
基于深度学习的无人驾驶汽车车道线检测方法
2021-09-13 02:28李昭健
科学技术与工程 2021年24期
高 扬,王 晨,李昭健
(1.长安大学汽车学院,西安 710000;2.长安大学汽车学院,西安 710000;3.汽车运输安全保障技术交通行业重点实验室,西安 710000)
无人驾驶汽车是一个集环境感知、路径规划、系统控制等功能于一体的综合系统[1]。车道线作为一种交通标志,约定了汽车的基本行驶规范。因此对车道线的检测是无人驾驶技术的关键。
已有车道线检测方法大致可分为:基于特征的方法,基于模型的方法及基于深度学习的方法[2]。基于特征的车道线检测方法,主要是利用车道线与路面及其周边之间的纹理、灰度值、梯度变化以及边缘等特征差异,通过阈值分割,将车道线特征信息从图片中分离出来[3]。刘源等[4]提出了一种基于边缘特征点聚类的车道线检测方法。赵岩等[5]提出了一种基于轮廓筛选的车道线检测方法,提取车道线特征点进而拟合车道线。王智宇等[6]提出了一种改进随机抽样一致算法的车道线识别方法。这种类型的算法对噪声比较敏感,且易受到车道线遮挡及破损的影响,鲁棒性较差。
基于模型的方法原理是将车道线检测问题简化为求解模型参数问题[7]。根据路面的特征将车道线转换为几何模型,然后通过霍夫变换、随机抽样一致(random sample consensus,RANSAC)算法和最小二乘法[8]获得该模型的参数来拟合对应的车道线。Cai等[9]建立一种高斯统计颜色模型在感兴趣区域提取车道线颜色,利用改进的霍夫变换检测车道线。这种方法建立在特定几何模型基础上,通过分析道路图像中的目标信息来确定相应的模型参数,实时性好并且抗噪声强,对于车道线被遮挡、路面存在干扰的情况具有较好的鲁棒性。但是单一道路模型难以适应现实中复杂的道路线形与种路况,因而模型的选择和参数的求解是问题的关键[10]。
深度学习类方法的基本思想是通过搭建一个深层神经网络模型来实现车道线检测,然后使用大量数据对网络进行训练,使其自动提取车道线特征进而实现车道线的检测。Tripathi等[11]提出了使用带有过拟合特征的滑动窗口将车道检测为单独的类别。Li等[12]在使用深度学习方法进行车道线检测时将图像的空间结构信息融入神经网络。
VGG(Visual Geometry Group)网络模型由牛津大学团队提出[13],主要探究卷积神经网络深度与其性能之间的关系,在特征提取和迁移学习任务中经常被使用。针对车道线检测问题,基于VGG神经网络,引入特征图上下文信息融合算法,提出VGG-FF车道线识别网络,为进一步提升算法的识别能力,引入空洞卷积,提出VGG-FFD车道线识别网络,并在公开数据集和自制数据集上对所提方法和网络进行了验证。
1 特征图上下文信息融合方法
在图像分割领域,传统卷积神经网络通过一定大小的卷积核对输入图像进行不断卷积来提取特征进而实现物体之间分割[14]。网络在进行特征提取时,卷积层生成的特征图不经任何处理被输入下一个卷积层来继续卷积提取更高特征,这样并没有充分利用特征图中行和列之间的关系。
特征图上下文信息融合方法由行特征信息融合模块(Fusion_cow模块)和列特征信息融合模块(Fusion_column模块)组成,两个模块分别负责特征图中特征在行与行之间和列与列之间的融合,如图1所示。
图1为N=1的Fusion_column模块,其中N为该模块的一个超参数(N=1~n/2任意值,n不超过列信息宽度),表示列特征信息融合宽度,即当对某列特征进行信息融合时,需要加上该列向左和向右宽度为N经一维卷积后的列特征,图1中Old Feature Map表示进行列特征信息融合之前的特征图(原始图像卷积之后的特征图),New Feature Map表示列特征信息融合之后的特征图。如图1所示,宽为W,高为H的特征图在进入Fusion_column模块之前被分成W个宽为1,高为H的列特征。对特征图中任意第h行,w列特征进行列特征信息融合,有融合式(1)~式(3), 其中,式(1)定义了第1列的融合操作,式(3)定义了第w列的融合操作;式(2)定义了其他列的融合操作。

红色表示一系列列特征;绿色竖条表示当前需要进行信息融合的列特征;黄色竖条代表经一维卷积后列特征
FC(h,w)=C(h,w)+C(h,w+1),
w=1;h=1,2,…,H
(1)
FC(h,w)=C(h,w-1)+C(h,w)+C(h,w+1),
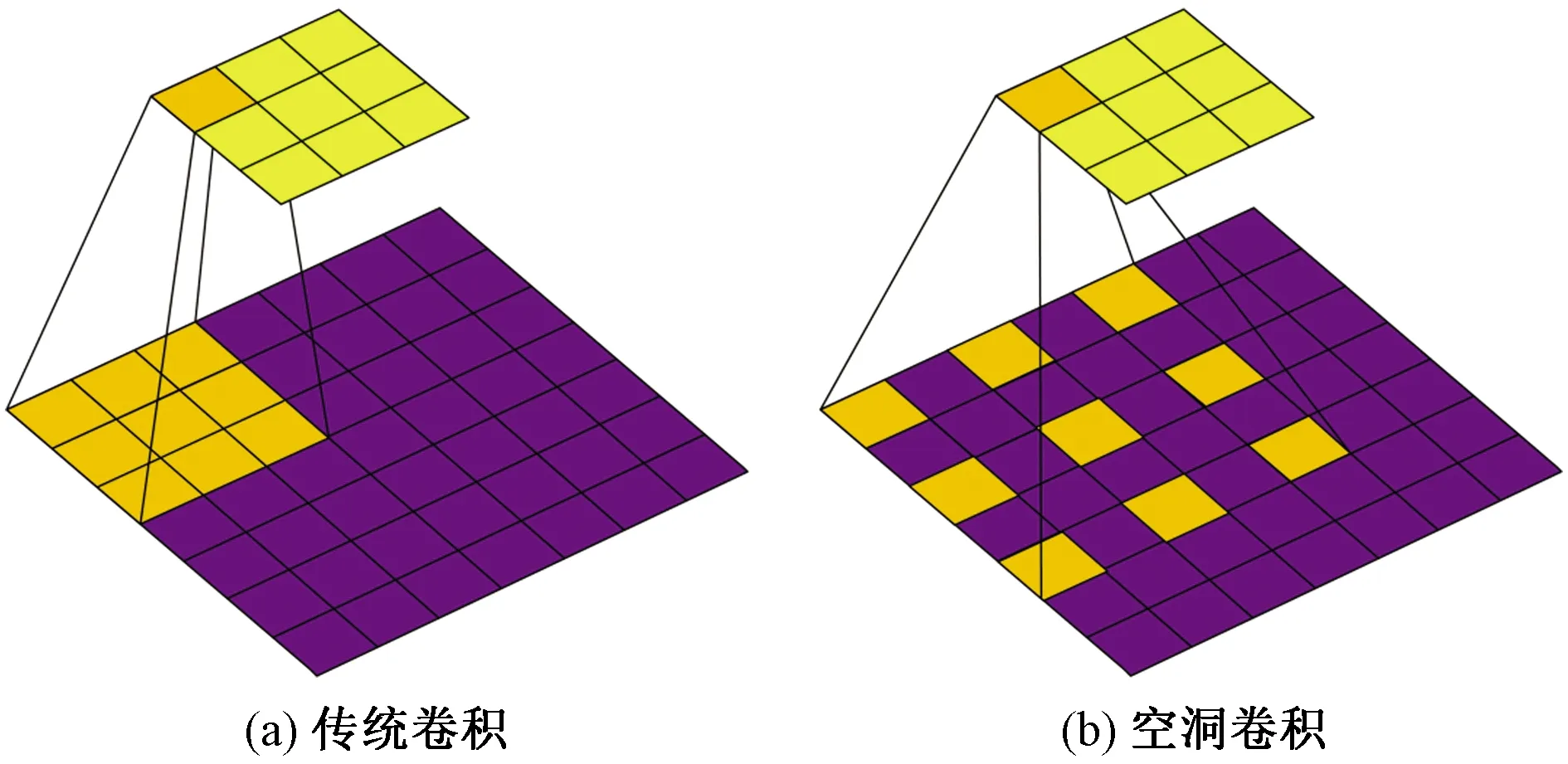
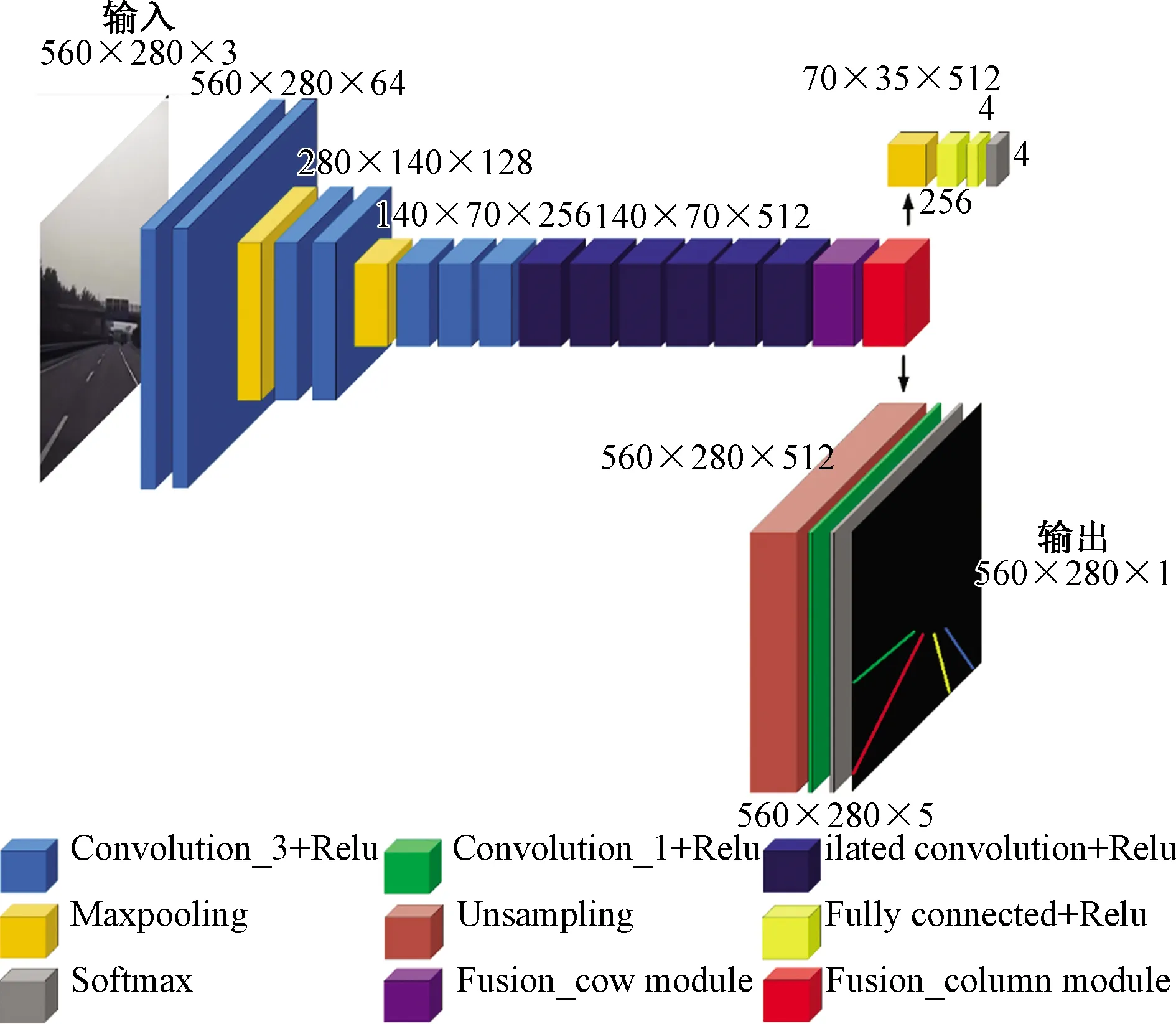
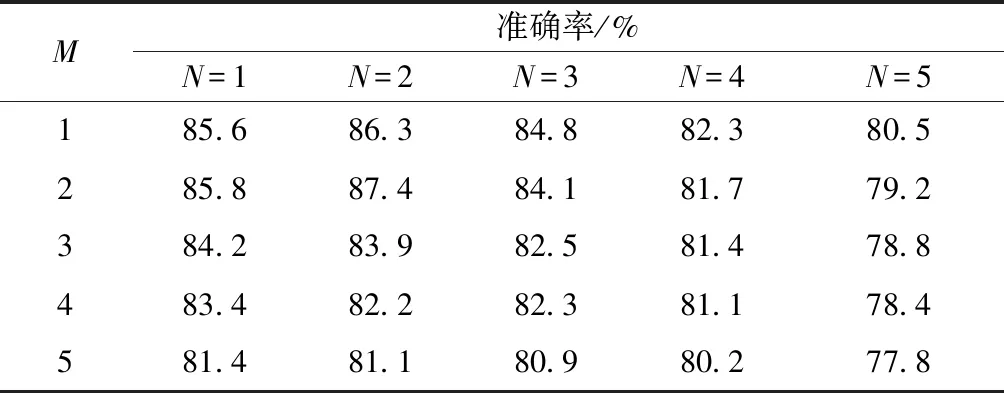
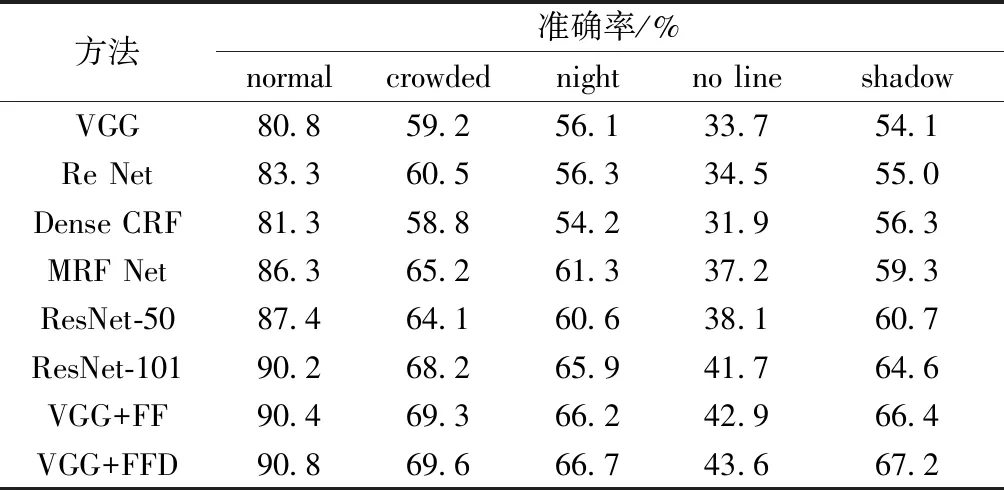
1 (2) FC(h,w)=C(h,w-1)+C(h,w), w=W;h=1,2,…,H (3) 式中:FC(h,w)表示第h行、w列特征执行列融合后获得的特征;C(h,w)表示第h行、w列特征经一维卷积后特征。 同理,为实现特征图中特征在行与行之间融合,Fusion_cow模块进行了相似的设计。图2为M=2的Fusion_cow模块,其中M为该模块的一个超参数,表示行特征信息融合高度。与列融合类似,对特(M=1~m/2任意值,m不超过行信息宽度)征图中第h行、w列特征进行行特征信息融合,有融合式(4)~式(6),其中,式(4)定义了第1行、第2行的融合操作;式(6)定义了第H-1行、第H行的融合操作;式(5)定义了其他行的融合操作。 图2 Fusion_cow模块 FH(h,w)=H(h-1,w)+H(h,w)+H(h+1,w)+H(h+2,w), h=1,2;w=1,2,…,W (4) FH(h,w)=H(h-2,w)+H(h-1,w)+H(h,w)+H(h+1,w)+H(h+2,w), 2 (5) FH(h,w)=H(h-2,w)+H(h-1,w)+H(h,w)+H(h+1,w), h=H-1,H;w=1,2,…,W (6) 式中:FH(h,w)表示第h行、w列特征执行融合后获得的特征;H(h,w)表示第h行、w列特征经一维卷积后特征,当h=0或h=H+1时,H(h,w)=0。 式(7)、式(8)分别为Fusion_cow、Fusion_column 模块对所有通道的特征图中每个像素点进行信息融合时的表达式,X(c,h,w)表示c通道、第h行、w列的像素点,Y(c,h,w)表示执行融合后的c通道、第h行、w列的像素点,H表示特征图高度(行融合),W表示特征图宽度(列融合),K表示一维卷积核的尺寸,A(c,1,w)表示c通道一维卷积核w列的权重,f为卷积层的激活函数(采用线性整流函数即Relu函数)。 Y(c,h,w)= (7) Y(c,h,w)= (8) 在经过行信息融合和列信息融合方法处理后的特征,每个像素都可以接收到来自相邻行和列像素的信息,丰富了每个像素的表达信息,更加有利于车道线检测,所以将特征图上下文信息融合方法与特征提取网络模型VGG13和改进的VGG13网络模型相结合进一步提出VGG-FF车道线识别网络。VGG-FF网络结构如图3所示,它由特征提取网络VGG13、Fusion_cow、Fusion_column模块和车道线数目预测分支和车道线分割分支组成。VGG-FF的特征提取网络由13个卷积层和3个池化层组成。该网络输入为RGB的道路图像,每个卷积层中卷积核的大小为3×3,激活函数为Relu,每个池化层中池化核的大小为2×2。这里将VGG13输出特征称为顶层特征,顶层特征输入Fusion_cow模块进行行特征信息融合,将行特征信息融合完成后的特征图输入Fusion_column模块进行列特征信息融合,融合完成后生成的新顶层特征图将分别进入两个分支:车道线数目预测分支;车道线分割分支。车道线数目预测分支用于预测当前输入图像中车道线的数目,设定车道线数目预测分支最多只预测4条车道线,因此车道线数目预测分支输出单元为4。车道线分割分支用于根据所提取的特征对车道线进行语义分割。由于网络的输出是和输入图像宽、高相同的单通道图像标签,在进行语义分割前需要进行上采样,使新顶层特征图大小与输入图像大小一致。使用双线性插值方法对特征图进行上采样。 Input为输入;Output为输出;Convolution_3+Relu为卷积;Convolution_1+Relu为卷积;Maxpooling为最大池化;Unsampling为上采样;Fully connected+Relu为全连接;Softmax为softmax逻辑回归;Fusion_cow module为行融合模块;Fusion_column module为列融合模块 为了进一步提升算法的识别能力,设计了VGG-FFD 车道线识别网络,它在VGG-FF的基础上,增加了空洞卷积。常规下采样操作如图4(a)所示,它虽然具有缩小图片尺寸增大感受野的功能,但必然会损失较多的信息,空洞卷积可以在不进行下采样操作的基础上增加卷积核的感受野[15],空洞卷积工作原理如图4(b)所示,可以看出,同样一个3×3的卷积,却可以达到5×5卷积的感受野。 图4 传统卷积和空洞卷积 VGG-FFD网络结构如图5所示,可以看出,将空洞卷积与VGG-FF特征提取网络结合时,将最后一个池化层pool3去除,在conv7~conv12的6个卷积层使用空洞卷积代替原来的普通卷积。 图5 VGG-FFD 为了更好地检验所提出算法的性能,采用车道线数据集CUlane[16]进行验证研究。 4.1.1 超参数选取实验 为了选取合适的超参数M和N,设计了M、N在不同取值时的对比实验。将数据集的规模缩小为原来的1/8进行实验,表1为M和N在不同取值组合下的模型准确率。 表1 M和N在不同取值时的模型准确率 从表1可以看出:当超参数M=2和N=2时模型的表现最好,原因在于:特征图中距离较近的像素点间相关性更大,在进行信息融合时有利于增强像素点的信息表达能力,而特征图中距离较远的像素反而在进行信息融合时可能带来干扰信息。因此后文实验中,设置M=2和N=2。 4.1.2 车道线识别网络对比实验 为验证本文算法的有效性,将所提出的 VGG-FF 和VGG-FFD车道线识别网络与VGG、ReNet等先进车道线检测方法进行比较,仿真中各算法对比时采用了相同的参数设置。 如表2所示,在正常环境(normal)拥挤环境(crowded)夜晚(night)无车道线(noline)和有阴影环境(shadow)下将各检测方法进行比较,可以看出,在正常环境的数据集下,VGG-FF分别优于 MRF Net 模型和ResNet-101模型4.1%和0.2%,VGG-FFD分别优于MRF Net模型和ResNet-101模型4.5%和0.6%。在有阴影的数据集下,VGG-FF分别优于ResNet-50模型和ResNet-101模型5.7%和1.8%,VGG-FFD分别优于ResNet-50模型和ResNet-101模型6.5%和2.6%。证明了本文方法的有效性。 表2 各算法在CU Lane数据集上的准确率对比 为验证VGG-FFD车道线识别效果,在自制的车道线识别数据集上进行了实验验证。图6分别给出了车道线图像的原图、标注图、VGG-FFD 方法识别图,绿线、红线、黄线和蓝线表示车道线,第1列表示正常环境,第2、3列表示有汽车遮挡环境,第4列表示有阴影环境,第5列表示车道线数目变化环境。由第2、3列可以看出在车道线存在遮挡时,VGG-FFD仍然实现了较好的识别;第4、5列可以得出在车道线数目发生变化时,VGG-FFD同样实现了较好的车道线识别,证明了VGG-FFD车道线识别网络的有效性。 background为背景;left为左侧;right为右侧 (1)针无人驾驶汽车中的车道线识别问题展开研究,基于VGG神经网络,引入上下文信息融合方法,提出了VGG-FF车道线识别网络。进一步引入空洞卷积,设计得到的VGG-FFD车道线识别网络在识别成功率上有良好的表现,与已有方法相比,在正常环境和有阴影环境等方面识别效果均有提升。 (2)所提出的网络在车道线检测成功率上表现不错,但模型整体偏大,模型运行速度不高。因此如何在提高精度的同时尽可能减少推算时间,是需要进行深入研究的问题。
2 VGG-FF车道线识别网络

3 VGG-FFD车道线识别网络
4 基于数据集的实验验证
4.1 基于公开数据集的实验验证
4.2 基于自制车道线数据集的实验验证

5 结论
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25中学生数理化(高中版.高考数学)(2022年3期)2022-04-26汽车实用技术(2022年5期)2022-04-02卫星应用(2021年11期)2022-01-19北京航空航天大学学报(2021年9期)2021-11-02电子制作(2019年13期)2020-01-14电子制作(2019年11期)2019-07-04电子制作(2019年11期)2019-07-04当代陕西(2019年10期)2019-06-03北京航空航天大学学报(2018年1期)2018-04-20
