
基于双神经网络结构的新型人工神经网络训练算法
2021-09-24 02:42毛炳强孙铁良孙凌祎
化工自动化及仪表 2021年5期
毛炳强 孙铁良 孙凌祎 陈 鹏 高 畅
(1.国家石油天然气管网集团有限公司油气调控中心;2.昆仑数智科技有限责任公司)
BP神经网络是目前神经网络理论中发展最为完善、应用最为广泛的网络,但在训练时通常需要较多的迭代步数[1]。 尤其在训练较长数据序列时,就难免耗用大量CPU时间。 目前,国内外的改进工作主要集中于BP神经网络算法的优化上,而对拓扑结构的研究相对较少。 Lopes N和Ribeiro B提出了多神经网络结构, 并对一些分类问题进行了研究[2]。 Chen K和Salman A提出了一种针对语音信号处理的深度神经网络结构[3]。
在计算机视觉中, 处理景象匹配问题时,一般会先进行实时图和基准图的粗匹配计算[4],以减少计算时间。 小波分析可以准确定位信号的瞬变特征,通过多分辨率变换可对信号进行“切片式”分析。 这一思想与视觉中由粗到细的多分辨率分析过程是一致的,更符合人类的视觉特性[5]。在此,笔者基于视觉生理学特征和小波分析在信号特征提取方面的优势,提出了一种加速神经网络训练的新结构——双神经网络结构(Dual Neural Networks Architecture,DNNA)。 首先对输入输出信号进行小波分解,得到近似系数。利用DNNA中的辅助神经网络对小波分解后的原始数据近似序列进行训练, 将训练得到的权值和阈值传递给主神经网络, 再利用主神经网络对全部的输入输出信号进行训练。 在非线性函数逼近、非线性动态系统辨识和井底压力预测仿真实验中,与常规的神经网络结构相比,在达到相同精度的前提下,DNNA占用的CPU时间更少, 训练效率更高。
1 双神经网络结构
1.1 原始数据的小波分解
1989年,Mallat S G将计算机视觉领域内的多尺度分析思想引入到小波分析中,统一了小波函数的构造,提出了离散信号按小波变换进行分解和重构的金字塔算法,即Mallat算法[6],该算法使得多尺度分析在众多领域取得了许多重要的理论和应用成果。
根据Mallat算法,一维输入信号X可分解为一个低频近似系数caJ和不同频率的高频细节系数cd1,cd2,…,cdJ(图1)。

图1 一维输入信号X的3层小波分解
该过程中, 系数可通过离散小波分解的Mallat算法获得:

其中,D为下抽样算子, h-*为高通滤波器h的共轭反转,g-*为低通滤波器g的共轭反转,*表示卷积运算。
同理, 可以得到一维输出信号Y的小波分解分量tcaJ和tcd1,tcd2,…,tcdJ。 如果X和Y为多维信号,则可将多维信号的每一维按相同的分解方式分别进行分解。 数据序列分解后,每层的分解序列相对于分解前的长度减半。 另外,小波分解中低频部分随层次的增加,它含有的高频成分信息会随之减少,当分解到下一层次时,就有更高频的信息被去除,则低频部分可以以较短的长度表征时间序列的变化趋势。
1.2 双神经网络的训练
双神经网络结构[7](图2)包含一个辅助神经网络ANN_a和一个主神经网络ANN_p,它们具有相同的网络结构和学习参数。 其中,辅助神经网络主要根据小波分解得到的原始数据的近似序列的趋势特征, 在较短时间内寻找权值和阈值,并提供给主神经网络作为初始权值和阈值,以缩短整体训练时间。

图2 双神经网络结构
在双神经网络结构中[8],首先利用小波分解获取原始数据序列的近似序列,该序列的长度随着分解层数的增加逐层减半,接着利用新获得的近似序列进行辅助神经网络训练,找到一个合理的初始权值和阈值,最后以此权值和阈值作为初始值对原始数据序列进行主神经网络训练,这样可以大幅减少计算量,缩短训练时间。
值得注意的是,近似系数是从原始输入输出数据中提取的低频信息和趋势信息,所以双神经网络结构对包含大量高频信号的数据并不适用;另外,信号中的突变点会在小波分解后成为幅值最大点,所以双神经网络结构对包含较多突变点的信号也不适用。 因此,使用双神经网络结构时需要注意以下3点:
a. 数据的归一化预处理。为了保证辅助神经网络传递给主神经网络的参数的有效性,辅助神经网络和主神经网络的输入输出数据标准化必须在相同的范围内。
b. 分解级数的选择。分解级数既不能过大也不能过小。 过大则分解得到的近似系数包含的原始数据的信息过少,为主神经网络提供的初始值不够有效,多次实验表明,一般分解最大层数不超过5层; 过小则辅助神经网络的训练会占用较多CPU时间。
c. 小波函数的选择。 选择不同的小波函数,将得到不同的分解分量,从而影响最终的训练结果。 小波变换后的小波系数反映了小波与被处理信号之间的相似程度。 如果小波变换后的小波系数较大,则小波和被处理信号之间的波形相似程度较大,反之则较小[9]。 在双神经网络结构中,小波变换仅需反映小波信号整体的近似特征即可,因此可选用尺度较大的小波。
2 仿真实验与结果分析
采用非线性函数逼近、非线性动态系统辨识和井底压力预测3个仿真实验, 并与常规神经网络结构训练结果进行比较,以验证双神经网络结构的有效性。 其中,训练误差函数均选择均方根误差函数(RMES),即:

其中,N为数据长度,y(·)为实际输出,yn(·)为预测输出。
2.1 非线性函数逼近
考虑如下非线性函数:

其中,x为-15~15之间均匀分布的数,共1 500组数据。
实验中,神经网络训练的终止条件设为均方根误差不大于0.01或者最大迭代次数达到10 000。采用常规BP神经网络和双神经网络(db3小波基,3层小波分解)分别进行25次独立实验,结果如图3所示。可以得到,常规BP神经网络的训练时间平均值为144.85 s, 双神经网络的训练时间平均值为16.03 s,节约时间约88.93%。
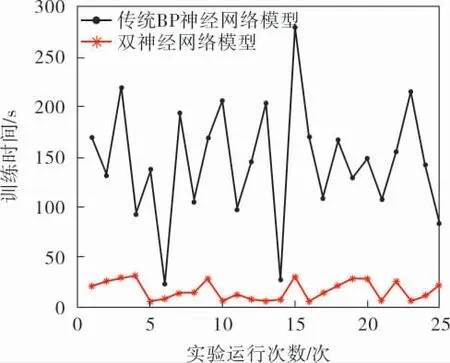
图3 非线性函数逼近的两种神经网络训练时间对比
固定小波类型为db3小波, 考虑不同的分解层数对训练时间的影响。 由表1可知,1~3分解层的运行结果类似,当分解层数达到4、5之后,标准差变大,说明运行结果的起伏变化较大,不稳定,这是因为分解后的近似系数长度过短,不能很好地表征原始输入输出信号所包含的信息。
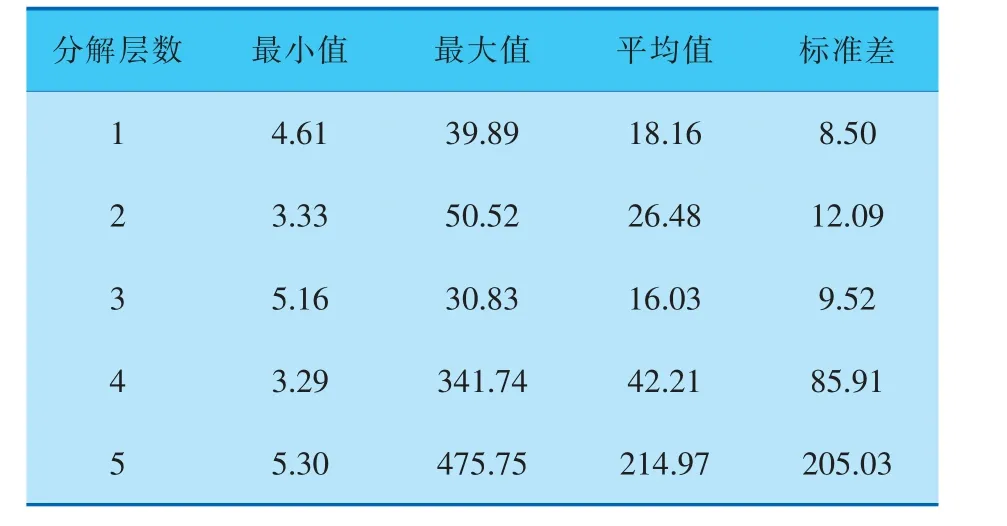
表1 不同分解层数下的训练时间 s
固定小波分解层数为3层时, 考虑不同的小波类型对训练时间的影响。Ingrid Daubechies是较为常用的一组小波基。 由表2可知,总体训练结果差别不是很大, 其中db1的结果波动最小但平均值最大,db10的结果波动最大,最不稳定。

表2 不同小波类型下的训练时间 s
2.2 非线性动态系统辨识

在物理模型内部结构未知的情况下,输入变量选为y(t-1)、y(t-2)和u(t-1),输出变量为y(t),输入输出共800组数据,误差精度设为0.008,选择db3小波基,3层小波分解。 非线性动态系统辨识的两种神经网络训练时间对比结果如图4所示,可以看出,BP神经网络平均训练时间为9.10 s,双神经网络平均训练时间为3.41 s, 节约时间约62.53%。

图4 非线性动态系统辨识的两种神经网络训练时间对比
2.3 井底压力预测
井底压力预测系统是典型的非线性系统,以中东油田现场测量得到的垂直井筒气液两相流井底压力数据为训练对象,对井底压力进行预测。输入变量为液相流量、气相流量、管直径、管长度、井口压力、API油相密度、地面温度和井底温度,输出变量为井底压力,共选取150组数据[10]。 采用多入多出的BP神经网络进行井底压力预测, 标准化区间为-1~1,误差精度设为0.05。 由于原始数据序列波动剧烈且无规律, 选用db3小波基,1层小波分解。 得到井底压力预测的两种神经网络训练时间对比结果如图5所示, 可以看出,BP神经网络的平均训练时间为128.41 s,双神经网络的平均训练时间为85.38 s,节约时间约33.51%。

图5 井底压力预测的两种神经网络训练时间对比
3结束语
为提高常规神经网络的训练效率,笔者提出了双神经网络结构,利用小波分解提取特征的优势,构建辅助神经网络,并为主神经网络提供训练初值。 仿真实验结果表明,双神经网络结构相对于常规的神经网络结构,可以极大地节约训练时间。 另外,由于双神经网络结构对算法和内部结构不做要求,因此不影响其泛化、容错等性能,使之可以应用在多种神经网络(如径向基神经网络、回归神经网络及小波神经网络等)中,使用简单、方便高效,有利于神经网络的开发和应用。
猜你喜欢
中国特种设备安全(2022年3期)2022-07-08
现代电力(2022年2期)2022-05-23
科技风(2021年19期)2021-09-07
物联网技术(2020年12期)2021-01-27
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
汽车零部件(2017年4期)2017-07-12
北京航空航天大学学报(2017年12期)2017-04-23
教学月刊·中学版(教学参考)(2016年5期)2016-06-14
