
基于三种机器学习方法的降水相态高分辨率格点预报模型的构建及对比分析*
2022-01-04 06:32南刚强陈明轩宋林烨刘瑞婷程丛兰曹伟华
气象学报 2021年6期
杨 璐 南刚强 陈明轩 宋林烨 刘瑞婷 程丛兰 曹伟华
北京城市气象研究院,北京,100089
1 引言
降水是地球水循环和能量循环的关键环节之一(Zhang,2005),冬季降水相态主要包括雨、雪、雨夹雪、冰粒、冻雨等(蔡雪薇等,2013),不同相态的降水对陆地表面物质和能量循环的影响巨大(Wu,et al,2009),相同的降水量不同的相态所产生的影响存在显著差异(孙燕等,2014; 王春乙等,2005)。
随着近年来北京城市化进程的不断加快,大城市面对极端气象灾害的脆弱性也日益凸显,冬季降雪、冻雨甚至雨夹雪天气会给城市交通、电力通信及人民生产、生活带来巨大危害。即使是很弱的降雪过程,如果降水相态预报失败或漏报,也会给城市运行带来严重的不利影响(孙继松等,2003),另外,2022年第24届冬季奥林匹克运动会将在北京和张家口举办,冬奥会对气象条件要求严苛,尤其是精细化的温度、湿度及降水相态预报服务等,将是冬奥会气象服务保障的重点(Chen,et al,2018)。因此,做好冬季降水相态及其转变时间的精细化预报,研究京津冀地区冬季降水相态预报方法,并开发适用于京津冀地区的降水相态高精度格点分类客观预报算法,对提升现代气象预报服务质量、保障国家重大活动、防灾减灾等具有重要现实意义。
降水相态的形成机制包含大气垂直热力学和微物理过程两个方面。一方面,到达地表的降水类型很大程度上取决于大气的垂直温度,而大气的垂直温度通常由高空的暖层和下面的再冻结层组成。大气垂直温度一个微小的变化都会导致地表附近降水类型的变化(Sankaré,et al,2016)。而区分降水类型转化区的一个重要的热力信息即融化层(Tw>0℃)相对于地面高度的位置(Stewart,et al,2015)。另一方面,造成降水相态不同的关键在于云中的成雪机制以及雪花下落过程中发生的变化,粒子在降落的过程中涉及到扩散生长、增生、聚集、融化、再冻结等许多复杂的物理过程(Thériault,et al,2010)。
国际上利用数值模式开展了许多针对降水相态精细化预报的后处理算法,为降水相态的分类预报提供了丰富的科学依据,如一些学者(Bourgouin,2000;Shafer,2010,2015)通过提取模式输出产品温度和湿度廓线中的特征量,利用算法、决策树或统计学的方法建立特征量与降水相态的关系,实现雨、雪、冻雨、冰粒的区分。还有一些学者(Ramer,1993; Schuur,et al,2012; Elmore,et al,2015)通过计算或推导下落水成物中的液态水含量,实现雨、雪、冻雨、冰粒的区分。另外,一些学者(Thompson,et al,2004,2008;Ikeda,et al,2013)通过改进模式中的微物理方案,利用混合相云微物理方案预测的水成物信息,如云水、雨水、冰晶、雪、霰和水汽含量等计算出的混合比预报物理量作为诊断量区分降水相态。
中国学者从不同方面开展了大量研究工作,主要包括降雪气候分布及其变化趋势的相关研究(段长春等,2011;刘玉莲等,2012),不同地区和台站雨雪转换的经验温度阈值的研究(李江波等,2009; 尤凤春等,2013; 董全等,2013; 杨成芳等,2015)。如漆梁波等(2012)通过对中国东部冬季降水相态的研究,认为温度平均廓线对雨和雪的区分较好,雪和雨夹雪在低层的大气冷暖状态较相似。张琳娜等(2013)在建立北京地区冬季降水相态识别指标时,除了将不同高度层上的温度和位势厚度作为判据,还加入了地面 2 m 气温和相对湿度,为模式制作客观预报产品提供了参考依据。崔锦等(2014)利用数值模式的云微物理量输出产品,对东北地区的冬季降水相态进行了预报试验。董全等(2013)选取降水发生时和发生前6 h的地面2 m气温、露点温度作为预报因子,对相同条件下线性回归法和人工神经网络法对降水相态的预报效果进行了对比检验。陈双等(2019)基于2001—2003年地面观测和探空资料,对地面气温位于0—2℃中国降雪的时、空分布及其与降雨的垂直热力特征进行了研究,引入了决策树判别方法对上述条件下雪和雨进行了判别分析。这些研究结果表明:温度和湿球温度的垂直廓线、地面2 m气温、露点温度、相对湿度,数值模式的云微物理量输出产品等对于地面降水相态的客观诊断具有很好的指示意义。
对于京津冀地区降水相态的高分辨率格点客观分类预报模型,Yang等(2021)(以下简称Y20)基于中国气象局北京快速更新循环数值预报系统(CMA-BJ)(原华北区域快速更新循环数值预报系统,RMAPS-ST)预报的雪、雨、冰、霰降水混合比及粒子降落末速度结合快速更新多尺度分析和预报系统集成子系统(RMAPS-IN)分析和预报的高分辨率湿球温度廓线、雪线高度等联合地面观测订正,开展了降水相态诊断变量最优阈值的研究分析,构建了降水相态综合诊断算法,可提供覆盖京津冀全域、空间分辨率1 km、时间分辨率10 min的雪线高度及降水相态的高分辨率诊断分析及0—12 h预报。客观检验结果表明该算法能够较好地诊断冬季降水类型,尤其是雨和雪,准确率均超过90%,雨夹雪的准确率相对较低(41%)。
实际的预报和研究中,预测降水类型的难度主要在于雨雪过渡区。而雨雪相态转换阶段,850和925 hPa温度对于雨、雪、雨夹雪的识别没有明显指示性(杨成芳等,2015),地面气温往往在0℃附近,有时甚至还会出现地面气温在0℃以上却发生降雪的情况(董全等,2013)。另外,京津冀地区地形复杂,地形的特征差异对地面的辐射加热、地形抬升等的影响会进一步造成不同海拔高度下雨雪相态转变规律及阈值的细微差异(Rajagopal,et al,2016)。模式热力学和微物理输出信息的不确定以及由网格插值引起的诊断类型和观测类型的空间偏移是Y20诊断算法中降水类型误诊的重要原因之一,另外,诊断算法中京津冀范围内选取和使用同一阈值也会给降水类型的诊断带来一定的误差。
为进一步提高冬季降水相态客观预报的准确率,将在Y20基础上,充分利用RMAPS-IN系统生成的高分辨率温度、相对湿度、湿球温度及雨、雪混合比等网格化快速更新精细集成产品(Haiden,et al,2011),结合自动气象站观测资料,进一步通过机器学习方法构建、测试和优化京津冀地区降水相态客观预报算法。
文中首先利用京津冀地区国家级气象站观测资料及网格化快速更新精细集成产品,统计分析了京津冀地区复杂地形下各类降水相态温度和湿球温度平均气候概率的分布差异、不同降水相态时RMAPS-IN提供的网格化快速更新精细集成产品中7个可能影响降水相态判断的特征信息,包括地面2 m气温、露点温度、相对湿度、雪线高度、近地面大气层中冻结部分降水混合比在可凝结成降水的水汽混合比中的比例以及气温和湿球温度三维气象要素客观分析场等。然后将地面观测天气现象资料、复杂地形下降水相态气候特征及高分辨率模式输出产品作为特征向量,分别基于梯度提升(XGBoost)、支持向量机(SVM)、深度神经网络(DNN)3种机器学习方法建立降水相态的客观分类模型,并对同样条件下3种机器学习方法对雨、雨夹雪和雪3种京津冀主要降水相态的预报效果进行对比检验。
2 数据及其统计特征
2.1 数据
观测数据包括2部分:(1)2016年1月—2019年4月冬季15个降水日京津冀地区174个国家级自动气象站天气现象资料,此数据分别用于对RMAPS-IN网格化快速更新精细集成产品降水相态分类模型样本的筛选及客观检验。这部分的天气现象观测资料采样处理为10 min时间间隔,即原始观测的天气现象数据集是根据人工判断的每一个降水日的雪、雨、雨夹雪具体起止时间进行记录,如A站记录的降雪时间为08时(北京时,下同)—09时10分,B站记录的降雨时间是08时—09时10分,那么在进行采样处理时,从08时到09时10分的每10 min,如08时—08时10分、08时10分—08时20分,······,09时—09时10分,A站的降水类型记录为雪,B站记录为雨。(2)1955年11月至2019年4月京津冀地区174个国家级观测站的日天气现象及其对应的地面气温、气压、相对湿度观测数据(其中1955—2003年为02、08、14、20时4个时次,2004—2019年为逐时)。虽然选取的站点数据已经经过质量控制,但由于天气现象为人工判断和记录,且天气现象为日数据,所以文中根据以往关于降水相态的研究(许美玲等,2015),对筛选出的数据做了进一步的质量控制。京津冀地区国家级站点分布如图1所示。

图1 京津冀地区174个国家级气象站分布 (红色雪花表示海拔高度在1000—1500 m的站点;黑色圆点表示海拔高度在400—1000 m的站点,蓝色三角表示海拔高度在400 m以下的站点,色阶为海拨高度)Fig.1 Locations of 174 stations in Beijing-Tianjin-Hebei region(red asterisk indicates the altitude is 1000-1500 m,black circles indicate the altitude is 400-1000 m,and blue triangles indicate the altitude is 0-400 m; color shadings show terrain height,shaded:altitude)
文中用到的模式数据为2016年1月—2019年4月冬季15个降水日RMAPS-IN提供的网格化快速更新精细集成产品,RMAPS-IN系统(杨璐等,2019;程丛兰等,2019;宋林烨等,2019)利用最新的自动气象站和雷达、下垫面地形地表信息等其他观测资料进行精细化融合分析后,结合线性外推技术和数值预报结果提供一个更接近真实大气的0—12 h短时天气预报,水平方向上分辨率为1 km,垂直方向上分辨率为200 m,共21层,时间分辨率为10 min,建模中使用的分析场数据包括地面2 m气温(T2m)、露点温度(Td)、湿球温度(Tw)、相对湿度(RH)、雪线高度(Zs)、雪混合比占雨和雪混合比的比例(Snf),以及气温和湿球温度三维气象要素;预报场数据包括T2m、Td、Tw、RH、Zs及Snf。
其中,雪线高度Zs定义为雪开始融化(Tw=0℃)时对应的高度。基于RMAPS-IN系统不同气压层上的高分辨率温度和比湿数据,用二分算法(李金霞等,2012)反复迭代,自上向下计算各层的湿球温度。当某层湿球温度首次出现大于临界值0℃时,用该层和上一层线性插值得到的高度来计算雪线高度。若计算得到的雪线高度低于最低地形高度时则设为0,计算出的雪线高度为海拔高度,所以若想得到融化层相对于地面高度的位置,需要用计算出的雪线高度Zs减去地面高度。
基于Thompson混合相云微物理方案的高分辨率数值模式对近地面大气层中混合比的预报结果,将模式预报的雪、雨、冰、霰降水混合比通过三维插值到1 km分辨率网格点上,计算得到Snf,Snf的取值范围为0—1。
以上采集到的观测数据和模式数据,都将作为特征向量,用于3种机器学习方法对京津冀地区降水相态客观预报算法的构建和测试。
2.2 降水相态的气候分布特征
2.2.1 不同降水相态的空间分布特征
基于1955—2019年京津冀地区174个国家级气象站逐日天气现象数据,统计了雨、雨夹雪及雪的空间分布,1955—2003年天气现象观测资料采样处理为对应的02、08、14、20时4个时次,即对应时次有天气现象时,记录1次;2004—2019年天气现象观测资料采样处理为逐时数据,即每个时次对应有天气现象时,记录1次。从京津冀地区国家级气象站雨、雨夹雪及雪的空间分布(图2)可以看出,京津冀地区雪的出现次数远多于雨和雨夹雪,雨夹雪的出现次数最少。其中,北京地区雨和雨夹雪的出现次数较河北地区少,最多降雨次数主要出现在河北的南部及东北部平原地区;海拔高度大于400 m的山区站,雨夹雪和雪的出现次数高于海拔高度400 m以下的平原站,张北(位于河北北部,海拔1393 m)雨夹雪和雪的次数位居京津冀首位,说明不同海拔高度下各类降水相态平均气候概率分布不同,地形对于京津冀地区降水的多少也有一定的影响。

图2 1955—2019年京津冀地区雨 (a)、雨夹雪 (b)、雪 (c) 3种降水相态次数空间分布Fig.2 Spatial distributions of precipitation type frequencies of rain (a),sleet (b) and snow (c) in Beijing-Tianjin-Hebei region from 1955 to 2019
2.2.2 不同降水相态湿球温度的空间分布特征
降水相态的判别紧紧依赖于相对湿度、海拔高度及气温(Ding,et al,2014),而湿球温度包含了气温、相对湿度、气压信息。在Y20的基础上,进一步利用各气象站的本站气压、相对湿度、气温数据分别计算了各站对应时次的湿球温度(Ding,et al,2014),重点关注地面湿球温度为0—1℃各类型降水相态的空间分布特征,统计临界湿球温度条件下与降水相态的关系,并将复杂地形下降水相态的气候特征作为特征向量用于3种机器学习方法对京津冀地区降水相态客观预报算法的构建和测试。
图3、4、5分别给出了雨、雨夹雪和雪各降水相态Tw<0℃、0≤Tw<1.0℃和Tw≥1℃三个区间的概率分布情况。从图3可以看出,Tw<0℃的条件下,京津冀地区除河北东北部个别站外,其他站雪出现的概率基本都在0.9以上,雨夹雪和雨的概率都在0.1以下,可以区分出90%以上的雨和雪。0≤Tw<1.0℃的条件下,雪出现的概率开始降低(0.5—0.7),但还是高于雨和雨夹雪的出现概率(0.1—0.5),海拔400 m以下的站,雨出现的概率相对较高(0.2—0.4),海拔400 m以上的山区站,雨夹雪出现的概率高于雨出现的概率。Tw≥1℃条件下,除河北北部海拔高于1000 m的几个站及河北南部个别站外,雨出现的概率基本都在0.9以上。

图3 雨 (a)、雨夹雪 (b)、雪 (c) 3种降水相态在Tw<0℃时的概率空间分布Fig.3 Probability spatial distributions of rain (a),sleet (b) and snow (c) atTw<0℃
2.3 RMAPS-IN高分辨率格点数据的统计特征
文中利用2016年1月—2019年4月冬季15个降水日京津冀地区174个国家级自动气象站采样处理好的逐10 min天气现象资料,提取各站周围对应的RMAPS-IN系统8个网格点上相应的分析场和1—12 h预报场资料。
温度垂直分布是降水相态的主要决定因素,本研究从京津冀地区RMAPS-IN高分辨率气温和湿球温度三维客观分析场样本中随机抽取雨、雨夹雪和雪各30组样本,分别绘制并分析了3种降水相态对应的气温和湿球温度随高度的变化。图6给出了不同降水相态对应的湿球温度随高度的变化。

图4 雨 (a)、雨夹雪 (b)、雪 (c) 3种降水相态在0≤Tw<1.0℃的概率空间分布Fig.4 Probability spatial distributions of rain (a),sleet (b) and snow (c) at 0≤Tw<1.0℃

图5 雨 (a)、雨夹雪 (b)、雪 (c) 3种降水相态在Tw ≥1℃的概率空间分布Fig.5 Probability spatial distributions of rain (a),sleet (b) and snow (c) atTw≥1℃
从图6可以看出,不同降水相态湿球温度的三维廓线分布特征不同。雨的30组样本,基于地面高度的0 m湿球温度都在0℃以上,湿球温度在低层高于0℃的面积明显大于雨夹雪,开始融化的高度较雨夹雪和雪高很多,暖层厚度相比雨夹雪更深厚,基本在离地250 m以上,低层温度的垂直递减率较大。雨夹雪的30组样本,0—500 m高度,大部分廓线有弱的逆温层,0 m湿球温度分布在−1—2℃,近地层都存在一个暖层,暖层相比雨较浅薄,分布在0—100 m。雪的30组样本中大多样本整层湿球温度都在0℃以下,有极少数的廓线样本近地层湿球温度高于0℃,有非常浅薄的暖层。从三者湿球温度的垂直分布来看,湿球温度差异比较明显的区域主要位于500 m以下,尤其是近地面层,500 m以上3种不同降水相态湿球温度基本都是冷冻层。

图6 京津冀地区雨 (a)、雨夹雪 (b) 和雪 (c) 对应的湿球温度随高度的变化Fig.6 Vertical profiles of wet bulb temperature corresponding to rain (a),sleet (b) and snow (c) in Beijing-Tianjin-Hebei region
图7是京津冀地区3种降水相态对应的T2m、Td、RH、雪线高度和地面高度(Z)的差值(Zs−Z)以及Snf总样本的箱线图。方框中间的横线为中值(样本覆盖率达到50%的值),方框的上边界和下边界分别为25%和75%分位,上须和下须分别为样本中的最大值和最小值。

图7 京津冀地区3种降水相态对应的T2m (a)、Td (b)、RH (c)、Zs−Z (d) 和Snf (e)箱线图Fig.7 Boxplots ofT2m (a),Td (b), RH (c),Zs−Z (d) and Snf (e) corresponding to three precipitation types in Beijing-Tianjin-Hebei region
从图7可以看出,雨、雨夹雪和雪2 m气温中位数分别为2.04℃、1.59℃、−0.09℃,25%—75%分位的范围只有雨夹雪与雨有小范围的交叉,雪的75%分位在0.61℃以下,雨的25%分位在1.66℃以上,雨夹雪25%—75%分位在1.2—1.86℃。2 m露点温度雪的75%分位在−0.27℃以下,雨的25%分位在0.37℃以上,雨夹雪25%—75%分位在−0.11—0.63℃。从相对湿度来看,雪、雨夹雪和雨的中位数比较接近,3种相态的分布交叉范围较大。Zs−Z表示从开始融化到地面的高度,不同相态Zs−Z的分布特征比较明显,雨、雨夹雪和雪的中位数分别为279 m、146 m、−45 m,25%—75%分位的范围只有雨夹雪和雨有小范围交叉,雪的25%—75%分位在−461—−12 m,雨夹雪的25%—75%分位在5—276 m,雨的25%—75%分位在213—424 m。Snf雨和雪的特征比较明显,雪和雨的中位数分别为1和0,降水相态为雪时,Snf的值主要集中在0.9—1,降水相态为雨时,Snf的值主要集中在0—0.25,雨夹雪分布在0—1。
3 机器学习理论基础
3.1 XGBoost算法原理
XGBboost(Chen,et al,2016)是基于梯度提升框架的一种高度可扩展的树结构增强模型,对稀疏数据的处理能力卓越,算法原理是将原始数据集分割成多个子数据集,将每个子数据集随机分配给基分类器进行预测,然后将弱分类的结果按照一定的权重进行计算,它由模型、参数和目标函数组成。其中,模型是根据给定的输入样本因子去预测输出的结果,参数是指最终建立的最优模型对应的系数,而目标函数的优化情况则决定了模型的准确性,目标函数优化的越好,预测结果就越接近真实值。目标函数 Obj(θ)由两部分组成,如式(1)所示

文中选择CART回归树作为模型的基函数,单个CART第m次预测的结果可以表示为式(2)

式中,T为决策树,m代表基分类器的数量,θ代表决策树的划分路径,每棵决策树一个一个往里面加,最后预测结果为前一次的预测结果加上当下的。误差项可以表示为

3.2 支持向量机
支持向量机(Support Vector Machine,SVM)由 Cortes等(1995)提出,是一种建立在统计学习理论和结构风险最小化原理基础上的小样本学习方法。它最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器。文中采用libsvm中的一对一法,其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k−1)/2个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。
3.3 DNN深度神经网络
DNN(Deep Neural Networks)是深度学习中较为常见的也是最为基本的网络结构,由输入层、隐藏层、输出层组成。输入层是经过预处理的输入数据,紧接着是隐藏层,隐藏层可以是一层,也可以多层级联。网络的最后一层是输出层,输出层则是需要针对不同的预测目标来设计其节点数,例如是手写体数字识别则属于十分类任务,可以输出10个结点代表十分类的概率分布。DNN的训练可以分为两个过程,输入信息的前向传播和基于误差的反向传播。试验中所用深度神经网络结构是一个4层的全连接神经网络,包含两个隐藏层,输入层节点数为训练样本的特征数,训练样本从输入层传入到整个神经网络,输出层含有3个节点,对应3分类。设Wij为连接节点i与j的权值,bj则是节点j对应的偏置,aj为节点最终的激活值,σ代表激活函数,通常选用Relu函数或者是sigmoid函数。正向传播的公式如下

误差的反向传播通常采用经典的BP算法(Rumelhart,et al,1986),通过计算损失函数,使用梯度下降法来不断的调整网络中的权值以减少输出结果的误差,例如d是期望输出,y是网络输出,损失函数的定义可以是平方差损失

整个训练以梯度下降法(Gradient Descent Optimizer)作为优化器、以交叉熵作为损失函数进行网络的优化,使用带指数衰减的学习率设置、L2正则化来避免过度拟合,并使用滑动平均模型来使得最终得到的模型具有更强的鲁棒性。
4 降水相态分类模型构建及结果检验对比
4.1 不同特征参数组的选取方法
使用2016—2019年1月—次年3月的高分辨率模式产品和同期的国家级自动气象站观测资料,将分析场(t=0 h)按近似7∶3的比例随机划分为训练集和测试集;同样将预报场(t=1—12 h)样本按近似7∶3的比例随机划分为训练集和测试集,分别基于分析场和预报场70%的样本建立降水相态模型,并利用剩余的30%的样本开展独立检验。分析场和预报场总样本数如表1所示。

表1 分析场和预报场样本总数Table 1 Total number of samples of analysis field and prediction field
通过对与预报对象有明确意义的各种特征参数的选取,最终选取41个分析场特征,11个预报场特征,各特征的物理意义如下:
(1)RMAPS-IN模式输出产品:分析场样本包括T2m、Td、Tw、RH、Zs、Snf及气温和湿球温度三维气象要素;预报场样本包括T2m、Td、Tw、RH、Zs及Snf。
(2)地面实况观测数据:实况天气现象。
(3)复杂地形下降水相态气候特征:基于1955—2019年自动气象站观测数据,得到京津冀地区各国家级站点T2m和Tw在[−10℃,10℃]每0.5℃间隔内雨、雨夹雪和雪的出现概率。
为比较不同特征参数构建对不同机器学习方法降水相态分类预报模型的影响,文中设计了2组(test1和test2)特征参数组的构建方法(表2),其中test2中增加了复杂地形下降水相态气候特征,即根据RMAPS-IN模式输出的2 m气温和湿球温度,匹配[−10℃,10℃]每0.5℃间隔内雨、雨夹雪和雪的出现概率,并利用XGBoost、SVM和DNN三种机器学习方法,针对test1和test2对应的两种不同特征参数组,分别进行建模和检验。

表2 不同模型不同特征参数组的构建方法Table 2 Construction methods for different characteristic parameter groups in different models
4.2 数据归一化
由于奇异样本数据会导致训练时间增大和模型无法收敛的情况,为消除其带来的不良影响,使用min-max标准化将全部样本的每个特征映射到[0,1]。
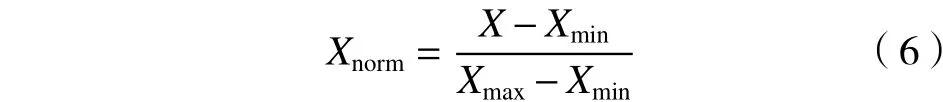
式中,Xmin是 原始特征X的最小值,Xmax是原始特征的最大值,Xnorm是标准化结果。
4.3 预测结果
由于雨、雨夹雪和雪的数据集不平衡,为了客观评测不同模型的性能差异,文中利用混淆矩阵进行评价。混淆矩阵是衡量分类模型准确度中最基本、最直观、计算最简单的方法,即分别统计分类模型归错类、归对类的观测值个数,然后把结果放在一个表里。混淆矩阵的具体定义如表3所示,其中TP表示正类样本中分类正确的数量,FN表示对正类误分为负类的样本数,FP表示将负类错分为正类的样本数,TN表示负类正确分类的样本数。因为样本数量大,为方便对比,数字下面加“()”里标上相对于总体的百分数,表示预测准确率,如表4和表5所示。

表3 混淆矩阵Table 3 Confusion matrix
表4中test1特征参数组为RMAPS-IN分析场样本和地面实况观测的天气现象,test2特征参数组中增加了复杂地形下降水相态气候特征。针对2种不同特征参数组构建得到的3种不同降水相态混淆矩阵可以看出,XGBoost和DNN两种机器学习方法对于雨、雨夹雪和雪的预测准确率相当,都明显高于SVM方法。特征参数中增加复杂地形下降水相态气候特征,可以明显提升3种机器学习方法对于雨、雨夹雪和雪的预测准确率。基于此,针对预报场样本,只对test2特征参数组方案(RMAPSIN预报场样本、地面实况观测的天气现象及复杂地形下降水相态气候特征)进行了建模和检测,混淆矩阵如表5所示。从表中可以看出,XGBoost和DNN两种机器学习方法对于雨、雨夹雪和雪的预测准确率相当,都明显高于SVM方法,整体预报准确率略低于基于分析场样本建立的降水相态模型。

表4 基于分析场样本建立的不同降水相态模型的混淆矩阵Table 4 Confusion matrix of different precipitation type models based on analysis field samples

表5 基于预报场样本建立的不同降水相态模型的混淆矩阵Table 5 Confusion matrix of different precipitation type models based on prediction field samples
另外,根据分析场和预报场test2方案混淆矩阵计算了不同降水相态模型的命中率(probability of detection,POD)、虚 警 率(false alarm ratio,FAR)和临界成功指数(critical success index,CSI)(Chen,et al,2017),如表6和表7所示。基于分析场样本,SVM模型3种降水相态的整体命中率为88.4%,XGBoost和DNN模型整体命中率分别为96.3%和97.1%,明显优于SVM模型。基于预报场样本,SVM模型3种降水相态的整体命中率为89.1%,XGBoost和DNN模型整体命中率分别为93.9%和93.4%。针对不同的降水类型,3种模型对于雨和雪的命中率都明显优于雨夹雪。另外,基于分析场和预报场样本建立的模型,针对3种不同的降水类型,XGBoost和DNN模型虚警率都低于SVM模型。基于预报场数据得到的模型命中率略低于分析场,虚警率略高于分析场。一方面是由于RMAPS-IN系统格点分辨率高,分析场数据本身应用5 min自动气象站观测资料进行了数据融合和快速订正,大多数站点观测值可作为“真值”处理,数据的精度和准确性要优于预报场数据;另外,基于分析场样本建模时,共选取了41个分析场特征,其中包括了气温和湿球温度的三维气象要素,而由于RMAPS-IN系统没有三维气象要素的预报场,所以预报场样本只选取了11个预报场特征,特征向量相对较少,对模型整体预测的正确性也有一定影响。

表6 基于分析场样本建立的模型预测评分Table 6 Model prediction scores based on analysis field samples

表7 基于预报场样本建立的模型预测评分Table 7 Model prediction scores based on prediction field samples
整体来看,基于XGBoost和DNN预报场模型,对于雨诊断的命中率为93%,略低于Y20方案(94%),基于SVM预报场模型,雨诊断的命中率较Y20方案偏低5%;对于雨夹雪,基于XGBoost和DNN预报场模型,命中率可以达70%左右,高于Y20方案(41%);对于雪,3种机器学习模型命中率都高于Y20方案,其中XGBoost和DNN命中率较Y20提升7%、SVM提升5%。这也进一步说明,面对不同气候背景和海拔高度的站点,将每个诊断变量设置为同一阈值本身也会给降水相态的客观诊断带来误差,而选取合适的特征参数,基于机器学习方法对样本进行训练和学习,能够更好地解决客观模型在不同区域的适用性和预报能力。
5 个例检验
利用Y20及3种机器学习方法建立的降水相态的高分辨率客观分类模型,对2021年2月13—15日降水相态进行了预测和检验。表8给出了Y20、XGBoost、SVM、DNN这4种降水相态客观分类模型对这次过程的预测准确率评分。从表8可以看出,这次过程Y20预测雪的准确率(0.89)高于3种机器学习方法,其中DNN方法预测的雪准确率(0.77)略优于XGBoost(0.75)和SVM(0.73);Y20方案对雨预测的准确率(0.79)低于3种机器学习方法,SVM对于雨预测的准确率(0.98)最高,其次为DNN(0.93)。

表8 2021年2月13—15日Y20、XGBoost、SVM、DNN四种降水相态客观分类模型预测准确率评分Table 8 Prediction accuracy score of four objective classification models for precipitation type based on Y20, XGBoost, SVM and DNN during 13—15 February 2021
6 结论与讨论
利用京津冀地区国家级自动气象站观测资料及网格化快速更新精细集成产品,统计分析了京津冀地区复杂地形下各类降水相态温度和湿球温度平均气候概率的分布差异、不同降水相态时网格化快速更新精细集成产品中可能影响降水相态判断的特征信息。将地面观测天气现象资料、复杂地形下降水相态气候特征及高分辨率模式输出产品作为特征向量,分别基于XGBoost、SVM、DNN三种机器学习方法建立了降水相态的高分辨率客观分类模型,并对同样条件下3种机器学习方法对雨、雨夹雪和雪3种京津冀主要降水相态的预报效果进行了对比检验。
(1)从1955—2019年京津冀地区雨、雨夹雪及雪的空间分布来看,海拔高度高于400 m的山区站点,雨夹雪和雪的出现次数都高于海拔高度400 m以下的平原站点,张北(位于河北北部,海拔1393 m)雨夹雪和雪的次数均居京津冀之首,说明不同海拔高度下各类降水相态平均气候概率分布不同,地形对于京津冀地区降水相态有一定的影响。
(2)通过统计长时间序列京津冀地区国家级站点观测资料降水相态与湿球温度(Tw)的关系,发现在Tw<0℃时,京津冀地区除河北东北部个别站点,其他站点雪出现的概率基本在0.9以上,雨夹雪和雨的概率在0.1以下。0≤Tw<1.0℃时,雪出现的概率开始降低,但还是高于雨和雨夹雪的出现概率,雨和雨夹雪出现的概率开始升高,雨出现的概率在大部分海拔400 m以下的站点相对较高,海拔400 m以上的山区站点,雨夹雪出现的概率高于雨出现的概率。Tw>1℃时,除河北北部海拔高于1000 m的几个站点及河北南部个别站点,雨出现的概率基本在0.9以上。整体来看,湿球温度低于0℃时,可以区分出90%以上的雨和雪。
(3)3种机器学习方法对3种降水相态都具有较好的预报能力,对降雨和降雪预报最好,其次是雨夹雪,并且XGBoost和DNN的预报能力相当,都明显优于SVM。SVM本身是一个二分分类器,要实现多分类必须构造合适的多类分类器,一般有一对一法和一对多法,本试验中使用一对一法,其缺陷就是使得训练时间和测试时间较长,再者SVM缺失数据敏感,对参数和核函数的选择敏感,对于大规模训练样本难以实施。
(4)构建的特征参数中增加复杂地形下降水相态气候特征,可以明显提升3种机器学习方法对于雨、雨夹雪和雪的命中率。基于分析场样本,SVM模型3种降水相态的整体命中率为88.4%,XGBoost和DNN模型整体命中率分别为96.3%和97.1%。基于预报场样本,SVM模型3种降水相态的整体命中率为89.1%,XGBoost和DNN模型整体命中率分别为93.9%和93.4%。
(5)在本试验中,XGBoost和DNN都很好地实现了降水相态的分类。XGBoost是GBDT的一种实现,既可以解决分类问题,也可以解决回归问题。XGBoost算法在目标函数中加入了正则化防止过拟合,使得算法的健壮性更好,在处理每个特征列时可以做到并行,并且考虑了训练数据稀疏值的情况,可以为缺失值或指定的值指定分支的默认方向,这大幅度提升了算法的效率。而DNN是深度学习方法,网络结构搭建灵活,可调控参数较多,并且有丰富的优化器,可以深度挖掘数据特征,并且可以利用GPU加速计算,适用于大数据特征挖掘。所以在其他区域构建降水相态模型时,DNN不失为一种更便捷的方法。另外,在以后研究中还可以另辟新路,构建各物理特征的多维样本,利用卷积神经网络(CNN)实现降水相态的高准确度分类。
猜你喜欢
祝您健康·文摘版(2022年7期)2022-07-07
江西农业学报(2022年1期)2022-03-16
成都信息工程大学学报(2021年4期)2021-11-22
疯狂英语·新读写(2018年3期)2018-11-29
领导决策信息(2018年7期)2018-05-22
民生周刊(2017年19期)2017-10-25
科技资讯(2014年23期)2014-10-20
法人(2014年4期)2014-02-27
