
基于学习者兴趣挖掘的个性化课程推荐方法
2021-10-27 09:06李全龙
郑州大学学报(理学版) 2021年4期
郭 阳,李全龙,李 骐
(1.哈尔滨工业大学 计算机科学与技术学院 黑龙江 哈尔滨 150001;2.教育部考试中心 北京 100084)
0 引言
近年来,随着互联网+教育的融合,各种在线教育平台迅速发展。这些平台凭借其优质而海量的资源,积累了众多用户。在线教育已成为学习者知识获取、技能拓展及学历教育等重要的教育模式和技术途径。如何在海量的课程资源中为学习者提供个性化的内容是一个值得研究的问题。
在线教育平台中,小部分学习者是为了完成学校规定的学分任务,有更多的学习者是基于兴趣驱动学习的。所以,对在线教育平台学习者的兴趣进行挖掘,有助于更好理解学习者的需求,帮助平台为学习者提供个性化的教学服务。
随着在线教育应用的不断增加,在线教育平台已经成为多个学习者共同创造、共享和获取知识的重要平台和空间。在线教育平台中涉及许多不同的学习者,每个人都有不同的兴趣爱好,并且是动态变化的。为了标注和管理学习者的兴趣,在线教育平台通常为学习者提供了通过标注主题来自定义兴趣的方法。但是学习者很难详细描述自己的兴趣,而且不一定会随着兴趣的变化而更新兴趣标签。此外,还有许多学习者并不积极标记他们的兴趣。因此,如何在开放的学习环境中自动发现学习者的学习兴趣是一个值得研究的问题。
在线教育平台吸引了百万的学习者,积累了海量的学习者行为数据,根据学习者行为数据,可以挖掘出学习者的学习兴趣,进一步地,可以为学习者提供个性化的课程推荐。传统的兴趣挖掘方法,要么以学习者感兴趣的课程作为兴趣点,要么以讨论区的主题作为兴趣点。本文提出基于学习者感兴趣的知识主题、感兴趣的课程、感兴趣的领域的多维兴趣模型的表示方法。此外,不仅学习者感兴趣的点值得关注,其感兴趣的程度也具有参考价值。根据学习者行为数据,本文对学习者的兴趣进行了刻画,并根据学习者之间兴趣的相似性,采用协同过滤的思想,使用KNN算法对学习者进行个性化课程推荐。在现实数据上进行的实验表明本文的兴趣模型对课程推荐有明显的帮助。
1 相关工作
1.1 学习者兴趣挖掘
学习者兴趣在基于网络的学习环境中发挥着重要作用,并与学习结果呈正相关。在开放的学习环境中,学习者生成的内容及其与在线资源交互的大量数据提供了自动检测学习者兴趣的机会。同时,利用这些数据,开放的学习环境可以通过自适应地发现学习者的需求,并自动推荐相关资源,从而改善他们的教育服务[1]。
主流的发现学习者兴趣的方法有文本挖掘、聚类分析等。Wu等基于文本挖掘方法构建了一个学习者兴趣模型来解决学习者兴趣发现问题,将学习兴趣分为知识兴趣(基于学习者产出内容)和收集兴趣(基于其他学习资源),并在开放学习环境中自动生成了学习者的兴趣[1]。Liu等基于学习者讨论区数据,使用潜在狄利克雷分配方法来挖掘讨论的关键话题。该方式是一个数学模型,可以自动对大量文本进行分类并按主题进行标记[2]。Dun等提出了一种在社区问答系统中,基于命名实体识别、同义词扩展和同义词替换等技术,将学习者关心的问题作为主题分布来揭示学习者兴趣的方法[3]。
总的来说,在学习者兴趣挖掘方向上,已经有了许多工作。主流的方法是对用户的行为数据进行分析挖掘,但是并没有对学习者的兴趣的感兴趣程度进行标注。而学习者的兴趣意图是动态发展的,且学习者对于不同的知识主题有不同的感兴趣程度。此外,从学习者行为数据中发现的是学习者直接兴趣,还可以考虑基于学习者关系网络发现学习者的潜在兴趣,从而对学习者进行个性化课程推荐。
1.2 个性化课程推荐
在线教育平台的个性化课程推荐也是一个热点研究问题。当前的课程推荐主要以协同过滤为主。具体来说,包括以学习者为中心的协同过滤、以课程为中心的系统过滤及混合方式[4]。
李国成[5]提出基于学习者的互动行为等建立学习者之间的信任关系,从而对学习者进行个性化课程推荐。Obeidat等基于传统的数据挖掘方法[6],采用协同过滤方法和关联规则分析对比的方式,为学习者进行课程推荐,其实验结果表明,对学习者进行分组聚类,对推荐效果有明显改善。Huang等使用强化学习方法和马尔科夫决策过程[7],对学习者进行习题推荐,推荐时综合考虑习题难度的平滑、复习和预习及学习者的参与程度。Liu提出使用基于神经网络的方法[8],对学习者的知识水平进行追踪,从而为学习者提供个性化学习路径推荐。Zhang等提出的MCRS 基于分布式关联规则挖掘算法[9],使推荐信息传递得更加及时,并提高了用户的课程检索效率。Chen等提出一个基于学习者现有知识和学习材料的知识推荐算法[10],将推荐过程建模成一个马尔科夫决策问题。
综上,在学习者个性化课程推荐方面已有许多工作。学习者兴趣作为个性化课程推荐中的一个重要特征,已有的研究多以学习者对课程评分进行刻画,较少有对学习者兴趣特征的深入分析并将其用于个性化推荐。此外,协同过滤算法是当前流行的一种推荐算法,但大部分是根据用户对项目的评分数据进行聚类,没有对用户或项目之间的隐含信息进行充分利用[11]。
2 学习者兴趣模型
2.1 兴趣模型表示
本文将学习者的兴趣特征分成三个层级表示:知识主题、课程、知识领域。它们之间的关系如图1所示。

图1 兴趣分层结构示意图Figure 1 Schematic diagram of interest hierarchical structure
系统中的学习者集合为U={u1,u2,…,un},系统中的课程集合为C={c1,c2,…,cm},系统中的知识主题集合为T={t1,t2,…,tl},系统中的知识领域集合为D={d1,d2,…,dp}。
学习者ui的知识主题兴趣向量表示为
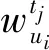


2.2 兴趣模型抽取
前文提到,为了获取学习者感兴趣的领域向量,需要对学习者的知识主题兴趣向量及学习者课程兴趣向量进行聚合,因此需要获取知识主题所属领域信息和课程所属领域信息。课程所属领域信息一般在课程的描述信息及元数据信息中提取,而知识主题所属领域信息则需要通过一定的方法获取。
这部分主要解决两个问题:系统知识主题抽取及对应领域生成;学习者兴趣向量生成。为了从系统中抽取出合适的知识主题,从而进一步刻画学习者的兴趣,本文使用了自然语言处理工具分词加词频统计的方法。具体的过程如图2。
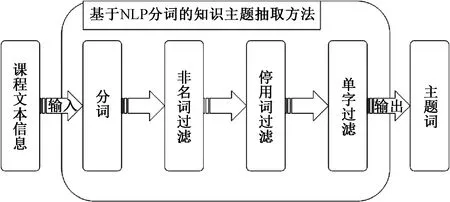
图2 知识主题抽取流程图Figure 2 Knowledge topic extraction flowchart
为了判断知识主题词所属领域,本文使用了类似于TF-IDF统计的方法。TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
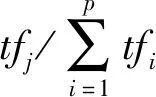
学习者兴趣模型包括三个兴趣向量:知识主题兴趣向量、课程兴趣向量及知识领域兴趣向量。在2.1节兴趣模型表示中,给出了计算公式。具体来说,学习者知识主题兴趣向量的计算根据学习者的搜索行为分析和讨论区数据分析;学习者的课程兴趣向量的计算根据学习者课程学习行为数据分析;学习者的知识领域兴趣向量则根据知识主题兴趣向量和课程兴趣向量进行聚合。
算法1学习者知识主题兴趣向量生成算法
输入:学习者集合V,搜索日志Search_Log
输出:学习者兴趣主题集合列表
1 for each v in V do
2 topicMap← {}
3 find wordlist in Search_Log
4 for each word in wordlist do
5 topics=segment(word)
6 for each topic in topics do
7 if (topic in topicMap)topic.count++
8 else add topic to topicMap
9 count each topic.weight
10 output v.topicMap
11 return
3 基于兴趣关系网络的课程推荐算法
本文将学习者的兴趣表示成知识主题兴趣向量、课程兴趣向量和知识领域兴趣向量。基于这三个向量,可以计算学习者之间的兴趣相似性,进一步构建学习者兴趣关系网络。具体过程如图3所示。

图3 基于兴趣模型的个性化课程推荐Figure 3 Personalized course recommendation based on learner interest model
根据余弦相似性的定义计算学习者兴趣相似性,学习者知识主题兴趣相似性的计算公式为t_sim(ui,uj)=tui·tuj/|tui||tuj|。学习者课程兴趣相似性的计算公式为c_sim(ui,uj)=cui·cuj/|cui||cuj|。学习者知识领域兴趣相似性的计算公式为d_sim(ui,uj)=dui·duj/|dui||duj|。
基于相似性可以构建学习者基于兴趣的信任关系网络。学习者的信任关系网络是一个图G(V,E),V表示全体学习者的集合,E表示学习者之间的关系组成的边。学习者之间兴趣相似性也可以组成边。如果两个学习者u1和u2之间的兴趣相似性大于一个给定的阈值,则可以在这两个学习者之间添加一条边,边的权值为学习者之间的相似性。具体见算法2。
基于构建的信任关系网络,可以对学习者进行课程推荐。类似协同过滤的思想,推荐过程为:首先获取当前学习者的距离最近的k个邻居,包括直接邻居和间接邻居,即当前学习者在给定的跳数内能够到达的学习者,本文实验中,跳数设为2;然后统计邻居所选择的课程,并按频率进行排序,即出现次数越多的课程,排在越前面;最后过滤掉学习者已选择的课程,剩下的课程根据语义与学习者的兴趣匹配的分数高低推荐给学习者。具体见算法3。
算法2兴趣关系网络构建算法
输入:学习者集合V,学习者兴趣向量D,T,C
输出:图G(V,E),V为结点,E为学习者兴趣相似性的边
1 E←∅
2 for each v1in V do
2 for each v2in V do
3 sim=getSimilarity(v1,v2)
4 if(sim>threshold)
5 E←E∪{〈v1,v2〉}
6 return
算法3基于兴趣相似性的个性化课程推荐算法
输入:学习者u1,学习者兴趣关系网络图G(V,E)
输出:为学习者u1生成的课程推荐列表Rec_Courses
1 Rec_Courses←∅
2 for each u in findNeighbors(ui,G)do
3 Rec_Courses←Rec_Courses∪u.courses
4 for each c in Rec_Courses do
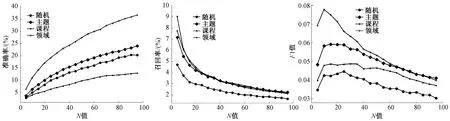
5 if(getScore(c,u1) 6 E←E-{c} 7 return Rec_Courses 数据来自学堂在线提供的学习者行为数据,其中包含了370万学习者。本文对系统提供的8 524门课程描述信息进行了处理,对包括课程名称、授课教师、课程介绍等几个字段进行了分词,并对主题词出现的频次及在各个领域出现的频次进行了统计。通过这种方法,从系统给的课程文件中抽取出了18 042个主题词,并获取每个主题词对应的领域。 选取数据集中5 000名学习者进行了实验,采用随机、基于知识主题向量、基于课程向量、基于知识领域向量的推荐方法进行对比。评价指标包括:准确率、召回率和F1值。准确率指推荐的课程列表中,用户感兴趣的概率。召回率指用户感兴趣的课程出现在列表中的概率。F1值是准确率和召回率的调和平均数。 实验结果如图4,分别为对比实验的准确率、召回率和F1值随N值的变化曲线,其中N值指的是最近邻算法KNN中邻居的个数。从图中可以看到,所有对比实验的准确率都随着N值的升高而升高,召回率都随着N值的升高而下降,F1值随着N值的升高,都经历了一个先升后降的过程。这是符合准确率、召回率及F1值的一般规律的。 图4 实验结果Figure 4 Experimental result 此外,可以看到,当基于学习者的知识领域兴趣向量进行协同过滤推荐时,相应的评价指标的值最好。这是比较符合预期的,因为学习者的知识领域兴趣综合考虑了学习者的知识主题兴趣和学习者的课程兴趣,并对学习者的知识领域有一定的预测性(如选择《编译原理》课程和选择《计算机网络》课程的学习者同属于计算机领域),故而基于知识领域进行推荐可以比单纯的基于课程推荐和基于知识主题的推荐效果更好。 本文提出了一种基于学习者兴趣挖掘的个性化课程推荐算法。本文将学习者的兴趣模型表示成结合知识主题、课程、领域信息的多层兴趣模型,并基于学习者的行为数据,对学习者的兴趣模型进行了刻画。在学习者的兴趣模型基础上,对学习者进行了个性化的课程推荐。在数据集上的实验结果证明了本文方法的有效性。4 实验
4.1 系统知识主题抽取及对应领域生成
4.2 课程推荐
5 结束语
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
现代职业教育·职业培训(2019年6期)2019-10-09
计算机技术与发展(2019年1期)2019-01-19
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
