
一种基于页面赋权的网页内容提取方法
2021-10-27 00:46余杨奎李婉茹程振林
通化师范学院学报 2021年10期
余杨奎,王 旅,李婉茹,程振林,刘 洁
WEB内容提取技术是针对WEB网站目标内容进行结构、语法、语义、规则、特征等分析的基础上实现对信息的自动提取.WEB内容的提取根据不同的划分标准可分为如下几类:根据所提取的WEB内容可划分为静态内容的提取、动态内容的提取;根据WEB内容提取的自动化程度又可以划分为人工提取、机器提取;根据提取技术的不同,可以划分为基于传统文本信息的技术、基于树形结构的技术、基于模板的技术、基于视觉处理的技术.其中基于传统文本信息的WEB内容提取技术是以自然语言处理为基础,通过WEB内容的句型、语法、语义等方面的分析,按照一定规则实现对内容信息的提取;由于传统文本信息提取技术的约束性较强,规则较为单一,使得此类提取WEB页面内容的效率不高,限制较多,并不能有效支持具有片段性特点的WEB内容标签.
基于树形结构的WEB内容提取技术,是从WEB页面结构视角展开的对内容提取技术,它突破了传统提取技术只针对WEB页面文本信息的束缚,转而对WEB页面的结构信息进行分析并获得内容.在该类提取技术中,充分利用了WEB页面具有的HTML标签结构,将HTML源代码看成一种典型的树结构,具体如图1所示.
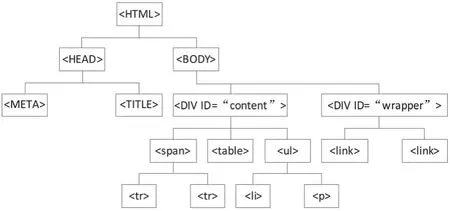
图1 WEB页面的树形结构
基于模板的WEB内容提取技术,是在归纳总结出WEB内容提取规则的基础上展开的,此类技术的实现一般分为两个步骤,第一步为训练样本并产生规则;第二步为利用规则进行内容提取.首先通过获得大量的WEB内容样本,对其展开训练,产生WEB内容提取规则;其次利用这些规则在目标WEB页面集中实现内容提取,并将提取内容存储到相应的数据库中.该技术的基本提取流程如图2所示.基于模板的WEB内容提取技术,可专门用于对具有近似特征的WEB页面内容进行提取,具有很高的提取精确度;但该方法的普遍适应性较差.
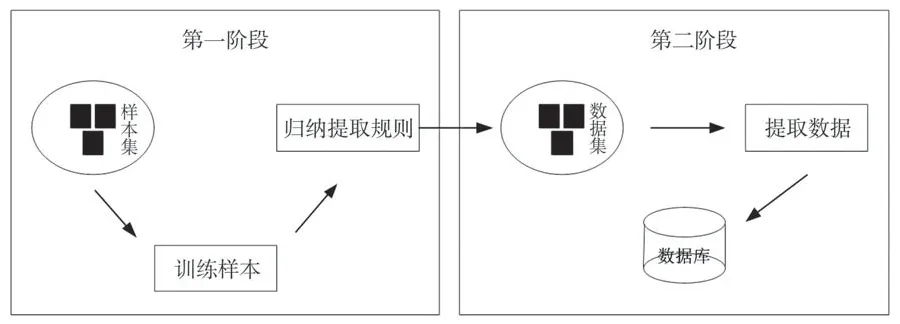
图2 基于模板的提取技术图示
1 WEB内容提取技术的相关研究
对于WEB内容的提取技术,国内外很多学者从统计学领域、视觉特征领域,以及WEB模板技术领域等方面进行了深入的研究.常见的WEB内容提取方法包含三种:基于模板[1]、基于机器学习[2]和基于页面分块的网页内容提取方法[3],第一类方法基于模板方法使用模板来匹配网页中的内容,然后进行提取;第二类方法基于机器学习为基础的WEB内容提取技术,主要是通过已经提取的特征集实施训练,构建对应模型,并使用构建的模型进行WEB内容提取;第三类方法在网页内容提取领域是比较主流的方法,目前有两种较为常用的页面分块算法:基于视觉特征的页面分块方法(VIPS)[4−5]和基于文本对象模型(DOM)的页面分块方法[6].杨柳青等提出并实现了一种基于布局相似性的网页正文提取方法,通过比对来自同一网站同一专题的网页DOM树中节点数据信息的相似性实现正文提取[7].潘心宇等通过分析正文信息DOM树节点路径的规律提出了相应的正文信息提取方法.多名学者针对基于WEB内容信息的抽取方法进行了深入研究,主要借助了树结构匹配的思想,认为在WEB页面的树结构中,匹配的节点越多,表明两个WEB页面结构的树相似度就越高;在此基础上,进一步提出了WEB树结构近似度算法,为WEB内容的提取提供了基础[8−10].王宇龙等依据网页头部标题元素与网页内容上的联系提取网页标题;提取网页正文区域的网页结构和内容上的多个特征分类网页DOM节点,定义节点的扩展、整合规则获得正文候选块,引入密度值和影响因子从各候选块中甄别正文块;利用发布时间与标题、正文之间的位置关系,通过正则表达式实现发布时间的提取[11].李桐宇对基于文本对象模型的WEB内容提取技术进行了研究,借助DOM网页分块算法,实现了对各种WEB页面内容的识别与提取,并有效检测WEB页面内容的噪声,具有较大的通用性;研究结果表明,在召回率近似的条件下,利用DOM网页分块算法具有更高的WEB内容提取效率[12].吴克介对基于模板匹配技术的WEB内容提取方法进行了研究,指出使用模板进行WEB页面信息匹配是在规则集合的基础上展开的,典型的如正则表达式集合,在绝大多数情况下,相同集合的规则都是在近似WEB页面树结构基础上产生的,从而提高WEB内容提取过程中的效率和正确率[13].陈婷婷等针对内容分析算法在正文抽取中易丢失部分正文字段、锚文本、结构数据(表格、列表)的缺点,提出一种改进的网页正文提取算法.在搜集大量网页,总结网页布局及正文特征规律基础上,就正文块生成和剪枝两个方面对Readablility算法进行改进[14].王海涌等提出一种基于结构相似网页聚类的网页正文提取算法.该方法在正文提取时充分考虑网页采集来源的不确定性,以及网页结构的复杂性对正文提取准确度的干扰,引入网页结构权重的概念,并将网页块相似度计算转化为网页DOM树相似度计算,对聚类之后结果簇中的所有网页内容相似部分进行去除,剩余部分则是网页正文信息[15].张龙龙提出了一种基于网站结构特征和内容特征相结合的网站特征抽取算法,并结合BM25算法和余弦距离实现相关度的计算,同时综合考虑网站的特征数量和更新频度等评价网站的重要度[16−17].
尽管国内外学者对于WEB内容的提取技术进行了深入而广泛的研究,所得到的成果也是非常丰富的,但是,由于WEB内容本身具有的复杂性,使得各种研究技术和成果总是具有一定的缺陷.在新的互联网时代,大数据的广泛应用更加推动了对WEB内容获取的需求,该领域的研究仍然需要更加深入地展开.基于此,本文在对前人研究成果总结的基础上,设计一种可针对异构WEB网站内容进行高效、动态获取的算法.
2 基于页面赋权的WEB内容提取算法的实现过程
基于页面赋权的网页内容提取方法,是在互联网海量WEB信息范围内进行目标WEB页面的搜索,并剔除掉不相关的WEB页面内容,准确地提取获取到的WEB页面内容.为实现WEB内容提取算法目标,需要对算法进行必要的初始化配置,配置目的是强化网络爬虫的搜索效率,并为WEB内容的自动提取解析更精确的数据路径.此外,初始化配置也可以让本算法更加具有广泛性和通用性.表1中为初始化配置信息.

表1 初始化信息
根据上述初始化的信息进行初始化配置,即针对目标链接地址、定位关键词、WEB内容提取数据等信息,可以发现初始化配置较为简单,特别是定位的关键词往往能够通过HTML标签直接获取.本文设计的算法流程如图3所示.
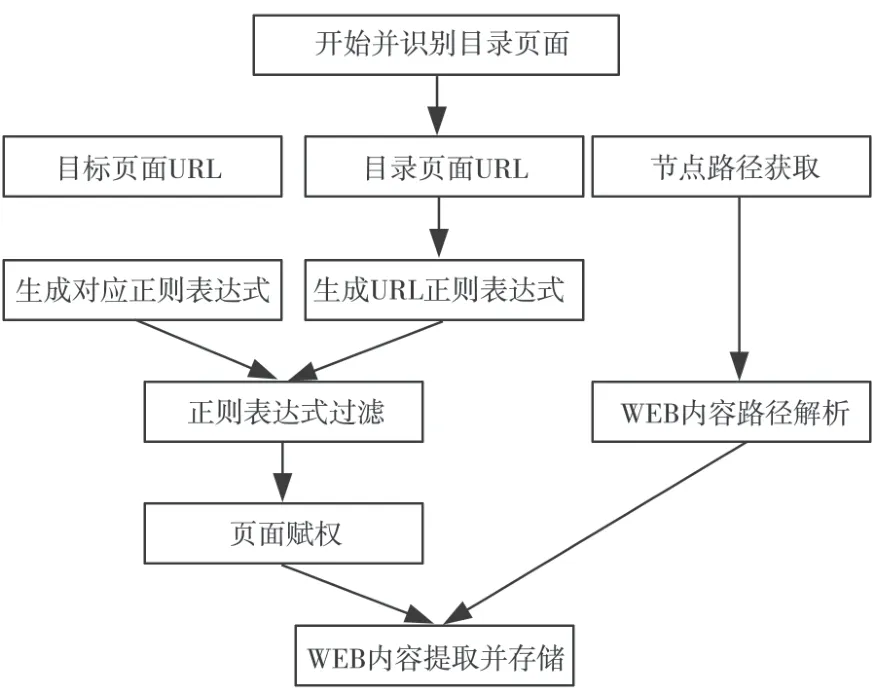
图3 本文算法流程
设计的算法按照两个步骤划分,初始化配置为第一步骤,该步骤成为后续URL正则表达式产生、筛选和解析模板构建的基础.在这一阶段中,通过网络获取目标内容的相关URL,并针对这些WEB页面进行页面URL、目录URL的识别,构建自身的正则表达式,并对正则表达式实施多重筛选.存在的正则表达式分为两类,一类为页面URL正则表达式,一类为目录URL正则表达式,通过这两类不同的正则表达式,进一步获取到目标WEB页面的HTML标签节点链接,再按照初始化配置的内容,获得WEB内容所需要的正确路径,最后构建WEB内容提取模板.
在第二个步骤中,针对WEB页面的赋权操作是该阶段的首要步骤,根据第一阶段的初始化配置内容和相关路径,确立WEB页面的搜索赋权,从而建立与定位关键词相匹配的精确WEB页面定位,并通过筛选技术,完成对WEB内容的自动提取,这是本文所提算法关键的提取信息技术环节.
本文提出的算法能够完成针对不同网站精确、高效的WEB内容获取.在本算法的实现过程中需要解决两大关键问题,其一是精确的预先搜索策略如何实现;其二是在路径模板基础上如何实现WEB内容的自动提取.
2.1 WEB内容提取前置算法:带权搜索
从前文的算法设计中可以发现,WEB内容提取需要以页面搜索为基础,搜索能力的高低在很大程度上决定了WEB内容获取的时间效率,如果搜索结果中包括大量的和目标内容无关的主题信息,显然会降低WEB内容提取的精确度,而且还会消耗大量的提取时间和空间.为此,本文提出了带权的搜索算法,该算法作为WEB内容提取的前置算法,是在传统的广度优先搜索策略基础上实现的.在WEB页面中,信息量大且类型复杂,一些信息所表现出来的数据类型和结构并不能与正则表达式很好地匹配,从而让一部分目标WEB页面被遗漏.
为此,本次算法设计过程中,将正则表达式与广度优先搜索策略进行结合,使用正则表达式完成筛选,并在广度优先搜索策略基础上得到WEB页面的对应URL.具体而言,本算法利用正则表达式建立针对WEB页面URL与链接的规则筛选工具,从而有效筛选掉一些与搜索目标无关的URL;此外,利用规则筛选工具还可以完成对WEB页面权重的计算,促进实现优先搜索.利用正则表达式实现WEB页面URL的筛选,主要完成两项工作,其一为识别URL与筛选工具中正则表达式的匹配程度,对于匹配完好的URL,则标识为爬虫选取的对象;否则,则要筛选掉那些不匹配的URL.其二在具体的带权搜索过程中,需要围绕参数计算页面权重,并对搜索的WEB页面进行URL检测,确定是否包含目标URL.
本算法通过初始化配置信息所包含的链接地址,以及定位关键词,对互联网中的WEB页面进行获取,并精确定位到目标URL,据此将所属的URL进行正则表达式转换,构建正则表达式筛选工具.一般情况下,初始化配置中包含的链接只是提供了一个WEB页面目录URL,缺少必要的具体页面URL,这就使得算法在进行WEB内容爬取时无法预先知晓具体的URL信息和相关格式;此外,对于WEB页面目录与具体的WEB页面而言,URL信息往往具有一定的差别,且具体的WEB页面内容在互联网中也存在非常大的数量,因此,如何根据初始化配置、页面目录URL来提取目标内容是需要解决的关键问题.
大多数WEB站点都包含三个不同的层级,分别为初始WEB页、WEB目录页、WEB内容页,三个层级由浅入深,由粗到细逐步展开.在这样的结构条件下,提取WEB内容的爬虫只有同时横向、纵向进行爬取,才能最大限度地获得目标页面.显然在这个过程中,很多与目标页面不相关的WEB页面也会被爬取,浪费大量的时间,甚至由于不相关WEB页面路径的延伸,使得爬虫效率极低,与目标页面相距甚远,降低了WEB内容提取的精确度.为此,本算法中充分在WEB站点多层结构的基础上,实现对WEB页面的权重计算,从而减少爬虫搜索过程中对于不相关页面的搜索.本算法借鉴BERGMARK等人提出的WEB页面主题隧道理论,通过对WEB页面进行赋权,并判断页面权重与目标页面之间的关系,假若页面与目标内容相关,则赋权为0,假若页面与目标内容不相关,则将该页面的权重值在其上级页面的权重值基础上增加1.具体原理如图4所示.
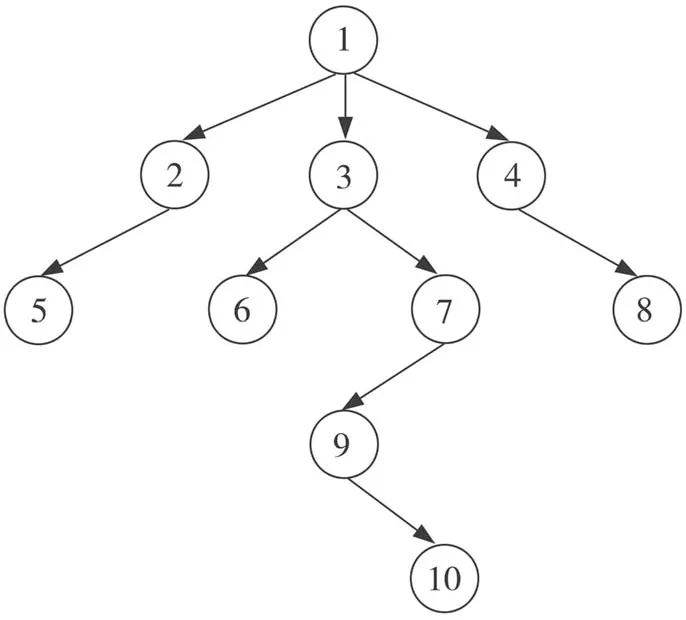
图4 WEB页面权重隧道理论
图4 的各节点中,1表示该节点页面的赋权为0,下层的2、3、4节点页面的赋权则为1,而节点6、7、8的赋权则为2;同理,节点5、9的赋权也是0,对应下层的节点赋权为1.算法中规定只针对某一值范围内的节点进行爬取,如权重小于2的节点,这样,在爬取时图4中的6、7、8节点都不会被搜索.
根据这一理论,本算法针对WEB页面的赋权进行了如下设定:假若WEB页面的HTML内容中包含了与目标页面URL吻合的内容,那么就认定该页面具有可使用正则表达式进行筛选的URL;当WEB页面URL的HTML内容中包含了初始化配置中的定位关键词时,同样将该URL赋权为0.反过来,假若WEB页面URL的HTML内容中未包含初始化配置中的定位关键词,而且也没有包含目标页面的URL时,那么该WEB页面URL的赋权是其父页面URL权重值增加1.赋权的计算公式如下:

显然,对于URL而言,对其赋权越小,表明该URL与搜索内容的吻合度较高,否则吻合度较低.对于不同的筛选阈值,本算法所获得的爬取数量有很大的差异,一般情况下设置的阈值越大,爬取获得的WEB页面较少,反之则较大,这主要是由于阈值设置较大的情况下,本算法的爬取范围也有很大增加,爬取的不相关WEB页面会更多.换句话说,如果阈值选择1的情况下,爬取到的WEB页面权重为小于2的,而如果阈值选择为2,则爬取到的WEB页面权重还会包括3,必然会导致不相关WEB页面的增加.
2.2 WEB内容提取模板算法:具体路径的产生
本文在研究传统WEB内容提取算法的基础上,以基于模板技术和树结构技术为基础,结合前文提出的带权搜索技术,提出了WEB内容提取模板的产生算法.对于WEB页面的HTML源代码而言,其中所包含的内容节点均对应有唯一的定位路径,在进行WEB内容提取时,便是在这样的路径基础上展开的,因此针对这些路径的提取便成为WEB内容提取的关键,借助算法实现对内容定位路径的自动提取并构建模板,便能够更好地实现对WEB内容的提取.
总体来看,本算法在该环节中充分利用了基于模板的WEB内容提取思想,通过设定预获取样本集,从而有效识别出目标WEB内容页面,并从这些URL集合中选择出基准页面URL,将该基准页面URL中的内容信息作为提取的目标信息,然后根据该信息从其他的WEB页面中进行节点路径提取,并把节点路径转变为最后的提取路径,构建路径模板,凡是那些结构近似的WEB页面,都可以使用该路径模板进行WEB内容的提取.在WEB内容提取的初始阶段,本算法通过标记两条不同的WEB页面路径,将其存储在初始化配置文件中,构成WEB内容提取的基准信息,并将两条路径定位为树形结构,二者的公共节点作为新的模板树的起始节点,生成路径模板.具体的算法如下(仅以伪代码形式展现):


在获得WEB内容提取的模板之后,算法还需要按照初始化配置中的获取目标定位出需要爬取的WEB内容的具体路径,从而完成目标内容的提取.在具体路径的定位过程中,按照以下算法描述展开:
(1)根据与设定的目标WEB内容信息文件中提取目标WEB内容详细属性;
(2)在已经构建的子节点队列中遍历搜索提取获得目标WEB内容的详细属性;
(3)如在队列中存在了与目标WEB内容详细属性相同的内容,那么存储该子节点以及其具体路径进入到新的队列中;
(4)如在队列中不存在与目标WEB内容详细属性相同的内容,那么按照自底向上的方式遍历所有树中的非子节点,同样将满足需求的非子节点及其具体路径进入到新的非子节点队列中;
(5)如在子节点以及非子节点中均为搜索到与目标WEB内容详细属性相同的内容,那么进一步搜索包含目标WEB内容详细属性的节点,每找到一个此类节点,都要向其父节点延伸,延伸过程中,发现相同层级相同名称节点的,存储其节点名称,如名称不同,则存储包括名称在内的其他属性,包括类别、ID号等.
按照上述描述的步骤,算法最后将获得与目标WEB内容爬取属性相关的一般路径定位模板,所有路径都通过Json格式进行文本存储,同时该模板文本信息中包含了属性节点内容、位置、具体的属性值等,根据这些属性值,可以获得不同目标WEB内容标签的爬取.在实际的WEB内容提取过程中,通过这种页面赋权的策略与方法,可对互联网中的目标页面完成搜索,而对于已经获取的WEB页面,则根据属性标签进一步实现路径定位,快速提取页面内容.
3 基于页面赋权的WEB内容提取算法实验效果
为进一步验证基于页面赋权的WEB内容提取算法可行性和具体效果,笔者在算法设计完成的基础上,将其应用在爬虫系统中进行实验,并将实验结果与其他爬虫算法进行对比.基于页面赋权的WEB内容提取算法实验环境分两部分,软件环境主要包括Eclipse开发平台,通过该平台的多个开源模块,实现WEB页面的模拟浏览与内容解析,此外还可以借助Redis完成WEB页面重复性的消除;硬件环境根据系统的应用需求采用普通的服务器系统,该实验服务器的CPU为AMD系列8核3.6 G,内存为8 G,配备windows 2012 server操作系统.
按照本文提出并设计的WEB内容提取算法,从两个层面展开对其效果的检验,分别为不同类型WEB站点的多次实验,检验算法的通用性和效率性;与其他同类算法相比,检验本算法的优劣性.
3.1 应用本算法提取不同类型WEB内容实验
选择股票类WEB内容、体育类WEB内容、教育类WEB内容三大类目标WEB内容提取作为基本需求,应用本算法进行检验.这三类内容在构成方面各有特点,例如股票类WEB站点往往具有大量的分类信息、公司名称、地址,以及很多与股票相关的评论等,这些信息能够为使用者提供较大的数据挖掘价值.体育类WEB站点更能体现数据的聚合利用,同时包含各类信息的采集,大数据的分析等.教育类WEB站点则属于文本信息相对较多的网站,最有利于爬虫系统实现WEB内容获取 类 型[18−19].通 过 对 这 些 不 同 类 型 网 站 的 实验,对具体结果展开分析,测试基于页面赋权的WEB内容提取算法稳定性和通用性,并判断它与预期的判断是否相符.
在对上述不同类型网站进行对应的爬虫系统初始化设置之后,根据设定的关键词进行页面内容的提取,分别得到表2所示的结果.
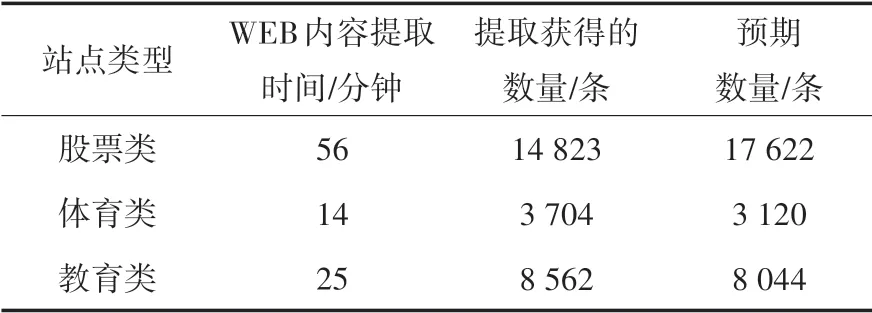
表2 各站点内容平均提取结果
表2中的预期数量是按照一般人工搜索关键字方式获得结果确定的.对比三类网站的提取结果可以发现,不同的WEB内容提取关键字,所获得的提取数量及需要的提取时间各不相同,预期数量与最终提取获得的数量是相匹配的.事实上,表2中各站点的提取时间、数量都属于平均值,是使用本算法多次提取实验之后得到的结果,每个类型WEB内容提取和预期数量的差距主要是由于定位关键词中覆盖范围仍然有限而形成的.总而言之,从本算法实际的WEB内容提取结果来看,基本能够满足需求.
3.2 应用本算法提取WEB内容的效率比较实验
前文对于本算法的实验是从某些类型WEB内容需求出发的,使得本算法构建的爬虫系统只是实现了固定类型WEB内容关键字提取,还没有针对更大范围的通用WEB站点内容进行提取.为此,按照本文算法策略,与某一传统的WEB内容爬虫系统进行效率比较实验.
针对WEB内容的提取效率是评价本算法的基本指标,也是证明本算法可行的主要参数.首先通过实验比较对单一WEB页的内容提取效率,在相同的网络实验环境中,某传统的WEB内容爬虫系统在多媒体加载的条件下,提取该WEB页内容约为13秒,而在多媒体不加载的条件下,提取该WEB页内容约为5秒;相比而言,本次设计的算法未支持对WEB页面多媒体的加载,但在不加载多媒体的条件下,本文算法提取该WEB页内容的时间约为3秒,这是由于算法在设计过程中考虑了URL路径的解析,对于WEB页面可通过该路径完成提取,增加了提取的速度.
评价本算法的另一个重要指标为WEB内容提取的精确度,即利用本算法能够获得的WEB页面内容与目标页面的相关性程度.实验结果表明,利用本算法构建的爬虫系统,无法针对全部WEB内容的提取都达到100%精确,但精确度都在95%以上,有一些WEB站点的提取精确度达到100%.表3所示为本算法的爬虫系统与传统爬虫系统的精确度比较实验结果.

表3 本算法的爬虫系统与传统爬虫系统的精确度比较结果
由表3可知,与传统爬虫系统相比,本算法构建的爬虫系统精确度方面要明显高于传统系统,特别是由于提取过程中借助正则表达式筛选环节过滤掉一部分无关目标的WEB页面内容,从而提高了精确度.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
民族文汇(2022年9期)2022-04-13
昆明医科大学学报(2021年12期)2021-12-30
现代信息科技(2021年21期)2021-05-07
南大法学(2021年6期)2021-04-19
成都信息工程大学学报(2021年6期)2021-02-12
活力(2019年15期)2019-09-25
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2018年2期)2018-04-18
