
基于支持向量机与LASSO的双模态音乐分类与评价
2021-11-23 01:28周涛
科技创新导报 2021年19期
周涛

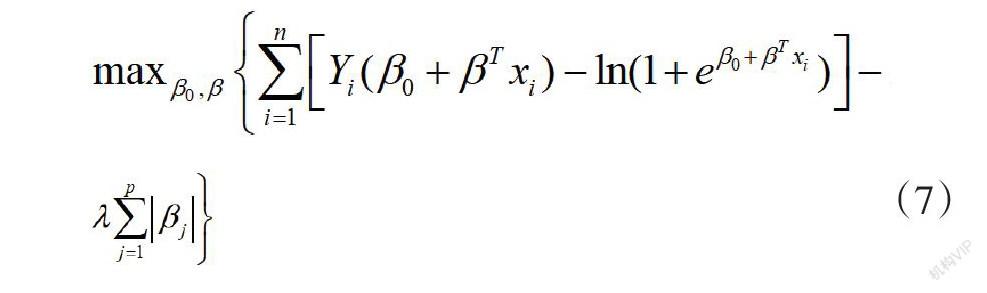
摘 要:随着互联网技术的高速发展,人们与数字音乐的关系更加紧密,人们会依据自己的偏好以及场所选择音乐,因此如何有效管理数量庞大的音乐并对其分门别类显得尤为重要。为提高音乐分类的准确率,本文从音频中提取特征向量,运用遗传算法优化支持向量机实现音乐流派分类;从歌词中提取特征关键词,采用LASSO降维实现文本情感分类,最终构建双模态音乐分类模型。结果表明,该分类方法准确率为73.1%,可靠性与稳定性良好,有效地避免了传统方法产生局部最优的问题。
关键词:音乐分类 支持向量机 遗传算法 LASSO 双模态融合
中图分类号:TP391.41 文献标识码:A 文章编号:1674-098X(2021)07(a)-0075-04
Bimodal Music Classification and Evaluation Based on Support Vector Machine and LASSO
ZHOU Tao
(Nanjing University of Information Science and Technology, Nanjing, Jiangsu Province, 210044 China)
Abstract: With the rapid development of Internet technology, people have a closer relationship with digital music. People will choose music according to their preferences and places. Therefore, how to effectively manage a large number of music and its classification is particularly important. In order to improve the accuracy of music classification, this paper extracts feature vector from audio, uses genetic algorithm to optimize support vector machine to achieve music faction classification; ex-tracts feature keywords from lyrics, uses lasso dimension reduction to achieve text sentiment classification, and finally constructs a dual-mode music classification model. The results show that the accuracy rate of the classification method is 73.1%, the reliability and stability are good, and the problem of local optimum is avoided effectively.
Key Words: Music classification; Support vector machine; Genetic algorithm; Lasso; Bimodal fusion
隨着互联网技术的高速发展,数字音乐不断衍生,人们与数字音乐的关系愈发紧密。音乐蕴藏着丰富的真情实感,人们会依据自己的偏好和场合来选择音乐,因此如何有效管理数量繁多的音乐,并对其进行分门别类,从而为用户推荐相应偏好类型音乐显得尤为重要。
为建立分类性能较好的音乐分类模型,首先对目前音乐分类模型进行调研,经过文献查阅及调查可以发现当下最优音乐分类模型是基于神经网络[1]的音乐分类模型,并且大多数音乐分类模型是从音频或歌词单模态实现音乐分类。但其存在局部最优等无法避免的问题,因此本文建立基于遗传算法优化支持向量机和LASSO的双模态音乐分类模型,以提高音乐分类的准确率和全面性。
1 构建双模态音乐分类模型
1.1 模型基本框架
基于支持向量机和LASSO双模态音乐分类模型构建步骤如下。
(1)通过离散傅里叶变换和高通滤波器从原始音乐中提取高频音乐片段。
(2)对高频音乐片段选取音频特征向量。
(3)将歌词中常见的连接词等去除,再对文本数据进行转换,其中每个词语作为一个独立的变量。
(4)采用遗传算法优化支持向量机,进行音乐流派类型分类;采用LASSO降维处理,进行音乐文本情感分类。
(5)对音乐流派分类和音乐文本分类进行双模态融合。
1.2 音频数据的特征提取
1.2.1 基于离散傅里叶变换的高频片段提取
为避免数据处理过程中出现“内存不足”错误,应先对音乐数据进行片段提取。由于音频中有用的信号往往集中在高频部分,且人耳对高频声的感受更为灵敏,因此本文提取音乐样本的高频部分作为该音乐的特征片段[2]。
鉴于计算机处理的是数字信号,采用离散傅里叶变换,将连续信号离散化。假设连续的声音信号为f(t),确定间隔Vt,再对f(t)进行均匀采样。即可得到离散化后的声音信号序列为,,。
被抽样的离散傅里叶变换表达式为:
(1)
(2)
式中,N为采样点个数,与的周期相同。
在上述基础上,将变换后的结果通过高通滤波器[3],最后利用离散傅里叶反变换将得到的高频域部分转换成时域,即可得到特征片段。
1.2.2 音频特征向量指标
音乐是由不同音符有机组合而成,而每个音符有自己独有的特征,都包含自身的音高、音强等基本要素。基本要素取值和组合的多样性致使音乐的多样性。针对音乐的多样性,构建音乐分类模型时需提取特征向量,特征向量[4]具体的指标如下。
(1)平均音高。音高是音乐的基本要素之一,也是不同类型的音乐的重要特征之一。本文定义平均音高:
(3)
其中,n表示音乐片段音符的个数,Pi表示音符的音高。
(2)音高的稳定值。音高的稳定性反映了音高的变化情况,本文定义音高的稳定值:
(4)
式中,表示音高的平均值。
(3)声压级[5]。将一定时间间隔内的瞬时声压对时间求方均根得到有效声压,得到有效声压的表达式为:
(5)
式中,x表示语音信号的采样点,N为采样点数,T为语音长度。
声压级由有效声压与基准声压取对数计算得到,与人耳听觉系统类似:
(6)
式中,表示待测声压的有效值,单位为dB。为参考声压,空气中的参考声压一般取2×10-5Pa。
(4)频率。音乐的频率通过对音频进行傅里叶变换得到频谱图,将所有信号的频率值相加求和,并以按从小到大的顺序依次相加得到的值为总和的70%时对应的频率值为该首歌的频率。
1.3 双模态音乐分类模型
1.3.1 基于支持向量机的音乐流派分类模型
支持向量机(SVM)[6]本身是一种二分类模型,尤其对于中小规模的音乐数据,分类效果较好。但本文需要的音乐分类为多分类非线性情况,因此需要对支持向量机进行改进,进一步引入核函数和多分类算法。
本文采用径向基函数为核函数,就是某种沿径向对称的标量函数。定义为空间中任一点到某一中心之间欧氏距离的单调函数,即样本点远离中心时函数取值很小。径向基函数表示为,其中k=1,2,...,N,取γ=10,σ2=0.2。
假设将音乐分为k个级别,记S={1,2,...,k},采用基于支持向量机的M-ary多分类算法进行音乐分类。值得注意的是,针对支持向量机中参数选择的问题,本文使用遗传算法搜索最佳参数。相较于传统的交叉验证,它克服了算法搜索空间过大、计算过于复杂的问题。基本原理为:给定空间范围,设置初始种群,然后引入杂交算子,集中搜索期望出现最符合适应度的那部分参数。
1.3.2 基于LASSO的文本情感分类模型
不同类别音乐不仅仅在音频角度存在差异,在歌词角度也存在差异。但是由于音乐的歌词文库大,样本数量远小于歌词数量,因此本文选用LASSO-logistic实现歌词降维,从而依据歌词提取出不同情感类别音乐的特征关键词[7]。
LASSO[8]是一种常用的估计参数模型和选择变量的方法,其估计计算性能好且得到了广泛应用。本文分别以喜悦、悲伤和轻松、紧张作为两组结果指标,因为协变量特征词为离散型数据,因变量特征词为是否表现喜悦或轻松情绪,若为否则表现的是悲伤或紧张情绪,也是离散性数据。所以使用LASSO-logistic进行高位数据降维处理。LASSO-logistic回归模型为:
(7)
1.3.3 双模态融合
音乐是通过旋律与歌词共同来表达其中蕴含的情绪情感,因此仅用其中一种对音乐进行分类评价是不全面的,并且依据单模态进行分类的效果并非最好。因此本文采用双模态音乐评价体系[9],针对同一首歌曲基于支持向量机的音乐流派分类模型中的音频特征向量结合音乐情感特征词进行双模态融合建立多模态数据,得到决策结果。根据所得结果可以基于音频与歌词双重模态对音乐进行流派和情感分类,从而实现音乐鉴赏。
2 实验及结果分析
2.1 音乐流派分类结果
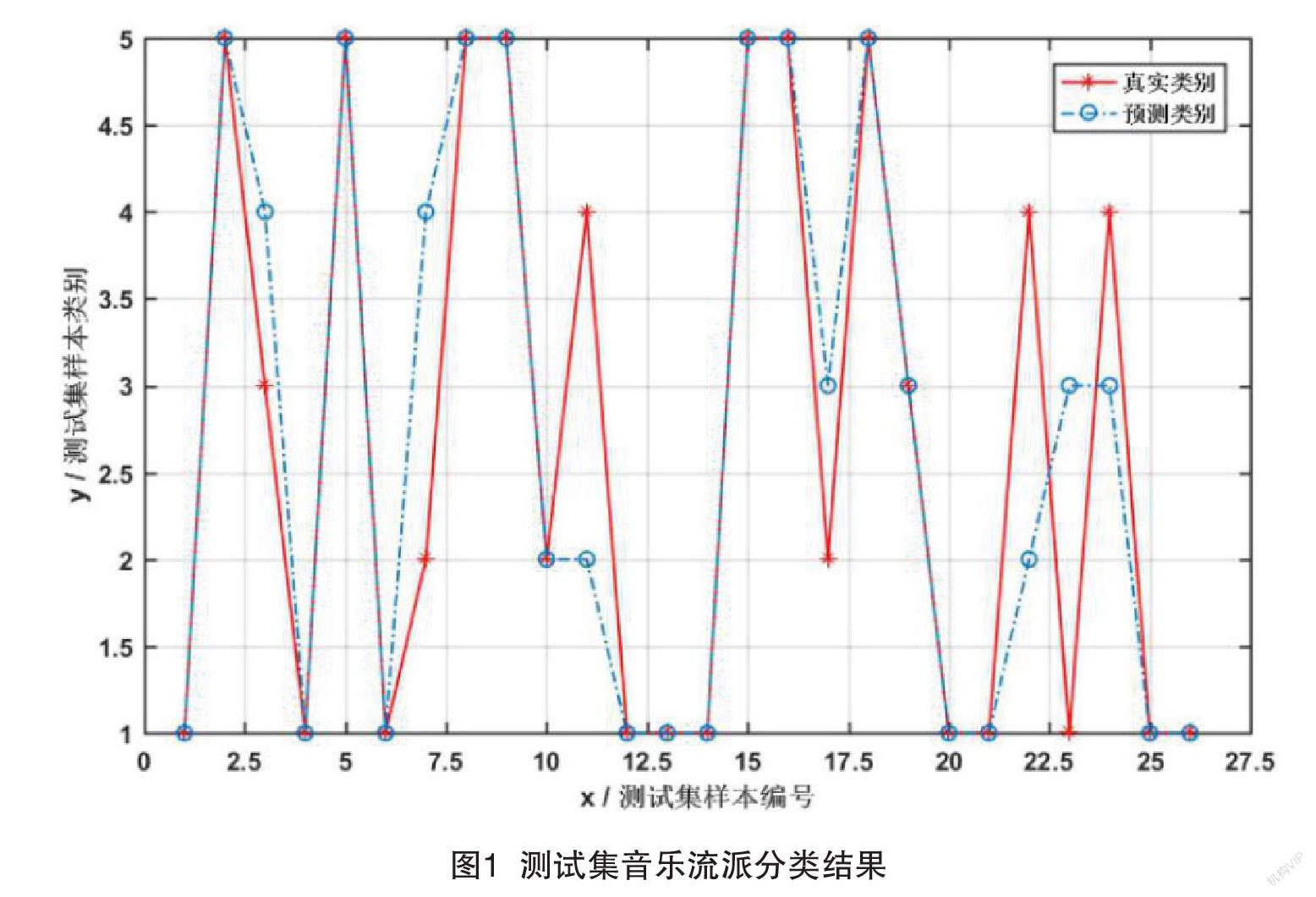
音乐流派分类结果如图1所示,图中每一个结点均表示一个测试集样本,纵坐标的1、2、3、4、5类别分别表示流行、摇滚、民谣、电子和说唱5种流派。可以发现真实类别与预测类别有大部分的结点是完全重合的,说明该模型得到的音乐流派分类结果与实际类别相同,该模型的分类准确性有71.0769%,说明该模型具有很好的分类结果。
2.2 文本情感分类结果
文本情感分类结果如表1所示,由表可知筛选之后表现压力、放松、喜悦、悲伤使用频率较高的特征词。其中β的估计值最高的词分别为“忙”“放松”“期待”“痛”,说明这4个词在表现相应情绪的歌词中较常用也能很好地传达出情绪。根据表中的特征词选取,可对歌曲进行歌词情感的分类鉴赏,从而来推断出该首歌是否有强烈的情感倾向,进而得到该音乐的歌词的风格。
2.3 双模态音乐分类结果
随机选取中国好歌曲第二季音频50个作为样本集,对其进行双模态音乐分类。在音乐流派方面,得到如表2的分类结果,由结果可知流行音乐的选歌占比很大,选择说唱的人数很少。此外,得到的不同音乐类型的音乐特征有差异,因此针对这5种音乐流派各选取一首代表歌曲,比较它们各种指标的差异(见表3)。结果表明大部分摇滚和说唱流音乐的平均音高和声压级较大,摇滚和流行音乐的音高的稳定值较大。在文本情感方面,以民谣中的《南山南》为例,其歌词中包含3个悲伤情绪特征词,多于其他类别特征词,说明这首歌更多地表达悲伤情绪。
3 结语
综上所述,为提高音乐分类效率,本文从音频角度和歌词角度建立了基于音频和歌词的双模态音乐分类模型。一方面从音频角度出发,首先利用傅里叶变换提取高潮片段作为特征片段,然后从特征片段中提取音高、帧能量等6个特征向量,进一步依据这些特征向量利用支持向量机实现音乐流派分类,即流行、摇滚、民谣、电子、说唱五类;另一方面从歌词角度出发,首先对歌词进行转换,再利用LASSO进行降维,提取表征情感的特征词,以喜悦、悲伤和轻松、紧张作为两组结果指标,以实现音乐情感分类。最后将这两方面实现融合得到最终音乐分类结果。
参考文献
[1] 刘天华.基于多特征融合和神经网络的电子音乐分类模型[J].现代电子技术,2018,41(19):173-176,182.
[2] 冯平兴,魏平.多类型噪声中的独立成分分離算法[J].电子科技大学学报,2017,46(2):352-356.
[3] 张晓娜,赵晶晶.基于粒子群算法优化神经网络的电子音乐分类模型[J].现代电子技术,2020,43(9):101-104,108.
[4] 陈晓鸥,杨德顺.音乐情感识别研究进展[J].复旦学报:自然科学版,2017,56(2):136-148.
[5] 李策,李智.粒子群优化算法和支持向量机的电子音乐信号分类研究[J].现代电子技术,2020,43(21):51-54.
[6] 周婧,范凌云.基于最小二乘支持向量机的电子音乐识别研究[J].现代电子技术,2018,41(9):109-112,116.
[7] 胡冰洁.基于特征向量的音乐情感分析的研究[D].西安:西安电子科技大学,2014.
[8] Robert Rowe.Mathematics and music: composition perception and performance[J].Journal of Mathematics and the Arts,2014(8):3-4.
[9] 陈颖呈,陈宁.基于音频内容和歌词文本相似度融合的翻唱歌曲识别模型[J].华东理工大学学报:自然科学版,2021,47(1):74-80.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
乐府新声(2021年1期)2021-05-21
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
计算机应用(2018年8期)2018-10-16
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
乐府新声(2017年1期)2017-05-17
电子制作(2017年9期)2017-04-17
