
人工翻译与神经网络机器翻译译后编辑比较研究*
——基于对隐喻翻译的眼动追踪与键盘记录数据
2021-12-13 09:26湖南大学王湘玲陕西国际商贸学院湖南大学
外语教学理论与实践 2021年4期
湖南大学 王湘玲 陕西国际商贸学院 湖南大学 赖 思
湖南师范大学 贾艳芳
提 要: 本文通过眼动追踪、键盘记录、反省报告和问卷调查多元互证,比较了30名译者对隐喻表达进行人工翻译(HT)与译后编辑(PE)的认知负荷和译文质量。研究发现: 无论是HT还是PE,译文区的注视时间均明显长于原文区,且隐喻译文的准确度均高于忠实度。不同之处含PE中原文区的注视次数、注视时间及单位单词停顿次数均显著少于HT,且隐喻译文的忠实度和准确度均显著高于HT。本研究表明PE在处理隐喻表达时,既可减少译者认知负荷还可提高译文质量。
1. 引言
2. 文献回顾
1) 人工翻译与译后编辑比较研究
译后编辑研究始于21世纪初(Krings, 2001),近年来围绕其与人工翻译过程及产品展开的实证研究层出不穷,其中过程评估多探讨速度和认知负荷。为提高翻译效率,早期实证研究较为关注翻译速度。研究表明译后编辑能有效提高专业文本的翻译速度(O’Brien, 2007; Groves & Schmidtke, 2009; Zhechev, 2014),但其在通用文本中未必具有速度优势。Carl et al.(2011)和Dames et al.(2017) 证实译后编辑在翻译新闻文本时明显快于人工翻译,但也有研究结果显示其对此类文本的翻译速度无明显提升作用(Screen, 2017)。
认知负荷是人工翻译与译后编辑比较研究的另一焦点。因工作记忆有限,译者在高负荷的认知环境下长时工作容易疲劳,导致工作效率下降(Sweller & Chandler, 1991)。认知负荷可通过眼动法和键盘记录法间接测量。反映认知负荷的常用眼动指标有注视时间、注视次数和瞳孔直径(闫国利等,2013),其中注视时间越长认知负荷越大,注视次数越多认知负荷越大(Rayner, 1998),瞳孔直径越大认知负荷越大(Just & Carpenter, 1980)。但瞳孔直径受较多不可控因素影响(如被试情绪、疲劳程度、身体状况等),其能否有效反映认知负荷有待考证。此外,击键数据中的停顿时间和停顿密度也能有效反映认知负荷(Schilperoord, 1996: 11)。停顿时间越长、停顿密度越大,认知负荷越大。O’Brien(2007)比较人工翻译、译后编辑和翻译记忆三种模式,发现译后编辑的认知负荷小于人工翻译。Sekino(2015)从关联理论视角提出译后编辑需同时进行概念编码和程序编码,所耗认知负荷大于人工翻译。此类研究结果差异较大,未得出译后编辑能减轻译者认知负荷的定论。
此外,人工翻译与译后编辑产品比较研究主要围绕译文质量展开。Fiederer & O’Brien(2009)发现译后编辑的准确度和流利度均高于人工翻译。Dames et al.(2017)表明译后编辑和人工翻译的错误数量无明显差异。Guerberof(2009)发现译后编辑的译文质量高于翻译记忆,但不及人工翻译。由于此类研究所采用的机器翻译系统、被试、语言对和质量评估方法各有不同,因此研究结果也各不相同。
整体看来,人工翻译与译后编辑比较研究选题丰富,但研究结果不具普适性,尤其是针对不同文本类型的比较研究结论一致性较低,亟待更多实证研究考证。
2) 语言隐喻的翻译过程实证研究
隐喻分为语言隐喻和概念隐喻两个层面(Lakoff,1993),两者是“相互对立的概念”(Kövecses,2002: 33)。语言隐喻指“由于两个所指之间存在一些真实或隐含的相似性,因此将原用于指代某物的词或词组指代另一事物”(Anderson,1964)。本文探讨的是隐喻的语言表达层面,即“语言隐喻”。
隐喻翻译是翻译学领域的重要研究选题之一(Schäffner,2004)。随着实证研究方法的应用和研究工具的革新,部分学者开始关注语言隐喻的翻译认知过程(孙毅,2017)。Sjørup(2013)在英语译入丹麦语的研究中发现,相比于字面表达语言隐喻在翻译产出阶段所耗的认知负荷明显增多。但Schmaltz(2015)关于汉语译入葡萄牙语的研究则表明字面表达和语言隐喻的翻译认知过程无明显区别。隐喻翻译认知过程研究成果日益丰富也日趋差异化。译后编辑作为信息化时代的一种特殊翻译认知过程,目前针对语言隐喻的译后编辑过程研究尚嫌不足,亟待新的研究方法和工具来进一步推动。Koglin(2015)首次综合使用眼动追踪和键盘记录探究英语译入葡萄牙语时人工翻译与译后编辑的认知负荷差异,验证了隐喻翻译中译后编辑认知负荷小于人工翻译这一假说,为译后编辑运用于隐喻翻译提供了有力支撑,但该结论是否适用于英汉隐喻翻译仍有待验证。
通过广泛的文献梳理,本研究发现,译后编辑和隐喻翻译已引起了学界关注,但鲜有将两者结合进行针对英汉隐喻互译的译后编辑研究,这与当下翻译市场中存在的大量英汉隐喻翻译实践不成比例。目前机器翻译译后编辑模式已在语言服务行业广泛运用。随着市场需求的快速增加与机器翻译技术的不断完善,译后编辑必将受到企业和高校越来越多的关注和重视(Yang & Wang, 2019)。因此,以语言隐喻这一常见语言现象的翻译为例,对比人工翻译考察译后编辑具有重要意义。基于此,本研究采用眼动追踪法和键盘记录法,辅以反省报告和问卷调查探究译后编辑是否适用于隐喻翻译。囿于篇幅,本文所涉及的翻译方向为英译汉,针对英语隐喻汉译提出以下两个假设:
假设一: 译后编辑的认知负荷小于人工翻译;
假设二: 译后编辑的译文质量高于人工翻译。
观察和测量认知负荷的指标包括眼动数据和击键数据。其中,眼动数据主要反映原文和译文阅读阶段的认知负荷,而击键数据则主要揭示译文产出阶段的认知负荷。
3. 实验设计
本实验的自变量为翻译任务,即人工翻译和译后编辑两种翻译模式。因变量为认知负荷和译文质量。认知负荷测量指标为被试在原文区及译文区内的注视次数和注视时间、总停顿时间和单位单词停顿次数(1)单位单词停顿次数的计算公式如下: PWR=停顿次数 /原文总单词数。(Pause to Word Ratio, PWR)(Lacruz & Shreve,2014)。译文质量指隐喻译文的忠实度和准确度。
1) 被试
本研究共招募到30位本地某高校自愿参与实验的翻译硕士,其中包括25名女性,5名男性。被试平均年龄为24岁(SD=3.58),母语为汉语,第二语言为英语,均已通过英语专业八级考试。被试双眼矫正视力均在1.0以上,基本具备盲打能力,且能熟练使用实验电脑上的搜狗拼音输入法。测前问卷显示被试均未曾接触过本实验文本。根据实验需要,30名被试随机平均分为人工翻译组(编号P01-P15)和译后编辑组(P16-P30)。经LexTALE测试(Lemhöfer & Broersma, 2012)(2)LexTALE全名为Lexical Test for Advanced Learners of English,它是一项针对高级英语学习者的词汇测试,用户可在其官网http: / /www.lextale.com /index.html上进行免费测试。检验,两组被试的英语水平无显著差异。人工翻译组直接翻译实验文本,译后编辑组则对该文本的机器译文进行译后编辑。鉴于目前译后编辑研究多选用谷歌翻译系统,为保证同类研究结果的可比性,本研究机器译文产自谷歌NMT。被试参与实验前自愿签署实验知情同意书,并获得一定报酬。实验结束后,30位被试的眼动数据均通过质量评定标准,即屏幕注视总时间高于30%、平均注视时长大于200毫秒。
2) 实验文本
实验文本参考Zheng & Xiang(2014)节选自克林顿2001年离职演说词。该语料真实自然,含有大量语言隐喻,且理解难度适中(3)Lexile指数为1400L-1500L,Flesch Reading Ease得分为55.3。,作为翻译材料可操作性较强。由于眼动实验过程中Translog界面无法滚动,实验文本长度需控制在150词左右((Sjørup,2013)。本研究删除了选段中不影响语义连贯的部分语句,并另邀两名母语为英语的评估员检验文本的可读性和可理解性,以确保实验文本语义流畅且无歧义,最终确定实验文本长度为157词。本研究根据语言隐喻的定义,并参考《麦克米伦高阶英语词典》(Rundell, 2001)和《牛津高阶英汉双解词典》(Hornby, 1997),最后确定实验文本中语言隐喻为7处。
3) 数据收集方法
本实验的眼动数据由EyeLink 1 000+(1 000 Hz)遥测式桌面眼动仪采集,击键数据由Translog II键盘记录软件记录,Audacity2.1.0录音软件记录反省报告,问卷星收集调查问卷数据。所有被试在同一台电脑上完成翻译任务。被试距离电脑屏幕50-60厘米,电脑屏幕分辨率为1 024×768。原文和译文在屏幕上以上下分割方式呈现。英文字体为Times New Roman,中文字体为宋体,字号为16,行间距为2倍(见图1)。本实验在隔音且光线稳定的眼动实验室内进行,以减少噪音和光线对眼动数据的干扰。
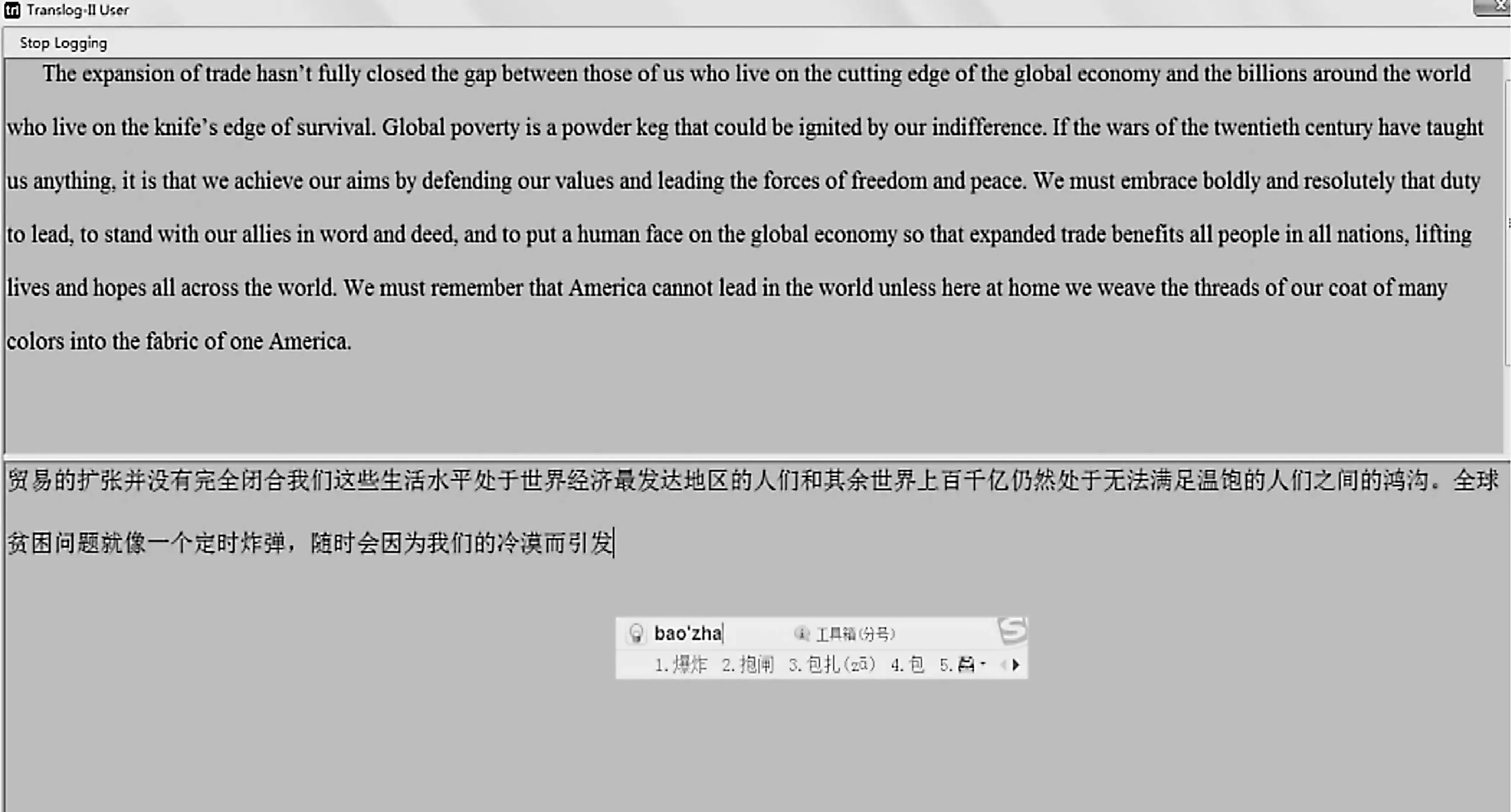
图1. Translog II操作界面(P01)
4) 实验流程
本实验包括三个阶段,分别是前期培训、热身阶段和正式实验阶段。前期培训为被试介绍眼动实验室环境,发放实验流程和注意事项表,译后编辑组另发放一份译后编辑指南(4)参考TAUS(2010),译后编辑指南如下: (1) 确保原文信息传达准确完整;(2) 确保没有意外的増译或漏译;(3) 确保译文拼写和标点正确;(4) 修改任何不符合中文规范和文化上不可接受的内容;(5) 尽可能多保留机器翻译原始译文。。被试了解实验任务后填写实验知情同意书和背景信息问卷。被试在热身阶段即处于正式实验环境,要求其翻译一篇50词的英译中热身文本。正式实验阶段中两组被试均要求遵循以下三个流程: (1) 校准瞳孔位置后,Translog II界面显示实验文本,翻译任务开始,不允许搜寻任何外部资源,不设时间限制,译文质量达到可发表水平即可结束;(2) 通过Translog II的回放功能,被试逐一回顾实验文本中七处隐喻的翻译问题及应对策略,并进行反省报告,全程被录音;(3) 填写测后问卷。整个实验过程约用时60分钟。
5) 数据处理
本研究参照Carl et al.(2016)将记录有30名被试击键数据和眼动数据的Translog XML.文件上传至YAWAT网站进行手动对齐后获得所有用户活动数据(user activity data),再根据眼动数据和击键数据切分出7处语言隐喻,编号为M1,M2……M7。根据研究问题,划分Translog II界面上半部分为原文兴趣区域(ST AOI),下半部分为译文兴趣区域(TT AOI)。最终数据采用SPSS 19.0进行统计分析。
4. 结果与讨论
本研究采用多元互证模式(Alves,2003),综合分析眼动追踪与键盘记录的定量数据和反省报告与问卷调查的定性数据,研究结果如下。
1) 研究假设一: 译后编辑的认知负荷小于人工翻译
认知负荷测量指标包括原文和译文区M1至M7的注视时间、注视次数、总停顿时间和单位单词停顿次数。因指标较多,眼动指标和停顿指标将分类考察。
(1) 眼动指标
本小节考察原文区和译文区M1-M7的注视次数和注视时间。对人工翻译和译后编辑两组实验数据进行独立样本t检验,以检验组间均值是否具有显著差异。在t检验前,本研究利用Shapiro-Wilk检验进行分析,结果显示数据总体服从正态分布。如表1所示,各指标的均值差与研究假设一相符,进一步统计分析发现译后编辑时原文区和译文区的注视次数与注视时间分别比人工翻译时少41.54%、14.34%、50.84%和31.02%。
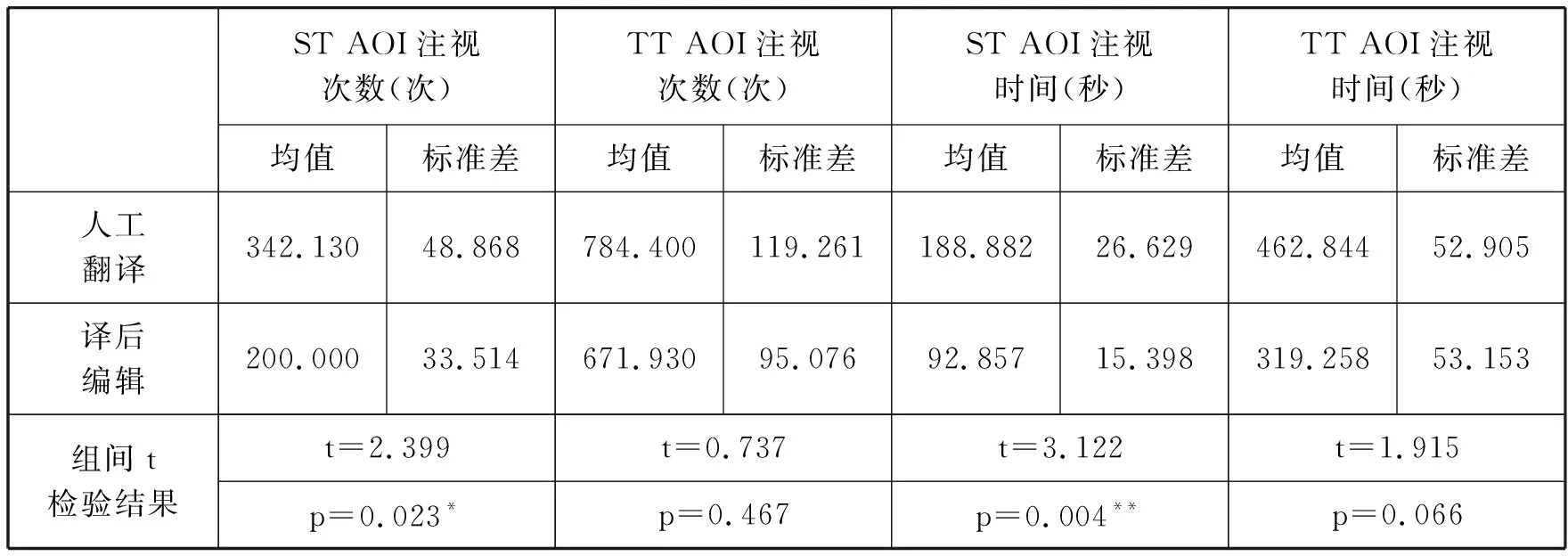
表1. 人工翻译、译后编辑中ST AOI和TT AOI的注视次数与注视时间
表1中各指标的独立样本t检验结果显示,原文区注视次数和注视时间的组间均值有显著差异(分别是t=2.399,p=.023;t=3.122,p=.004),表明译后编辑时原文区注视次数和注视时间明显少于人工翻译。但译文区注视次数和注视时间的组间差异则不显著(分别是t=0.737, p=.467;t=1.915,p=.066),尚不能证明译后编辑时译文区注视次数和注视时间少于人工翻译。该发现与Carl et al.(2011)、Lourenço da Silva et al.(2015)和卢植、孙娟(2018)的研究结果基本一致,原文区注视次数和注视时间的组间差异显著,译文区则无显著差异。究其原因,人工翻译和译后编辑中的原文功能及译者对原文的认知机制均不相同。译后编辑时,译者基于原文评估机器译文质量并决定采用何种修改策略。译者通常“先阅读一段机器翻译原始译文,再将其与对应的原文比较,然后对机器译文进行修改”(Carl et al.,2011)。译后编辑为译者提供了机器翻译原始译文,译者只需修订其中的错误和不足之处,节省了重新理解原文和输出整篇译文所需的认知努力。相比而言,人工翻译则更多是基于译者对原文的深度理解,因此其原文加工的认知负荷更大。从某种程度来说,人工翻译更趋向于以原文为中心,而译后编辑则更以译文为中心。但需要注意的是,本研究的所有被试均未接受过译后编辑培训。若译者对译后编辑这一任务更为熟悉,其注视行为也可能会发生变化。
本研究还通过比较注视时间来进一步探讨了人工翻译和译后编辑在处理隐喻表达时的注视行为。图2显示了30名被试的注视时间在原文区和译文区的分布情况。

图2. 人工翻译、译后编辑中ST AOI和TT AOI的注视时间分布情况
如图2所示,无论是人工翻译还是译后编辑,译文区注视时间均长于原文区(P14除外),即译者都将更多的认知资源分配在了译文产出而不是原文理解上。这与Carl et al. (2011)、Daems et al. (2017)等的研究发现一致。在译文产出阶段,译后编辑需对机器翻译原始译文进行反复修订,而人工翻译则涉及译文输出、监控、修改等一系列认知活动,可见人工翻译和译后编辑中译文产出的认知负荷均大于原文理解。另外,所有被试中仅有P14在原文区的注视时间长于译文区。击键数据也显示P14的译文产出过程修改行为较少。其原因可能如反省报告所示,P14在进行人工翻译时受生词制约,花费了大量时间运用语境来推断隐喻含义,因此不愿再花过多时间来反复修改译文。
(2) 停顿指标
停顿时间和单位单词停顿次数的统计结果见表2。两个指标的均值差与研究假设一相符: 经计算译后编辑中停顿时间和单位单词停顿次数分别比人工翻译时少18.71%和41.66%。
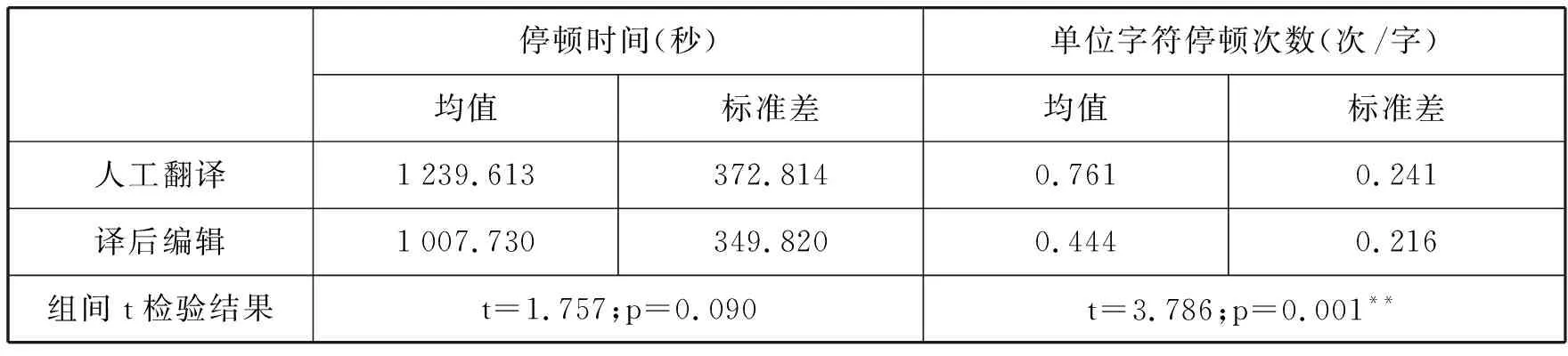
表2. 人工翻译、译后编辑的停顿时间和单位单词停顿次数
表2中独立样本t检验结果显示单位单词停顿次数的组间差值具有统计显著性(t=3.786, p=.001),表明译后编辑时单位单词停顿次数少于人工翻译,支持研究假设一。停顿时间组间差值无统计显著性(t=1.757,p=.090),即译后编辑停顿时间并未显著短于人工翻译。
本研究发现译后编辑时译者的单位单词停顿次数显著少于人工翻译,这与Schaeffer et al. (2016)和Jia et al.(2019b)的研究发现一致。单位单词停顿次数少即停顿密度小,说明在处理隐喻表达时译后编辑的认知负荷小于人工翻译。译后编辑的主要目的在于通过充分有效利用机器译文产出符合一定质量标准的译文。当机器译文基本满足译文质量标准时,译者无需投入更多认知努力来寻找其他译文。人工翻译则不同,译者通常会努力寻找灵感,针对原文产出多种待选译文表达,最终择优而译。这在反省报告中可找到大量相关解释。以M3(the knife’s edge)为例,译后编辑组被试P24直接采用了机器译文“刀刃”,因其认为机器译文既传达了原文意思,表达又十分形象。人工翻译组被试P2则最终在“刀刃”、“生存边缘”和“水深火热”三种表达中选择了后者。可见,译后编辑能在一定程度上节省译者搜索内部资源和翻译决策所需的认知努力。
研究结果还显示译后编辑停顿时间均值小于人工翻译,但无统计显著性。原因之一可能是本研究部分被试未能严格遵循译后编辑指南。指南要求被试“尽可能多保留机器翻译原始译文”,但反省报告显示部分译后编辑组被试(如P18和P25)因过于追求译文的政治演讲风格,对机器译文进行反复修改,因而未能遵循此要求,导致无法有效利用机器译文。Christensen(2014)指出译后编辑者不遵循译后编辑指南的原因主要在于其缺乏正规译后编辑培训。目前国内译后编辑人才培养相对滞后,值得业界学界关注。其二,停顿时间能否有效反映认知负荷有待更多实证研究考察。O’Brien(2006)指出停顿不能单独作为认知负荷的测量指标,须与其他指标多元互证才可保证研究信度。
综上所述,原文区的注视次数、注视时间和单位单词停顿次数支持研究假设一。译文区的注视次数、注视时间和停顿时间的描述统计数据与假设一相符,但无统计显著性,因此不能验证该假设。
2) 研究假设二: 译后编辑的译文质量高于人工翻译
本研究参考翻译自动化用户协会(TAUS, 2013)提出的动态翻译质量框架(Dynamic Quality Framework,简称DQF)和项霞、郑冰寒(2015)的翻译质量评估标准,以忠实度和准确度为评分参数。其中忠实度指译文正确完整传达原文信息的程度,准确度指译文表达符合译语语言规范的程度。每个维度划分为4个等级,译文得分依次为1—4分。10位评分者独立匿名给30名被试的隐喻译文打分,最后打分的平均值为译文最终得分。具体译文评分标准见表3。
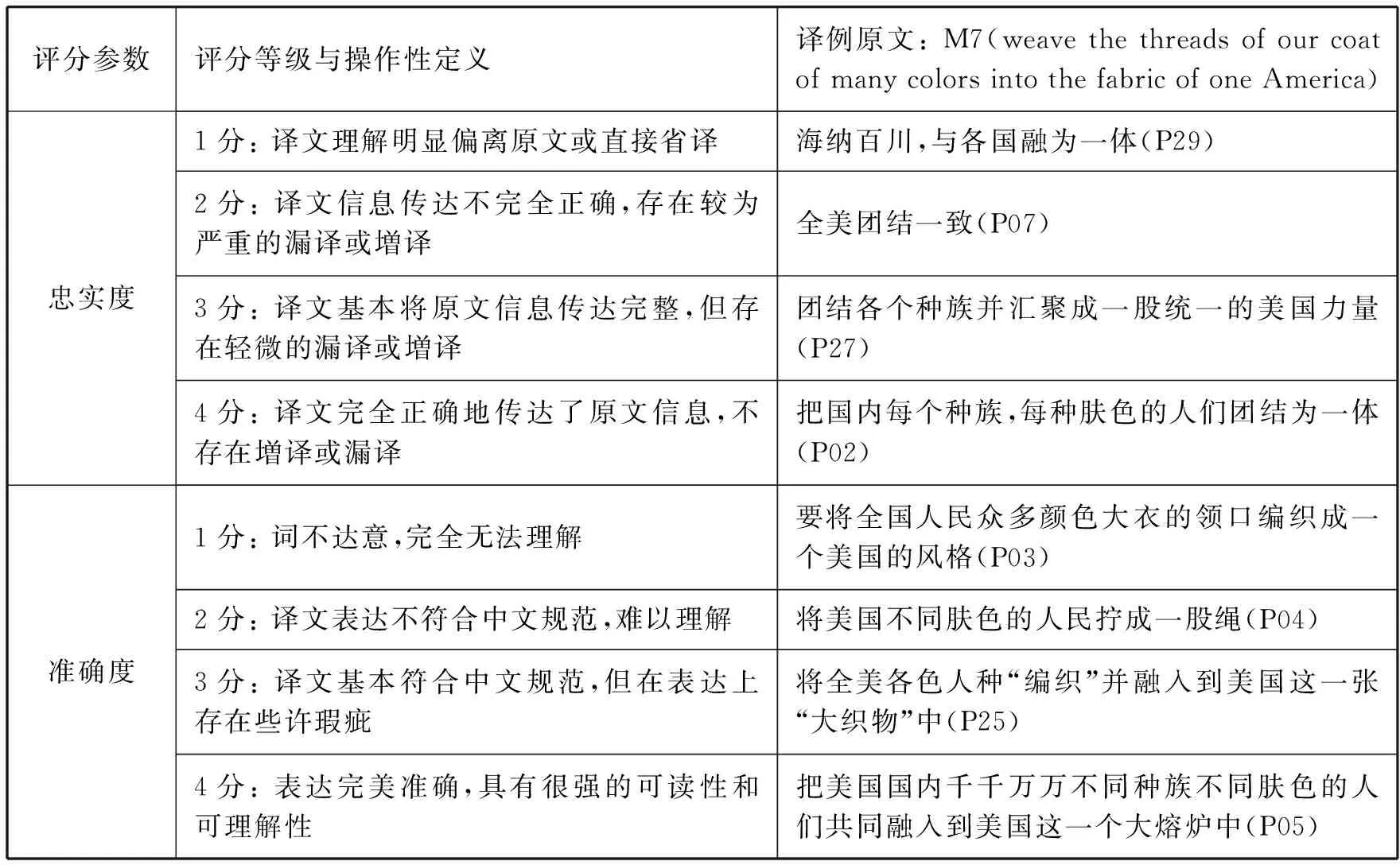
表3. 隐喻译文评分标准及示例
依据上述评分标准对30名被试的210处隐喻译文进行评分,译文得分统计结果见表4。本研究比较组间均值发现,译后编辑隐喻译文忠实度和准确度得分分别比人工翻译高出12.10% 和8.34%,其中译后编辑对忠实度的提升效果更为明显。问卷结果显示人工翻译组中60.00%的被试表示生词是造成其隐喻翻译困难的主要原因,与之对应的译后编辑组被试仅占13.33%。可见机器译文能有效减少因生词导致的隐喻理解不当,从而提高译文忠实度。
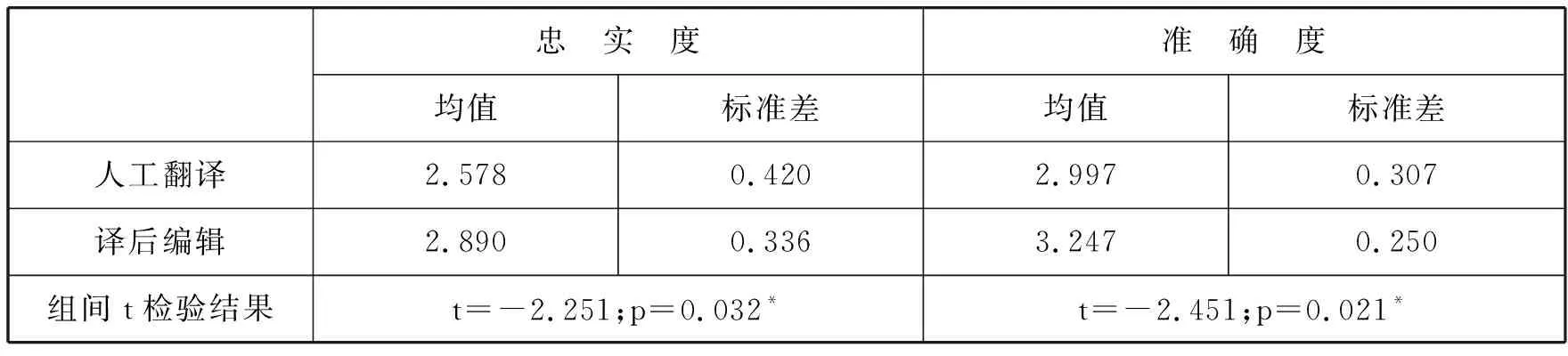
表4. 人工翻译和译后编辑隐喻译文的忠实度和准确度得分
表4中独立样本t检验结果显示,忠实度和准确度的组间差值均具有显著差异(分别为t=-2.251,p=.032; t=-2.451,p=.021),即译后编辑译文质量显著高于人工翻译,支持研究假设二。这主要是因为机器译文既能有效帮助被试理解语言隐喻,又能为隐喻译文表达提供参考。Ortony et al.(1978)将隐喻理解划分为两个阶段: 1) 根据字面意思理解、识别其与语境之间的语义或语用冲突;2) 推断其隐喻意义。机器译文通常为被试提供了隐喻的字面意义,可为被试省去隐喻理解第一阶段。这在反省报告中可得到验证。译后编辑组被试遇到生词时会迅速查看机器译文,如机器译文中的“火药桶”一词帮助部分被试成功理解了M3(a powder keg)的意思。另外,隐喻翻译的难点有时并非理解不当,而是未能找到准确流畅的译文来表达。此时机器译文便能发挥参考作用,如译后编辑被试P19在翻译M6(Put a human face on)时受机器译文“树立人性的面貌”启发,引申出“闪耀人性的光辉”这一译文。综上可见,译后编辑能有效增加隐喻理解的忠实度和隐喻表达的准确度,从而提高隐喻译文整体质量。
随后,本研究对比30名被试隐喻译文的忠实度和准确度得分发现其准确度得分均高于忠实度得分(P02除外,其译文忠实度和准确度得分基本持平)(见图3)。
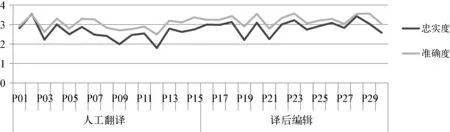
图3. 被试的隐喻译文忠实度和准确度得分情况
5. 结语
本研究比较了人工翻译和神经网络机器翻译译后编辑在处理语言隐喻时的认知负荷和译文质量。研究假设一“译后编辑的认知负荷小于人工翻译”有原文区注视次数、注视时间和单位字符停顿字数三组指标支持。但译文区的注视次数、注视时间和停顿时间无组间显著性差异,不能验证该假设。研究假设二“译后编辑的译文质量高于人工翻译”得到了完全验证,即译后编辑的隐喻译文忠实度和准确度得分均显著高于人工翻译相应得分。本文结论还有待进一步研究验证,如扩大实验规模(增加被试人数和隐喻样本量)、增设研究对象分类、增加隐喻英汉互译对比等,以更全面地考察人工翻译和译后编辑在处理语言隐喻时的差异,从而提高研究结果的普适性。
综上,本研究初步证实在处理语言隐喻时,神经机器翻译译后编辑具有人工翻译难以比拟的效率和质量优势。在欧美等诸多国家和地区,机器翻译已成为语言服务行业的核心技术,机器翻译译后编辑模式也已广泛应用于语言服务行业。随着人工智能的不断发展,机器翻译质量势必会越来越高,全球化和信息化的快速推进也将使机器翻译译后编辑模式在未来的应用前景更为广阔。国内相关业界和学界应顺应信息化发展趋势,努力为推动国内机器翻译译后编辑理论模型构建与翻译人才培养做出贡献。
猜你喜欢
中国神经再生研究(英文版)(2022年2期)2022-08-08
汽车实用技术(2022年7期)2022-04-20
载人航天(2021年5期)2021-11-20
商用汽车(2021年4期)2021-10-13
作文周刊·小学一年级版(2021年36期)2021-01-14
阅读与作文(小学高年级版)(2020年8期)2020-09-12
大自然探索(2019年7期)2019-12-13
小天使·二年级语数英综合(2017年12期)2017-12-05
小天使·二年级语数英综合(2017年3期)2017-04-01
小学生时代·大嘴英语(2006年1期)2006-06-06
