
顶煤放落过程煤矸声信号特征提取与分类方法
2021-11-06 05:54袁源汪嘉文朱德昇王家臣王统海杨克虎
矿业科学学报 2021年6期
袁源汪嘉文朱德昇王家臣王统海杨克虎
1.中国矿业大学(北京)机电与信息工程学院,北京 100083;2.中国矿业大学(北京)能源与矿业学院,北京 100083;3.山东能源临沂矿业集团有限责任公司,山东临沂 276022
推进煤矿智能开采是我国能源技术的发展趋势,是信息革命的时代要求。 相比其他采煤法,放顶煤采煤法具有高产高效、巷道掘进率低等优势而被广泛应用。 优化改进放煤工艺是实现煤矿智能开采的一个重要环节[1-2]。 传统放顶煤开采过程环境感知困难,煤矿工人工作环境恶劣、粉尘多、视野窄,加之放煤工艺烦琐,容易造成过放、欠放的现象,无法保证资源的回采率与煤质的优良率。 煤矸识别方法的引入可以让煤矿工人更好地掌控放煤口的开关时机,为煤矿智能开采提供技术支持。
学术界对煤矸识别方法进行了大量的研究。针对放落煤和矸石的纹理形态、灰度特征,文献[3-5]研究了基于图像的煤矸识别方法,该方法因样本集易受光照、粉尘干扰,识别精度受到了一定程度的影响;针对粒子波在煤层与矸石层传播的差异性,文献[6]研究了基于电磁波的煤矸识别方法,该方法适用于顶煤探测,由于存在波长衰减,探测范围和煤矸识别精度被顶煤厚度所制约;针对煤与矸石所包含元素放射性强度的不同,文献[7]研究了基于γ射线的煤矸识别方法,适用于顶煤探测,由于受到矸石占比变化的影响,回采率较低,且存在放射性危害;针对采煤机割煤时滚筒扭矩的变化,文献[8]研究了基于扭矩信号的煤矸识别方法,该方法适用于采煤机割煤过程的煤矸识别,但识别装置对传感器要求较高;针对煤矸普氏系数的差异,文献[9]研究了基于振动信号的煤矸识别方法,该方法识别效果受到了工作面复杂程度和机械振动的影响,抗干扰能力较差;针对煤和矸石放落到液压支架尾梁和后部刮板输送机上的声信号物理特性差别,文献[10-11]研究了基于声信号的煤矸识别方法,该方法抗干扰能力较强,但是目前采集与识别系统尚未完善。
基于声信号的煤矸识别方法,因其成本低、标注便捷而广受重视。 文献[12]采用了独立分量分析法对顶煤放落过程的声信号进行分析处理,根据频谱差异初步判断了顶煤中的含矸率;文献[13]考虑了环境噪声,采用含噪的超完备独立分量分析方法解决放顶煤过程中声信号分离的问题;文献[14]采用小波包变换的分析方法,发现频谱会随煤矸混合比例不同而产生差异;文献[15]经实验分析得出煤矸声波时域信号中的峰峰值、方差和峭度系数区分度明显;文献[16]通过独立分量分析将放煤声信号分离,并提取其梅尔倒谱系数特征作为神经网络的输入,进行煤矸识别;文献[17]通过希尔波特-黄变换的方法提取声振信号特征,基于双峰深度学习网络实现煤矸分类。
目前,放顶煤声信号特征提取和分类算法的研究对比较少,且大部分测试没有现场数据的支持。本文完成了工作面放顶煤声信号的采集,通过人工标注建立放顶煤声信号样本库来研究声信号的机理,综合分析样本帧长、特征差异、算法性能,对机器学习分类模型进行评估。
1 放顶煤声信号特征提取方法
放顶煤声信号的特征可以用音调、响度、音色来描述。 声信号的高低称为音调,声信号振动的频率越高,即声源物体振动得越快,音调越高;声信号的强弱称为响度,声信号的振幅越大,响度越大;声信号的波形特征表现称为音色,声信号波形的各个谐波频谱与包络决定了音色的特性。 本文通过滤波去噪,分析振幅、相位与时间、频率的对应关系来提取声信号的特征。
1.1 时域特征提取
放顶煤声信号的本质为非平稳信号[18],可使用非平稳信号的时域分析方法进行特征提取,放顶煤声信号的时域特征及计算公式见表1。

表1 放顶煤声信号的时域特征及其计算公式Tab.1 Time-domain characteristics of caving coal acoustic signal and its calculation formula
表1 选取了有效值、标准差、偏度、峭度、峰峰值、波形因数、脉冲因数和峰值因数8 种特征。 其中,x(n)为放顶煤声信号;N为序列长度;Xrms为信号的有效值;Xstd为信号的标准差;Xske为信号的偏度;Xkur为信号的峭度;Xp-p为信号的峰峰值;CF为信号的波形因数;SF为信号的脉冲因数;IF为信号的峰值因数。
1.2 频域特征提取
放顶煤声信号是数字采样信号,可使用离散傅里叶变换(Discrete Fourier Transform, DFT)方法进行频域特征提取。 离散傅里叶变换公式为
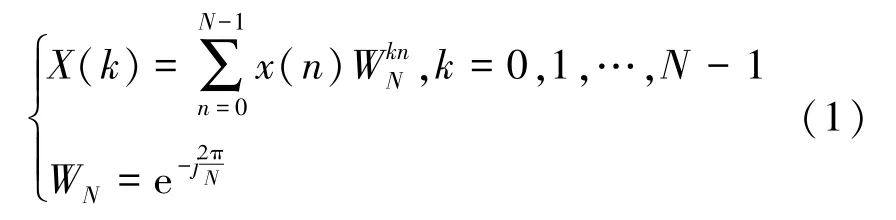
式中,X(k)为频率系数;WN为蝶形因子。
基于蝶形因子的周期性和对称性,在DFT 基础上改进,得到快速傅里叶变换(Fast Fourier Transform, FFT)方法,将复数乘法运算转换为复数加法运算,大大降低了复杂程度与运算量,非常适用于计算机运算。 进一步计算得到声信号的频域特征及计算公式见表2。 其中,XFC为信号的重心频率;XMSF为信号的均方频率;XVF为信号的频率方差。
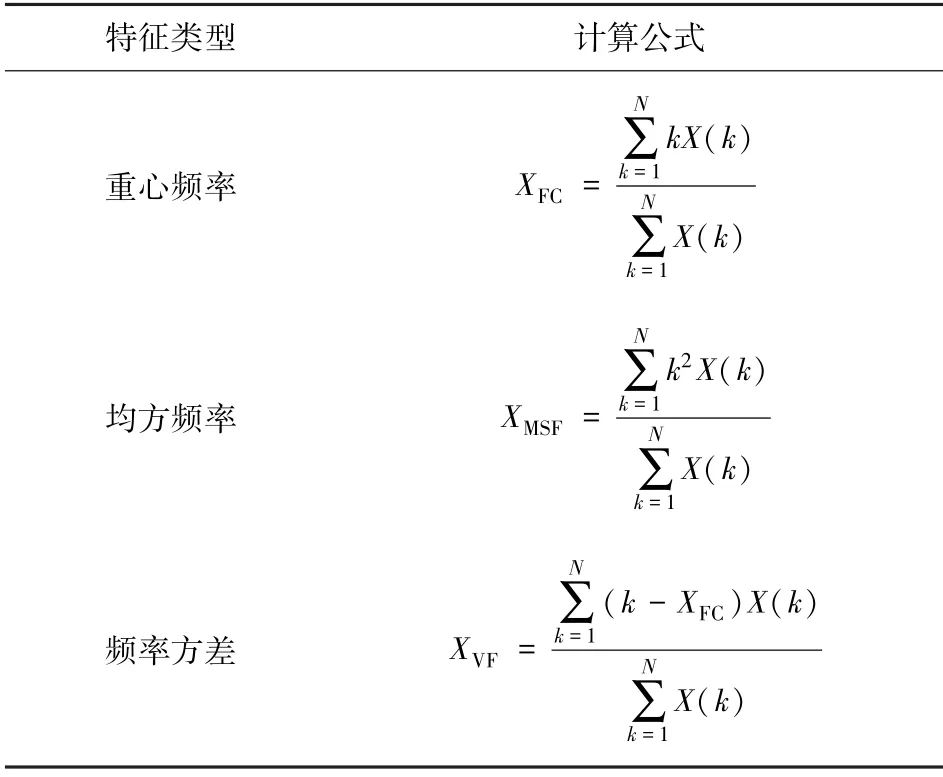
表2 放顶煤声信号的频域特征及其计算公式Tab.2 Frequency-domain characteristics of caving coal acoustic signal and its calculation formula
1.3 时频域特征提取
放顶煤声信号局部特征区别较大,可使用小波变换(Wavelet Transform, WT)[19]的方法进行时频域特征提取。 小波变换可以完成多尺度化的时频分析,但是其分辨率随着频率增加而降低,高频处难以区分。 为对其适用性进行改进,衍生出小波包分解(Wavelet Packet Decomposition, WPD)[20]的方法,小波包分解引入了不同中心频率的带通滤波器,以获得各个节点的信号分量。
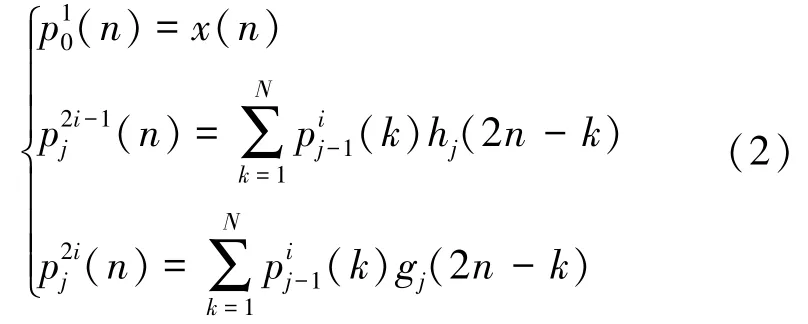
各频带分量的能量:
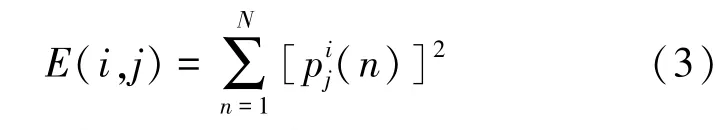
式中,E(i,j)为第j层上的第i个小波包频带能量。
对各频带能量归一化后,得到各频带能量占比:
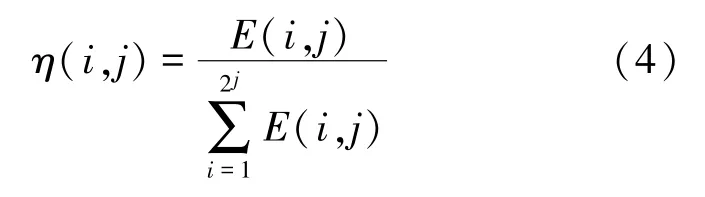
2 机器学习分类算法的理论基础
执行机器学习算法来完成对放顶煤声信号样本集数据的学习过程,获得分类模型。 该模型本质上是对声信号数据集的划分。
2.1 支持向量机算法
支持向量机 ( Support Vector Machine,SVM)[21]算法的目标是找到一个最优的分割面,使得样本分类间隔最大。 在样本空间中,划分超平面为ωTx+b=0,线性支持向量机的目标函数与约束条件为

式中,ω为超平面法向量;b为偏移项;(xi,yi)为样本坐标点;γ为样本点到超平面的距离,通常取值为1。
支持向量机算法具有良好的学习能力,泛化能力强,可以将多分类问题以二分类的方法解决,但它对参数选择要求较高。
2.2 K 近邻算法
K 近邻算法(K-Nearest-Neighbor, KNN)[22]无须使用训练集进行训练,只需计算测试样本到训练样本的距离,选取距离测试集最近的k个训练样本,通过加权投票法得到测试样本的类别。
常用的距离衡量标准有LP 距离、欧氏距离、切比雪夫距离和曼哈顿距离。 其中欧氏距离为
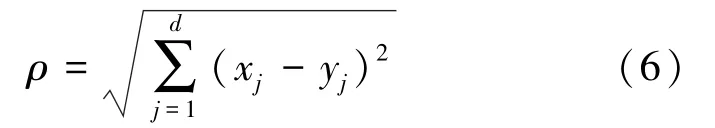
式中,(xj,yj)为空间坐标点;d为空间维数。
K 近邻算法理解简单、易于实现,可用于分类、回归问题,对异常值不敏感,但计算太复杂,属于懒惰学习,需要大量的存储空间。
2.3 朴素贝叶斯算法
朴素贝叶斯算法(Naive Bayes Classifier,NBC)[23]是在贝叶斯定理的基础上增加了条件特征独立性假设的算法。
朴素贝叶斯的推断标准为
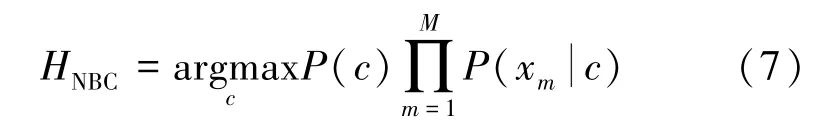
式中,c为类别;M为属性数目;xm为x在第m个属性特征上的取值。
在实际分类问题中很难保证各项特征条件相互独立,朴素贝叶斯模型精度受到了特征相关性的影响,但算法本身比较简单,常用于多分类问题。
2.4 决策树算法
决策树算法(Decision Tress, DT)[24]应用了经典的树形结构。 ID3(Iterative Dichotomiser 3)算法以信息增益作为特征。 C4.5 算法是ID3 的改进算法,支持对连续值输入样本节点的划分,满足对缺失值的处理要求。 CART(Classification And Regression Tree)算法为二叉树结构。
信息增益可表示为
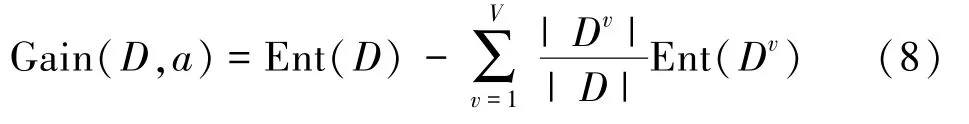
式中,Ent(D)为信息熵;D为样本集合;a为离散属性。
有V个可能的取值,其中第v个分支节点包含了D中所有在属性a上取值为av的样本,记作Dv。
决策树算法易于实现,可在短时间内对大量数据做出可行性较高的判断,但解决多分类问题的效果不理想,且难以预测连续值。
2.5 随机森林算法
随机森林算法(Radom Forests, RF)[25]是决策树的集合,它的核心思想是增加树的多样性。
RF 模型包含z轮训练,即z个决策树模型,其分类序列可表示为[DT1(ζ),DT2(ζ),…,DTz(ζ)],再进行投票表决。 分类决策为
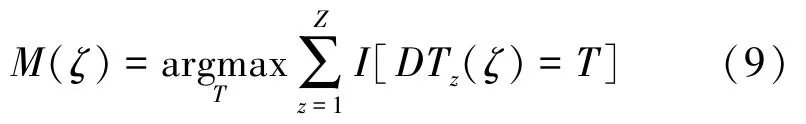
式中,M(ζ)为RF 分类模型;DTz(ζ)为单个分类模型;I为随机变量的信息;T为输出变量。
随机森林算法常用于多分类任务,具备较高的抗过拟合能力,对训练集样本数量与特征数量有着较高要求。
2.6 神经网络算法
神经网络算法[26],即人工神经网络(Artificial Neural Network, ANN)算法。 常用的模型为多层感知器(Multi-Layer Perceptron, MLP)。 神经网络算法模型的复杂程度随着参数的增加而增加,复杂的网络结构可以进一步完成更加复杂的学习任务,但该算法存在训练效率低、易于过拟合等问题。
3 放顶煤声信号样本集构建
放顶煤声信号样本数据主要分为实验模拟采集数据与工作面现场采集数据。 实验室未考虑综放工作面恶劣环境与复杂工况,模拟论证阶段的数据较为理想;工作面现场采集的数据反映了真实的放煤过程,但数据量较少,且大都是人工参与采集,采集装置成本较高、适用性较差。 缺乏大量现场数据作为支撑,使得现有的煤矸识别方法难以投入实际生产中。
针对这一现象,本文设计了一种低成本、无须人工干预、可长时间采集、使用方便、适用性高的放顶煤液压支架尾梁声振数据采集装置。 该装置安装于液压支架尾梁内侧,采用内部电池供电,覆盖防水透气膜并置于防水外壳中,通过对比加速度传感器信号变化,结合运动识别算法,判断液压支架是否为放煤状态。 若是,则进一步采集放顶煤声振数据,并存储于装置中。
数据采集装置电路结构如图1 所示,控制模块选取了低功耗微控制器STM32L051 和高性能微控制器STM32F407,麦克风为MEMS 麦克风ICS-43432,振动传模块选取了MEMS 加速度计ADXL1002,存储器容量为16 GB,采样频率为48 kHz,采样深度为24 bit。
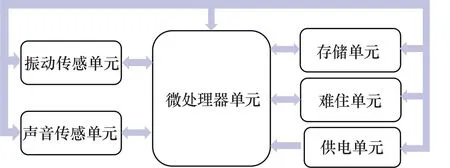
图1 数据采集装置电路结构Fig.1 Circuit structure diagram of data acquisition device
本实验数据均采集自山东能源古城煤矿3106综放工作面现场,数据采集装置实物如图2 所示。将采集到的音频文件进行人工标注,划分为不同类型的声信号。 图3 为放煤声信号,图4 为放矸声信号。

图2 放顶煤液压支架尾梁声振数据采集装置Fig.2 Acoustic and vibration data acquisition device for tail beam of caving coal hydraulic support
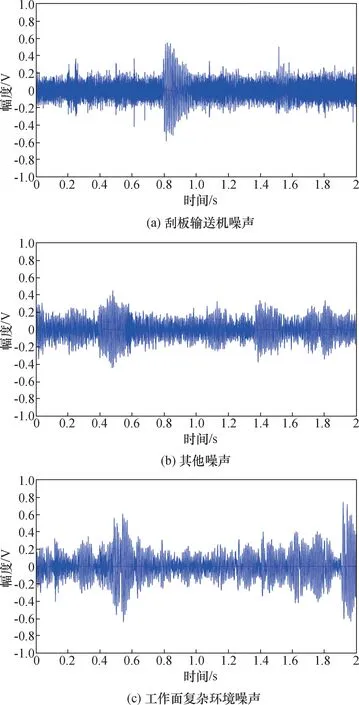
图3 不同噪声影响下的放煤声信号Fig.3 Coal sound signal under the influence of different noises
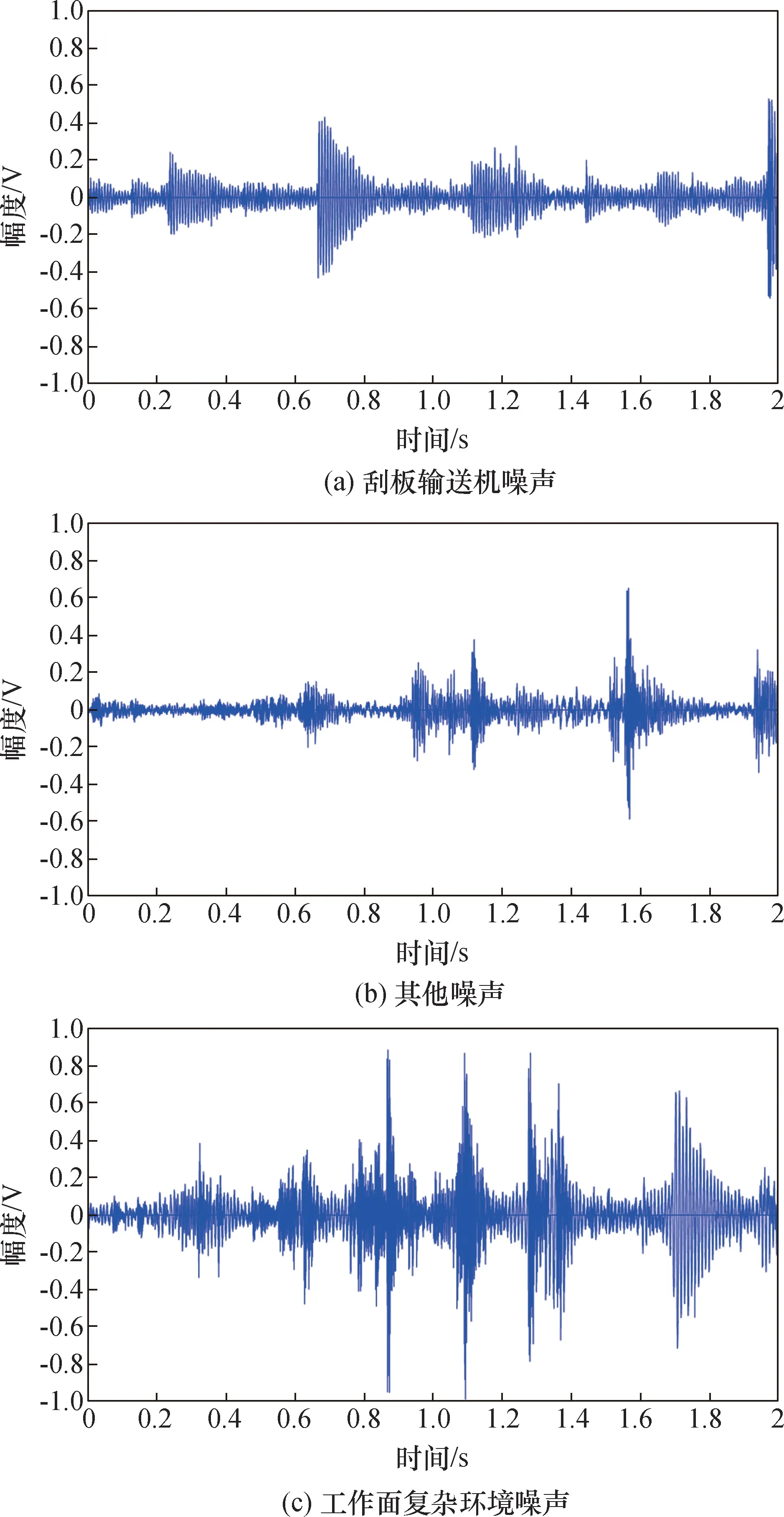
图4 不同噪声影响下的放矸声信号Fig.4 Gangue sound signal under the influence of different noises
放顶煤声信号样本库共有1 012.97 MB,总时长为5 825 s。 其中,放煤声信号样本共912.64 MB,总时长为5 296 s;放矸声信号样本共100.33 MB,总时长为529 s。
放顶煤声信号时域特征提取,是采用了非平稳信号时域分析的方法,获得有效值、方差、偏度、峭度、峰峰值、波形因数、脉冲因数、峰值因数作为输入的8 维特征向量。 频域特征提取是通过FFT 算法对原始信号进行运算,得到重心频率、均方频率、频率方差作为输入的3 维特征向量。 时频域特征提取是采用小波包分解的方法,设置小波基为sym8、最大分解层数为6,根据能量守恒定律计算出每个频带分量的能量占比,将其作为输入的64维特征向量。 放煤声信号和放矸声信号的小波包分解频带能量占比如图5、图6 所示。
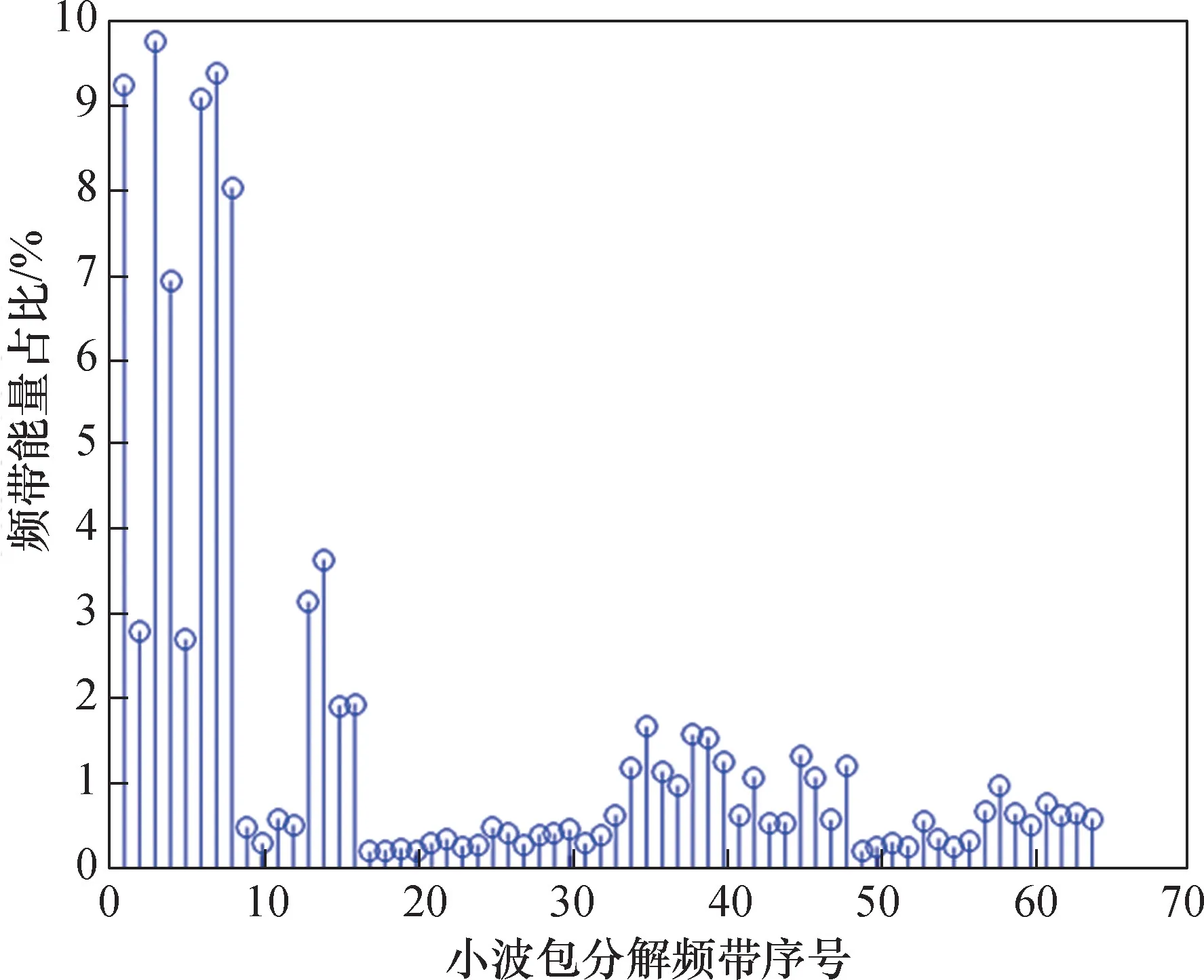
图5 放煤声信号小波包分解频带能量占比Fig.5 Frequency band energy ratio of wavelet packet decomposition of coal caving acoustic signal
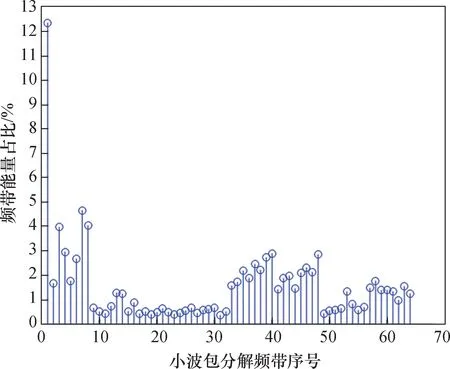
图6 放矸声信号小波包分解频带能量占比Fig.6 Frequency band energy ratio of wavelet packet decomposition of gangue acoustic signal
4 机器学习分类模型训练
本实验环境为Windows10 系统,CPU 为Intel Core i7-8750H 2.20 GHz,运行内存为8 G,数据处理、模型训练与方法验证均在PyCharm 上运行。
支持向量机、随机森林、K 近邻算法、朴素贝叶斯、决策树和神经网络均使用预处理后的声信号样本进行训练,输入特征分别为时域特征、频域特征和时频域特征。 考虑RF 模型性能与系统运行效率,设定随机森林子树数量n_estimators=100,通过oob_score 属性打印模型的oob 分数,设定oob_score = True。 神经网络模型采用拟牛顿法优化器,设定lbfgs= quasi-Newton,正则化参数alpha 设置为0.000 01,隐藏层参数设置为(5,5)。 其余模型参数均为默认。
使用交叉验证的方法对煤矸识别准确率进行评估,采用k-fold 交叉验证法,设置参数cv=10。分类模型的参数见表3。 每一种模型的识别时间均在3 ms 左右,满足工作面的实时性要求。
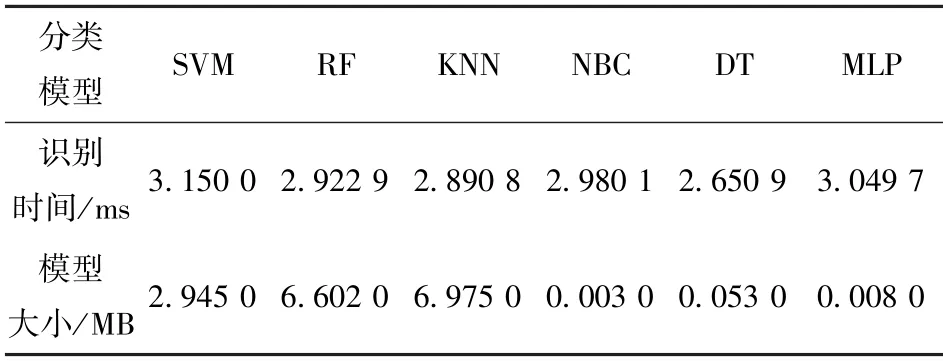
表3 多种分类模型的参数Tab.3 Parameters of multiple classification models
5 分类模型应用与性能评估
基于放顶煤声信号样本集,运用不同的特征提取方法与分类算法完成模型分类应用实验与性能评估。
5.1 样本帧长对分类准确率的影响
不同帧长的样本会影响煤矸识别的准确率,本文选取帧长为50 ms、100 ms、150 ms、200 ms、250 ms、300 ms 的6 种情况,帧移默认为1/2 的帧长,针对不同特征与不同分类器进行对比实验。
对于时域特征,SVM、MLP 的模型分类准确率随着帧长的增加而降低,如图7 所示;RF、KNN、DT的模型分类准确率随着帧长增加而增加,在200 ms 之后趋于平缓,准确率基本保持不变;NBC 的模型分类准确率波动较大,在100 ms 时取得最大值。 RF、DT 模型表现较好,RF 模型在帧长为200 ms 时,最大值为91.60% 。
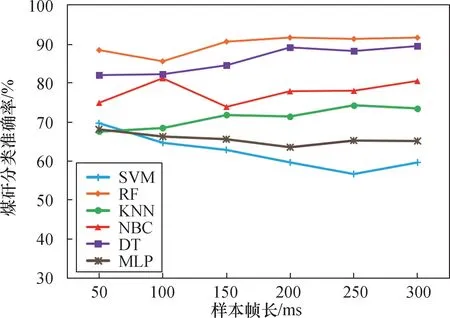
图7 时域特征提取下不同帧长的煤矸识别准确率Fig.7 Accuracy of coal gangue recognition in different frame lengths under time-domain feature extraction
对于频域特征,RF 模型的分类准确率随着帧长的增加而缓慢增加(图8),其余5 种算法的准确率均有较大波动。 NBC 模型表现较差;KNN、RF、MLP 模型表现较好;KNN 模型在帧长为50 ms 时,煤矸分类准确率为87.69% ,随着帧长的增加准确率有所下降, 在帧长为150 ms 时最大值为87.61% ,较为接近帧长50 ms 的表现。
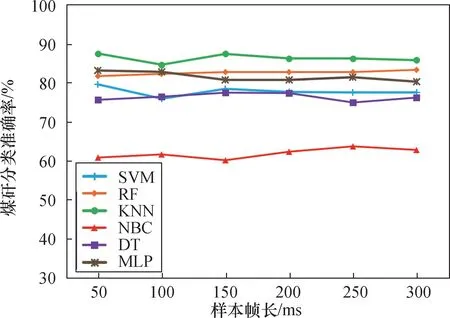
图8 频域特征提取下不同帧长的煤矸识别准确率Fig.8 Accuracy of coal gangue recognition in different frame lengths under frequency-domain feature extraction
对于时频域特征,随着帧长的增加,SVM 模型分类准确率持续下降(图9),其余5 种模型均有上升的趋势。 RF、KNN、DT、MLP 模型表现较好;RF模型在帧长150 ms 时煤矸识别准确率为93.05% ,之后增长趋于平缓,受限于样本数量,其准确率甚至有所下降,200 ms 帧长的煤矸识别准确率,最大值为93.35% 。

图9 时频域特征提取下不同帧长的煤矸识别准确率Fig.9 Accuracy of coal gangue recognition in different frame lengths under timedomain feature extraction
综合考虑,本次实验最佳帧长为200 ms,帧移为100 ms。 6 种机器学习算法模型中,SVM、NBC模型分类表现较差,之后的实验主要是对其余4 种分类模型进行分析。
5.2 特征选取对于分类准确率的影响
不同的特征选取会影响到煤矸识别的准确率,本文研究不同特征向量对煤矸识别准确率的影响。现采用矩形窗函数对声信号进行分帧,设置帧长为200 ms,比较RF、KNN、DT、MLP 在不同特征选取下的分类准确率(图10)。
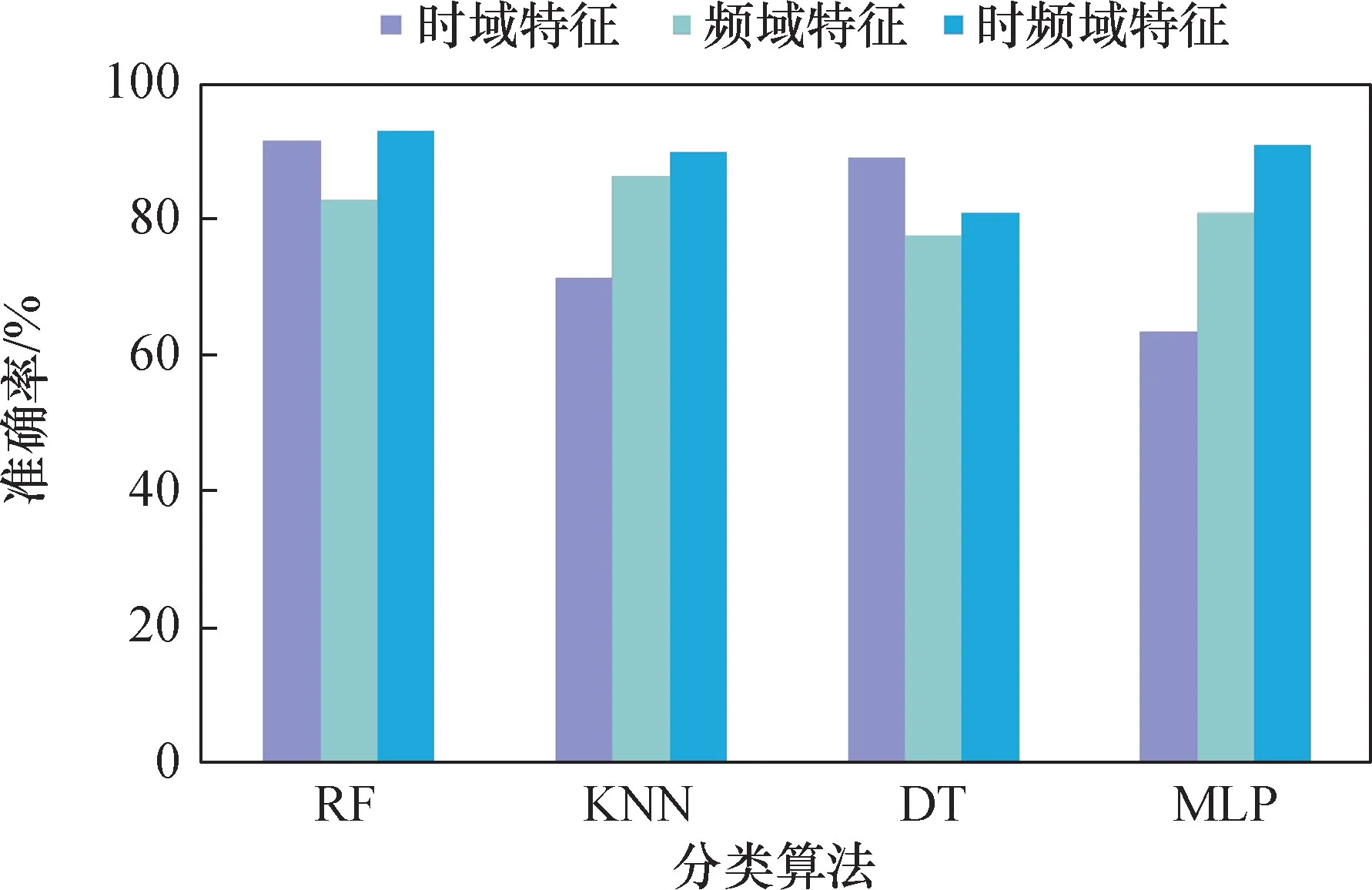
图10 不同特征的煤矸识别准确率Fig.10 Recognition accuracy of coal and gangue with different characteristics
RF、KNN、MLP 选取64 维时频域特征作为输入可获得较高的准确率, 分别为 93.06% 、90.02% 、90.92% 。 DT 选取时域特征作为输入可获得较高的准确率,为89.08% ,但未达到90% ,不作考虑。 因此,选取时频域特征,对声信号样本进行小波包分解,可提取更具备区分性的特征,有助于提升煤矸识别准确率。
5.3 特征维度对于分类准确率的影响
时频域特征向量的维度会影响分类的准确率,本文利用主成分分析( Principal Component Analysis, PCA)[27]对时频域特征向量进行降维,将高维的特征向量映射到低维空间中,增大样本采样密度,降低运算耗时,减弱信息重叠现象对分类模型性能的影响。
本实验设置窗函数为矩形窗,最佳帧长为200 ms,以时频域特征作为输入特征向量,共有64 维,对其进行主成分分析降维的结果共有64种。 输入不同维度的特征向量,基于不同的机器学习算法进行模型训练,采用交叉验证法测试煤矸分类准确率。 图11 为不同维度下多种分类模型的煤矸识别准确率。 由图11 可知,RF、KNN、DT、MLP 模型分类准确率在降维的过程中均有提升,在64 维特征向量中存在较多无区分性特征,准确率分别为93.06% 、90.56% 、85.87% 、91.05% 。在降维至1 维时,由于损失过多的有效特征,准确率分别为54.91% 、58.36% 、54.89% 、59.00% 。 4种模型在降维过程中的煤矸分类准确率最大值分别为94.51% 、90.85% 、88.27% 、91.96% ,RF 模型分类准确率略高,可有效提升煤矸分类准确率。 当特征维度为20 维时,采用RF 分类模型,煤矸分类准确率最高,为94.51% 。

图11 不同维度下多种分类模型的煤矸识别准确率Fig.11 Accuracy of coal and gangue recognition by various classification models in different dimensions
6 结 论
本文研究了放顶煤声信号的特征提取方法,对比了主流机器学习算法的分类表现,得出以下结论:
(1) 不同帧长的样本选取会对煤矸分类的准确率产生影响。 选择帧长为200 ms、帧移为100 ms 时,基于时域特征提取与时频域特征提取的分类准确率最高,分别为91.60%与93.35%。
(2) 不同的特征选择适用于不同的算法模型。本文的时频域特征提取方法适用于RF、KNN 与MLP 分类器,煤矸分类准确率分别为93.06% 、90.05% 、91.02% 。 相比于时域特征和频域特征,时频域特征能提高分类准确率。
(3) 对于时频域特征向量,降维有助于提升分类准确率。 RF、KNN、DT、MLP 4 种模型的分类准确率分别提升了1.45% 、0.29% 、2.40% 、0.91% ,其中RF 分类模型准确率最高,为94.51% ,对应的时频域特征向量维度为20。
(4) RF、KNN、DT、MLP 在获得较高分类准确率的同时,模型大小分别为6.60 MB、6.98 MB、0.05 MB 和0.01 MB。 综合考虑分类准确率与模型大小,MLP 模型更具备低功耗平台的适用性。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
北京汽车(2021年2期)2021-05-07
健康体检与管理(2021年10期)2021-01-03
振动工程学报(2019年2期)2019-05-13
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
物联网技术(2016年11期)2017-01-12
