
基于图学习正则判别非负矩阵分解的人脸识别
2022-01-05 02:31龙显忠
计算机应用 2021年12期
杜 汉,龙显忠*,李 云
(1.南京邮电大学计算机学院、软件学院、网络空间安全学院,南京 210023;2.江苏省大数据安全与智能处理重点实验室(南京邮电大学),南京 210023)
(∗通信作者电子邮箱lxz@njupt.edu.cn)
0 引言
非负矩阵分解(Non-negative Matrix Factorization,NMF)是将非负约束整合到一般的矩阵分解中[1-2],其目标是找到两个非负矩阵,使其乘积能够最大可能地近似原矩阵。具体而言,NMF 是使用基向量的线性组合来表示原始数据,并且线性组合和基向量中的元素值都是非负的。这与大脑对于事物认知的方式是一致的,都是对于事物整体的认知是基于对事物整体的部分的认知[3-5]。已有研究表明,当基向量的数量较大时,NMF是一个NP-hard问题[6-8],并且相应的文献已经证实了在何种条件下NMF 是可解的[9]。NMF 应用在诸多方面,如文档聚类[10]、人脸识别[11]、DNA 基因表达[12]、疾病关联预测[13]等。其中最具代表性的研究工作是用于人脸识别的局部非负矩阵分解(Local Non-negative Matrix Factorization,LNMF)[11]和用于图像聚类的图正则非负矩阵分解(Graph Regularized Non-negative Matrix Factorization,GNMF)[14]。研究人员将基于NMF 的方法分为四大类[15],并从理论上对其进行分析,分别是:非负矩阵分解(Basic NMF),仅添加了非负的约束;受限的非负矩阵分解(Constrained NMF),即增加了一些额外的约束,如添加正则化项等;结构化的非负矩阵分解(Structured NMF),修改了标准的因式分解公式;广义非负矩阵分解(Generalized NMF),在广义上突破了传统的数据类型或因式分解的模式。此外,在传统NMF 的基础上,通过结合深度学习提出了一些新颖的人脸识别方法,其中性能较为先进的是采用三层金字塔模型获取图像多尺度信息和采用生成对抗网络训练人脸与草图之间的映射关系[16]。对于人脸识别,在损失函数中嵌入自适应图学习的思想,实现了一种新的人脸识别训练策略,并且该方法调整了不同训练阶段中容易识别样本和难识别样本的相对数量比例[17]。
近年来,诸多研究发现高维数据通常位于非线性的低维流形空间中。因此,提出了各种各样的流形学习算法用以发现高维数据在低维空间中的非线性表示[18]。针对流形学习的优点,提出了几种基于流形学习的NMF 的方法,如图正则非负矩阵分解(GNMF)[14]、保持邻域正交投影非负矩阵分解[19]、鲁棒性的基于图重构非负矩阵分解[20]以及稀疏对偶图正则化深度非负矩阵分解[21]。然而,在这些方法中,构造图的过程和NMF 的迭代过程是相互独立的。即这些算法一旦被用来构造图,在随后的矩阵分解过程中,它的图结构不会再发生变化。为了解决这一问题,已有文献提出了下面几种算法:自适应图正则的低秩矩阵分解[22]、鲁棒自动图正则判别的非负矩阵分解[23]、基于自适应稀疏图正则化的非负矩阵分解[24]、自适应离散超图匹配[25]、自适应近邻的NMF[26]和局部受限的自适应图NMF[27]。在这些算法的迭代过程中,可以同时学习系数矩阵、基矩阵以及图的权重矩阵。
样本的标签信息对于分类任务十分重要,于是有研究提出了几种半监督NMF 算法,例如约束NMF[28]、基于半监督的NMF[29]和基于共性提取和半监督的NMF[30]。
本文的主要工作如下:
1)利用子空间学习中的自表示模型获得自表示系数,并生成权重矩阵,从而得到拉普拉斯矩阵。本文将流形学习中拉普拉斯矩阵、子空间学习中的自表示以及用于判别的标签信息结合到NMF 框架中,提出了图学习正则判别非负矩阵分解(Graph Learning Regularized Discriminative Non-negative Matrix Factorization,GLDNMF)算法,在它的迭代求解过程中,由于对自表示系数进行更新,所以该算法中的拉普拉斯矩阵在每一次迭代过程中都会被更新。
2)利用训练集的标签信息构造类别指示矩阵,并分别用降维后的训练样本和权重系数矩阵分别重构类别指示矩阵,从而得到两个不同的正则项,使得学习到的投影矩阵保持了数据的判别信息。
1 相关工作
从模式识别的角度看,NMF 可以看作是无监督学习。通过添加样本的标签信息,NMF 可进一步扩充为监督学习,即判别NMF。它现在正被成功地应用于图像分类任务中,如人脸识别和面部表情识别。
目前,大量的分类文章大多以广义KL 散度(Kullback-Leibler Divergence)为基础,通过引入不同的判别约束来构造目标函数。在此基础上,又出现了大量的判别NMF 应用于人脸识别,分别是加上局部约束的非负矩阵分解(LNMF)[11],加上拉普拉斯矩阵的非负矩阵分解(GNMF)[14],以及加上流形学习和判别信息的图正则判别非负矩阵分解(Graph Regularized Discriminative Non-negative Matrix Factorization,GDNMF)[31]。
本章将介绍NMF 算法以及它的几种典型变体,同时回顾了两种经典的降维算法:主成分分析(Principal Component Analysis,PCA)[32]和局部保持投影(Locality Preserving Projections,LPP)[33]算法。设矩阵X=[x1,x2,…,xn]∈Rm×n,每一列代表一幅m维的图像。一般来说,当数值m较大时,会导致维数灾难,从而导致识别精度低并且识别速度慢,因此,有必要在人脸识别之前进行降维,下面将介绍六种常用的维数约减算法。
1.1 非负矩阵分解
NMF 即对于任意给定的一个非负矩阵X∈Rm×n能够分解成两个非负矩阵W∈Rm×r和H∈Rr×n(r≪min(m,n))相乘的形式,如下所示:

为解决NMF 的优化问题[2,7],提出了如乘性更新算法、交替最小二乘算法和梯度下降算法等。
利用欧氏距离度量NMF重构误差的优化问题如下:

其中:||⋅||F表示Frobenius范数;X∈Rm×n是数据矩阵;W∈Rm×r为基矩阵;H∈Rr×n为系数矩阵。矩阵X、W和H中的元素都是非负的。对应的乘性更新规则如(3)所示:

1.2 图正则非负矩阵分解
基于流形学习理论,研究人员提出了GNMF 模型[14]。在该模型中,高维空间中相邻的数据点在低维流形空间中仍然保持相邻。
利用欧氏距离度量GNMF重构误差的优化问题如下:
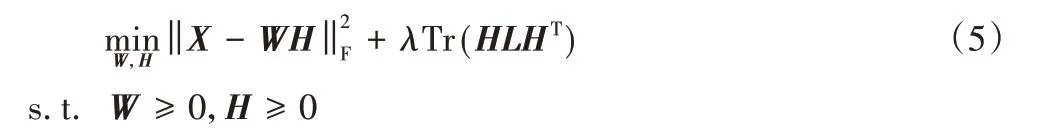
其中:Tr()为矩阵的迹;L为拉普拉斯矩阵;正则化参数λ≥0控制重构误差与正则项之间的平衡性。
1.3 图正则判别非负矩阵分解
在GNMF 的目标函数中加入标签信息来构造图正则判别非负矩阵分解(GDNMF)[31],此模型能够使分类的精确度比GNMF更高。
利用欧氏距离度量GDNMF重构误差的优化问题如下:
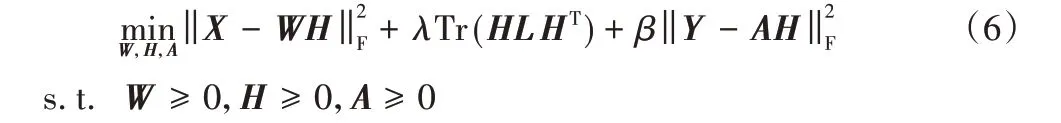
其中:参数λ和β的值都是非负的;Y是一个类别指示矩阵;A是一个随机初始化的非负矩阵。
1.4 局部非负矩阵分解
在NMF 的基础之上,通过添加局部约束提出了局部非负矩阵分解(LNMF)[11],能够更进一步地提取图像的局部特征。LNMF 对基矩阵添加了空间局部性的约束,所以在学习基矩阵的过程中,表现出了比NMF 更加优异的性能,并且随着原始图像维数的增加,LNMF所学习到的特征更加局域化。
利用KL散度度量LNMF重构误差的优化问题如下:
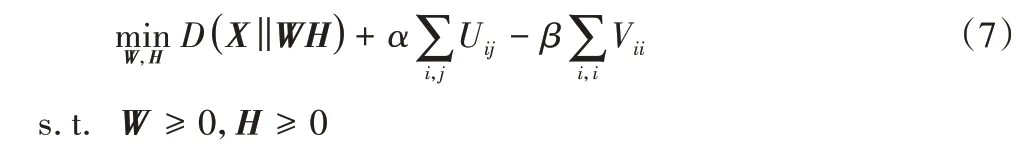
其中:参数α和β大于0;D(X‖WH)表示KL 散度;U=WTW;V=HHT。
1.5 主成分分析
主成分分析(PCA)是一种最广泛的数据降维算法。它的主要思想是将m维特征映射到d维上,这d维是全新的正交特征,也被称为主成分,即在原有m维特征的基础上重新选择出来的d维特征。假设数据样本已经中心化,即;再假设投影变换后得到的新坐标系为{b1,b2,…,bm},其中bi是标准正交基向量。若丢弃新坐标系中的部分坐标,即将维度降低到d(d<m)维,则样本点xi在低维坐标系中的投影是zi=(zi1;zi2;…;zid),其中是xi在低维坐标系下第j维的坐标。
考虑整个数据矩阵X,原样本点xi和基于投影重构的样本点之间的距离用欧氏距离可表示为:
其中:矩阵B为矩阵X投影变化后得到的新坐标系;矩阵I为单位矩阵。
1.6 局部保持投影
局部保持投影(LPP)是非线性降维方法的线性化,进一步可理解为相互间有某种非线性关系的样本点在降维之后仍然保持这种非线性关系,如原始空间内距离较近的样本点,映射后对应样本的距离仍然较近。
根据原始数据构造一个邻接图,对应的权重矩阵为E(邻接图中点相邻为1,否则为0),令映射后的数据矩阵为T=(t1,t2,…,tn)。原始样本与映射后的数据样本之间的重构误差为:

2 图学习正则判别非负矩阵分解
2.1 GLDNMF模型
受子空间聚类中自表示学习的启发,利用得到的自表示系数构造亲和矩阵(权重矩阵)[34]。根据亲和矩阵进一步构造拉普拉斯矩阵,并使其在迭代过程中不断更新。为了更进一步利用标签信息,构造一个类别指示矩阵Y∈Rr×n,其定义如下:
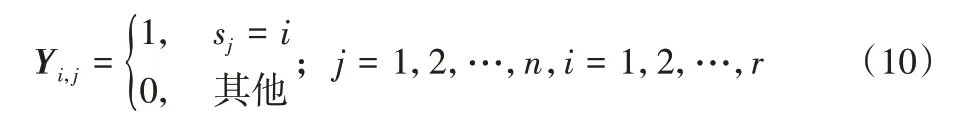
其中:sj∈{1,2,…,r}表示第j个样本xj的标签;r和n分别是训练集X中的样本类别数和样本总数。Y中每个行向量的代数和表示从每类中随机选取的用来构造训练集的图像个数。
图学习正则判别非负矩阵分解的模型如下:
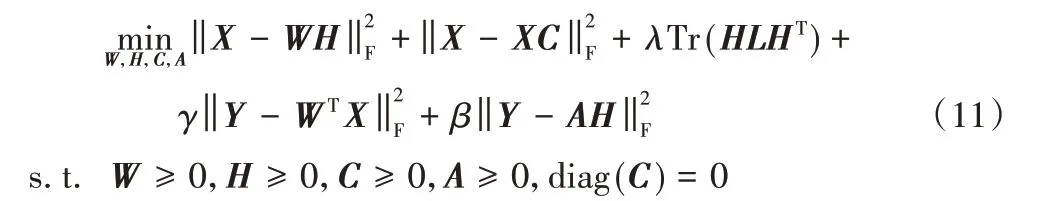
其中:参数λ、γ和β是三个非负常数;C∈Rn×n为自表示的系数矩阵,diag(C)=0 表示矩阵C的主对角线上的元素全为0;P=(C+CT)/2 是一个亲和矩阵,根据P可得到对角矩阵Q∈Rn×n,Q的主对角线上的元素Qii是P的第i行(或第i列,因为P是对称的)之和,即;拉普拉斯矩阵L=Q-P,L∈Rn×n;A∈Rr×r是一个随机初始化的非负矩阵。
式(11)中的第一项为NMF 的基本公式,第二项是子空间学习中的自表示约束,它可以学习到一个新的自表示系数矩阵C,然后通过C构造L所需的P和Q。通过引入自表示约束正则项,使式(11)中的L不断地被更新,在每次迭代过程中均能构造出最优的图结构,提升模型保相似性的能力。第4 项和第5 项是利用训练集的标签信息构造类别指示矩阵,并分别用降维后的训练样本和权重系数矩阵重构类别指示矩阵,增强模型的判别能力。
从本质上讲,GLDNMF 是将子空间学习、图学习、流形学习和标签信息一起整合到NMF 的框架中。通过求解式(11)得到的基矩阵W不仅具有保相似性结构的能力,同时蕴含了很好的判别能力。
2.2 GLDNMF的更新规则
虽然式(11)对于(W,H,C,A)不是凸函数,但当固定式(11)的其他变量时,对于(W,H,C,A)中的一个变量是凸函数。式(11)的目标函数可以进一步地写成如下形式:
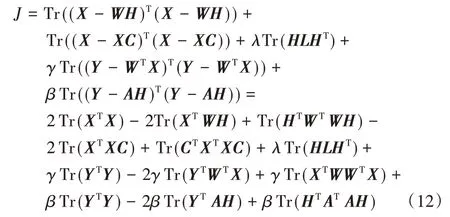
应用矩阵迹的性质Tr(AB)=Tr(BA)和Tr(A)=Tr(AT)。令φ、ψ、Ω和θ分别为W、H、C、和A的拉格朗日乘子,则J对应的拉格朗日函数的形式为:
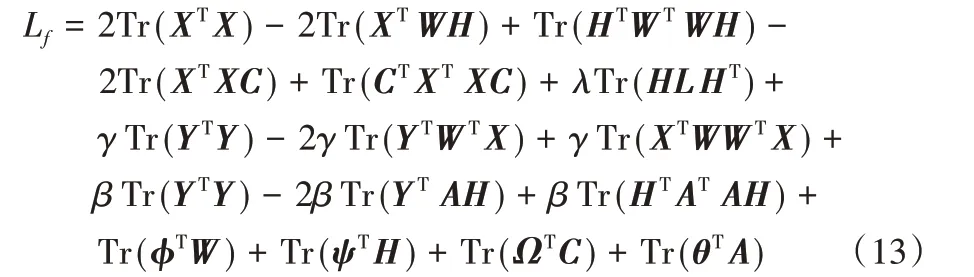
分别对Lf中的W、H、C和A求偏导数:
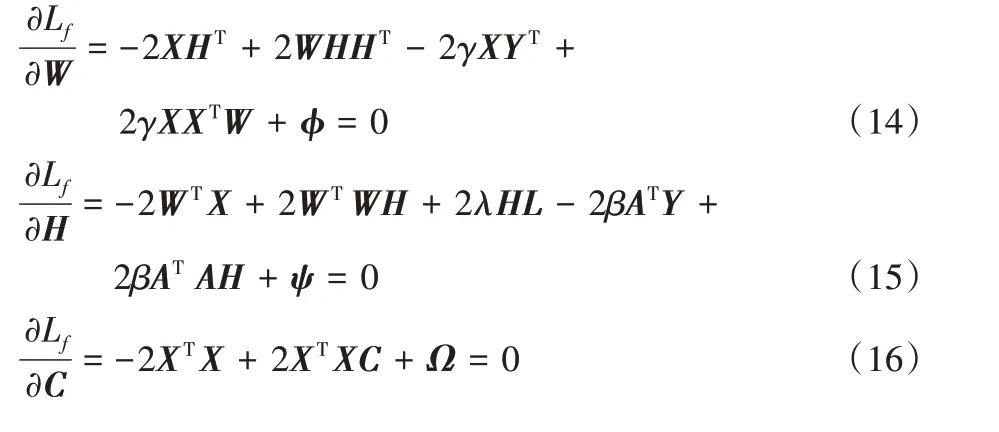
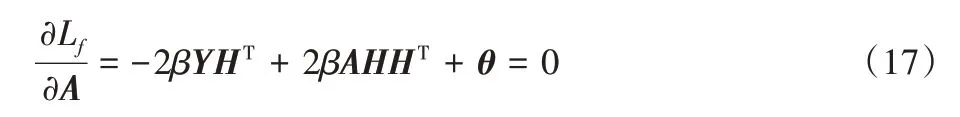
由KKT 条件φijWij=0、ψjkHjk=0、ΩkkCkk=0 和θjj Ajj=0,可以得到下面的公式:
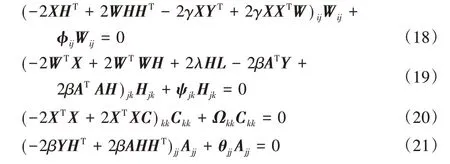
于是,式(11)中关于W、H、C和A的乘性更新规则为:
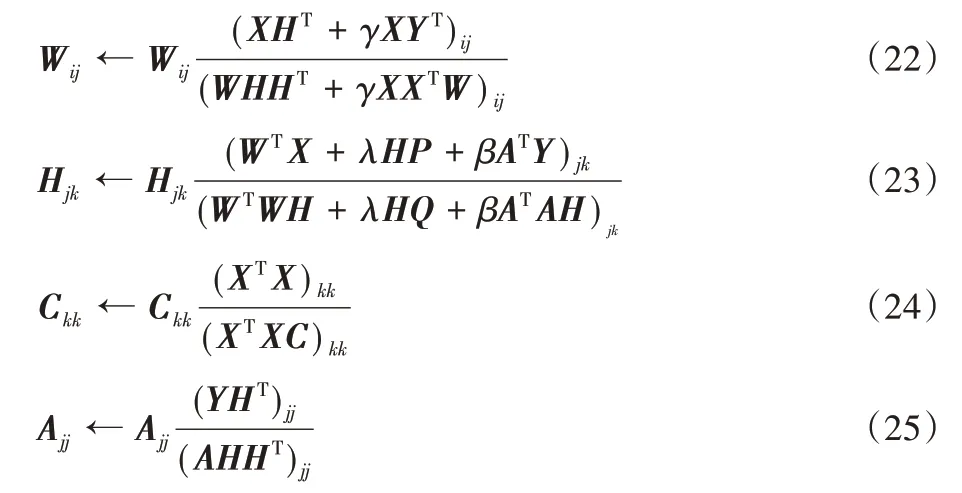
在式(22)~(25)的更新规则下,目标函数
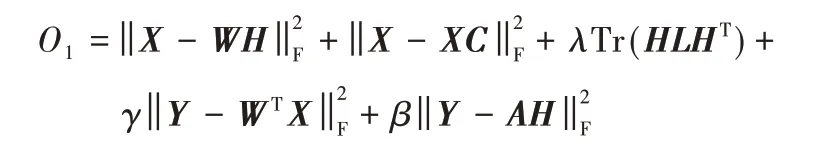
是非增的。目标函数中的W、H、C和A分别进行迭代,直到迭代次数超过设置的最大值或者式(11)的值趋于不变。具体流程如算法1所示:
算法1 图学习正则判别非负矩阵分解。
输入 训练集矩阵X∈Rm×n,类别指示矩阵Y∈Rr×n,参数λ、γ、β和r(r为训练集中样本的类别总数);
输出 基矩阵W。
过程
①初始化:随机初始化4 个矩阵W∈Rm×r,H∈Rr×n,C∈Rn×n,diag(C)=0,A∈Rr×r;计算P和Q;
②通过式(22)~(25)依次更新W、H、C、A;
③更新diag(C)=0;
④计算P=(C+CT)/2,;
⑤迭代步骤②~④直到目标函数的值趋于不变或者迭代次数到达所设定的最大值。
2.3 RCGLDNMF模型
RCGLDNMF 模型去掉了GLDNMF 中的自表示学习正则项,其中RC是Remove C 的英文简写,即不与GLDNMF 中学习到的自表示系数矩阵C结合,其模型为:
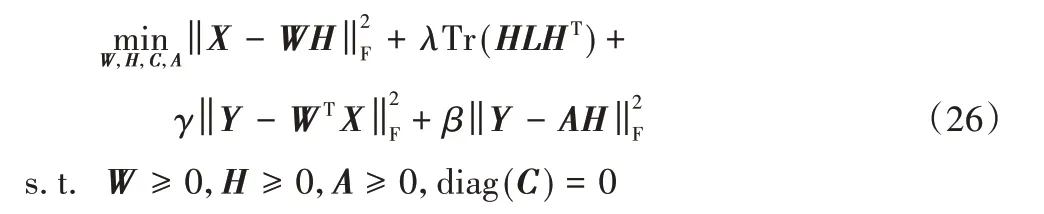
参数设置和矩阵语义均与GLDNMF 保持一致,但采用GNMF 中的相同方式构造拉普拉斯矩阵L所需的矩阵P和Q,并使用式(22)、(23)和(25)迭代更新W、H和A,在更新过程中不再修改矩阵L。
2.4 算法1的收敛性证明
为了证明本文所提出的算法1,需要证明O1在式(22)~(25)的更新步骤下不增加。对于目标函数O1,如果仅更新W,需要固定H、C和A,所以O1的第一项和第四项存在;同样,如果更新C,需要固定W、H和A,则O1的第二项存在。因此,本文对图学习正则判别非负矩阵分解中的W、C和A的更新公式与NMF中的公式相同。于是,本文利用NMF的收敛性证明来证明O1在式(22)、(24)和(25)的更新步骤下是不增加的。而NMF 的收敛性已被证实[2],因此,本文只需要证明O1在式(23)的更新步骤下是不增加的。本文遵循其中描述的过程,利用辅助函数可以证明O1的收敛性。
定义当G(h,h′)满足以下条件为F(h)的辅助函数:

此辅助函数对于以下的引理非常重要。
引理1如果G是F的辅助函数,那么F在更新的过程中是非递增的。

现在证明在式(23)中对H的更新等同于对在上述辅助函数的条件下对式(28)的更新。
考虑任意元素hab∈H,用Fab表示在O1中只与Hab有关的元素。通过对其求偏导易得出下列式子:
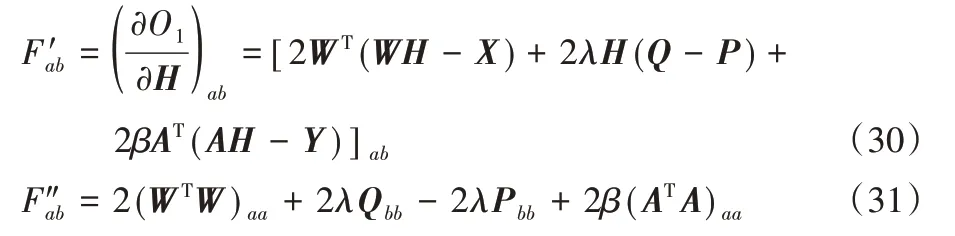
由于更新的本质是基于元素的,所以这足以说明在式(23)的更新步骤下每个Fab都是非递增的。于是,引入以下引理。
引理2函数
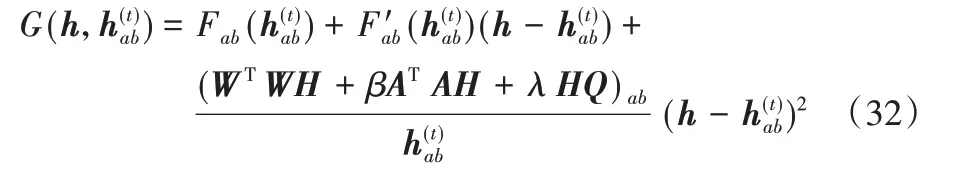
是Fab的辅助函数。
证明 由于G(h,h)=Fab(h)是显而易见的,所以仅证明。因此,首先考虑用Fab(h) 的泰勒展开公式:

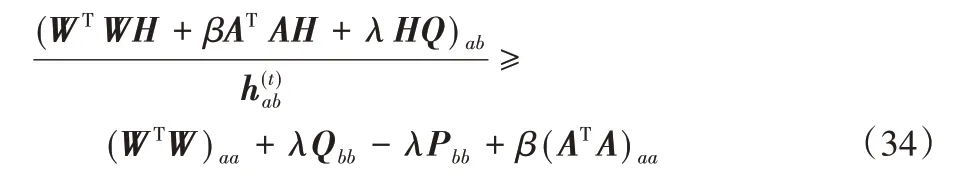
并且存在以下事实:
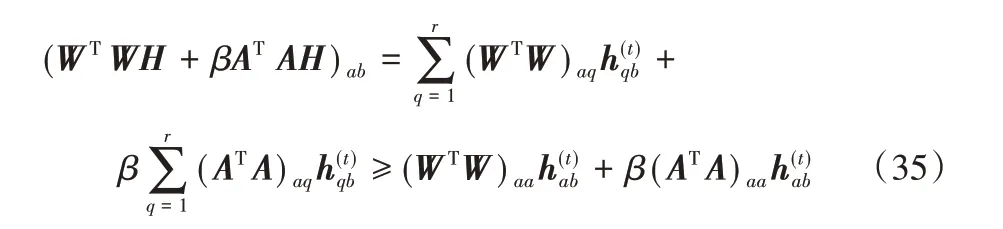
和


由于式(32)为辅助函数,所以在此更新规则下Fab是非递增的。
3 实验与结果分析
本文在两个人脸数据集UMIST[35]和Yale[36](部分示例如图1 所示)上测试了所提算法的识别性能,并与已有的典型算法进行对比,包括:PCA、LPP、NMF、LNMF、GNMF、GDNMF 和RCGLDNMF,而且实验中不同算法的相同参数都取一样的值。

图1 UMIST和Yale数据集中的人脸图像示例Fig.1 Face image examples of UMIST and Yale datasets
3.1 实验数据集
两个数据集的统计描述如表1所示。

表1 两种数据集的统计Tab.1 Statistics of two datasets
UMIST 人脸数据集包含20 个人的575 张PGM 格式的图像,每一类的样本数从19~48 张不等。将每幅图像下采样为40×40 像素阵列,然后使阵列中的每一列首尾相接拼成一个列向量。Yale 人脸数据集包含15 个人的165 张GIF 格式的图像,每一类的样本数为11 张图像。将每幅图像下采样为40×40 像素阵列,然后使阵列中的每一列首尾相接拼成一个列向量。
3.2 实验过程
实验中使用的所有人脸图像都是手动对齐和裁剪的。每张人脸图像都被表示为一个列向量,而后将其特征(像素值)缩放到[0,1](即每个像素点的值除以255)。从每个类中随机选取一些图像构造训练集,例如表2中的5train 表示每类中随机选取5 个样本构造训练集,剩余的图像构造测试集,其他情况以此类推。如表1 所示,在UMIST 和Yale 数据集中,UMIST 中每类的样本数目为19~48,而Yale 中每类的样本数目为11,所以在UMIST 数据集中可以选择11train,而在Yale数据集中最多只能选择9train。将训练集输入到不同的模型中学习低维空间的基矩阵,并将学习到的基矩阵作为投影矩阵分别对训练集和测试集进行降维。测试集用于测试在得到的低维空间中人脸识别的准确性。在本文实验中,使用1-近邻分类器。在计算基矩阵W的过程中,NMF及基于NMF的各种改进算法都要进行1 000 次的重复迭代。这些实验独立进行10次,然后计算出平均精度,以保证实验结果的准确性。
3.3 实验参数选择
本文提出的GLDNMF 存在三个正则化参数,即λ、γ和β。在实验中,固定从每类中选取的样本数量,以此来分析参数对识别精度的影响,实验中随机从每类中选取5 张图像构造训练集,每类中剩余的图像构造测试集。本文算法在不同数据集上的平均识别精度会随着参数值的变化而变化。
图2 是固定γ和β时,准确率与λ的关系曲线,可以看出,随着λ的增大,识别精度并未表现出明确的规律性,波动幅度较大,但在λ<100 时,随着λ的增大,识别精度虽有剧烈波动,但大体趋势是逐渐升高,并在λ=100 时达到顶峰,而后λ继续增大时,识别精度的大体趋势是逐渐减小。图3是固定λ时,准确率与γ和β的关系曲线,可以看出,随着γ的增大,识别精度在逐渐提高,但是,随着β的增大,识别精度时好时坏,综合UMIST 和Yale 数据集中的表现,选择γ较大,β较小。综合考虑三个参数的取值在两个数据集上的实验结果,折中选择的实验参数取值为:λ=100,γ=0.6,β=0.2。
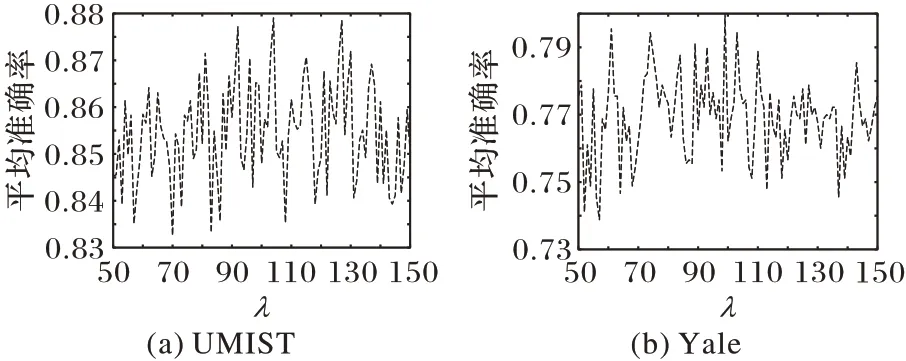
图2 γ和β不变时准确率与λ的关系Fig.2 Relationship between accuracy and λ with fixed γ and β
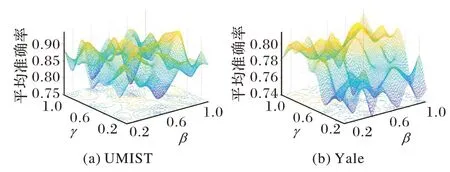
图3 λ不变时准确率与γ和β的关系Fig.3 Relationship among accuracy and γ,β with fixed λ
表2 与表3 中的RCGLDNMF 是在设置相同参数值时,去掉自表示的正则化项后进行的模型测试结果,即在该模型的学习过程中,不再更新拉普拉斯矩阵。表2和表3中的粗体表示在相同参数的情况中,不同算法用于人脸识别的最佳平均准确率。
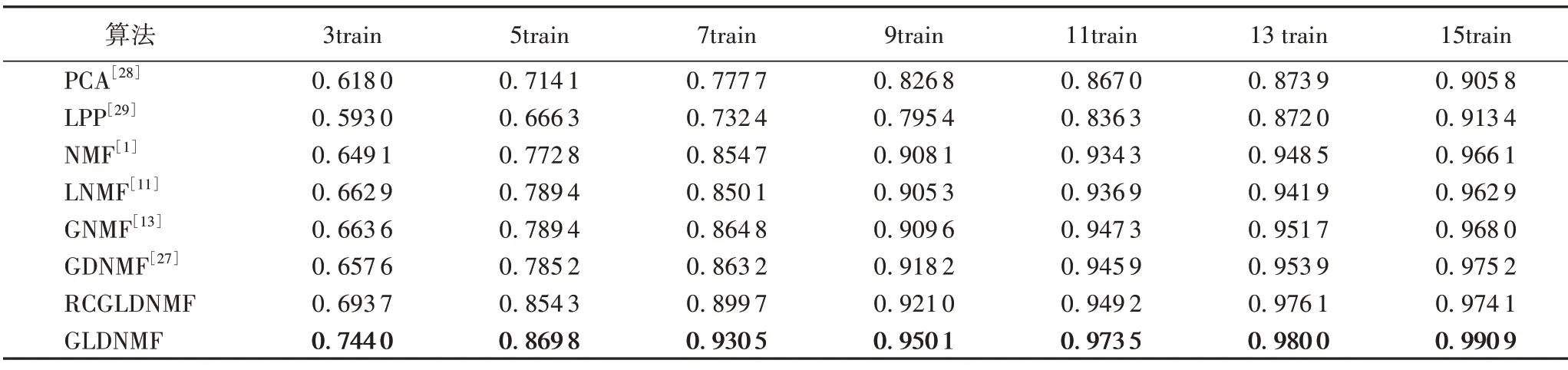
表2 不同算法在UMIST数据集上的平均准确率Tab.2 Average accuracies of different algorithms on UMIST dataset
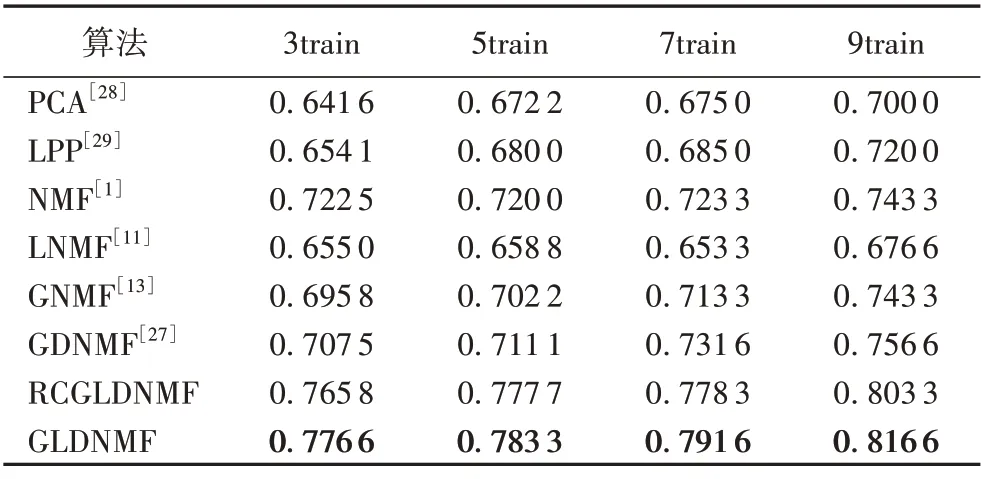
表3 不同算法在Yale数据集上的平均准确率Tab.3 Average accuracies of different algorithms on Yale dataset
从表2、3 的实验数据可以看出,GLDNMF 比RCGLDNMF在识别精度上最多达到5 个百分点的提升,这说明在模型学习过程中更新拉普拉斯矩阵对识别精度是有益的。而且在此实验中,数据集要降到的维数r为训练集中样本的类别总数:对于UMIST数据集,r=20;对于Yale数据集,r=15。
图4 验证了本文算法的收敛性,随着迭代次数的增加重构误差趋于平缓并且不变。

图4 迭代次数与重构误差之间的关系Fig.4 Relationship between iteration number and reconstruction error
4 结语
本文提出了图学习正则判别非负矩阵分解算法GLDNMF,同时引入了子空间聚类中的自表示学习、流形学习和标签信息。在非负矩阵分解的迭代过程中不断更新图的拉普拉斯矩阵,可以更好地保持高维数据在低维空间中的结构信息,利用训练集的标签信息可以提高投影矩阵的判别能力。实验结果表明,与PCA、LPP、非负矩阵分解及其几种有代表性的变体相比,GLDNMF 具有更强的判别能力和更高的识别精度。
猜你喜欢
当代陕西(2022年4期)2022-04-19
作文中学版(2022年1期)2022-04-14
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
文萃报·周五版(2021年17期)2021-05-31
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
通信产业报(2018年10期)2018-04-13
天津诗人(2017年2期)2017-11-29
神州·上旬刊(2017年9期)2017-10-15
