
融于图像多特征的路面裂缝智能化识别
2021-09-13 02:28陈健昌张志华
科学技术与工程 2021年24期
陈健昌,张志华*
(1.兰州交通大学测绘与地理信息学院,兰州 730070; 2.地理国情监测技术应用国家地方联合工程研究中心,兰州 730070; 3.甘肃省地理国情监测工程实验室,兰州 730070)
传统人工路面裂缝识别,存在效率低,主观判断性强等因素,容易产生较大误差。路面裂缝自动识别技术使用机器自动识别无人工干扰,工作效率高,是当前路面裂缝识别领域主流手段。
20世纪80年代出现路面裂缝自动识别技术[1],在随后二十多年中,该技术得到了极大发展,其中出现了基于直方图统计和形状分析算法[2]、多级去噪模型算法[3]、图像自动匀光[4]、数学形态学算法[5]、基于小波的路面裂缝检测算法[6],这些算法存在设备要求高、易受外界环境干扰、图像预处理操作复杂以及误差不确定性等缺点。邱延峻等[7]基于多特征检验对三维沥青路面裂缝检测。先原始裂缝图像进行尺寸降维、灰度校正、高斯滤波。之后,对截面进行倾斜度、高斯分布、边缘梯度3种特征检验。最后,根据路面粗糙度高低,变化高斯分布相关参数,实现裂缝检测。研究结果表明准确率达89.19%。谭卫雄等[8]基于改进人工蜂群算法(artificial bee colony, ABC)和反向传播(back propagation, BP)神经网络对沥青路面路表裂缝识别。利用改进的ABC算法优化BP神经网络权值与阈值,建立混合神经网络路面裂缝识别算法,实验结果表明,准确率、召回率和综合评价指标都超过了95%。但路面裂缝在复杂背景或背景差异小的环境下错误率较高。所以传统路面裂缝图像识别方法与鲁棒性存在缺陷。封筠等[9]基于多级卷积神经网络对沥青路面裂缝图像进行筛选,将AlexNet作为一级筛选网络,Visual Geometry Group(VGG)16或ResNet50作为二、三级筛选网络,具有较好检测效果。Tong等[10]采用卷积神经网络对路面裂缝进行识别,结果表明与传统算法相比更具稳定性;Cha等[11]基于深度学习对裂缝进行识别,结果表明在环境条件较差的情况下与传统边缘检测算法相比精度更高,适用性更强;沙爱民等[12]基于卷积神经网络的路表病害识别与测量,设计了多个卷积网络对路面病态进行识别分类;李楠[13]基于深度学习框架Caffe的路面裂缝识别研究,对图像裂缝和完整进行分类,取得了良好的实验效果。Ni等[14]将GoogLeNet和ResNet-20进行网络模型整合用于路面裂缝的识别,但是对于较小的裂缝识别效果并不理想,由于网络过于复杂导致识别速度缓慢。虽然基于深度学习对路面裂缝识别应用广泛,但这些神经网络结构设计比较复杂、参数较多、测试精度较低、耗时长。因为原始路面图像有很多影响裂缝识别的干扰因素,如标线、噪声、图像亮度等,对这些干扰因素经过图像处理后,由于模型训练需要大量样本,所以这些图像仍存在误差不确定性。
针对上述问题,提出将路面标线作为图像特征,图像样本种类分为有标线有裂缝、有标线无裂缝、无标线无裂缝和无标线有裂缝,这样便消除路面标线干扰。对图像进行切割分块,将分块后图像进行双线性内插上采样得到训练样本,使用神经网络提取图像特征训练模型。
1 深度学习框架
深度学习是机器学习的一个分支,以神经网络为架构,对数据特征进行学习的算法,可从低层次的特征得到高层次特征。深度学习假定某一学习过程可以分为多个层次,代表对观测数据的多层抽象,不同层和层的规模可用于不同程度的抽象。研究深度学习的过程在于模仿人脑学习的过程,通过不断地注入数据特征提高学习能力[15-16]。深度学习框架众多,如深度神经网络、卷积神经网络(convolutional neural network,CNN)、深度置信网络、递归神经网络等。因为卷积神经网络具有良好的特征提取能力和泛化能力,在图像处理等领域取得了巨大的成功[17]。路面裂缝作为图像目标特征可直接输入卷积神经网络以特定方式输出,卷积神经网络还具有背景噪声滤波能力[18-19],可消除路面图像中的噪音以及低对比度问题,所以对路面裂缝图像识别的研究将基于卷积神经网络。卷积神经网络由卷积层、池化层、全连接层构成,根据需要可设置多个相关层提高算法精度[20]。
TensorFlow由谷歌人工智能团队开发和维护,拥有多层级结构,可部署于各类服务器、PC终端和网页并支持图像处理器(graphics processing unit, GPU)和张量处理单元(tensor processing unit, TPU)高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究。TensorFlow框架具有高度灵活性,可移植性,科研与产品联系性,自动求微分,多语言支持,性能最优化等特征[21-22]。因此选择TensorFlow框架进行路面裂缝图像识别研究。
2 研究方法
原始图像尺寸较大,将整个图像作为训练样本输入模型训练,会增加计算机运算负载。此外,裂缝在整张图像中所占面积较小神经网络无法完全提取裂缝特征,因此需要对原始图像进行裁剪。裂缝是图像中极为敏感区域,为避免裁剪图像时裂缝边缘化,保护图像主体,所以优化图像行列像素能量图,尽量降低小区域内裂缝被裁剪。图像裁剪为较小分辨率图像后,需要对其上采样凸显裂缝便于神经网络提取特征学习。使用双线性插值法进行图像上采样,根据采样点周围4个像素灰度值,在两个方向进行线性内插,综合两个方向线性内插结果。假设要求函数f在(x,y)处的值,其中f未知,M11(x1,y1)、M12(x1,y2)、M21(x2,y1)、M22(x2,y2)在函数f中的值已知,首先在X方向差值,M12、M22插入(x,y2),M11、M21插入(x,y1),差值公式为
(1)
(2)
之后在Y方向插值求出(x,y),计算公式为
(3)
卷积神经网络由输入层和隐含层组成,输入层为常见的输入数据;隐含层由卷积层、池化层、全连接层组成。卷积层是卷积神经网络中最重要的一层,主要通过卷积运算来计算图像的特征[23],包含所带权重的卷积核,通过一组深度数相同的卷积核对原图像特征进行卷积计算。卷积核的高度和宽度要比原图像小得多,经过一组卷积核后,可从图像中提取不同特征。M表示卷积层输入,M∈RW×H×C是三维数据,W表示图像宽度,H表示为图像高度,C为图像深度,mi∈RW×H为图像特征图。输出层N∈RW1×H1×C1也是三维数据,分辨率由W×H转为W1×H1,个数由C转为C1,从输入到输出的表达式为
(4)
式(4)中:i为通道数;wp,i为卷积核,其中p为卷积核尺寸;*为卷积运算。
池化层的主要作用是减少特征图的维数,降低数据量,防止过拟合,包括平均池化操作和最大池化操作,在进行池化操作时只针对相邻像素,最大池化为该像素区域最大值来代替该区域所有像素值,平均池化为该区域平均值代替该区域所有像素值。全连接主要操作是矩阵乘法,把一个特征的空间线性转化为另一个空间特征,全连接层连接前层所有神经元,在经过卷积,池化之后,全连接层将特征向量映射输出,同时起到分类器的作用,并针对分类样本输出合适的分类值。激活函数主要用于非线性分割,增强神经网络各层之间的非线性关系,这样神经网络就可用于非线性模型中。本文模型使用的是ReLU激活函数,可使神经网络很稀疏,提高计算效率,具有收敛速度快,防止梯度消失,减少过拟合以及参数相互依赖性等特点,输出公式为
(5)
随着硬件性能不断提升,为提高模型精度,神经网络层数也与之增加。然而网络层数据的增加太多则出现梯度爆炸、精度降低等问题。ResNet网络模型的出现可解决这个问题,输入x对应特征提取函数为H(x),W(x)为特征提取函数与输入x之差,可表示为
W(x)=H(x)-x
(6)
利用残差学习特征,通过不断训练模型提取特征,将残差结果不断趋向于0,模型训练精度保持稳定。
使用softmax函数计算样本类别概率,选概率最大的作为预测结果,每类样本概率的计算公式为
(7)
式(7)中:k为类别数量;yn为输入之前的值;ym为输出概率。
损失函数Loss是计算训练样本真实标签与预测标签之间的差距。使用交叉熵计算各分类损失,能评估真实样本与预测样本之间差距。通过扩大预测样本与错误样本之间的差距训练模型进而提高算法性能,可表示为
(8)
式(8)中:p为真实样本;M为总样本数;N为批次样本数;q为i样本预测为j的概率。
3 实验过程及结果
3.1 实验环境装置
计算机处理器为CPU i9,内存32 GB,显卡RTX2080,操作系统为Windows10系统,卷积神经网络在TensorFlow深度学习框架下实现,使用Python编程,还嵌入matplotlib,OpenCV,numpy,PIL等类库。
3.2 实验数据分类
实验数据来源于甘肃省高速公路路面图像,数据真实可靠。路面图像中最基本和明显的特征是图像中的标线,路面裂缝。过去对于裂缝识别的算法,首先要剔除标线干扰因素,再进行路面裂缝识别,这个过程比较烦琐同时还有很多不确定性因素。本文方法是直接将标线作为一个特征要素,和路面裂缝特征一起训练,这样减少了前期对路面图像预处理工作。
通过人工筛选从高速公路路面图像选取有标线有裂缝图、有标线无裂缝图像、无标线无裂缝图像、无标线有裂缝图像各2 000张组成路面图像样本库。原始采集图像尺寸较大如图1所示,需要对其裁剪扩大裂缝在其图像中所占面积比例,进而突出裂缝在图像中特征便于网络模型提取。通过双线性内插法对裁剪图像上采样,增大图像尺寸。之后对图像进行去噪处理,统一背景值,消除采集图像时噪声和光照产生的误差。从裁剪图像样本库中每种类型各挑选2 000张图像作为训练样本,500张作为验证样本,随机从4类样本图像中各抽取500张,将该2 000张图像打乱顺序作为测试样本用来测试模型精度、评估模型性能,实验流程如图2、图3所示。

图1 原始图像
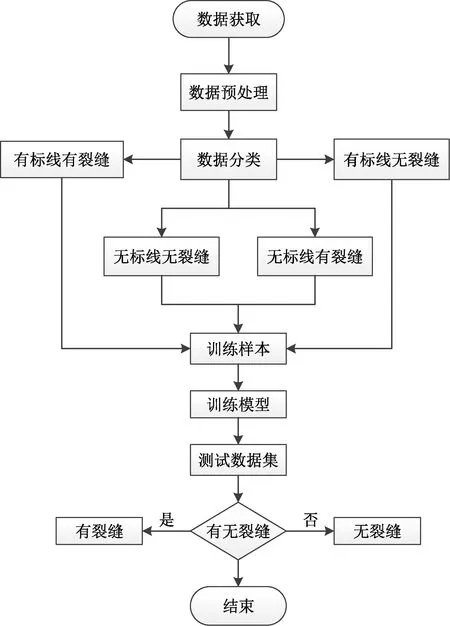
图2 实验设计流程图

图3 实验过程图
3.3 实验结果分析
使用ResNet101网络架构进行路面裂缝识别,学习率设置为0.001,共训练40个epoch,每训练10个epoch保存一次模型,并对保存模型进行精度测试,训练验证损失函数如图4所示、训练验证模型精度如图5所示。训练到第10个epoch时模型开始收敛,训练精度和损失函数逐渐趋向稳定,此时训练损失函数为0.425,模型训练精度为0.87;训练至第40个epoch时,训练损失函数为0.257,模型训练精度为0.897。

图4 训练和验证损失函数

图5 训练和验证模型精度
使用准确率accuracy、精确率precision、召回率recall、调和均值F及Kappa系数来评估各模型性能,其计算公式分别为
(9)
(10)
(11)
(12)
(13)
式中:TP为正类样本预测为正样本数量;FP为负类样本预测为正样本数量;FN为正类样本预测为负样本数量;TN为负类样本预测为负样本数量;pe为实际样本数量与预测样本数量乘积之和与样本总数平方比值。
由于模型在10个epoch开始趋向收敛,所以在其前后epoch模型精度差距较大。如表1、表2所示,precision 1、recall 1、F1分别为路面存在裂缝图像精确率、召回率、调和均值,precision 2、recall 2、F2分别为路面无裂缝图像精确率、召回率、调和均值,随着训练epoch增加两种样本各项评估指标均提高,训练到第40个epoch时,模型对路面裂缝图像识别精确率达到0.91,召回率为0.883;无裂缝图像精确率为0.883,召回率达到0.913;两种样本调和均值分别为0.869、0.876。模型测试精度在第10个epoch和第20个epoch之间提升0.033,Kappa系数提升0.05,两种指标与其他训练区间epoch相比提升幅度较大。训练至第40个epoch时,模型测试精度达到0.898为保存模型中最高,Kappa系数为0.815模型已处于理想分类识别效果。

表1 保存模型精度评估

表2 保存模型精度评估
将图像作为训练样本输入AlexNet、VGG19、GoogleNet、ResNet50、文献[24]和文献[25]以及机器学习支持向量机(support vector machine, SVM)、邻近算法(K-nearest neighbor, KNN)、随机森林进行训练得到模型,分别对测试数据集进行路面裂缝识别,各模型性能评估如图6~图9所示,深度学习模型训练均为40个epoch时,ResNet101各项评估指标均为最高,其次是GoogleNet,模型测试精度为0.887,Kappa系数为0.797,较为复杂裂缝识别效果较好,而对于不明显的裂缝识别效果没有ResNet101表现理想;由于网络结构相对较少图像特征提取能力较弱,ResNet50模型测试精度为0.863,Kappa系数为0.759,两项指标均与ResNet101相比有明显差距,与VGG19和AlexNet模型测试精度相比ResNet50具有优势,特别是对于较小裂缝的识别。与文献[24]、文献[25]中的算法相比,所使用的ResNet101网络结构模型测试精度和Kappa系数均有显著提高。机器学习模型中测试精度最高的是SVM算法达到0.795,但与深度学习算法相比模型测试精度差距较大。

图6 各模型精确率、召回率、调和均值对比
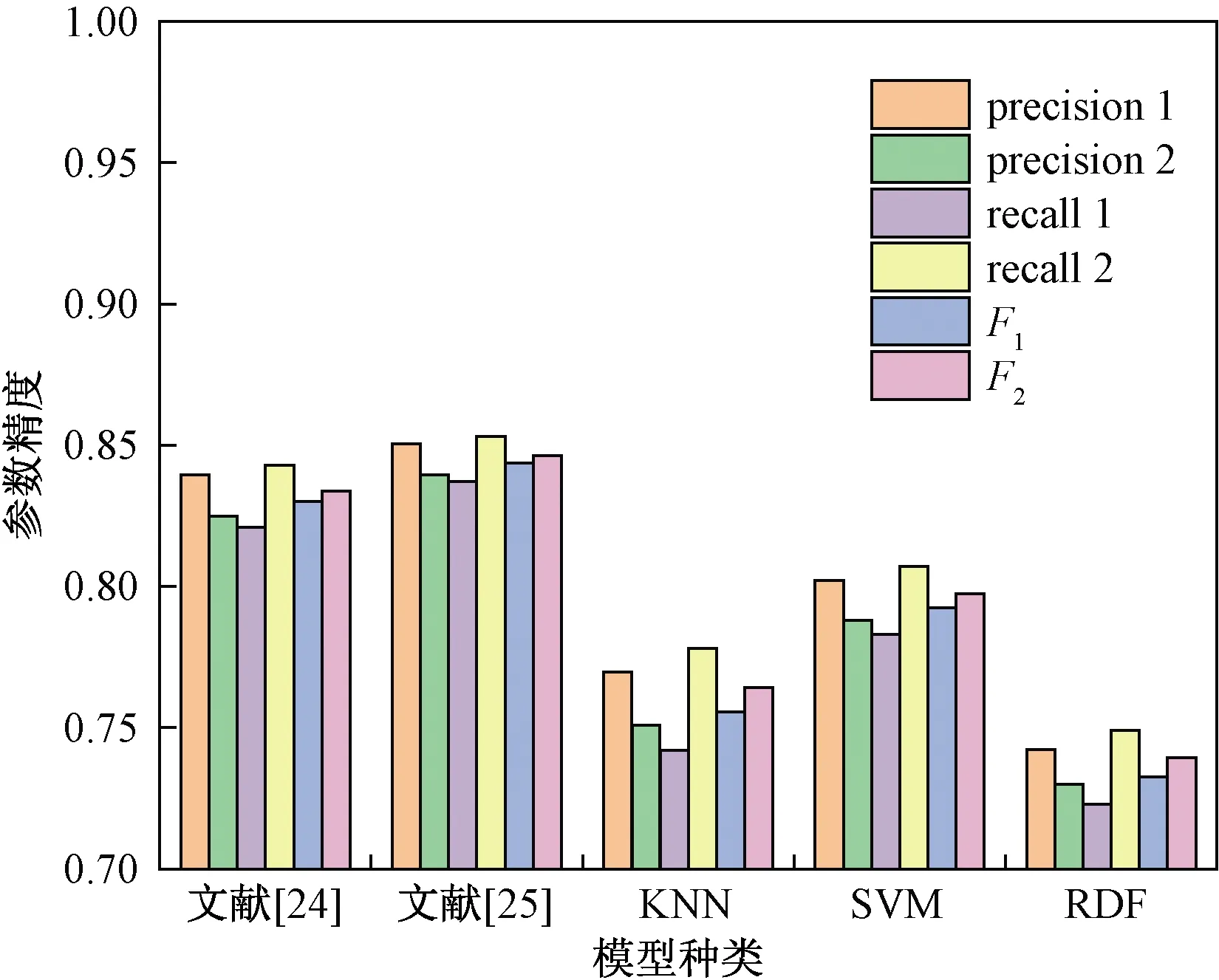
图7 各模型精确率、召回率、调和均值对比

图8 各模型测试精度和kappa系数对比

图9 各模型测试精度和Kappa系数对比
为验证各种模型对不同裂缝识别效果,使用SegNet模型[26]对各模型测试数据集识别正确的路面裂缝图像进行裂缝区域分割,如图10所示。统计所有测试样本裂缝区域像素点平均个数来反映裂缝大小,如图11、图12所示,ResNet101识别路面裂缝图像的裂缝区域像素点平均个数最小,进而识别出的平均裂缝最小,对小裂缝识别效果优于其他模型。通过对比发现,机器学习模型识别出的裂缝图像,其裂缝区域像素点个数平均值大于深度学习模型,表明其提取的裂缝平均面积较大,对于细小裂缝分类精度低于深度学习模型。因为路面存在裂缝图像较为复杂,裂缝结构不统一,深度学习算法拥有众多网络层数其图像特征提取能力较为强大,能识别出更为细小的裂缝,对于明显裂缝识别两种方式均可满足。通过实验分析,所有网络模型对与无裂缝图像识别效果优于有裂缝图像识别,有些裂缝不太明显并且裂缝形状不规则,由于模型提取特征能力有限,所以将这些图像识别为无裂缝图像。

图10 路面裂缝提取

图11 裂缝区域像素点平均数

图12 裂缝区域像素点平均数
4 结论
针对当前路面裂缝识别技术的缺陷,提出了一种基于深度学习的路面裂缝识别方法。该方法在建立训练样本数据集时,充分考虑其图像的特征因素,将数据集类型进行细分,消除路面图像中标线干扰因素;通过对原始图像裁剪,再将裁剪完的图像进行上采样处理,突出图像特征,使神经网络更容易学习特征,提高模型精度。对同一数据集进行模型训练当训练到第40个epoch时,ResNet101模型测试精度为0.898,Kappa系数为0.815,均高于其他深度学习模型;与机器学习算法相比,深度学习模型测试精度具有全面优势,平均精度高出0.1,Kappa系数高出0.15,表明了该智能化方法的可靠性,为路面裂缝识别提供了一种新思路。
猜你喜欢
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
华人时刊(2016年19期)2016-04-05
华人时刊(2016年16期)2016-04-05
专用汽车(2015年4期)2015-03-01
筑路机械与施工机械化(2014年2期)2014-03-01
