
基于多特征的数字图书推荐算法
2021-12-17 00:56李冬
智能计算机与应用 2021年6期
李冬
(商丘职业技术学院,河南 商丘 476001)
0 引言
伴随着信息技术的高速发展,数字媒体技术日新月异,大量的数字资源的诞生和普及,对数字资源服务也提出越来越高的要求,如何从海量的数字图书中,根据相关的数据信息,为读者提供高质量、差异化、个性化的图书推荐愈发重要。提高图书推荐的效率和准确率,提高读者的满意度、粘合度是各种数字图书平台努力的目标和方向。
基于各种算法建立起来的数字图书推荐系统是根据读者的个人偏好,提供差异化图书推荐的有效方法。算法是推荐系统高效、准确运行的基础和关键,目前推荐系统常用的算法有基于内容的推荐算法、基于知识的推荐算法、基于关联规则的推荐算法、基于协同过滤推荐算法以及基于模型的各类推荐算法[1]。以这些算法建立起来的推荐系统通过对用户历史行为数据的分析,得出用户的真实需求,向用户推荐相关的产品及信息,随着正反馈结果的不断提高,加强了用户和平台间的紧密度,实现用户链式反应增值,这些推荐系统在电子商务、音视频推荐、新闻、图书等很多领域已经取得的广泛的应用,产生了很好的经济效益和社会效益。
数字图书和普通图书相比在数据信息和数据质量上更加的丰富和准确,读者对数字图书的评价可以更加的便捷、有效,数字图书的名称、简介、评论、作者、出版社、出版时间、上线时间、搜索量、浏览频次、页面停留时间等因素都可能会影响读者的兴趣偏好。基于某一特征建立起来的推荐系统,在一定程度上欠缺了对其它影响因素的考虑,在推荐的有效性上略显不足。因此,本文提出一种融合数字图书多项特征的推荐算法,并以此为基础建立推荐模型。
1 多特征数字图书的数据处理
通过对多个数字图书管理系统中的数据研究发现,数字图书的数据属性主要有名称、简介、评论、作者、出版社、出版时间、读者信息、图书评分等等。找到合适的方法,融合这些数据,以此为基础构建数字图书的推荐方法,下面介绍各种数据特征的处理和模型构建。
1.1 数字图书简介信息的数据处理及特征提取
数字图书简介信息主要采用文本展示,基于卷积神经网络CNN 在文字识别中表现出较好的识别效果,并且对于未知样本的类标号也具有较好的预测性,本文采用卷积矩阵分解ConvMF 的算法,对数字图书简介信息进行处理,得到数字图书预测评分矩阵P1。
忽略标点符号、空格等无效信息,通过Word2Vec模型计算得到数字图书简介信息的词向量矩阵,输入CNN 中。每条数字图书的最大简介信息单词数为max_lenth=300,超出单词直接截断。所有数字图书简介信息单词形成序列L,基于数据库中数据大小的考虑,选取出现最多的前2 000个单词组成列表Vs,用UNK 对应的词向量表示仅在L 中出现的单词。数字图书简介信息组成m × n矩阵,m为简介信息的单词序列,n为每个单词向量维度;如若卷积神经网络输出的数字图书分类类别为未知,则视未知类别数字图书特征向量为V1。
定义读者数量为M,数字图书数量为N,Ui表示读者特征向量,Vj表示数字图书特征向量,Rij表示读者i对数字图书j的评分,W为卷积神经网络中的权重向量,Wk为第k列元素,ε表示读者整体评分矩阵R与读者、数字图书的特征向量内积之差的方差,εu、εv、εw分别为读者特征向量矩阵U、数字图书特征矩阵V和卷积神经网络中内部权重W的方差。结合公式(1),利用随即梯度下降法求解U和V。
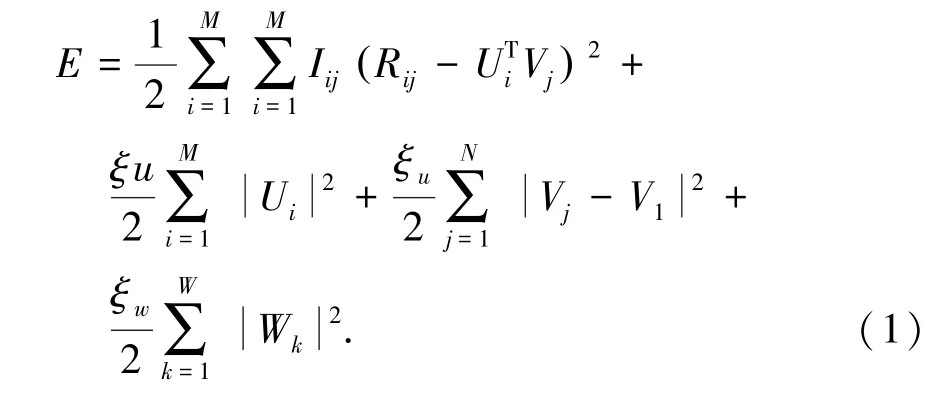
卷积矩阵分解算法中引入概率模型优化矩阵分解,利用已知数据预测评分矩阵中的未知值,将上文得到数字图书特征向量V1与矩阵概率分解相结合,能很好地预测读者对数字图书的预测评分P1,P1的取值在[0,5]之间。
1.2 数字图书评论信息处理
读者对数字图书的评论会用许多带有感情色彩的词汇,这些词汇也是读者对图书喜爱程度的表达,对图书推荐具有重要的参考价值。因此,对这些图书评论中词汇进行量化处理,得到读者对数字图书的预测评分矩阵P2。
用AFINN 情感词典对图书评论中的情感词汇进行量化,每一个关键性词汇对应一个情感分值,取值范围在[-5,5]之间,经过处理计算可以得到每条评论的总情感分值[2]。利用Python 自然语言工具包对评论语言进行分词,并根据Natural Language Toolkit 中的停用词表,进行停用词过滤,建立结构化的评论数据[3]。
AFINN 情感取值介于[-5,5]之间,因此可以将正向积极的评论取值为(0,5],负向消极的评论取值为(0,-5],中性评价取值为0,利用公式(2)计算得出总的情感分值。

其中,Qui=(w1,w2,…,wj),Qui表示读者u对数字图书i的结构化评论;wj是第j个单词或词汇;W(wj) 是每个单词或词汇的情感分值;K为AFINN中的词汇。
利用公式(3)对G(Qui) 所得结果进行泛化处理,使其结果取值在[0,5]之间,x∈[-5,5],y∈[0,5],得到读者评论的图书预测评分矩阵P2。
半个多世纪以来,超高速碰撞不仅在极端条件下的物性与高压状态方程、高温高压高应变率下材料动态响应特性、材料科学、生命起源、行星与地球物理等基础学科研究中发挥了重要作用,而且推动了常规武器与核武器武器物理、惯性约束聚变(ICF)、核反应堆安全防护设计、航天器空间碎片防护、反弹道导弹、轻质装甲设计、飞机和车辆受撞击时乘员与货物的安全防护等工程应用研究的快速发展。本文在概要介绍超高速碰撞现象及其关键科学问题的基础上,评述了超高速碰撞应用于航天器空间碎片防护、小行星撞击地球防御研究的若干近期进展, 展望了研究发展趋势。

1.3 对图书作者和出版社进行数据建模
作者、出版社对于数字图书的评分也有着较高的影响力,因此将其作为影响图书最终预测评分的影响因子,赋予一定的权重。
最近邻方法KNN 可以对一个不知类别的样本找出最相似的近邻用户进行分类,采用此方法求出近邻读者对作者ds所有数字图书的评分均值,以及近邻读者对出版社eo所有数字图书的评分均值,利用公式(4)计算出其均值,作为作者、出版社共同影响下,读者对数字图书i综合评分为P(i)dseo,表示作者为ds,出版社为eo,读者对图书i的综合评分。

根据P(i)dseo得出的结果,利用公式(5)可以构建读者u对图书i的评分预测矩阵P3,P′(ui)为读者u对图书i的评分。

1.4 读者-图书评分数据的处理
基于读者、图书、图书评分矩阵,通过协同过滤技术进行图书推荐已相对成熟,无需对数据再进行特别的处理。根据数据源D=(U,I,R),结合协同过滤算法,利用余弦相似度计算,可以得到目标读者对图书的预测评分矩阵P4,其中U={User1,User2,…,Useri}为读者样本集合,I={Item1,Item2,…,Itemj}为数字图书样本集合,R为i × j阶矩阵,是已有读者对各数字图书的实际评分矩阵。
2 融合多特征数字图书数据的模型构建
根据多特征数字图书的数据处理,重点研究了图书简介信息、图书评论、图书作者和出版社以及图书的评分等影响因子,以此为基础分别构建了读者对数字图书的预测评分矩阵P1、P2、P3、P4,将每个影响因子赋予一定的权重,利用公式(6)融合计算,作为最终预测评分Pui。

其中,α、β、γ、δ为不同预测评分矩阵相应的权重,并且α+β+γ+δ=1,通过问卷调查的方式获取图书简介信息、图书评论、图书作者和出版社以及图书的评分等因素对读者选择图书的直观影响程度,根据问卷结果,设定α、β、γ、δ的初始值,不断调整权重,对不同的权重组合进行比较,取最小的MAE值所对应的α、β、γ、δ值作为公式中的权重值。
Pui为读者u对图书i综合多特征的预测评分,根据前文所述,P1为读者u根据图书简介信息对图书i的预测评分;P2为读者u根据图书评论对图书i的预测评分;P3为读者u根据图书作者和出版社对图书i的预测评分;P4为读者u根据图书的评分对图书i的预测评分,P1,P2,P3,P4∈[0,5]。根据已经确定的α、β、γ、δ权重值分别赋予P1、P2、P3、P4,αP1+βP2+γP3+δP4所得结果即为Pui,得到目标读者对未选择图书的综合预测评分后,根据评分由高到底排序,将评分最高的前k个图书推荐给该读者。
3 实验分析
3.1 实验数据
3.2 评价指标
平均绝对偏差MAE(Mean Absolute Error)体现预测评分与真实评分之间的偏差平均值,计算公式如式(7)所示:
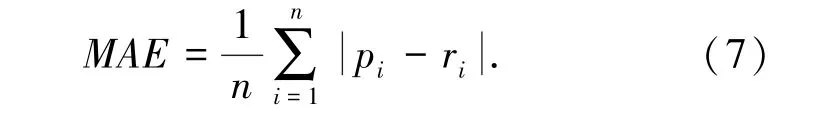
其中,n为读者数量;Pi为预测读者评分集合{p1,p2,…,pN};ri为实际读者评分集合{r1,r2,…,rN};计算出的MAE值越小,误差越小,推荐效果越好。
3.3 实验结果及分析
首先进行权重调整实验,获得最佳的权重组合对数字图书的评分矩阵P1、P2、P3、P4权重赋值,然后验证融合多特征数字图书推荐性能。
3.3.1 权重调整实验
权重α、β、γ、δ取值组合范围较大,通过对50位读者直观感受和实际经验进行的问卷调查显示,数字图书简介信息、读者评论、评分对其选择图书的影响较大,因此可以假定数字图书简介信息、读者评论、评分对图书推荐结果的影响较大,作者、出版社对图书推荐结果的影响较小,设置初始值α=0.3,β=0.3、γ=0.3、δ=0.1,不断调整权重进行测试。邻居数N在10-50 之间取值,当N取值30时,不同权重对应的MAE值见表1。
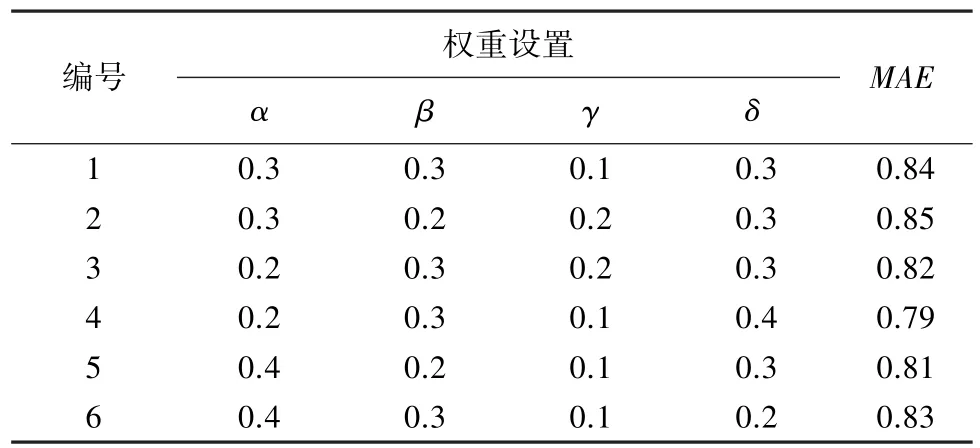
表1 N=30时不同权重对应MAE值Tab.1 N=30,Different weights correspond to MAE values
实验结果如图1 所示,权重编号为4、12、19时MAE值较小,采用权重编号4 所对应的权重,取值α=0.2、β=0.3、γ=0.1、δ=0.4 进行后续的数字图书推荐实验。
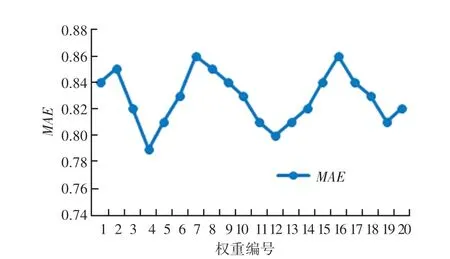
图1 N=30时不同权重编号对应的MAE值Fig.1 N=30,Different weights serial number correspond to MAE values
3.3.2 融合多特征数字图书推荐性能实验
该实验验证本文提出的融合多特征数字图书推荐性能,用协同过滤算法CF 与本文提出的方法进行对比,比较平均绝对偏差MAE值。协同过滤算法CF 得到的预测评分矩阵就是目标读者对图书的预测评分矩阵P4,得出的MAE值如图2 所示。
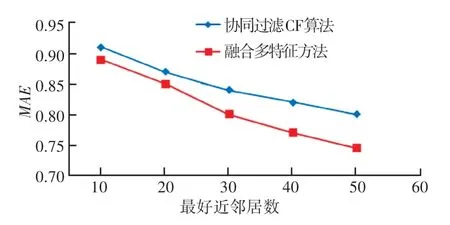
图2 最近邻居数变化时对应的MAE值Fig.2 MAE values of nearest neighbors’ number changes
实验表明,融合多特征数字图书推荐方法与协同过滤CF 算法相比较,MAE值均最小,表明本文提出的数字图书推荐方法的有效性,该方法在一定程度上提高了数字图书的推荐性能,获得了较好的推荐效果。
4 结束语
数字图书具有多特征属性,随着现代信息技术的发展,数字图书特征数据已经极大的丰富,这为融合多特征数字图书推荐奠定了基础。本文通过对数字图书特征的分析,考虑图书简介、读者评论、作者、出版社、读者评分等多种影响因素,分别对图书评分进行预测,对预测结果加权融合,赋予一定的权重,以此提高图书的推荐性能。通过实验证明该方法优于协同过滤CF 算法,具有更好的数字图书推荐性能。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
心理学报(2022年5期)2022-05-16
中国药学药品知识仓库(2021年18期)2021-02-28
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
足球周刊(2017年27期)2018-04-16
读与写·教育教学版(2017年10期)2017-11-10
足球周刊(2016年13期)2016-10-18
南都周刊(2015年4期)2015-09-10
