
基于双向编码文本摘要-长短期记忆-注意力的检察建议文本自动生成模型
2021-09-26 02:37孙豫峰
科学技术与工程 2021年25期
邹 蕾,崔 斌,樊 超,孙豫峰
(北京京航计算通讯研究所信息工程事业部,北京 100074)
公益诉讼作为一种新型的权益救济方式,与人民生活息息现关。随着社会经济的发展,越来越多的公益诉讼案件(如食品安全类)涌入法庭,检察建议作为监督行政部门整改的依据,可以更大程度地保障人民权益,如何从海量文本信息中获取关键信息便于检察官完成检察建议文本生成,成为一种急需解决的问题。目前,公益诉讼案件的检察建议生成主要靠检察官人工提取相关违法事实以及行政部门不作为等相关事实描述并生成检察建议文本,存在人力资源浪费和效率不高等问题。如何有效生成检察建议文本是一个研究热点。
目前,检察建议文本自动生成可采取基于文本摘要的方法来完成。基于摘要的研究主要包括抽取式摘要方法和生成式摘要两种方法[1-4]。有学者提出将融合关键词的方法用于抽取式文本摘要生成[5-11]。例如,李峰等[10]提出将关键词作为指示来提高文本抽取准确率,通过关键词与标题词相结合得到关键词列表,并依据此构建与当前文本相近的语料库从中抽取出主题相关词,最后采用算法完成摘要抽取。宁珊等[11]针对现有模型在生成摘要时会出现无关摘要词的问题,提出将关键词融入到文本摘要生成过程中。该方法利用关键词信息并结合门控单元去除冗余信息,从而获得更精准的文本信息。也有学者使用聚类的方法来完成文本摘要自动生成[12-15]。徐馨韬等[13]采用一种改进的K-means算法对相似文本进行聚类,然后利用Textrank算法对文本进行排序,最终抽取主题句生成摘要,相比基于特征的算法生成的摘要质量更高。
对文本语义的准确理解有助于提高下游各类任务的效果。为了提高对文本的语义理解,有学者将注意力机制克神经网络相结合[16-19],对向量化的文本进行加权表示,通过对文本表示赋予不同的权重参数来区分文本中的重要特征。例如,姜同强等[16]将长短期记忆(long short term memory,LSTM)与注意力机制结合,获取具有不同关注度的文本表示信息,对食品安全领域的法律文书中的重要特征进行重点关注,将分类准确率提高至95.23%。也有学者将基于BERT[17]的模型与注意力机制相结合[18],通过BERT的强大表征能力获取上下文语义信息,结合注意力机制克服传统模型存在的多义性问题,提高了实体识别准确率。以上方法通过对语义的准确理解,在下游的命名实体识别任务中取得了较高的准确率。
受此启发,很多学者将神经网络与注意力机制结合并用于文本生成,通过对语义的准确理解,提高文本生成质量[20-28]。例如,周健等[26]将循环神经网络(recurrent neural networks,RNN)与注意力机制相结合,并注入文本语言特征信息,构造了一种改进的序列-序列的神经网络模型,该模型采用基于注意力机制的RNN模型,可以很好地进行语义理解,进而提高文本摘要生成效果。周才东等[27]将卷积神经网络(convolutional neural networks,CNN)作为编码端完成高层次特征提取,并在解码端添加注意力机制,相比其他模型,获得了更好的摘要效果,解决了词语重复、语序混乱等问题。为了解决基于CNN或者RNN所构建的编码-解码框架在生成摘要时存在并行能力不足且无法解决长距离依赖所导致的文本生成质量下降问题,王侃等[29]提出一种基于transformer[30]的文本摘要生成方法,相比以上基于word2vec的方法得到词向量,该方法以语言模型嵌入(embeddings from language models,ELMo)[31]作为词向量并结合当前句子的句向量作为最终的文本表征,相比基于CNN或者RNN的编码-解码框架,该方法解决了RNN难以并行计算和CNN不能直接处理变长序列的问题。然而此方法无法实现同步双向运算,影响文本特征表达。谭金源等[32]提出一种基于BERT-PGN的模型完成中文新闻摘要自动生成任务,该方法以BERT模型获取文本词向量,得到更细粒度的上下文相关的文本表示,进而获得更高的文本摘要结果。
以上方法对于包含句子数量较少的文档取得了较高的文本摘要生成质量。但对公益诉讼案件诉前审查报告文档,通常包含多个句子,属于多句子文档生成问题,所以需要处理多句子文档文本生成问题。Liu[33]提出一种改进的BERT模型BERTSUM进行句子级别编码,可以提取多个句子特征,并将其与摘要层相结合,将摘要任务转化为分类任务,在摘要层分别实现了基于Transformer和LSTM的摘要生成,发现基于Transformer的摘要层获得了最优的生成结果。然而不足之处是基于Transformer的摘要层参数过多,无法完成文本的快速生成。基于LSTM的摘要生成适用于长文本特征提取并完成摘要生成,相比基于Transformer的文本摘要生成方法,节省运算时间,实时性较好,但文本生成质量有所下降。
综合以上分析,通过神经网络强度大的语义表征能力,引入注意力机制可以重点关注文本中的重要特征,这更符合人对文本的自然理解。另一方面,在文本语义理解的基础上,如何保证高质量文本的快速生成,显得尤为重要。针对公益诉讼案件诉前审查报告文本文档包含句子数量较多导致无法兼顾模型实时性和文本生成质量的问题,现提出一种基于BERTSUM-LSTM-attention的公益诉讼案件检察建议文本自动生成模型,该模型通过BERTSUM,以文档作为输入,可以处理包含不同个数的句子并得到BERT词向量,将每个句子的标识符[cls]作为BERT编码的输入,获得不同句子的表征,结合双向LSTM来提取句子长时双向特征,引入attention机制来捕捉出现在长句子中任何位置的关键信息,以期在保证模型实时性的基础上提高文本生成质量。
1 公益诉讼案件检察建议文本自动生成模型构建
基于BERTSUM-LSTM-attention的公益诉讼案件检察建议文本自动生成模型结构如图1所示,主要由3个部分组成,即文本标记、BERTSUM-LSTM-attention编码(包括基于 BERTSUM的词嵌入表示、基于BERT的特征提取阶段和基于LSTM-attention编码)和模型输出。

图1 基于BERTSUM-LSTM-attention的公益诉讼案件检察建议文本自动生成模型Fig.1 BERTSUM-LSTM-attention based model for the automatic generation of the text of procuratorial suggestions for public interest litigation cases
1.1 文本标记
通常情况下,将公益诉讼案件的诉前审查报告作为输入文本,检察建议书作为摘要,通过训练模型,完成检察建议文本摘要生成。首先对诉前审查报告进行标签标记,根据检察建议内容对诉前审查报告中的句子进行重要性标记,如两者相关,则当前句子标签为1,反之为0,从诉前审查报告中抽取句子作为检察建议的内容就转化为对诉前审查报告句子标签的预测,如果预测为1,则将其抽取出来,作为检察建议的内容。经过标签标记后,文本摘要任务转化为文本分类任务。标记后的样本如图2所示。

图2 部分标记样本Fig.2 Labeled samples
1.2 BERTSUM-LSTM-attention模型编码
基于BERTSUM-LSTM-attention模型编码主要包括3个部分:基于 BERTSUM的词嵌入,基于BERT预训练语言模型的特征提取和基于LSTM-attention编码构成。
1.2.1 基于 BERTSUM的词嵌入
通常,对于传统语言模型,句子s=w1w2…wn由n个词语构成,其概率分布由p(s)表示为
(1)
式(1)中:p(s)为文本序列联合概率的密度估计。由于联合概率按照文本序列从左至右分解,所以无法利用上下文信息进行双向特征表示,由此模型所得到的词向量是固定的,无法解决一词多义等问题。针对此,BERT采用自编码语言模型来获取上下文相关的双向上下文表示,自编码语言模型表达式为

(2)
BERT主要基于自编码语言模型,可以利用上下文信息得到双向特征表示,主要是通过提出两种预训练任务掩码语言模型(mask language model,MLM)和下一个句子预测(next sentence prediction,NSP)来实现。
MLM原理是在输入文本序列s中,随机遮挡15%的词,目标是去预测遮挡的词,相比传统语言模型,MLM实现了从左右双向去预测遮挡的词。但此遮挡方式会使预训练收敛变慢,由于预测的目标是15%的词而不是整个句子,为了解决这个问题,在掩码方式上做了改进,即不总是用[MASK]去掩盖遮挡的词,而是有80%的概率去掩盖,10%概率用随机词替换以及10%概率保持不变。为了使BERT适用于阅读理解等句子级别的任务,添加了一个句子关系判断任务NSP,即判断当前句子B是否是另一个句子A的下文,如果是模型输出“isnext”,否则输出“notnext”,对于此任务的训练数据,50%的句子关系是“isnext”,另外50%则为“notnext”,是一个二分类任务。最终预训练模型的目标函数就是对两个任务求和求最值。
基于BERTSUM的词嵌入对于每个词首先被编码为词向量,每个词向量由词汇令牌编码,句子分割编码和位置编码三部分相加组成,原理图如图3所示。

sep为分隔符,表示句子和句子间的分割;S1、S2为两个不同的句子图3 BERTSUM词嵌入Fig.3 BERTSUM embeddings
BERTSUM的输入是由多个句子构成的文档,每一个文档作为一个样本,每一个句子都有一个符号[cls]来表示句子的开始,这样做的目的是为了便于后续句子级别的特征提取。
1.2.2 基于BERT预训练语言模型的特征提取
模型BERTSUM或者BERT均是以Transformer作为编码器[26],Transformer编码器主要由自注意力机制(self-attention)和前馈神经网络(feed forward network)两部分构成。
自注意力机制以图3中得到的句向量为输入,每一个句子以[cls]开始,[sep]结束。自注意力机制公式为
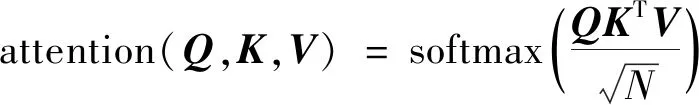
(3)

图4 “单头”注意力的机制Fig.4 “Single head”attention mechanism
BERT或者BERTSUM编码是基于“多头”模式的,“多头”模式通过“不共享参数”(不同的权重参数)来获取更为丰富的语义表示,完成一词多义理解,这种机制更加符合人类对语言的理解。多头注意力机制表达式为
Multihead=[Concat(head1,head2,…,
headN)]*W
(4)
式(4)中:headi来自式(3);W为网络中可以训练的参数;Concat为对每一个“单头”进行拼接操作。“多头”注意力机制原理如图5所示。

图5 “多头”注意力机制Fig.5 “Multihead”attention mechanism
下一步是将多头注意力的输出z送至编码器的下一个阶段,即前馈神经网络,包括两个部分:ReLU激活函数和线性激活函数,即
z′=max(0,W1z+b1)
(5)
(6)
式中:W1、b1分别为是ReLU激活函数的权重和偏置参数;W2、b2分别为线性激活函数的权重和偏置参数。编码阶段会重复进行上述过程L次,L是模型的超参数BERT编码层数,更深层的层数可以使模型能对文本进行更深层次的编码,获取更加全面的文本特征。
1.2.3 基于LSTM-attention的编码
在NLP任务中,循环神经网络可以保存长句子间的依赖关系,由于公益诉讼案件诉前审查报告往往由长句组成,较CNN等网络模型,RNN对长句子建模更为有效,所以RNN更适合对诉前审查报告进行深层次编码。LSTM作为一种功能更为强大的RNN模型,由于加入特殊的记忆单元,可以解决由于句子过长而导致的梯度消失或者梯度爆炸等问题,因此,将其用于长句文本特征提取。典型LSTM单元由输入门、输出门、遗忘门和记忆单元构成,表达式为
ft=σ([Wfz″t+Wf′ht-1]+bf)
(7)
it=σ([Wiz″t+Wi′ht-1]+bi)
(8)
ot=σ([Woz″t+Wo′ht-1]+bo)
(9)

(10)

(11)
ht=ot⊗tanh(mt)
(12)

以上是单向的LSTM,现采用双向的LSTM进行拼接得到最终的长时文本特征,即
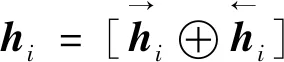
(13)
对正向和逆向隐藏层输出进行拼接可以更好地捕捉文本上下文表示,提高最终文本生成效果。
接下来是将注意力机制引入双向的LSTM,进一步完成文本特征提取,即
α=softmax[WTtanhh]
(14)
γ=hαT
(15)
h′=tanhγ
(16)
式中:h=[h1,h2,…,hT],T为句子的长度,注意力机制是先计算每个时序h1,h2,…,hT的权重α,然后对双向LSTM的输出向量h求加权和γ,得到最终的句子表示,作为之后进行softmax操作的输入。
1.3 输出模块
最终的摘要输出是一个二分类任务,标签为1的文本作为生成的摘要。输出层仍使用softmax函数进行处理,即
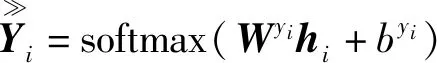
(17)
式(17)中:byi、Wyi为全连接层的偏置和权重参数。
模型的训练目标是最小化预测标签和真实标签的交叉熵损失函数,损失函数表示为

(18)
2 实验结果和分析
2.1 数据集和评价指标
为了验证所提模型有效性,通过网络爬虫技术爬取了一些公益诉讼案件数据进行实验。实验数据来自“裁判文书网”,以公益诉讼案件中的环境保护案件为例,经过数据爬虫并清洗得到4 300条样本,按照7∶3的比例划分数据集,其中训练集3 000条数据,测试集1 300条数据。部分样本如表1所示。
以自动文摘评测方法标准指标ROGUE-1、ROGUE-2和ROGUE-L为评价指标。ROGUE(recall-oriented understudy for gisting evaluation)指的是一种基于召回率的相似性度量方法,主要有ROGUE-1、ROGUE-2和ROGUE-L 3种。其中,ROGUE-1、ROGUE-2的召回率、准确率、F1值的计算公式如式(19)~式(21)所示,ROGUE-L的召回率(R)、准确率(P)、F1值的计算公式如式(22)~式(24)所示。

(19)
式(19)中:ngram(X,Y)为标准摘要和预测摘要共现的单词个数;M为标准摘要单词的个数。
如果分母为预测摘要的个数N,则可以计算准确率,如式(20)所示。

(20)

(21)
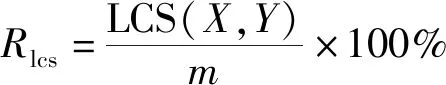
(22)

表1 数据集举例Table 1 Example of data set

(23)

(24)
式中:LCS(X,Y)为X和Y的最长公共子序列(longest common subsequence,LCS)的长度;m和n分别为标准摘要和模型自动摘要的长度(句子所包含词语的个数);参数β取1。
2.2 实验环境和参数设置
对于以上模型,采用python语言进行编程,采用基于pytorch的框架进行搭建,pytorch是Facebook人工智能研究院推出的开源机器学习库。
输入数据集相关参数设置:由于BERTSUM对输入数据的设置,每次可以处理包含不同个数句子的文档,所以无需对句子进行等长处理。其中,dropout值为0.1,迭代步数为6 000,经过交叉验证,学习率选为2×10-5。对于BERT预训练模型,受限于硬件环境,选取base版本,其中BERT编码位置向量维度为512,注意力头个数为12,激活函数选取gelu。对于LSTM,其隐藏层维度选为768。
模型主要参数如表2所示。
2.3 实验结果与分析
为了验证模型的有效性,实验采用了文本摘要经典模型lead3,oracle和基于transformer的BERT+FC、BERT+RNN、BERT+transformer这几种方法进行对比分析,采用ROGUE-1、ROGUE-2和ROGUE-L为评价指标,同时计算了3种指标的P,R和F1值。

表2 相关参数设置Table 2 Related parameter setting
2.3.1 各模型结果对比
表3 是各种方法在ROUGE-1指标下的对比结果,可以看出,在召回率R的指标下,本文方法取得了最高值,为57.12%。在F1指标上,本文方法结果为28.2%,稍高于最优模型BERT+transformer的27.8%,优于BERT+RNN模型的26.9%及BERT+FC模型的26.81%。原因在于,相比BERT+RNN,本文方法在其基础上添加了attention机制,模型在对长距离句子进行建模时,即使相隔比较远的词,也能对其正确理解并找到它们之间的相关性。相比BERT+FC模型,本文方法和BERT+RNN在F1值上分别提高了1.39%和0.09%,这说明在BERT特征提取基础上,采用RNN模型要比全连接效果更好,这是因为RNN可以对长句子进行深层次的特征提取,提取到的关键信息作为分类层的输入,可以提高分类结果,最终提高了F1指标。相比经典模型lead3和oracle,基于BERT模型在F1指标上均有不同程度的提高,比如表现最差的BERT+FC较lead3和oracle分别提高了10.13%和0.54%,说明基于BERT的方法,对文本理解更为准确,特征提取更加完善,最终提高了F1值。
表4为ROUGE-2指标下的对比结果。可以看出,在ROGUE-2指标上与ROGUE-1有相似的结论。本文方法在召回率R指标下取得最大值,为33.29%,而BERT+transformer在精确率P取得最大值,为14.22%。本文方法的F1指标为15.76%,而BERT+transformer模型的F1指标为15.46%,BERT+RNN为14.4%,BERT+FC为14.49%。但相比ROGUE-1,在ROGUE-2上,各方法在指标上均有大幅程度的下降,这与ROGUE-2指标本身定义有关,因为ROGUE-2是基于词语“二元”组合来计算对比的,“二元”组合种类很多,预测结果尽最大可能地接近真实“二元”组合,才有可能取得较好的指标,尤其对于长句子,“二元”组合更丰富,预测难度就更大。
表5 为ROUGE-L指标下的对比结果,可以看出,本文方法的精确率P的结果为19.41%,召回率R的结果为51.68%,F1指标为23.95%,均优于BERT+RNN模型及BERT+FC模型的各项指标。同时召回率R也优于BERT+transformer模型的49.23%。同样,基于BERT的方法在各指标上均优于经典方法lead3和oracle。
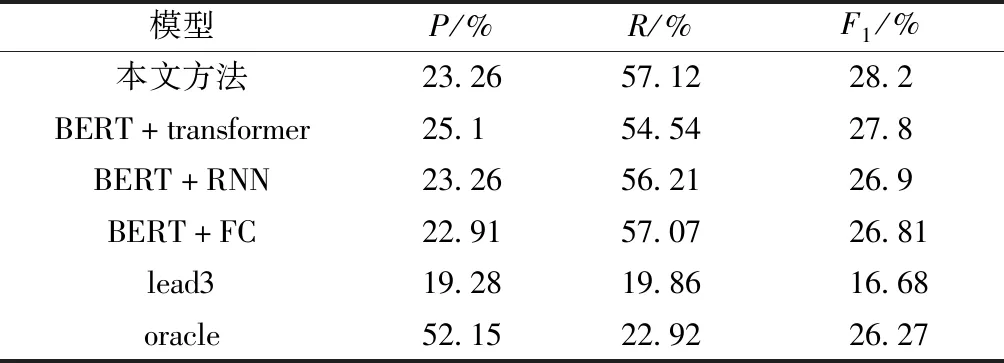
表3 ROUGE-1对比结果Table 3 Results of ROGUE-1

表4 ROUGE-2对比结果Table 4 Results of ROGUE-2

表5 ROUGE-L对比结果Table 5 Results of ROGUE-L
综上所述,在ROGUE-1、ROGUE-2、ROGUE-L的F1指标,本文方法取得了最优的结果,分别为28.2%、15.76%、23.95%,本文方法相比BERT+transformer,在F1指标上有0.4%、0.3%、0.16%的提升,在3个指标的召回率R上取得了最好的效果,分别为57.12%、33.29%、51.68%,说明本文方法对诉前审查报告中的关键句更敏感,可以将关键句挑选出来,对关键句的查全效果更好。基于BERT的方法在各指标上相比经典方法均有不同程度的提高,其中本文方法在F1值上相比lead3有5%~10%的提高,较oracle也有不同程度的提高。
2.3.2 各模型运行速度与参数量对比
本文方法相比其他模型,在ROGUE-1、ROGUE-2和ROGUE-L的3项指标上均取得了最优的结果。相比目前表现最好的BERT+transformer模型,本文方法在3种ROGUE的F1值上均有不同程度提升,但本文方法对实时性更好,比如,模型参数量更少,运行速度更快,更少的参数量降低了内存消耗。表6为各方法的运行速度与模型参数比较,如表6所示,本文方法的参数量为105 M,训练速度为67 s/100步,测试速度为7 s/100步,优于BERT+transformer的各项指标。
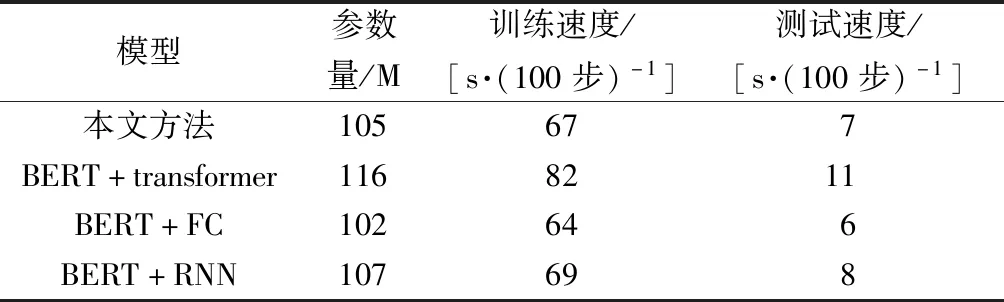
表6 运行速度与模型参数比较Table 6 Comparisons of running speed and model parameters
结合2.3.1节对比结果可以得出,本文方法可以在保证实时性的条件下提高文本的生产质量,而且参数数量比最优的BERT+transformer模型少11 M左右,训练和测试速度均快于最优模型,保证了模型测试的实时性。
2.3.3 迭代次数对模型影响
为了探索迭代次数对模型的影响,图6给出了训练过程中模型F1值随迭代次数的变化情况,从图6可以看出,最优迭代次数为5 000,ROGUE-1、ROGUE-2、ROGUE-L的F1值分别达到最大值,为0.282 0、0.157 6、0.239 5,再增加迭代次数,F1值会下降,所以迭代次数5 000既可以保存最优结果,又可以节省训练时间,保证了文本的快速生成。
图7是不同方法ROGUE-L的召回率R指标随迭代次数的变化,从图7可以看出,本文方法BERT+LSTM+attention在整个迭代过程中取得了较高的召回率,并且在5 000的迭代次数取得了最优值0.516 8,如再继续增加迭代次数,R值会下降。

图6 模型F1值随迭代次数变化Fig.6 The value of F1 varies with the number of iterations
3 结论
基于BERTSUM-LSTM-attention模型的公益诉讼案件检察建议文本自动生成方法相比其他方法,在ROGUE-1、ROGUE-2、ROGUE-L的F1指标上取得了最好的效果,可以在保证实时性的条件下提高文本生成质量。BERTSUM通过微调输入编码端,对句子标识符[cls]向量进行编码,得到句子级别的特征满足多句子输入的文本生成任务。加入LSTM神经网络,能够对长句子进行双向特征提取,引入attention机制,给关键信息分配较大的权重,相比没有注意力机制的方法,在F1上分别提升了1.3%、1.36%、1.19%,提高了文本生成质量。另一方面,本文方法相比其他改进方法,由于参数量少,训练和测试速度均最快,是一种快速文本生成方式。
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
汉字汉语研究(2020年2期)2020-08-13
检察风云(2020年10期)2020-06-29
检察风云(2020年8期)2020-06-09
电子制作(2019年22期)2020-01-14
检察风云(2019年20期)2019-11-06
北京航空航天大学学报(2019年9期)2019-10-26
检察风云(2019年18期)2019-10-18
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
