
基于指针网络的抽取生成式摘要生成模型
2022-01-05 02:31陈伟,杨燕
计算机应用 2021年12期
陈 伟,杨 燕
(西南交通大学计算机与人工智能学院,成都 611756)
(∗通信作者电子邮箱yyang@swjtu.edu.cn)
0 引言
随着网络空间中数据的爆炸性增长,摘要生成技术应运而生,使得人们可以处理非结构化的文本数据,从而获得文本的大意。文本摘要技术的实现可以增强文档的可读性,减少搜寻信息的时间,获得更多适用于特定领域的信息,极具学术研究意义。目前文本摘要生成技术可分为生成式和抽取式方法,其中:抽取式文本摘要可确保语法结构,但不能保证所生成摘要中的语义连贯性;而生成式文本摘要有效地维持了语义的连贯性,但又无法确保所生成摘要的语法结构。为了结合两者的优点,一些方法也同时使用抽取结合生成的方法来完成摘要任务。在生成式摘要中,生成过程往往缺少关键信息的控制和指导,因此一些方法首先提取关键内容,再进行摘要生成,任务可以大致分为两步:首先选择重要文本内容,再将候选内容进行改写。基于此,本文探索了抽取生成式摘要生成方法,构造了融合两者优势的抽取生成式摘要生成方法。利用抽取式算法抽取主题句子作为辅助语义特征,将语义与生成式方法相结合,生成的摘要句子具有与主题更加相似以及语义更加连贯丰富的优势。
首先,在抽取式摘要生成环节,利用TextRank 算法[1]对每个句子节点进行权重计算,并融合主题相似性,根据最终的权重值对文章句子进行抽取,抽取的信息给后续的生成式方法提供了额外的信息;然后,在生成式摘要环节,模型基于Seq2Seq(Sequence-to-Sequence)模型框架,分别对抽取出的候选语义与原文语义进行编码,再对语义进行融合,送入Seq2Seq 的编码器,经过训练,模型将能够学会从抽取式文本中提取有效信息;随后,引入指针网络(pointer-generator network)模型来处理未登录词(Out-Of-Vocabulary,OOV)问题;最后,在公共数据集上进行验证,客观地表明了该模型的效果,分别在ROUGE-1、ROUGE-2 和ROUGE-L 指标上获得提升。
1 相关工作
自动摘要生成一直以来都是自然语言处理领域经典并且热点的话题,随着深度学习的出现,摘要生成领域得到了极大的发展。文献[2]中提出了Seq2Seq 模型用于学习句子中的特征信息。随后文献[3]中将序列到序列模型应用于机器翻译中,取得了很好的翻译效果,从此序列到序列模型开始逐渐应用于抽象文本摘要,并且生成的抽象文本摘要也获得了很好的效果。文献[4]中第一次使用注意机制进一步扩展了基本的序列到序列模型,结合了更多的功能和技术来生成摘要。文献[5]中利用Seq2Seq 模型进行句子压缩,为后续不同粒度的摘要生成奠定了基础。文献[6]中为了控制哪一部分的信息从编码器到解码器,在基本模型中增加了一个选择门控网络。文献[7]中提出了一种基于图和注意机制的模型来加强源文本重要信息的定位。为了解决未登录词问题,文献[8]和文献[9]中分别提出了COPYNET 模型和pointing 机制,文献[10]中创造了read-again 和复制机制。文献[11]中提出了一个更新版本的指针网络模型,效果证明得到了提升。对于重复单词的问题,文献[12]中为了解决翻译过多或遗漏的问题,提出了覆盖机制,利用历史信息进行注意力计算。文献[13]中介绍了一系列不同的结构来解决单词的重复问题。到目前为止,在摘要生成领域,很少有文章在语言层面上考虑结构或语义问题。文献[14]中提出了一种新的无监督方法,利用修剪后的依赖树获取压缩后的句子。基于中文短文本摘要(Large scale Chinese Short Text Summarization,LCSTS)数据集和注意力序列模型,文献[15]中提出了通过计算摘要与文本之间的相似性来增强语义相关度方法。
另一方面,抽取生成技术从源文本中抽取与主题相关的关键词和重要句子,构成摘要。文献[16]中提出了一种具有层次编码器和注意力解码器的模型,用于解决单词和句子级别的抽取摘要任务。文献[17]中提出了SummaRuNNer 模型用于抽取摘要内容,取得了较好的性能。
2 相关原理
2.1 Seq2Seq模型
Seq2Seq模型在摘要生成领域中应用广泛,尤其是生成式摘要生成方法,也有将问题建模为序列标注问题,都会广泛地使用到Seq2Seq 模型。该模型可以看作是一个最简单的文本摘要模型,使用了多层长短期记忆(Long Short-Term Memory,LSTM)网络,将输入序列映射到固定维向量中,然后使用另一个LSTM 从向量中将目标序列进行解码,模型的主体结构主要由两部分组成,分别是编码器和解码器,编码器依次接收文本中的每个单词作为输入。
2.2 TextRank算法
TextRank 算法[1]最早受PageRank 算法的影响,将投票的思想应用到算法中,当某一个网页节点获得的投票数越多,其重要性就越大,在算法计算过程中的权重值也就越大。同时,一个节点的权重还受到投票节点重要性的影响,因为一个节点自身越重要,那么其被链接的节点重要性就越大。所以,一个节点的重要性由其获得的投票数及其周围投票节点自身的重要性所决定。
而TextRank 算法正是应用了这样一种思想,将文本切割为若干以单词或则句子为文本单元的状态,然后将这些文本单元作为一个又一个节点,通过节点间的相似性来确定边和权重值,以此来构建图模型。进一步地将文本量化,使用矩阵的形式来进行表示,有助于进行迭代计算,最终通过节点值的大小进行排序选择,获得需要的信息内容。
该算法不需要对文档进行训练,使用其文档信息就可以实现文档中关键词和关键句的提取,其简洁性促进了该算法的广泛使用。
该算法模型的实际应用可以看作是对文档中句子节点的图模型构造:文档中句子所构成的节点集合为V={V1,V2,…,Vn},构建网络图G=(V,E,W),E是边集合,W是边的权重集合,节点之间的权重可以通过相似度计算函数得到。
节点间概率转移矩阵如下:

通过节点间的概率矩阵和网络图G可以将每个节点的权重进行迭代计算,公式如下:

其中:WS(Vi)是节点权重值;d∈(0,1)是阻尼系数,用来表示图中某一个节点跳转到任意节点的概率,一般设置为0.85;IN(Vi)表示指向节点Vi的所有节点的集合,OUT(Vj)表示节点Vj所指向的节点集合;wij表示节点Vi与Vj之间的相似度;WS(Vj)表示上一次迭代后的权重值。
同时,还需要注意到节点的自身权重,通常将所有节点的初始值权重设置为1,经过多次迭代后,每个节点的权重值趋于稳定达到收敛,B0=(1,1,…,1)T,且收敛公式如下:

通过上式,计算每一次迭代结果,当两次迭代结果差值接近于0 时停止计算,可得到包含各个节点的权重值向量,再按照权重值大小进行排序,选择内容。摘要句抽取主要步骤如下:
a)预处理。将文本中句子进行完整分割、词性标注等操作。句子集合为S={S1,S2,…,Sn}。
b)计算句子间相似度。相似度计算基于句子之间的内容重叠率,计算两个句子包含相同词项的个数,公式如下:
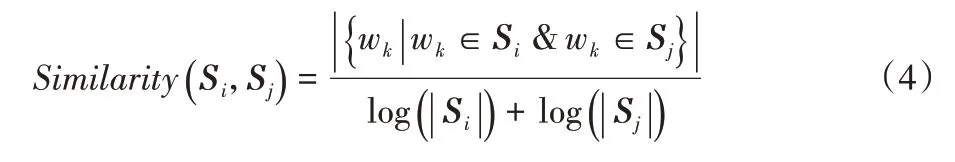
若两条边之间存在语义相关性,则利用它们构成边,边的权值为:

c)利用式(2)迭代计算句子权重直至收敛,得到每个的句子得分。
d)排序选择。利用c)中的得分进行排序,选择最重要的句子作为该文本的候选摘要句。
e)组成摘要。根据相关的要求,如句子数目、摘要字数等,从d)中选择最终内容。
3 改进方法
3.1 句子主题相似性计算
文档的标题、真实人工摘要往往都具有鲜明的主题特色,蕴含了丰富的主题信息,可以简单明了地概括出整个文档的中心思想,是天然的参照信息,所以可以利用其优势来增强模型摘要的生成质量。因此,将参考摘要信息考虑到算法中。用S0表示参考摘要句子,则代表参考摘要的特征词向量,h′用来标记特征词数量。
计算参考摘要与每个句子之间的相似度,若相似度越大则对应句子的权重越大,反之权重提升越小或者保持原状,计算公式如下:
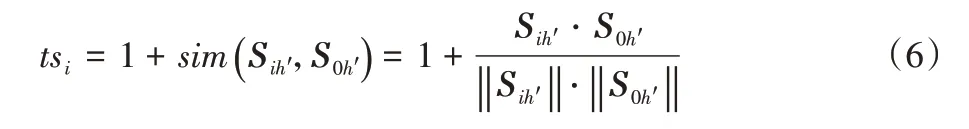
其中:Sih′与S0h′分别表示每个句子与参考摘要的第h′个特征词。根据上式可获得向量,以此可将式(3)调整为:

考虑单词层面的共同包含的特征词项。若文档中各特征词出现在参考摘要中则对应单词的权重越大,反之权重保持原状,计算公式如下:
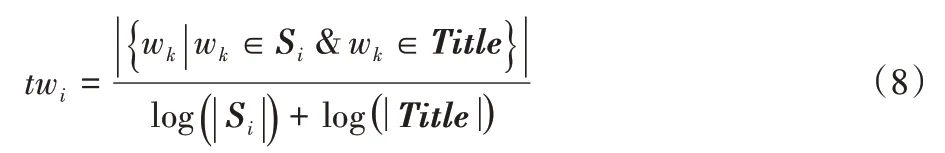
其中:Si是预处理后句子i的词项表,Title表示预处理后参考摘要的词项表,wk是同时出现在参考摘要与句子中的词项。
计算结束后,可得到最终的权重调整值,通过对融入主题相似性的句子权重进行排序,抽取权重大小排名靠前的句子作为候选摘要。
3.2 指针网络
在模型训练过程中,针对出现的OOV 问题,同时也为解决生成文本摘要时词汇量不足的问题,在基础模型之上将指针网络模型进行结合,利用该算法的优势来解决较生涩词汇的生成问题,为提升摘要质量提供了解决思路[11]。具体计算公式如下:
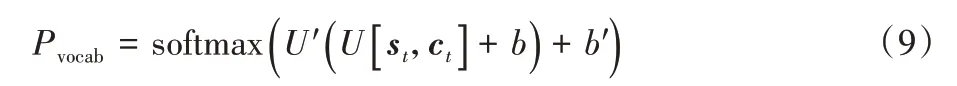
其中:U′、U、b和b′是模型训练中可获得的学习参数,Pvocab是字典上的概率分布。最终预测的单词概率用Pw进行表示,公式如下:

该模型根据时刻t的上下文向量ct和解码器隐藏层的输出状态st以及模型的输入xt来共同生成指针概率Pgen,且Pgen∈[0,1],计算公式如下:


该模型的损失函数使用的是交叉熵函数,对于模型训练过程中的每步t,所预测目标词为wt*,在t步时,损失函数将表达为:

则整个序列的损失函数为:

3.3 基于指针网络的抽取生成式模型
抽取式文本摘要可确保语法结构,但不能保证所生成摘要中的语义连贯性;生成式文本摘要能有效地维持语义的连贯性,但又无法确保所生成摘要的语法结构,所以将两者的优势结合,以期生成更加有可读性的内容。本文模型利用抽取出来的候选语义与生成式方法相结合,参照文献[3],模型如图1 所示,使用单层双向LSTM(Bi-directional Long Short-Term Memory,Bi-LSTM)作为模型编码器,将原文和抽取语义进行编码,利用单向LSTM 作为解码器进行解码操作。对于模型训练每一个步i,分别对应原文文本和抽取的候选摘要的词嵌入将会共同输送到编码器中,同时会生成对应的隐藏状态←→。在解码步骤时,对每一个时间步t,解码器将从步骤t-1 接收词嵌入,该步骤是在训练过程中根据参考摘要中的前一个单词获得,或解码器在测试时自己提供。然后获取隐藏状态st,生成词汇分布P(yt)。
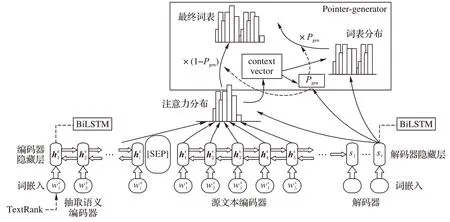
图1 抽取生成式摘要生成模型Fig.1 Extractive and abstractive summarization model



随后,编码器隐藏层的输出hi由融合而成,充分利用原文和抽取语义的信息,具体公式如下:

然后,引入注意力机制[4],计算解码器隐藏状态st与hi之间的相关性eit,计算公式如下:
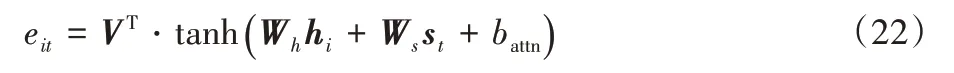
其中:tanh()是激活函数;hi与st分别代表编码器和解码器隐藏层的输出;V、Wh、Ws和battn是模型训练所学习的参数。由此可获得上下文向量ct,公式如下所示:

其中:αit是输入到编码器中单词的注意力分布,可以视为原始文本上的概率分布,可以使得解码器关注某些重要词汇,有助于提取更加重要的语义信息,获得文本信息表示,促进摘要生成。
在该模型中,首先,使用基于注意力机制的Seq2Seq 模型进行构建,同时使用基于TextRank 算法进行文本主题信息抽取。然后,在模型编码层利用特殊字符[SEP]将抽取出来的候选语义与原文语义进行信息融合,特殊字符[SEP]的作用是用于分隔非连续token序列的特殊符号,目的是在于区分原文语义和抽取语义。随后,分别使用编码器对原文及抽取语义进行编码,通过编码器可以得到各自的隐藏状态,再通过编码器隐藏层上对应的语义向量拼接实现信息融合,再将融合之后的语义向量一起送入模型中进行训练,经过训练后,模型将能够学会[SEP]这个标记之后的内容是抽取式文本,并提取其中的有效信息辅助完成摘要生成任务。
最后,引入指针网络模型[18]来解决模型中出现的OOV 问题,利用式(11)获得指针概率Pgen的值,利用其大小来判断模型是从词汇分布中生成单词又或是通过注意力分布从原文中复制单词;然后,利用Pgen对注意力分布和词汇分布进行加权平均,由于Pgen∈[0,1],可以根据其大小灵活设置模型对词汇分布和注意力分布的关注,当单词在词汇分布中不存在时则通过注意力分布将原文单词进行复制,以此将词汇表进行补充,得到扩展词汇表上的最终分布,有效解决了OOV 问题,有利于进一步提升摘要质量。
4 实验分析
4.1 实验环境和模型训练
本文实验在Ubuntu 18.04 LTS 操作系统上进行,编程语言采用的是Python3.6,深度学习框架为TensorFlow 1.10.0,另外使用了CUDA 10.0,用于GPU 加速。主要硬件配置包括CPU 为Intel Core i7 8700K,8 核3.6 GHz;GPU 为NVDIA GTX 1080Ti,显存11 GB;RAM为16 GB。
在基本模型训练过程中,编码器隐藏层使用的是单层双向LSTM 网络,隐藏单元数为256,字向量维数为128,解码器隐藏层使用的是单层单向LSTM 网络。由于该模型使用指针网络来解决词汇量不足的问题,因此字典的大小设置为50 000。训练过程中使用了Adagrad 优化器来进行模型优化[19],学习率设置为0.15,初始累积值为0.1。模型批量大小是32,beam size 为4,模型最大编码长度设置为500,最大解码的输出长度为100,同时最小输出长度设置为35,抽取算法中抽取的候选语义长度设置为100。
4.2 数据集和评价指标
实验数据集使用的是CNN/Daily Mail 数据集[20],该数据集平均每篇文章中有781 个标记、3.75 个摘要句,利用CoreNLP 进行数据预处理[11],将文章划分为句子,并将数据分为若干块,每一块中包含1 000 条文章及摘要信息,该数据集包含了训练集、验证集、测试集,其中训练集中包含287 226个文章摘要对,验证集中包含13 368个文章摘要对,测试集中包含11 490个文章摘要对,并按照相对应的分类进行文件命名。
本实验评价指标采用自动摘要领域中常用的ROUGE(Recall-Oriented Understudy for Gisting Evaluation)[21]系列方法。使用ROUGE-1.5.5工具包对最终摘要结果进行测评,其中ROUGE‑N计算公式如下:
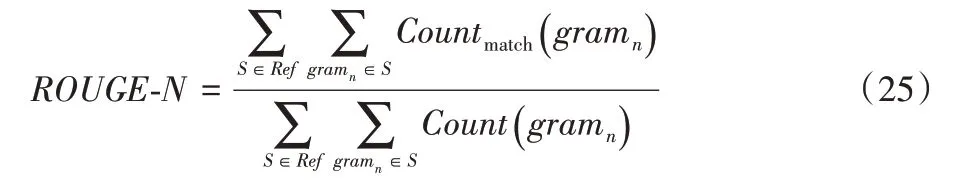
其中:n代表连续单词数;Ref代表参考摘要集;Count(gramn)用于计算基准摘要的N个连续单词数;Countmatch(gramn)计算了基准摘要和生成摘要之间匹配的N个连续单词数。
ROUGE 分别计算了准确率P、召回率R和F值,并且F=2PR/(P+R)。
4.3 实验结果与分析
为了验证本实验的有效性,选择了9 种基准实验进行对比,参照文献[22],其中包含典型的生成式摘要方法和抽取式方法:
1)Seq2seq+Attn:以Seq2seq模型为框架,并融合了注意力机制,是摘要生成领域的典型模型,促进了该领域的大力发展。
2)Seq2seq+Attn(150k):在1)的基础上改变词汇量大小,扩大词汇。
3)Seq2seq+Attn+PGN:首次提出指针生成网络,将该网络融入摘要生成模型训练中,提高了解决未登录词的能力,促进了摘要质量。
4)ABS[5]:利用自动构造的句子-标题来训练神经网络摘要模型。
5)Lead-3+Dual-attn+PGN[22]:将抽取式方法Lead-3与生成式方法结合,设计了双重注意力框架并引入指针网络模型。
6)WordNet+Dual-attn+PGN[22]:在5)的基础上利用WordNet进行句子抽取,并融合指针生成网络模型。
7)TextRank;将句子视为节点来构造图模型,分别迭代计算节点权重值,抽取权重较大信息为摘要内容。
8)Graph-Based Attentional Neural Model[7]:构造基于图模型的注意力机制来完成摘要生成任务。
9)SummaRuNNer[17]:将摘要内容进行抽取,取得了较为良好的性能。
对比数据如表1 所示,可以看出本文模型在ROUGE 相关指标上的表现均得到了一定的提升,从客观上表明了本文模型在生成文本摘要任务中具有一定的优越性。
从表1还可以看出,在实验Seq2seq+Attn基础上引入指针网络后,Seq2seq+Attn+PGN 实验结果在三个指标上分别提升了5.08、3.81 和4.48 个百分点,因此使用指针网络可以较好地提升摘要质量。同时,传统的抽取式摘要生成模型TextRank 模型也为摘要生成带来了良好的评价结果,所以基于此,本文在TextRank 模型的基础之上进行模型的优化也能进一步提升摘要效果,本文模型对比TextRank 模型在三个指标上分别提升了1.74、1.65和1.73个百分点。这表明将生成式方法与抽取式方法相融合的方式更能表达文本的内容,也体现了本文模型的优势。

表1 在CNN/Daily Mail数据集上的实验结果 单位:%Tab.1 Experimental results on CNN/Daily Mail dataset unit:%
同时也给出了该模型对比TextRank在准确率P、召回率R和平均F值上的对比,如表2 所示。可以看出本文模型在相关指标上好于对比模型,说明生成的摘要效果要更加接近于参考摘要,也进一步表明了本文模型在同时考虑抽取式与生成式方法结合时能提升摘要生成的质量。

表2 不同模型在P、R、F指标上的对比结果 单位:%Tab.2 Comparison results of different models on indexes P,R,F unit:%
实验在CNN/Daily Mail 数据集上生成的摘要示例如表3所示。由表3 可以看出,本文模型所生成的摘要在语义信息相似性方面得到了一定程度的提升。例如,在第一个实例中,面对文章内容较多的情况时该模型可以保留较为重要信息,并且相对于TextRank 来说,可以去掉较为冗余的信息,生成的摘要更为简洁;在第二个实例中,对比TextRank 时,出现了相同的关键信息,同时该模型又对部分信息进行了改写,充分体现了抽取式和生成式模型在实验中的作用,突出了抽取生成式摘要模型的优势,同时也肯定了该实验在探索结合两者方法过程中的做法。

表3 文本摘要生成实例Tab.3 Text summarization instances
5 结语
本文研究了结合抽取式方法和生成式方法优势的基于指针网络的抽取生成式摘要生成模型。首先,基于传统的TextRank 算法将主题相似性因素考虑进句子抽取中,得到有效的候选语义,提高句子主题相关性;其次,设计融合抽取语义与原文信息的框架,分别对其进行处理,并通过语义融合共同完成对摘要的生成;然后,引入指针网络模型解决未登录词问题;最后,在CNN/Daily Mail 数据集上验证了本文模型的有效性。在未来工作研究中,将进一步考虑抽取生成式摘要模型在文本摘要生成中的表现。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年3期)2022-05-24
心理学报(2022年5期)2022-05-16
数字技术与应用(2021年1期)2021-03-24
当代陕西(2020年17期)2020-10-28
娃娃画报(2019年4期)2019-05-14
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
广东第二课堂·小学(2017年9期)2017-09-28
科技与创新(2017年5期)2017-03-28
