
基于动态概率抽样的标签噪声过滤方法
2022-01-05 02:31张增辉姜高霞王文剑
计算机应用 2021年12期
张增辉,姜高霞,2,王文剑,2*
(1.山西大学计算机与信息技术学院,太原 030006;2.计算智能与中文信息处理教育部重点实验室(山西大学),太原 030006)
(∗通信作者电子邮箱wjwang@sxu.edu.cn)
0 引言
噪声可以被定义为由与产生数据分布无关的外生因素引起的对数据项收集的信息的部分或全部改变[1]。对于分类任务,一般噪声按照其出现的位置可以划分为两类:特征噪声和标签噪声[2]。噪声的存在对建模产生许多影响,其中特征噪声的分量在统计上彼此更加独立,并且大多数的分类器在面对特征噪声时更加鲁棒[3],而有研究表明,由标签噪声引入的偏差更大,因此通常情况下它比特征噪声具有更大的破坏力[4],会导致模型复杂度增加,分类精度下降,并且更容易出现过拟合现象[5]。然而,无论是特征中出现噪声还是标签中出现噪声,机器学习算法都会将其看做标签噪声[6]。因此,标签噪声的处理成为近些年来亟待解决的机器学习问题之一。
现有的处理标签噪声的方法可以划分为三大类:修改现有模型使其对标签噪声具有鲁棒性,构建基于模型预测的标签噪声过滤器,以及标签噪声校正方法。虽然对算法本身进行鲁棒性改进可以使学习器直接处理带有标签噪声的数据,但这样的方式不适用于所有学习方法,因此,使用基于模型预测的标签噪声过滤器对样本进行预处理的方式更为常见。过滤器是通过模型预测的方式识别样本集中的潜在噪声并将其移除的方式来提高样本质量。
从模型的角度来看,标签噪声过滤方法主要通过基于集成的方法、基于迭代的方法和基于分区的方法来实现。其中多分类器的集成使用最广泛,集成分类器方法分为同质集成和异质集成。MVF(Majority Vote Filter)[7]和CVF(Consensus Voting Filter)[8]均属于异质集成分类器;HARF(High Agreement Random Forest Filter)[9]则由多棵C4.5 决策树集成而得,是同质集成分类器的典型代表。迭代方法是将上一次分类结果作为下一阶段训练的输入,直至达到事先规定的迭代跳出条件为止,代表算法有IPF(Iterative Partition Filter)[10]和 INFFC(Iterative Noise Filter based on Fusion of Classifiers)[11]。分区的思想主要是针对大型数据集或分布式数据集,将训练集划分为多个子模块分别训练,再将训练结果汇总投票[12]。若将过滤过程抽象为一个抽样过程,标签噪声过滤器方法可以分为0-1 抽样方法和概率抽样方法。现有的经典过滤算法CVF、MVF 和HARF 等均属于0-1 抽样,即给定确定阈值,依据阈值和集成算法的投票结果的大小关系过滤潜在的噪声样本。这种传统的0-1 抽样方式无法精确表达不同样本之间的差异性,因此,近年来有学者创造性地提出了概率抽样的思想,即为每一个样本提供一个概率,这个概率指的是该样本为干净样本的可能性大小,将这个概率作为依据,抽样得到干净样本集,代表算法有PSAM(Probabilistic Sampling)[13-14]和局部概率抽样(Local Probability Sampling,LPS)[15],利用多分类器集成投票获取样本置信度,全区间随机生成阈值进行抽样。概率抽样的思想能够有效利用置信度区分同一数据集内部样本与样本之间的差异性,但是仍然无法避免人为设置阈值区间的主观性,且现有的概率抽样方法对不同数据集采用相同的过滤策略,忽视了数据集之间的差异性,影响了过滤器在不同数据集上的噪声识别性能。
本文了提出一种动态概率抽样(Dynamic Probability Sampling,DPS)的标签噪声过滤算法。在本文算法中,通过统计样本的标签置信度在区间内的分布频率,分析置信度分布频率的信息熵走势变化来决定进行概率抽样的样本范围。由于不同数据集之间置信度分布差异巨大,置信度分布频率的信息熵走势差异明显,因此本文算法能够敏锐探测不同数据集之间样本差异性,合理规划阈值区间,以达到较强的标签噪声识别能力。
1 DPS算法
1.1 置信度分布分析
对于一个可能存在标签噪声的样本集DT,为了获取每个样本的可信程度,有效区分样本之间的差异性,应对其每个样本合理估计其标签置信度。随机森林(Random Forest,RF)模型集成了多棵决策树,其随机过程有效地解决了决策树容易产生的过拟合问题,并且置信度的精度可以通过集成决策树的数量灵活调整,模型中集成的决策树越多,最终估计出的标签置信度精度越高。因此本文推荐使用随机森林模型对样本进行置信度估计。计算方法为:

其中:confi表示样本集DT中某一样本的标签置信度,nTree为模型中集成的决策树个数;表示模型对训练集样本的预测标签向量,表示向量的第i个元素。
从预测准确性来看,随机森林由多个彼此独立的决策树集成,因此,它的预测结果比基模型非独立的集成模型更准确;其次,随机森林中的随机过程可以有效解决单一决策树中的过拟合问题;除此之外,在评估置信度的过程中,nTree越大,标签置信度的差异就越细化,因此nTree可以调节清洁度差异的细化程度;最后,对于这样基于最大似然估计的方法,实验次数越多,置信度估计就越准确。
标签置信度虽然能够合理展现出样本标签的可信赖程度,但是由于数据集之间的差异性,使得数据集的标签置信度分布也具有很大的差异。图1 和图2 分别展示了在理想情况下置信度分布和实际情况下各个数据集的置信度实际分布(各个数据集的详细描述见3.1 节)。在理想条件下,使用集成分类模型计算样本的标签置信度时,每一个基分类器都能够准确预测样本的真实标签,因此,干净样本的标签置信度均为1,噪声样本的标签置信度均为0。然而由于在计算标签置信度时分类器本身存在一定的误差,且不同的样本分布情况也影响着分类器的预测结果,因此,实际各个数据集的标签置信度往往与理想情况相差甚远。
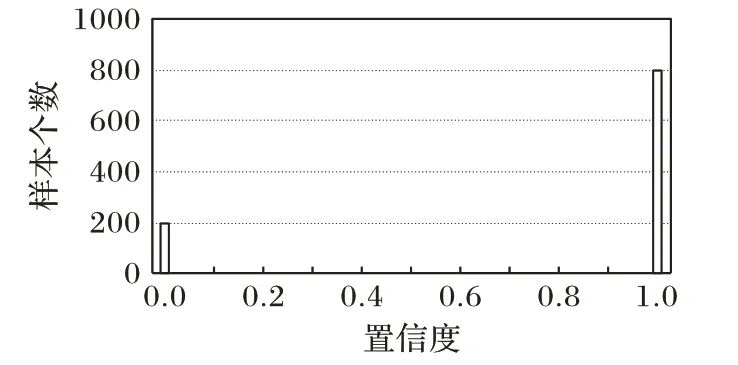
图1 理想情况下的置信度分布Fig.1 Confidence distribution in ideal condition
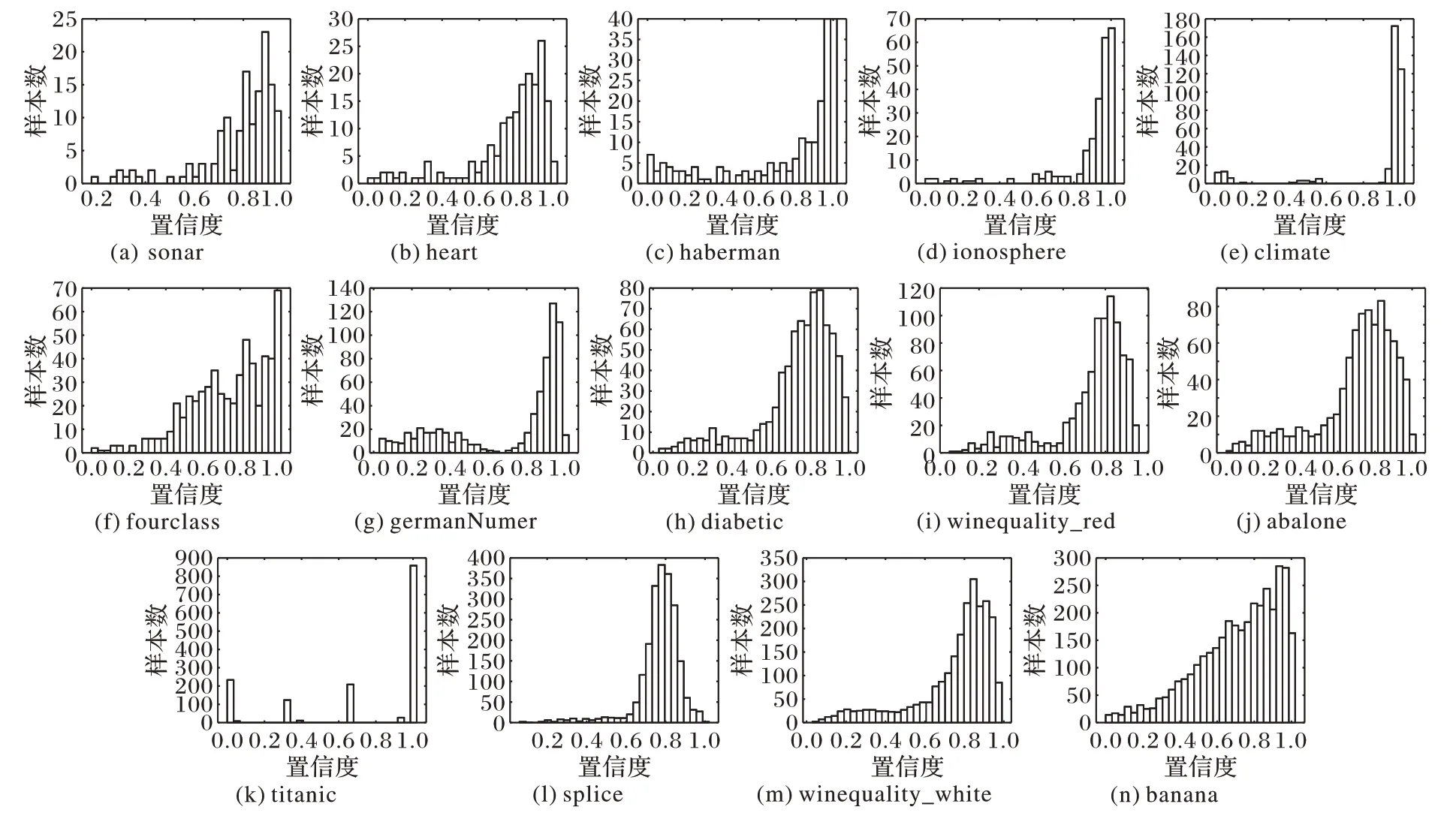
图2 不同数据集置信度分布Fig.2 Confidence distribution of different datasets
显然,在置信度分布差异巨大的情况下,针对各种置信度分布的数据集采用一致的标签噪声过滤策略是不可行的,因此,本文提出的DPS 算法使用信息熵对样本的标签置信度分布情况进行分析。
信息熵被定义为离散随机事件的出现频率,是数学上一个用于衡量信源的不确定度的抽象概念,信息熵越小,表示信源不确定性越低。在本文的问题中,将样本的标签置信度的值看作随机变量X,X的取值范围为[0,1]。将[0,1]平均划分为b份,有b+1,那么P(x∈(xi,1])为b个随机事件发生的概率,统计b个随机事件出现的频率并计算信息熵,公式为:

随机变量X的信息熵EQ(X)是一个单调递减函数,随着i的增加,区间(xi,1]逐渐减小,此时EQ(X)减小,意味着X事件的确定性逐渐增大,因此,寻找EQ(X)一阶差分最小值点e,在e点处EQ(X)下降速度最快,此时将e更新为阈值选择区间的右端点。EQ(X)在e点处下降速度最快意味着不确定性流失最快。
然而,此时的e点并不是最终要寻找的最佳临界点,最佳临界点应该选取信息熵开始大幅下降的瞬间,也就是信息熵EQ(X)的拐点处,因此,最佳临界点应该满足两个条件:1)在信息熵EQ(X)产生大幅下降的点(即一阶差分最小值点)之前;2)处在EQ(X)的某一拐点处。此时从e点出发向前搜索,继续寻找EQ(X)二阶差分最小值,就能够找到最佳临界点。事先寻找EQ(X)下降最快的点而不直接寻找拐点的原因是,无法确定拐点只有一个,部分数据集的信息熵EQ(X)可能存在两个或多个拐点,先利用一阶差分更新点e能够缩小拐点寻找范围,避免最佳临界点的寻找陷入局部最优。
寻找到最佳临界点e后,令e的横坐标xe作为阈值区间的右端点,xe-w为左端点,w为进行概率抽样的范围,此时就得到了最优阈值区间[xe,xe-w],利用局部概率抽样的方式,在区间内随机生成阈值r,利用阈值r和每个样本的标签置信度的大小关系对样本进行识别。由于概率抽样方法基于最大似然估计,因此需要进行多次的独立重复实验,抽样过程连续进行SamplingNum次,汇总最终各个样本的识别结果进行过滤。
1.2 DPS算法
根据1.1 节中的描述寻找最佳临界点后,在阈值区间中利用概率抽样的方式进行标签噪声的过滤,得到DPS 算法。DPS算法的主要步骤如下:
输入 初始样本集DT;
参数 随机森林集成的决策树个数nTree,置信度划分区间个数b;
输出 预测标签集L。
步骤1 利用随机森林模型构建nTree棵决策树投票获得训练集DT中每个样本的标签置信度confi。
步骤2 将置信度区间[0,1]平均划分成b个子区间[xi,xi+1],统计置信度处于各个子区间的概率,并通过式(2)计算置信度处于不同区间的信息熵EQ(xi)。
步骤3 计算EQ在每个xi处的一阶差分FD(xi),将最佳临界点e更新为FD的最小值点。
步骤4 计算EQ在每个xi处的二阶差分SD(xi),从e出发向前搜索,寻找到SD的极小值点xe,此时最佳阈值区间为[xe-0.2,xe]。
步骤5 在[xe-0.2,xe]区间内随机生成阈值r,保留conf值高于r的样本构成干净样本集CT,剩余样本被标记为噪声。基于CT构建分类器hj。
步骤6 重复步骤1~5 共SamplingNum次,最终构建SamplingNum个分类器hj,对训练集样本进行过滤。
在DPS 算法中,构建随机森林模型的时间复杂度为O(nTree⋅N⋅C⋅log(N)),置信度计算的时间复杂度为O(nTree⋅N),在对置信度分布分析的过程中,时间复杂度为O(b),最终过滤过程的时间复杂度为O(N),上述的各个过程均为串行,且重复进行了SamplingNum次,因此,DPS 算法总体时间复杂度为O(SamplingNum⋅nTree⋅N⋅C⋅log(N))。
2 实验结果与分析
2.1 实验数据与实验环境
本文在14 个经典UCI 数据集上验证本文DPS 算法的有效性,数据集描述见表1。为避免不平衡数据对分类性能的影响,对winequality_red 和winequality_white 抽取了其中的第5 和第6 类,对abalone 抽取了其中的第9 类和第10 类。数据的平滑、拟合以及实验部分均在Matlab环境下实现。

表1 实验数据集描述Tab.1 Experimental dataset description
2.2 数据设计
实验前先将数据集划分为两个部分,取其中2/3作为训练集,剩余1/3作为测试集。将训练集按照实验要求随机加入噪声,即随机改变一定比例样本的原始标签。在对比实验中,选取四种标签噪声过滤算法与DPS 算法进行比较,分别是随机森林(RF)、MVF、HARF和LPS,其中:RF、HARF和LPS都是基于随机森林提出的方法,在构建森林时构建决策树的数量均为500;MVF 是异质集成分类器,由3NN、朴素贝叶斯、随机森林三种模型集成而得;HARF的阈值设置为0.7;LPS和DPS的抽样次数设置为11。在标签噪声过滤后将保留下的样本利用随机森林训练为一个分类器对测试集进行分类,以该分类结果判断该标签噪声过滤算法的分类泛化性能。为避免实验随机性的影响,实验结果均为重复10次求取的平均值。
本文中对比实验指标使用了识别准确率Acc(Accuracy)、召回率Re(Recall)、查准率Pre(Precision)、F1和Classif(分类准确率),具体计算方式如下:

其中:TP表示实际标签和预测标签均为正类的样本数;FP表示实际标签为负类,预测标签为正类的样本数;TN表示实际标签和与预测标签均为负类的样本数;FN表示实际标签为正类,预测标签为负类的样本数。
2.3 实验结果与分析
2.3.1 信息熵走势分析
本组实验主要验证信息熵走势对探索最佳临界点的有效性。图3展示了在14个数据集下,由式(2)计算出的信息熵的一阶差分图随置信度的变化情况,为避免局部内的微小波动对实验造成的影响,将原信息熵一阶差分函数利用三次样条插值进行平滑处理,图3为处理后的一阶差分曲线。从图3中可以看出,不同数据集的信息熵差分的走势差异很大,但它们也存在一些共同点:在所有数据集的信息熵一阶差分图像中,函数值在某一点或某个小区间内会出现至少一次大幅度下降。这是因为横坐标每向右移动一个点,就会损失一个置信度子区间中所包含的信息量,当移动到某点,函数值出现大幅下降时,说明当损失该置信度子区间的信息量时,获取到的信息的不确定性骤降,因此,最佳临界点应当出现在该点附近。然而,对于部分数据集,信息熵差分极小值点不止一个,针对这样的情况,则选取最小值点,即信息熵下降最快的点作为探索最佳临界点的起点。

图3 14个数据集的一阶差分图Fig.3 First-order difference graphs of 14 datasets
若直接将信息熵一阶差分最小值点作为最佳临界点,带来的问题是损失大量有效信息。因为从图3 中可以看出,对于部分数据集(如sonar、heart、diabetic、winequality_white 等),一阶差分值都不是在某一点突然下降的,而是在某个区间内连续下降,且下降幅度都比较明显,当一阶差分下降到最小值时,信息已经产生较大损失。因此,为解决这样的问题,应当利用二阶差分寻找一阶差分图像的拐点作为最佳临界点。
2.3.2 噪声识别性能
本组实验主要对比了DPS与RF、MVF、HARF 及LPS的噪声识别能力,噪声比例ratio从5%到30%,每次以5%的幅度递增。图4(a)展示了五个算法在14 个数据集下的噪声识别准确率Acc的汇总结果,结果由不同噪声比例下14 个数据集实验结果的均值得来。五个算法中,RF、MVF、HARF为0-1抽样算法,LPS、DPS是概率抽样算法。从噪声识别率来看,概率抽样算法的噪声识别能力明显高于0-1 抽样算法。DPS 算法因采用了动态过滤策略,其噪声识别能力相比LPS 也有一定的提高,尤其在噪声比例较低的情况下,噪声识别能力的优势更加明显。
图4(b)和(c)分别展示了五个算法在14个训练集下噪声识别的召回率和精确率,从图中可以看出,DPS的召回率远高于HARF 和LPS,且这三个算法的召回率几乎不随噪声比例ratio的增长而变化,RF 和MVF 召回率较低且不够稳定,随ratio的变化比较明显。从精确率来看,五个算法在噪声比例为5%时几乎没有表现出差异,随着ratio的增加,各个算法的精确率逐渐显现出差异,其中,HARF 和DPS 下降速度较快,而MVF 的Pre指标在此时显示出一定的稳定性,下降速度相比其他算法更加缓慢。从图4(b)和(c)可以看出:DPS 和HARF 更倾向于保留干净样本,会不可避免地保留部分噪声,因此精确率较低;而MVF 更倾向于过滤噪声样本,在过滤的过程中也会过滤掉部分干净样本,严重时还会造成过度过滤现象。
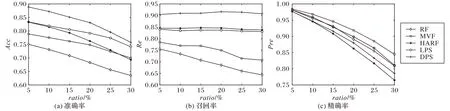
图4 五种算法的Acc、Re和Pre指标对比Fig.4 Comparison of Acc Re and Pre of 5 algorithms
为综合Re和Pre的实验结果,图5 展示了五个算法在14个数据集上的F1值,从图中可以看出,在绝大部分情况下,HARF、LPS 和DPS 的F1值在不同的数据集上表现各有优势,且明显优于其他两种算法。
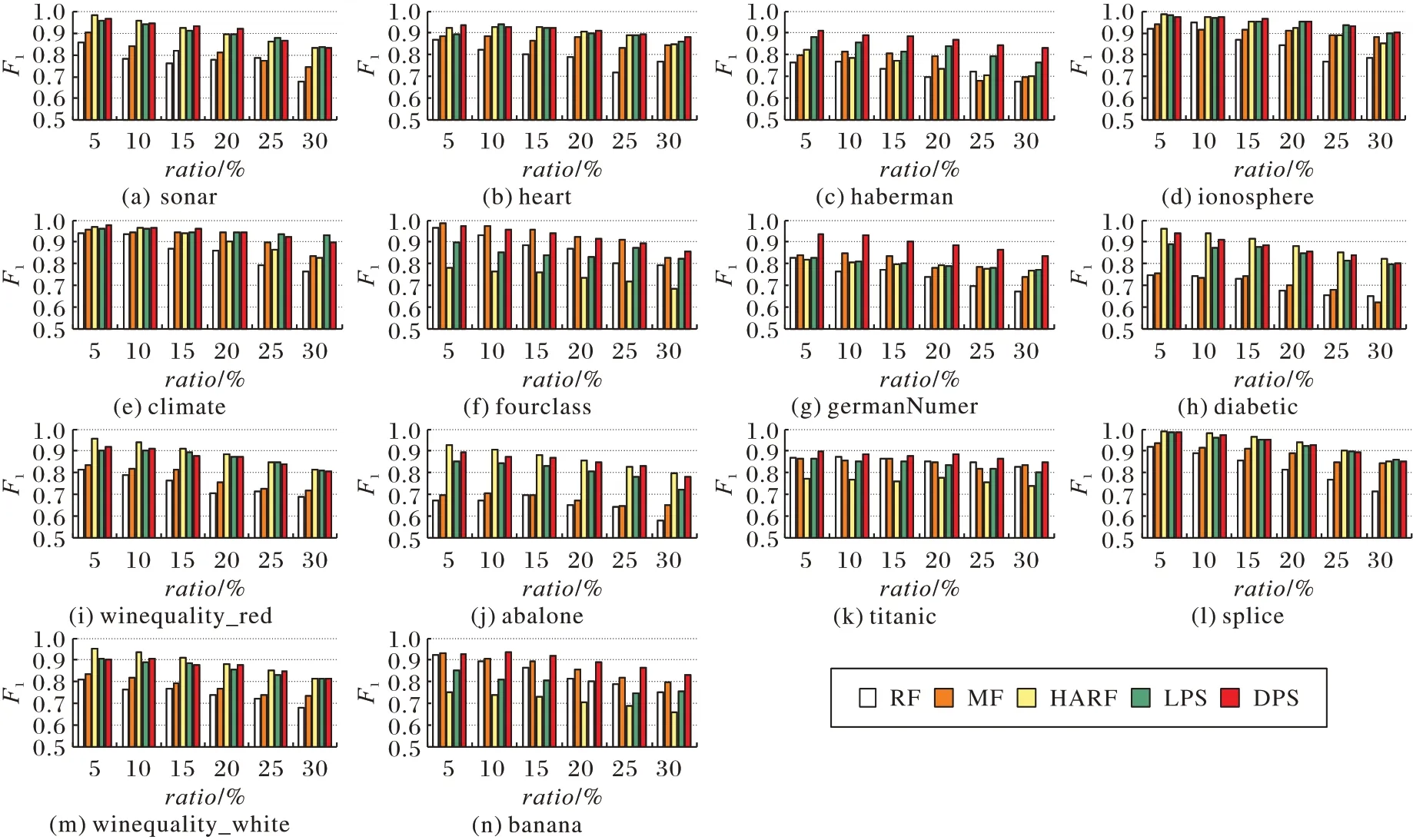
图5 五种算法的F1指标对比Fig.5 Comparison of F1 of 5 algorithms
为了更好地比较五种方法的F1指标,图6 对14 个数据集的F1指标求取平均值,总体来看,在F1指标下,概率抽样方法仍然具有较大的优势,其中DPS 的F1指标在各个噪声比例下均能够保持较高水平。

图6 五种算法的F1均值对比Fig.6 Comparison of F1 mean value of 5 algorithms
2.3.3 分类性能比较
图7 对比了五种算法在14 个数据集下的分类泛化能力,Classif越高,表示数据集在经由该算法过滤后,训练出的分类器分类能力越好。从图7 中可以看出,DPS 的分类准确率在大多数情况下比其他算法表现更好,在低噪声的情况下,DPS更具优势。除了DPS 外,LPS 在少部分数据集下的分类准确率也表现出了一定的优势,而HARF 的分类能力相比其他算法表现最差。

图7 五种算法的Classif指标对比Fig.7 Comparison of Classif of 5 algorithms
14 个数据集Classif的平均值如图8 所示,可以看出,随着噪声比例的增大,五个算法的Classif基本呈下降趋势,其中DPS 下降速度最慢,且Classif指标最高,说明其概率抽样方法受噪声影响更小,鲁棒性更高。

图8 五种算法的Classif均值对比Fig.8 Comparison of Classif mean value of 5 algorithms
3 结语
本文主要针对置信度分布差异较大的各类数据集无法适应统一的标签噪声过滤策略的问题,提出了一种基于动态概率抽样的标签噪声过滤方法,该方法通过统计不同数据集的样本置信度出现的频率来分析置信度的分布特点,利用此概率的信息熵寻找过滤的最佳临界点,再结合概率抽样的思想,在使得过滤器达到高识别率、高分类准确率的目标的同时,也增强了过滤器在不同数据集上的普适性。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
上海师范大学学报·自然科学版(2022年3期)2022-07-11
军民两用技术与产品(2022年1期)2022-06-01
小型微型计算机系统(2022年4期)2022-05-09
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
计算机应用(2016年10期)2017-05-12
中国水运(2016年11期)2017-01-04
中国科技纵横(2016年20期)2016-12-28
