
基于深度学习的多重文档结构识别方法研究
2021-11-10 05:27徐一鸣潘伟民
电子设计工程 2021年21期
徐一鸣,潘伟民
(新疆师范大学计算机科学技术学院,新疆乌鲁木齐830001)
随着信息技术的快速发展与信息系统的广泛使用,越来越多的人以更加开放的格式文档转向数字化存档,便于文档的上传与读取[1-2]。文档结构正向多语言、图片文字混合排版,手写、纯印刷和手写印刷混排等多重文档模式的发展,增加了文档结构识别的难度[3-4]。
为进一步提高多重文档结构识别的精准度及效率,文中提出了一种基于深度学习的多重文档结构识别方法。通过自编码器来构建多层文档学习网络,使用多层神经网络提取多重文档特征、特征学习与次抽样。通过多重文档的特征属性,将上述特征转至文档空间库内,明确该文档结构的构成内容,继而完成对多重文档结构识别。
1 多重文档结构识别方法设计
1.1 文档框架范围判定
凭借布拉格公式拆分文档结构,文档框架范围λB可表示为:

式(1)中,ndff代表范围文字边界超出率,Λ 代表辨识周期。在文档框架外出现页码、页眉和页脚标识时[5],文档框架的ndff与Λ 对应进行调整转变,进而引发文档框架判定的偏移误差[3]。文档框架范围和页码与页眉页脚的关联如式(2)所示。
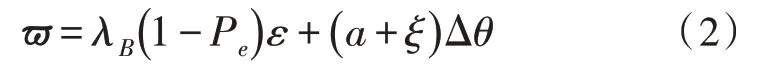
式(2)中,λB代表框架内文档框架界定偏移,ε代表页码转变率,Δθ代表页眉页脚位置偏差,a与ξ分别代表文档框架范围的膨胀系数与缩减系数[6-7],Pe代表文档框架范围的有效判定系数,,其中,P11与P12代表弹性判定系数,v代表选取范围长宽配置比。当弹性范围小于纸张惯性范围时[8-10],文档框架的形变公式能够简化为:
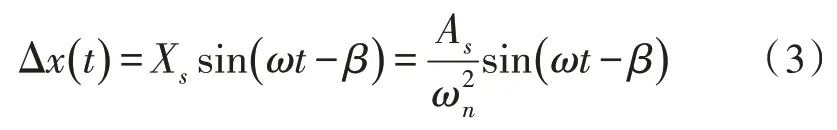
式(3)中,ω与Xs分别代表添加在弹性范围中的划分频次与弹性划分幅度,t表示调制幅度,ωn代表自由度范围内的固有划分频次,As代表输入弹性系数后的划分幅度,β代表范围划分偏移相位。经过对光栅周界震动传感器反射的波长偏移量进行测量,就能够完成对外界震动频率的感知。
1.2 基于自动编码器的文档特征表达
自编码器是一种典型的无监督特征学习方法,其结构包括输入层、编码层与输出层[11-12]。拟定输入值与输出值为不同状态,编码器出现的结果可表达为:

式(4)中,f(x)代表非线性文档特征激活函数,通常叫做逻辑函数,W为网络的初始化权重,bh代表隐藏层偏权值。逻辑函数f(x)如式(5)所示。

式(5)中,z表示修正收敛速度。利用解码器函数g(h)重组隐藏层数据,其表示式如式(6)所示。
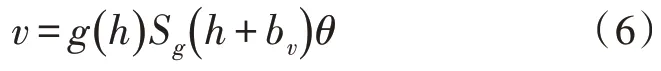
式(6)中,Sg代表单元特征激活函数,通常为线性函数或sigmoid 函数,θ表示超参数,bv表示可见层的偏置。自动编码的训练过程就是探索拟定数据集里超参数θ的最小化重组误差。重组误差能够通过式(7)表示:
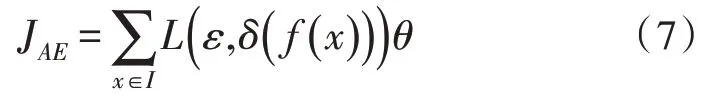
式(7)中,L代表文档结构判定误差函数,δ代表隐藏层变量,ε表示循环误差值。一般可以利用平方误差函数表示误差重组后输出值的文档特征,通过式(8)能够表示为:
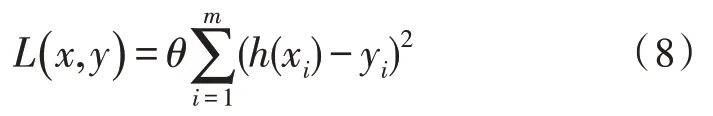
式(8)中,h(xi)代表预测的第i个特征值,yi代表实际的第i个特征值。在现实使用的流程内,凭借堆叠多层的自动编码器,可以让文档结构特征出现一种多层的表示,进而得到最符合期望的特征表达。
1.3 基于卷积神经网络的文档二维结构识别
人工神经网络即卷积神经网络,主要用于识别文档的二维结构[13]。经过以上叙述得知,该网络的所有层均是由多种二维文档平面构成的,所有层都存在较多的独立神经元,这种神经元分别被称之为复杂元与简单元。即通过S元所聚集的面就是S面,S面聚集的层则是S层,C元、C面、C层同样与此关联。其S层即指特征提取层,网络的计算层都是利用多种特征所反射而成,每一种特征所反射的平面,其神经元权值都是一样的。模型C层即凭借卷积层的神经元所构建的网络层,S层即凭借次抽样层的神经元所构建的网络层。在卷积层内,可以利用上一层的文档结构特征和学习的卷积核,但卷积架构通过激活函数后输出构建该层特征。每一种输出的特征都可以和上一层的特征进行卷积构建。通常来说,卷积层如式(9)所示。

式(9)中,l为文档结构层的总量,k为卷积核,j为输入选择文档特征值,b为每一种输出偏置值[14-15]。凭借次抽样层对输入的文档进行抽样操作处理,假设输入特征为n种,那么通过次抽样层后特征的数量即为n。次抽样层的表达式为:
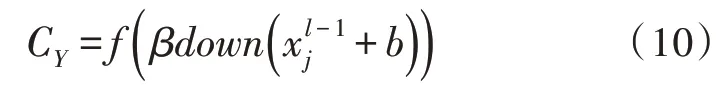
式(10)中,down(·) 代表次抽样函数,β为特征修正参数,xlj-1为抽样层参数。主要是利用对输入特征的n×n尺寸进行求和,所以输出长度是输入长度的1n。
基于上述文档特征的计算,关于文档的卷积神经网络训练流程具有两个步骤。
1.4 多重文档结构识别
因多重文档中包含多种变量,因此针对存在n种变量的多元函数Q=Q(x1,x2,…,xn),拟定Q在整体定义域内连续且可导[16],使Q0=Q(x10,x20,…,xn0),那么把Q=Q(x1,x2,…,xn)在Q0的同一领域里扩展同时剔除高阶项,可得:
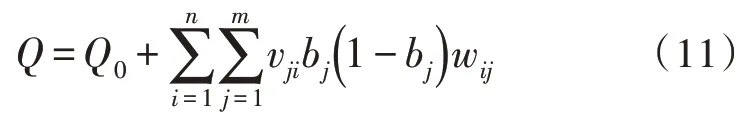
式(11)中,v代表识别输出层的权值,wij代表识别输入层的权值,bj代表中间层的输出值。值得考虑的是,Q0取[ ]0,1 中的随机常数,Q0只能挑选存在代表性的多重文档结构样本,这样才可以确保模型的精准性与可信度。
针对具体问题,xi、Δxi、Q0、v与w都是已知的,所以可以推算出文本特征:
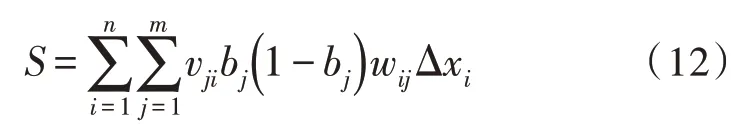
代入化简得:
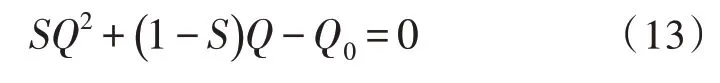
如果S=0,那么Q=Q0。
如果S≠0,那么就存在如式(14)与式(15)的两种状况:
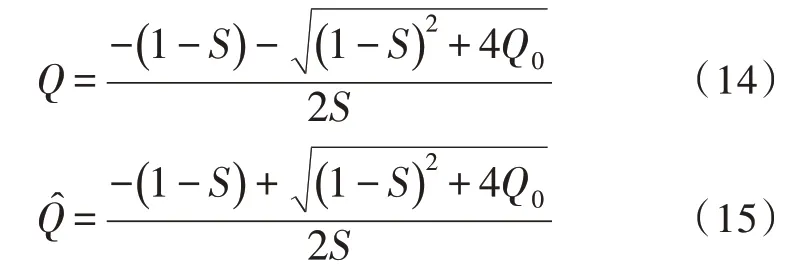
在F(Q)=SQ2+(1-S)Q-Q0时,讨论F(Q)=0 时解的存在状况。
在现实使用中,Q0能够取[0,1] 内的随机常数,所以:
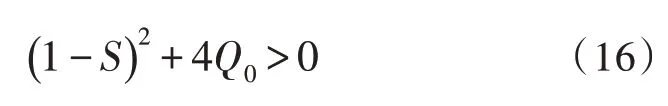
F(Q)满足:
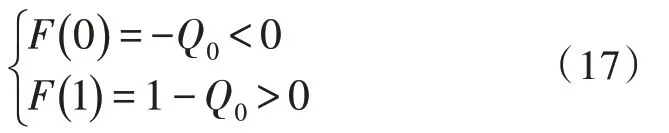
通过式(16)与式(17)能够看出,F(Q)=0 在[0,1]中一定存在实数解,F(Q)=0 曲线的对称轴是,分区间讨论:1)S<-1 时,0 <Q1<1,此时唯一的解是式(17);2)-1 <S<0 时,Q1>1 此时唯一的解是式(16);3)S>1 时,0 <Q1<1,此时唯一的解是式(18);4)0 <S<1 时,只考虑[0,1] 区间内的情况,所以唯一解为式(14)。通过上述可知,式(14)存在多重文档特征识别实数解表达式:
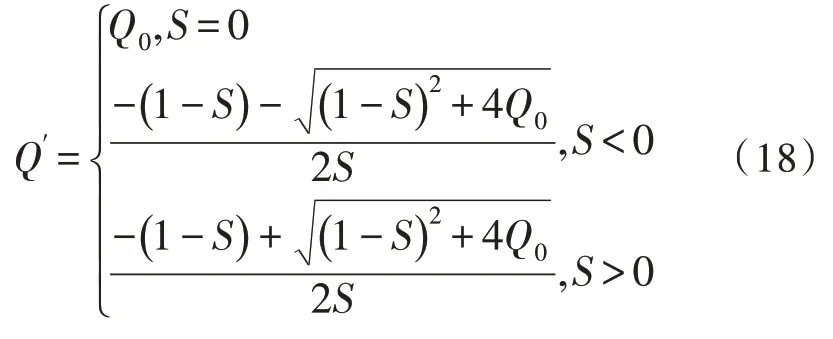
2 实验证明
实验环境为Intel(R)Core(TM)2Quad2.66 GHz CPU,3.50 GB 内存的PC 机。该文实验通过Matlab(2019a)仿真平台来验证所提方法的有效性。为确保实验的真实有效性,需要定义多重文档结构,并归一化处理实验样本,获得准确的结构向量。
完成算法训练后,再向仿真系统内输入包括图片、手写字、电脑键入字,以及包含英语、中文的400篇硕士学位论文。对比标准的识别结构特征与利用该文方法识别的结果,并在仿真平台输出识别结果[17]。由于多重文档结构特征项较多,所以选取具有代表性8 项作为识别项目,包括图片、手写字体、计算机键入字体、中文、英文、正文、关键词、标题对应的特征与正文相同。上述标准文档框架范围权重与文档范围提取阈值如表1所示。
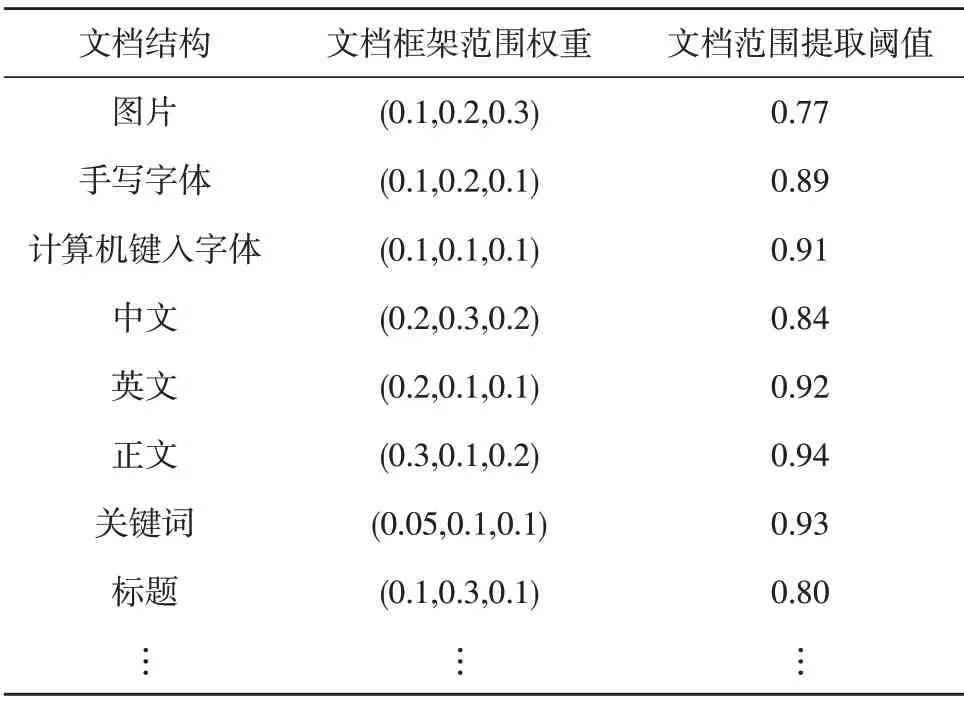
表1 标准数值设定
该文方法识别实验结果如表2所示。
由表2实验数据可知,对上述8 项的识别率均高于94%,准确识别文档数量多于360 篇,对文档框架范围权重的设定相同,对文档范围提取阈值均不超过标准值的0.05,说明该文方法在多重文档识别中具有较高的准确性与效率。
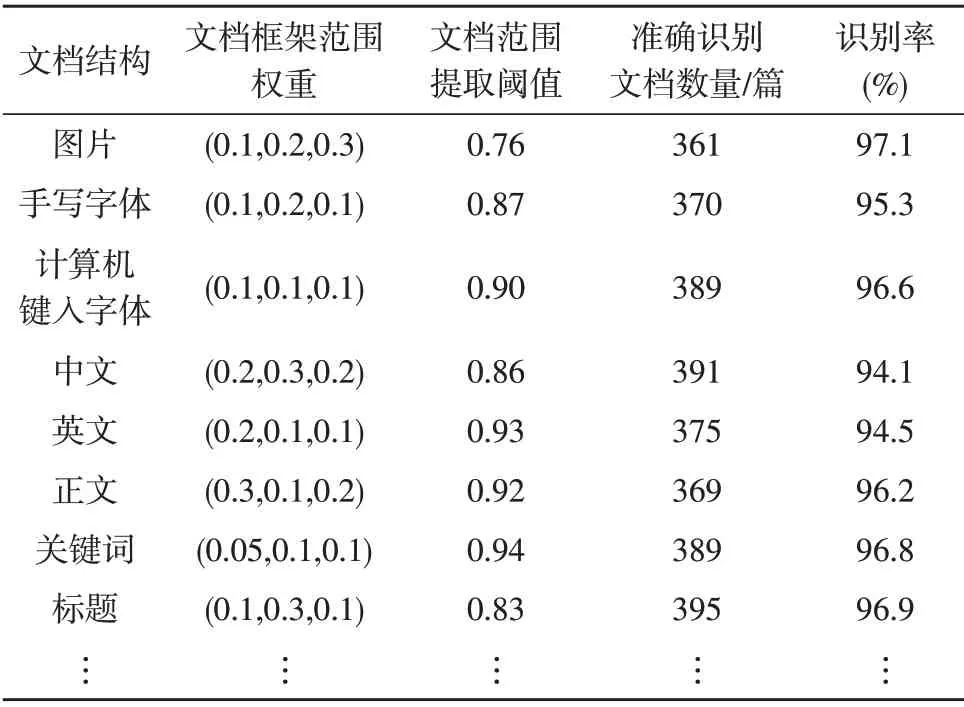
表2 多重文档结构识别结果
3 结 论
针对多重文档结构识别时出现的识别效率慢与识别精准度低的问题,提出了一种基于深度学习的多重文档结构识别方法。利用自编码器来构建多层网络,并调整训练参数,使用多层神经网络对多重文档进行特征提取、特征学习与次抽样[18],估算现实输出和对应的期望输出的差值,利用多元函数识别文档结构。实验证明,该文方法在多重文档结构识别上具有识别效率较快和识别精准度较高的优点。
猜你喜欢
客联(2022年3期)2022-05-31
北京航空航天大学学报(2021年9期)2021-11-02
中国新闻周刊(2021年26期)2021-07-27
电子制作(2019年11期)2019-07-04
成都信息工程大学学报(2018年3期)2018-08-29
北京航空航天大学学报(2018年1期)2018-04-20
制造技术与机床(2017年7期)2018-01-19
信息安全研究(2016年4期)2016-12-01
电子器件(2015年5期)2015-12-29
