
基于神经正切核的多核学习方法
2022-01-05 02:31许传海
计算机应用 2021年12期
王 梅,许传海,刘 勇
(1.东北石油大学计算机与信息技术学院,黑龙江大庆 163318;2.黑龙江省石油大数据与智能分析重点实验室(东北石油大学),黑龙江大庆 163318;3.中国人民大学高瓴人工智能学院,北京 100872;4.大数据管理与分析方法研究北京市重点实验室(中国人民大学),北京 100872)
(∗通信作者电子邮箱liuyonggsai@ruc.edu.cn)
0 引言
核方法,如支持向量机(Support Vector Machine,SVM)[1]、最小二乘支持向量机[2]等,是一类重要的机器学习方法。这些方法隐式地将数据点从输入空间映射到一些特征空间,并在特征空间中学习线性学习器。隐式特征映射是由核函数诱导生成,因此核函数选择的好坏决定核方法的性能。然而,传统的核函数如线性核函数、多项式核函数和高斯核函数等只具有浅层结构,表示能力较弱。
虽然核方法能使线性方法这样简单的算法表现出令人印象深刻的性能,但是它们都是基于单个核函数的单核方法,它们在处理样本中包含异构信息[3-7]、样本规模较大[8-9]、数据不规则或者数据分布不平坦[10]时存在很多的不足。为此,人们提出了多核学习方法代替单核方法,不仅能增强决策函数的可解释性,还能获得比单核模型更优的性能[11]。
为了提高多核学习方法的精度,一些人开始在规定的一组连续参数化的基本核函数的凸集中学习核问题[12],但大多数的多核学习算法所使用的度量通常是基于半径边缘或其他相关的正则化泛函,通常具有较慢的收敛速度。
为解决上述问题,本文提出了一种基于神经正切核(Neural Tangent Kernel,NTK)的多核学习方法。首先,用NTK 替代传统的核函数如线性核、高斯核和多项式核等作为多核学习方法的基核函数;接着,采用主特征值比例的度量方法证明了一种收敛速度较快的泛化误差界,相比现有的度量方法,该度量定义在核矩阵上,可以很容易通过训练数据进行估计;然后将主特征值度量求出的特征值比例与核目标对齐方法相结合,求出每个基核函数的最优权重系数,采用线性合成的方法求出多核决策函数进行问题的求解;最后,在标准数据集上进行实验,结果表明本文提出的方法有着较好的效果。
1 相关工作
1.1 多核学习
与单核只学习单个核函数不同的是,多核学习遵循不同的方式学习一组基本核函数的组合系数[13]。但是,如何通过学习获得最优的组合系数是一个需要解决的难题。针对这一问题,近年来学者们通过理论研究和经验证明提出了多种多核学习方法。如基于Boosting[14]的多核组合方法,基于半无限线性规划[15]的学习方法,以及简单多核学习[16]方法和基于无限核[17]的学习方法等。在这些多核学习框架内,最终的内核函数通常是有限个基本核函数的凸组合,且基核函数需要进行提前设置。
在过去的几年中,人们针对多核学习方法展开了大量的研究,提出了许多有效的算法来提高学习效率和预测(分类)的精度。如Alioscha-Perez 等[18]采用随机方差缩减梯度方法,避免了大量的矩阵运算和内存分配,解决了多核学习方法无法扩展到大规模样本的问题;Wang等[19]基于类内散布矩阵的迹,提出了一种名为迹约束多核学习的方法,该方法可以在学习基核权重的过程中同时调整正则化参数C,节省训练时间;Liu等[20]根据每个样本的观测通道对样本进行分类,提出了一种无需进行任何插补的缺失多核学习方法,提高了算法的分类性能。针对基核函数的组合策略,王梅等[21]通过求解秩空间差异性对核函数进行组合;贾涵等[22]采用模糊约束理论求解各核函数的权重得到组合核函数;He等[23]通过使用核目标对齐的方法计算单核的权重,进而构造最终的合成核。
1.2 泛化理论
基核选择对于多核学习具有重要影响,它与泛化误差算法密切相关,一般泛化误差最小的核被认为是最优核。近年来,人们利用局部拉德马赫复杂度推导出了更紧的泛化界。Koltchinskii 等[24]首次提出局部拉德马赫复杂度的概念,利用迭代的方法获得数据相关的上界。Bartlett等[25]基于局部拉德马赫复杂度导出了泛化界,并进一步提出了凸函数在分类和预测问题中的一些应用。基于局部拉德马赫复杂度和积分算子尾部特征值的关系,Kloft 等[26]导出了多核学习的泛化界。然而核函数积分算子的特征值很难计算,为此Cortes等[27]利用核矩阵的尾特征值设计了新的核学习算法。但对于不同类型的核函数,核特征值的差异可能很大,因此核函数的尾特征值不能很好地反映不同核函数的优度。对此,Liu等[28]首先考虑了核函数的特征值的相对值,并在文献[29]中将特征值相对值的另一度量——主特征值比例应用到多核学习方法中。
1.3 神经网络与核方法
神经网络和核方法之间的联系在二十几年前就已经开始研究。Williams[30]的早期工作已经注意到具有无限宽度的单隐层的神经网络和高斯过程之间具有等价性。Lee 等[31]又将该结果扩展到深度完全连接的神经网络上,只对最后一层进行训练,其余层都保留初始值。最近Jacot等[32]研究表明过参数化深层神经网络的训练可以用一种名为神经切线核的核回归训练动力学来进行表征。NTK在无限宽极限下趋于一个确定的核,而且在梯度下降的训练过程中保持不变。虽然上述理论结果仅在无限宽度限制下是精确的,但Lee 等[33]通过实验发现,即使对于有限宽度的实际网络,原始网络的预测与线性化版本的预测之间也具有很好的一致性。除了在全连接网络上,NTK 还被应用于卷积神经网络[34]、残差网络[35]和图神经网络[36]等多种神经网络结构中。此外,Li 等[37]从经验上表明,使用NTK 进行分类可以获得具有相应结构的深层神经网络的性能。最近的工作还比较了NTK 与普通核函数的性能,Arora等[38]通过实验表明NTK优于高斯核和低次多项式核。
2 本文方法
下面将简要介绍NTK、主特征值比例和核对齐等概念,然后对本文提出的基于NTK 的多核学习方法(Neural Tangent Kernel-Multi-Kernel Learning,NTK-MKL)进行阐述。
2.1 符号定义
令k:X×X→R 表示d维输入空间X∈Rd中的核函数,它对应于再生核希尔伯特空间H中输入向量的点积。也就是,存在映射函数φ将输入数据从输入空间X映射到核空间H中,使得k(xi,xj)=φ(xi)⋅φ(xj),其中xi,xj∈X。
泛化误差(风险)R(f)是度量算法性能的常用评价准则:
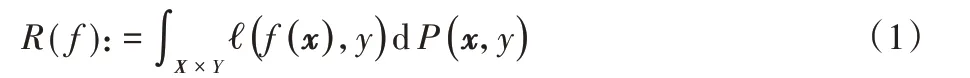
其中ℓ(f(x),y):Y×Y→[0,B]为损失函数,B为常数。在本文中,对于分类ℓ 是铰链损失:ℓ(t,y)=max(0,1-yt)。由于概率分布P是未知的,那么R(f)就不能被明确地计算出来,因此使用它的经验分布:

2.2 核方法与多核学习
支持向量机(SVM)是一种比较常用的核方法。假设在二分类问题中,SVM 的目的是在特征空间中找到一个能以最小错误率将数据分开的分类超平面vTφ(x) +b=0,其中v是超平面的法向量,b为偏置。超平面的获得可通过求解以下优化问题解决:
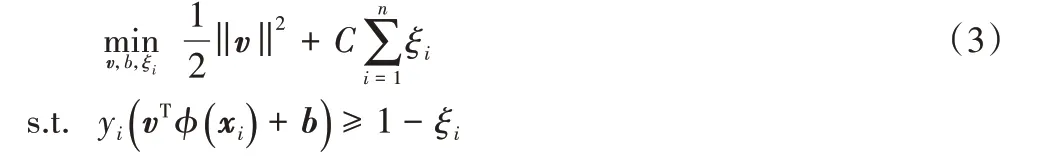

其中:ξ=(ξ1,ξ2,…,ξn)T是松弛变量的向量形式;C是权衡训练误差和泛化之间的正则化参数。假设αi是式(3)中第i个不等式对应的拉格朗日乘子,那么式(3)的对偶问题可以写成:

对式(4)进行求解后,SVM的决策函数可以写成:

其中样本xi是具有拉格朗日乘子ai>0的支持向量。
与用一个固定的核进行学习不同的是,多核学习通常组合不同的基核函数来获得更好的映射性能,其采用φ(⋅)=的形式进行映射,且这些基核可以由不同类型的核函数或具有不同核参数的核构建。本文采用线性组合合成方法对多个基核函数进行凸组合,则最终的组合核函数Kd可表示为:


2.3 神经正切核
首先定义一个含L个隐层的全连接神经网络,其中第0层为输入层,第L层为输出层。让x∈Rd表示为输入数据,则,那么L隐层的全连接神经网络可以被递归定义为:
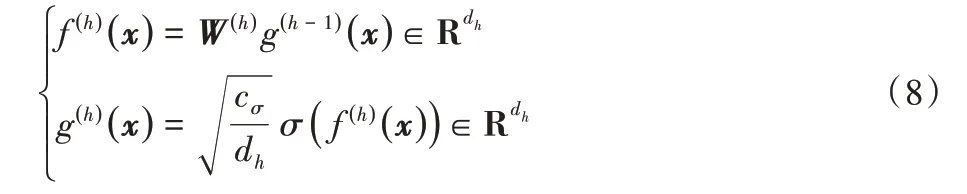
其中:h=1,2,…,L;表示为第h层的权重矩阵,dh为隐层的宽度;σ:R →R 是激活函数;cσ是缩放因子。本文中,对于全连接神经网络,将σ设置为ReLU激活函数,对于NTK 考虑其为具有ReLU 激活函数的全连接神经网络所诱导出的核函数。神经网络的最后一层被表示为:

给定n个数据点,y′=,则神经网络的输出函数可以表示为:
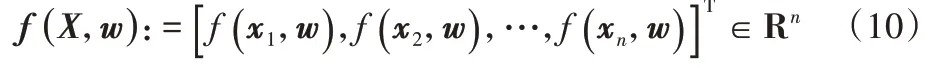
在神经网络的训练过程中,使用无穷小学习速率的梯度下降最小化目标的平方损失来学习网络参数w。对于时间t≥0 时,可以将网络参数w视为在优化过程中出现的随时间变化的连续变量wt。
当隐层宽度趋于无限宽限制时,即d1,d2,…,dL→∞,文献[32]证明了wt在优化过程中保持恒定等于w0,即NTK 核在无限宽限制下不随时间变化。此外,该文献中还证明了在一定的随机初始化和无限宽限制下,NTK 核概率收敛到一个确定的极限核,这意味着在某些初始化下对神经网络的预测与使用NTK 核进行的核回归之间是等价的。NTK 核的极限梯度核形式可以写为:
由式(11)可知NTK 核相当于一个具有多层结构的神经网络,相对于一般多核学习方法使用浅层结构的基核函数,NTK 对于复杂数据有着更好的表示能力,且最近的实验工作表明,使用NTK 核的核方法的性能与具有相似网络结构的神经网络性能相似,某些情况下甚至更好,所以本文采用NTK核作为多核学习方法的基核函数。
2.4 核对齐
核对齐是由Cristianini等[39]引入的一种核度量标准,它定义了理想核函数,主要度量目标核函数与理想核函数之间的相似性,两者的对齐值越大,分类器在特征空间中泛化能力越强。
定义1核对齐。设K1和K2是两个来自数据集S={(x1,y1),(x2,y2),…,(xm,ym)}上的核k1和k2所导出的核矩阵,那么这两个核之间的核对齐定义为:

当K2为从标签y(x)中导出时,式(12)转换为:

其中:K为核函数k对应的Gram 矩阵;y=(y1,y2,…,ym)T,yyT为理想核矩阵。
从式(13)可知,其值越大,目标核矩阵与理想核矩阵之间的距离越小,目标核函数对样本数据的特征选择和表示能力就越好,可以很好地度量核函数k的性能,所以本文采用核对齐方法对基核函数进行度量,计算对应基核函数的权重参数。
2.5 主特征值比例
定义2主特征值比例。设K是一个核函数,K=是它的核矩阵。那么K的主特征值比例被定义为:

其中:t∈{1,2,…,n-1};λi(K)是矩阵K降序排列的第i个特征值;tr(K)是矩阵K的迹。
定理1假设ℓ是一个L-Lipschitz损失函数,∀K∈КNTK有:
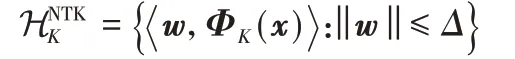
其中:ΦK(x)是关于NTK 核的特征映射函数,КNTK是一组有限的NTK 核函数,概率为1-δ,那么当∀k≥1 且时,下面的不等式成立,

其中:c3=40Δ2L2k,c4=。
证明 该定理是基于前期工作导出的,首先基于局部拉德马赫复杂度证明了NTK 核再生希尔伯特空间关于主特征值的界。然后根据文献[40]定理4.1的不等式

导出了关于泛化误差R(f)和经验误差的不等式。上式中f为一类范围在[-1,1]中的函数,B为常数为子根函数(sub-root function)的定点。最后,估计了,并给出了的范围,完成了定理的证明。具体的证明过程可以参考文献[29]的定理2。与之不同的是,本文把以前的传统核换成了NTK核,当令k=log(n)时,的收敛速率为:

当n较大时,可以知道,所以R(f) -。可以看到,对于任意的t,的值越大,其泛化界就越紧,导出的界也就越好。
2.6 基于NTK的多核学习算法

其中:λ为正则化参数,分别表示为第i个基核函数的主特征值比例和核对齐值。将上式进行归一化得到:

式(16)即为最终的基核函数的权重系数。那么式(6)可以改写为:

参考式(7),最终基于SVM 的多核学习方法求解优化问题后,得到的决策函数可表示为:
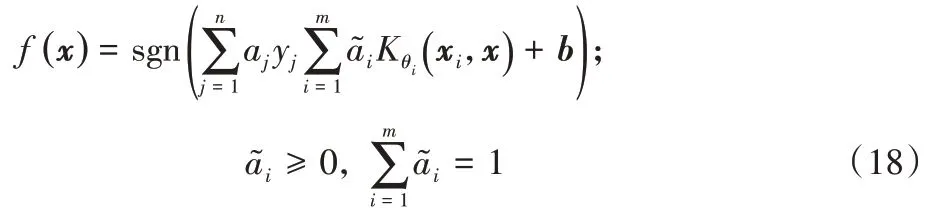
综上所述,本文基于NTK 核提出了一种名为NTK-MKL的多核学习算法,将传统的单层次的基核函数改为具有深层结构的NTK 核,将核对齐方法和主特征值比例结合来求取基核函数的权重参数,最后以线性加权组合的方式来构造多核函数进行问题的求解,算法的具体流程如算法1所示。
算法1 NTK-MKL。

3)基于步骤1)、2)根据式(16)求得基核函数权重参数αi;
4)将αi根据式(16)进行归一化得到最终的权重参数;
6)将Kd代入多核SVM 中求解优化问题,求出决策函数f(x)。
2.7 时间复杂度分析
假设数据集的规模为n,基核函数个数为m,特征值个数为t,输入数据的维度为d,则计算基核函数的主特征值比例的时间复杂度为O(tn2),计算基核函数的相似性度量的时间复杂度为O(n2),计算具有L个隐层全连接神经网络的NTK 的时间复杂度为O(n2(d+L)),应用梯度下降法求解优化问题的时间复杂度为O(n2)。由此可知,本文提出的NTK-MKL 算法的时间复杂度为O(tmn2)+O(mn2)+O(n2)+O(mn2(d+L))。
3 实验结果与分析
3.1 数据集
本文采用6 个UCI 数据集来验证所提算法的性能,其中包括汽车评估数据集(car)、避孕方法选择数据集(cmc)、红酒质量数据集(red-wine)、苗圃数据集(nursery)、网上购物者购买意图数据集(shoppers)和阿维拉(avila)数据集,数据集的详细信息如表1所示。

表1 UCI数据集信息Tab.1 UCI dataset information
虽然UCI 数据集是标准数据集,但其官网提供的原始数据中还是会出现一些格式的问题,不能直接用于程序的计算,需要对其进行相应的处理。如avila 数据集标签属性的值为A-I和W-Y 共计12类,为方便进行分类任务,需将连续数值离散化,本文根据不同类别所占的数据规模,将数据分为三类,其中A 和B-F各为一类,G-I与W-Y 合成为一类,分别用0、1、2表示。还有一些数据集中存在一些字符型离散型数据,需要将其根据某种规则转换为数值型数据。如car 数据集中的low、med、high和vhigh等属性值,本文在[-1,1]区间内平均取n个实数进行替换,n为字符型属性个数,那么low、med、high和vhigh根据规则被转换为-1、-0.5、0.5和1。
3.2 实验方法与结果分析
本节将通过2 类实验来验证本文提出的多核学习方法的有效性和可行性。实验1 为NTK 与传统的核函数的对比实验,实验2 为在本文提出的多核学习方法上分别使用传统核和NTK 与其他分类算法的对比实验。实验采用准确率(accuracy)、召回率(recall)和精确率(precision)三个指标来对多核学习算法的性能进行评价,其中召回率和精确率为宏召回率和宏精确率。所有实验均随机选取70%数据作为训练数据,30%作为测试数据。
3.2.1 单核对比实验及结果
首先利用Google 开发的NEURAL TANGENTS 软件包来随机初始化3 个NTK 函数,分别用ntk1、ntk2和ntk3表示,随机数的范围为{0,1,2}。每个ntk的网络结构均为3层,第0层为输入层,第3 层为输出层,激活函数为ReLU,第一层的神经元数均为2 048;第二层的神经元数均为2。然后将3 个NTK 函数与高斯核函数和多项式核函数应用到支持向量模型,在car数据集和shoppers 数据集上进行对比实验,其中高斯核函数的参数为0.1,多项式核函数的参数为3,car 数据集和shoppers 数据集的实验结果如表2。由表2 可以看出,NTK 的准确率在两个数据集上均高于传统的核函数,说明NTK 相较于传统的核函数有着更好的效果。除此之外,在表2 中传统核虽然有着不错的准确率,但精确率和召回率相对较低,也就是说传统核在进行多分类时对数据规模较大的类别识别效果较好,但对于规模较小的类识别效果较差。由此,也可看出NTK 相较于传统的核函数,在数据集较大且数据分布不均衡时有着更好的表示能力。

表2 car数据集和shoppers数据集上的实验结果 单位:%Tab.2 Experimental results on car dataset and shoppers dataset unit:%
3.2.2 分类算法对比实验及结果
首先采用与上一节相同的方法来完成NTK 的初始化,然后对传统核和NTK 采用2.6 节所描述的算法,在cmc、redwine、nursery、shoppers 和avila 数据集上与Adaboost 算法和K近邻(K-Nearest Neighbor,KNN)算法进行对比。其中Adaboost 算法的最大迭代次数(n_estimators)设置为50,学习率(learning_rate)设置为1;KNN 算法的k值设置为5,近邻样本的权重(weights)设置为uniform。分类算法在数据集上的准确率结果如表3 所示,其中:MKL(r+p)表示使用高斯核和多项式核采用本文所提算法进行组合计算,NTK-MKL 表示使用ntk2和ntk3使用本文算法组合计算。由表3 可以看出,MKL(r+p)和NTK-MKL 的效果在所有数据集上都比Adaboost和KNN 算法要好,说明本文的NTK-MKL 算法是有效且可行的。除此之外,在nursery、shoppers 和avila 等规模较大的数据集上NTK-MKL 效果要好于MKL(r+p),说明NTK 核相较于传统的核函数在处理较大规模的数据时具有更好的表示能力。
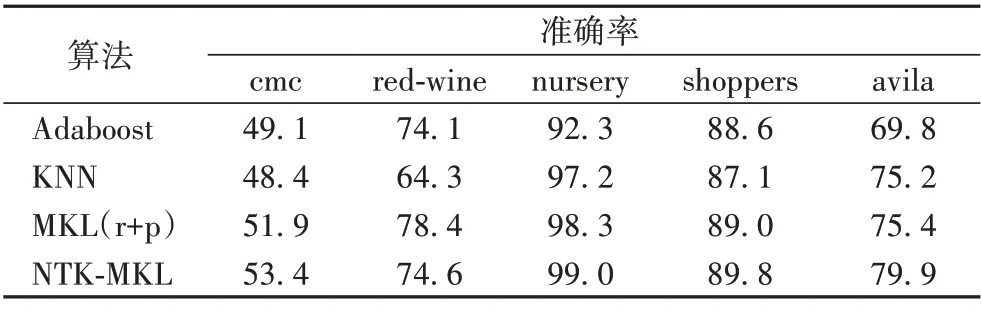
表3 分类算法对比实验结果 单位:%Tab.3 Experimental results comparison of classification algorithms unit:%
4 结语
本文基于主特征值比例和目标核对齐度量,提出了一种新的多核学习算法NTK-MKL。该算法首先使用NTK 作为多核学习的基核函数,然后将主特征值比例和核对齐相结合作为基核函数的度量准则,求出每个基核函数的权值比例,根据权值比例将基核函数进行线性加权组合,基于SVM 形成多核学习分类器,完成分类任务。相较于传统的多核学习方法,NTK-MKL 拥有更好的表示能力和更快收敛速率的泛化误差界。实验结果表明,本文提出的多核学习方法在多个数据集上的学习结果较佳。由于NTK 核具有多层结构,在对其进行计算时需要消耗较多的时间,如何减少计算时间将是下一步需要解决的问题。
猜你喜欢
北京大学学报(自然科学版)(2022年4期)2022-08-18
上海文化(文化研究)(2022年3期)2022-06-28
安徽工业大学学报(自然科学版)(2022年2期)2022-04-16
社会科学战线(2022年2期)2022-03-16
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
新生代(2019年16期)2019-10-18
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
