
试论IFLA LRM对FRSAD的继承与发展
2021-10-19 02:19蔡丹
图书馆学刊 2021年9期
蔡 丹
(国家图书馆,北京 100081)
1 引言
IFLA LRM 全称为 IFLA Library Reference Model,译作 IFLA 图书馆参考模型。2017 年 8 月,作为FR 家族概念模型的统一版由IFLA 专业委员会批准正式发布。自FRBR 于1998 年诞生以来,FRAD 和FRSAD 相继发布,三者均以“实体—关系”框架建立模型,将对书目领域的研究从书目数据延伸至规范控制领域,由此构成了彼此补充、相互联系又各自独立的FR 家族概念模型。FR 概念模型的构建对编目理论和实践产生了深刻的影响[1]:在编目规则方面,概念模型虽不能直接作为编目规则使用,但却是指导规则编制的思想基础,《资源描述与检索》(Resource Description and Access,简称RDA)正是基于FR家族概念模型编制的一部国际编目规则;在编目实践方面,很多图书馆都在探讨在联机公共检索目录中实现书目数据的FRBR 化显示。然而,分立建模也存在明显的局限性,例如,针对某些相同的问题,3个模型在界定及处理方法上存在差异;3 个模型各自的平面化结构造成了整体的重复冗赘;一个完整的书目系统要用到全部3个模型,需要以特别的方式解决诸多复杂的问题,而模型本身并没有对此做出指导。因此,编目界迫切需要一个统一的概念模型来指导编目规则的制定和书目系统的实施,IFLA LRM 应运而生。
ILFA LRM 模型为高级概念模型,旨在明确控制书目信息逻辑结构的一般原则,而并不直接规定数据的编制方法或存储系统,即不对传统上存储于书目或馆藏记录和存储于名称或主题规范记录中的数据进行区分,所有这些数据在IFLA LRM中都包含在“书目信息”这一术语中[2]。IFLA LRM与FR 家族3 个模型相比,在建模方法和编排结构上有一致性,但在术语和定义方面有了较大的变化,更具抽象化、普遍化和逻辑化。具体而言,FRBR 和FRAD 的研究对象分别为书目数据和名称规范数据,其模型相对比较容易接受和理解,而FRSAD 的研究对象是构成书目世界的另一重要部分——主题规范数据,其晚于FRBR 和FRAD 多年才构建完成,足见其建模的难度。尽管FRSAD 最初的研究对象为FRBR 的第3 组实体(概念、物体、时间、地点),但实际上,在研制过程中,FRSAD 已经将研究对象确定为更广泛的实体超类“Thema”和“Nomen”,FRSAD 中的关系也指的是“Thema”和“Nomen”的属性和关系,与FRBR和FRAD相比,研究内容更为抽象和理论化。可以说,FRSAD 已经上升为对整个人类知识组织方法的研究,属于高等哲学范畴[3]。IFLA LRM 对FR 家族三模型的元素进行了简化和提炼,最重要的就是引入了FRSAD 中“超类”的概念,并由此新增的两个非常重要且颇具抽象性的实体“资源”(Res)和“命名”(Nomen)也明显受到了FRSAD 模型的影响和启发。笔者由此进一步探研ILFA LRM 和FRSAD 模型之间的关联之处,希望通过理论层面的分析,更好地理解主题规范数据在编目实践中的应用。关于IFLA LRM 和FR 家族概念模型之间的区别与联系已有其他多篇论文论述,笔者不再赘述。
2 FRSAD概述
FRSAD 全称为 Functional Requirements for Subject Authority Data,译作“主题规范数据的功能需求”,由 IFLA 于 2011 年 5 月正式发布,后来于2013年3月进行过修订。FRSAD与1998年出版的《书目记录的功能需求》(Functional Requirements for Bibliographic Records,简称 FRBR)和2009 年发布的《规范数据的功能需求》(Functional Requirements for Authority Data,简称FRAD)共同构成了FR 家族概念模型。FRSAD 是对主题规范数据的功能需求进行阐述的概念模型,同样是基于FRBR“实体—关系”模型构建,但其所划分的实体与FRBR和FRAD有很大不同,更加宏观和抽象。
在FR 家族概念模型中,FRAD 名为规范数据的功能需求,但由于对规范控制领域的研究不易统一进行,其最终未能完全涵盖主题规范控制的要素。因此,就FRBR 框架的三组实体而言,FRBR主要针对第一组实体,FRAD 主要针对第二组实体,而针对第三组即主题实体的研究仍有待完善,这也是单独制订FRSAD 的原因。2005 年4 月,IFLA 成立了主题规范记录功能需求工作组(Working Group on Functional Requirements for Subject Authority Records,简称FRSAR 工作组),全面分析主题规范记录的实体、属性和关系,调查主题规范数据被广大用户直接和间接应用的情况。2011年,FRSAD 正式出版,它与 FRAD 同为以 FRBR 模型对规范控制领域的研究,是对FRAD 的必要补充,是FR 家族中将FRBR 知识组织理论发挥到极致的代表。FRSAD 的完成,标志着FRBR 理论和框架全面覆盖了整个书目世界。
主题规范的一项重要任务是建立主题词之间以及同其他系统的标引词之间的联系,既保证了在一个系统内部主题标引的规范和统一,也能实现不同系统之间主题规范数据的共享。从全球信息机构来看,不同的系统可能使用了不同的主题规范数据,它们之间的共享通常通过词表之间或词表与分类法之间的语义映射实现。要构建更具普适性的概念模型,需要从更为宏观的视角来审视主题规范记录的功能需求。因此,FRSAD 构建了“Thema-Nomen”概念模型,它将主题同主题所知的、所指的和所称谓的东西分离开,不管各个系统中使用何种形式、语种的Nomen,如果其所指的Thema是相同的,就能方便地实现主题规范数据的全球共享和利用。Thema-Nomen 模型可以在更为抽象的层面上理解作品的主题和主题指代名称,超越语种、文化、国籍、地域的限制,为未来书目世界的统一规范控制提供了一种可资利用的框架[4]。
3 IFLA LRM 对 FR 家族概念模型的整合
FR家族概念模型FR家族概念模型FR家族概念模型
如前所述,ILFALRM 旨在实现FRBR、FRAD和FRSAD3个概念模型的统一,解决模型间的矛盾与冲突,因此,简言之,ILFA LRM 就是对 FR 家族概念模型的整合。然而,该整合过程绝不仅仅是将3 个模型(FRBR、FRAD、FRSAD)简单地拼接在一起,而是通过对三模型中各元素(用户任务、实体、属性、关系)进行全面地审视与分析,寻求在现有定义的基础上进行合并,从而实现高级概念模型要求的一般化。整合过程依次审视和分析了用户任务、实体、关系和属性,对“实体—属性—关系”的建模经过了多次反复,每次过程都力争实现简化和提炼,然后再将这些简化和提炼应用于整个模型之中进行检验,以保证模型内部定义的一致性和完整性。
经过反复提炼,IFLA LRM 完成了对FR 家族概念模型的统一化,对原有三模型的元素进行了整合,包括保留(有可能更名或赋予更一般化的定义)、合并、一般化、另行建模或弃用。具体体现在以下几个方面[5]:(1)编制结构。IFLA LRM 在结构上进行了微调,它在阐明建模背景和方法之后,将用户任务提升到实体、属性和关系的内容之前,在明确用户任务的基础上,再对实体、属性和关系进行分析。(2)用户和用户任务。IFLA LRM 定义的用户和用户任务基本继承自FR 家族,略有调整,取消了FRAD 中的“阐明关系”和“提供依据”两个用户任务,整合并拓展了其他几项用户任务的内涵,使其更具普遍性。(3)实体。IFLA LRM 对 FR家族三模型中的实体进行了保留、合并、删除及新增,将原有的共计18 个实体整合为11 个实体,实体的结构由平面化变为立体化,即通过“超类”(superclass)和“子类”(subclass)结构反映实体间的层级。(4)属性。IFLA LRM 模型整合了 FR 家族三模型的所有属性,一是将不具普遍性的属性取消或整合为新的属性,二是将部分属性转化为了关系。(5)关系。IFLA LRM 也对FR 家族的关系进行了整合,包括保留、合并、取消和新增,共定义了36 种关系,其中有33 种存在非对称的逆向关系。IFLA LRM 仍然保留了家族模型中的重要关系,并与实体的整合相对应,提炼了更具普遍性的关系类型,并将其转移至更具普遍化的实体上,取消了与最终用户需求无关的关系。(6)对语义网环境的适应程度。IFLA LRM 是一个主要由格式化的表格和图表组成的简明概念定义文件,其借鉴了先前为FR 家族概念模型创建IFLA 词汇表的经验,具有更加高度结构化的形式,能够更好地在语义网环境下进行数据关联从而实现对数据的有效利用。
4 IFLA LRM关于主题的内容分析
IFLA LRM 受到FRSAD 最重要的影响就是引入了FRSAD 中“超类”的概念,由此其新增的两个重要且非抽象的实体“资源”(Res)和“命名”(Nomen)分别源自 FRSAD 的“Thema”和“Nomen”,且在实体定义、属性分析中有很大的相似性。因此,可以说,IFLA LRM 中关于“资源”和“命名”这两个实体的所有属性和关系均与主题相关。表1和表2分别对比了FRSAD 和IFLA LRM 中有关上述两个实体的定义、属性和关系,以便更加清晰地发现二者的相似性及变化,以及更好地理解IFLA LRM 关于主题数据的参考模型。
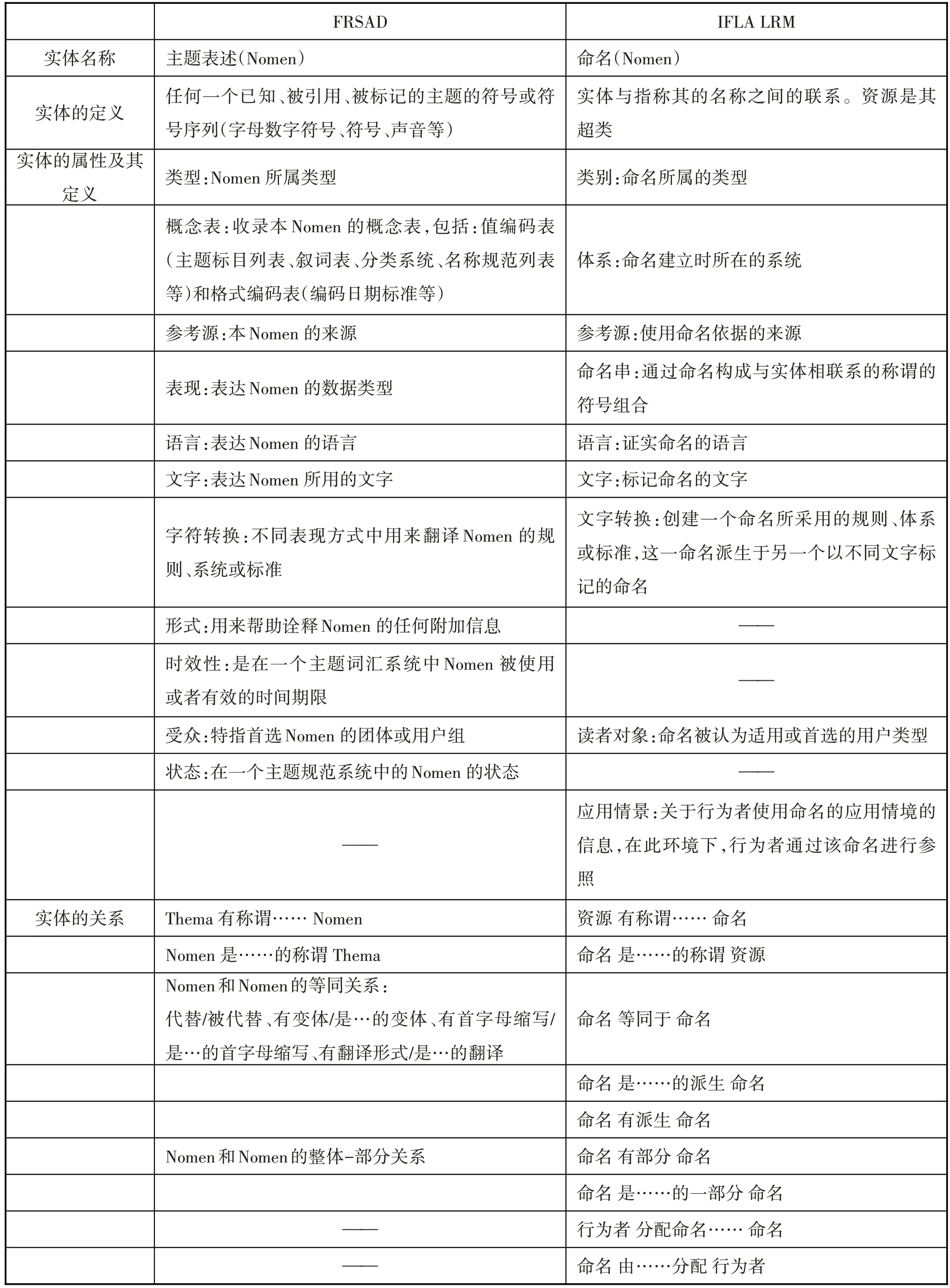
表2 Nomen的定义、属性及关系对比
4.1 实体Res和实体Thema
从表1 可以清晰地对比两个高级实体Res(IFLA LRM)和Thema(FRSAD)的定义、属性和关系。
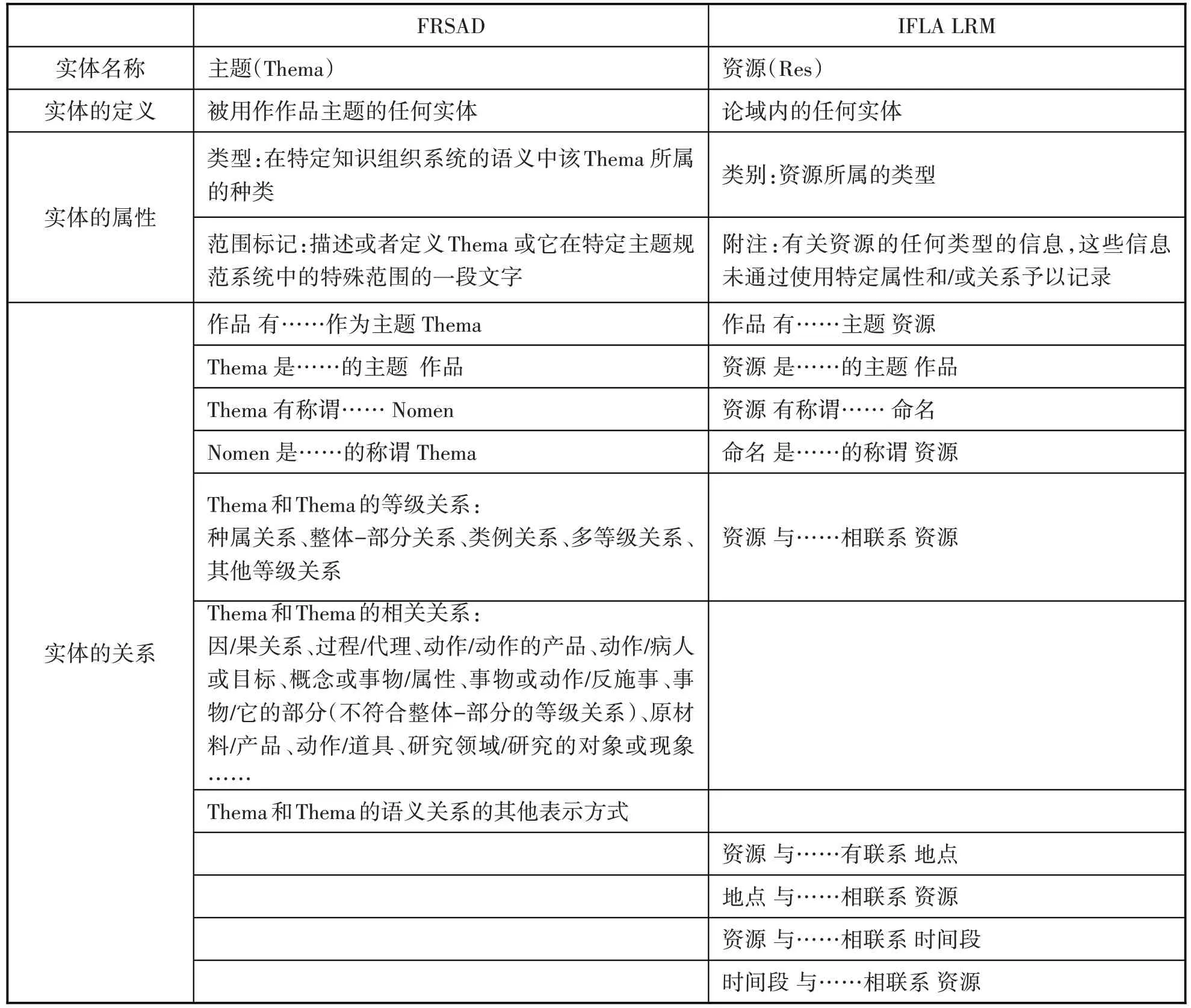
表1 Res和Thema的定义、属性及关系对比
一方面,可以发现二者存在很大的相似性。首先,从定义来看,Res 和Thema 都被定义为“任何实体”,只不过Thema 定义中有限定语“被用作作品主题的”,但在通常的认知中,任何实体都可作为作品的主题,因此,二者的定义从实质上来讲是一致的。其次,从属性来看,Res 和Thema 都定义了两个属性,尽管语言表述有所差异,但实质内容基本一致。最后,从关系来看,IFLA LRM 继承了FRSAD 中最重要的一组关系——不同类型实体间的关系,即作品-Thema-Nomen 之间的关系,并将其相应转化为作品—资源—命名之间的关系。
另一方面,从实体Res 到Thema 还是存在着一些发展变化。首先,Res 被定义为所有实体的“超类”,位于实体等级的顶层,这是对实体Thema 重要性的一个提升。其次,FRSAD 中相同类型的实体间的关系在IFLA LRM 中并没有明确列出,这是因为,IFLA LRM 模型本身就是对原有模型的简化和提炼,摒弃过于具体、细化的东西,提炼出更具一般性的内容,而 Thema 和 Thema 之间、Nomen 和Nomen 之间的关系更多地体现为具体主题词表中的语词之间的关系,正如IFLA LRM 所指出的“在主题词表环境下,作为主题的资源间的具体叙词关系可定义为高级关系的细化”,而其所谓的高级关系就是模型中最高层、最普遍的关系——“资源与……相联系资源”。最后,IFLA LRM 将部分实体的地点、时间方面的属性转换为了关系,定义为资源和地点之间、资源和时间段之间的关系,如个人的出生日期变为个人和时间段之间的关系,载体表现的出版日期变为载体表现和时间段之间的关系,这一点和主题概念中的时间或地点的分面涵义不同,这种分面在FRSAD 中是涵盖在Thema和Thema 的关系中的,但ILFA LRM 中的“资源—
地点”“资源-时间段”之间的关系实质上也包含了这种分面如事件发生的年代可以理解为事件和时间段之间的关系。
4.2 实体Nomen
与Res 和Thema 的对比类似,从表2 也可以比较清晰地看出Nomen 实体在两个模型中定义、属性和关系之间的异同。首先,从定义来看,IFLA LRM 中Nomen 的定义更抽象,而且从等级上不再和Thema 并列,而是作为Res的子类,但实质来看,两个模型中Nomen 的含义是一致的。其次,从属性来看,FRSAD 为 Nomen 定义了 11 个属性,IFLA LRM 定义了9 个属性,其中有8 个定义是一致的,归因于 IFLA LRM 对 FRSAD 中 Nomen 的属性进行了合并和转化:Nomen 的“形式”和“状态”可作为划分Nomen 类型的依据,因此合并入“类别”;Nomen 的“时效性”转化入“资源与时间段相联系”这一关系中。此外,IFLA LRM 还新增了1个属性“应用场景”,基于其认为该属性对于满足用户任务的意义重要。再次,从关系来看,ILFA LRM 基本继承了FRSAD 定义的关于Nomen 的关系,在此基础上,增加了Nomen 和行为者之间的关系,其认为“在书目环境中,命名分配适用于主题术语、受控检索点、标识符等的创建”,亦基于认为该关系对满足用户任务的意义重要。此外,IFLA LRM 保留了Nomen 之间的等同关系,即“命名等同于命名”,并定义为“这是命名之间的关系,它们是同一资源的称谓”,并指出“由此关系联系的命名从含义上具有等同的功能(分配给同一资源),但是,由于它们在为其记录的任何属性中保留了自己的值,所以就使用而言,它们是不可互换的。等同命名在重要属性方面可能有所不同,如体系、语言或应用情境”[2]。但是,IFLA LRM 为 Nomen 新增了“有派生/是……的派生关系”,将其定义为“表明一个命名用作另一个命名的基础,两个均为同一资源的称谓”,其指出“一个命名可由另一个命名派生而来,由于所使用符号的正式修改(如音译)或者由于文化或语言惯例的变化(缩写、简写或变异形式的创造)”[2],这里的派生关系实质是等同关系的一种情况,笔者认为,作为高层概念模型的IFLA LRM 无需再单列出派生关系,仅保留等同关系即可。
综上可以发现,FRSAD 已经具有高级概念模型的抽象性和理论性,IFLA LRM 则继承了FRSAD的这种特点,对原有模型的元素进行了高度提炼和简化,实现了作为高级概念模型要具有的一般性和普适性。同时,IFLA LRM 还继承了FRSAD 的实体、属性和关系,并在原有基础上更进一步。IFLA LRM 毕竟是对3 个模型的融合,其需涵盖的内容远多于FRSAD,因此,对继承自FRSAD 的实体、属性和关系,IFLA LRM 在内涵上了有了极大的丰富和拓展。
5 概念模型对主题标引实践的影响
无论是FRSAD,还是后来的统一版IFLA LRM,都是概念模型,都不预设数据存储于任何特定系统或应用。特别是IFLA LRM 模型“不对传统上存储于书目或馆藏记录和存储于名称或主题规范记录中的数据进行区分”“所有这些数据都包括在书目信息这一术语之中,也在模型的范围之内”。概念模型从实践中提炼一般逻辑规则,再用以指导具体应用规则的编制,概念模型中有关主题的内容也正是指导未来主题规范控制实践的思想基础。
通过主题途径获取信息早已成为用户满足其信息需求的重要方法,且通过在信息检索系统中进行词汇控制可有效提高主题检索的效率。在主题编目实践中,主题概念著录发展为主题规范数据和书目数据的结合,即通过书目数据对主题词进行规范控制。在绝大多数的大型书目数据库中,规范控制或者由手工制作完成或者利用规范文档半自动实现,这个文档包含了检索点的数据——名称、题名或者主题款目,这些主题款目在书目记录中被规范化。另外为了保证主题显示的一致性,一个主题规范系统往往也记录已经建立的主题概念和他们标签之间的语义关系。主题规范系统中的数据通过语义关系互相连接,这种关系在印刷本或在线显示的叙词表、主题词表、分类表和其他主题规范系统中以主题规范记录被表示出来或根据特殊的需要生成(如展示更加宽泛和更加专指的概念)[6]。这些系统被称为“受控词汇”“结构化词汇”“概念表”“编目方案”和“知识组织系统”等,根据他们的功能和结构,可以交换使用,也可以由使用他们的团体决定,在这些系统中规定了主题规范数据应用的规则。但如何将不同系统的主题规范数据应用到所有的系统和结构中,实现数据共享,满足用户的需求,则需要概念模型在更高层面上给予统一和指导。
IFLA LRM 为“资源”和“命名”实体的定义及其属性、关系的揭示提供了一个很好的主题规范数据的功能需求模型,但由于比较抽象,且主题编目本身是一个很复杂的过程,因此,IFLA LRM 在5.4 部分专门阐述了图书馆环境下的命名,其中指出“在图书馆环境中,个人、集体行为者(如家族和团体)或地点的命名传统上被称为名称。作品、内容表达和载体表现的命名被称为题名;用于主题环境的资源的命名名称不一,被称为术语、描述符、主题标题和分类号”[2],原FRAD 中的标识符和受控检索点都是命名的一种类型,其中,受控检索点是在书目系统中根据相关规则构建的命名,可以是名称、题名、术语、编码等形式。在当前的图书馆实践中,通常为具有重要书目意义且指称实体相同实例的命名集建立名称规范记录,同时也以之记录代表检索点(命名)首选形式的命名串和与任何变异检索点或标识符(附加命名)对应的命名串。尽管规范记录可以控制命名,而由命名指称的实体实例的快捷信息通常会和有关命名的信息共同记录在同一规范记录中,因此模糊了实体资源和命名之间的区别。在当前图书馆实践中,所有类型规范记录的建模非常复杂,超出了IFLA LRM的范围。
和概念模型相对的是编码模型,传统编码模型有MARC、DC,新兴编码模型有W3C的SKOS(简单知识组织系统)、OWL(对象本体语言)。笔者所述的概念模型与新兴的SKOS、OWL 等编码模型匹配的很好,这些编码模型提供了表达基本结构和KOS(知识组织系统)的内容(如叙词表、分类表、主题标目列表、大众分类法和其他相似类型的受控词汇,也包括本体)的模型。在语义网发展的背景下提出主题规范数据,特别是从网络数据的视角,由 IFLA LRM 模型化、SKOS 和 OWL 编码化的主题规范数据将成为关联开放数据的一部分,并将有助于语义网的进一步发展。
关联数据等语义网技术在图书馆界的应用及发展还有很长的路要走,无论计算机及网络技术如何助力关联数据发挥价值,图书馆应该始终关注自身数据的质量、共享自身的数据,并建立适用的模型[7]。笔者希望通过对编目概念模型关于主题规范数据思想的解析,更好地理解主题词表的编制需求及应用变化,为未来图书馆主题数据的关联化(如跨语种、跨领域等)提供思考。
猜你喜欢
都市人(2022年3期)2022-04-27
纺织科技进展(2021年5期)2021-07-22
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
东方女性(2018年3期)2018-04-16
军事运筹与系统工程(2018年3期)2018-03-26
散文诗(2017年17期)2018-01-31
商业经济研究(2016年24期)2017-01-10
电脑知识与技术(2016年24期)2016-11-14
中国科技术语(2012年5期)2012-03-20
全国新书目(2009年1期)2009-04-13
