
基于上界单纯形投影图张量学习的多核聚类算法
2022-01-05 02:31雷皓云任珍文汪彦龙李浩然
计算机应用 2021年12期
雷皓云,任珍文,汪彦龙,薛 爽,李浩然
(1.西南科技大学国防科技学院,四川绵阳 621010;2.电子科技大学信息与通信工程学院,成都 611731;3.计算机软件新技术国家重点实验室(南京大学),南京 210023;4.浙江传媒学院媒体工程学院,浙江杭州 310018)
(∗通信作者电子邮箱rzw@njust.edu.cn)
0 引言
聚类致力于将一组无标签数据划分为多个类簇,是一种在机器学习与人工智能领域被广泛研究的基础科学问题[1-2],特别地,针对复杂非线性数据的聚类极具挑战性。
核方法能将原始空间中的非线性数据映射到可再生核希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS),使数据线性可分。因此,核方法在非线性数据处理问题上被广泛地应用。近年来,尽管传统的单核学习取得了长足的进步,但其面临着核函数与核参数选择的难题,而多核学习能很好地克服单核学习这一缺陷,同时能充分利用基核之间互补与一致信息,这使得多核学习在复杂数据聚类任务中变得非常流行。此外,图学习具有很强的挖掘数据复杂结构信息的能力,被特征提取、聚类分析、半监督学习和深度学习等研究广泛使用。基于上述讨论,将多核学习与图学习相结合,形成了新的多核聚类研究范式,即多核图聚类。
多核图聚类的核心问题是从多个预定义的基核中,利用图学习方法学习聚类用的关系图(Affinity Graph,AG)[3-6]。其典型的工作方式包括:1)通过多个基核函数构造多个核格拉姆矩阵,简称为基核;2)利用基核学习一个共识核与一个关系图;3)在关系图的基础上,使用图聚类算法得到最终聚类结果。
基于多核学习和图学习的优越性,近年来,涌现出了大量多核图聚类方法:例如,自保持结构的多核聚类(Structure-Preserving Multiple Kernel Clustering,SPMKC)算法分别引入了核组自表示项(Kernel Group Self-Expressiveness,KGS)和自适应局部结构学习项(Adaptive Local Structure Learning,ALSL),保留了数据的全局和局部结构信息[7],提高了关系图的质量;基于邻核子空间分割的多核聚类(Multiple Kernel Clustering with Neighbor-Kernel Subspace Segmentation,KSMKC)算法定义了近邻核概念,在线性加权核的邻域内搜索最佳共识核,并引入拉普拉斯秩约束规范图结构[8]。虽然上述方法已具备良好的性能,但将研究重心放在学习共识核上,这违反了基于图聚类过程中任务核心在于图的事实。因此,基于纯图学习的多核聚类(Multiple Kernel Clustering with Pure Graph learning,PGMKC)算法利用核空间中全局低维的流行结构获得多个候选关系图,随后通过自加权图融合策略和一个块对角性质直接完成类簇分割;基于共识关系图的多核聚类算法(Consensus Affinity Graph Learning,CAGL)保留了核空间中数据的局部流形结构,利用多个基核学习多个候选关系图,再直接通过一种自适应权重的图融合模型得到一个共识关系图,避免了同时学习共识核和关系图带来的巨大计算复杂度[9];同样的候选图学习方式在基于局部一致性和多样性图(Locally Consistent and Selfish Graph,LCSG)的多核聚类算法中被使用,与CAGL 不同,LCSG 通过施加图形连通性约束将数据自然地划分为所需的簇数,而不需要执行额外的聚类算法来生成最终的聚类标签[10]。
虽然现有的多核图聚类方法具有优秀的聚类性能,但仍面临三个问题:1)复杂的图学习技术将弱化聚类模型的可读性,并带来较高的计算代价;2)数据集样本的个数n远大于簇的个数c,导致图拉普拉斯矩阵的高秩特性,使得对聚类结果起到关键作用的块对角性质很难满足,削弱了聚类性能;3)大部分方法局限于二维矩阵层面的低阶信息挖掘,而忽略了候选关系图之间的高阶结构信息。
针对上述问题,本文提出一种新颖的多核图聚类方法,即基于上界单纯形投影图张量学习的多核聚类算法(Multiple Kernel Clustering algorithm based on Capped Simplex projection Graph Tensor learning,CSGTMKC)。如图1 所示,该方法的主要步骤包括:1)CSGTMKC利用核技巧将原始数据映射到希尔伯特核空间中得到多个基核;2)将每个基核直接投影到上界单纯形上形成候选关系图,同时,在此空间上提出了一种精确的块对角约束,使关系图在上界单纯形上具有良好的块对角性质;3)引入低秩张量学习,充分挖掘多个候选关系图间的高阶结构信息。
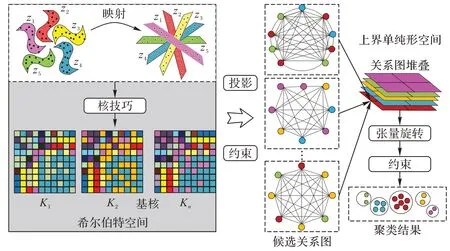
图1 CSGTMKC的框图Fig.1 Block diagram of CSGTMKC
本文主要的工作如下:
1)提出了一种新的图学习范式,利用投影技术将基核直接投影到上界单纯形上形成候选关系图,降低了图学习的计算复杂度;
2)提出一种新的块对角约束,使关系图具有更好的聚类结构;
3)引入三阶图张量学习,充分挖掘候选关系图间的高阶结构信息;
4)设计了一种基于ADMM 的优化算法来求解CSGTMKC,与最先进的多核图聚类方法相比,所提方法的聚类性能得到了显著提升。
1 相关工作
本章主要介绍本文提出的基于上界单纯形投影图张量学习的多核聚类模型。
1.1 符号定义
为了方便介绍,半正定的矩阵如M,表示为M-≻0。使用Q表示张量,对于一个三阶张量,它包含了两个重要的定义,即纤维和切片:纤维定义为三阶张量任意一阶为可变而剩余两阶为固定的状态,分别表示为:模式-1,Q(:,j,k),模式-2,Q(i,:,k)和模式-3,Q(i,j,:);切片定义为张量任意两阶为可变而剩余一阶为固定的状态,如水平切片Q(i,:,:),侧切片Q(:,j,:)和前切片Q(:,:,k)。为方便表示,将Q(:,:,k)表示为Q(k)。Qf=fft(Q,[],3)和Q=ifft(Qf,[],3)分别表示三阶张量Q的傅里叶变换和傅里叶逆变换。定义和fold(bvec(Q))=Q表示三阶张量的块向量化操作和块向量化操作的逆运算。使用分别表示块对角和分组循环矩阵。
1.2 三阶张量术语
为了帮助理解张量,本节介绍三阶张量相关的主要定义。
定义1两个维数相匹配的张量,如和,对应的乘积表示为,如:

定义2若一个张量的所有前切片都为对角矩阵,则称该张量为f‑对角张量。
定义3本文将张量的奇异值分解(tensor Singular Value Decomposition,t-SVD)定义为:

定义4本文使用‖Q‖⊛表示张量Q基于t-SVD 的核范数(t-SVD based Tensor Nuclear Norm,t-TNN)。等价于Qf所有前切片的奇异值之和,即表示为下式:
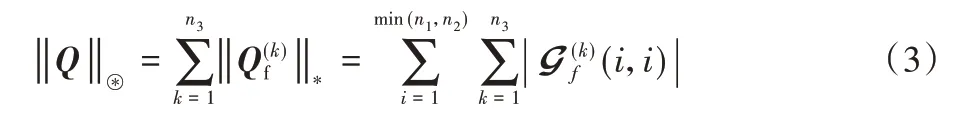
与基于展开的张量核范数相比,t-TNN 能更好地利用张量的结构信息[5]。
2 本文方法
在文献[23]中,通过大量基核来学习共识核,提升了关系图的质量。为避免复杂的图学习过程,本文将基核投影到上界单纯形(即可行单纯集与上限的组合)上直接形成关系图,因此预定义的m个基核投影后可得到m个候选关系图。在基于图的方法中,块对角性质是用于类簇分割的重要性质,由文献[4]可知:任意关系图对应的拉普拉斯矩阵中特征值0 的个数n应等于连通分量个数c。基于此,许多方法都使用了图拉普拉斯秩约束rank(L)=n-c来获得精确的块对角数[6],但由于实际情况中n的数量远大于c,导致L具有很高的秩,使得该约束很难满足。基于上述讨论,本文提出如下的目标函数:
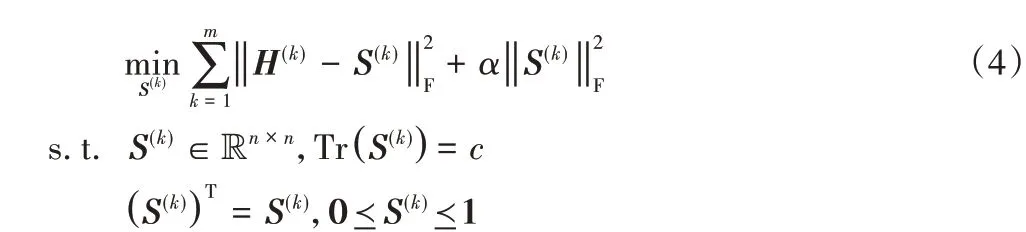
其中:H(k)和S(k)分别表示第k个基核和第k个候选关系图,α为平衡参数。在上界单纯形中投影得到S(k)后,使用F 范数正则化项来避免产生平凡解,同时避免S(k)中的某些元素值太大造成偏袒部分样本。此外,是单纯形上的块对角约束,来保持学习的图S具有精确的c个连通子图。由于篇幅限制,详细证明可在实验室主页(http://unix8.net)下载。
另一方面,由于张量能从高维角度出发,挖掘多个候选关系图之间的高阶结构信息来提高聚类性能[11],本文将获得的m个关系图堆叠成三阶张量S*∈Rn×n×m,然后旋转S*变为S∈Rn×m×n,即rotate(S*)。此外,由于图张量中的样本数n和特征数d远大于关系图的个数m,即n≫m和d≫m,因此给图张量S施加秩约束能捕获视图-视图、样本-样本之间的低秩结构信息。随后,通过对关系图的堆叠和旋转,并引入‖S‖⊛作为正则项,能充分捕获候选关系图间的高阶结构信息,如图2所示。至此,最终目标函数可以写成:

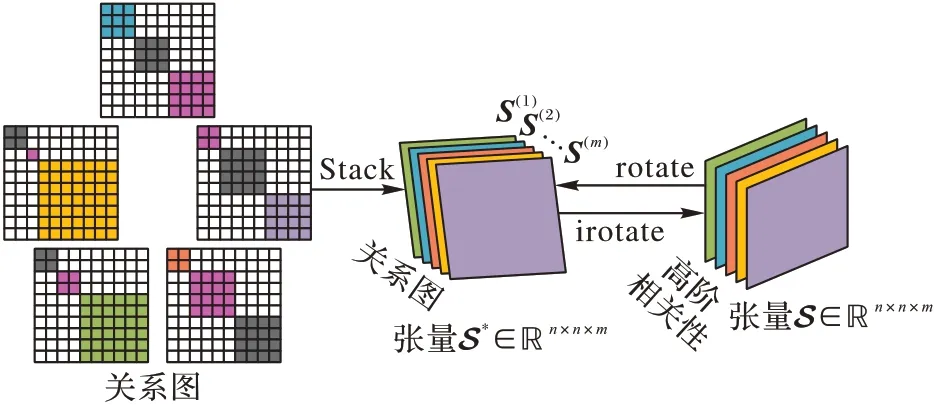
图2 CSGTMKC中张量的堆叠与旋转Fig.2 Tensor stacking and rotation in CSGTMKC
3 模型优化
本章提出了一种基于交替迭代方向乘子法(Alternating Direction Method of Multipliers,ADMM)的优化算法对式(5)进行优化求解。根据ADMM 的原理,首先引入一个辅助变量A,得到如下优化问题:
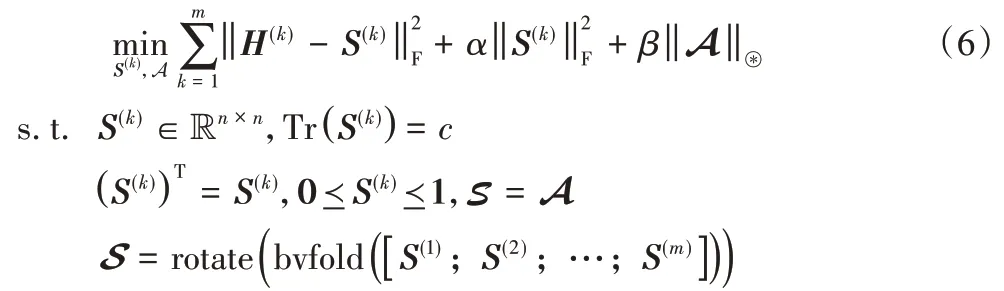
接着,式(6)的增广拉格朗日函数定义如下:
国际网间互联:DDoS统一管理平台通过骨干网运维系统对国际出口路由器或海外 POP 路由器发送黑洞路由,实现对特定方向流量、特定区域流量或全部流量的封堵。


其中Y为拉格朗日乘子,μ>0 为惩罚参数。接着,通过交替迭代的方法逐个更新每个变量。
3.1 固定其他变量,更新S

其中:A(k)和Y(k)分别为张量rotate(A)和rotate(Y)的第k个前切片。式(8)可以被改写为:
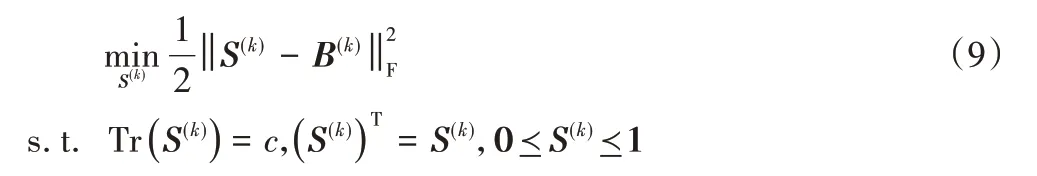
其中,B(k)为引入的辅助变量,定义为

接着,优化问题(9)可利用定理1进行快速求解。
定理1对于任意一个对称的关系矩阵S∈Rn×n,其SVD分解为B=UDiag(δ)UT,则下述问题:
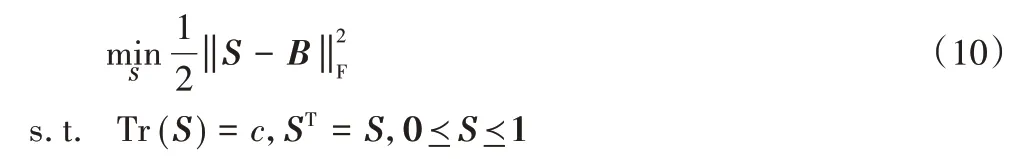
的最优解可通过S*=UDiag(ρ*)UT得到,其中ρ*由下式计算得到:

3.2 固定其他变量,更新A
关于A的优化问题如下:

定理2对于任意标量ρ>0 以及两个三阶张量,以下问题:

的全局最优解可由奇异值收缩算子计算得到[12],即
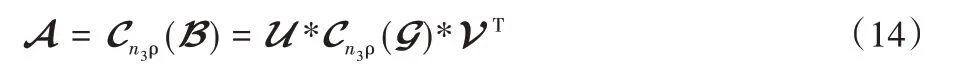
当B=U*G*VT且Cn3ρ=G*Q时,则表示一个f‑对角张量,Q的每一个对角元素定义为:
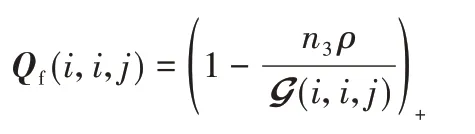
3.3 ADMM变量更新
本文通过以下方式更新ADMM的变量:

其中ρ和μmax是ADMM所涉及的标量。在每次迭代中,通过下述等式检查算法的收敛性:

其中,ε为阈值参数。在得到大小为n×m×n维度的张量S后,通过张量逆旋转操作S*=irotate(S),将S旋转为为n×n×m维度。随后,通过下式计算S*所有前切片的均值作为最终关系图,即-S:

综上,CSGTMKC 的伪代码如算法1 所示。有关聚类结果ACC、NMI的详细介绍参见实验部分4.2节。
算法1 CSGTMKC算法。

3.4 计算复杂度
4 实验与分析
本章通过6个公共基准数据集对CSGTMKC 进行评估,实验均在Matlab2016 上进行,电脑配置为3.2 GHz CPU 和16 GB RAM的Mac mini 2018。
4.1 实验准备
实验数据集包括:4 个人脸图像数据集Yale、Jaffe、AR 和ORL,一个物体数据集COIL20 和一个字符图像数据集(Binary Alphadigits,BA)。这些数据集被广泛用于评估聚类算法的性能。关于数据集的类数、样本数和特征数如表1 所示,6 个数据集的示例图像如图3 所示,读者可查阅文献[13-14]获得这些数据集更详细的描述。

图3 六个数据集的样本图像Fig.3 Sample images of six datasets

表1 数据集详细信息Tab.1 Details of datasets
本节选取6 个具有代表性的聚类方法包括:基于鲁棒多核k均值的聚类算法(Robust Multiple Kernelk-Means,RMKKM)[15]、基于多核k均值的聚类算法(Multiple Kernelk-Means,MKKM)[16]、基于图的低秩核学习聚类算法(Low-rank Kernel learning Graph-based clustering,LKGr)[17]、多核谱聚类算法(Spectral Clustering with Multiple Kernels,SCMK)[18]、基于自加权多核学习的聚类算法(Self-weighted Multiple Kernel Learning,SMKL)[19]和基于欧氏距离的权重策略(Euclidean Distance-based Weight Strategy,EDWS)检测的自保持全局和局部结构的多核聚类(Simultaneous Global and Local Graph Structure Preserving in EDWS,SPMKC-E)算法[20]进行对比分析。为了公平,这些对比方法分别遵循作者推荐的实验设置进行了仔细调整。
4.2 评价标准
聚类精度(ACCuracy,ACC)、标准互信息(NormalizedMutual Information,NMI)和纯度(Purity)是多核聚类任务用来衡量聚类精度普遍使用的指标[21],本文采用前2 个指标来评价所有多核聚类方法的聚类性能。若指标的值越大则表明聚类效果越好。有关这些指标的详细信息请参阅文献[22-23]。
4.3 聚类性能比较
实验分别对CSGTMKC 和6 个对比方法进行了20 次独立实验,结果如表2 所示,高优值用加粗字体表示,次优值加下划线表示。实验结果表明:

表2 基于ACC与NMI的聚类性能比较Tab.2 Clustering performance comparison in term of ACC and NMI
1)本文CSGTMKC 明显优于对比方法,在Yale、ORL、AR、COIL20、BA 数据集上,与MKKM、RMKKM、LKGr、SCMK、SMKL和SPMKC-E中获得的最高精度相比,CSGTMKC 的ACC分别提高了17.2、22.5、15.2、14.7 和44.1 个百分点,NMI 分别提高了18.8、13、8.2、7.9和33.4个百分点。
在Jaffe数据集上CSGTMKC 与SPMKC-E 的ACC 与NMI值都达到了1,但CSGTMKC的计算复杂度更低。
2)基于图的方法优于基于核k均值的方法,因为核k均值是在核空间中处理原始数据,而基于图的方法是通过在核空间中捕获数据的连通性来完成聚类。
3)与基于图的方法相比,CSGTMKC具有更好的块对角性质和稀疏性,且CSGTMKC 打破了低维关系的限制,通过构造三阶图张量获得高阶结构信息,提高了聚类精度。
4.4 参数敏感性
本文目标函数包括两个参数,其中:α用于平衡候选图S(k)的稀疏性(如,1≤k≤m);β平衡高阶张量S的低秩属性(如‖S‖⊛)。为验证CSGTMKC参数的敏感性,在ORL、COIL20 和AR 数据集上使用网格搜索法,分别在[10-6,10-5,10-4,10-3,10-2,10-1,1] 和 [10-3,10-2,10-1,1,101,102,103]范围内调谐α和β。实验结果如图4 所示:在AR、ORL 和COIL20 数据集上,当两个参数的范围分别为:α≥10-3,β≤10;α≥10-1,10-2≤β≤102和α≥10-3,β≤10时,CSGTMKC 能获得较好的聚类精度。实验结果表明,CSGTMKC的参数易调谐,对于较大范围内的参数都不敏感。

图4 AR、ORL和COIL20数据集上关于α和β的聚类性能Fig.4 Clustering performance in terms of α and β on AR、ORL and COIL20 datasets
4.5 收敛性和计算时间
本节通过记录每次迭代中收敛标准的值(即‖A-S‖∞)来分析算法1 的收敛性,在ORL 和COIL20 数据集上得到的收敛曲线如图5 所示:在经过20 次左右的迭代后收敛曲线趋于稳定,表明CSGTMKC具有良好的收敛性质。

图5 CSGTMKC在ORL和COIL20数据集上的收敛性能Fig.5 Convergence of CSGTMKC on ORL and COIL20 datasets
此外,本节评估了不同对比方法的运行时间,在Yale 和ORL 数据集上计算所有多核聚类方法的聚类时间(以秒为单位)。为提高方法之间的可比性,在实验过程中对每种方法设置相同的收敛条件。实验结果如表3 所示,结果表明:本文CSGTMKC 的运行时间低于MKKM、RMKKM、LKGr、SCMK、SMKL和SPMKC-E,且CSGTMKC 的聚类性能也是最好;此外,虽然MKKM 和LKGr 等方法的计算成本低于CSGTMKC,但它们的聚类性能较差。因此,从收敛性和计算成本两个方面考虑,本文提出的CSGTMKC是一种高效的多核聚类方法。
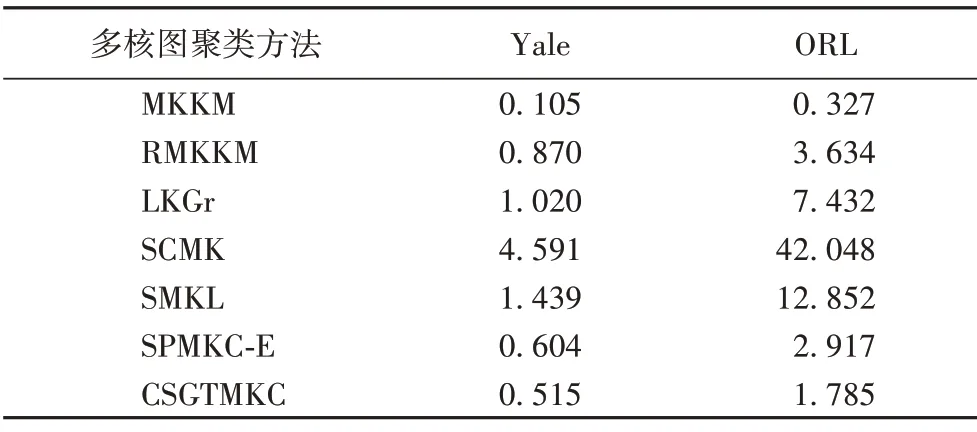
表3 不同多核图聚类方法的计算时间比较 单位:sTab.3 Computational time comparison of different MKGC methods unit:s
5 结语
本文提出了一种新的多核图学习方法,即基于上界单纯形投影图张量学习的多核聚类算法CSGTMKC,该方法通过将每个基核直接投影到上界单纯形上形成候选关系图,使其具有精确的块对角性质,同时引入张量学习来挖掘图中的高阶结构信息进而完成聚类。理论上,CSGTMKC能够解决图学习技术复杂、块对角性质难以满足和高阶结构信息缺失的问题。实验表明,与目前最先进的方法相比,CSGTMKC 在聚类性能与聚类时间上更有优势。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
科技信息·学术版(2022年8期)2022-02-25
现代计算机(2021年26期)2021-11-01
安徽大学学报(自然科学版)(2021年3期)2021-05-18
北华大学学报(自然科学版)(2021年1期)2021-03-12
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
数学大王·低年级(2018年4期)2018-05-07
科技视界(2018年5期)2018-05-07
