
钓鱼网站检测技术研究综述
2021-11-12 09:06云雷李丹王欢欢
电子产品可靠性与环境试验 2021年5期
云雷,李丹,王欢欢
(工业和信息化部电子第五研究所,广东 广州 511370)
0 引言
互联网的发展对在线银行、电子商务和社交网络等许多应用程序的业务增长和促进产生了积极的影响,为人类的工作与生活提供了众多便利;与此同时,由于互联网具有开放性与匿名性的特点,互联网中不可避免地存在着网络信息安全隐患。其中,钓鱼网站是网络中众所周知的安全威胁之一,大量的网络攻击都与钓鱼网站有关。
钓鱼网站是用于网络攻击的网络链接。网络链接一般由资源类型、存放资源的主机域名和资源名称组成,也可称为由协议、主机、端口和路径4个部分组成的网络链接,如图1所示,且带方括号“[]”的为可选项。网络链接中有相当多的一部分是钓鱼网站[1],钓鱼网站的攻击方式多样,与良性网站链接极其相似,用户不易区分,用户访问钓鱼网站即成为各种骗局的受害者,将会造成金钱损失、私人信息泄露和重要资料丢失等。
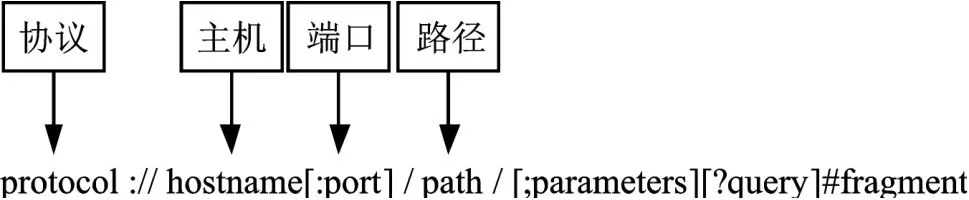
图1 网络链接标准格式
使用钓鱼网站的主要攻击类型包括:网络钓鱼、偷渡式下载和垃圾邮件。网络钓鱼[2]通过假冒原始网页诱骗用户泄露私人或敏感信息。偷渡式下载[3]是指用户访问网络链接时对恶意软件的无意下载,通过利用插件中的漏洞或通过JavaScript插入恶意代码来进行此类攻击。垃圾邮件[4]是出于广告或网络钓鱼目的而未经请求的邮件的使用,NIST基于垃圾邮件开发了一个评估钓鱼网站风险的工具,基于垃圾邮件里面的钓鱼网站,该工具考虑了网络钓鱼线索和用户背景,评估其组织网络钓鱼活动的难度并解释相关的点击率[5]。钓鱼网站的滋生已经对网络信息安全构成了极大的威胁,对用户的网络安全造成了极大的破坏,能够及时准确地检测到钓鱼网站的研究是迫切的。钓鱼网站的相关研究者从页面采集、特征提取和检测技术方面进行不断的突破,并提出有效的解决方案。
1 钓鱼网站的检测技术
现有的钓鱼网站检测技术研究大部分是基于黑名单[5]、 信誉系统[6]、 主机[7-8]、 词汇[9-10]、 蜜罐技术[11-12]、入侵检测技术[13-14]和机器学习方法[15-16]等方式。一直以来应用最为广泛的为基于黑名单和机器学习方法,下面将从这两个方面介绍钓鱼网站的检测技术。
1.1 黑名单方法
黑名单方法是钓鱼网站检测中常见的一种技术,是一种极为简单的检测技术, 基于黑名单的过滤是针对钓鱼网站的主要对策。此方法是将已被确定为钓鱼网站的数据放入数据库中,组成钓鱼网站黑名单数据库。每当访问新的网络链接时,首先在黑名单数据库中查找,如果该网络链接存在于黑名单中,即被认为是恶意的,并生成警告;否则为良性。传统上,这种检测主要通过使用黑名单来完成。但是,黑名单不能详尽无遗,并且缺乏检测新生成的钓鱼网站的能力[17]。黑名单必须实时地更新,因为钓鱼网站往往寿命很短,并且其子字符串可能会采取部分突变的方法以避免被列入黑名单中。基于此,Akiyama等人[18]提出了一种有效的黑名单网络链接生成方法。尝试使用搜索引擎来发现钓鱼网站附近的网络链接,并通过使用已列入黑名单的网络链接以按照驱动下载和点击下载感染实验性地评估了此文建议的生成方法,证实了此方式的有效性。Prakash等人[19]使用近似匹配算法,该算法将网络链接分解为多个组件,这些组件分别与黑名单中的条目匹配,以此方式完成钓鱼网站的检测研究。
Hong等人[20]经过文献调查后收集了许多词汇特征,并将它们与列入黑名单的域结合起来以提高检测性能。Yagi等人[21]假定未知钓鱼网站存在于由同一对手创建的已知钓鱼网站的附近。提出了一种有效的黑名单网络链接生成方法,该方法通过使用搜索引擎来发现钓鱼网站附近的网络链接。但是,由于大多数开放式数据集已过时,因此收集了许多最新的钓鱼网站。由于钓鱼网站往往寿命很短,并且可以对其进行部分变异以避免黑名单,因此必须更新黑名单。
尽管诸如钓鱼网站黑名单之类的解决方案在某种程度上具有有效性与简单易行的优势,但是它们依赖与黑名单条目的精确匹配,使攻击者易以逃避、无法维护所有可能的钓鱼网站的详尽列表,因为每天都可以轻松地生成新的网络链接,从而使他们无法检测到新的威胁[22]。并且,由于难以保持详尽的最新名单,因此遭受了虚假的高误报[23]。当攻击者通过算法生成新的网络链接,从而可以绕过所有的黑名单时,这一点尤其重要。尽管黑名单面临一些问题,但由于其有效性与简单易行的特点,它们仍然是当今许多防病毒系统最常用的技术之一。
1.2 机器学习方法
由于黑名单不能穷举,也无法检测到新生成的钓鱼网站,为了解决这个问题,近年来使用机器学习方法进行钓鱼网站检测的研究工作[24]很盛行。即将钓鱼网站检测的问题形式化为机器学习任务。在将网络链接转换为特征向量之后,通常可以将学习算法中的许多算法以相当直接的方式应用于训练预测模型。在设计特定的学习算法方面,要么利用钓鱼网站的训练数据显示的属性,要么解决应用程序面临的一些特定的挑战。Cui等人[25]提出了一种基于梯度学习的统计分析和使用S形阈值水平的特征提取相结合,基于机器学习技术的新检测方法。
在现实世界中的钓鱼网站检测任务中,钓鱼网站与良性网络链接的数量之间的比例非常不平衡,这使其非常不适合简单地优化预测准确性。此外,现有工作的另一个主要局限性是假设有大量的培训数据可用,这是不切实际的,因为人工标签的成本是非常昂贵的。为了解决这些问题,Zhao等人[26]提出了一种成本敏感的在线主动学习(CSOAL)的新颖框架,该框架仅查询小部分训练数据进行标记,并直接优化了两种成本敏感的措施来解决班级不平衡问题。Kumar等人[27]基于机器学习分类算法,提出了一种用于检测钓鱼网站的多层模型。过滤器可以通过训练每个层过滤器的阈值来在到达阈值时直接确定网络链接;否则,过滤器会将网络链接留给下一层。
研究中有各种各样的机器学习算法,可以直接在钓鱼网站检测的上下文中使用。由于潜在的培训数据量巨大,因此需要可扩展的算法,这就是为什么在线学习方法在该领域获得了巨大成功的原因。在线主动学习旨在开发一种在线学习算法,用于训练仅在需要时查询传入的未标记网络链接实例的标签的模型[28-29]。Lin等人[30]通过结合CW和PA算法,采用了一种混合在线学习技术。具体而言,CW用于从纯词汇特征中学习,而PA用于从描述性特征中学习。他们认为词法功能可以更有效地检测钓鱼网站,而它们却可以经常更改,而描述性属性则更稳定、更静态。在框架中引入了一种在线学习技术,如果后端内容分析引擎有任何反馈,则可以动态修改过滤模型。减轻了进行基于内容的分析,以及将带宽用于内容检索的负担;并且可以与其他Web安全服务顺利地组合在一起。
然而,机器学习方法存在以下弊端:1)机器学习算法需要大量的数据进行学习训练,然而数据量越大,计算量越大,需要消耗的时间越长,无法满足日益激增的钓鱼网站的实际情况;2)机器学习检测技术需要带有良性和恶意钓鱼网站标签的训练数据,难以获得;3)特征提取对机器学习方法具有至关重要的影响,而特征提取具有极大的难度。
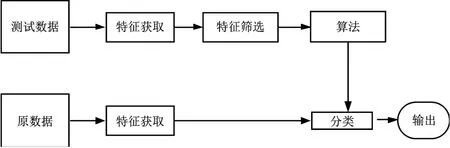
图2 基于机器学习方法检测技术
2 网站的特征提取
训练数据的质量直接影响着机器学习算法的检测效果,而训练数据的质量取决于特征提取的质量。特征提取一般分为特征收集与特征预处理,特征收集阶段是面向工程进行收集有关网络链接的相关信息,从网络链接字符串中获得的功能,其中包括Google PageRank值[31]及搜索结果数[32]、Alexa流量信息[33]、域名信息[34]和WOT声誉值[35]等信息。特征预处理阶段是将有关网络链接的非结构化信息适当地格式化,并转换为数值向量,以便可以被输入到机器学习算法中。例如:数字信息可以原样使用,而词袋模型通常用于表示文本或词汇内容。如今可以将钓鱼网站研究中的特征分为静态特征和动态特征两类,下面将从这两个方面介绍钓鱼网站研究中的特征要素。
2.1 静态特征
静态特征主要来自于网页的静态信息,主要为主机信息特征[36-37]、URL信息特征[38-39]和网页内容特征[40-41]3类。主机信息特征是从主机名的属性中获得的,因此,可以获得多种主机的相关信息,深入网络链接的主机内部获得信息,能够提高特征的有效性,有利于钓鱼网站检测的相关研究,通过学习主机信息特征能够获得主机时间、身份和位置等相关信息。由于原始的URL数据是字符串,通过对机器学习的学习可以理解其是不可行的,因此必须将数据进行处理以得到有效的信息,此特征是从网络链接数据本身得到的,此类信息即为数据的URL信息特征。网页内容特征即为从网页中的图片、文字、特殊字符和颜色等网页信息中得到所有的信息、JavaScript代码、网页漏洞信息和链接关系等。静态特征具有种类多样、提取方式简单和内容丰富等优点,由于不需要执行,因此这些方法比动态方法更安全。
2.2 动态特征
动态特征主要来自于网页的动态信息,常见的动态特征主要包括跳转关系[42-43]、注册表变化[44-45]、浏览器行为[46-47]和文件变化[48-49]等。动态分析技术包括监视潜在受害者的系统行为,以查找任何异常情况,其中包括监视系统调用序列中的异常行为[50],以及挖掘Internet访问日志数据中的可疑活动[51]。动态特征的提取需要花费较长的时间,动态分析技术有固有的风险,并且难以实现和推广。
3 挑战与展望
目前钓鱼网站检测研究在检测技术和特征提取方面都面临着较大的挑战。以往的研究已经达到了瓶颈期,检测技术方面没有较新、效果更好的技术提出。特征提取固定于静态特征与动态特征的特征提取方式,没有新维度的特征提取方式提出,并且静态特征与动态特征的提取角度也日趋固化,难有新的特征提取角度提出。
基于钓鱼网站检测研究现状,我们从检测技术和网站的特征提取这两个方面对未来发展方向提出展望。
a)开展能够自动地获得钓鱼网站数据的检测研究
针对现存技术受限于硬件条件、实验条件的问题,相关研究使用计算机能够在一定时间内运算的个人构建的数据集居多。未来随着硬件条件、实验条件的改善,开展能够自动地获得钓鱼网站数据的检测研究。将要构建能够随着恶性或良性网络链接的产生自动地更新数据的方式,并得到新的特征信息,自动地学习填充,以达到钓鱼网站检测研究更好的效果。
b)针对钓鱼网站动态特征研究来降低时间复杂度的提取方式
由于动态特征的提取需要花费较长的时间,动态分析技术具有固有的风险。虽然现在的研究补充了特征提取的方法,但都是基于静态特征的研究,未来的研究将要基于钓鱼网站动态特征的自动获取。并且期望能够补充现有的已经固化的动态特征的提取方法,针对钓鱼网站动态特征研究来降低时间复杂度的提取方式,钓鱼网站检测研究将能够达到更好的效果。
4 结束语
随着越来越多的研究者对钓鱼网站检测领域日益渐增的关注,近几年钓鱼网站检测的相关技术发展迅速。钓鱼网站检测研究大致能够概括为检测技术和特征提取两个部分。本文从检测技术和特征提取两个方面总结了现存钓鱼网站检测领域的进展。从黑名单方法和机器学习方法方面对检测技术进行了总结,从静态特征与动态特征方面对特征提取技术进行了总结。同时,本文也介绍了现存检测技术面临的困难,并对未来研究方向进行了展望。
猜你喜欢
好日子(2022年6期)2022-08-17
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
中国信用(2017年5期)2017-05-25
中国信用(2017年4期)2017-05-23
自动化学报(2017年11期)2017-04-04
儿童故事画报(2016年7期)2017-02-08
小学生导刊(低年级)(2016年8期)2016-09-24
小学科学(2015年6期)2015-07-01
小学科学(2015年6期)2015-07-01
