
基于深度自编码器的移动通信基站异常度检测
2021-10-25 11:42马敏贾子寒王磊
移动通信 2021年5期
马敏,贾子寒,王磊
(1.中国移动通信集团设计院有限公司陕西分公司,陕西 西安 710065;2.中国移动通信集团设计院有限公司,北京 100080)
0 引言
目前,LTE 网络已经进入稳定发展阶段,形成了庞大的网络规模,要保证全网数以万计的基站正常、高效地运行,对网络运维提出了很高的要求[1],尤其是随着5G 网络的规模部署和商用,基站数量将远远大于4G 网络[2],网络运维面临更大的挑战。传统的移动网运维是以周期性巡检、故障派单等方式为主,存在着运维效率不高、运维资源投放时效性不足等问题,这种非预防性运维模式已完全不能满足当前网络运营的需要,运用人工智能和大数据等新技术,实现主动运维、快速运维和精准运维是网络运维发展的新趋势。基站异常检测是新型网络运维模式的一项重要内容,它的目标是要实时了解基站的健康状态,提前发现基站的隐性问题,有针对性地进行巡检,从而减少和避免基站退服类严重故障的发生,起到预防性网络维护的作用[3]。
目前基站异常检测的方法主要有网络指标阈值对比法[4]、基于机器学习的方法[5]和基于深度学习的方法[6]等,指标阈值法需要依赖人员经验,指标的统计分析也相当耗时耗力。采用有监督的机器学习方法,准确率较高,但需要大量的样本标注,这在大规模应用中很难做到。
本文提出一种基于深度自编码器模型进行基站异常度检测的方法,通过对基站故障告警、性能KPI、OMC运维指标等多维数据建立深度自编码器模型,挖掘基站正常运行时各类告警出现的频次规律、相关性能指标的波动规律,以此来进行当前基站异常度的检测。该方法具有准确性高、评测粒度细、容易实施等特点,为后续网络运维部门进行基站精准巡检以及进一步实现智能运维提供了可靠的数据支撑。
1 深度自编码器模型
自编码器(AE,Auto Encoder)是机器学习和深度学习的方法之一,采用无监督学习方式,即送入网络训练的只是数据本身,不需要对样本数据打标签。AE 的学习目标是重构原始输入,根据重构结果与原始输入之间的误差来训练网络,使得输入与输出值尽可能接近。最简单的AE 是一个三层的神经网络,包括输入层、隐藏层和输出层,深度自编码器是具有多个隐藏层结构的自编码器,它将多个基本的AE 堆叠形成深度学习神经网络,可用于输入数据的特征提取、高维数据的降维以及深度神经网络的预训练等。
自编码器分为传统的自编码器和改进的自编码器[7],如降噪自编码器(DAE,Denoising Auto-Encoder)、稀疏自编码器(SAE,Sparse Auto-Encoder)、变分自编码器(VAE,Variational Auto-Encoder)等,从数据规模、模型整体性能及模型健壮性等综合因素考虑,本文采用了稀疏降噪自编码器(SDAE,Sparse Denoising Auto-Encoder)模型。
1.1 基本的自编码器
基本的AE[8]网络结构如图1 所示,从输入层到隐藏层是编码过程,从隐藏层到输出层是解码过程,层与层之间相互全连接。
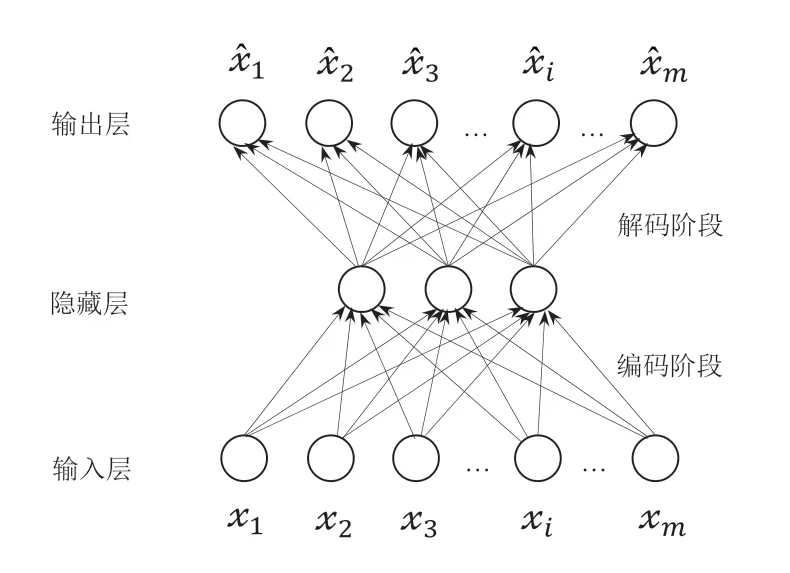
图1 基本的自编码器网络结构
假设对于样本x={x1,x2,x3,…,xm},重构输出为,则AE 的编码和解码过程分别为式(1)和式(2)。

其中W为输入层到隐藏层的权值矩阵,W′为隐藏层到输出层的权值矩阵,通常取W′=WT,即W的转置;b和b′ 分别为隐藏层和输出层神经元的偏置向量;f(x) 和g(h) 分别表示编码和解码的激活函数,一般使用相同的Sigmoid 函数或relu 函数等。
1.2 稀疏降噪自编码器
降噪自编码器(DAE)模型是通过对原始输入数据人为加入一些噪声,然后将这个加了噪声的数据送入AE,使其尽量重构出与干净输入相同的输出。DAE 使重构输出对输入中的噪声具有一定的鲁棒性,降低网络对输入样本的敏感性。
稀疏自编码器(SAE)模型是给AE 的隐藏层神经元增加一些稀疏性约束,使得隐藏层大部分神经元处于抑制的状态,只有少数被激活,目的是在保证模型重建精度的基础上,使隐藏层更加稀疏简明地表示,提高模型的性能。
稀疏降噪自编码器(SDAE)模型是融合了DAE 和SAE 两种模型,以SAE 为基本架构,输入数据中加入干扰噪声,模型重构输出的损失函数是在AE 损失函数的基础上增加了稀疏性约束,使得隐藏神经元的平均激活值保持在很小的范围内。式(4)给出了SDAE 的损失函数[8],其中,为稀疏性惩罚因子,β是控制稀疏性惩罚因子的权重,可取0~1 之间的任意值。

稀疏性惩罚因子如式(5) 所示。
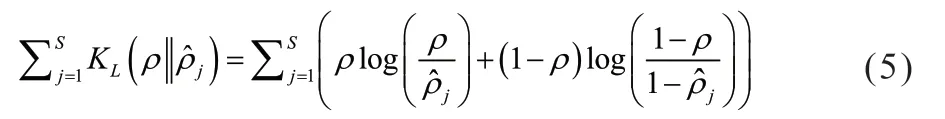
式(5) 中,S为隐藏层中隐藏神经元的个数,j为隐藏层中的神经元,ρ是稀疏参数,通常是一个接近于0 的较小的值,代表所有训练样本在j上的平均激活值,aj为j上的激活值。稀疏性惩罚因子采用散度来衡量ρ与之间的差别,在网络训练过程中,若与ρ明显不同时就会进行惩罚,达到对隐藏层神经元抑制的效果。
2 基于深度自编码器的基站异常度检测方法
2.1 基于深度自编码器的基站异常度检测方法总体流程
基于深度自编码器进行基站异常度检测的总体流程如图2 所示,包括特征参量选取、数据准备、建模以及模型结果应用等几部分。
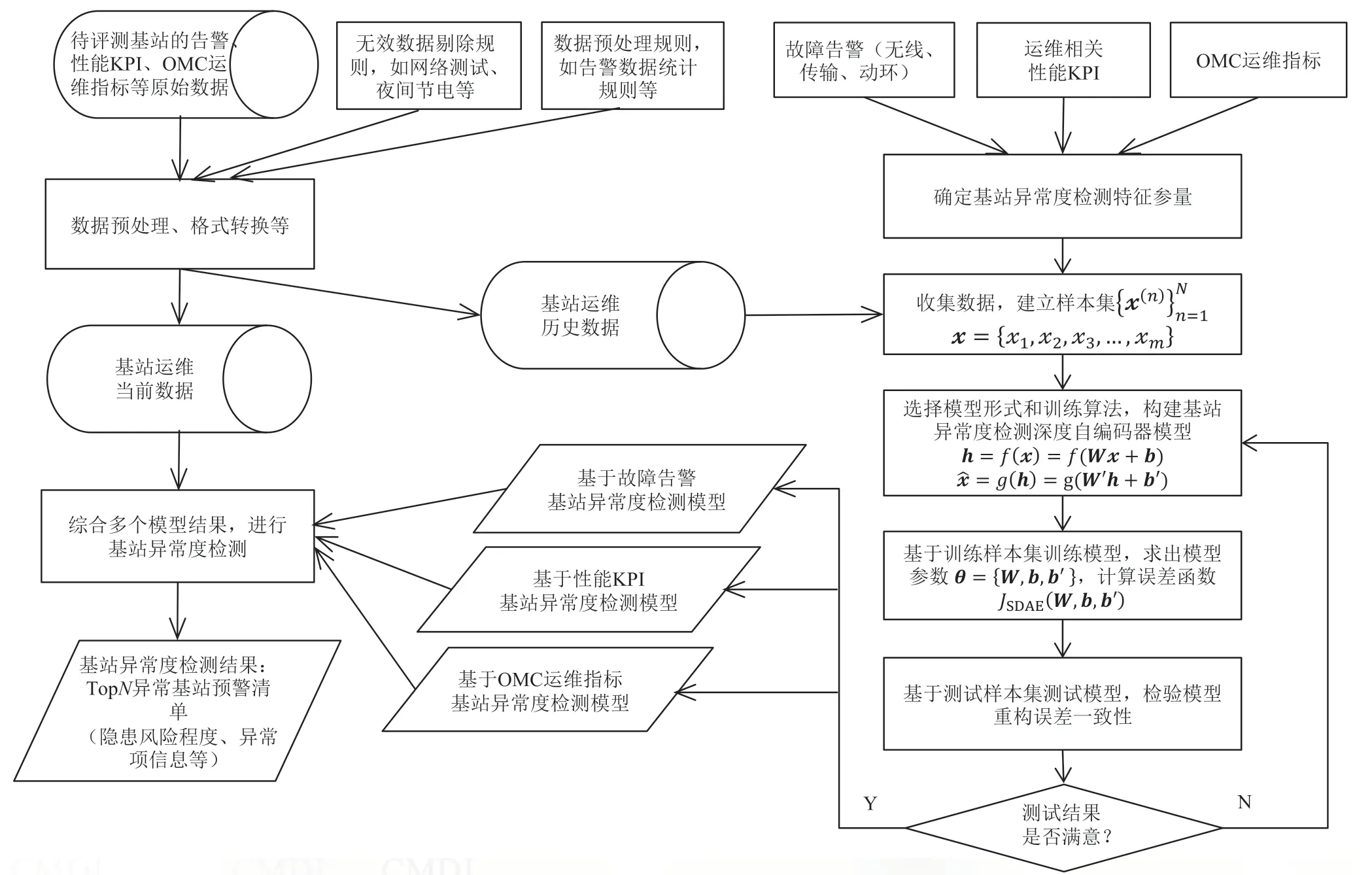
图2 基于深度自编码器的基站异常度检测方法总体流程
特征参量选取是要确定能够反映基站异常程度特性的参数,由于基站退服类重要告警的发生常伴有次要告警、性能指标波动、动环数据波动等,因此选择故障告警频次、与运维相关的性能KPI 以及OMC 运维指标作为基站异常度检测模型的特征参量。
数据准备主要完成以上特征参量数据的采集、预处理(如剔除无效告警数据、按一定粒度进行各告警频次统计等),以及数据格式转换、建立基站异常度检测运维数据库等,抽取该数据库中一定数量的历史数据就得到模型输入的样本集。
建模部分是运用深度自编码器建模方法建立基站异常度检测模型,具体建模过程见第2.2 节。由于故障告警数据是基于基站级的,性能KPI 数据是基于小区级的,OMC 运维指标是基于板卡级的,考虑到数据粒度不同,因此首先基于以上三种特征参量数据分别建立模型,最后再综合三个模型的输出结果(如对模型结果加权),对基站进行更全面、更精细化的异常度评测。
模型结果应用是对模型输出结果进行分析和后评估,如绘制所有待评测基站在评测时间段内异常情况的变化趋势图、计算各基站异常程度的排序以及列出TopN异常基站预警清单等(包括基站的隐患风险程度、异常项的具体信息等),提供给网络运维部门作为智能巡检的数据依据。
2.2 基于稀疏降噪自编码器的基站异常度检测建模
(1)建模过程
基于深度自编码器的基站异常度检测建模过程实质上就是对输入的特征参量重构的过程,下面以基站故障告警特征参量为例详细说明。
图3 给出了基于稀疏降噪自编码器的基站故障告警序列重构过程[9]。
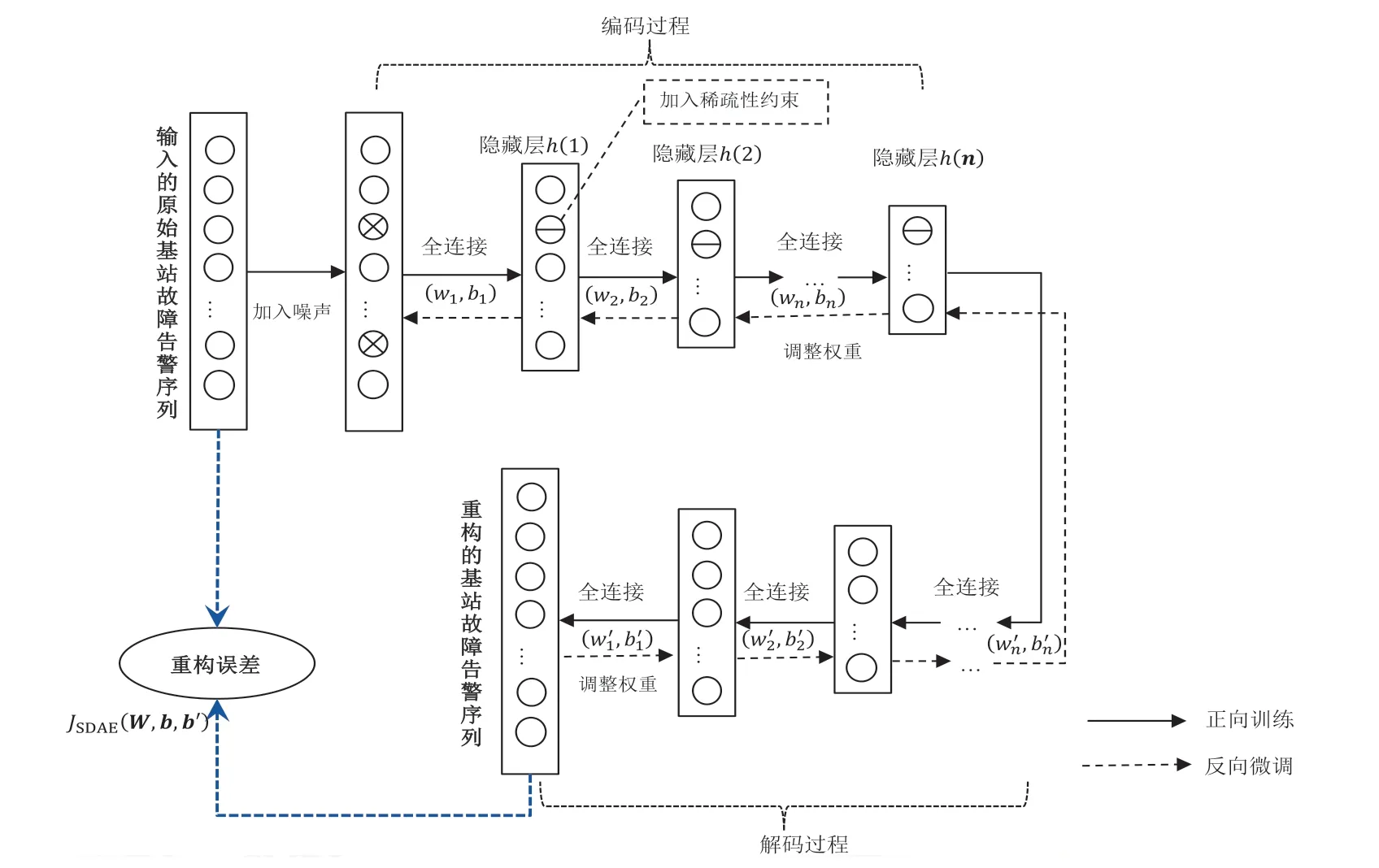
图3 基于稀疏降噪自编码器的基站故障告警重构过程
具体步骤如下:
1)对预处理后的基站原始故障告警序列{x}进行加噪处理,得到有随机噪声的模型输入{x'}。
2)对各隐藏层的神经元加入稀疏性约束,将输入{x'}作为第一层隐藏层输入,单层训练得到第一层隐藏层的输出,将该输出作为第二层隐藏层输入,依次类推,由下至上逐层训练,直到完成给定数量的隐藏层的训练,得到初始的网络模型参数。
3)计算模型的误差函数JSDAE(W,b,b´)。
4)迭代训练网络,利用后向传播算法和梯度下降算法[10]等,再由上至下逐层进行微调,最终得到最优化的网络模型参数。
5)当总体重构误差达到最小时,得到重构的基站故障告警序列。
(2)模型输入、输出及样本数据获取
模型输入,就是按照一定的格式要求输入到基站异常度检测模型的特征参量数据,以下分别给出基于故障告警、性能KPI、OMC 运维指标的三个模型的输入数据说明。
1)故障告警:包含无线、传输、动环的全量告警,模型输入为在一定时间粒度(如每天)内各个告警的频次,表1 给出了故障告警数据输入样例。

表1 故障告警数据输入样例
2)性能KPI:依照专家经验,筛选出与运维相关的性能KPI,模型输入为各性能KPI 值,表2 给出了性能KPI 数据输入样例。

表2 性能KPI数据输入样例
3)OMC 运维指标:主要有驻波比、设备温度、光功率、基站输入电压等,模型输入为各OMC 运维指标值,表3 给出了OMC 运维数据输入样例。

表3 OMC运维数据输入样例
模型输出,即通过基站异常度检测模型得到的输入数据集的重构误差,为欧氏距离,将其作为基站异常度的检测量。
样本数据获取,就是通过一定的方式得到模型训练的样本集,分别通过移动网运行的集中故障平台、网优大数据平台以及综合网管后台指令方式等,采集相当数量(如6 个月以上)的特征参量数据,剔除无效数据,按照以上模型输入要求完成数据处理,最后得到近似基站正常态的样本集。
3 算例实现及应用效果
3.1 算例实现
本文基于Python 的Keras 深度学习库搭建深度自编码器模型,训练数据集和测试数据集选取某省移动公司的基站运维数据,包括历史6 个月的无线告警、传输告警和动环告警等,下面以基于故障告警的基站异常度检测模型为例说明算例实现。
(1)数据预处理
1)在告警数据中剔除退服类告警(如小区不可用告警、链路异常告警等);不影响业务的告警类型(如证书失效告警、门禁告警等);因工程施工、测试、网络割接等导致的异常告警;剔除工程预约、夜间节电、载波调度等白名单基站的告警。
2)统计每天各个基站发生各类告警的频次,根据时间、基站名称、基站所属机房关联各个维度告警数据(包括无线告警141 类、传输告警30 类、动环告警38 类),构建训练样本,共计86 912 条,如表4 所示。

表4 训练样本
(2)参数选择与优化
将以上209 维告警样本数据作为SDAE 模型的输入,按照上述的建模过程进行模型构建和训练,选择的SDAE网络参数见表5。
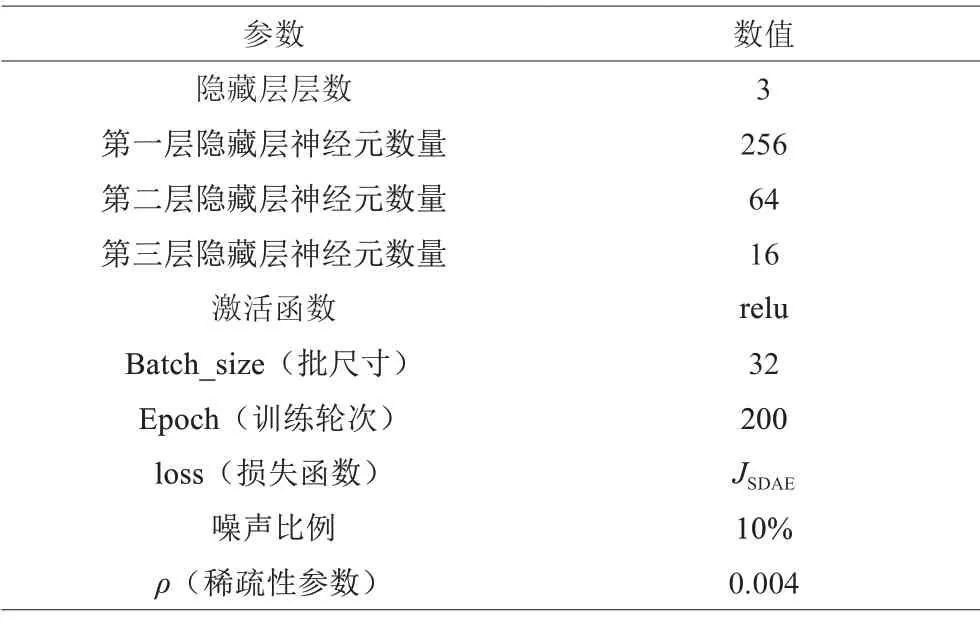
表5 SDAE网络参数
经过实验训练对比,设置SDAE 模型隐藏层数为3 层,隐藏层神经元个数设置为256、64 和16,稀疏性参数ρ设置为0.004,加入10% 的高斯噪声比。
将训练数据输入SDAE 模型,经过200 次迭代训练,误差函数JSDAE(W,b,b´) 在0.000 1 左右趋于平缓,如图4所示,表明该降维序列能够很好的体现原始序列的特征,有效重构原始数据。

图4 告警频次序列的重构误差
实验采用5 折交叉验证方法,即将样本分成5 部分,每次取4 部分做训练,剩余1 部分做测试,共需进行5 次验证,取5 次训练后测试集重构误差的平均值作为最终的重构误差。
3.2 应用试点及效果分析
目前在运维工作中,巡检资源投放缺乏指导手段,传统的巡检工作为按计划轮巡式安排巡检任务,不仅造成巡检资源浪费,而且巡检效果也不明显。基于此问题,某省移动公司采用本文提出的基站异常度检测模型进行了LTE 网络智能巡检应用试点,初步取得了比较好的效果。
智能巡检应用试点以周粒度方式进行,首先按照以上第3.1 节异常检测模型算法自动计算出各待测基站的异常度,而后考虑到告警重要程度和基站告警发生时间对基站当周异常程度的影响,在模型结果的基础上,增加了告警重要程度和告警发生时间的加权项:第一步根据告警级别以及告警是否影响业务配置权重;第二步根据告警发生时间与巡检时间临近的顺序依次按照从高到低权重进行加权。综合以上基站异常度评测结果,排出基站巡检优先级,同时,针对高异常的告警维度生成巡检重点关注项,并对一周内多天高异常度基站给出多天异常的预警提示,最终输出TopN基站智能巡检清单,如表6 所示,其中N可根据实际基站规模以及巡检资源配置情况灵活选取。
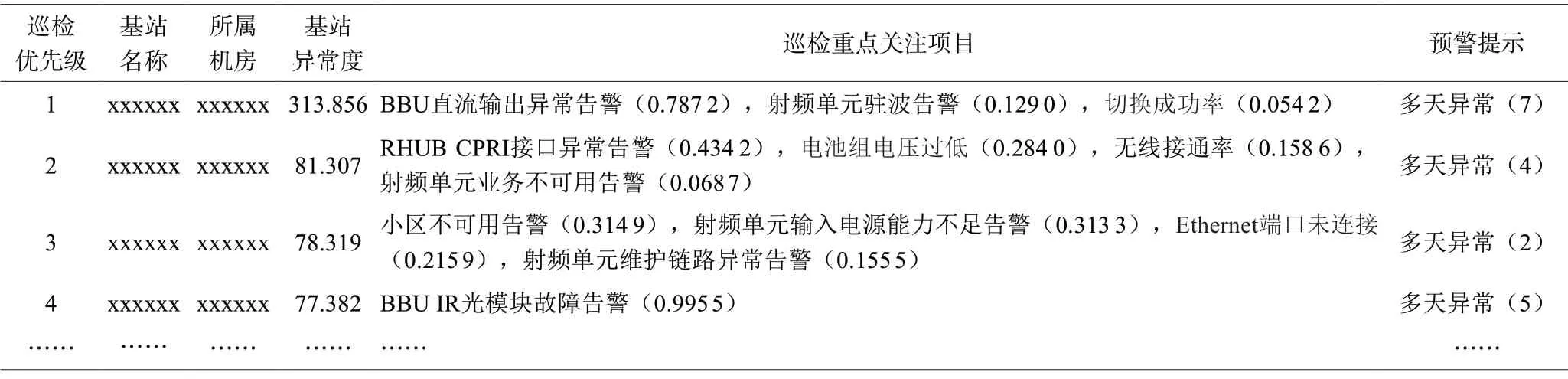
表6 基站智能巡检清单
本试点进行了8 批次(每周为一批次)、1 098 个基站的巡检,经过后评估,巡检过基站的告警量平均下降50.5%、故障工单量平均下降37.9%,具体每批次巡检后告警量、工单量下降情况如图5 所示。

图5 智能巡检后评估初步结果
4 结束语
智能运维是未来网络运维的发展方向,人工智能在移动网络运维领域的深度应用必将带来其运维模式的变革,推动网络运维的新发展。本文研究了无监督方式的深度学习在基站异常检测中的应用,提出了一种基于稀疏降噪自编码器的基站异常度检测方法,该方法可以应用于LTE 以及5G 网络中。经过实际的应用试点,验证了该模型能够有效挖掘基站隐患,为提高运维巡检的有效性、降低运维成本提供了有力的支持。进一步的工作是对检测出的基站隐患问题进行根因定位,并结合专家经验给出解决措施,形成一套行之有效的基站隐患预判方案,应用到网络运维的实际工作中。
猜你喜欢
中国交通信息化(2019年5期)2019-08-30
成都信息工程大学学报(2018年3期)2018-08-29
探索科学(2017年4期)2017-05-04
电子设计工程(2017年20期)2017-02-10
中国交通信息化(2016年8期)2016-06-06
现代工业经济和信息化(2016年8期)2016-05-17
电子器件(2015年5期)2015-12-29
发明与创新(2015年29期)2015-02-27
电测与仪表(2014年13期)2014-04-04
