
网络虚拟仿真实验室数据隐私度定量测算模型
2021-12-10 08:32黄恩铭
计算机仿真 2021年11期
蒋 斌,黄恩铭
(南京中医药大学,江苏 南京 210023)
1 引言
高等教育不仅要求学生牢牢掌握理论知识,还要增强学生的实际操作能力。实验教学是培养高素质人才的关键途径,但传统实验室通常受到时间、空间以及设备等因素制约。虚拟实验室则具备低成本、高效率等优势,有效解决实验教学受限问题,在高等教育中发挥重要作用。网络虚拟仿真实验室融合了Web技术与VR技术,建立了开放式、网络化的教学系统,能够让学生在虚拟环境中模拟不同场景与设备配置,充分了解实验过程,提高学生学习兴趣[1]。但在为学生提供便利的同时,海量实验数据在不断被流转。实验室数据蕴藏较大价值,包含大量涉及隐私的数据信息。由于缺少通用的隐私界定标准,要实现某些数据在隐私层面进行“是”与“否”的判断非常困难[2]。现阶段,针对数据隐私定量问题已有很多研究成果。
文献[3]提出基于度量空间与范数基本原理的数据隐私度量模型。该模型分析数据数值化处理方式,将数据表变换为矩阵形式,引入隐私偏好函数,研究敏感属性随时间的变换关系,建立度量空间,计算数据的隐私量。该方法针对数据的隐私进行设计,提升了数据的安全性,但该方法对数据因素定量考虑甚少,存在一定局限性。文献[4]在隐私偏好基础上实现数据隐私度定量计算。分析基于用户隐私偏好的策略选择,同时提出基于博弈隐私度量的计算模型,在混合模式下利用策略熵度量隐私度情况。该方法对隐私数据测算的精度较高,但该方法测算过程中考虑的因素较多,导致测算的时间较长。
为此,将差分隐私技术与神经网络相结合,共同建立隐私度定量测算模型。差分隐私对数据隐私有着强大的定量控制性能,将该技术应用到决策树模型中,可以对决策树进行保护,不容易被使用者逆推出树的结构,在实现数据保护的同时,还能将数据集合转变为具有类似性质的数据集,实现隐私数据分类,提高定量测算效率。与传统测算模型相比具有一定优势。
2 网络虚拟仿真实验室功能与运行模式分析
虚拟实验室是借助图像仿真[5]和虚拟现实[6]技术,在计算机中搭建虚拟实验环境。其中任意一个可视化物体均表示为实验目标,利用鼠标进行点击实现虚拟实验操作。
网络虚拟仿真平台分为资源管理、实验库管理、过程管理、报告评估、互动系统等子系统,功能架构如图1所示:

图1 仿真实验室功能模块
分析上述实验室功能结构,可以得出虚拟仿真实验室具有如下特征:
1)开放性与选择性:虚拟实验室是在网络基础上构建的平台,具有开放特征。对于用户而言可以结合自己实际情况合理安排实验时间,为实验者提供更多自主选择空间。
2)协同工作与实时反馈:虚拟实验室属于统一平台,多个实验者可共同操作,实验与操作过程必须实时反馈并进行处理。
3)可操控性和人机交互:此特点相对于传统实验模式而言,在传统实验中对于实验者来讲更多的是“看”,实际操作较少。而在虚拟实验室中能够通过远程计算机交互达到预期实验目的。
4)信息共享:对互联网而言其最大优势在于信息共享,无论实验者身在何地,均可以使用虚拟平台提供的各类共享资源。
结合上述特征,可以确定虚拟实验室的运行模式[7],如图2所示。
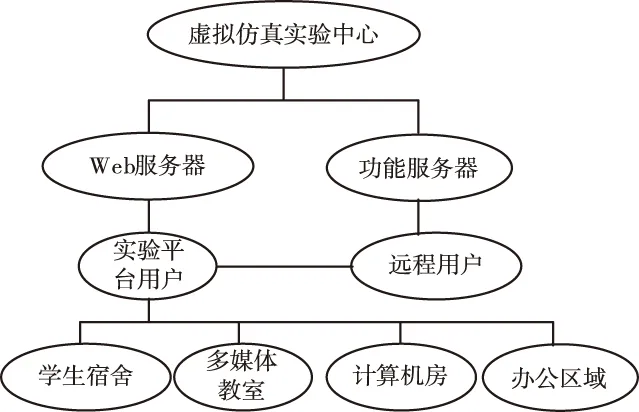
图2 虚拟实验室运行模式
分析虚拟仿真实验室的功能结构与运行模式,有助于了解隐私数据所在区域,实现实验数据的全面收集,为数据分类提供依据。随着网络技术的不断发展,利用虚拟实验室进行实验教学已发展为一种趋势,同时也会成为未来实验教学的主要方式。
3 测算模型构建
3.1 基于差分隐私的数据分类
3.1.1 差分隐私主要机制
差分隐私技术可以保证在数据库中对任意单独记载或删除的数据不敏感。
假设某任意函数f符合ε-差分隐私,针对任意相邻数据库B1与B2(B1ΔB2=1),其任意输出O∈Range(f)均满足Pr[f(B1)∈O]≤eε×Pr[f(B2)∈O]。其中,B1和B2是相邻数据库,其中仅存在一条不同记录,ε为隐私预算[8],其可以控制隐私登记。该值越小,需要加入的噪声越大,保护力度也随之增强。
差分隐私需符合可组合性与极大化两个条件。其中,可组合性指若所有函数fi提供εi-的差分隐私保护,则与其有关的一系列函数fi(B)可提供(∑iεi)-差分隐私的保护。极大化性质可理解为若所有函数fi提供εi-的差分隐私保护,则与其相关的独立函数[9]可以提供maxi(εi)-差分隐私保护。
现阶段,主要有拉普拉斯与指数机制能够实现差分隐私。这两种方法均需要计算函数f的全局敏感程度。
函数f:B→Rd的全局敏感度为

(1)
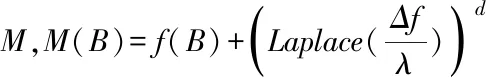
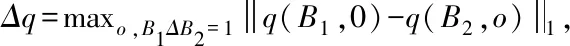

(2)
针对不同类型数值,通过上述差分隐私机制能够提高定量测算过程中隐私数据的安全性,确保数据不被破坏。
3.1.2 决策树模型
决策树模型是数据挖掘领域常用的分类方式之一,其核心思想是利用树形结构将样本集合引入到树状空间中,任意一个样本Ii=(Ai=[ai,1,ai,2,…,ai,m],ci),均由一个属性和一个类标签构成。假设生成决策树后,若已知样本属性,则可估计出样本种类。
决策树生成时,会反复选取最优属性对训练样本分类,直至出现节点终止条件,不再继续分裂,将终止条件用来终止树的构成。此外,还能对决策树进行剪枝操作,防止树结构太过复杂,影响分类效率。生成后的决策树中,随机一片叶子节点均会被赋予不同类标签,对于某个测试目标,综合其属性,将会被分配到某节点中,此节点的类标签是此样本的预测标签。以嵌入差分隐私到决策树中的模型如图3所示。
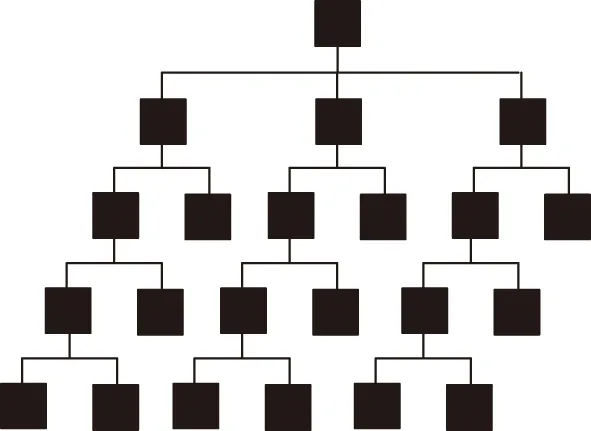
图3 决策树模型
3.1.3 隐私数据分类
在决策树模型中,打分函数[10]非常重要,它是选择分类属性的衡量方式。利用基尼指数评估分类的有效性,基尼指数越小,表示生成决策树过程可以很好地完成分类。传统的打分函数表达式为
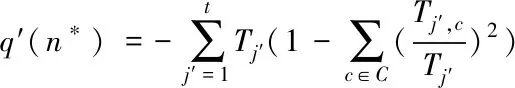
(3)
式中,n*表示某个节点,t为n*子节点数量,Tj′为子节点j′包含的样本数量。
为更好选择分类结构,重新建立一个新的打分函数,同时对其全局敏感度进行分析。当从节点n*生成子树st时,子树分数表达式为
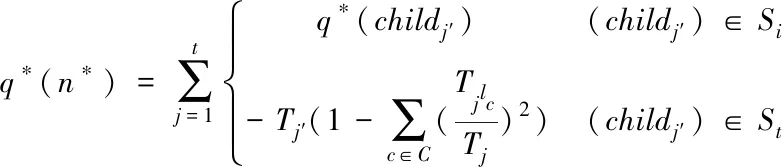
(4)
式中,Si与St分别表示st内部节点与叶子节点集合。
利用上述打分函数,将相同类型隐私数据合并在同一个集合中,这些数据隐私级别大致相同。在实现数据分类基础上,再对实验数据进行定量测算,有助于提高计算精度,同时可以检验出计算结果是否准确。
3.2 基于BP神经网络的隐私度定量测算模型
BP神经网络属于一种反向传播的多层前馈式网络[11],该方法核心思想是梯度下降法,通过梯度搜索技术,减小实际输出与理想输出的误差均方差。BP神经网络包含输入层、隐含层与输出层。神经元和下一层神经元互相连接,而同层神经元并无连接。
该网络最大特性为可以学习并保持大量输入输出关系,同时不用事先已知这些关系。在正向传播过程中,输入信号经过隐含层作用,在输出节点上,对其进行非线性转换,形成输出信号。如果实际输出与理想输出差距较大,则转入反向传播。误差反传即为将输出误差经过隐含层向输出层传递,同时将误差平均分配到所有单元,将从每层获取的误差信号当作权值调整依据。
为此,提出基于IE-BPNN(Information Entropy-BP Neural Network)的隐私度定量测试模型。其核心思路是将虚拟仿真平台中的数据,按照上述分类结果,解析全部隐私要素,并将其进行规则化处理;再通过计算不同类别数据之间相同的二级隐私要素信息熵确定权重;最后计算一级隐私要素中隐私量,完成对隐私要素降维,并通过训练好的神经网络获取最终隐私度测算数值。
3.2.1 隐私数据规则化处理
隐私的含义相对广泛,根据上述对全局敏感度的分析,从内容(P1)、状态(P2)与隐私详情(P3)三个方面挑选具有代表性的要素作为隐私度定量测算的指标。
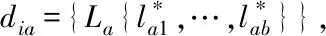

(5)
3.2.2 隐私度定量测算模型
对n′条记录在三个不用维度上每个一级要素分别构建信息熵度量矩阵[12],如果某一级要素La含有b个二级要素,针对n′条记录的测算结果,通过构建n×b大小的二级要素信息熵矩阵实现。详细过程如下:

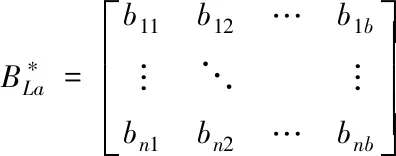
(6)
式中,bij是规则化处理后第i个记录中第j个二级要素值,通常取值为0或1。
步骤二:对上述矩阵中元素进行转换,即

(7)
则可以得到矩阵
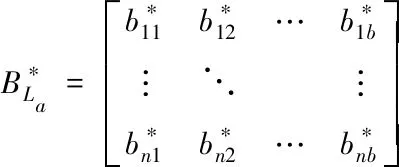
(8)
步骤三:根据信息熵定量矩阵获取每个二级要素j的信息熵为
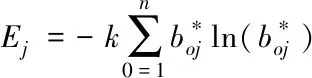
(9)
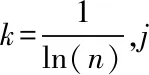
步骤四:获取要素lj的权重值
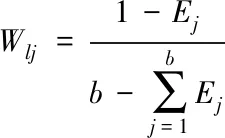
(10)
步骤五:计算一级要素La对于单条记录di的定量值
②层黏土(Q3-4al+pl):灰黄色~黄色,局部上部为灰黑色,可塑~硬塑,局部底部含铁锰质结核,稍有光泽,中等干强度,中等韧性,中等压缩性;场区沟渠及北部有缺失。

(11)
Ldia值越高,表明隐私度越高。
根据上述构建步骤,完成了 隐私度定量测算模型的设计。
4 仿真研究
4.1 仿真方案
仿真在server上进行,其处理器为3.10GHz Intel Core i5,内存位36 GB。设定神经网络训练次数为1000次,学习效率为0.2,训练误差为0.01,结合下述公式确定初始隐含层节点数量

(12)
式中,I*与O*分别表示输出层与输出层节点数量,a为调节参数。最终确定隐含层节点数量为8。
训练过程误差曲线如图4所示。由图4可以看出,该网络在经过200次训练后可满足误差需求。
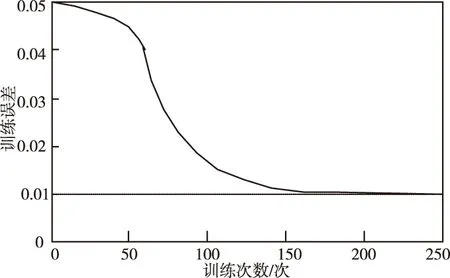
图4 神经网络误差曲线
4.2 仿真结果
对提出的基于决策树模型的隐私数据分类性能进行仿真,引入分类偏差程度概念,计算公式为

(13)
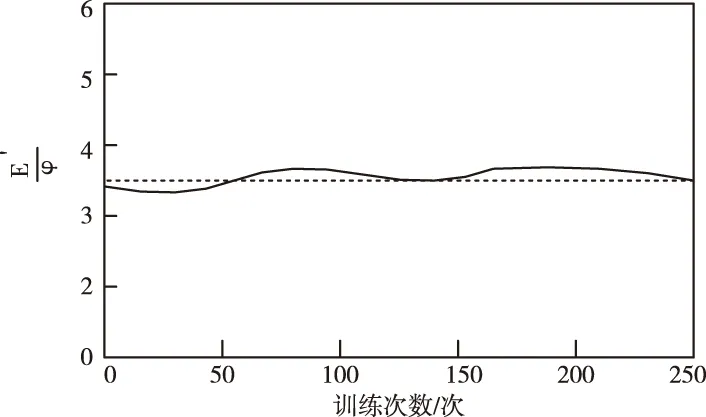
图5 隐私数据分类结果
在确保测算误差较小情况下,分别引入不同大小的隐私数据,对所提模型、结构化数据的隐私与数据效用度量模型与基于隐私偏好的隐私保护模型的测算效率进行对比,实验结果如图6所示。

图6 不同方法测算效率对比图
由图6可知,随着隐私数据量的不断增多,三种方法测算时间均呈现上升趋势。其中,所提方法增长速度较慢,且最短测算时间约为13 s,而其它两种模型的测算时间始终高于所提模型。这是由于神经网络训练性能较好,能够选取较为重要的定量要素,缩短了测算时间。
5 结论
为保证网络虚拟仿真实验室数据的安全性,设计了一种新的隐私度测算模型。首先尝试将隐私差分嵌入到决策树中,在确保测算过程中隐私数据安全性的同时,实现数据隐私级别分类,使数据确定到一定范围中,并进一步进行量化处理;再利用训练的BP神经网络,对隐私数据进行定量测算。与传统该方法相比,所提模型看测算误差控制在允许范围内,且测算的最短时间约为13 s。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
科学与信息化(2019年28期)2019-10-21
上海师范大学学报·自然科学版(2018年3期)2018-05-14
计算机应用(2016年10期)2017-05-12
科学与财富(2016年32期)2017-03-04
现代经济信息(2016年4期)2016-06-20
商业经济研究(2016年6期)2016-03-30
决策与信息·下旬刊(2013年1期)2013-03-11
