
一种非仿射高超声速飞行器的智能控制方法*
2021-11-24 02:15马长波茹海忠马广程夏红伟
飞控与探测 2021年4期
王 冠,马长波,茹海忠,马广程,夏红伟
(1.哈尔滨工业大学 航天学院·哈尔滨·150001;2.上海卫星工程研究所·上海·201109)
0 引 言
高超声速飞行器(Hypersonic Flight Vehicle, HFV)是一类速度不低于马赫数5的临近空间飞行器。与传统飞行器相比,HFV在速度、飞行包线和突防能力等方面具备明显的优势。控制系统作为HFV的重要子系统,是使其完成既定任务和安全飞行的重要保障。然而,HFV在飞行过程中具有快时变、强非线性、强耦合性等特点,这使其控制系统的设计成为HFV在实现工程应用时所面临的具有巨大挑战性的核心问题之一。
近年来,许多先进的控制技术已被应用于HFV控制,如自适应控制[1]、滑模控制[2]、鲁棒控制[3]、容错控制[4]、模糊控制[5]、神经网络控制[6]等,并取得了较好的效果。上述控制研究大都基于仿射模型而设计控制器,模型中的气动系数根据已知曲线拟合模型进行近似。然而,HFV实际受到的气动力与攻角、控制舵偏角等因素呈非仿射关系,将其描述为仿射模型,会造成一定程度的控制精度损失。损失严重时,在某些情况下,将不能正确描述飞行器的气动特性。因此,目前针对HFV非仿射模型的研究受到了越来越多的关注。BU[7]利用神经网络估计了未知的非仿射动态,设计了基于反步法的控制器。WANG等[8]建立了纵向通道的半分解半仿射模型形式,在考虑了执行机构死区的前提下设计了预设性能控制器。HU等[9]通过反馈线性化方法设计了鲁棒自适应模糊控制器,利用中值定理处理了气动阻力表达式中的非仿射形式项,进而得到了仿射模型。SHEN等[10]针对非仿射纵向短周期姿态模型,设计了自适应滑模模糊控制器,并取得了较好的控制效果。
随着未来HFV任务需求的发展和控制复杂度的增大,上述以经典控制理论为基础发展起来的控制方法面临一定的技术瓶颈[11]。近年来,深度学习、强化学习等机器学习手段逐渐地受到控制科学领域研究学者的关注,人工智能技术的飞速发展为飞行器自主智能飞行的实现提供了新的可能。早在20世纪末期,华裔科学家吴恩达[12]利用强化学习中智能体不断与环境进行交互的特点,对智能直升机进行了相关应用的研究,利用策略梯度算法对无人直升机悬停进行了控制。近几年兴起的深度确定性策略梯度算法(Deep Deterministic Policy Gradient, DDPG)[13]则是深度强化学习中具有代表性的算法之一。KOCH等[14]利用强化学习训练了四旋翼角速率内环控制器,并获得了部分性能优于PID控制器的效果。本文针对HFV的非仿射模型,进行了基于DDPG算法的飞行控制研究。不同于无人直升机和四旋翼,本文的研究对象HFV是一种非传统的飞行器,其具有面临的飞行环境复杂、模型非线性程度高、强耦合以及参数不确定等特点,上述特点增加了将机器学习方法直接应用于HFV控制中的难度。此外,从目前的技术途径来看,无论是传统的最优控制,还是深度强化学习,在飞行器实时自主控制方面均存在不足。传统控制方法与新兴人工智能的关系不是替代关系,而是应该相辅相成。以反步控制为例,其具有算法简单易实现、稳定可靠的优势,这都是当前智能控制技术所欠缺的特点。因此,本文研究了基于反步控制框架的智能控制器,将传统飞行控制与人工智能技术进行了创新结合,这是实现智能控制发展的一个重要方向,也是解决HFV智能飞行控制的一种可靠思路。
基于以上分析,本文针对HFV非仿射模型研究了基于强化学习的反步控制方法。在本文其余部分,首先给出了HFV的数学模型,然后利用反步法的思想,依次设计了俯仰角速度虚拟控制指令和升降襟副翼控制律,并借助Lyapunov方法分析了闭环系统的稳定性。在此基础上,利用DDPG算法,设计了针对反步控制的智能参数整定和控制律补偿方案。最后,通过仿真实验对其控制效果进行了验证。
1 数学模型和问题描述
1.1 HFV纵向通道非线性模型
本文以文献[15]给出的一类HFV为研究对象,研究了其纵向非线性模型的控制问题。其模型可描述为
(1)
式中,攻角α、俯仰角速率Q和航迹倾角γ是HFV短周期运动的三个状态变量;Iyy是俯仰通道转动惯量;MA和MT分别是由气动力和推力产生的俯仰力矩;Δ是由环境干扰、模型不确定性等因素造成的额外扰动。MA和MT可表示为
(2)

1.2 问题描述
本文的研究目标为:设计升降襟副翼控制律δa和δe,使得攻角α能够跟踪给定的参考指令αd。为实现此目标,本文以反步法为基础,在考虑外部扰动的情况下,以俯仰角速度作为虚拟控制量,设计了虚拟控制律,进而完成了升降襟副翼控制律的设计。由于反步法对参数比较敏感,对其的调整在很大程度上依赖于控制人员的经验,通常需要经过反复的试验,才能达到较好的控制效果。此外,对于处于复杂飞行环境和执行复杂飞行任务的HFV而言,较多的控制量将导致其参数整定工作耗时且繁琐,往往会给控制器的设计带来诸多不便。在反步控制的基础上,利用强化学习进行智能参数整定和控制律补偿,将使俯仰角速度能够较好地跟踪俯仰角速度虚拟控制指令,进而实现HFV的飞行控制。
2 控制器设计
本节主要介绍控制器设计的具体方案。首先,利用反步法分别设计了俯仰角速度虚拟控制律和升降襟副翼控制律;然后,给出了所采用的DDPG算法的原理;最后,将其与反步控制结合,提出了本文所研究的智能控制器。
2.1 俯仰角速度虚拟控制律设计
首先,定义x1=α-αd。根据式(1)可得
(3)

(4)
式中,H和V为HFV的高度和速度,可由相应的传感器测量得到。
对于式(3),设计虚拟控制律Qd
(5)
式中,k1为控制增益。定义误差变量x2=Q-Qd。结合式(5),可将式(3)写为
(6)
(7)
2.2 升降襟副翼控制律设计
对于误差变量x2的动态,文献[11]给出的CD的表达式包含控制量u的二次项。根据文献[11]和式(2),这些分量会对攻角和俯仰角速度动态产生一定的影响,其影响随马赫数增加而愈发明显,对其进行简单忽略并不合理。基于此,x2的动态可描述为
(8)
式中,未知函数f(·)是连续可导的非仿射控制函数,为由气动系数不准确和外部干扰所导致的扰动项。同时,选定u0(x)作为控制输入的理想值
(9)
式中,k2>0为控制增益。
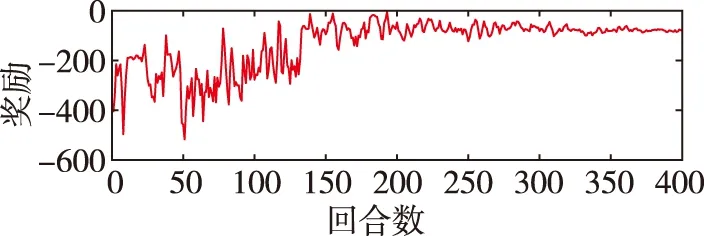
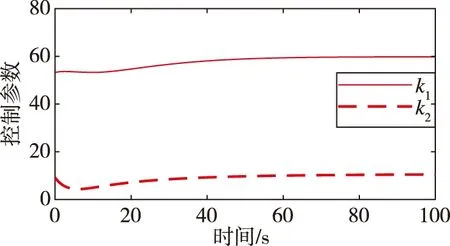
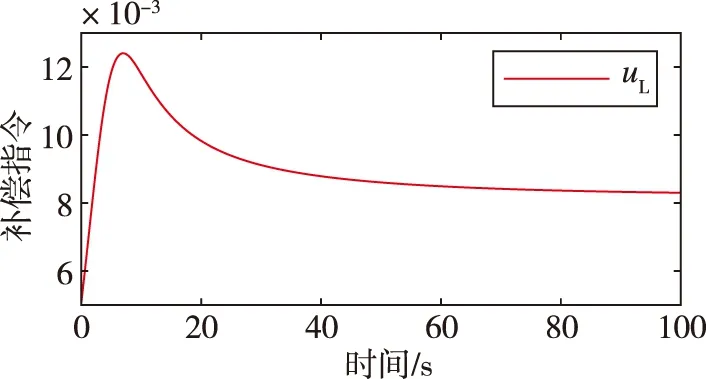
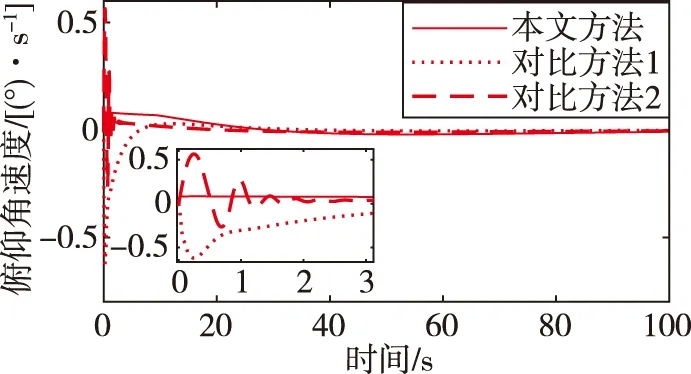
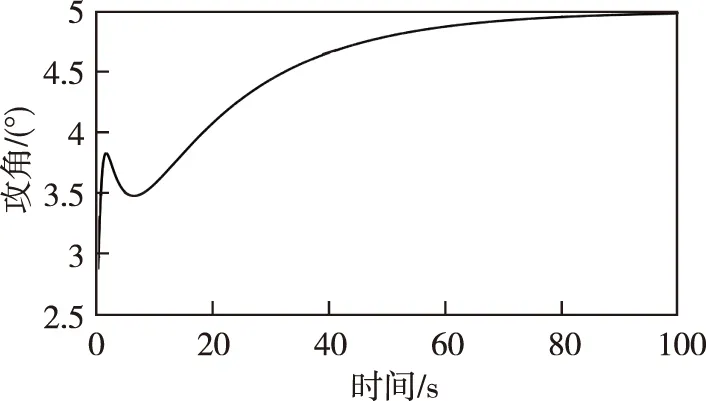
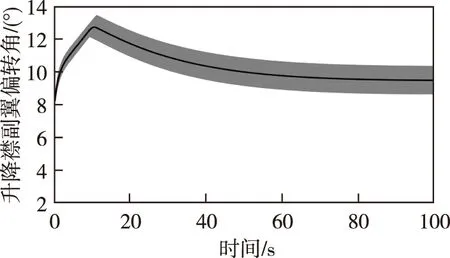
假设|u-f(x1,x2,u,Δ)| (10) (11) 式中,σ>0为收敛系数。 (12) 对于W=W1+W2的导数而言 ≤0 (13) 因此,在假设未知函数有界时,可以通过以上控制设计进行实现。需要指出的是,在上述反步控制器中,控制参数的值将直接影响控制输入的大小,进而影响到控制的效果。 (14) DDPG算法借鉴了深度Q网络算法的优秀经验,将记忆回放单元以(si,ai,ri+1,si+1)的形式存储为样本,而后模拟人类大脑的回忆过程进行了采样学习。对于动作价值网络的训练,是要最小化损失函数 (15) 其中,yi=ri+γfQ(si+1,μ(si+1)|θQ),N为样本总数。不同于深度Q网络算法直接将策略网络的参数赋值给目标网络,DDPG算法采用的是更加平滑的、类似惯性更新的思想,以进行目标网络的参数更新。τ为惯性更新率 (16) 以上介绍了DDPG算法的基本原理。下面利用控制器补偿的思想,结合强化学习,设计了如下控制器 u=u0+uL (17) 其中,uL为补偿指令。所设计的智能控制器的结构如图1所示。 图1 控制器结构Fig.1 The structure of the controller 至此,本小节基于反步法的控制律设计并结合DDPG算法原理提出了一种HFV智能控制器。其主要思想为:一方面,利用参数整定机制取代耗时的试错方法,可以根据当前的飞行条件决定关键的控制参数;另一方面,通过生成合理的补偿指令,可实现对HFV的安全高效控制。 为验证上述方法的有效性,首先需要采用DDPG算法进行训练。在本文中,状态集选为st=(α,Q,V,H),动作集选为αt=(k1,k2,uL)。此外,奖励函数可设为如下形式 (18) 其中,kα和kδ是奖励函数中两个目标的权重;αmax和δmax是攻角和舵偏角的上界值,其目的是将不同量级上的状态进行归一化处理。 本文所考虑的训练场景基于表1中HFV的状态约束。在每轮训练开始时,智能体根据系统随机产生的初始状态,不断地对外部环境进行试探,并进行对整个状态空间的探索,以找到行动值更高的行动。 表1 HFV的状态约束 Actor网络和Critic网络均采用了全连接结构。其中,Actor网络使用了三层神经网络,其输入为系统的状态集st,输出k1、k2为反步法的控制参数,uL为控制器的补偿指令;Critic网络使用了两层神经网络,其输入为系统的状态和动作集,输出为拟合行动值Q(s,a)。tanh函数g1(z)的输出位于(-1,1)之间,这样可保证控制输入约束在一定范围。因此,本文中Actor网络的输出层采用了tanh函数。除此之外,其余网络均采用了可为神经网络提供更快处理速度的Relu函数g2(z)。在所选用的DDPG中,训练的相关参数设置如表2所示。 表2 训练参数设置 (19) 在本文中,kα=0.8,kδ=0.2。设计算法的仿真时长为T=100s,步长dt=0.2s。因此,在一个回合训练中有500个数据。通过训练得到的奖励如图2所示。由图2可以看出,累积奖励在300回合左右基本收敛,展现了快速学习的过程。DDPG是采用深度神经网络进行函数拟合的一类新兴的强化学习算法,适合解决复杂大维度应用场景问题,并已在围棋AlphaZero算法中得到了技术验证[16]。需要指出的是,智能控制的实际应用可能存在的缺点包括了由随机动作探索引发的学习效率低下以及训练样本的海量需求。本文关于HFV智能控制的探索工作主要针对纵向通道的控制问题,这极大地简化了训练的复杂程度。 图2 总回报奖励曲线Fig.2 Total reward curve 针对式(1)中的HFV动力学模型进行了仿真实验。其中,式(2)所采用的气动参数可参考文献[16]。所选取的飞行任务是HFV在巡航状态下,飞行速度设置为V=3060m/s,飞行高度设置为h=20000 m,飞行状态初始条件为α(0)=2.66°,q(0)=0[(°)·s-1],跟踪指定的攻角参考轨迹αd(t)=5+2e-0.3t-2.5e-0.05t(°)。 首先,将训练出的神经网络移植到所提出的控制器中,在当前任务中所产生的控制参数和补偿指令如图3所示。 (a)控制参数 (b)控制指令补偿图3 控制参数和补偿指令Fig.3 Control parameters and compensation commands 接下来,将式(10)对应的控制方法(记为对比方法1)和文献[7]对应的控制方法(记为对比方法2)作为对照,进行仿真实验。图4分别给出了其攻角、俯仰角速度、升降襟副翼偏转角的状态曲线。由仿真结果可以看出,上述三种方法均可取得较好的攻角跟踪控制效果。其中,对比方法2和本文方法的控制效果要优于对比方法1。对比方法2在控制初始阶段会产生较为明显的抖振,并且两种对比方法的控制效果均依赖于参数调整。本文方法能够在较短的时间内实现攻角跟踪,这是由于相比于对比方法,本文方法经强化学习而得到的控制参数是随系统状态可调整的,且对控制器具备较好的补偿作用。 (a)攻角 (b)俯仰角速度 (c)升降襟副翼偏转角图4 对比实验Fig.4 Comparative simulations 最后,为了验证对参数不确定性的适应能力,考虑气动参数在标称值±20%内变化,对该任务执行了600次的蒙特卡洛仿真实验,实验结果如图5所示。由图5可以看出,本文方法具有较好的鲁棒性。 (a)攻角 (b)俯仰角速度 (c)升降襟副翼偏转角图5 蒙特卡洛仿真Fig.5 Monte-Carlo simulations 本文提出了一种非仿射HFV的智能控制律,HFV智能控制律具有结构简单、鲁棒性强的特点。在反步法控制器的基础上,借助DDPG方法,对控制器进行了参数在线调整和控制指令补偿。该控制器能够在额外扰动和未建模动态的情况下,保证攻角稳健地跟踪期望目标。最后,数值例子验证了所提出方法的有效性。本文主要进行了对HFV智能控制方法的研究探索工作,所提出的方法具有一定的学术研究价值和工程参考价值。
2.3 基于深度强化学习的HFV控制策略



3 仿真试验及结果分析
3.1 训练流程


3.2 仿真结果



4 结 论
猜你喜欢
导航定位学报(2022年4期)2022-08-15
舰船科学技术(2022年11期)2022-07-15
中国自行车(2022年3期)2022-06-30
小天使·三年级语数英综合(2022年4期)2022-04-28
阅读与作文(英语初中版)(2019年8期)2019-08-27
网络空间安全(2019年8期)2019-03-18
汽车导报(2017年5期)2017-08-03
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
