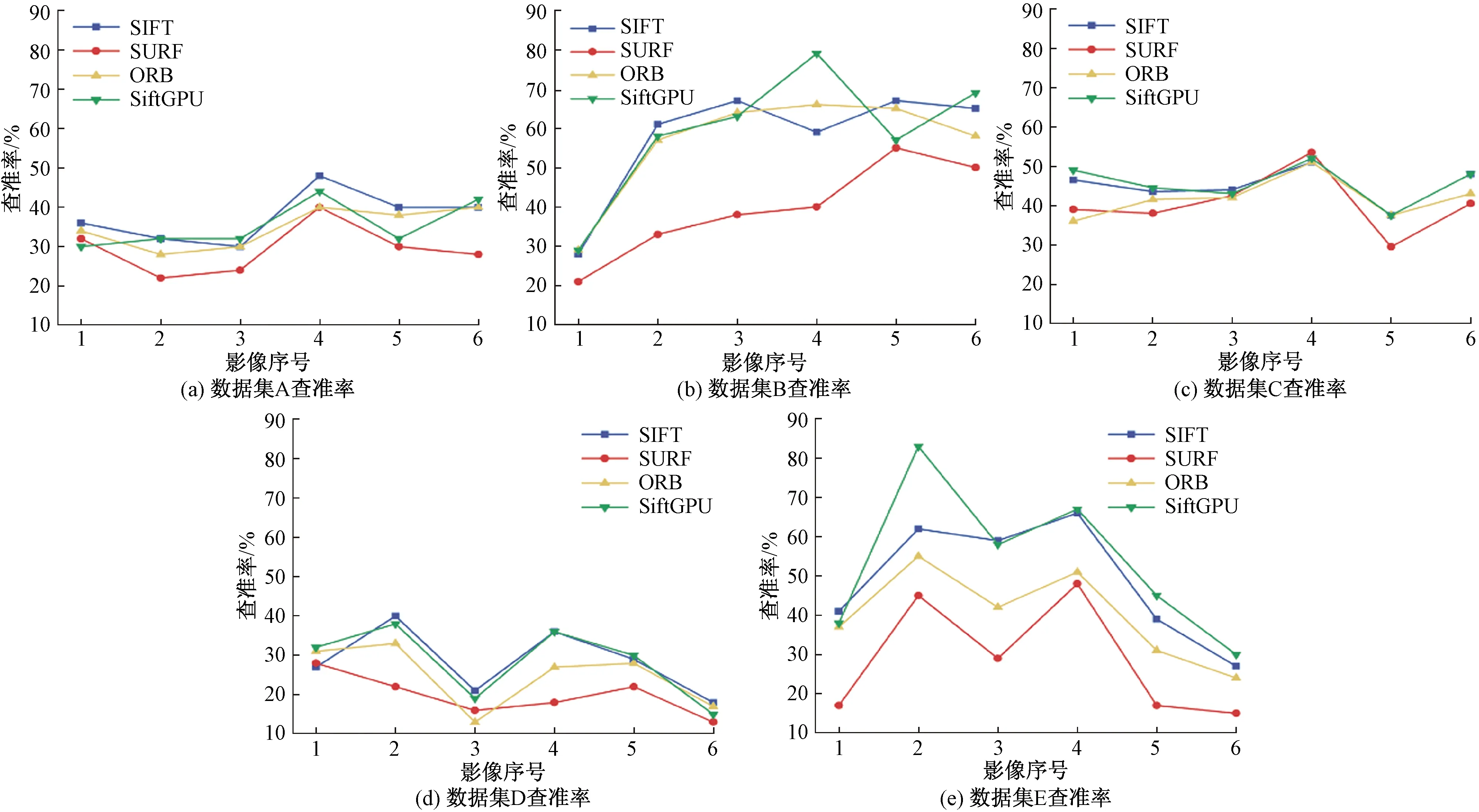
图7 5组数据集的查准率

图8 5组数据集的查全率
为进一步分析影像检索的准确率与查询深度Q的关系,从数据集C、数据集D和数据集E中各抽取一张影像进行检索实验,计算查询深度分别为100、200时影像的查准率与查全率,统计结果如表3所示。
通过综合权重因子进行影像检索因为考虑到影像的空间地理位置,在不同查询深度下计算得到的查准率与查全率结果均明显优于相似因子。在查询深度为100时,数据集C、数据集D和数据集E查准率分别提高了20%、19%和24%,查全率分别提高了19.2%、30.9%和17.4%。
为了分析综合权重因子与相似因子的检索计算详细过程,从数据集B中提取一张影像分别在综合权重因子模式和相似因子模式下进行检索得到的评价因子曲线进行说明,结果如图9所示。
如图9所示,综合权重因子曲线和相似因子曲线都能检索出绝大部分正确影像。两种评价因子在曲线前端具有明显差异,后端则趋于平坦,不具有明显的可区分性。在相同的查询深度阈值条件下,综合权重因子检索得到的正确影像数量比相似因子更多。因此,采用综合权重因子进行检索计算,其正确的检索影像大部分集中在查询曲线的前端。
2.5 算法效率分析
表4中,特征提取时间与影像数量成正比,检索时间随着特征点数量的增加而增加。穷举法和本文算法具有相同的特征提取时间,但本文算法平均检索耗时与穷举法相比要低两个数量级。总体而言,利用穷举法获取的相似影像其检索结果和本文算法检索结果相差不大,但检索效率远远不如本文算法。

表4 两种方法检索耗时对比
3 结论
提出了一种快速提取无人机影像匹配像对的方法。通过选取5种不同类型的影像数据进行试验。得出如下结论。
(1)本文算法具有较高的适用性。不需要相机参数、不受地形条件限制即可自动完成无人机影像匹配。
(2)本文算法能有效提高查询影像的准确率。与一般的词汇树检索算法相比,数据集C、数据集D和数据集E查准率分别提高了20%、19%和24%,查全率分别提高了19.2%、30.9%和17.4%。
(3)本文算法具有较高的计算效率。本文算法与穷举法相比,平均检索耗时要低两个数量级。尤其针对海量的无人机影像数据,本文算法具有更高的处理效率。
将进一步通过引入其他特征提取算子或对词汇树算法进行修改,使本文算法能够更好地适应倾斜影像。
猜你喜欢
建材发展导向(2021年19期)2021-12-06
临床骨科杂志(2020年1期)2020-12-12
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
现代电子技术(2018年20期)2018-10-24
现代情报(2018年11期)2018-01-07
科技视界(2014年25期)2014-04-27
中国管理信息化(2009年10期)2009-06-19
