
基于语义与情感词典的微博评论情感分析方法
2021-12-10 02:48白刚
现代计算机 2021年30期
白刚
(桂林旅游学院,桂林 541006)
0 引言
每逢节假日旅游点均出现游客暴增现象。游客量的增加会改变旅游体验,游客的评论数据是游客体验直观的反映,其中的情感倾向代表了对旅游点的积极或消极态度,也是旅游点规划的重要参考依据[1]。
但是,评论信息作为非结构化文本数据难以直接分析其情感倾向,需要采用算法将文本转换成可定量的情感倾向数据。传统的方法主要包括基于情感词典的方法[2-4]和基于机器学习的方法[5-7],但基于情感词典的方法主要依赖于情感词典的构建[8],对上下文语义及语气等考虑不足。机器学习的方法需要大量人工的特征标注,对较小训练集效果欠佳,且不同的分类器对结果精度影响较大。
本文拓展了情感词典的基础方法,借鉴了机器学习方法中的标注语料方法,采用哈工大语言技术平台(language technology platform,LTP)进行分句、分词和词性标注,结合知网情感词典(HowNet)进行情感词统计,情感副词、语气标点加权进而获得文本情感得分。
1 研究背景及方法
1.1 研究背景
2021年“五一”期间出现了国内旅游高峰,成都和重庆或为热门旅游目的地,游客量分别达到了390万和280万人次。微博作为国内用户基数最大、信息交换速度最快的社交平台之一,“五一”期间产生了大量的用户评论信息,评论中隐含用户对旅游目的地的情感倾向,挖掘潜在的情感倾向对旅游目的地的规划和运营有重要的意义。但由于评论数据的非结构化属性,难以直接进行量化分析,迫切需要高效准确的将文本数据转换成情感分值的方法。
1.2 研究方法
N-LTP中采用的中文分词(CWS)被视为基于字符的序列标记问题,采用线性解码器对每个字符进行分类[9]:

其中,y i表示每个字符的标签概率分布;WCWS和bCWS是可训练的参数。
N-LTP中的词性(POS)标记使用一个简单地MLP来对每个词语进行词性分类,分类后可对名词等非情感词进行删除以减少计算工作量。

式中,y i表示每个词的词性概率分布;WPOS和bPOS是可训练的参数。
输入文本情感得分如公式(3)。

式中,CPOS和Cneg分别为情感正向词和情感负向词的出现频次,wadv为情感副词权重,Cadv为前置情感副词出现频次,wpun为情感词后强调性标点权重得分。
2 数据来源及处理
2.1 数据来源及采集方法
选择新浪微博作为数据采集平台,采用爬虫进行数据采集。采用新浪微博的高级搜索,关键词限定为话题标签#成都#和#重庆#,时间区间限定为2021年5月1日00:00~2021年5月5日23:59,分别抓取成都和重庆的用户ID、评论、来源地、性别等相关信息。
最终获取数据集数量为成都评论数据共计4789条,重庆评论数据8563条。
2.2 数据处理及结果
观察数据发现,数据存在部分缺失、错误、无效、重复等问题。导入Mariadb数据库后,采用存储过程对数据进行基本清洗,去除重复和无效记录,并根据人工检查去除广告性质的评论文本记录,最终得到成都有效评论数据3941条,重庆有效评论数据7123条。
3 文本情感分析
3.1 情感分析原理
评论文本情感分析流程如图1所示,情感倾向可认为是主体对某一客体主观存在的内心喜恶和内在评价的一种倾向。主要由两个方面来衡量:一个情感倾向方向,由情感词数量测量;一个是情感倾向度,由情感词分级+情感程度副词与语气标点加权测量。
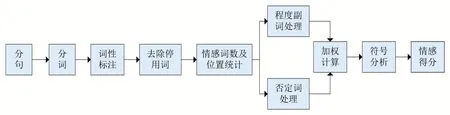
图1 情感分析原理
文本情感分析的分析粒度可以是词语、句子、段落或篇章。
段落级情感分析主要是面向特定事件或主题进行情感倾向分析,通常要事先构建对应主题的情感词典,如音乐评论的分析,就需要音乐特定的情感词典来进行分析,最终效果会由于通用情感词典;也可以通过人工标注大量音乐评论来构建分类器。句子级的情感分析一般通过统计分词后的情感词的分值进行计算。
篇章级的情感分析,通常通过聚合篇章中所有的句子的情感倾向来计算得出。因此,句子粒度的情感分析,既是解决如评论等短文本情感分析的基础,同时也是篇章级文本情感分析的基础。
3.2 分句与分词
对于中文评论,分句方式较为简单,采用标点分句。分词采用哈工大N-LTP的cws.model模型,其基本原理为建模为基于字的序列标注问题,对于输入句子的字序列,模型给句子中的每个字标注一个标识词边界的标记(式1),然后基于统计模型同时融合词典的方法最大正向匹配得到分词结果。为增加分词准确率,添加了知网情感词典等外部词典,分词样例如表1所示。

表1 分词结果样例
词性标注中n为名次,v为动词,wp为标点,d为副词,a为形容词,c为连词。
3.3 情感分析
将分词以后的词袋按照词性比对停用词列表(StopWords),去除不带有情感意义的停用词,提高情感分析性能。然后根据情感词级别进行情感词频统计、情感词位置与程度副词、否定词加权计算以及句尾符号加权计算得出句子的最终情感得分。算法逻辑的关键部分如下:
算法1:微博评论情感分析算法
输入:微博评论自然语言段落weibo_content
输出:评论情感分析得分S s
1S s=[]
2 sentences=Cut_Sentence(weibo_content)
3 for sent in sentences:
4 words=tokenize(sent)#式1
5 seg_words=del_stopwords(words)
6CPOS=0
7 Cneg=0
8 for word in seg_words:
9 if word in posdict:
10CPOS+=1
11wadv,Cadv=Match_adv(CPOS)
12 elif word in negditc:
13…#消极情感计算
14 elif word word==′!′or word==′!′or word==′?′or word==′?′:
15wpun=Set_WP(CPOS)
16S ss=(CPOS+wadvCadv+wpun)-(Cneg+wadvCadv+wpun)#S ss为分句情感得分
17S s=∑S ss
18 returnS s
采用算法1对数据库中微博评论文本(表1)进行情感分析打分,样例结果如表2所示。

表2 情感分析样例
表2中,副词“尤其”为情感倾向为正向的形容词“开心”的前置位置为1的语义加强副词,在词典中权重为6。本例评论结束标点为句号,没有标点符号加权。本例情感分析最终得分计算公式为:Ss=(5+6×1+0)-(2+0+0),最终情感得分9,情感倾向方向为正向,情感倾向度较强。
4 效果测评
4.1 算法效率
软件环境数据库采用Mariadb 10.4版本,开发语言采用Python 3.6版本,硬件环境为Intel(R)Xeon(R)CPU E5-2620 v4;32 G RAM。对4000条评论信息进行情感分析打分,运行时长为483秒,平均每条评论数据情感打分时间为0.12秒。
4.2 人工标注与机器标注对比
选取数据库中机器标注评分为正向(评分为正数)、中性(评分为0)和负向(评分为负数)的记录各10条进行人工情感标注和打分,打分采用5人小组的感性打分方式,不规定单个词语的得分细则,最后取平均值作为最终该条目的情感得分。最终人工标注得分与算法标注得分对比如图2所示。
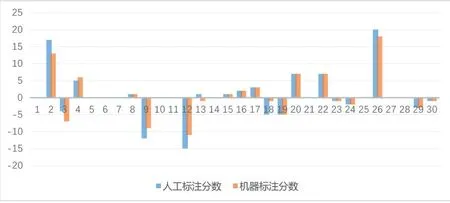
图2 人工标注与机器标注对比
如图2所示,在情感倾向方向上,人工标注与机器标注倾向性在30条样例中,一条出现情感倾向差异,正确率96.7%;情感倾向度方面,人工标注与机器标注在低分区间(绝对值<8)基本没有差异,在高分区间,人工标注普遍评分略大于机器标注,最小差异11%,最大差异36%。
可以发现,在情感倾向方向维度上,人工标注和机器标注结果基本一致,但机器标注效率远高于人工标注。在情感倾向度维度上,人工标注在无给定单个词语得分的情况下,人工标注与机器学习标注有较大差异,同时人工小组内打分差异较大,存在较大波动。
5 结语
本研究采用哈工大语言技术平台进行分句、分词和词性标注,同时结合知网情感词典进行情感词统计,情感副词、语气标点加权获得文本情感得分,构建了新的算法。该算法对传统的情感词典打分方法进行了延伸和拓展,加入了上下文语义要素,考虑了情感词前置副词的语义加强效果,增加了句子结尾标点语气效果的权重。
综合来看,算法效率高(0.12秒/条),准确率较高(96.7%),在对社交网络采集的文本大数据进行分句、分词和情感分析的工作中,采用本算法可极大提高研究工作的效率。后续研究将对算法使用的情感词典和副词词典进行人工修订以增加准确率。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
娃娃画报(2019年8期)2019-08-05
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
中关村(2014年5期)2014-05-15
高中生学习·高三版(2014年3期)2014-04-29
中学英语园地·初二版(2008年3期)2008-07-15
