
基于对抗神经网络的增强YOLOv3模糊目标检测
2021-10-18 01:50梁铭峰成都信息工程大学四川成都610000
计算机应用与软件 2021年10期
梁铭峰 李 蠡(成都信息工程大学 四川 成都 610000)
0 引 言
随着高速公路与高速城市道路交通事故频率的不断攀升,防碰撞预警辅助装置的需求也在日益增多。由于行车记录仪的镜头物理特性导致在高速情况下出现图像失真、检测目标模糊等情况,通过消除模糊并提前预警前车的突然出现或者异常状况可以最大程度地使驾驶员做出相应的防御措施。模糊图像去模糊方法分为两种不同的类型:盲目和非盲目去模糊。早期传统方法主要围绕着非盲目去模糊展开,如Lucy提出的一种基于贝叶斯理论且使用最频繁、变体最多的迭代去卷积方式Lucy-Richardson图模糊算法[1]。Wiener或Tihkonov regularization范数最小化误差去卷积正则法也是最常用于获得IS估计的两种方法[2]。但在实际中很难找到适合模糊图像的滤波系数,因为每一个模糊图像的像素模糊都存在不确定性,无法预先设定好系数使其完美滤波。自从生成对抗模型被提出以来,GAN已经扩展到各种应用程序[3]。针对高速运动模糊的运用场景,本文对于模糊图像的处理采用生成对抗网络(GAN)。相较于传统处理模糊图像的方法,GAN网络的效率更高,对于图像的重建效果更好。本文采用的GAN网络主要为DeblurGAN[4],是基于条件对抗式生成网络和内容损失的端对端学习网络。深度检测算法可以分为“one-stage”和“two-stage”两类;“two-stage”检测算法将检测问题划分为两个阶段,首先产生候选区域(region proposals),然后对候选区域进行识别位置调整与目标分类,这类算法的典型代表是基于region proposal的R-CNN系算法[5],如R-CNN[6]、SPPNet[7]、Faster R-CNN[8]、FPN[9]、R-FCN系列算法[10]。“one-stage”检测算法由于不需要region proposal这个过程,直接产生物体的类别概率和位置坐标值,经过单次检测即可得到最终的检测结果,因此有着更快的检测速度,如YOLO、SSD[11]、Retina-Net[12]。为了更好地处理动态场景中的去模糊与目标检测所具有实时性与高准确性的要求,本文在YOLOv3[13]的网络基础上根据目标尺度进行网络裁剪压缩,与预处理网络相结合,形成深度融合的快速防碰撞交通检测模型。
1 DeblurGAN与YOLO检测原理
1.1 生成对抗网络
生成对抗网络(GAN)[14]是非监督式学习的一种方法,该方法由Goodfellow等在2014年首次提出。该网络主要由一个生成网络与一个判别网络构成,两个网络相互具有竞争性。生成模型G的目标旨在生成与真实图像相似的图像。判别模型鉴别器D的目标旨在将来自发生器的伪图像与真实样本尽可能分辨出来。两个网络模型都是基于深度神经网络构建的,因此,GAN网络构建了一种反馈循环结构,其中生成模型G帮助改进鉴别器D,与此同时鉴别器D帮助改善发生器G的生成质量,这两个网络模型相互反馈,针对目标任务相互优化,其原理与损失函数如图1所示。

(1)
式中:B来源于模糊图像数据源;S来源于真实图像数据源;psharp表示真实图像集中的图像S所对应的分布情况;pblurry表示模糊图像集中的模糊图像B经生成器G所产生的输出分布;E表示期望;D表示判别器对输入图像为真的概率;G表示生成器对图像的生成结果。
1.2 生成对抗去模糊预处理网络
DeblurGAN的网络结构主要由模糊生成器、去模糊处理和比较器三个模块组成,网络结构中包含两个1/2间隔的卷积单元、9个residual单元和两个反卷积单元。每个ResBlock由一个卷积层、一个实例归一化层和一个ReLU激活函数组成,这样可以模拟更逼真和复杂的模糊像素。该算法遵循Boracchi等[15]描述的随机轨迹生成的想法,通过将子像素内插于轨迹向量来生成图像。每个轨迹是复值向量,其对应于在值与连续域中跟随2D随机运动的对象的离散位置。轨迹生成是通过马尔可夫过程完成的,轨迹的下一个点的位置是基于先前的点速度和位置、高斯扰动、脉冲扰动和确定性惯性分量随机生成的。DeblurGAN的原理如图2所示。
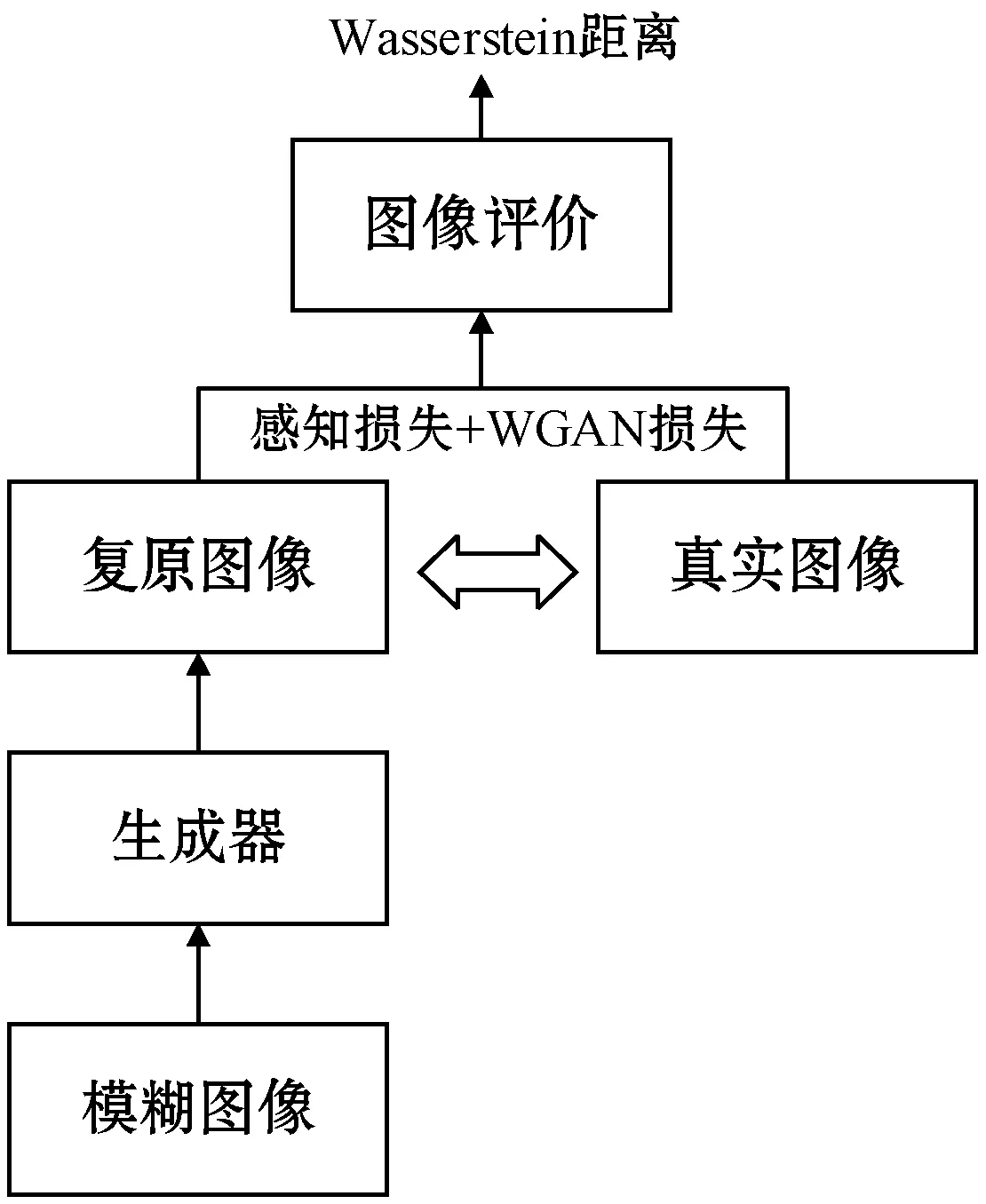
图2 DeblurGAN原理
随后对抗过程是使用两个卷积进行两倍下采样,同时将网络的通道数由原来的64增加至256。之后经由9个residual残差模块进行去模糊处理,最后由两个反卷积模块对图像的上采样还原图像最初的输入尺寸。DeblurGAN网络结构如图3所示。
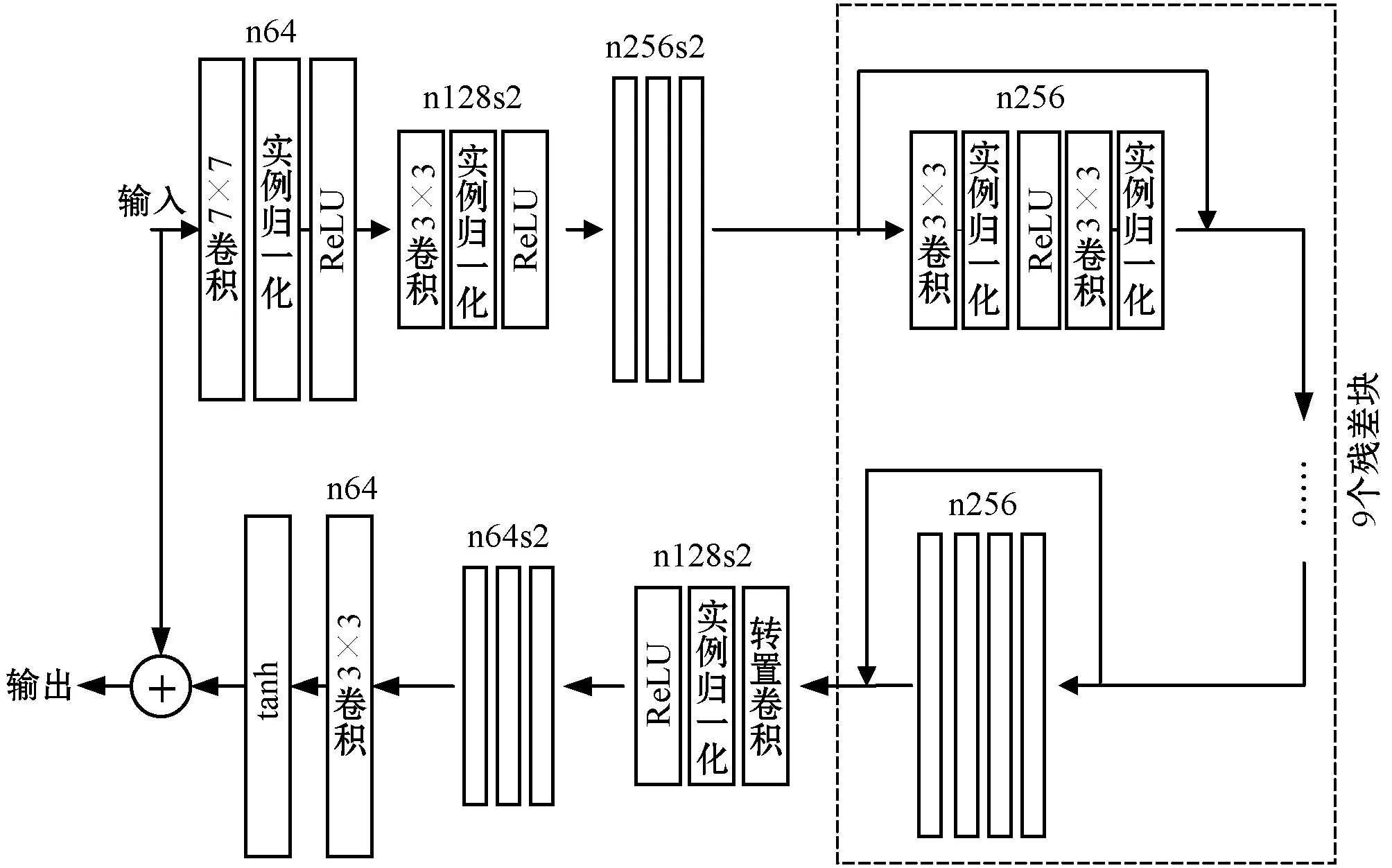
图3 DeblurGAN网络结构
1.3 YOLOv3检测网络原理
YOLO是一种一阶段目标检测算法,是端到端目标检测算法,它可以直接预测目标的类别和位置,因此具有高效的检测速度与精确度[16]。YOLOv3新提出了一种名为Darknet-53的深度特征提取网络架构,它包含53个卷积层,每个卷积后面都有标准池化层和Leaky ReLU激活层,并使用步长为2的卷积层来对特征图进行下采样。
YOLOv3将待检测图像划分为N×N个网格,如果待检测目标的中心位置落入网格中,网格则发起检测,预测出边界框的分布及其置信度得分,同时得到待检测目标分类的概率。边界框的组成包含五个数据值,即x、y、w、h和置信度,其中:x和y表示当前网格预测的对象边界框中心位置的坐标;w和h是边界框的宽度和高度。置信度的定义如下:
(2)
式中:pr(·)表示目标是否存在,当待检测目标落入网格中时pr(Object)=1,其他情况pr(Object)=0;IoU用于表示所预测的边框与实际边框的重合率大小,当多个边界框检测到同一目标时,则使用非最大值抑制(NMS)[17]用于选择最佳边界框。尽管YOLO的检测速度比R-CNN系列检测速度更快,但它具有较高的检测误差。为了解决这个问题,YOLOv3提出的第一项改进是使用多标签分类,使用多标签分类的Logistic分类器,对于重叠的标签,可以更好地模拟数据。以前的YOLO版本使用Softmax函数用于分类,而YOLOv3中的分类损失函数对每个标签使用二进制交叉熵损失判别,从而代替先前版本中使用的一般均方误差。第二项改进是使用不同的边界框预测方法,先前版本使用passthrough layer层,其作用是将前一层的feature map进行特征重排,然后与后一层的全连接层进行连接,感受野范围的缩小有利于提升对小目标检测的精确度,这个思想在YOLOv3版本中得到了更进一步提升。同时使用批量标准化BN(Batch Normalization)技术,它通过归一化的预处理达到调整和缩放激活输入图层,在所有卷积层上添加BN层后,YOLOv3的mAP提高了2%。此外,伴随着BN与Dropout技术的使用,使得模型过拟合的情况得到抑制。YOLOv3采用了3个不同尺度的特征图进行检测,经过32倍的下采样得到13×13的特征图,这里特征图感受野比较大,适合中大尺寸对象检测,第79层进行上采样与第61层进行特征融合得到较细粒度的特征图,具有中等尺度的感受野,适合中等目标检测。最后,第91层特征图再次上采样,并与第36层特征图融合,最后得到相对输入图像8倍下采样的特征图。它的感受野最小,适合检测小尺寸的对象[18]。YOLOv3不仅为大特征映射提供了更精细的目标信息,也为小特征映射提供了更深层的语义信息,通过上采样调整特征图的深度,通过串联与深层的特征图融合,使其具有良好的检测性能。
1.4 运动模糊原理
通常模糊图像可以使用式(3)进行建模。
F(x)=h(x)*f(x)+n
(3)
式中:F表示模糊图像;f表示清晰原图;h表示模糊点扩散函数PSF(Point Spread Function);*表示卷积运算符;n表示附加噪声,通常情况n是高斯噪声白噪声。
运动模糊是在曝光期间内,由待检测目标与物理镜头之间的相对线性运动所引起的,且与水平轴成θ角,运动模糊的点扩散函数表达公式如下:
(4)
式中:L是模糊长度;θ是模糊角度;x与y为真实像素点坐标。运动模糊处理效果如图4所示。

(a) 清晰原图

(b) 运动模糊处理图4 运动模糊处理效果
2 BL-YOLOv3
为了实现检测模糊图像功能,本文在YOLO网络的预处理功能中加入DeblurGAN网络,YOLO除了对输入的图片进行尺寸自适应外,同时也能够增强图像清晰度,并将模型应用于防碰撞预警检测任务,具体流程如图5所示。在新的网络结构中,去除了DeblurGAN网络的模糊生成器和比较器,只保留其去模糊处理,尽量减少GAN网络的加入对YOLO原网络的影响。当YOLO网络接收到输入的图片经过自适应处理生成416×416尺寸的帧图片后,由DeburlurGAN网络中的去模糊处理模块对其进行去模糊操作,DeburlurGAN在完成去模处理后经由反卷积网络层将图片大小重新恢复成416×416尺寸。去模糊完成后经由YOLO特征提取网络resnet网络进行特征的提取。在这一部分本文分析检测对象,行人、汽车、交通标志,三者有明显的刚性结构特征且不易混淆,先由YOLOv3-tiny网络进行训练测试,达到了mAP 54.23%的检测结果。考虑到将DebulurGAN加入到YOLOv3网络中势必会增加网络整体的计算量,大大降低其检测速度。基于在YOLOv3-tiny中测试得到的结果,对特征提取网络进行网络压缩,降低由于增加去模糊模块所带来的影响。分析YOLO的网络结构,其对于目标的特征提取网络主要由23个残差结构组成,每个残差结构由1×1和3×3的卷积层组成,之后分别由三个不同尺度的YOLO层完成对目标的检测。本次实验中采用的压缩方法主要为剪裁网络层和对网络通道进行降维。对YOLOv3网络层的参数结构进行分析,对于尺度为13和26的特征图所使用的卷积层通道数较多,其中含有较多的无效连接,因此对于这两个尺度的特征提取模块,本文均对其卷积层进行降维操作。分析整体应用场景,本文实验去除一半52尺度的特征提取通道检测,最终训练得出的mAP也能达到76.48%,相较于网络修改前所测得的mAP 79.14%,只下降了2.66百分点,即说明了52尺度的细粒度场景检测对于本次实验中的检测对象无太大检测增强作用。在网络结构中,本文将60至80层的卷积残差模块特征提取通道降为原来的一半。BL-YOLOv3检测流程如图6所示。

图5 防碰撞预警检测流程
2.1 建立行驶样本数据集
由于车辆日常使用环境的多变性,本实验通过行车记录仪截取了在不同天气情况(雷雨、阴天)下以及早中晚不同阳光强度下的行驶视频帧,并充分涵盖了上坡、快速、街道、下坡、急转弯等复杂路段。本文检测对象分别是行人(person)、车辆(Car)、交通标志(Traffic Sign),选取多个不同环境下且具有良好目标特征的视频帧后,利用LabelImg标工具对目标进行标示,最后将标签数据文件.xml转化为YOLO训练所需要的的TXT文本。数据集如表1所示。
2.2 模型训练
YOLOv3中的默认anchor尺度是由作者通过聚类VOC数据集得到的,20类目标中大到bicycle、bus,小到bird、cat,这样的anchor参数并不适合本场景的待检测目标对象,本文利用标签中的先验信息进行聚类计算anchor,提高bounding box的检出率。同时批次样本数(Batch)设置为64,为了进一步提升训练效率,将Subdivsion Size提高到16,将图像输入的默认resize尺寸由416提升到608以达到提升图像识别精度,迭代次数设置为83 000次,采用小批量SDG(随机梯度下降法)进行训练。本实验条件如下:基于Windows 10下的Visual Studio 2015平台,CPU为Intel I7-8700K,内存为32 GB,GPU为NVIDIA GTX-1080TI,硬件加速库为NVIDIA CUDA10.1。
3 实 验
3.1 去模糊块对比实验
为了检验BL-YOLOv3的去模糊块有效性,本文采用Lucy-Richardson算法估计点扩展函数(PSF)与维纳滤波器的传统图模糊算法、生成对抗网络去模糊块(deblur)与基于深度学习的图像超分辨率重建算法在二级运动模糊情况下进行仿真实验。Lucy-Richardson算法是一种基于贝叶斯思想的空间域上的图像复原方法,该算法从贝叶斯理论出发推导了图像迭代复原的基本框架。维纳滤波器则是用最小均方差滤波来去除含有噪声的模糊图像,其目标是找到未污染图像的一个估计,使它们之间的均方差最小。超分辨率重建算法则是对于一个低分辨率图像,先使用双三次(bicubic)插值将其放大到目标大小,再通过三层卷积网络做非线性映射,得到的结果作为高分辨率图像输出。本实验采用Tenengrad梯度的算法对增强图像质量进行评估。该方法利用Sobel算子分别计算水平和垂直方向的梯度,同一场景下梯度值越高,图像越清晰,衡量的指标是图像的平均灰度值,值越大,代表图像越清晰。去模糊实验效果如图7所示,图像质量评估结果如表2所示。

(a) Lucy-Richardson算法结果

(d) 超分辨率重建算法图7 去模糊实验效果

表2 图像质量评估
由结果可知,在相同运动的模糊强度条件下,Lucy-Richardson与维纳滤波器算法增强结果较差,当噪声较为复杂时,传统滤波方法难以计算出噪声的频域模型,不能合理地去除噪声干扰,在这个应用场景下几乎失去了目标检测条件。相对于超参数处理算法,deblur的Tenengrad的Sobel结果更大,质量评估效果更好,超参数处理算法在还原清晰图像过程中,会带来峰值信噪比(PSNR)与结构相似性指标(SSIM)的下降从而失去一些有用的细节部分,神经网络在浅层的特征提取只是位置信息,而加入的噪声会导致在深层提取细节信息时造成干扰。由于YOLOv3具有良好的泛化能力,在模型计算开销与实时性的客观要求下,deblur去模糊算法取得了较好的效果。
3.2 检测网络优化
由于本次检测的目标主要为车辆,其目标体积较大易检测。在YOLOv3结构的设计中为了增强小目标的检测加入了52尺度的特征检测,但根据实际应用场景中需要检测的目标为大目标较多,故本模型对52尺度的feature map进行裁剪,减少网络整体不必要的推算,并对裁剪前后的检测效果进行比对。同时对网络层的参数量进行计算,13和26尺度的feature map存在有计算量较多的层,为保证不丢失过多的目标信息,只对每个残差块中最后一个3×3卷积层进行通道压缩,压缩后的前后精度测试结果如表3所示。

表3 目标检测模型优化对比结果
综上,经过剪裁与压缩后的网络在精度上并没有太大损失,但对于计算量的减少与计算速度的提升有一定程度的优化。
3.3 训练结果与分析
本文进行了两组对比实验,分别使用改进算法BL-YOLOv3和YOLOv3算法在自建数据上进行训练测试,并计算出各自算法的AP(Average Precision),如图8所示。

图8 平均准确率对比
实验结果表明,相比在相同基础训练集上的YOLOv3模型,BL-YOLOv3网络在轻量化处理以后,其在准确性与精度上均达到了不错的水平,同时也加快了模型的识别速率与训练速度。从图8中可以得到,本文提出的BL-YOLOv3获得了75.48%的mAP,在此使用场景下,精度方面优于YOLOv3,在视频检测中,实时速率达到了42.16帧/s,满足实时检测的要求。可以看到,本文提出的模型对车辆、人、交通标志的检测分类具有较好的鲁棒性。
图9(c)和图9(d)右边图像为Deblur预处理过后的识别效果,对比未先预处理过的YOLOv3模型,可以看出,BL-YOLO在该应用场景下的(人、车、交通标志)的AP数据有了一定幅度的提升(约13%),取得了较好的效果。

(a) 模型视频帧测试场景示意1

(b) 模型视频帧数测试场景示意2
3.4 实验结果与分析
按照3.1节的实验配置,本文将结合BL-YOLO与YOLOv3在同一超参数设置下进行训练,并对测试结果做了横向对比。首先是对两个网络进行25 000次的迭代训练,将训练日志保存输出,绘制出两个网络的训练损失曲线图。曲线图如图10所示。
为了降低DeblurGAN网络的加入对YOLOv3检测速度影响,本实验对YOLO的主干网络进行了压缩,减少网络参数加快了网络的计算。通过训练损失曲线图可以看出,虽然对主干网络的压缩操作会对特征的提取造成一定的影响,但是压缩前后的训练损失偏差值只在0.1~0.2的范围区间,说明其检测精度并未大幅度下降,满足实际运用条件。
根据8 ∶2的训练集与测试集比例需求,本文使用测试集对BL-YOLOv3和YOLOv3进行对比测试。测试的内容主要包括准确率、召回率、漏检率和平均准确率,测试集为6 961幅经过运动模糊处理的样本。测试结果如表4所示。
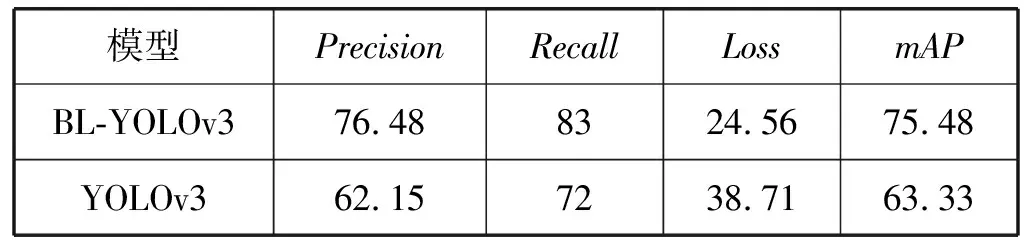
表4 测试结果(%)
(5)
(6)
(7)
(8)
分析表4数据,YOLOv3即使拥有良好的泛化能力,但是对于模糊图像的检测,其检测精度与检测性能都有明显下降。但是加入去模糊处理的BL-YOLOv3对于模糊图像的检测,精度与性能接近于目前深度学习算法对于该类目标检测的平均值,说明了去模糊处理的加入在很大程度上提高了检测性能。
关于二者的性能对比,查准率结果如图11所示,本实验直观地从P-R曲线图中可以看出,对于模糊目标样本的检测,优化后的BL-YOLOv3要优于YOLOv3。

图11 查准率结果
另外本实验采集了道路实景照片,经过不同等级的运动模糊处理模仿实际情况中可能出现的模糊效果,对改进前后的YOLOv3进行对比,二者的检测结果如图12所示。

(b) 二级模糊图12 运动模糊处理图像
图12(a)采用一级运动模糊模(一次运动模糊处理)拟车速较快时出现的模糊情况,图12(b)采用二级运动模糊(在一次运动模糊的基础上,保持相同参数再次模糊)模拟当车辆经过减速带等崎岖路面抖动造成的模糊情况。
对于一级模糊的检测对比如图13所示。

(a) YOLOv3

(b) BL-YOLOv3图13 一级运动模糊检测效果对比图
对于二级模糊的检测对比如图14所示。
从图13(a)和图13(b)的对比结果直观分析,在一级模糊的情况下YOLOv3的检测只出现了小规模的漏检情况,但在二级模糊条件下,如图14(a)和图14(b)所示,YOLOv3基本失去检测能力。但是改进后的算法仍然能对目标进行有效检测,说明了加入去模糊模块对检测性能的提升有很大的帮助。
4 结 语
本文提出一个基于生成对抗网络去模糊网络模块实时检测算法的目标检测神经网络BL-YOLOv3,并用于实时防碰撞预警驾驶视频目标检测,为汽车前向目标防碰撞测试提出了优化方案。利用DeblurGAN的快速盲去模糊预处理的方法,优化了一般检测算法在模糊环境下的检测精度。为了证明本文方法的有效性,将其与YOLOv3方法进行了比较。实验结果表明,与YOLOv3模型相比,BL-YOLOv3在检测速度与精度上有了显著的提高。目前对灰暗环境以及处于反光条件的小目标交通标志的识别中,仍然出现空目标或者识别框不准确等问题,这是下一步需要继续完善的地方。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
汽车工程师(2021年12期)2022-01-18
小学生学习指导(低年级)(2021年12期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
阅读与作文(英语初中版)(2019年8期)2019-08-27
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
