
基于相似树查询的隐私大数据定向检索算法
2021-12-10 08:32李盼盼林慧恩
计算机仿真 2021年11期
李盼盼,赵 浩,林慧恩
(1.福建农林大学金山学院,福建 福州 350002;2.福州大学图书馆,福建 福州 350108)
1 引言
数据管理是直接影响网络服务质量的核心要素,如何有效保证信息安全及数据隐私是长久以来网络系统查询处理中最热门的研究课题。数据隐私涵盖用户隐秘信息,倘若此类关键数据被第三方查看或拦截,会对用户安全带来威胁[1]。
为确保数据隐秘性,用户隐私数据多数通过密文形式保存在数据服务方。密文检索是一种云环境下访问数据的关键手段[2],但传统检索模式对加密过的数据处于失效状态。云储存服务器内,数据所有权与管理权互不相关,且用户对数据的操作限制性较多,容易产生隐私数据泄露问题。如何增强用户对数据的操控性,保证隐私大数据检索可靠性,是本文研究的主要内容。
冯在文[3]等使用均匀划分法或自动聚类法对大规模云工作流模型库采取恰当子集划分,融合改进的基于图结构的流程检索算法,设计基于数据集分割的大规模云工作流模型库并行检索方法。但该方法对数据类型要求很高,无法适用于检索多类型数据集合。滕一平[4]等提出一种子序列快速查询算法。对数据集中特定长度下全部子序列实施分组,同时标记出代表性子序列,在查询过程中把查询序列分割为定长小段序列,运用DTW算法明确和小段序列相近的代表子序列候选集,序列拼接候选集,得到查询结果序列。但方法计算时容易出现多个代表性子序列,对序列的筛选工作量较多。
基于上述内容,本文提出通过构建隐私大数据检索系统,利用相似树查询方法得到兄弟叶节点的查询结构,增强检索效率,综合分段融合与数据聚类,实现隐私大数据的准确高效定向检索目标。
2 物-雾-云的三层体系
本文设计的隐私大数据检索系统使用物-雾-云的三层体系结构,如图1所示。

图1 物-雾-云三层结构示意图
系统中,数据拥有者即为数据贡献者,是一个单终端设施。譬如系统用于探测某区域气候,则数据拥有者就是传感器[5]。另外,随机一个智能物理对象均能产生数据,同时把数据传输到距离系统内最相近的雾节点。数据拥有者也可以是一个组织架构。为保障隐私大数据安全,全部上传数据都会加密,且数据拥有者和授权数据用户可密钥共享,得到查询令牌。
雾节点一般部署于网络边缘,担负采集本地数据所有者的全部隐私数据及加密数据集的查询服务。雾节点把加密查询结果与验证目标返回给本地搜查用户,将数量众多的数据访问和运算查询提交至远程公共云服务器内。雾节点可对用户提供计算功能、储存及通信业务。由于密集的地理分布,雾节点能支撑移动性与即时数据解析[6]。其真实设施可为拥有通信及若干数据服务板块的智能路由或切换器。
云服务器处在网络中心,具备大量保存与计算资源,从雾节点接收上传的历史信息。另外针对拥有该计算成本的检索任务,云服务器把处理检索结果返回到对应数据用户的最相近雾节点,最终把结果传递至检索用户。在这种状态下,雾节点仅为云服务器与数据用户间的通信中继设施。
数据用户可为单个移动用户与组织。为保障隐私大数据检索安全性,采用密钥对初始查询实施编码加密。若数据用户发出检索请求,产生的查询令牌会被提交至距离最近的雾节点,数据用户解密结果同时验证数据可靠性。
3 基于相似树查询的隐私大数据定向检索
3.1 基于相似树查询的隐私大数据检索流程
在相似树查询中若数据拥有者任意产生一个(n+u+1)位的矢量当作分割指示矢量S,同时产生两个(n+u+1)*(n+u+1)的可逆矩阵(M1,M2),构成密钥SK={S,M1,M2}。
数据拥有者对各个文档均会产生一个n维的文档矢量DC[i],其中的每位DC[i][j]会记载关键词wj相对目前文档的权重。
用户按照关键字在词典内是否出现,设定Qw,假设出现于词典内,那么相对位置的Qw[i]的解是1,反之为0。任意从u个关键字内挑选v个,在Qw相对位置内设定成1,其它设定成0,最后一维取任意值t,然后产生一个任意值q对Qw的前(n+u)维采取全局变化,得到
Qw=(q*Qw(n+u),t)
(1)
利用陷门Tw,服务器预先算出查询超球体与根节点每个超球体的关联,获得交集最多的某超球体,再按照获得的超球体继续往下一层节点探寻,直至找到叶子节点。推算叶子节点内的文档矢量与查询矢量超球体的中心矢量间距,计算相邻叶子节点的兄弟节点间距,明确间距最短的前k个文档矢量,同时折回k个文档矢量列表。
相似树查询为一种R树的形变过程,使用超球体完成空间划分,相似树自上而下组成,上层节点是刚好遮盖下层节点的全部因素超球体,各个节点通过一个中心点与半径表示,如果此节点是叶子节点,那么中心点就是文档矢量值,如果是中心节点,就代表超球体球心。传统隐私大数据检索算法关于查询返回的k个文档仅查询交集最大的超球体,针对少量交集的超球体没有返回查询步骤,但数据用户所需文档有很大几率在交集很小的超球体内出现,这样就无法符合用户隐私数据查询需要[7-8]。建立索引架构过程中,把相似树叶子节点引入兄弟节点指针中。查询超球体和文档超球体全部交集最大时,此文档超球体邻近的超球体一定会有交集,在查询到叶子节点时,同时查询k个兄弟节点,根据相应比例返回文档列表,减少相关度计算量,获取更高检索效率。
以上述查询算法为基础,引入分段融合算法,确立数据定向谱特征量,从而获得准确的定向检索结果。检索流程如图2所示。
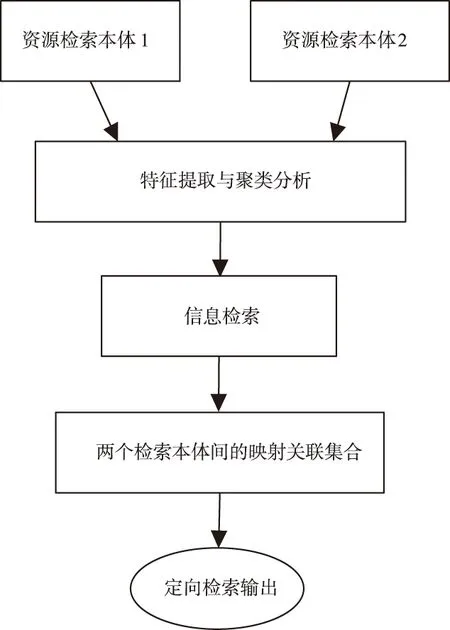
图2 隐私大数据定向检索流程
3.2 隐私大数据资源预处理
隐私大数据资源池网格区域分割表示按照构成实物外形表面类别,把多组数据资源分割为描述不同类型的网格区域,让相同区域的隐私数据资源拥有相等特征,使用网格区域分割法把多种繁杂数据集分成多个子集[9],组建隐私大数据资源池分布式向图G1和G2,获得资源数据库数据特征分类集O,将其输出数据流记作
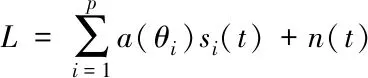
(2)
式中,p表示数据采样点数量,n(t)是定向检索干扰项,si(t)代表扰动特征向量,a(θi)是多种类繁杂数据检索本体架构模型。
在使用网格区域分割手段把多种类繁杂数据集分成多个子集前提下,对海量隐私大数据资源实施匹配滤波检测处理[10],减少冗余数据侵扰,大数据信息流在语义特征分布空间t内的差别性属性分类集是ci,获得大数据资源查询频次是
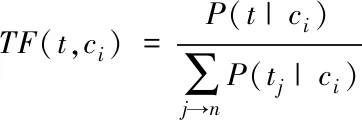
(3)
其中,t是数据检索关联度,融合分段信息融合理念,获得隐私大数据智能检索概率密度特征分布是
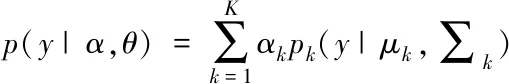
(4)
创建匹配滤波器,将滤波函数记作
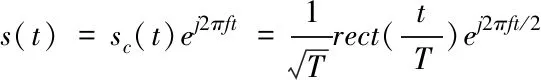
(5)
x(n)=L|s(n)+v(n)|

(6)
其中,s(n)代表原始采样的多种类繁杂数据实向量,v(n)是冗余数据分量。
3.3 基于数据聚类的数据集相关度获取
聚类方法基本原则为:类内样本之间相关度高,类间样本相关度小。如果把各个数据样本当作图内的顶点V,按照样本间相关度把顶点进行赋权,获得一个无向加权图,将图内的聚类问题变成图划分问题。
进行数据聚类时,单个词有可能属于多个类,单个数据可能为多主题数据,这就需要采用模糊聚类手段进行处理。模糊聚类方法具备优秀的弹性,可容许单个词同时属于多个类,单个数据同时属于多个数据类。聚类过程如下:
首先建立表示数据连接的图模型,设定无向加权图表达式为
G=〈V,E,W〉
(7)
V={d1,d2,…,dn}
(8)
式中,V代表对称矩阵,W为边权重,是两个数据间的相关度。
采用模糊分词手段,算出数据词频和数据相关度,把数据粗化的聚类变成无关或相似度很低的f个数据子类。挑选数据的过程分为两步,首先剔除在全部数据库内出现的高频词,然后提取其余数据的词干存进词根表内。采集这些词根构成一个索引词集E。词h在数据集di内权重推导过程为
w_term_document(h,di)

(9)
式中,fih是词h在数据集di中出现的频次,fh是包含词h的数据集个数,L是数据集di内涵盖的索引词个数,N表示数据集内数据个数,w_term_document(h,di)的解代表词h在数据集内的关键性,取值范围为[0,1]。
算出词权重之后,把数据定义为矢量di=(wi1,wi2,…,wis),那么两个数据集di和dj的相关度是

(10)
评估每个数据子类内是否仅存在一个数据类,将其引入和自身高度相似的子类内,变成c*个子图。使用谱聚类方法把各个数据子类再细化聚类,输入c*个子图,利用谱图分割下的聚类算法对各个子图的顶点集Vk=(v1,v2,…,vn)实施聚类,获得各个子图聚类结果和其相对的类型数ki,算出ki的和就是全局聚类数K,实现数据关联属性特征提取。
3.3 定向检索算法实现
对海量隐私大数据资源完成匹配滤波处理,减少冗余数据侵扰前提下,实施大数据定向检索优化设计,结合模糊谱聚类完成数据关联属性特征提取,得到聚类中心函数

(11)
建立语义概念树,按照数据聚类属性实施特征分类,分类统计判定量是
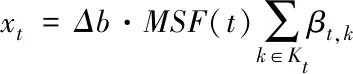
(12)
对随机两种隐私大数据X、Y来说,在数据模糊聚类中心采取数据融合处理,函数解析式为

(13)
式中,P(X)、P(Y)代表检索到数据种类是X、Y的有效几率,P(X∩Y)为联合分布几率。
分析隐私大数据的定向谱特征量,获得大数据检索关联分布中心矢量
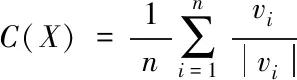
(14)
根据大数据检索关联分布中心矢量检索输出的分类识别,获得最终定向检索结果是

(15)
4 仿真研究
为验证所提算法有效性,实验使用某医疗隐私大数据库,数据库涵盖15个种类数据共8000个文件,数据库训练集内的各个文件均以分类。实验软硬件环境搭配为:Intel Core i5-3570,Windows7操作系统,运用Python语言编程。在同等实验条件下,对本文方法和文献[3]方法及文献[4]方法进行对比实验。实验共分为6组,依次选择50、100、150、200、250、300个文件,选择的文件大小都在1~40kB之间。检索关键字数量为1000,检索请求通过15个关键字构成,每个关键字拥有1~5的权值,用户需要返回8个文件。关于不同文件个数检测三种方法的检索时间,如图3所示。

图3 不同方法检索时间对比
从图3可以看到,在初始阶段,本文方法与文献[3]的方法的检索时间较为相近,伴随文件个数的上升,两个文献方法的检索时间大致展现出线性增长,但本文方法检索时间均低于两个文献方法。所提方法运用相似树查询方法,有效降低相关度计算数量,大幅提升检索效率。
为更直观体现所提方法的应用有效性,选取30×30mm2大小网格,网格内分布50个数据,其中有45个普通数据和5个隐私数据,对网格内的隐私数据进行定向检索,实际数据分布结果如图4所示,并在同等实验条件下,对本文方法和文献[3]方法及文献[4]方法进行对比。

图4 实际数据分布图
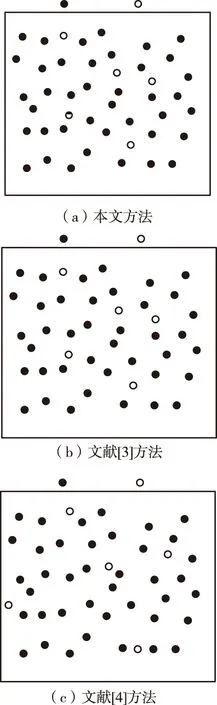
图5 不同方法检索隐私数据结果
由上述结果可知,文献[3]只检索出2个隐私数据,文献[4]虽检索出5个隐私数据,
但其位置分布不准确,相比两种传统方法,本文方法在实际数据定向检索中,其能准确检索出隐藏在普通数据中的5个隐私数据,并能准确找出隐私数据的位置分布。
5 结论
为提升用户隐私数据检索安全性与准确性,设计一种基于相似树查询的隐私大数据定向检索算法。该方法计算简便,检索效率与精度较传统方法均得到显著改善,鲁棒性好。但在大数据资源预处理中,数据匹配滤波检测时效性较短,有必要对其采取进一步优化,更加符合现实操作应用。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
导航定位学报(2022年4期)2022-08-15
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年11期)2021-09-05
数学大王·低年级(2021年4期)2021-04-27
消费电子(2020年5期)2020-12-28
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
新高考·高一物理(2016年1期)2016-03-05
