
深度图注意力聚类网络
2021-11-22 04:04苏晓明王海波董建敏
新一代信息技术 2021年18期
苏晓明,斯 琴,王海波,董建敏
(1. 内蒙古工业大学数据科学与应用学院,内蒙古 呼和浩特 010000;2. 内蒙古自治区纪检监察大数据实验室,内蒙古 呼和浩特 010000)
0 引言
聚类是通过学习分析数据的潜在分布,进而将相似的样本划入相同的簇。它是数据科学以及机器学习领域中的一个重要研究方向。传统的聚类算法包括基于划分的K-均值算法[6]、基于层次的 CURE算法[7]、基于概率分布的 EM 算法[8]以及基于密度的DBSCAN算法[9]。但是对于高维数据集,传统的聚类算法很难达到理想的聚类效果,会需要很高的内存消耗。虽然目前也有相关方法对原始高维数据进行降维,但是只能进行线性降维,而不能进行非线性关系映射处理。针对该问题,基于深度学习的聚类算法引发了众多学者的研究兴趣,它使用不同的非线性函数降维,减少噪声数据,提高数据有效性。
深度聚类算法的主要思想是将聚类目标融合进数据表达里面。例如Bo等[3]首次提出了深度聚类网络(Deep Clustering Network,DCN),它采用栈式自动编码器对数据进行非线性降维,使用包含K-均值原理[6]的损失函数去训练模型,使得模型更容易对数据进行K-均值划分。深度嵌入聚类网络(Deep Embedding Clustering,DEC)[4]通过 KL散度损失函数使得自动编码器生成的数据表达更接近聚类的中心,提高了内聚性。改进的深度嵌入聚类网络(Improved Deep Embedding Clustering,IDEC)[5]在 DEC模型的基础上添加了重建损失函数来帮助模型学习到更好的表达。但是这些方法只提取了有效的数据表达,没有考虑到数据结构信息对聚类目标准确性的影响。
针对以上问题,一些基于图结构的聚类算法被广泛使用,Kip等[2]提出了图自动编码器和图变分自编码器,它们使用图卷积网络作为编码器将结构信息和结点特征融合在一起,去学习结点的表征。Yang等[11]设计了一种基于图嵌入的高斯混合变分自动编码器,将局部数据结构添加到深度高斯混合模型中进行聚类。Bo等[1]提出结构化深度聚类网络(Structural Deep Clustering Network,SDCN),将图卷积网络融入聚类网络中,旨在捕捉数据的结构化信息,提升模型聚类性能。但是上述网络缺少针对聚类目标更具判别性的数据表征。
为了解决上述问题,本文提出深度图注意力聚类网络,旨在融合数据结构信息的基础上利用注意力机制的特点,根据预定聚类目标提取数据重要部分,从而提升整个模型的分类准确度。
1 深度图注意力聚类网络
本文提出了一种基于图注意力机制的深度聚类网络。首先利用自动编码器模块分层提取不同表征的全局信息。根据输入数据特点建立图结构数据,计算图结构数据中邻居结点重要度,采用多头图注意力模块提取包含图结构的特征信息,将不同层全局表达与对应图结构信息相连,通过随机梯度下降与反向传播来优化重建损失与基于KL散度聚类损失的加权和,学习网络表征及其簇分配,如下图1所示。
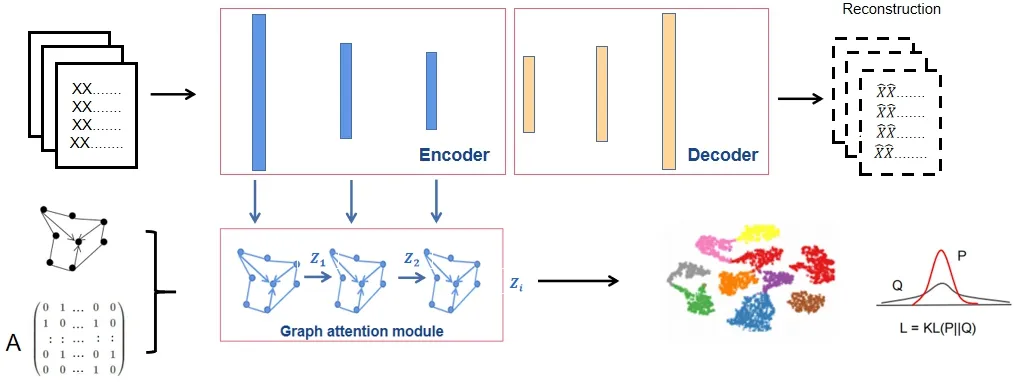
图1 深度图注意力聚类网络示意图Fig.1 diagram of deep attention clustering network
1.1 图数据的构建
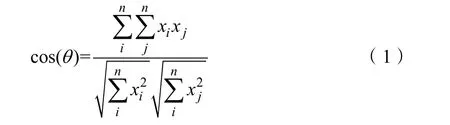
1.2 自动编码器
对于深度聚类来说,有效的数据表达是非常重要的。在这里我们为了保持一般性并使模型能适用于不同的数据格式而选择自动编码器(Autoencoder,AE)[9]提取全局信息。假设有L层编码器,i代表层数。第i层编码器或者解码器学习到的特征表达公式为:
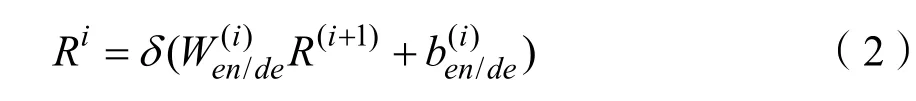
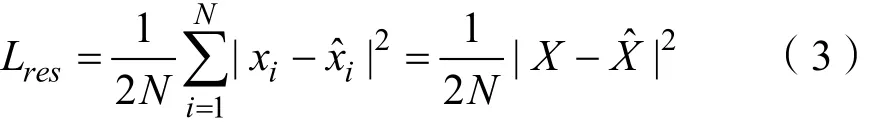
1.3 图注意力机制
这里我们采用的是多头注意力机制思想融入图结构中形成多头图注意力机制[11],选定某一结点,它的每个邻居结点选取K个独立的注意力机制进行计算,K个不同结果采用平均或者拼接方式作用在该结点上。如图2所示,本图演示了三头注意力机制,不同颜色箭头表示不同注意力机制的计算。
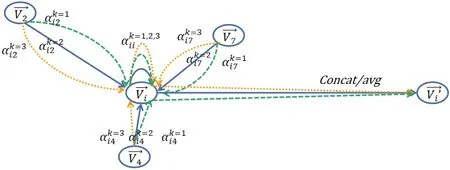
图2 多头注意力机制示意图Fig.2 diagram of multi-head attention mechanism
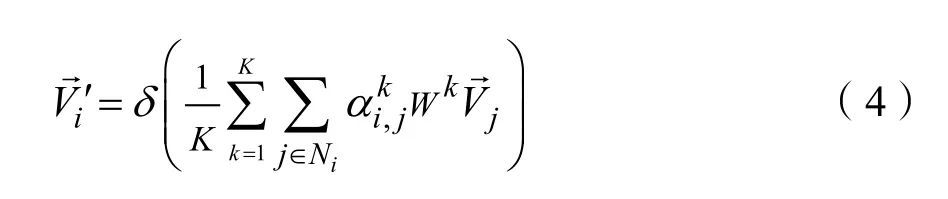
其中Ni表示与结点i相邻的结点,K表示注意力机制的个数,δ表示非线性函数,αi,j表示结点 j与结点i之间的注意力权重系数,其计算公式如(5)所示:
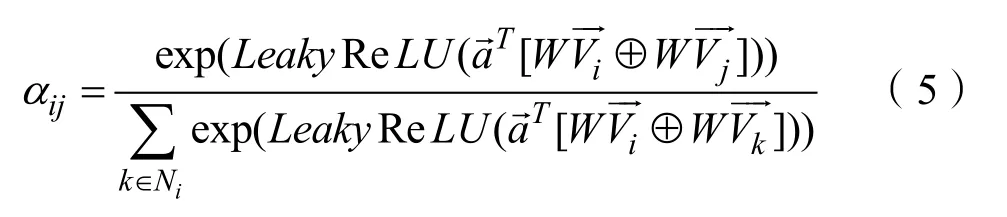
聚合邻居信息时,需要对每个节点的所有邻居的注意力进行归一化。归一化之后的注意力权重才是真正的注意力聚合系数。通过学生 t分布计算图注意力模块输出zi与聚类中心ui的相似度通过高自信度计算聚类频率目标分布pij,运用KL散度优化qij和pij得到聚类的损失函数,如公式(6)所示,通过随机梯度下降与反向传播优化重建损失与基于 KL散度聚类损失的加权和,学习网络表征及其簇分配。
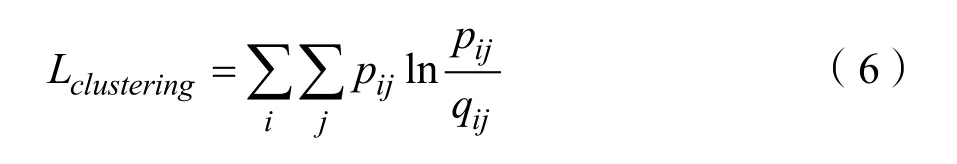
2 实验及结果分析
本文实验环境如下:
操作系统为Ubuntu1804。
硬件平台为 Intel(R) Xeon(R) E5-2640 v4@2.40 GHz CPU,120 GB。
内存,11 GB。
高速缓存,GPU是Nvidia Geforce GTX 1080.编程环境Python3.8。
深度学习框架为Pytorch1.7.1。
2.1 数据集介绍
我们的模型在六种数据集上进行了评估,其中HHAR包含来自智能手机和手表的10 299个传感器记录。所有样本分成6类:骑自行车、坐、站立、行走、上楼梯和楼梯;Reuters是一个文本数据集,包含大约 81万标记好的英文新闻故事的分类树,分为企业/工业、政府/社会、市场和经济四类;ACM2是一个描述论文之间关系的数据集,包含数据库、无线通信和数据挖掘选三类论文;DBLP是作者为结点的数据集。如果两位作者是合作关系,那么他们之间有一个边。作者写作的类别为数据库、数据挖掘、机器学习和信息检索;Citeseer是一个描述文档之间关系的数据库,文档之间有引文链接,那么设定一条边。文档的类型包括代理、商业智能、数据库、信息检索、机器语言和HCI。
2.2 评价指标及结果对比
为了衡量算法的聚类性能,采用如下聚类评价指标进行评价。(1)聚类准确度(Clustering Accuracy,ACC)表示的是预测为正的样本中有多少是对的;(2)归一化互信息(Normalized Mutual Information,NMI)是衡量2个聚类之间共享信息量的信息论度量,较可靠地评价不平衡数据集聚类效果;(3)调整兰德指数(Adjusted Rand Index,ARI)是衡量两个数据分布的吻合程度的,值越大意味着聚类结果与真实情况越吻合;④F1值(F1-score)是精确率和召回率的调和平均数,综合考虑准确率和召回率的影响。从表 1的对比实验的结果可以看出,我们的算法在其中四种数据集上的结果准确度更优。加粗的黑色数值表示该算法在当前数据集的结果最优。
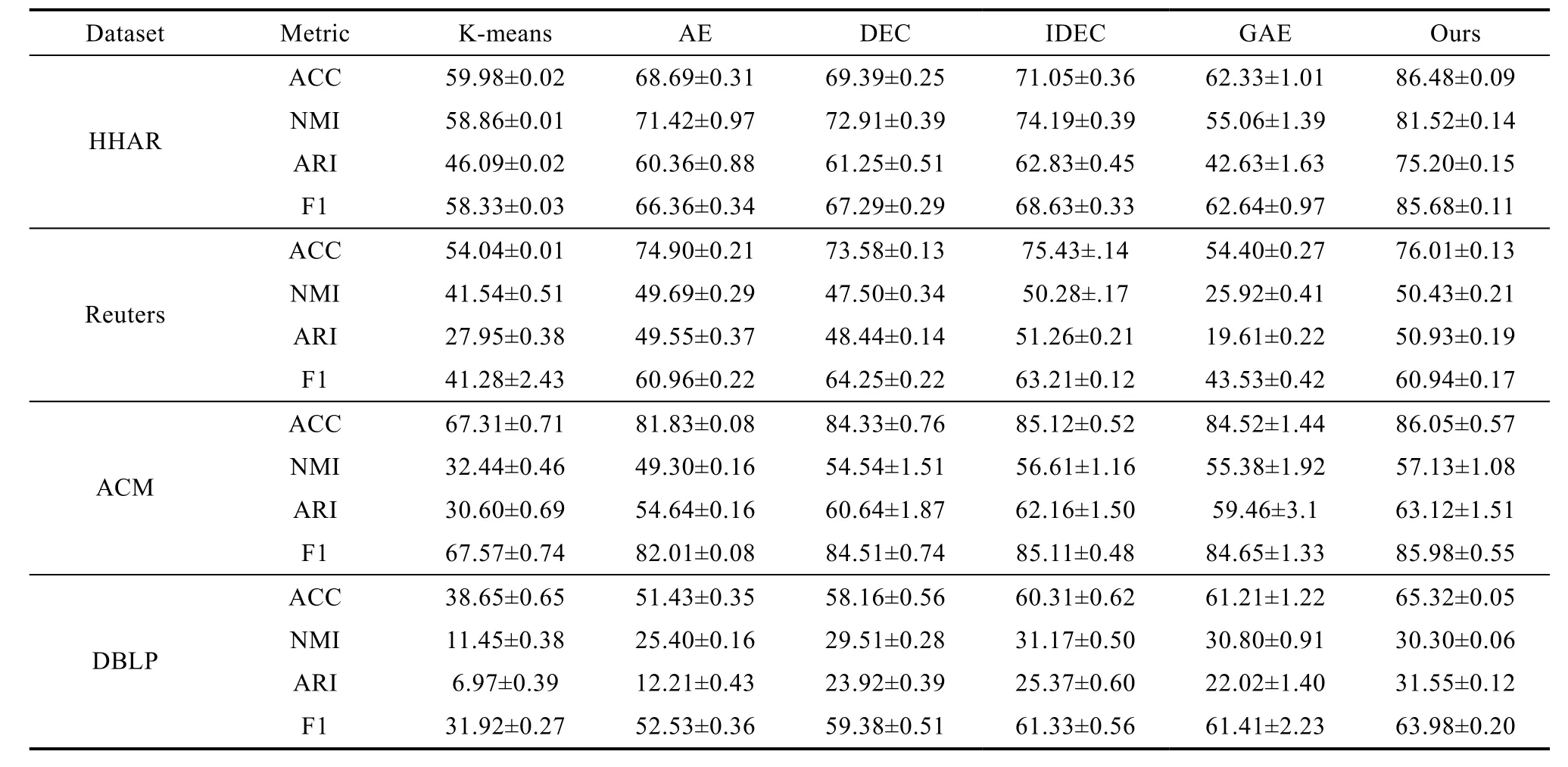
表1 不同算法在数据集上的指标值对比Tab.1 model result comparison on different datasets

续表
3 结论
本文提出深度图注意力聚类网络,该模型全方位地抽取数据的图结构信息、全局表达以及对聚类更有效的局部特征,具体流程如下,首先利用自动编码器学习较好的全局特征,在原数据的基础上构建图结构。根据邻居结点重要度,采用图多头注意力模块提取包含图结构的特征信息,将不同层全局表达与对应图结构信息相连,通过随机梯度下降与反向传播优化重建损失与面向聚类目标的KL散度聚类损失。在5个公开的图像数据集上的实验表明,我们的网络具有较优的聚类性能与良好的泛化性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
电子制作(2021年14期)2021-08-21
成都信息工程大学学报(2018年3期)2018-08-29
传媒评论(2017年3期)2017-06-13
西安工程大学学报(2016年6期)2017-01-15
第二课堂(课外活动版)(2016年2期)2016-10-21
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
电子设计工程(2014年12期)2014-02-27
