
面向异构单类协同过滤的阶段式变分自编码器
2022-01-05 02:31陈宪聪潘微科
计算机应用 2021年12期
陈宪聪,潘微科*,明 仲
(1.大数据系统计算技术国家工程实验室(深圳大学),广东深圳 518060;2.人工智能与数字经济广东省实验室(深圳)(深圳大学),广东深圳 518060;3.深圳大学计算机与软件学院,广东深圳 518060)
(∗通信作者电子邮箱panweike@szu.edu.cn)
0 引言
随着信息爆炸时代的到来,人们难以从海量的信息流中挑选出符合自己兴趣的物品。推荐系统的出现在一定程度上缓解了该问题,而且在现代社会中扮演着越来越重要的角色。它通过不同的推荐算法学习用户的偏好,选出符合他们兴趣爱好的物品,进而为不同的用户提供个性化推荐。个性化推荐在现实生活中的应用很多,如商品推荐[1]、电影音乐推荐[2]和新闻推荐[3]等,因此,对推荐算法的研究与探索越来越受到学者的关注。
用户的反馈能在一定程度上反映用户的偏好,充分利用用户的反馈并对之进行建模,可以为用户提供物品推荐。通常而言,用户反馈可分为显式反馈和隐式反馈。显式反馈能较为准确地反映用户的偏好(如评分),根据分数的高低可以判断用户对物品的喜爱程度,但是显式反馈在很多场景下难以获得;而隐式反馈在现实应用中较为常见,如用户是否购买了某物品。早期很多工作基于用户的单类反馈展开,并取得了较好的推荐效果,它们通常被称为单类协同过滤(One-Class Collaborative Filtering,OCCF)[4];然而在这些工作中,用户的单类反馈通常是比较稀疏的,这导致模型的表现受到一定的限制。
考虑到辅助反馈信息的价值,异构单类协同过滤(Heterogeneous One-Class Collaborative Filtering,HOCCF)[5]在近些年被提出,并受到了较为广泛的关注。在HOCCF 问题中,除了用户的目标反馈,还存在着用户的辅助反馈。例如,在线上购物中,用户的购买行为可以看作目标反馈,用户的浏览、收藏和加入购物车等行为可以看作辅助反馈。用户的辅助反馈往往比较稠密,可用于帮助刻画用户的偏好。如何对用户的异构反馈进行建模从而准确刻画用户的真实偏好成为了一个新的挑战。具体而言,引入用户的辅助反馈同时也会引入一定的噪声,需要设计合适的模型筛选有价值的信息;同时,也需要探索两种不同类型反馈的关系,并合理融入模型中学习用户的偏好。
目前有很多工作用于解决HOCCF 问题,它们可大致分为基于分解的方法、基于迁移学习的方法以及基于深度学习的方法。其中,基于分解的方法通过采用不同策略对用户反馈进行建模[5-7],如权重策略;基于迁移学习的方法则是从迁移学习的角度出发,通过采取不同的迁移方式进行建模[8-9]。以上两类方法大都依赖于传统的推荐技术,该技术通过简单的用户物品向量內积表示用户对物品的偏好,这种线性模型在某些场景下推荐效果可能会受到一定的限制[10]。基于深度学习的方法则借助深度学习技术对用户反馈进行建模,复杂的网络和非线性函数的使用使得这些模型的性能得到一定程度的提升,但已有的模型需要依赖一些辅助信息[11-12],如时序信息和文本信息等。
可以看到,将迁移学习引入到异构单类协同过滤(而非传统的协同过滤)的工作并不多,而且它们都是采用传统的矩阵分解[13],推荐效果受到一定的限制。同时,变分自编码器(Variational AutoEncoder,VAE)[14]在单类协同过滤问题上的推荐效果很好,但目前还没有相关工作将迁移学习和VAE 结合用于解决异构单类协同过滤问题。因此,本文从迁移学习的角度出发,提出了一个新的迁移学习解决方案——阶段式变分自编码器(Staged Variational AutoEncoder,SVAE)模型,该模型采用迁移学习中基于参数的迁移方式[15],与变分自编码器结合对用户的异构单类反馈进行建模。具体而言,SVAE分为浏览模型建立和购买模型建立两个阶段。在浏览模型中,输入用户的辅助反馈(即浏览反馈),以多项式变分自编码器(Multinomial Variational AutoEncoder,Multi-VAE)[14]为基础模型学习并生成隐特征向量。在购买模型中,迁移浏览模型中生成的隐特征向量到该模型,用于辅助对用户的目标反馈(即购买反馈)的建模。实验结果表明,SVAE在三个真实数据集上的推荐效果在多数情况下优于其他流行的推荐算法(如基于角色的迁移排序(Role-based Transfer to Rank,RoToR)[9]模型),验证了模型的有效性。
本文的主要工作包括:1)针对异构单类协同过滤问题,从迁移学习的角度提出了一个新的SVAE 模型,在不同阶段利用多项式变分自编码器对用户的异构反馈进行建模,通过不同阶段的训练和知识迁移,有效捕捉了用户对物品的真实偏好;2)在三个真实的数据集上进行了实验,实验结果验证了本文提出的方法的有效性。
1 相关工作
近年来针对隐式反馈(或单类反馈)的推荐算法受到很多学者的关注,当存在一种或多种用户的隐式反馈时,如何对其建模从而提升推荐效果是一个重要的研究问题,本章对流行的相关方法进行简述,包括基于分解的模型、基于迁移学习的模型以及基于自编码器的模型。
1.1 基于分解的模型
矩阵分解(Matrix Factorization,MF)[13]是最经典的分解模型之一,可用于解决推荐中的单类协同过滤(OCCF)问题,它把用户对物品的交互矩阵分解成用户特征矩阵和物品特征矩阵的乘积,该乘积可表示用户对物品的偏好程度。简单有效的矩阵分解在一定程度上可以缓解数据的稀疏问题,因此很多模型在此基础上进行扩展和改进。如贝叶斯个性化排序(Bayesian Personalized Ranking,BPR)[16]算法是其中之一,它认为用户对已交互(已购买)的物品的偏好值大于未交互(未购买)的物品的偏好值,其中偏好值是基于矩阵分解计算得出的。
在异构单类协同过滤问题中,存在两种或以上的用户单类反馈,很多模型以上述面向OCCF 问题的算法为基础进行改进和扩展,并取得了一定的效果。自适应贝叶斯个性化排序(Adaptive Bayesian Personalized Ranking,ABPR)[5]将浏览数据融入BPR 中,并赋予相应的权重,该权重在训练过程中根据设计的公式自适应地进行调节。浏览数据权重的引入能在一定程度上缓解偏好不确定的问题,但是计算过程比较耗时。基于异构隐式反馈的贝叶斯个性化排序(Bayesian Personalized Ranking for Heterogeneous implicit feedback,BPRH)[6]在BPR 损失函数的基础上,增加了用户辅助反馈的损失项,并在损失函数中添加了权重系数,用于衡量目标反馈和辅助反馈的关联性。然而,由于该权重系数需要通过特定复杂的计算公式得到,因此BPRH 的通用性受到一定的限制。面向浏览数据增强的最小二乘(View-enhanced element-wise Alternating Least Squares,VALS)[7]模型在损失函数中分别为购买物品、浏览物品以及未交互物品上定义了不同的损失项,模型的推荐效果有一定程度的提升,但是不足之处在于模型的超参数比较多,调节范围较大,过程比较繁琐。
1.2 基于迁移学习的模型
在异构单类协同过滤问题中,迁移学习通过对辅助反馈进行建模,将学习到的知识迁移至目标任务中,从而更好地对目标反馈建模。联合相似度迁移学习(Transfer via Joint Similarity Learning,TJSL)[8]模型的预测公式包含了用户对已购买物品的偏好值,同时也引入了用户对浏览物品的偏好值,用于辅助预测用户对目标物品的偏好。基于boosting 方法的思路,TJSL 通过多次迭代的方式选取具有代表性的浏览数据,这在一定程度上消除了数据中的噪声;但是该方法的预测公式较长,时间复杂度较高。基于角色的贝叶斯个性化排序(Role-based Bayesian Personalized Ranking,RBPR)[17]模型是一个两阶段的模型。在第一阶段,从用户扮演浏览者的角色出发,对浏览数据建模,输出候选物品的列表;在第二阶段,从用户扮演购买者的角色出发,利用购买数据训练模型,然后对候选物品列表重排,得到最终的列表。在这里,候选物品列表可以看作迁移的知识,用于辅助第二阶段的建模。RBPR 的缺点是需要维护两个阶段的模型以及中间输出的候选物品列表。基于角色的迁移排序模型(RoToR)[9]与RBPR 类似,但是推荐效果有明显的提升。RoToR 包含两种变体:集成式和顺序式。集成式在预测公式中融入了基于分解的模型和基于邻域的模型,分别对购买数据和浏览数据进行建模。顺序式则是两阶段的模型:在第一阶段采用基于邻域的模型产生候选物品列表;在第二阶段采用基于分解的模型对候选物品进行重排,与RBPR 的建模方式相似。RoToR 的缺点也是时间复杂度较高,同时需要维护两个阶段的模型和候选列表。
1.3 基于自编码器的模型
近年来,深度学习技术在计算机视觉、自然语言处理以及语音识别等领域取得了巨大成功。在推荐领域,深度学习技术也越来越受到关注,被广泛用于不同的推荐任务和场景中[18]。本文主要关注深度学习技术中与SVAE 相关的自编码器模型。基于自编码器的协同过滤推荐模型(Autoencoderbased collaborative filtering Recommendation model,AutoRec)[19]是早期用于评分预测的模型,该模型将用户对物品的评分样本映射到隐藏层,再通过解码器还原评分样本,训练完成后输出用户对物品的预测评分。协同降噪自编码器(Collaborative Denoising AutoEncoder,CDAE)[20]对AutoRec 进行了改进,通过在输入样本进行降噪操作,并且引入了用户节点,增强了模型的鲁棒性,在一定程度提升了推荐效果。多项式变分自编码器(Multi-VAE)[14]是一个更鲁棒的生成模型,它通过拟合两个概率分布去生成隐向量并还原输入样本,同时引入了多项式似然函数,使得该模型的推荐效果得到进一步提升。需要说明的是以上模型都只是对用户的单种反馈进行建模。
针对用户多种信息的建模,也有一些代表性的工作。文献[21]把自编码器应用在协同过滤工作中,并指出了传统VAE 模型的不足;文献[22-23]提出的模型在对多种输入建模时只生成单个隐向量,可能存在模型表达能力不足的问题。针对该问题,学者提出了几种基于VAE 对用户辅助反馈建模的模型,如条件变分自编码器(Conditional Variational Autoencoder-based Collaborative Filtering,CVAE-CF)[21]和联合多模态自编码器(Joint Multimodal Variational Autoencoderbased Collaborative Filtering,JVAE-CF)[21]。具体而言,它们引入了额外的隐向量用于挖掘更丰富的表征信息,前者学习的是一个条件分布,后者学习的是一个联合分布。两个模型以不同的方式融合了辅助信息(如用户的社交信息),最后对用户的目标反馈进行更准确的预测。变分协同模型(Variational Collaborative Model,VCM)[24]分别为目标反馈和辅助信息建立了两路VAE,通过交互两路VAE 的分布来达到协同的目的,具体通过Kullback-Liebler(KL)散度来近似它们的分布。基于风格条件的推荐(Style Conditioned Recommendations,SCR)[25]提出了风格注入的概念,通过文本编码器得到用户风格的表征向量,然后把该向量作为条件输入到条件变分自编码器的结构中,最后为用户进行推荐。模型的输入除了用户的点击记录,还需要额外的物品属性信息。上述模型中的辅助信息都是用户的社交信息、文本信息或其他信息,没有针对异构单类反馈进行建模。本文主要关注推荐系统中对异构单类反馈建模的问题。
2 预备知识
2.1 问题定义
在异构单类协同过滤问题中,假设有来自n个用户和m个物品的两种不同的单类反馈:例如购买反馈,表示为RT={(u,i)};以及浏览反馈,表示为RA={(u,i)}。具体来说,对于每一个用户,都有其购买物品的列表和浏览物品的列表。目标是根据不同用户的购买记录和浏览记录,为每个用户进行个性化建模,最后为用户推荐符合用户兴趣而且之前没有购买过的物品列表。表1 是本文使用的一些符号和相应的解释。

表1 符号说明Tab.1 Symbol description
2.2 变分自编码器
与传统自编码器不同的是,变分自编码器是一种生成模型,它不再将输入样本映射到固定的隐向量,而是假设通过输入样本生成的隐向量的分布服从正态分布,并通过该分布生成隐向量,再基于生成的隐向量重构输入样本。
VAE问题求解的关键在于确定输入样本生成隐向量的分布,即后验分布p(z|x),由贝叶斯定理可知该后验概率难以求解。为了解决该问题,VAE 采用变分推断[26]近似后验分布p(z|x),具体做法是引入一个分布q(z|x),通过KL 散度让两个分布接近,具体推导过程[27]如下:
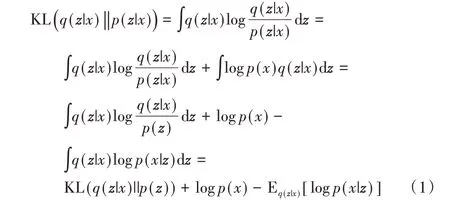
整理上面的公式,可以得到:
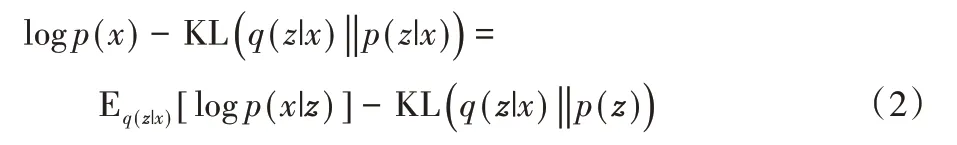
VAE 的目标是最大化似然概率logp(x),由于KL(q(z|x)‖p(z|x))≥0,VAE 的优化目标等价于最大化等式右边的两项,也就是VAE 的证据下界(Evidence Lower Bound,ELBO)[14]。ELBO中的第一项可以看成重构样本的误差,第二项可以看成正则化项,约束后验分布q(z|x)服从先验p(z)。因此,VAE最终的目标函数可表示为:
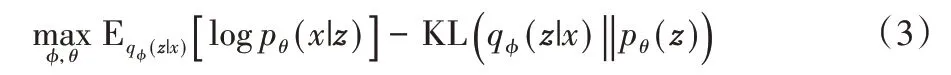
VAE 利用神经网络拟合两个概率分布模型[28]:一个是编码器对输入样本进行变分推断,生成隐向量的概率分布模型,即qφ(z|x),其中φ是编码器神经网络的参数;另一个是根据生成的隐向量,通过解码器还原接近输入样本的概率分布模型,即pθ(x|z),其中θ是解码器神经网络的参数。变分自编码器模型如图1 所示。由于编码器的输入隐向量z是根据概率分布qφ(z|x)采样得到,但是采样结果取决于编码器的均值μu⋅(x)和标准差σu⋅(x),是一个不可导的操作,因此VAE采用了重参数技巧[22],从标准正态分布采样一个高斯噪声ε∈N(0,Id),令zu⋅=μu⋅(x) +ε⊙σu⋅(x),从而使得模型的训练过程变得可导。

图1 变分自编码器模型结构Fig.1 Model structure of variational autoencoder
2.3 多项式变分自编码器
Liang 等[14]将VAE 扩展到协同过滤问题中,提出了多项式自编码器(Multi-VAE)模型。与近年流行的模型相比,如神经协同过滤(Neural Collaborative Filtering,NCF)[10]和协同记忆网络(Collaborative Memory Network,CMN)[29]等,Multi-VAE的表现较好,推荐精度的提升较多。该方法的主要优点是引入了多项式似然函数的生成模型,同时调整了标准VAE 模型中的目标函数。
具体来说,Multi-VAE 的输入是用户u对所有物品的观测向量,用ru⋅表示,经过编码器得到隐向量zu⋅=fφ(ru⋅)。然后隐向量zu⋅经过解码器产生一个物品集I上的概率分布π(zu⋅)[14]:
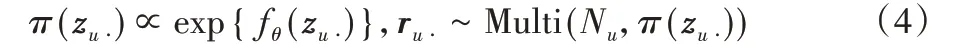
其中:Nu表示用户u交互物品的总次数;编码器的输出fθ(zu⋅)通过softmax 函数产生概率分布π(zu⋅),假设用户u对所有物品的观测向量服从该分布,可以得到用户u的多项式似然[14]
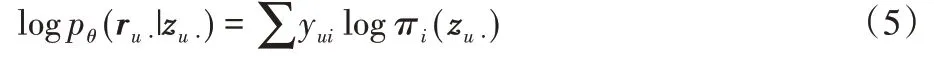
与高斯似然和对数几率似然相比,Multi-VAE的作者认为多项式似然更适合面向Top-K 排序的推荐模型[14],因为多项式似然会倾向于赋予ru⋅中的非零项更高的概率,能在一定程度上提升模型的准确率。
对于模型的目标函数,Multi-VAE 对标准VAE 模型的目标函数进行了调整,通过引入参数β来调整重构样本误差项和正则化项的比例,具体的目标函数[14]如下:

新的目标函数在拟合数据和近似后验分布之间做了权衡,把β当成超参数选择,能够有效提升推荐的效果。
3 阶段式变分自编码器
3.1 模型概述
Multi-VAE模型仅对用户的一种单类反馈进行建模,而在现实应用中,用户的反馈往往包括多种类型。本文提出的SVAE 模型对用户的两种单类反馈(购买反馈和浏览反馈)进行建模。具体来说,SVAE 是一个双路变分自编码器模型:在浏览阶段,对浏览反馈进行建模,将每一个用户对所有物品的浏览向量rAu⋅输入到Multi-VAE,以重构浏览反馈样本为目标进行优化;在购买阶段,对购买反馈进行建模,把浏览模型学到的隐向量zAu⋅作为用户的浏览表征向量迁移至购买模型,并与购买反馈样本一起输入到另一路Multi-VAE,最后以重构购买反馈样本为目标进行优化。SVAE模型如图2所示。
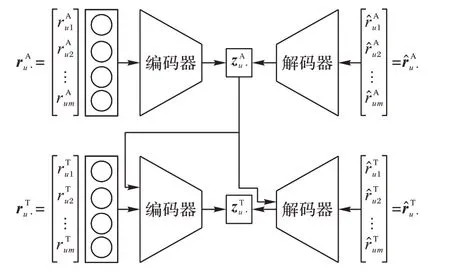
图2 SVAE模型Fig.2 Model of SVAE
SVAE 模型以Multi-VAE 为基础进行了改进,主要包括:1)Multi-VAE 仅对用户的单一类型反馈进行建模,而SVAE 采用阶段式的建模方式对用户的两种不同反馈进行建模,更接近实际的应用场景;2)Multi-VAE的输入仅是用户对物品的交互向量,SVAE 在购买阶段融合了浏览阶段学到的隐向量,并与购买物品向量一起输入到模型中。同时,在解码阶段,也融合了浏览阶段的隐向量。这种方式有效地融合了浏览反馈的信息,有助于提升推荐效果。
3.2 浏览模型
用户浏览反馈的特点是数据量大、稠密,但由于用户浏览行为的随机性比较大,也伴随着很多噪声。浏览阶段的目标是根据大量的浏览反馈记录学习用户的浏览表征,这能在一定程度上表示用户的偏好。具体而言,把用户的浏览反馈输入到Multi-VAE 模型中,模型生成的隐向量可作为用户偏好的初级表征(用户的浏览表征),然后将其作为辅助信息(知识)帮助购买模型更好地学习用户的偏好。
选择Multi-VAE 的原因是其具有良好的表现和较强的特征抽象能力,所以以Multi-VAE 为基础模型进行建模。在浏览模型中,输入的是用户对所有物品的浏览向量,模型以重构用户的浏览样本为目标进行优化,具体的目标函数如下:

其中:φA,θA是模型求解的参数,β是需要通过验证集选择的超参数。值得注意的是,浏览模型的输入有两种形式,一是把用户的浏览反馈数据和购买反馈数据混合后作为浏览模型的输入,它的假设是用户购买物品之前都会浏览这些物品,因此把用户的购买集合也看成是浏览物品集合的一部分;二是直接把用户的浏览反馈数据作为浏览模型的输入。在实验部分会对两种不同输入得到的效果进行比较。浏览模型训练完毕后,提取浏览模型编码器生成的隐向量作为用户的浏览表征向量。
3.3 购买模型
受到条件变分自编码器的启发,在购买阶段采用类似的方式融合从浏览模型学到的知识。具体而言,以Multi-VAE为基础模型,编码器的输入不仅有原始输入样本,还有浏览模型学到的浏览表征向量作为条件信息用于帮助购买模型的学习,同时在解码器的输入除了生成的隐向量,也把浏览模型的条件信息一起输入。具体的目标函数如下:
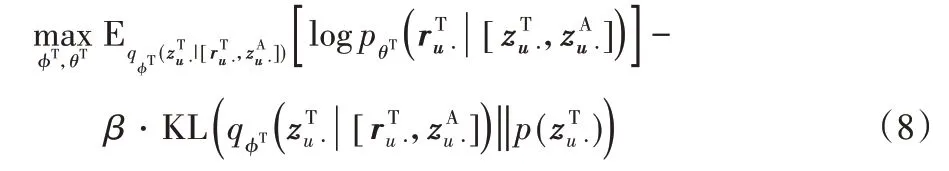
其中φT、θT是模型求解的参数,β是需要手动选择的超参数,表示向量之间的拼接。与Multi-VAE 不同的是,购买模型的输入是用户对所有物品的购买向量以及条件信息,经过编码器生成隐向量后,与条件信息一起输入解码器,并以重构购买反馈样本为目标进行优化。通过这种方式,有效地将浏览模型学习的用户浏览表征向量迁移至购买模型,提升最终的推荐效果。
3.4 算法流程
SVAE模型的算法的流程主要分为两部分:1)浏览模型的建立。输入用户浏览样本到Multi-VAE 模型,训练生成隐向量作为用户的浏览表征向量。2)购买模型的建立。迁移浏览模型的信息(用户浏览表征向量),与用户的购买样本一起作为Multi-VAE 的输入,经过编码器生成隐向量后,再与浏览模型中的信息一起输入解码器进行样本重构。在整个过程中,可以采用交替训练或顺序训练的方式。对于交替训练,首先训练所有用户的浏览样本,然后训练所有用户的购买样本;不断重复迭代该过程直至模型收敛,收敛的条件是实验结果连续多次(如50 次)迭代也没有效果提升,交替训练的SVAE 模型的具体算法流程如算法1 所示。顺序训练的方式与交替训练的方式的区别是:前者充分训练浏览模型,直到浏览模型收敛后再训练购买模型;后者是在每一次迭代中,先后训练浏览模型和购买模型。
算法1 SVAE模型的算法。
输入 所有用户的购买物品记录集合RT={(u,i)},浏览物品记录集合RA={(u,i)}以及模型的所有超参数;
输出 浏览模型参数φA和θA,购买模型参数φT和θT。

对于每一次迭代(epoch),训练会遍历所有用户,而对于每一个用户,模型的输入是该用户交互过的所有物品和全部或部分未交互过的物品,因此模型的时间复杂度是O(T1nm1),其中:T1是迭代次数,n是用户数,m1是平均每个用户实际参与训练的物品数,在实验中使用了全部物品(即m=m1)。相关工作中使用传统方法的模型RoToR[9]的复杂度是O(T2|R|m2),其中:T2是迭代次数,|R|是交互记录数,m2是平均每个用户实际参与训练的物品数。此外,SVAE模型的主要优点如下:1)需要调节的参数少。除了学习率和正则化参数,SVAE模型只有隐向量维度这一参数需要调节,而部分模型如VALS需要调节的参数较多,且调节的范围较大。2)不需要额外维护候选列表。RBPR 和RoToR 在训练过程中需要生成候选列表,需要进行额外的维护。3)推荐效果更好。与相关工作的模型相比,SVAE模型的推荐效果在多数情况下得到了显著的提升,详细的实验结果在第4章中展开描述。
4 实验结果与分析
4.1 实验数据集和评价指标
在实验中,采用三个常用的真实数据集MovieLens 10M(记为ML10M)、Netflix 以及RecSys Challenge 2015(记为Rec15)来评估模型的效果。具体而言,ML10M 数据集包含71 567 个用户对10 681 部电影的约107条评分记录;Netflix 数据集包含了480 189 个用户对17 770 部电影的约109条评分记录。对这两个数据集的处理步骤与RoToR[9]一致,具体如下:1)首先随机选择数据集60%的评分记录,筛选出用户对电影评分为5 分的记录,保留用户ID 和物品ID,记为(u,i),作为购买集合,评分小于5 分的记录丢弃;2)把购买集合再平均分成三份,一份用作训练集,一份用作验证集(用于参数选择),一份用作测试集;3)数据集中剩余的40%的评分记录全部当成浏览集合,只保留用户ID 和物品ID。Rec15是RecSys 2015竞赛公开的符合实际购物过程的数据集,原始数据包含了9 249 729 个会话和52 739 个物品,以及对应的1 150 753 条购买记录和33 000 944 条浏览记录。对该数据集进行了如下处理:1)对会话中有重复购买或浏览的物品,仅保留交互时间最早的记录,去除后面重复出现的记录;2)去除被购买次数少于5的物品;3)去除购买记录少于5的会话;4)对每一个会话,把倒数第二次购买记录当成验证集,最后一次购买记录当成测试集,剩下的部分当成训练集;5)若训练集中的浏览物品在验证集和测试集也出现过,将训练集中的这些物品移除。处理后的三个数据集的具体信息如表2所示。

表2 处理后的三个数据集的统计信息Tab.2 Statistics of three datasets after processing
对于ML10M 和Netflix,重复以上步骤三次,便能得到三个不同的数据集副本。在具体实验中,根据验证集上的实验结果选择最优的参数,然后把该最优参数在三个副本上进行实验,最后将三个副本得到的实验结果取平均作为最后的实验结果。对于Rec15,在验证集上选择最优参数,然后在测试集上进行实验得到最后的实验结果。
评价指标采用推荐系统和信息检索中常用的基于排序的指标[30],包括精确率Precision@5、召回率Recall@5、F1@5、归一化折损累计增益(Normalized Discounted Cumulative Gain@5,NDCG@5)以及1-call@5。其中:Precision@5 表示推荐的物品中有多少个是用户喜欢的;Recall@5 表示推荐的物品占用户真正喜欢的物品的比例;F1@5 综合考虑了Precision@5 和Recall@5 两个指标;NDCG@5 表示如果用户喜欢的物品在推荐列表的位置越靠前,对应的增益越大;1-call@5 表示的是推荐的所有物品中至少有一个是用户真正喜欢的概率。
4.2 基准算法和参数选取
为了研究SVAE 的推荐效果,选取较为流行的推荐算法进行比较,包括单类协同过滤算法和异构单类协同过滤算法。因为只关注对异构单类反馈进行建模的算法,因此不包含需要用到辅助信息的算法[21,24-25]。对比算法如下:
1)贝叶斯个性化排序(BPR)模型[16]:该模型是单类协同过滤的经典算法,它的基本假设是用户对已购买物品的偏好大于对未购买物品的偏好,模型通过基于成对偏好假设的方式进行训练。
2)基于对数几率损失的矩阵分解(MFLogLoss)模型[13]:该模型也是对用户的单类反馈进行建模,是基于对数几率损失的矩阵分解模型,通过逐点偏好假设以逐点的方式进行训练。
3)多项式变分自编码器(Multi-VAE)模型[14]:该模型是生成模型,以重构输入样本为目标最大化用户的多项式似然概率,也属于单类协同过滤算法。
4)基于角色的迁移排序(RoToR)模型[9]:该模型是对用户的购买反馈和浏览反馈进行建模的排序模型,根据不同的迁移形式和训练方式设计了不同的变体。
5)SVAE 模型:该模型由两路VAE 构成,经过训练的浏览模型生成抽象隐向量,然后迁移至购买模型,最后以重构用户购买样本为目标进行优化。根据不同的输入形式,模型有两种变体:一是把用户的浏览数据和购买数据混合在一起输入到浏览模型,在这种处理方式下,浏览模型的输入是原始浏览数据和原始购买数据的混合,购买模型的输入是原始购买数据,因此浏览数据和购买数据是相交的,符合实际的购买场景,该变体记为SVAE(B+P);二是把用户的原始浏览数据输入到浏览模型,原始购买数据输入到购买模型,这种情况下认为原始浏览数据仅包含用户浏览(但未购买)的物品,原始购买数据包含用户既浏览又购买的物品,这种做法不失一般性,该变体记为SVAE(B)。SVAE(B+P)和SVAE(B)均采用交替训练的方式进行训练。
关于参数选择,对于BPR、MFLogLoss 以及RoToR,固定用户和物品的特征向量维度d=100,固定学习率γ=0.01,正则化系数从{0.1,0.01,0.001} 中选取,迭代次数T从{100,500,1000}中选取。对于Multi-VAE,设置迭代次数T=1000,隐向量维度h=100,学习率从{0.01,0.001,0.000 1}中选取。对于本文提出的SVAE,参数设置与Multi-VAE 保持一致。正则化系数、迭代次数、学习率等最优参数的选择都根据验证集上的NDCG@5指标确定。
4.3 实验结果与分析
在三个真实数据集ML10M、Netflix 和Rec15 上对所有基准算法进行了实验,结果如表3所示。
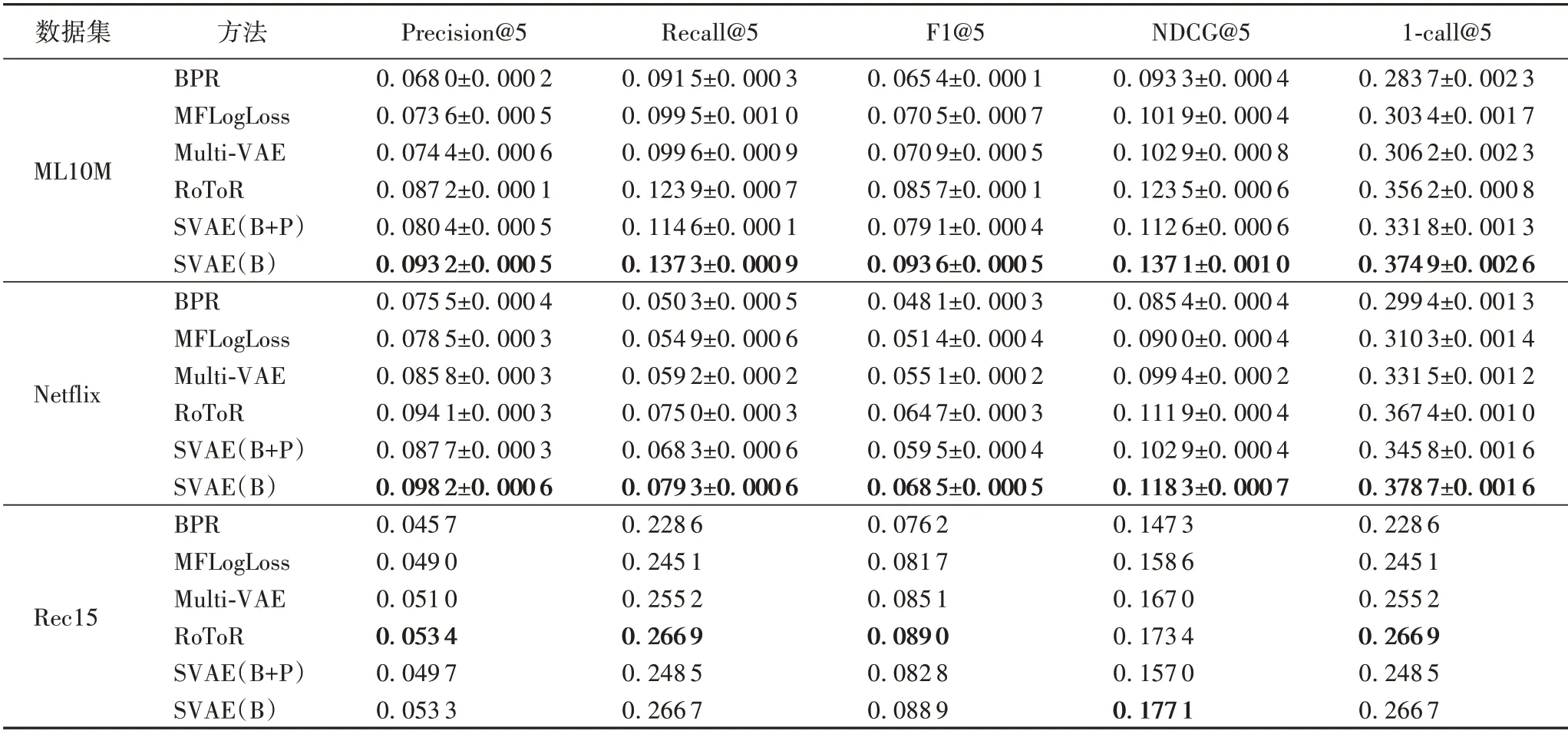
表3 各模型在三个数据集上的实验结果Tab.3 Experimental results of each model on three datasets
由表3可知:
1)在单类协同过滤算法(BPR、MFLogLoss 和Multi-VAE)中,Multi-VAE 在三个数据集上均表现最好,说明变分自编码器模型能够对用户的单类反馈进行有效的建模,优于传统的基于矩阵分解的协同过滤算法(BPR和MFLogLoss)。
2)从三个数据集上的效果来看,基于多种单类反馈建模的算法(RoToR 和SVAE)的实验结果在多数情况下明显优于基于一种单类反馈建模的算法(BPR、MFLogLoss 和Multi-VAE),这说明引入辅助反馈信息是有效的,即两种反馈具有互补性,而且合理有效的建模方式对提升推荐效果是显著的。
3)SVAE模型在多数情况下都是表现最好的,且实验结果相对其他基准算法有显著的提升。具体而言,在ML10M 和Netflix 数据集上,SVAE(B)的效果最好;在Rec15 数据集上,SVAE(B)的效果与最好的基准算法RoToR 相当。这充分说明了本文设计的模型的合理性和有效性,能够准确学习用户的偏好。
表3 是K=5 时各指标的结果值,当K=1、5、10、15 时在三个数据集上的实验结果如图3~5 所示,选取具有代表性的指标Precision@K和NDCG@K上的结果进行展示。由图可观察到,当K取不同值时,SVAE 在多数情况下都是效果最好的模型,与上述的结论一致。
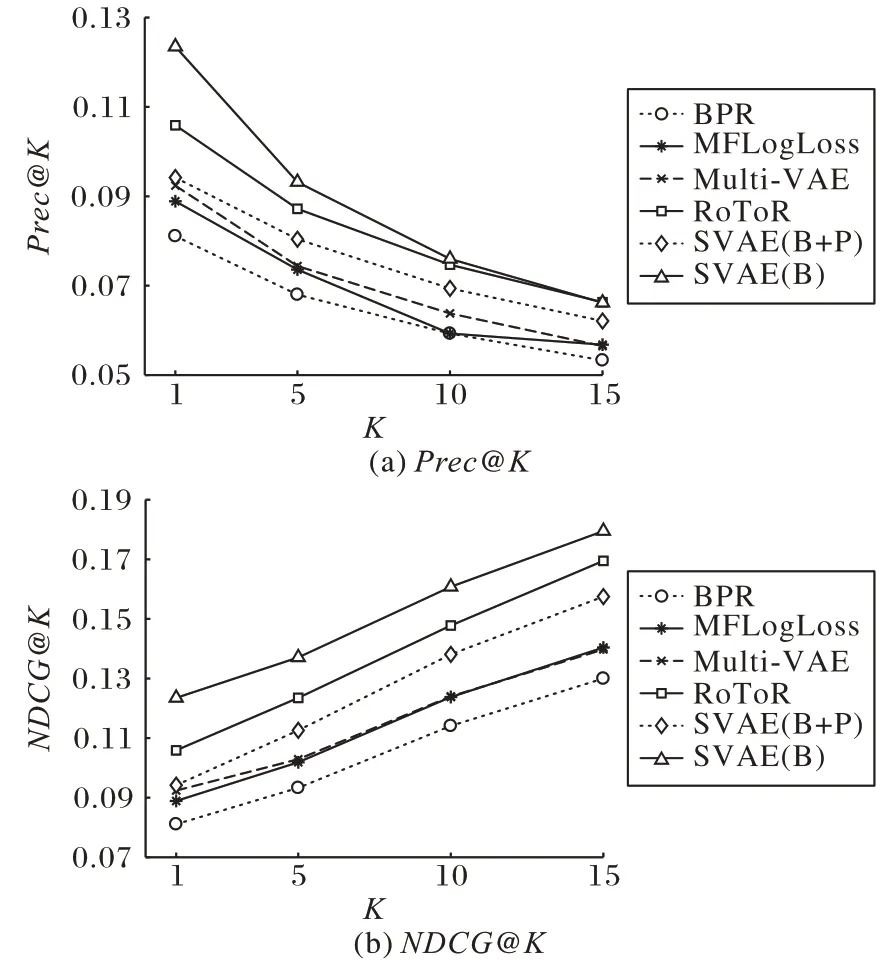
图3 K取不同值时在ML10M上的实验结果Fig.3 Experimental results on ML10M with different values of K

图4 K取不同值时在Netflix上的实验结果Fig.4 Experimental results on Netflix with different values of K
4.4 参数敏感性分析
在上一节中,所有的实验结果都是固定隐向量维度h=100 时得到的结果。本节研究隐向量维度h的大小对模型效果的影响。具体而言,在SVAE 模型中,浏览模型生成的表征向量对应的维度大小记为hA;购买模型生成的表征向量对应的维度大小记为hT。为了缩小选参的范围,设置h=hA=hT,h取不同值时的实验结果如图6 所示,选取具有代表性的Precision@5和NDCG@5两个指标上的结果进行展示。

图5 K取不同值时在Rec15上的实验结果Fig.5 Experimental results on Rec15 with different values of K
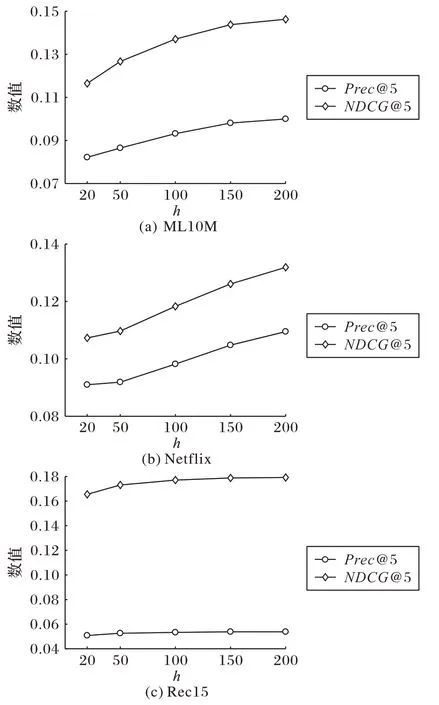
图6 隐向量的维度h取不同值时的实验结果Fig.6 Experimental results with different values of hidden dimension h
可以看到,在ML10M 和Netflix 两个较大的数据集上,两个指标上的结果随着h的增大而增大,说明在较大规模的数据集上适当增大隐向量维度h有助于提升推荐效果;在Rec15数据集上,当h较小时,两个指标上的结果随着h的增大有一定程度的提升,当h>100 时效果趋于平缓,说明在较小规模的数据集上h取较小的值就能得到相对稳定的结果。
4.5 不同输入数据的结果分析
根据浏览模型输入数据的两种处理方式,SVAE模型有两种变体SVAE(B+P)和SVAE(B)。从表3 可以看到,在三个数据集上,SVAE(B)的效果都要优于SVAE(B+P);而与最好的基准算法RoToR 相比,SVAE(B)在ML10M 和Netflix上的效果要优于RoToR,在Rec15上与其效果相当。
对三个数据集的特点进行简要分析,具体信息如表4 所示。从表4可以看到,在三个数据集上,SVAE(B)取得了最优的推荐效果,说明在SVAE 中以混合浏览数据和购买数据的方式处理浏览模型的输入会对模型的效果带来一定的干扰,采用SVAE(B)是更好的选择。在ML10M 和Netflix上,与最好的基准算法RoToR 相比,SVAE(B)在各个指标上的推荐效果均有较为显著的提升,这两个数据集的特点是浏览记录数远大于购买记录数,更重要的是用户已交互的平均物品数较多,数据集较为稠密。在这种情况下,模型的推荐效果较为显著。在Rec15 上,SVAE(B)与RoToR 的推荐效果相当。该数据集的特点是浏览记录数和购买记录数相差不多,且用户已交互的平均物品数非常少,数据集非常稀疏。在这种情况下,模型的推荐效果受到一定的限制。
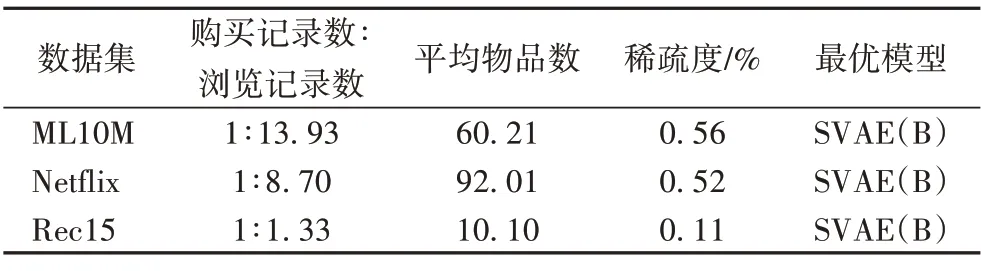
表4 三个数据集的特点及取得最优推荐效果的模型Tab.4 Characteristics of three datasets and model with the optimal recommendation results
4.6 不同训练方式的结果分析
前文提到了SVAE 的两种不同的训练方式,即交替训练和顺序训练:在交替训练中,每一次迭代首先训练所有用户的浏览数据,利用当前的浏览模型参数生成抽象特征zAu⋅,然后将其迁移至购买模型并对所有用户的购买数据进行训练;不断重复迭代该过程直至模型收敛。而在顺序训练中,SVAE首先对用户的浏览数据进行训练,待模型收敛时结束训练。在对购买数据建模时,利用已经训练好的浏览模型参数生成抽象特征zAu⋅,用于帮助购买模型的训练。为了方便展示结果,把基于交替训练的SVAE 模型记为SVAE(alt.),基于顺序训练的SVAE 模型记为SVAE(seq.)。两个模型在两个数据集上的实验结果如表5所示。
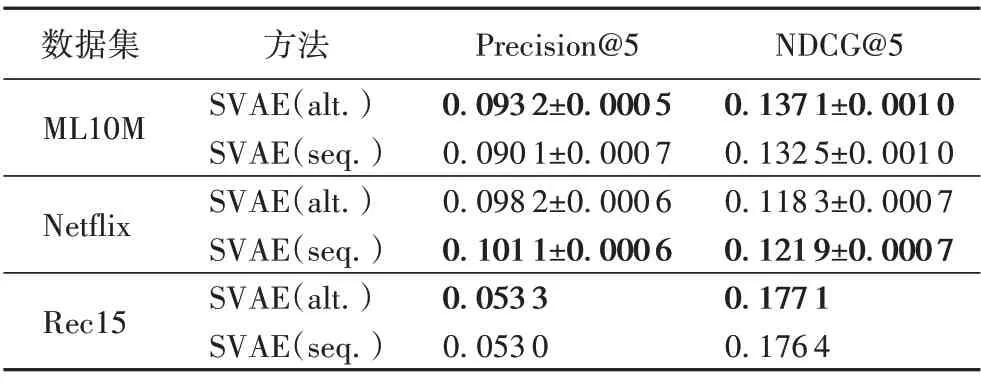
表5 SVAE(alt.)与SVAE(seq.)在三个数据集上的实验结果Tab.5 Experimental results of SVAE(alt.)and SVAE(seq.)on three datasets
从表5可以看到,在ML10M数据集上,SVAE(alt.)的效果比SVAE(seq.)要好;在Netflix 数据集上,SVAE(seq.)的效果比SVAE(alt.)要好;而在Rec15 数据集上,SVAE(seq.)的效果与SVAE(alt.)相当。顺序训练是采用训练好的参数生成抽象特征zAu⋅,从直觉上看根据浏览模型的最优参数生成的抽象特征更能表达用户的浏览偏好。在这种方式中,浏览模型和购买模型的参数是分开选择的(即浏览模型和购买模型的最优参数可能各不相同),浏览模型的参数选择取决于浏览模型在验证集上的表现。而在交替训练中,浏览模型和购买模型的参数是共同选择的(即浏览模型和购买模型的最优参数是相同的),浏览模型的参数选择取决于购买模型在验证集上的表现,在一定程度上会影响浏览模型的训练,也会影响生成的抽象特征向量。因此两种不同训练方式在不同的数据集表现出了一定的差异。
5 结语
本文研究了推荐系统中的一个重要问题,即基于异构单类反馈的协同过滤(HOCCF),其中包含了用户的购买反馈和浏览反馈,目的是利用这两种反馈为用户推荐喜欢的物品列表。针对该问题,提出了一种新的迁移学习解决方案——阶段式变分自编码器(SVAE)模型,分别构建浏览模型和购买模型对用户的异构反馈进行建模。在浏览模型中,输入用户的浏览反馈数据,以多项式变分自编码器(Multi-VAE)为基础模型学习,模型生成隐特征向量作为用户的浏览表征;在购买模型中,迁移浏览模型生成的隐特征向量,与用户的购买反馈数据一起作为另一路Multi-VAE 的输入,用于帮助购买反馈的建模。模型通过两种不同的训练方式学习参数,能够有效地将浏览模型的信息融入购买模型中,进而提升推荐效果。在三个真实的数据集上进行了实验,结果显示SVAE 模型表现在多数情况下显著优于其他流行的推荐算法,验证了模型设计的合理性和有效性。
在未来的工作中,考虑扩展SVAE 模型从而能够融合更多类型的单类反馈(特别是含有噪声的用户反馈),进一步提升模型的通用性和有效性。另一方面,近年来隐私保护逐渐受到大家的关注,如何在保护用户隐私的前提下利用用户的异构数据进行建模成为了一个重要挑战,在未来的工作中会研究并探讨如何将联邦学习技术[31-33]应用在异构单类协同过滤问题中。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年3期)2022-05-24
新高考·高一数学(2022年3期)2022-04-28
计算机研究与发展(2022年1期)2022-01-19
数字技术与应用(2021年1期)2021-03-24
科技与创新(2017年5期)2017-03-28
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
