
基于多维特征和候选项的易混手写英文识别
2021-11-20 01:57付鹏斌宋冬雪杨惠荣
计算机工程与设计 2021年11期
付鹏斌,宋冬雪,杨惠荣
(北京工业大学 信息学部,北京 100124)
0 引 言
手写英文字符识别是光学字符识别(optical character recognition,OCR)的一个重要分支,研究人员提出了多种方法[1-5]进行手写英文字符的识别。近年来,为了提高易混手写字符的识别准确率,现有的研究方法可以分为两类:以特征提取[6-8]为中心,以神经网络[9-11]为中心。以特征提取为中心的方法旨在通过找到字符高质量的特征并加强特征的表征能力来进行易混字符的区分。Inkeaw等[12]提出了一种利用潜在表征区域的梯度特征来增强图像特征的识别方法。Jangid等[13]提出了一种基于由类间方差和类内方差之比定义的统计度量,增强字符的可分辨部分的特征元素以进行判定。这类方式虽然能够对字符的形态特点进行直观性描述,但是对于产生形变的字符识别准确率并不高,缺乏鲁棒性。另一方面,以神经网络为中心的方法专注于开发一个复杂且高度区分的分类器,以更好地区分易混字符。Shao等[14]提出了一种基于多实例学习的易混字符识别方法。Wang等[15]提出使用层次化结构的卷积神经网络来区分易混字符。尽管这些研究中提出的识别分类器在易混字符识别方面表现良好,但由于分类器的复杂度较高,通常需要大量的样本进行训练,耗费较多时间。
本文通过分析易混字符相似区域的特点和字符间构成单词的相关性,提出一种结合多维特征和候选项区分易混手写英文字符的识别方法,进一步加强字符识别结果的可信度,有效提高了易混手写英文字符的识别准确率。
1 基于CNN的字符识别
1.1 数据准备
本文基于已公开的NIST、Chars74k数据集上扩充收集了包含不同年龄段作者的手写英文数据,并以此为基础,经过腐蚀、膨胀、加噪等一系列图像形变操作算法,形成了共38类包含大小写的手写英文字符数据集,其中将大小写书写形式相同的字符,合并成了同一类字符,这样的字符为 {C/c,F/f,K/k,L/l,M/m,O/o,P/p,S/s,U/u,V/v,W/w,X/x,Y/y,Z/z}。 最终形成了每类手写英文字符图像约10 000张,共计373 352张的手写英文字符数据集。
1.2 字符识别
文中所用的手写英文字符识别网络是基于CNN构建的网络模型,网络结构为两个卷积层、两个池化层和两个全连接层。
本文采用的网络模型如图1所示,其中输入的是28×28的图像,C1和C3层代表卷积层,S2和S4是池化层,F5和F6 是全连接层。整个网络第一层卷积设定有32个5×5大小的滤波器,从而得到32个28×28特征图。第二层池化层设定池化的大小为2×2,经过这层池化操作后,图像的长和宽都缩小一半,从28×28变到了14×14。再经过第三层的卷积操作,特征图数量变成了64。经过第四层又一个2×2的池化层后得到了64个7×7大小的特征图之后进入全连接层。选取了两个全连接层,第一个全连接层设置的神经元的个数是1024个,相当于把7×7×64的特征图转化成一个1024的列向量,第二个全连接层的神经元个数是38,即文中确定的英文字符分类数。

图1 CNN识别模型
1.3 实验测试及分析
为验证使用模型的有效性,实验统计了该模型对手写英文字符的识别准确率。将数据准备阶段构建的手写英文字符数据集,经过筛选、归一化后,每类字符的数量按照4∶1的比例划分为训练集和测试集。实验结果如图2和图3 所示,手写英文字符识别在测试集上的平均识别准确率是96.52%。

图2 字符“A-K/k”的识别准确率

图3 字符“L/l-Z/z”的识别准确率
由图2和图3可知,其中“a”,“C/c”、“D”、“g”、“I”、“q”、“r”、“V/v”等字符识别准确率均低于95%,并且“I”和“r”的识别准确率低于92%。与整体字符的平均识别准确率相比,存在一定的偏差。通过分析其识别结果发现,主要误差造成的原因是易混字符的误识。由于英文字符笔画简单,某些字符的字形相差不大,基于神经网络的字符识别算法,字符的特征提取蕴含在模型训练过程中,所以在初次识别时,由于易混字符的特征相似,会有较大概率出现分类错误的现象。因此,对于易混字符,有必要根据其相似区域找到差异性从而进行针对化的识别,弥补识别的不足。
2 易混字符的识别
2.1 易混字符类别划分
通过卷积神经网络得到的特征向量以SoftMax回归的形式输出手写字符归属于每一类的概率大小。输入一个手写字符图像,其输出向量在每个类别的概率大小反映该样本识别为该类别的置信度。一般置信度最大的字符就是识别结果。定义置信度最大的识别概率为第一识别概率pi,1, 依次类推,第二识别概率pi,2, 第三识别概率pi,3…pi,n。 设待识别字符图像经过卷积神经网络识别后输出的第一识别概率pi,1代表的字符为初步识别结果Ri,待识别字符对应的正确识别结果为Ci,统计易混字符类别的算法如下:
步骤1 输入:字符初步识别结果Ri,字符正确识别结果Ci;
步骤2 统计识别过程中与正确识别结果Ci比较,不等于Ci的Ri分别出现的次数,用F(Ci,Ri) 表示;
步骤3 计算混淆概率P(Ri|Ci)
(1)
F(Ci) 表示所有识别结果出现的次数;
步骤4 对所有混淆概率根据P(Ri|Ci) 的大小进行排序;
步骤5 取排序后的前N个Ri代表字符作为Ci的易混字符;
步骤6 统计各类字符中包含易混字符的公共部分,定义为同一类易混字符。
根据以上算法进行统计,将易混字符划分为以下6类:
(1)a,Q,q,g
(2)b,D,o
(3)c,l
(4)I,l,i,J,j,z
(5)n,h
(6)u,v,r,y
通过分析造成字符易混的影响因素,又可将以上类别细分为表1所示的易混字符对。

表1 易混字符类别
2.2 易混字符的判定
对字符经过卷积神经网络进行初步识别之后,设定判断识别结果是否可信的条件如下
pi,1>α&&pi,2<β&&pi,3<γ
(2)
即需要同时满足第一识别概率大于阈值α,第二识别概率小于阈值β,第三识别概率小于阈值γ的条件,这样才认为该字符的识别结果可取。对大量手写英文字符的识别结果进行分析,通过表2列出的部分因易混字符而造成的误识和其识别概率也可以看出,一般因为易混字符而造成的识别错误,其正确识别结果出现在识别概率排名前三位的字符中。

表2 部分因易混字符而造成的误识结果和识别概率
因此对易混字符的判定可以表示为
pi,1<α&&pi,2>β&&pi,3>γ
(3)
通过实验计算后得出,当α=0.9,β=0.1,γ=0.01时,若字符的识别概率满足式(3),并且前三位识别字符中包含易混字符中的某一类,则认为该字符为易混字符。
2.3 多维特征提取
对于易混字符结合特征对其识别,关键在于提取稳定的、最能体现字符间差异的特征。因此,在确定是易混字符造成的误识之后,首先需要确定易混字符的区分区域,在区分区域的基础上进行多维特征的提取。通过对大量易混字符样本进行观察和分析,定义了以下字符的多维特征,具体定义如下:
定义1 链码特征
链码是通过给定单位长度的序列来描述图像轮廓信息的一种特征,如图4所示,本文所用是八方向链码表示。对一个连通的像素序列来说,其轮廓曲线的链码可以定义为 {a0…ai…an}, 其中ai∈{0,1,2,3,4,5,6,7},n表示图像矩阵化后的点集数。如图5(a)和5图(b)所示,绘制字符“D”和“O”的外轮廓链码图,在图中按照箭头所指方向开始进行编码。对于手写字符“D”和“O”来说,其显著的区别在于字符左侧轮廓的变化趋势,字符“D”的相对趋势变化一直为第三象限的方向,而字符“O”则存在第三到第四象限的方向变化趋势。
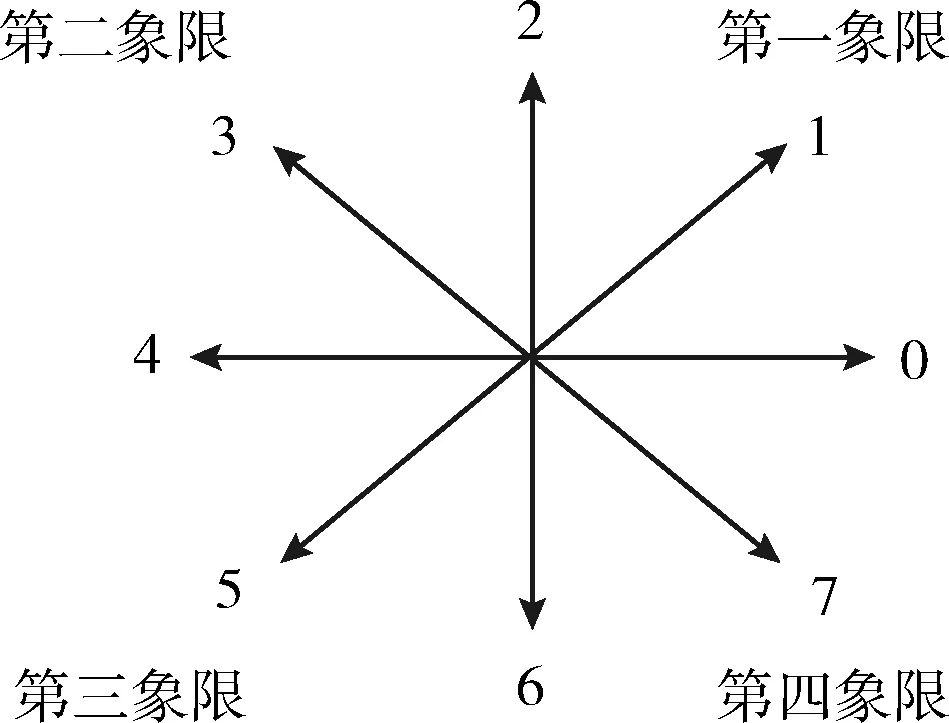
图4 链码方向码表示

图5 链码特征
定义2 横纵向交截数特征
在矩阵化的图片上,通过在每一行插入水平射线和在每一列上插入垂直射线,射线上像素的黑白交替变化次数即为横纵向交截数特征。从图6可以观察到,对不同手写英文字符来说,在不同区域位置的横纵向交截数会有所不同。例如字符“v”和“y”,从两个字符的高度起点开始,从上往下到字符高度终点,每行进行水平射线穿插,字符“v”水平射线穿插出来的横向交截数是2的行数占整个图形总行数的比例一定大于字符“y”的比例。

图6 横纵向交截特征
定义3 点特征
对于字符图像来说,是否存在交叉点是字符结构中最基本、最易见的特征。由于英文字符是由笔画连接或交叉而构成的,因此可以根据字符的连通性确定其点特征。通常点特征的计算需要依赖细化算法得到。
用式(4)逐个计算细化图中各目标像素对应的t值
(4)
其中,Xi为当前像素P周围8邻域中的像素值,且P=X8,t为二值图中相邻两元素值差的绝对值之和。当t的值分别为2、6、8时,则表明像素点P分别对应于细化二值图的端点、三叉点、四叉点。结合字符本身来说,端点就是指笔画(或笔段)的起点,三叉点是指从该点发出3条笔画的点,四叉点是指从该点发出4条笔画的点。手写字符“a”只有端点和三叉点存在,而字符“Q”中则存在四叉点。
定义4 几何特征
本文选取字符图像的宽高比,连通域个数作为易混字符的几何特征。宽高比即从字符最小外包矩形图像中计算得到的字符的宽度和高度的比值。连通域个数为图像中具有连通性的区域个数。图像中如果两个像素点邻接,则这两点彼此连通。所有彼此连通的点形成的一个区域,该区域为具有连通性的区域。
2.4 推荐候选项
在实际生活中,英文字符的出现形式是以单词为基本构成形式而应用,某些易混字符单从个体形态来看具有的差异性较小,但根据其在构成的单词之间则会有不同的组成。因此为了进一步提高识别结果的可信度,提出了一种结合字符合并形成候选项单词的识别算法。具体流程如图7所示。

图7 推荐候选项算法流程
为了研究单词的使用情况及提取单词中字符间的连接规律,本文主要针对高中阶段学生的学习类型建立了英文语料库。语料库中包含1000余篇高中英语范文、中国英语学习者语料库(CLEC)和英国国家语料库,其中去除了语料库中所有的标点符号。
确定易混字符后,它的前三位识别概率对应的字符表示为 {ri,1,ri,2,ri,3}, 将与该易混字符相连形成单词的其它字符的识别结果表示为 {R1…Ri…Rn}, 结合单词间字符的组成顺序建立候选项单词 {Word1…Wordi…Wordn},Wordi={R1,R2…r…Rn}, 其中r∈{ri,1,ri,2,ri,3}。
因为易混字符误识的原因,往往会造成单词的拼写错误。为了找到离错误单词相似程度最高的正确单词,即字符正确识别结果。可以利用单词的编辑距离来衡量候选项单词与语料库中单词的相似程度,根据式(5)计算单词间的编辑距离
dist(word,Tword)=sub(word,Tword)
(5)
其中,语料库表示为V,语料库中单词为Tword,Tword∈V,word∈{Word1…Wordi…Wordn},dist(word,Tword) 代表候选项单词与单词语料库中单词的编辑距离,sub(word,Tword) 代表候选项单词与单词语料库中单词比较,进行替换操作所需代价。
计算编辑距离的伪代码如下:
输入:word[0…m],Tword[0…n]; 0…m和0…n代表组成单词的字符
输出:编辑距离dist
Begin
//dist[i,j] 表示word[0…i] 和Tword[0…j] 这两个字串的编辑距离
Intdist[0…m,0…n]
Fori←0 TomDo:
dist[i,0]=i
Forj←0 TonDo
dist[0,j]=j
Fori←1 TomDo
Forj←1 TonDo
Intcost=(word[i]= =Tword[j]?0∶1)
dist[i,j]=min(dist[i-1,j-1]+cost)
Returndist[m,n]
通过已有研究发现,假设各个单词的使用频率相等,当两个或两个以上的字符被替换时单词的成词率很低。因此基于贝叶斯理论从概率的角度确定单词的正确输出,将需要计算概率的单词集合限制在与候选单词编辑距离为1的范围内。
假设与候选项单词word编辑距离为1范围内单词Tword构成的集合为S={S1…Si…Sn}, 求Si∈S使得P(Si|word) 最大,根据贝叶斯公式可得到式(6)
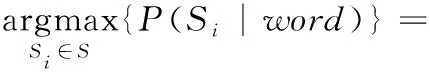
(6)
对于所有的Si∈S, 出现候选项单词的概率都是一样的,即P(word)都相等,因此近一步推导得式(7)
(7)
其中,P(Si) 表示语料库中单词Si出现概率,P(word|Si) 表示因为易混字符误识成word的概率。将二者乘积最大的语料库中单词Si挑选出来作为推荐候选项单词,将其中易混字符对应的字符作为识别结果。
2.5 结合多维特征和推荐候选项
对于待识别单词中出现的易混字符,利用上文定义的多维特征去除图像中的冗余属性,得到了不同类别的易混字符的识别规则,分类器根据其类别信息,查找对应的算法,通过计算从而得到识别结果。再结合推荐候选项,进一步加强了易混字符的识别可信度。整体识别算法如下:
步骤1 输入:易混字符图像image
步骤2 利用CNN识别算法,得到字符识别概率 {pi,1,pi,2,pi,3} 以及前三位识别字符 {ri,1,ri,2,ri,3};
步骤3 根据识别概率和前三位识别字符通过2.2节的算法确定是否为易混字符和其所属的易混字符类别;
步骤4 确定不同类别易混字符的区分区域 {xi,yi→xj,yj}, 进行记录;
步骤5 根据造成易混字符的影响因素的不同,分别选择字符的多维特征组;定义SFc表示特征组,FNc=(xi,yi→xj,yj) 表示为字符某段笔画的链码序列,LNc为横向交截数,VNc为纵向交截数,Bc=(BCc,BPc) 代表交叉点的数目和位置,宽高比WH,连通域个数CON;
步骤6 计算image的多维特征,对标记的区域结合字符形态特征,进行识别;若属于字符笔画结构相似造成的易混字符,SFc=(LNc,VNc,FNc,WH); 若属于笔画位置不同,SFc=(Bc,FNc,CON); 若属于笔画长度不同,SFc=(WH,LNc,VNc); 若属于笔画交叉位置不同,SFc=(Bc); 根据SFc获得识别结果Result1;否则拒识;
步骤7 对于字符结构相似字符,则还需要结合候选项单词进行识别。根据2.4节算法动态计算出与单词语料库中单词的编辑距离dist;若dist=0,则该候选项单词为推荐候选项单词,该推荐候选项单词中对应的易混字符结果为识别结果Result2;若dist>0,根据贝叶斯理论计算概率乘积最大的推荐候选项单词中的字符作为识别结果Result2;
步骤8 获得易混字符最终识别结果Result;若通过多维特征和推荐候选项算法计算得到的结果Result1=Result2, 则Result=Result1=Result2; 若 (Result1!=Result2&&dist=0),Result=Result2; 若 (Result1!=Result2&&dist=1), 并且属于由笔画相似造成的不同,Result=Result2; 否则Result=Result1;
步骤9 输出易混字符识别结果Result;
3 实验与分析
通过对易混字符识别处理前后的性能进行实验统计,并将字符的识别准确率作为性能评价指标,定义如下
(8)
其中,P为字符的识别准确率,CN为字符识别正确的总数,FN字符识别错误的总数。
在1.3节收集的实验数据的基础上,对单字符识别加上了本文算法再识别后,由图8和图9可以观察到,手写英文字符的平均识别准确率从96.52%提升到了98.67%,其中易混字符的识别准确率均有了明显提升。

图8 利用本文算法后字符“A-K/k”的识别准确率

图9 利用本文算法后字符“L/l-Z/z”的识别准确率
为了验证易混字符结合多维特征和候选项的识别准确率,收集了来自多名作者书写的手写英文单词,这些单词选择了在不考虑图像质量,单词中每个字符均能裁切为完整且独立字符的影响下,其中每个单词包含至少一个因为易混字符而造成的误识,合计600个单词。在已确定易混字符所属类别和其所属单词的情况下,进行实验结果如图10 所示:其中利用多维特征进行易混字符识别的平均准确率为70.85%,加上推荐候选项后平均准确率为78.03%。
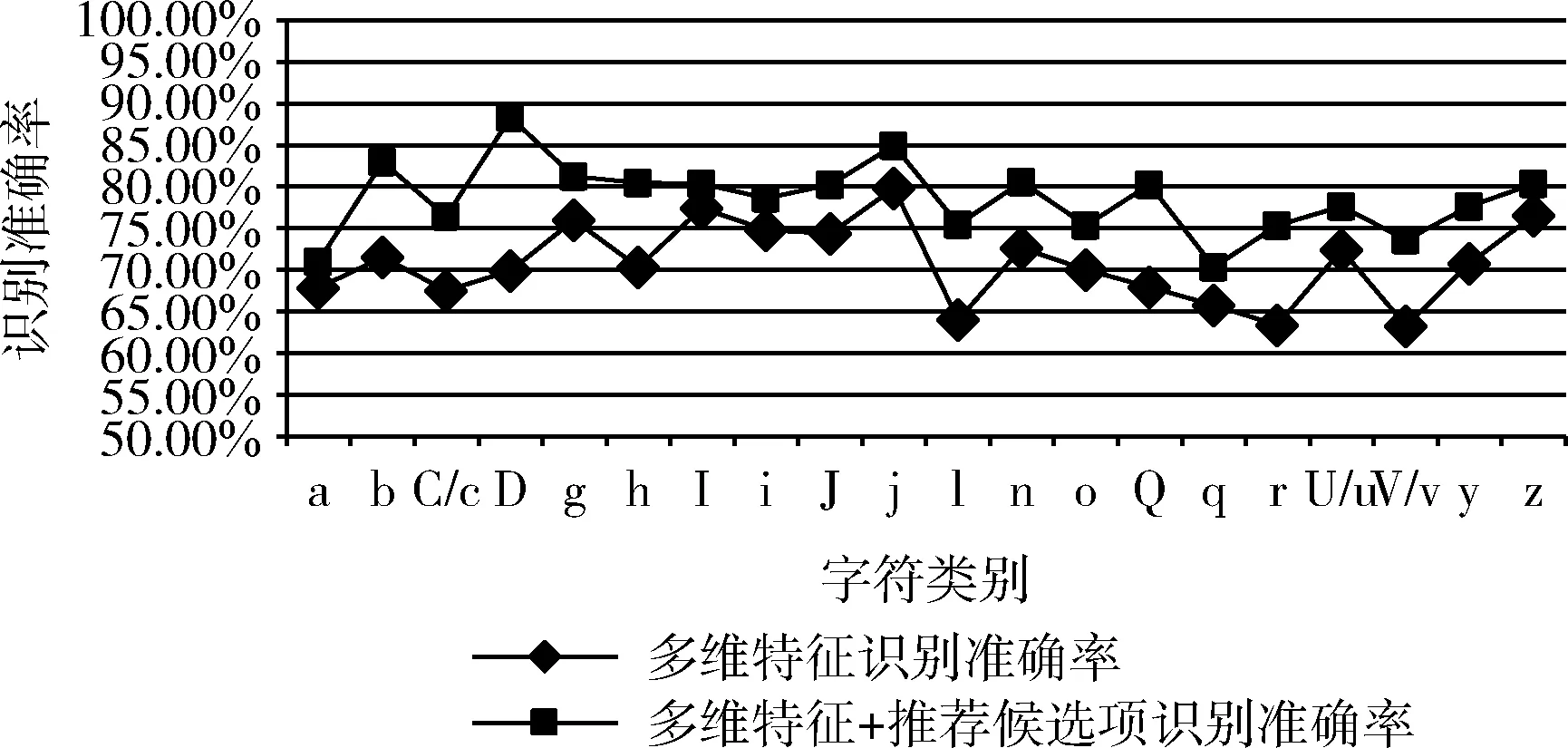
图10 利用本文算法的易混字符识别准确率
4 结束语
针对手写英文字符识别中易混字符造成的识别错误,在神经网络初步识别的基础上,提出了一种结合多维特征和候选项的识别算法。通过对大量易混字符进行识别实验表明,该方法能够较好地识别易混字符,并提高了手写英文字符的整体识别准确率,从而验证了该方法的可行性及正确性。根据易混字符在整体相似,局部差异的特点,对它们之间的细微差异信息进行精准识别,解决了采用特征输入神经网络时,由于选择特征的局限性造成的误识。同时为应用到其它语言的易混手写字符识别提供了思路。
猜你喜欢
故事作文·低年级(2021年12期)2021-12-21
作文成功之路·小学版(2020年7期)2020-08-24
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
电子制作(2018年18期)2018-11-14
成都信息工程大学学报(2017年3期)2017-11-09
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
自动化学报(2016年8期)2016-04-16
