
零样本学习综述
2021-10-14 06:33王泽深向鸿鑫
计算机工程与应用 2021年19期
王泽深,杨 云,2,向鸿鑫,柳 青
1.云南大学 软件学院,昆明 650504
2.云南省数据科学与智能计算重点实验室,昆明 650504
近年来,海量数据资源的不断涌现和机器计算能力的不断提高,给正在兴起的机器学习技术带来了巨大的发展机遇与挑战。随着大量研究成果已投入实际应用,机器学习技术催生出人脸识别、智慧医疗、智慧交通等多个前沿的商业化应用。机器学习旨在通过计算机来模拟或者实现人类的学习行为,让计算机具备能够从海量数据中获取新的知识的能力并不断地改善自身的性能。这也使得传统的基于监督的机器学习算法在某些识别(人脸识别、物体识别)和分类等方面的性能已接近甚至超过人类。
然而拥有如此高超的性能所需要付出的代价是大量的人工标记数据[1],这在实际应用中会消耗大量的财力、物力。因此,为了将机器学习技术更好地应用于实际问题中,减少大量标记数据对机器学习技术的约束,需要相关技术具备有像人类一样能够思考、推理的能力[2],而零样本学习技术在实现这个能力的过程中具有重要意义。通过这几年的不断研究,零样本学习技术已经具备了较为完整的理论体系。但是,零样本学习技术在应用方面却没有较好的总结。所以本文将回顾零样本学习近些年来在商业应用上的价值,为零样本学习技术构建一套比较完善的应用体系。
本文主要综述了零样本学习的理论体系和应用体系。第1 章论述零样本理论体系中的相关基础概念。第2章列举经典的零样本学习模型。第3章构建零样本学习的应用体系。第4 章讨论零样本学习应用中的挑战,并对研究方向进行了展望。
1 零样本相关基础理论
1.1 研究背景
在日常生活中,人类能够相对容易地根据已经获取的知识对新出现的对象进行识别[3]。例如:带一个从未见过老虎的孩子到动物园,在没见到老虎之前,告诉他老虎长得像猫,但是比猫大得多,身上有跟斑马一样的黑色条纹,颜色跟金毛一样。那么当他见到老虎时,会第一时间认出这种动物。通过已知的猫、金毛、斑马推理出老虎过程如图1所示。

图1 零样本学习推理过程Fig.1 Reasoning process of zero-shot learning
这种根据以往获取的信息对新出现的事物进行推理识别的能力,在2009年被正式提出,并取名为零样本学习(Zero-Shot Learning,ZSL)[4-5]。正因为零样本学习具有推理能力,不需要大量的人工标记样本,对于一些实际问题中(如医疗影像图像、濒危物种识别等)具有极高的商业价值[3]。同时,零样本学习技术也能够突破现有监督学习技术无法扩展到新出现的分类任务的难题。因此,零样本学习成为机器学习领域最具挑战性的研究方向之一[6]。
1.2 定义
将上述的推理过程抽象为通过已知信息加上辅助信息进而推断出新出现对象的类别。因此,推理过程中已知的信息(猫、斑马、金毛)为训练集,辅助信息(猫的外形、黑色的条纹、金毛的颜色)为训练集与测试集相关联的语义信息[7],推测(老虎)为测试集。训练集中猫对应的猫类、斑马对应的马类、金毛对应的狗类,在训练前就已知,为可见类(seenclass);测试集中虎对应的虎类,在训练过程中没见过,为未可见类(unseenclass)。设X为数据,Y为标签,S为可见类,U为不可见类,Tr为训练集类别,Te为测试集类别,则零样本学习的定义为fzsl:X→YU,即通过训练可见类数据提取出对应的特征,加上辅助知识的嵌入,最终预测出不可见类。其中Te与Tr不相交;Tr为S,Te为U。值得注意的是,预测时如果出现训练集对应的类别,则无法预测。
由于零样本学习依赖的已知知识仍是一种带标签的数据,可以得知零样本学习是一种特殊的监督学习技术。对比传统的监督学习,其定义为f:X→Y,其中Tr包含于Te,Te与Tr均为S,可见与零样本学习最大的区别是测试集的类别是否包含于训练集的类别。对比于广义零样本学习,一种特殊的零样本学习,其定义为fgzsl:X→YU∪YS,其中Te与Tr不相交。Tr为S,Te为S和U。可见与零样本学习最大的区别是预测时训练集对应的类别是否能预测出来。三者的区别如表1所示。

表1 三种学习比较Table 1 Comparison of three kinds of learning
1.3 关键问题
由定义可知,零样本学习是一种特殊的监督学习。其存在的问题除了传统的监督学习中固有的过拟合问题外[8],还有领域漂移、枢纽点、广义零样本学习、语义间隔四个关键问题。
1.3.1 领域偏移问题(Domain Shift)
同一事物在不同领域的视觉效果相差太大。2015年,Fu 等人[9]提出,当可见类训练出来的映射应用于不可见类的预测时,由于可见类和不可见类所属的域不同,可见类与不可见类相关性不大,不同域在同一事物的视觉特征上可能相差很大,在没有对不可见类进行任何适配的情况下,会出现领域偏移问题[10]。例如,在现实生活中,知道老虎的尾巴与兔子的尾巴在视觉上相差很远。如图2所示。然而当预测的类别为老虎,所给的辅助信息中有尾巴这一属性,用兔的尾巴训练出来的效果不符合实际效果。

图2 老虎尾巴与兔子尾巴Fig.2 Tiger tail and rabbit tail
目前学者们提出的解决办法主要有:第一种是在训练过程中加入不可见类数据[9,11-35],即建立直推式模型。典型的例子有文献[9]利用不可见类的流形,提出多视图嵌入框架缓解领域偏移问题。第二种是对训练数据强制增加约束条件/信息[10,13,36-40],即建立归纳式模型。第三种是生成伪样本到测试过程中,即建立生成式模型[13,41-60],其本质是将零样本学习转换为传统的有监督学习。最经典的例子是SAE[61]模型,在图像空间嵌入语义空间的过程中添加约束条件,尽可能地保留图像空间中的信息。
当然,上述的解决方案都是建立在可见类与不可见类的数据分布在样本级别上是一致的。而文献[62]则直接通过聚类的方法获取不可见类的数据分布。
1.3.2 枢纽点问题(Hubness)
某个点成为大多数点的最邻近点。2014 年,Dinu等人[63]提出,从原始空间投影到目标空间的过程中,某个点会成为大多数节点最邻近的点,同时也指出枢纽点问题是高维空间中经常会出现的问题。例如,在使用零样本学习模型进行分类时,采用的算法为最邻近节点算法(K-Nearest Neighbor,KNN),则可能会出现一个点有几个甚至几十个最邻近节点,会产生多种不同的结果,导致模型的效果不佳。如图3 所示。但枢纽点问题不仅存在于高维空间,Shigeto等人[64]指出低维空间中也会出现枢纽点问题,维度越高,出现枢纽点问题越严重。
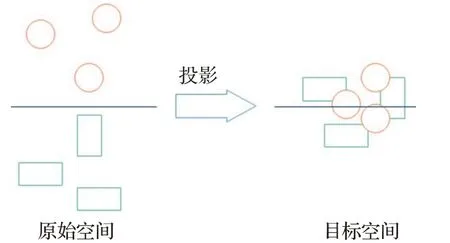
图3 枢纽点问题Fig.3 Hubness problem
目前学者们提出的解决办法主要有两种:第一种是使用岭回归模型,建立从低维向高维映射,在计算机视觉中则为建立从语义到视觉的映射,这种方法也称为反向映射[11,13,21,64-67]。其中,文献[64]直接将图像的特征空间进行嵌入,建立语义到视觉的映射,有效地缓解了枢纽点问题。第二种是使用生成式模型[11,14,23,55,68-70],生成伪样本,加入到测试过程中。
此外,非主流方法有文献[63]提出一种优化的近邻搜索算法,从根本上解决最近邻搜索问题。文献[65]则将岭回归模型替换为Max-Margin Ranking,来缓解枢纽点问题。
1.3.3 广义零样本学习(Generalized Zero-Shot Lear-ning,GZSL)
训练集类别与测试集类别互斥。本章已经对广义零样本学习的定义进行描述以及同零样本和传统监督学习进行比较。零样本学习的前提条件是测试集与训练集没有交集,即可见类等于训练集,不可见类等于测试集。这意味着测试阶段,如果样本来自训练集,则无法预测。这在实际生活中是不现实的。因此,2019年,Wang 等人[71]提出广义零样本学习,训练集仍是可见类数据,测试集则为可见类与不可见类数据的混合。零样本学习与广义零样本学习如图4所示。

图4 零样本学习与广义零样本学习Fig.4 Zero-shot learning and generalized zero-shot learning
目前学者们提出的解决方法主要有两种:第一种是先通过分类器,将测试集中可见类与不可见类数据进行划分。如果是可见类数据,则直接使用分类器进行分类;如果是不可见类数据,则利用辅助信息进行预测[72]。第二种生成模型,利用生成模型生成不可见类样本,再将生成的样本与可见类样本一起训练一个分类器,将广义零样本学习转化为传统监督学习[37,61,73]。
1.3.4 语义间隔(Semantic Gap)
语义空间与视觉空间流行构成不同,相互映射有间隔。零样本学习预测不可见类数据一般的解决方案是构建图像与语义之间的关系。2017年,Li等人[23]提出视觉特征来源于图像空间,语义信息来源于语义空间,两个空间的流行构成有差别,直接建立两者之间的映射,会导致语义间隔。
目前,学者们提出的主要解决方案是将从图像空间提取的视觉特征与语义空间提取的语义信息映射到公共空间中,并将两者进行对齐[74-75]。
1.4 常用数据集
目前,零样本学习在不同的领域得到了广泛应用。本节根据应用的不同类型,文本、图像、视频,分别介绍其在零样本学习中常用的数据集。
1.4.1 文本常用数据集
(1)LASER(Language-Agnostic Sentence Representations)
语言数据集。LASER 包括28 种不同字符系统的90多种语言,在零样本学习任务中主要用于开发该数据库中未包含的小语种。
(2)WordNet[11]
英文词语数据集。WordNet 包括超过15 万个词,20 万个语义关系。语义关系指的是名词、动词、形容词和副词之间的语义关系。零样本学习主要使用的是WordNet的名词部分。
(3)ConceptNet[76-77]
常识数据集。ConceptNet主要由三元组构成,包括超过2 100 万个关系描述、800 万个节点以及21 个关系。此外,其要素有概念、词、短语、断言、关系,边等[11]。在零样本学习任务中主要和知识图谱结合。
1.4.2 图像常用数据集
(1)AWA(Animal with Attribute)[78]
动物图像。AWA 由30 475 张动物图片构成,其中有50 个动物类别,每个类别至少有92 个示例,85 个属性。此外,AWA 还提供7 种不同的特征。由于AWA 具有版权保护,所以扩展数据集AWA2 应运而生。AWA2包括37 322张图片,与AWA同样拥有50个动物类别和85 个属性。一般将40 类作为训练数据的类别,10 类作为测试数据的类别。
(2)CUB(Caltech-UCSD-Birds-200-2011)[79]
鸟类细粒度图像。CUB由11 788张鸟类图片构成,其中有200类鸟类类别,312个属性。一般将150类作为训练数据的类别,50类作为测试数据的类别。
(3)aPY(aPascal-aYahoo)[80]
混合类别图像。aPY由15 339张图片构成,其中有32 个类别,64 个属性。并且明确规定20 个类共12 695张照片作为训练数据的类别,12 个类共2 644 张照片作为测试数据的类别[6]。
(4)SUN(SUN attribute dataset)[81]
场景细粒度图像。SUN由14 340张场景图片构成,其中包括717个场景类别,每个类别20张示例,102个属性。一般将645类作为训练数据的类别,72类作为测试数据的类别。
(5)ImageNet[37,82-84]
混合类别图像。ImageNet由超过1 500万张高分辨率图片构成,其中有22 000 个类别,属于大数据容量数据集。因此,一般使用其子数据集ILSVRC。IVSVRC由100 万张图片构成,其中有1 000 个类别,每个类别1 000 张示例。一般将800 类作为训练数据的类别,200类作为测试数据的类别。
1.4.3 视频常用数据集
(1)UCF101[85]
主要应用于人类行为识别。UCF101由13 320视频片段和101 个注释类组成,总时长为27 个小时。在THUMOS-2014[86]行动识别挑战赛上,UCF101数据集得到扩展。在UCF101的基础上,收集了来自于互联网的其他视频,其中包括2 500 个背景视频、1 000 个验证视频以及1 574个测试视频。
(2)ActivityNet[87]
主要用于人类行为识别。ActivityNet 由27 801 个视频片段剪辑组成,拥有203 个活动类(含注释),总时长为849 个小时,其主要优势是拥有更细粒度的人类行为。
(3)CCV(Columbia Consumer Video)[88-90]
主要用于社会活动分类。CCV 由9 317 个视频片段组成,拥有20个活动类(含注释),归属于事件、场景、对象3大类。
(4)USAA(Unstructured Social Activity Attribute)[90]
主要用于社会活动分类。USAA对CCV(Columbia Consumer Video)中8 个语义类各选取100 个视频进行属性标注。一共有69个属性,归属于动作、对象、场景、声音、相机移动5大类。
2 经典模型
本章通过介绍零样本学习在3 个发展阶段的经典模型,为第3 章应用体系的构建提供理论体系的支撑。这3 个发展阶段分别是:(1)基于属性的零样本学习;(2)基于嵌入的零样本学习;(3)基于生成模型的零样本学习。
2.1 基于属性的零样本学习
2013 年,文献[76]提出基于属性的零样本学习方法,属性是一种语义信息。这个方法是零样本学习的开山之作,也是零样本学习后续发展的基础。
Direct Attribute Prediction(DAP)模型[78]在PAMI 2013会议上提出,其预测不可见类标签通过以下两个步骤。第一,使用支持向量机(Support Vector Machine,SVM)训练可见类数据到公共属性的映射,为每个可见类数据学习一个属性分类器,这个属性分类器也是可见类与不可见类之间的共享空间。第二,使用贝叶斯公式对不可见类的属性进行预测,再通过不可见类与属性的关系,推出不可见类所属的类别。DAP结构如图5所示。

图5 DAP模型结构Fig.5 Structure of DAP model
DAP 模型在挑选样本方面,与AWA 数据集根据抽象名称指定动物和属性不同,其更细致的考虑了示例图像,根据图像来指定动物与属性,并使得示例图像中动物出现在最突出的位置。在数据集配置方面将优化后的数据集类别分为50%训练集和50%测试集。最终实验取得了多类别65.9%的准确率。
通过利用属性,DAP模型成功地将没有数据的类别进行预测,并且具有较高的精度。但是DAP 有三个明显的缺点:其一,对于新加入的可见类数据,属性分类器需要重新训练,无法对分类器进行优化和改善。其二,对于除了属性外的其他辅助信息(如网络结构的数据集Wordnet),难以使用。其三,由于使用了属性作为中间层,对于预测属性,模型能够做到最优。但对于预测类别,却不一定是最好的。
与DAP 模型一同出现的还有IAP(Indirect Attribute Prediction)[78]模型。IAP模型在PAMI 2013会议上提出,其预测不可见类标签通过以下两个步骤:第一,使用支持向量机(SVM)训练可见类到属性的映射以及不可见类到属性的映射。第二,使用贝叶斯公式得到可见类数据与可见类的概率,为每个可见类数据学习一个类别分类器,继而通过类别—属性的关系,推出不可见类数据所属的类别。IAP结构如图6所示。
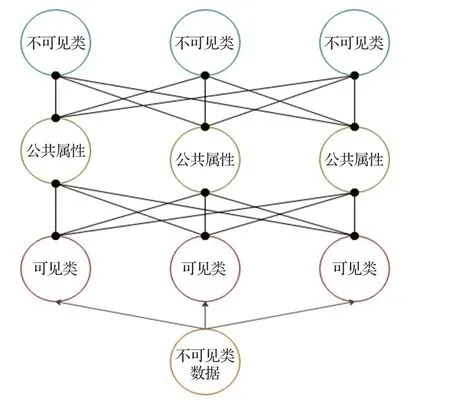
图6 IAP模型结构Fig.6 Structure of IAP model
与DAP模型一样,IAP模型也成功的预测出没有数据的类别,并且比DAP模型更加的灵活、简单。当有新类别需要进行训练时,IAP 模型的训练时间成本较小。但是IAP模型在实验中的效果并没有DAP模型的好。
在基于属性的零样本学习中,除了经典的DAP 和IAP 模型,文献[91]还提出结合DAP、IAP 各自的优点,通过属性分类器和相应组合策略进行零样本学习的BAP(Bimodal Attribute Prediction)模型。文献[92]提出的HAP(Hypergraph-based Attribute Predictor)更是将属性这一语义信息用超图构建起来,更好地利用类别之间的关系。
2.2 基于嵌入的零样本学习
随着机器学习的不断发展,计算机视觉逐渐成为研究者们的关注热点。只有属性的零样本学习,远不能满足对图像处理的需求,而且基于属性的零样本学习也存在着许多问题。因此,零样本学习提出基于嵌入的零样本学习,将语义信息与图像信息紧密结合起来。主要的方法有语义信息嵌入图像空间、图像信息嵌入语义空间、语义信息与图像信息嵌入公共空间等。
在图像信息嵌入到语义空间经常使用的训练函数有单线性函数、双线性函数、非线性函数等,损失函数有排序损失,平方损失等。
(1)Embarrassingly Simple Zero-Shot Learning(ESZSL)
ESZSL模型[93]在ICML 2015会议上提出,其将零样本学习分为两个阶段,训练阶段以及推理阶段。通过SVM学习双线性函数。一个在训练阶段利用训练样本实例与特征矩阵的相乘,建立特征空间与属性空间之间的映射;另一个在推理阶段利用训练样本的描述和特征空间与属性空间之间的映射获得最终预测的模型,为每一个类别都学习了一个图像空间到语义空间的映射。值得注意的是两个阶段均使用一行即可完成,且无需调用其他函数,十分简单的完成零样本学习。ESZSL还建立了对应的正则化方法以及平方损失函数对模型进行优化。ESZSL 模型结构如图7 所示。最终实验取得不错的效果。这是一种图像信息嵌入语义空间的模型。
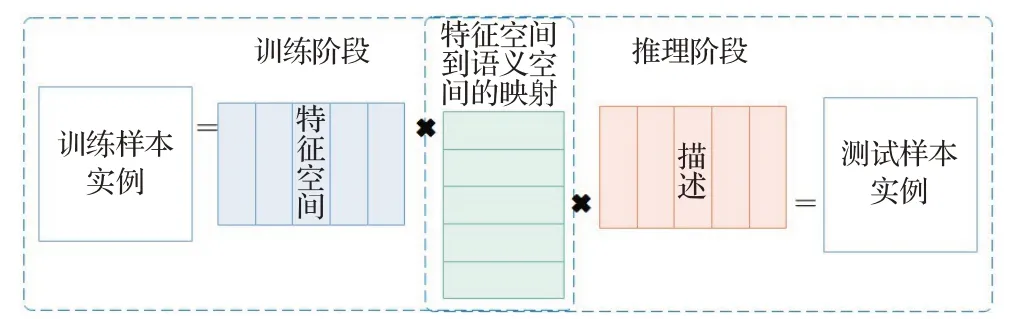
图7 ESZSL模型结构Fig.7 Structure of ESZSL model
ESZSL 模型在挑选样本方面,直接选择原始的AWA、aPY、SUN 数据集进行训练以及测试。最终实验在AWA 数据集上获得多类别49.3%的准确率,比DAP模型多7.8 个百分点;在SUN 数据集上则获得多类别65.75%的准确率,比DAP模型多13个百分点;而在aPY数据集由于准确度太低,不具备参考价值。
正因为ESZSL 模型的简单,使得在处理大规模数据上的表现不佳,并且每新来一个不可见类,就需要为其训练一个映射。而文献[94]提出AEZSL(Adaptive Embedding ZSL)以及DAEZSL(Deep Adaptive Embedding ZSL)模型正好解决这些问题。AEZSL 模型在ESZSL基础上进行改进,利用可见类与不可见类之间的相似性,为每个可见类训练一个视觉到语义的映射,然后进行渐进式的标注。DAEZSL模型则在AEZSL基础上进行改进,只需要对可见类训练一次,即可运用于所有不可见类,解决了大规模数据上ESZSL 需要多次训练的繁琐过程。
(2)Deep Visual Semantic Embedding(DeViSE)
DeViSE 模型[95]在NIPS 2013 会议上提出,其进行零样本学习通过以下3 个步骤。首先,预训练一个Word2Vec 中的skim-gram 词向量网络。网络的作用是输入单词能够找到其相近的单词,即查找输入单词的上下文。其次,预训练一个深度神经网络。网络的作用是对图像的标签进行预测。深度神经网络[95]采用的是在2012 年ImageNet 大型视觉识别挑战赛获奖的1 000 类别分类器,同时,分类器也可以使用其他预训练的深度神经网络。最后,将两个预训练模型进行预测的softmax层去除,然后合并两个模型,通过学习双线性函数以及相似性度量,对不可见类进行预测。DEVISE模型还使用排序损失进行优化。模型结构如图8 所示。这是一种图像信息嵌入语义空间的模型。
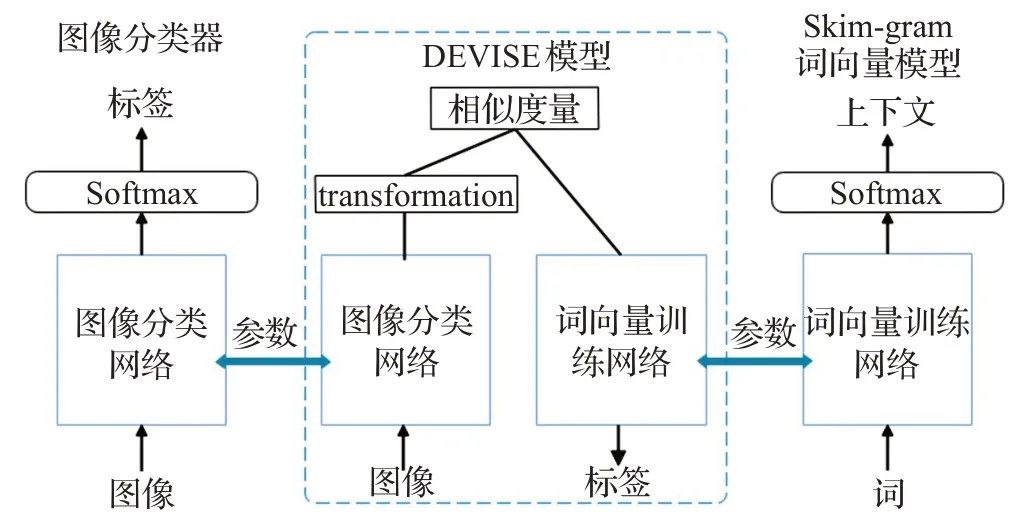
图8 DeViSE模型结构Fig.8 Structure of DeViSE model
DeViSE模型由于使用了skim-gram模型,其在语义上具有很强的泛化效果。这也使得它即使预测出来的标签错误了,结果也是非常接近正确值。但是,其图像分类器所采用的神经网络并非最佳,可以将其换为目前最好的图像分类器,例如在WACV 2021 会议上由文献[96]提出的Intra-class Part Swapping(InPS)模型。
DEViSE模型在挑选数据集方面,选择使用ImageNet的子集ILSVRC。在数据集配置方面,将数据集分为50%的训练集以及50%的测试集。但最终实验由于分类器还不够成熟,没有取得很好的精确度。
(3)Attribute Label Embedding(ALE)
ALE 模型[97]在CVPR 2015 会议上提出,对于DAP模型的三个问题:无法增量学习、预测类别差强人意、无法使用其他辅助源,ALE 首先通过SVM 学习双线性函数,从图像中提取特征以及将标签与属性对应起来。其次借助WSABIE 目标函数的思路,设计排序损失函数,使得特征空间与语义空间对齐损失最小化,继而对不可见类预测进行解决。同时,属性还可以换成其他辅助源,如HLE(Hierarchy Label Embedding)模型的层级,AHLE(Attributes and Hierarchy Label Embedding)模型的层级与属性结合。ALE 模型结构如图9 所示。这是一种图像信息嵌入语义空间的模型。
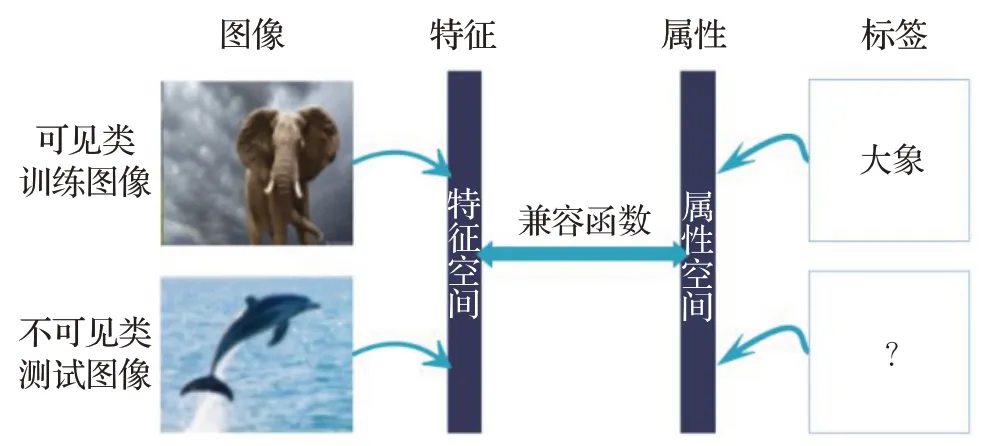
图9 ALE模型结构Fig.9 Structure of ALE model
ALE模型在挑选样本方面,选择AWA以及CUB两个动物数据集。在数据集配置方面,将AWA 数据集分为40 个训练类和10 个测试类,将CUB 分为150 个训练类和50个测试类。最终实验在这两个数据集上能够取得多类别49.7%和20.1%的精确度。
ALE 模型的缺点也是显而易见的:其一,标签所用属性描述是人为定义的,如果两个标签之间共享的属性基本一致,则会导致它们在属性空间中难以区分;其二,从图像中提取的不同特征可能对于同个属性。
(4)Structured Joint Embedding(SJE)
SJE 模型[98]在CVPR 2015 会议上提出,其受SVM的启发,将语义空间一种语义信息(属性)扩展到了多种语义信息融合的空间。SJE 模型与ALE 模型的训练过程相似,首先通过SVM学习双线性函数,从图像中提取特征以及将每一种语义信息与标签对应起来。其次设计排序损失函数,使得特征空间与每一种语义空间对齐损失最小化。最后比较每一种组合语义信息的效果,使用最好的效果对不可见类进行预测。SJE 模型的语义空间可以是属性、Word2Vec 编码的类别、Glove 编码的类别、WordNet 编码的类别。损失函数选择二分类损失。SJE模型结构如图10所示。

图10 SJE模型结构Fig.10 Structure of SJE model
SJE 模型在挑选样本方面,选择AWA、CUB 以及斯坦福大学推出的狗集3 个动物数据集。在数据集配置方面,将AWA 数据集分为40 个训练类和10 个测试类,将CUB分为150个训练类和50个测试类。最终实验在AWA 数据集中最高可获得66.7%的准确率;能在CUB数据集中最高获得50.1%的准确率。
由于SJE 模型计算每一类语义空间与特征空间之间的兼容函数,使得SJE模型能够进行细粒度识别。但也正因为如此,其必须在所有兼容函数计算完成后才能进行,这使得它的效率较为低下。
(5)Latent Embeddings(LatEm)
LatEm 模型[99]在CVPR 2016 会议上提出,其是SJE模型的变体。LatEm模型预测标签由以下步骤完成:第一,将训练图像分为多个特征并把每个特征使用线性函数映射到特征空间。第二,将标签与每个语义空间进行映射。第三,计算每个特征与每个语义空间的兼容函数。第四,给定测试图像,模型选择一个最为合适的兼容函数进行预测。LatEm模型将SJE模型中双线性函数变更为分段线性函数,是一个线性函数的集合,其作用是为测试样本找到最好的线性模型,而选择的过程可以看成是潜在变量。模型还针对分段函数无法使用常规优化,提出了改进版的随机梯度下降(Stochastic Gradient Descent,SGD)与排序损失结合算法。LatEm 模型结构如图11所示。
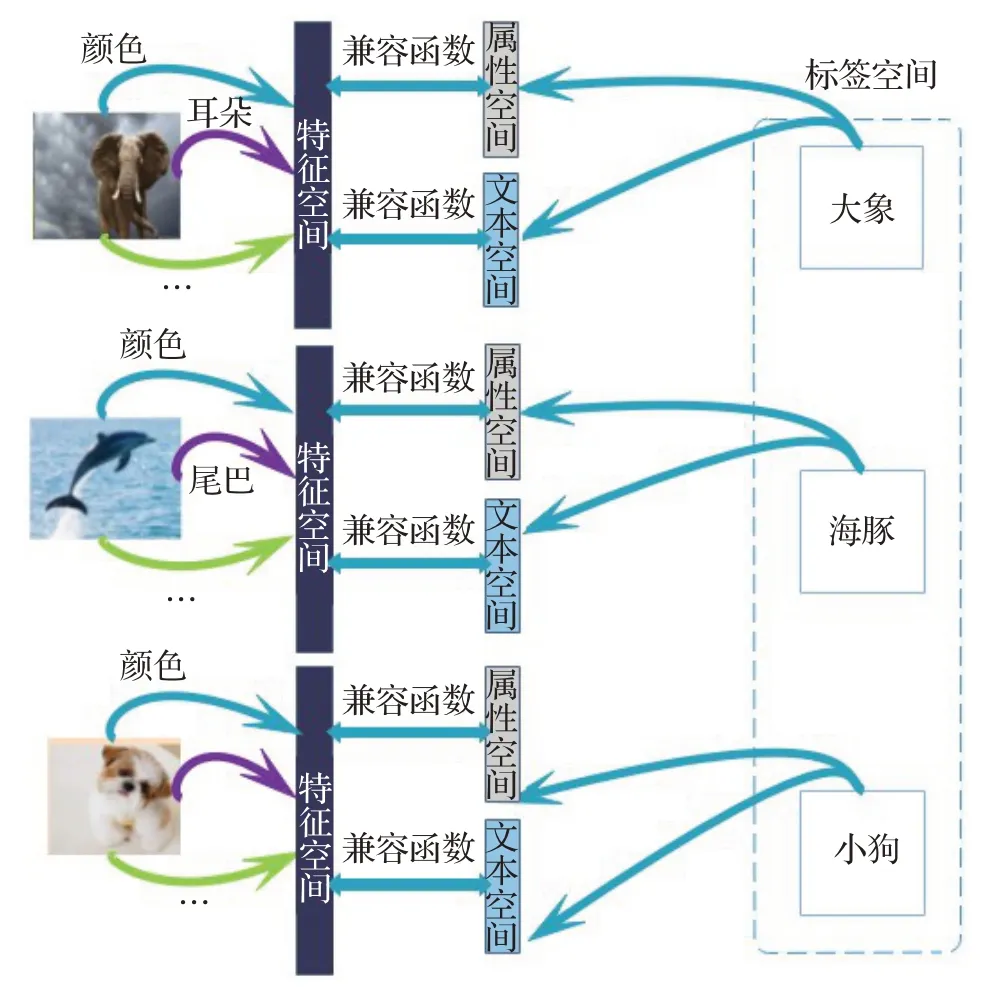
图11 LatEm模型结构Fig.11 Structure of LatEm model
LatEm模型在挑选样本方面,选择AWA、CUB以及斯坦福大学推出的狗集3 个动物数据集。最终实验在AWA 数据集中最高可获得71.9%的准确率;能在CUB数据集中最高获得45.5%的准确率。
由于LatEm模型考虑了图像的重要信息,使得它在细粒度分类上表现出来的效果在当下依然能够达到不错的效果。当然,在语义一致性以及空间对齐方面的问题也使得这个模型有些瑕疵。
(6)Semantic Similarity Embedding(SSE)
SSE模型[74]在ICCV 2015会议上提出,其假设不可见类为按照一定比例的混合的可见类。通过直方图将所有数据(包括可见类和不可见类)表示为多个百分比的可见类。直方图可以看作是可见类与不可见类之间的公共空间。SSE 模型将多种语义信息进行融合嵌入到公共空间,同时也将图像信息也嵌入到公共空间,计算两者的相似度。如果语义空间映射到直方图与图像空间映射到直方图相似,则将两者归为一类,继而完成对不可见类的预测。SSE 模型推理过程如图12 所示。模型针对仅使用分布对齐时会导致分类错误的问题以及仅考虑分类会出现没有完全对齐的问题,提出优化的结合分布对齐和实例分类的零样本学习。

图12 SSE模型推理过程Fig.12 Reasoning process of SSE model
SSE 模型在挑选样本方面,选择AWA、CUB、aPY、SUN 这4 个数据集。在数据集配置上AWA 数据集按50%为训练集,50%为测试集划分,CUB数据集分为150个训练类和50个测试类,aPY数据集与AWA相同,SUN数据集中10 类作为测试集。最终实验在4 个数据集上分别最高可获得76.33%、40.3%、46.23%、82.5%准确率。SSE 模型能够应用于大规模数据集,文献[92]的实验结果证明了这个优点,并且其在SUN 数据集上的运行效果稳定。但是,由于模型的类别是混合组成的,其对细粒度的分类并不能很好的识别。
(7)Joint Latent Similarity Embedding(JLSE)
JLSE 模型[75]在CVPR 2016 会议上提出,其首先使用SVM,通过双线性函数学习语义空间到其子空间以及图像空间到其子空间的映射。最后计算两个子空间之间的相似度。而子空间是通过概率模型得到的与原空间概率分布类似的空间。JLSE模型能够极大地减缓语义间隔的问题。
JLSE模型在挑选样本方面,选择AWA、CUB、aPY、SUN 这4 个数据集。在数据集配置上与SSE 模型相同。最终实验在4个数据集上分别最高可获得80.46%、42.11%、50.35%、83.83%准确率。
(8)Cross Modal Transfer(CMT)
CMT 模型[72]在NIPS 2013 会议上提出。与LatEm模型使用分段线性函数不同的是,CMT 模型通过两层隐藏层的神经网络将从图像中提取到的特征信息直接映射到50 维词向量空间中。针对广义零样本学习问题,模型对所给的测试样本先进行分类,属于可见类还是不可见类。由于是在语义空间中进行分类,模型给出离群点检查方法。对于可见类,使用传统的Softmax 分类器进行分类;对于不可见类,则使用混合高斯模型进行预测。
CMT 模型在挑选样本方面,选择CIFAR10 数据集。最终实验在不可见类分类上最高可获得30%的准确率。
(9)Deep Embedding Model(DEM)
DEM 模型[66]在CVPR 2017 会议上提出,其与之前的嵌入到语义空间以及嵌入公共空间模型不同,模型选择图像空间进行嵌入。原因是图像空间的信息远比语义空间多,并能够相对的减缓枢纽点问题。DEM 模型与DEVISE模型的架构基本一致。第一,将图像通过卷积神经网络(Convolutional Neural Networks,CNN)提取特征,形成特征空间。第二,语义表示可以有三种形式:一种语义、多种语义以及图像的文本描述,第三种表示方式需要先通过双向RNN 进行编码,最后通过两个全连接层(FC)以及线性整流函数(Rectified Linear Unit,ReLU)提取语义信息。第三,这两个分支通过最小二乘损失函数进行连接。DEM模型结构如图13所示。

图13 DEM模型结构Fig.13 Structure of DEM model
DEM 模型在挑选样本方面,选择AWA、CUB 和ImageNet子集ILSVRC这3个数据集。在数据集配置上AWA、CUB 数据集采用SJE 模型配置,ImageNet子集采用360个类作为测试类。最终实验在3个数据集上分别最高可获得88.1%、59.0%、60.7%准确率。
DEM 模型除了有减缓枢纽点问题的优点外,还能够适用于多个模态,并且提供端到端的优化,能够带来更好的嵌入空间。但是,模型也只是停留在理论层面的优势,在实践过程中,对零样本学习的效果不佳。
以上的模型都是基于嵌入的模型,它们之间的比较如表2所示。

表2 基于嵌入的零样本学习模型比较Table 2 Comparison of zero-shot learning based on embedding
2.3 基于生成模型的零样本学习
近年来,生成模型这一发现,引爆了计算机视觉许多领域,众多具有高实用价值的应用脱颖而出。现阶段生成模型有生成对抗网络(Generative Adversarial Network,GAN)、自动编码器(AutoEncoder,AE)、生成流(FLOW)。而在零样本学习领域,将语义信息嵌入到图像空间经常使用生成模型。在获取已知类视觉信息与语义信息的前提下,通过已知类与不可知类语义的连贯性,生成不可见类的样本,使得零样本学习变为传统的监督学习,将生成模型运用到极致。
(1)Semantic AutoEncoder(SAE)
零样本学习与AE 的结合。SAE 模型[61]在CVPR 2017会议上提出,其将语义空间作为隐藏层,通过编码器将可见类图像信息映射到语义空间,再通过已知类与不可知类语义的连贯性,使用解码器将语义信息生成不可见类图像,继而将零样本学习转化为传统的监督学习。SAE 模型的前提条件是图像信息到语义空间的映射矩阵是语义空间生成图像的嵌入矩阵的转置,并且加入了有惩罚项的约束,即图像信息到语义空间的嵌入矩阵与可见类图像信息表示的乘积等于隐藏层表示。这使得编码后的图像能够尽可能的保留原始图像的所有信息。SAE模型结构如图14所示。

图14 SAE模型结构Fig.14 Structure of SAE model
正是因为如此,SAE模型不仅模型简单,效果好,还能够运用于广义零样本学习,更能够解决领域漂移问题。但是SAE 模型所使用的语义信息与图像信息的嵌入函数过于简单且固定,无法生成高质量图片,不能十分精确地预测不可见类样本。
SAE 模型在挑选样本方面,选择AWA、CUB、aPY、SUN 和ImageNet 子集ILSVRC 这5 个数 据集。在数据集配置上采用1.4节的一般配置。最终实验在5个数据集上分别最高可获得84.7%、61.4%、55.4%、91.5%、46.1%准确率。
(2)f-x Generative Adversarial Network(f-xGAN)
零样本学习与生成对抗网络(GAN)的结合。f-xGAN模型在CVPR 2018会议上提出,指的是f-GAN、f-WGAN、f-CLSWGAN模型[48]的总称,其强调的是生成特征,而不是生成图像。首先,将图片特征通过卷积神经网络提取出来。卷积神经网络可以其他特定任务训练得出的,例如GoogleNet、ResNet、ImageNet 预训练模型。其次,结合随机噪声以及语义信息,通过生成网络得到生成特征。这个生成网络可以是一般的条件生成对抗网络GAN,也可以是加上优化的Wasserstein距离的WGAN,亦或是在WGAN 基础上加上分类损失的CLSWGAN。再而将语义信息、图像特征以及生成特征一并放入判别器。最后产生的不可见类特征放入分类其中,完成对不可见类数据的预测。f-xGAN分类过程如图15所示。

图15 f-xGAN分类过程Fig.15 Classification process of f-xGAN model
f-xGAN 模型没有训练语义与图像之间的嵌入关系,而是通过生成特征,将图像分类转化为图像特征分类来进行零样本学习。生成特征方法的好处在于生成特征数量无限,计算量小,训练时间少,效果好,还能够运用于广泛零样本学习。但由于f-xGAN模型使用的是生成对抗网络,生成数据的概率分布可能并不在给定数据上,会导致出现模型奔溃。
f-xGAN 模型在挑选样本方面,选择AWA、CUB、SUN、FLO(Oxford Flowers)这4个数据集。在数据集配置上采用1.4节的一般配置。最终实验在4个数据集上分别最高可获得69.9%、61.5%、62.1%、71.2%准确率。
(3)Invertible Zero-shot Flow(IZF)
零样本学习与流模型(FLOW)的结合。IZF模型[73]在ECCV 2020会议上提出,其利用FLOW的思想,通过可逆神经网络将已知类图像特征映射到语义和非语义空间,再利用可逆神经网络的逆网络直接生成不可知类样本,进而将零样本学习转化为传统的监督学习。IZF结构如图16所示。可逆神经网络的优点使得该模型只需要训练一次网络,得到参数,就可以直接运用于其逆网络,无需再次训练网络。

图16 IZF结构Fig.16 Structure of IZF model
IZF 模型通过双向映射,充分的利用已知类信息,不仅解决了生成对抗网络在零样本下学习应用中出现的模式奔溃问题,还解决了自动编码器在零样本学习中无法生成高质量图片问题。IZF 模型更是通过扩大已知类与不可知类的分布,解决了零样本学习固有的领域漂移问题。但是IZF 模型与传统的流模型NICE[100]、RealNVP[101]、GLOW[102]一样有明显的两个缺点:其一,可逆神经网络很难构建;其二,多次变换所需求得的雅可比行列式复杂,计算量庞大,训练时间长。
IZF模型在挑选样本方面,选择AWA1、AWA2、CUB、aPY、SUN 这5 个数据集。在数据集配置上采用1.4 节的一般配置。最终实验在5 个数据集上分别最高可获得80.5%、77.5%、68.0%、60.5%、57%准确率。
综上所述,在预测不可见类数据标签方面,基于属性的零样本学习多采用两阶段式,嵌入零样本学习多采用转移到能够比较的空间方式,生成模型零样本学习多采用生成不可见类样本方式。在数据集方面,小数据使用AWA、CUB、aPY、SUN。如需进行细粒度识别,则使用CUB、SUN 数据集。大数据集使用ImageNet。并且搭配常用的配置进行训练与测试。在评估指标方面,采用划分传统零样本学习以及广义零样本学习的配置,以可见类、不可见类每类准确率为指标,是一个零样本学习模型最佳的评估方案。在实现效果方面,上述模型中在广义零样本配置下,不可见类每类准确率在AWA、CUB、aPY、SUN数据集中最高的分别是IZF、IZF、DEM、IZF 模型。可见类准确率则是DAP、IZF、SAE、IZF 模型。在局限性方面,基于属性的模型取决于分类器的准确率,基于嵌入的模型取决于提供的语义信息质量,基于生成模型的模型取决于生成图片的智力。零样本学习经典模型发展如图17 所示;零样本学习模型比较如表3所示。
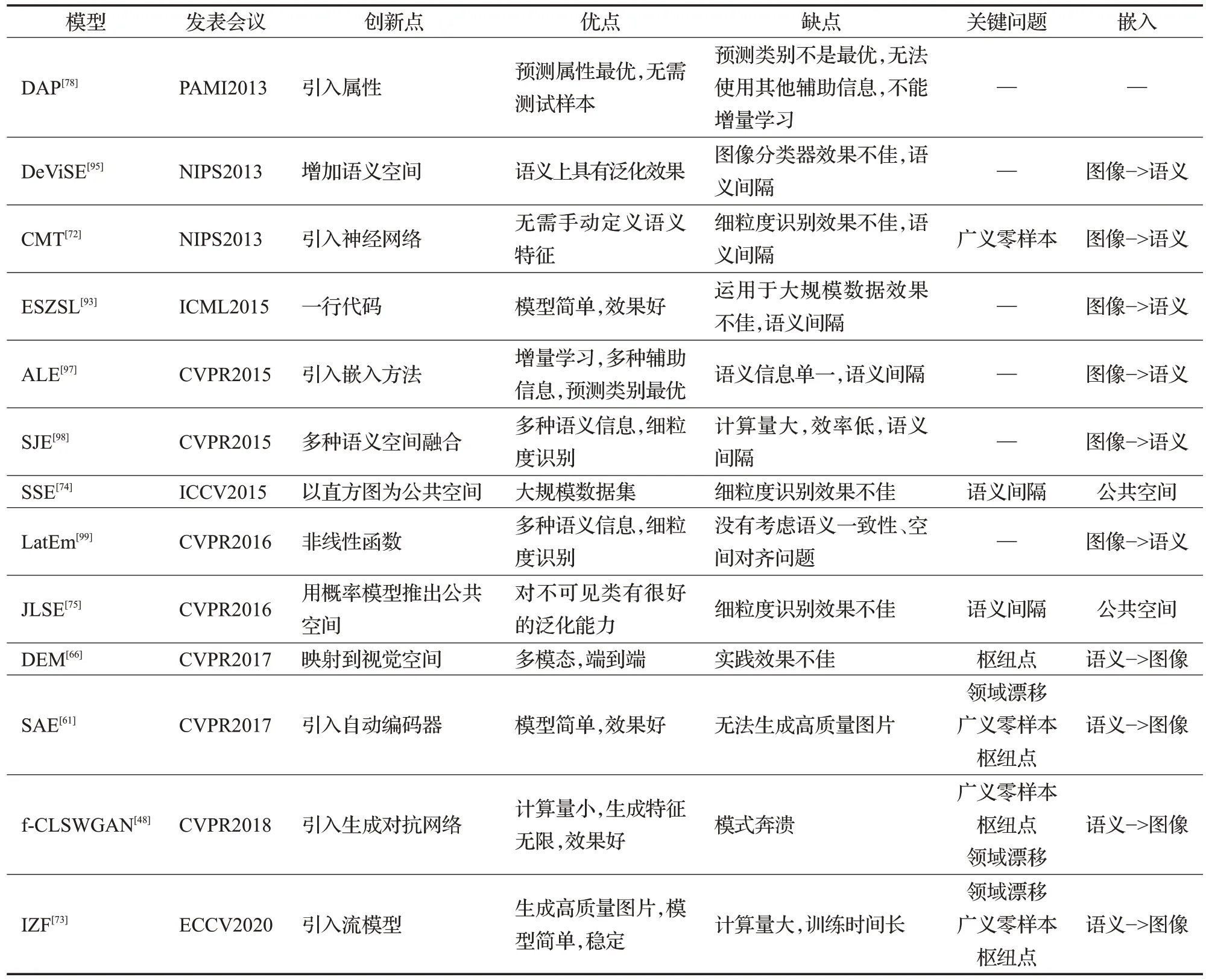
表3 零样本学习经典模型比较Table 3 Comparison of classic zero-shot learning model
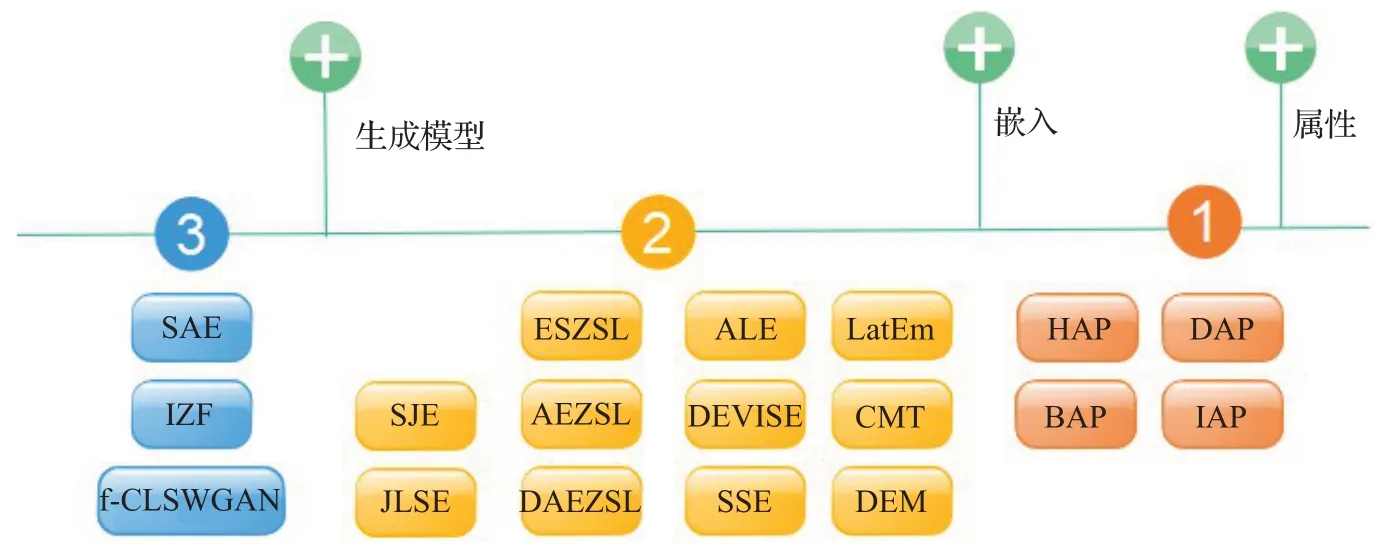
图17 零样本学习经典模型发展过程Fig.17 Development of classic zero-shot learning model
3 三维应用体系
本章主要介绍零样本学习在三个维度的应用。第一维是词。使用零样本学习技术对词作处理,并应用于多个领域。第二维是图片。在第一维应用中产生的文本信息可以作为语义信息,嵌入到视觉空间中,推进零样本学习在图片处理过程的应用。第三维是视频。视频中的每一帧可作为图片。将视频切分为图片,运用第二维的方法,使零样本学习在视频方面的应用更进一步。
3.1 一维:词
(1)对话系统
对话是由多个词组成。在对话系统中,涉及的技术有语音识别(ASR)、口语理解(SLU)、对话管理(DM)、自然语言生成(NLG)、文本生成语音(TTS)。按照流水线结构组成对话系统如图18所示。而零样本学习对对话系统的应用的贡献也是十分巨大的。例如文献[103]构建了一个统计口语理解模型,将口语理解模型推广到训练中从未出现的输入词或者训练中从未出现的输入类。在一个旧金山餐厅对话数据集中,实验出统计口语理解模型比支持向量机更好的运用于零样本学习,且这个模型大大减少了人工标注数据的数量。
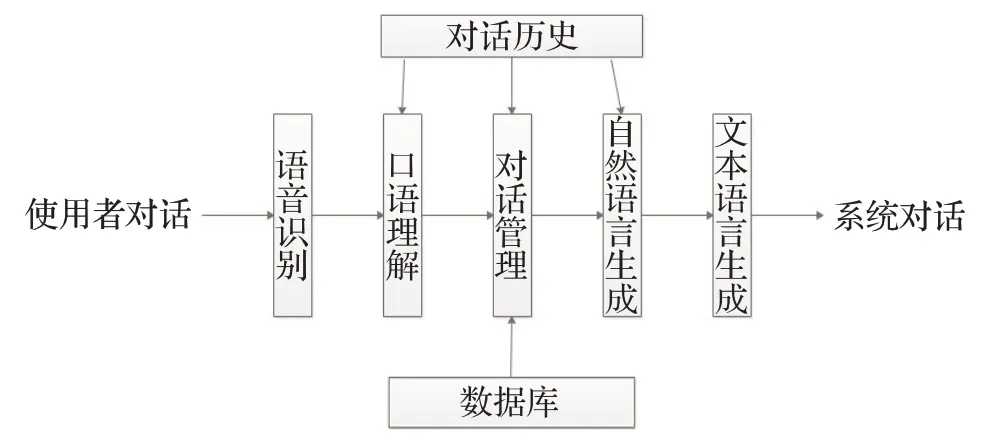
图18 流水线型对话系统Fig.18 Pipeline dialogue system
(2)机器翻译
语言是词的多种形式。在机器翻译中,FaceBook开发了一款包含90多种语言和28种不同字母表编写的工具包:LASER。该模型的原理是将所有语言使用多层BiLstm进行训练。LASER所有语言嵌入与传统单语言嵌入的区别如图19 所示。在介绍文本中,LASER 首先通过英语这一语种的数据进行训练,然后应用于中文、俄文、越南语等语言上,最终都取得了很好的结果。这个模型的成功说明对于一些没有样本甚至早已不可考究的生僻语种(如斯瓦西里语),可以通过已知语种的信息对生僻语种进行推理翻译,进而实现零样本学习的应用价值。

图19 语言嵌入对比Fig.19 Comparison of language embedding
(3)文本分类
文本是由多个、多种词组成的。在文本分类中,文献[104]采用简单的单词嵌入来计算标签与文本之间的语义相似度,进而预测出不可见类数据的标签。这个模型还能够解决文本多标签问题。
3.2 二维:图像
(1)图像检索
在图像检索方面,涉及的技术有基于文本的图像检索技术以及基于图像内容的图像检索技术。文献[105]构建了一种基于混合对象注意模块以及通道注意模块的模型来加强学习度量内的区分和泛化,从而运用于零样本的基于图像内容的图像检索。该模型最终在CUB数据集上取得了比当年最好的图像检索技术更好的效果。同时,这也是零样本学习与注意力机制的重要结合。
(2)目标识别
在目标识别方面,文献[106]使用属性描述来识别新出现的类别。这个模型在AWA 数据集上,对动物识别的准确率非常高。文献[107]提出两种方法对新出现的人脸在传统人脸识别上效果不好的问题进行优化。第一种方法采用属性分类器识别人脸图像可描述属性的存在与否,并预测出其属于哪类人。第二种方法使用名为微笑的分类器,旨在计算脸部区域与特定人之间的相似性,继而进行人脸识别。这两种方法的核心思想正是参考零样本学习属性以及嵌入的思想。这也是零样本学习在目标识别的重要应用。文献[108]构建了一种以WordNet 大型社交多媒体语料库为语义嵌入的对象分类器,实现对没有出现场景的识别。最终,通过实验证明该模型在SUN以及Places2两个大型数据集上表现优于属性模型。同时,稀有物种的识别也是零样本学习在图像上的重大应用。
(3)语义分割/图像分割
在语义分割方面,文献[109]提出一种新的模型ZS3NET。该模型结合深度视觉分割以及语义信息嵌入生成视觉特征的方法,实现零样本语义分割任务。最终在PASCAL-VOC和PASCAL-CONTEXT两个标准分割数据集上的实验,ZS3NET在零样本语义切分任务中表现出良好的性能,并且解决了广义零样本学习问题。
在图像分割方面,在2021 年的CVPR 会议上,提出零样本图像分割的解决方案:基于背景感知的检测-分割算法;并且文献定义了零样本下图像分割的标准,为数据样本难以获取的两个代表性领域:医疗以及工业后续的发展提供可行性方案。
3.3 三维:视频
(1)人体行为识别
人体行为识别领域,由于收集和标注视频中行为是十分困难且费力的工作,零样本学习通过文本的描述等信息可实现无样本识别大受欢迎。文献[110]通过支持向量机模型学习视频和语义属性之间映射,进而实现零样本人体行为识别。文献[14]将词向量作为可见类与不可见类之间的联系,通过嵌入视频以及标签实现零样本人体行为识别。文献[111]通过空间感知嵌入实现零样本人体行为识别的定位以及分类。
(2)超分辨率
超分辨率领域,零样本学习概念的引入,使得这个领域有了突破性的进展。超分辨率技术如图20 所示。与传统的超分辨率技术——提供高分辨率以及其对应的低分辨率样本进行训练不同,零样本超分辨率技术只需要提供低分辨率样本,然后通过退化(生成)模型得到更低分辨率的样本后进行训练即可。零样本超分辨率技术目前应用于多个领域,如在公共安全领域对摄像头抓拍到的视频进行超分辨率,以便公共安全部门进行识别;在医疗领域对医生远程会诊的视频进行超分辨率,恢复重要的局部细节[112]。

图20 超分辨率Fig.20 Super resolution
4 挑战与未来方向
作为新兴的研究领域,零样本学习已经具备了较为完整的理论体系和实际应用。根据嵌入方式的不同,其算法主要分为三大类,包括语义空间到视觉空间嵌入、视觉空间到语义空间嵌入和语义空间/视觉空间到第三公共空间嵌入。语义空间、视觉空间以及第三方空间,在机器学习领域也称为模态。由于受到模态内部的数据噪声、跨模态间数据的异构性以及跨模态导致的信息丢失等影响,使得零学习领域的性能仍具有较大的提升空间。目前,零样本学习领域中面临的主要挑战如下:
(1)由于零样本学习需要进行跨模态间的数据分析,因此,如何有效化解1.3 节所提到的语义间隔,将不同模态信息对齐并映射到相同的特征空间成为首要解决的问题。为此,研究人员分别提出了3种嵌入方案进行解决:语义到视觉的嵌入方法将可见类和不可见类的语义特征嵌入到同一个视觉空间进行对比;视觉到语义的嵌入方法将可见类和不可见类的视觉特征嵌入到同一个语义空间进行对比;语义特征/视觉特征到第三方公共空间嵌入将语义特征和视觉特征同时嵌入到同一个第三空间进行比对。这些方法很好地解决了多模态数据在比对时信息不对称的问题,然而,这些方法仅简单地对跨模态数据进行对齐,并未考虑数据本身存在的噪声、信息不足等问题在多模态对齐时造成的影响。此外,这些方法在进行模态间的信息对齐时,丢失了大量模态转化前的原始信息,并未综合考虑不同映射方式之间存在的相互共享和补充的情况。
(2)在零样本学习中普遍存在一个问题,即第1.3节提到的领域偏移问题,其问题的本质是不同模态数据之间存在较大的鸿沟。针对这个问题,研究人员提出了许多处理方法,例如:采用语义—视觉—语义或视觉—语义—视觉的双重嵌入方式来保证语义—视觉的强对应关系。这些方法虽然能够很好地解决语义—视觉的对应关系,但是却以较多置信度低的语义—视觉嵌入关系为代价。由于多个模态之间储存的信息差异较大,在进行双重嵌入方式构造对应关系时,会由于不同模态间的数据存在差异,影响最终的对齐效果。因此,如何有效地帮助信息储备较低的模态引入更多信息是处理该挑战的关键。
(3)零学习任务中可见类和不可见类的相关性会直接影响模型在不可见类上的预测性能。当可见类(如动物)与不可见类(如家具)相关性较小,存在较大的分布差异时,很容易出现领域漂移行为,导致模型在不可见类的识别性能降低甚至是无法识别,即出现迁移学习中的负迁移现象。如何简单有效地度量可见类与不可见类之间的差异来对模型进行自适应调整,迄今为止没有一个通用的方法。
(4)目前,零样本学习方法的训练模式较为单一,缺少协同训练(co-training)的过程。由于零样本学习的跨模态特性,致使其对于模态噪声更加敏感,而零样本学习本身就具备多模态、多视角的特征,使得在零学习中的协同训练更加具有研究意义。文献[113-116]中已经提出使用不同质(即不同模态或不同视角)的多个基础学习器协同训练可以有效提高学习模型的泛化能力。对于不可见类数据已知但其标签未知的情况,如何设计有效的协同训练方案,来挑选出可靠的、高置信度的样本进行进一步挖掘和训练并有效提高零学习的整体性能,是一个有待深入的问题。
针对以上4个挑战,引入集成学习思想是一个可行的解决方案。集成学习(Ensemble Learning)[117]是指通过构建并组合多个分类器(弱分类器)来完成同一个学习任务的机器学习方法,由于其具有比单一学习器更加显著的泛化性能而被广泛应用于情感识别[118-119]、文本分类[120-121]、图像分类[122-123]等多个研究领域,具有广阔的应用前景。随着集成学习研究的迅速发展,目前在零样本学习研究工作中已经出现了大量的引入集成学习思想来提高零样本学习性能的研究成果[12,124]。相较于传统的单模型零样本学习算法,集成零样本学习模型主要有以下优势:(1)集成样本零学习方法具有更好的泛化性能;(2)集成零样本学习通过对多模态数据进行挖掘和集成,可以解决多模态数据在语义对齐(跨模态)时导致的信息丢失问题,尽可能利用不同模态间的特征信息;(3)集成零样本学习对每个模态数据进行多视角挖掘,构建多视角中枢,解决零样本学习方法在学习过程中出现的领域偏移问题,增加模型泛化性;(4)集成零学习方法对于复杂的分布环境,如:噪声、异构数据、复杂数据分布等,具有很强的抗干扰能力。因此,如何产生差异性更大、泛化能力更强的多个跨模态语义对齐模型,并基于此构建源自不同视角的学习器,进而最终获得比单一学习器性能更好的集成零学习方法,是4个挑战的潜在解决思路。
5 结束语
本文通过124 篇文献对零样本学习的理论体系进行回顾,综述不同领域的应用情况。首先,通过零样本的研究背景推出其具体定义,并与传统的监督学习和广义零样本学习进行比较。其次,对零样本学习研究过程中出现的关键问题以及应用中经常使用数据集进行介绍。从零样本学习关键技术、属性、嵌入以及生成模型,按照出现的时间顺序列举了13 种经典模型,并对模型的过程、优点、缺点进行描述。然后,总结近些年来零样本学习在词、图像、视频中的应用。最后,根据关键问题以及实际中应用难题,提出零样本学习领域的4 个挑战,并引入集成学习来应对这些挑战,为研究者们提供新的研究方向。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
开放教育研究(2020年2期)2020-03-31
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
现代语文(2016年21期)2016-05-25
中国老区建设(2016年1期)2016-02-28
新校长(2016年8期)2016-01-10
大连民族大学学报(2015年2期)2015-02-27
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
