
基于RBF神经网络的辛烷值损失预测模型
2021-11-22 08:14楚庆玲平振东于明加
物联网技术 2021年11期
楚庆玲,平振东,于明加,唐 鑫
(长安大学,陕西 西安 710064)
0 引 言
汽油是目前小型汽车使用最多的燃料,汽车尾气排放对空气污染尤为严重。我国也高度重视汽车尾气排放问题[1]。汽油的清洁对于环境保护尤为重要。其中,烯烃是汽油中的高辛烷值组分,辛烷值是交通工具所使用的燃料抵抗震爆的指标。为解决车用汽油调和问题,在尽可能保持汽油辛烷值的同时,降低汽油中的硫和烯烃含量,为应对国Ⅵ车用汽油标准问题提供一定的指导[2]。
机器学习的迅速发展为建立学习模型提供了许多有效的算法[3-10]。周小伟等人[3]采用多元线性回归和BP神经网络建立了复杂反映辛烷值的预测模型;经测试,BP神经网络的性能较好。朱晓等人[4]研究了化学物质的结构与性能之间的关系,利用支持向量机算法建立了基于分子结构的辛烷值预测模型;结果表明,该模型具有较好的预测能力,为烷烃马达法辛烷值的预测提供了新的思路。孙忠超等人[5]将改进的支持向量机和BP神经网络模型应用于烯烃、烷烃的数据预测,建立了汽油中环烷烃和芳烃辛烷值预测的数学模型。计算结果表明,在样本较少的情况下,BP神经网络的预测性能略优于改进的支持向量机算法;当样本数增加到40个时,两者的性能有所改善,且没有显著差异。
本文采用最大信息系数筛选特征变量,选取代表性好、独立性高的主变量,采用径向基函数(RBF)神经网络预测辛烷值损失,并通过实验验证算法的适用性和可行性。
1 方法模型
1.1 数据介绍
本文采用中石化高桥石化实时数据库和LIMS实验数据库中的数据,收集2017年4月至2020年5月近三年共354个操作位点数。2017年4月至2019年9月,数据采集频次为3 min/次,后续时间使用采集频次为6 min/次。原料、产品和催化剂数据来自于LIMS实验数据库,数据时间范围为2017年4月至2020年5月。其中原料及产品的辛烷值是重要的建模变量,该数据采集频次为每周两次。
1.2 数据筛选
原始数据中包含大量的缺省值和异常值。缺省值处理过程中,对于只含有部分时间点的位点,如果数据中残缺部分较多,且无法补充,则删除;若325个样本中位点数据全部为空值,则删除;对于部分数据为空值的位点,用其前后两个小时数据的平均值代替。异常值处理过程中,根据拉依达准则(3σ准则)进行异常值的处理。首先对被测量变量进行等精度测量,得到x1, x2, ..., xn,计算出被测变量的算数平均值x:

以及剩余误差vi:
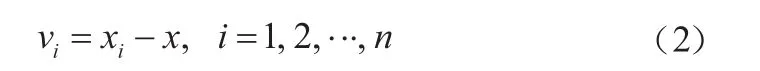
按照贝塞尔公式算出标准误差σ:
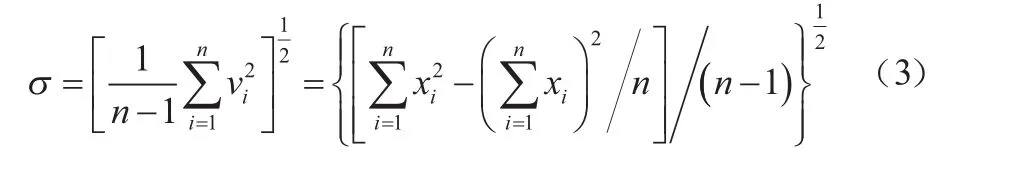
若某个测量值xb的剩余误差vb(1≤b≤n)满足:

最终剔除含有粗大误差值的异常值xb。
1.3 数据降维
在预处理的数据中,两小时内的平均值与目标辛烷值对应,其中出现大量的次要数据与冗余数据,且各个操作变量之间具有高度非线性和相互强耦联的关系,所以本文选用可以处理非线性数据的相关性分析—最大信息系数(MIC),衡量两个变量X和Y之间的关联程度,即线性或非线性的强度,通过相关性的强弱完成数据的降维操作。
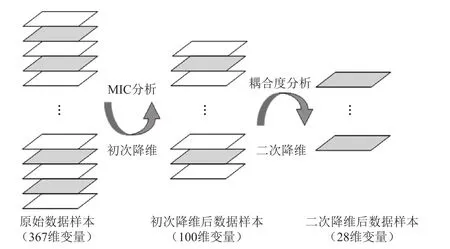
图1 数据降维思路结构图
1.3.1 最大信息系数(MIC)
最大信息系数是一种不需要对数据分布做任何假设的评估变量间函数关系和统计变量的相关性算法[7]。给定有序对数据集D={(xi, yi), i=1, 2, ..., 3},如果将X轴划分出x个格子,Y轴划分为y个格子,得到一个x×y的网格划分G,将数据集D中的点落入到G中格子的比例看作其概率分布D|G[8]。对于一个固定的数据集D,不同的网格划分则得到不同概率分布D|G,给出最大化信息如下:
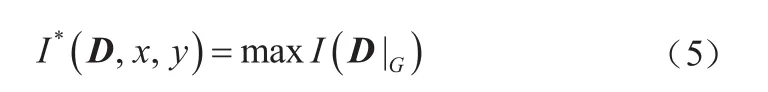
对式(5)进行归一化处理,以便进行不同的维数之间的比较,固定取值区间[0,1],则有:
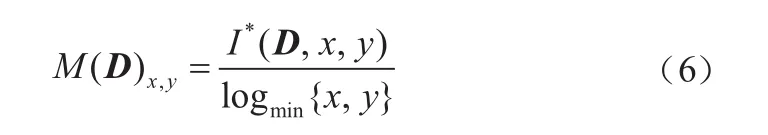
此时,定义数据集D中两个变量x、y的MIC公式如下:

其中B(n)表示需要搜寻的网格数量,一般设定B(n)=n0.6。
1.3.2 数据耦合性
对数据中的354个操作变量分别做MIC分析,得到各个操作变量之间对应的相关性系数。变量之间的相关性系数越大,证明变量之间的相关性越强。重点研究产品性质中硫含量和研究法辛烷值(RON)与其他变量的相关性系数大小关系,将其分别对应的变量进行相关性系数大小的排序,选取相关性系数强度在前100的变量,完成数据的初次降维。
将一次降维后的变量进行重新分析,进行二次筛选,如图2所示。变量二次降维过程重点分析相关性系数相近的操作变量之间是否存在高度耦合的情况。通过分析操作变量之间的相关性系数大小,确定变量之间的耦合程度。若相关性系数较高,则说明数据之间存在高度耦合的情况,需要对其进行分类、筛选,在同一类型的数据中选取具有代表性的操作变量作为主要操作变量。根据这个原则,对一次筛选的100个变量进行相关性耦合度分析;将相关性系数高于0.3作为筛选主要变量的依据,并对数据进行提取,得到最终的结果。

图2 数据降维流程
1.4 辛烷值损失预测模型
输入变量具有高度非线性和强耦合性,因此适合建立的是一个非线性数学模型;又因为实际数据量较大,所以本文选择径向基函数(RBF)神经网络建立辛烷值损失预测模型。
1.4.1 径向基函数(RBF)神经网络
RBF神经网络通常只有三层,包含输入层、径向基函数神经元的隐含层和输出层。图3所示是一个有多输入、单输出的RBF神经网络拓扑结构。

图3 RBF神经网络拓扑图
第一层输入层:将外部数据输入到神经网络中,其节点是由信号源节点组成。设X=(x1, x2, ..., xn)∈Rn,为RBF神经网络的n个输入样本值,即数据降维后的28个主要操作变量,xn=28为RBF神经网络的第n个输入信号矢量。
第二层隐含层:中间层计算输入矢量xi与样本矢量ci的欧式距离,对输入数据做非线性变换。节点的多少直接影响RBF的泛化能力,多数量节点的优点是结果更加准确,但会降低执行效率。令φ(·)为隐含层节点的激活函数,则有:
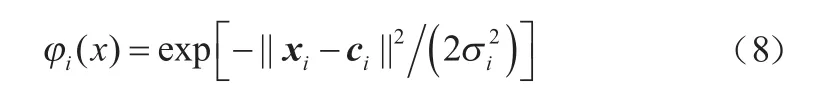
其中:||xi-ci||2为欧氏距离;σi为第i个基函数中心的宽度;ci是第i个节点的中心值。
第三层输出层:这是前两者的线性组合,即从仓储空间到输出层空间的变换是线性的,且有:
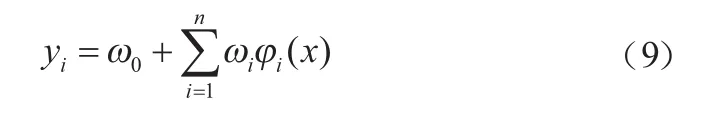
其中:yi为输出层第k个节点的输出;wi为权值。
RBF神经网络辛烷值损失预测模型具体执行步骤如下:
第一步:数据的选择。在上一节样本特征数据挖掘与提取分析中,有354个操作变量。首先分析变量之间的相关性,得到28个主要变量,其中包括17个可操作变量和11个不可操作变量;然后将其作为BP神经网络预测辛烷值损失的输入,输出为产品中的辛烷值。
第二步:数据归一化处理。为提高网络训练的精度和速度,样本输入进模型之前,先根据离差标准化将输入和输出值进行归一化处理,得到最终输出后将数据进行反归一化,便于辛烷值损失的求解。归一化公式为:
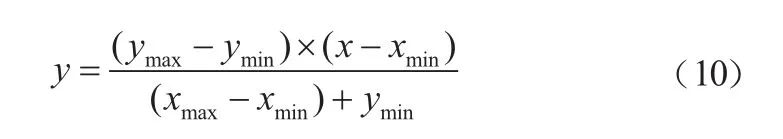
第三步:初始化。确定RBF神经网络输入层的各个变量和隐含层节点数。
第四步:开始训练。将28个主要操作变量的数据输入到RBF神经网络进行训练,计算训练出的结果与实际辛烷值的误差,不断修正,直至达到设定误差范围结束。
第五步:测试RBF神经网络。将25个样本数据输入到训练好的辛烷值损失预测模型中,输出最终结果,与真实值进行拟合。
第六步:计算辛烷值损失,通过模型中预测出的产品辛烷值推导出预测的辛烷值损失:
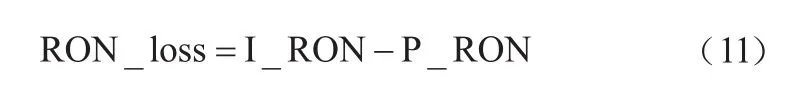
其中:RON_loss表示辛烷值损失;I_RON表示原料中辛烷值;P_RON表示产品中的辛烷值。
1.4.2 辛烷值损失预测模型的评估
为了进一步验证模型的准确性,选取决定系数R2为评价指标,对预测模型进行评估。
统计学里R2表示决定系数,R2的计算方法为:

其中:SSR为回归平方和;SST为总平方和;SSE为残差平方和。
R2的主要特点:(1)决定系数是非负的统计量;(2)取值范围:0≤R2≤1;(3)R2是随机抽样且变动的随机变量,是样本观测值的函数。为此,对可决系数的统计可靠性也应进行检验。
2 结果分析
2.1 数据降维结果分析
原始操作变量经过一次降维和二次降维的处理后,最终确定所有的非操作变量和17个可操作变量,共计28个建模主要变量,对这28个变量进行相关性分析。筛选的建模所需主要变量如下:
(1)原料性质变量:硫含量、辛烷值、饱和烃体积分数、烯烃体积分数、芳烃体积分数、溴值、密度(20 ℃)。
(2)待吸附剂性质变量:待吸附焦炭质量分数、待吸附硫质量分数。
(3)再吸附剂性质变量:再吸附焦炭质量分数、再吸附硫质量分数。
(4)其他变量:反应过滤器压差、精制汽油出装置流量、原料进装置流量累计、-S-ZORB.FT_1204.PV、废氢排放累计流量、火炬气排放累计流量、原料进装置流量、累计1、EH101出口、K-101A排气压力、K-101A进气压力、K-101A进气温度、E203重沸器管程出口凝结水流量、加氢裂化轻石脑油进装置累积流量、汽油产品去气分累积流量、8.0MPa氢气至循环氢压缩机入口、8.0MPa氢气至反吹氢压缩机出口、D101原料缓冲罐压力。
2.2 辛烷值损失预测结果
本文确定模型的输入为上一步确定的28个主要操作变量,输出为辛烷值损失。由于主要操作变量影响产品的辛烷值,它们之间具有较强的相关性,其损失与主要操作变量并无较强的相关性,所以对模型的输出加以更改,将产品辛烷值作为输出变量,再根据原料中的辛烷值与产品中辛烷值的关系,求出辛烷值损失。经过对模型的不断改进,最终得到较为准确的损失预测值。
如图4所示,模型输出为辛烷值损失,决定系数R2=0.242 68。改进模型输出,再次进行预测,如图5所示,将预测的辛烷值与产品辛烷值进行拟合,决定系数R2=0.964 8,数据拟合效果较上一步的模型效果有明显的提升。根据式(11)发现,辛烷值损失的预测效果更加精确。
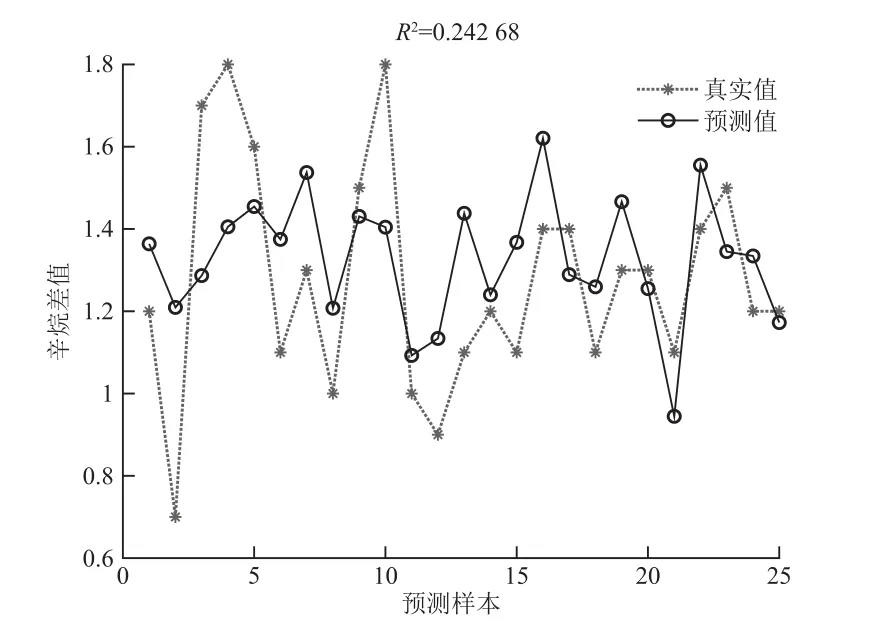
图4 RBF神经网络模型预测产品辛烷值损失

图5 RBF神经网络模型预测产品辛烷值
3 结 语
本文使用中石化高桥石化实时数据库及LIMS实验数据库对辛烷值损失进行预测。首先分析数据特性,处理缺省值和异常值;其次对所有变量进行MIC分析,对变量进行筛选,完成数据一次降维,在此基础上根据数据的强耦合性,对数据进行二次降维,筛选出主要变量作为预测模型的输入;最后,选用RBF神经网络对辛烷值损失进行预测,评估结果表明,曲线拟合精度高,预测结果良好。
猜你喜欢
车主之友(2022年4期)2022-08-27
数学小灵通·3-4年级(2021年5期)2021-07-16
海峡姐妹(2019年12期)2020-01-14
石油炼制与化工(2020年9期)2020-01-05
今日农业(2019年15期)2019-01-03
汽车文摘(2016年8期)2016-12-07
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
计算物理(2014年1期)2014-03-11
燕山大学学报(2014年1期)2014-03-11
