
煤矿井下视频行人检测算法研究
2021-11-17 12:38吴冬梅
计算机仿真 2021年9期
吴冬梅,袁 宵,张 静
(西安科技大学通信与信息工程学院,陕西 西安 710054)
1 引言
长期以来,煤矿井下灯光昏暗,运作的矿车和行人难以分辨,行人时常误入危险区域导致煤矿井下事故频发[1],而目前煤矿井下的监控视频通过人工观察,不能及时发现事故。因此若能在复杂的煤矿井下智能、实时的检测到行人,对矿工的安全保障具有重大意义。
目前常用的行人检测方法[2]仍然是基于计算机视觉。如果在人工确定提取适合的特征之前,对图像进行增强轮廓和细节的预处理,可以提高图像质量。文献[3]提出了基于Retinex的增强算法,是通过改变低频与高频信号在原图中占据的比例实现图像增强,但是该算法复杂、运行速度慢。文献[4]提出用改进的直方图均衡化算法优化原始图像的低频分量,用改进的Retinex算法估计和放大高频分量达到增强效果,但存在噪声且效率低的问题。文献[5]提出的基于安全帽检测的煤矿井下人员目标检测方法,针对四种检测场景,检测效率快,但平均准确率低。而文献[6]提出的基于HOG+SVM的矿工检测算法,检测精度虽有所提升,但处理实时的视频图像很难满足要求。基于此,本文提出一种改进的反锐化掩模算法以及多特征融合的方法,先对图像增强,然后对提取的特征进行降维、融合两种特征,最后多次训练分类器并对参数调优得到最佳检测模型。
2 改进的反锐化掩模算法
煤矿井下光照分布不均的特殊环境使得所获取的煤矿井下视频清晰度不高,因而煤矿井下的视频行人检测效率也不能得到提升。传统的直方图均衡化算法会扩增原始图像中较亮的区域;Retinex算法能够抑制原始图像中亮度较高的区域,但经过Retinex算法处理后图像整体的亮度和对比度较低;经过线性UM算法处理过的图像的清晰度会提升,但是整体增强效果达不到后续的处理要求。为了使得人物目标轮廓更加明显,图像质量更高,本文针对上述算法处理非均匀光照图像[7]的不足提出了改进的反锐化掩膜算法。
2.1 双边滤波
双边滤波是常用的非线性滤波方法,该方法不仅能有效抑制噪声,而且能对图像的边缘信息很好的保留。
假设f(x,y)代表原始图像,(x,y)表示某个像素点的坐标,g(x,y)表示点(x,y)经过双边滤波处理后的结果,如式(1)

(1)
式(1)中S(x,y)代表以点(x,y)为中心,邻域大小为(2N+1)×(2N+1);等号右边表示邻域S(x,y)内所有像素值的加权平均;ω(i,j)为加权系数, 如式(2)所示
ω(i,j)

(2)
在一幅图像中,波动越小的区域,邻域间像素值相差越小,对于波动较大的区域,原始图像的灰度值可以用邻域内的相似像素的均值替代。
2.2 自适应增益
传统的线性UM算法对高频图像的放大是使用确定的系数,对于整幅图像而言,使用同一个确定的系数放大图像,不能使图像均匀增强,因此对高频图像的放大,本文采用非线性函数处理。
首先,用线性函数把高频信号转换为另一个不同的信号,如式(3)所示
c=2d-1
(3)
其中,d表示高频信号,c为经过线性转换处理的信号。
其次,假定信号c与增益γ有一定的函数关系
γ(c)=α+β·exp(-|c|η)
(4)
当c分别取0和1时,可得出参数α和β,如式(5)和(6)所示
α=γmax-β
(5)
β=(γmax-γmin)/(1-exp(-1))
(6)
参数α,β确定之后就可以确定增益γ的函数表达式。
2.3 基于双边滤波的自适应增益反锐化掩膜
经过线性UM处理的图像的边缘信息不能达到很好的保留效果,并且对整幅图像的放大采用同一个系数,达不到最好的图像增强目的。因此,本文提出基于双边滤波的自适应增益反锐化掩膜算法,该算法能对原始图像的低频分量很好的保留,也可以对图像的高频分量进行增强。假设用F表示原始图像,L表示低频图像用,H表示高频图像,本文提出的改进算法可通过以下6个步骤实现:
1)颜色空间转换。
2)对原始图像F经过双边滤波得到L;
3)F-L=H;
4)自适应增益由H得到并放大;
5)增强图像是由F与放大后的H相加确定;
6)将增强之后的图变化到彩色空间。
本文对大量受光不均的矿井图像进行增强实验,为了验证本文提出改进的反锐化掩模算法的增强效果,下面将与直方图均衡化(HE)、单尺度Retine算法(SSR)、多尺度Retinex(MSR)算法、线性UM算法进行比较,图像增强后的处理结果如图1所示。

图1 五种算法对矿井原始图像的增强效果图
从上述结果可以看出原图经过直方图均衡化之后,亮的区域更亮,暗的区域更暗;经过SSR算法增强后,对原图中亮度较高的区域进行了抑制,但图像平均亮度低;通过MSR增强算法处理后,相比于SSR算法提高了图像的亮度,但是行人目标与背景对比度低,人物轮廓不明显;线性UM算法处理图像后,图像中灯光亮的区域没有扩大,但图像整体模糊;经过本文增强算法处理后,提升了图像亮度、对比度,弱化了原始图像中矿灯亮的区域且没有扩增,而且更好地突出了人形目标。
下面将对比传统的增强算法与本文提出的改进算法。其中,图像包含的信息可以体现在信息熵;图像对比度体现在标准差;图像的清晰程度体现平均梯度。统计结果如表1所示。
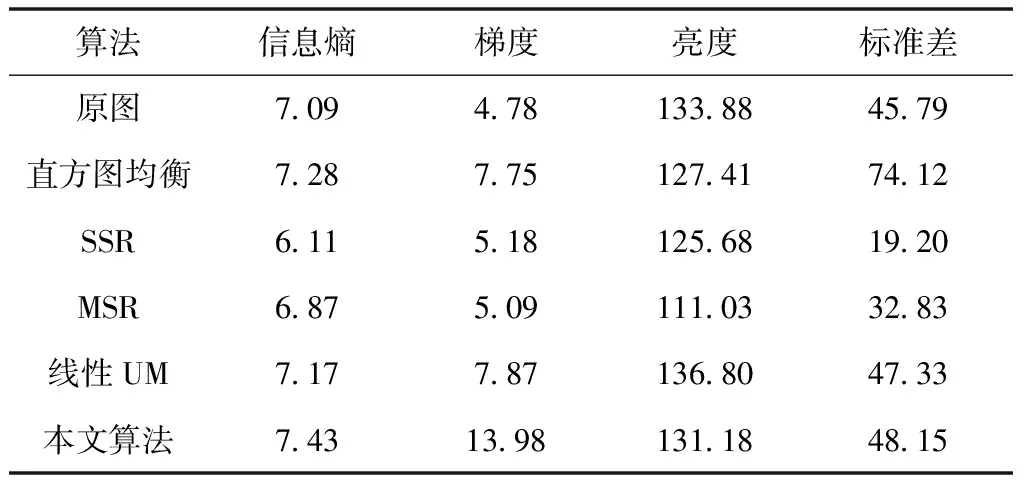
表1 五种算法对矿井原始图像增强处理的指标对比
从表1可知,MSR和线性UM对图像的增强效果比较明显,将本文改进算法与上述两种算法进行对比,标准差分别提高了46.6%和1.8%;信息熵分别提高了8.3%和3.4%;平均梯度是MSR算法的2.7倍,是线性UM算法的1.8倍,虽然直方图均衡化算法处理图像后标准差高于本文提出的改进算法,但从图像来看,原始图像中灯光亮的区域增大,而本文提出的改进算法避免了这种情况,而且行人目标更突出,可以确定本文提出的改进算法效果好。
3 基于HOG特征与LBP特征融合的煤矿井下行人检测
3.1 特征提取及降维
HOG特征是利用边缘梯度对一幅图像中目标的形状、轮廓等进行描述。用于行人检测时,若人体有部分轻微的动作变化,检测结果不发生改变。对于一幅尺寸为64×128的图像I,取8×8大小的Cell,16×16大小的Block,滑动窗口的移动间隔为8。通过灰度化、归一化、梯度的模值和角度构建的方向直方图得到图像的HOG特征。
由于提取HOG特征时包含了大量冗余信息,而在分类器训练过程中,随着特征维数的不断增加,匹配的过程就越复杂,系统的运行速率就越慢,所以为了提高检测速度,必须对原始的HOG特征进行降维[8],通过PCA将高纬度的特征映射至低纬度,保留高纬度数据的一些重要特征,去除噪声和不重要的特征。
LBP是表示图像纹理信息的特征描述符,对光照突变和复杂的背景稳定性高。获取图像的LBP特征的原理是选取(xc,yc)作为图像中心,邻域区域S的大小为3×3,且把S内除点(xc,yc)以外的8个像素点依次与阈值T值比较。超过T的为1,小于T的为0。
3.2 特征融合及分类
特征融合既能提取出多种特征中具有代表性的信息,又能去除掉大多数不重要的信息,提高了运行效率。而HOG特征可以代表图像的边缘信息,LBP特征对背景复杂和光照变化剧烈具有稳定性,所以本文选择串行融合HOG特征与LBP特征[9]。
假设特征空间A和B构成样本空间Ω,选择其中一个样本ε(ε∈Ω)分别对应A特征空间的α(α∈A)特征向量、B特征空间的β(β∈B)特征向量,经过串联融合两种特征,可以用γ=(α,β)表示特征矩阵。若有m维的α,n维的β,则(m+n)就代表串联融合特征之后的维度。
SVM分类器模型训练[10]的好坏决定了最终的分类效果。本文分类器的训练重点在于困难样本的挖掘,首先针对样本大小不一进行归一化处理,其次根据提取的融合之后的HOG-LBP特征用于初始分类器模型的训练,然后利用第一次训练完成的分类器在负样本上再次检测,将错误的检测结果归纳为困难样本,最后将正样本、负样本、困难样本输入SVM分类器进行训练,对分类器参数进行调优,得到最终需要的分类器模型。
4 实验结果分析
本文算法利用Vision Studio2013和OpenCV3.1.0配置编程实现,测试环境为Intel(R) Core(TM) i3-4030U,CPU频率为1.90GHz,内存4GB。
4.1 基于INRIA行人数据库检测结果分析
INRIA数据库是现在最常用的标准行人数据库,为了验证本文提出的融合HOG与LBP特征后分类器的检测效果,先在INRIA行人数据库上进行测试,结果如图2所示。

图2 INRIA行人数据库检测结果
从图2可以看出对于单个行人、多个行人、不同姿态多种情况下的人形目标都能够准确检测。
下面是提取融合后的特征与只提取单一的HOG特征或LBP特征的统计结果,分类器的检测效果将通过误检率、漏检率、查准率、查全率来评价,其中正样本有132张,负样本有110张,统计结果如表2所示

表2 三种特征的检测率
从表2中的结果可以看出,相比于提取单一特征与提取融合后的特征训练的分类器,融合后的特征查全率为96%,检测效果更好。
4.2 基于煤矿井下视频行人检测结果分析
为了验证本文所提出的改进算法在煤矿井下复杂环境中的检测效果,本文选取了3段不同场景的视频。测试视频1是模拟视频,选择的是室外场景光线较暗的情况,用同时出现的行人与车辆表示井下的矿工和矿车。测试视频2是背景环境更复杂的真实井下监控视频,有矿工以及运作的矿车和照明的矿灯两种干扰。测试视频3是自行拍摄的煤矿井下真实环境,其中包括矿工、矿灯两个目标,检测的结果如图3所示。

图3 3段测试视频检测结果
本文三段视频经过增强处理后的结果如表3所示。

表3 3段视频的检测率
将本文的行人检测算法与文献[5]和文献[6]的算法比较,其中文献[5]的四种场景平均检测率为84.1%,误检率为11%,文献[6]中矿工检测的准确率为86.7%,误检率为9.56%。通过对比,本文算法对测试视频1和3的检测率均高于文献[5]和文献[6]。视频2的准确率虽低于文献[5]和[6],但是测试视频2的干扰更多、背景环境更复杂。而本文行人检测算法误检率在三段测试中最高为7.3%,相比于文献[5]的11.49%和文献[6]的9.56%,误检率更低。因此本文的检测算法效果更好,且抗干扰能力更强。
5 结论
目前,行人检测针对静态图像的检测结果都不错,但由于视频存在背景复杂、相机晃动等不稳定因素,导致难以实现实时的视频行人检测,同时提取的特征维度过高也会影响检测的时效性,而且针对煤矿井下视频环境复杂,行人检测的难度更大且准确率更低。基于此,本文提出改进的 HOG-LBP 特征融合进行行人检测的方法,在特征融合之前,利用改进的UM算法对其进行图像增强,增强后的图像的清晰度更高、人形目标的轮廓更突出,融合特征之后送入分类器多次训练得到最佳模型进行煤矿井下的行人检测时准确率得到一定的提升。但本文算法没有考虑多个行人互相遮挡的问题,因此在下一步的研究中,主要考虑解决煤矿井下行人遮挡的问题。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
速读·下旬(2021年11期)2021-10-12
意林(2021年5期)2021-04-18
计算机系统应用(2021年2期)2021-02-23
大东方(2019年12期)2019-10-20
扬子江(2019年1期)2019-03-08
科学与财富(2017年22期)2017-09-10
软件导刊(2017年4期)2017-06-20
小天使·一年级语数英综合(2017年6期)2017-06-07
