
一种高冲突修正的区间证据水质数据融合研究
2021-12-14 07:41肖棋森李奉笑巫涛江赵明富程正富
重庆理工大学学报(自然科学) 2021年11期
肖棋森,汤 斌,李奉笑,肖 渝,巫涛江,2,赵明富,程正富
(1.重庆理工大学 重庆市光纤传感与光电检测重点实验室, 重庆 400054;2.电梯智能运维重庆市高校工程中心, 重庆 402260 )
地表水的安全问题关系社会生活的各个领域,对水质分类的研究十分重要。在水质参数中,各种数据存在难以统一化的问题。采用多传感器的综合判断可避免局部单传感器的错误判断影响全局的弊端[1-3]。数据融合作为一种处理数据的手段,能够消除单数据源的冗余和矛盾[4]。处理传感器测量的数据时,常见的2种融合方法有Dempster-Shafer证据理论(D-S证据理论)[5-9]和贝叶斯方法[10-11]。贝叶斯方法提供了一种计算假设概率的方法:在先验概率给定和充足的数据概率观察分析下才能得到有效融合[12],但大多数情况下,这2种条件不会满足。此时,D-S证据理论会成为这类不满足条件的最优解。由于融合得到不错的结果,关注和研究也越来越多[13-15]。D-S证据理论满足的条件比贝叶斯更宽松,能够清晰地表达不确定和不知道。但该组合规则的优势在于证据理论间冲突较小的情况。如果证据理论冲突较高时,会得到与认知相悖的结论[16-19]。
周剑等[20]运用区间数与证据理论结合,认为在表达缺乏的信息以及数据的不确定性时,区间数是一个很好的选择[21-22],根据识别框架决策水质等级,但其假设参数条件太多。唐菁敏等[23]提出了一种高冲突情况下的水质多参数区间数据融合理论。选择最重要的水质参数,合理地通过区间数生成信度后对数据进行高冲突判断,修正高冲突的证据,尽可能多地保留有效原始数据。
1 实验部分
通过传感器收集需要的水质数据。[EX]表示收集的样本区间数。利用区间数计算出数据与识别框架之间的距离,得到BPA。区间数中用[D]i={D1…D5}表示传感器i的样本跟识别框架Θ的第Ⅰ类水质到第Ⅴ类水质的距离。区间数相似度[S]i={S1…S5}表示传感器i的样本跟识别框架Θ的第Ⅰ类水质到第Ⅴ类水质的相似度。归一化区间数相似度,用[BPA]表示,[BPA]代表样本的基本信度分配。最后,对数据进行冲突修正,修正高冲突数据后,运用证据理论进行融合。得到的结果可作为最后判断水质等级的依据。
1.1 框架模型
设一个亟需解决的问题,用完备集合表示这个问题所有能认识到的可能答案,且这些元素都是互斥的;在任何时间,完备集合中的某一元素有对应的答案,且答案可以是数值变量或非数值变量。根据《国家地表水环境质量标准(GB3838—2002)》中对水质的分类,得到5类数据值。参考国家标准,令识别框架Θ={Ⅰ,Ⅱ,Ⅲ,Ⅳ,Ⅴ},每个水质等级都有一定的范围。实验中,该范围用来判别水质的主要区间。区间证据理论融合模型如图1所示。
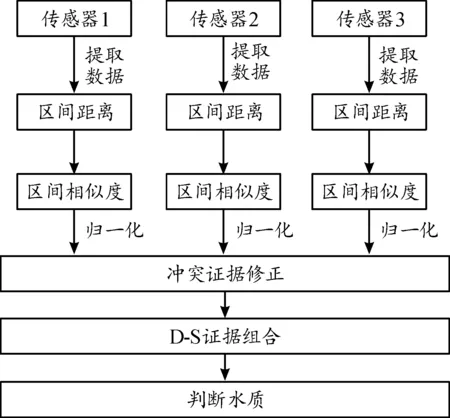
图1 区间证据理论融合模型框图
1.2 基于区间相似度的BPA生成方法
实验的首要问题是如何将传感器测量的原始数据转化成有效数据。由于传感器测量的值会在一个范围内进行波动,所以区间数能很好地表达提取的数据。计算区间距离、区间相似度后进行归一化可得到BPA。设a是一个在实数a-与a+的一群数,则a是一个区间数。式(1)中a为测量得到的样本数据范围,b为识别框架下某个具体的参数范围。计算得到区间数a、b之间的距离为:

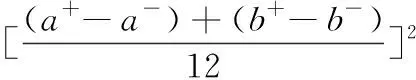
(1)
区间数相似度[14]越小,则代表a与b相差越小。这里,α是大于0的支持系数,D(a,b)为区间a和b的距离。容易证明,当a=b时,S=1。当a、b的距离越大时,S越小。离散程度主要由支持系数来调节,调节后的相似度对证据理论融合有一定的影响,其计算式为:
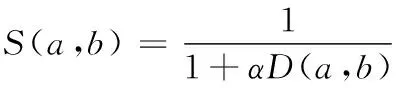
(2)
在识别框架Θ中,基本概率赋值m表示集合2n到[0,1]的映射。这里的S(a,b)相当于基本概率赋值m,其中m(A)称为事件A的基本概率分配(basic probability assignment,BPA)函数、基本信度分配函数或mass函数。BPA值的大小反映了用来计算的证据对命题A的支持程度,占比见式(3)。其中,m(φ)=0,反映了证据对于空集不产生任何支持度。
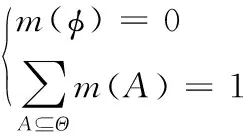
(3)
1.3 冲突系数K的修正
冲突系数K用于衡量证据之间的冲突程度。当冲突较小,也就是K值接近0时,组合规则能够完全满足期望。完全冲突时,也就是k=1时,DS证据合成规则会失效。冲突系数接近1时,若直接使用合成规则会产生与直觉相悖的结论[24]。因此,对证据的修正必不可少。规定识别框架Θ={A1,A2,…,An},An>2。假定每个元素共有n组证据,用m(Ak) 表示元素Ak的基本概率赋值。
1) 平均BPA:求n组证据的平均BPA,式(4)表示Ak的平均值BPA:
(4)
2) 证据距离:计算每个证据体与平均BPA之间的距离,式(5)表示第i个证据体的证据距离:
(5)
3) 权重:由证据距离计算权重,式(6)表示第i个证据体的权重:
(6)
(7)
4) 冲突证据的确立:权重小于平均权重的证据体需要修正。
5) 修正证据:式(8)为第i个证据体的修正系数,式(9)为第i个证据体修正后的Ak,式(10)为修正后的模糊度。
(8)
(9)
(10)
对于修改后的证据,由于修正系数小于1,所有BPA值一定会下降,模糊度同时也会增加。原始数据加上修改后的BPA组合规则后的证据,能达到降低证据之间冲突的效果。根据式(4)~(10),对证据理论进行的冲突系数进行分析。由于可能存在冲突的证据只会是个别数据,所以只需着重修改这一部分。尽可能多地保存数据是为了避免修改过度导致原始数据失去可靠性,因此仅修正存在冲突的证据。经过修正后的[BPA]用[m]来表示(无论是否进行修正,都用[m]来表示)。由于修正的存在,会得到一个不确定度。
1.4 数据融合
将[m]进行DS数据融合,得到最终的信度M。融合后的M能用来根据框架判断水质。融合公式称作证据合成公式,也称Dempster-Shafer证据合成规则,定义如下:
对于∀A⊆Θ,识别框架Θ上的n个信任函数,m1,m2,…,mn焦元分别为A1,A2,…,An:
(m1⊕m2⊕…⊕mn)(A)=
(11)
其中,冲突因子K的大小反映了证据冲突程度是否剧烈。
(12)
融合证据中的m1、m2、…、mn代表每条信度,A代表识别框架Θ中Ⅰ~Ⅴ,m1(A1)、m2(A2)、…、mn(An)代表在识别框架下每个信度的具体概率。融合数据后得到一个可靠的数据,代表当前水质的信任概率,数值越高,表示越能支持该框架下的分类,数值越低,则代表越不支持该框架下的分类,需满足概率相加为1。
2 结果与讨论
实验数据为3个传感器的参数,分别有溶解氧DO、氨氮NH3-N和化学需氧量COD。采用2018年重庆朱沱3个月的水质数据作为来源,得到区间数如表1所示。

表1 样本区间数 mg/L
建立框架。根据《国家地表水环境质量标准(GB3838—2002)》中对水质的分类,得到5类数据值(见表2)。识别框架Θ={Ⅰ,Ⅱ,Ⅲ,Ⅳ,Ⅴ}。例如,第Ⅰ类水质参数的溶解氧为[7.5,10],氨氮为[0,0.15],化学需氧量为[0,2]。

表2 水质参数特征值
求取BPA值。取样本区间[EX]={[7.44,8.9],[0.13,0.28],[2.4,2.8]},[EX]DO=[7.44,8.9]。根据式(1)求得样本DO与水质的距离[D]DO={1.281 9,1.657 3,2.762 8,4.288 0,5.714 3}。其中,第1个数值1.281 9表示采集的样本DO与水质为Ⅰ的区间距离。图2表示了溶解氧、氨氮及化学需氧量与水质Ⅰ~Ⅴ的距离,数值越小,代表越接近该等级,数值越大,代表越偏离当前等级。
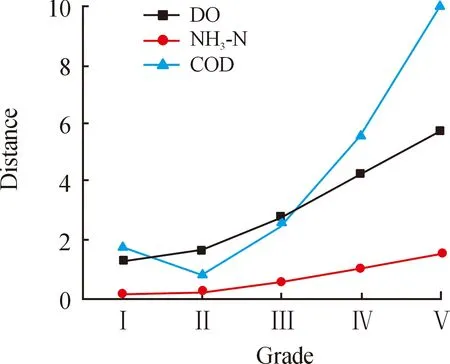
图2 溶解氧、氨氮、化学需氧量与水质等级的距离关系
根据式(2),求得DO的相似度(支持系数α=5),[S]DO={0.135 0,0.107 7,0.067 5,0.044 6,0.033 8}。图3表示溶解氧、氨氮以及化学需氧量与水质Ⅰ~Ⅴ的相似程度,相似度越小,代表与当前等级越不相似,相似度越大,代表与当前等级越相似。
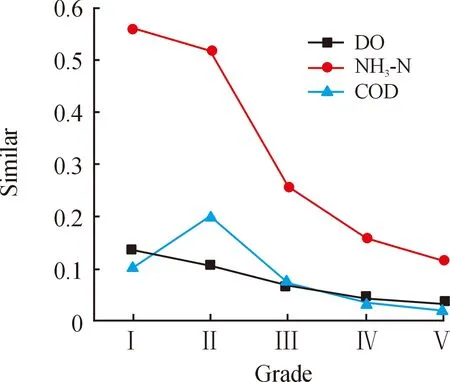
图3 溶解氧、氨氮、化学需氧量与水质等级的相似度关系
对相似度做归一化处理,得到DO的BPA,[BPA]DO={0.347 4,0.277 2,0.173 7,0.114 7,0.087 0}。同理,得到氨氮和化学需氧量的BPA。将得到的数据描绘成图像,得到如图4的BPA结果。图4表示溶解氧、氨氮、化学需氧量与水质Ⅰ~Ⅴ的基本信度分配,数值代表该参数为当前等级的概率。
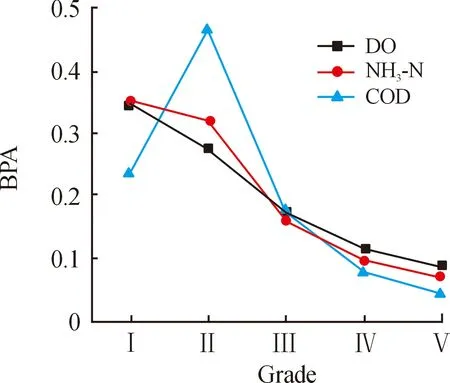
图4 溶解氧、氨氮、化学需氧量与水质等级的基本信度分配关系
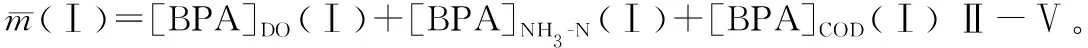
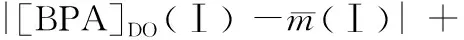
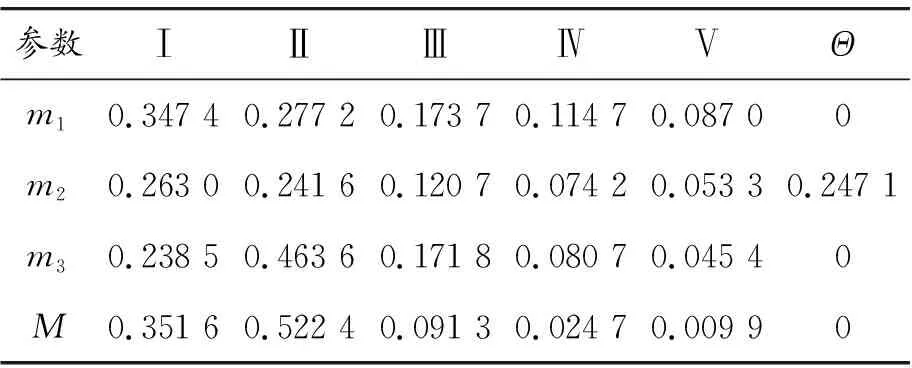
表3 数据融合修正
表1是水质的样本区间值,DO、NH3-N和COD是选取的重要参数。将该数据根据值的大小确定上下限后整合成一个数据区间,表示此次数据都在该范围内。表2是国标水质的区间化,左值和右值代表了当前水质类别的最小和最大值。图2~4和表3是DO、NH3-N和COD这3个参数的BPA生成步骤,如DO在Ⅰ下的[D]DO表示当前水质DO与第Ⅰ类的区间数距离为1.281 9。同理,[S]DO代表与第Ⅰ类的区间相似度为0.135 0。[BPA]DO是归一化后的相似度。对冲突证据处理后的数据如表3,引入不确定度Θ。m1、m2、m3,代表经过处理的[BPA]DO、[BPA]NH3-N、[BPA]COD。从表3可以看出,本次样本中与其他证据产生冲突的是NH3-N的BPA,本次处理后产生的不确定度为0.247 1。DO、NH3-N和COD的BPA按照DS规则组合后形成的M是融合结果,如0.351 6代表了本次水质为Ⅰ类的信度。通过该操作步骤能得到对水质的支持度。
实验中用框架对水质的国标进行分类。提供了一种基于区间相似度的BPA生成方法,系数α用于调节相似的生成,视情况可向上取值。对数据NH3-N进行冲突修复,得到0.247 1的不确定度。由于冲突修复是选择权重小于平均权重的BPA进行修复,那么始终会有不需要修复的数据,即不确定度为0。易知最后通过D-S证据理论融合得到的不确定度也必然为0。因此,在水质Ⅰ~Ⅴ范围一定有一个概率最大的值,这个值对应的就是当前水质分类。
3 结论
基本概率分配由基于区间距离和区间相似度生成,能有效操作数α的值使得相似度有一定调节空间。D-S融合规则能有效降低各数据之间的融合冗余。冲突系数K根据权重方法判断,既能保证有冲突的证据被筛选出,又能保证原始数据尽量多地保存,不会因数据被过多修改而影响数据原本的表达。进一步说明所提出方法具有较高的鲁棒性。区间的存在使传感器数据能够较好地保留,实现对水质等级的判断。区间数保证了传感器测量的水质在一个范围内的真实情况及浮动范围,进而有效利用原始数据。冲突修正能避免传感器测量不准确导致的高冲突证据与经验或实际情况完全相悖的结果。基于D-S证据理论的数据融合可使足够多的参数起到决策性的作用。使用融合后的结果能清晰地了解每个等级的支持度概率,从而迅速判断水质当前所处等级。
猜你喜欢
能源环境保护(2022年4期)2022-08-19
辽宁石油化工大学学报(2022年3期)2022-07-18
农业环境科学学报(2022年2期)2022-03-18
山东理工大学学报(自然科学版)(2022年2期)2022-01-19
快乐语文(2021年35期)2022-01-18
绿色科技(2020年16期)2020-10-13
——基于体育核心期刊论文(2010—2018年)的系统分析
体育科学(2020年2期)2020-04-09
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
旅游纵览(2015年8期)2015-09-25
科技视界(2015年25期)2015-09-01
