
融合句法信息的无触发词事件检测方法
2022-01-05 02:31张亚飞郭军军高盛祥余正涛
计算机应用 2021年12期
汪 翠,张亚飞*,郭军军,高盛祥,余正涛
(1.昆明理工大学信息工程与自动化学院,昆明 650504;2.云南省人工智能重点实验室(昆明理工大学),昆明 650504)
(∗通信作者电子邮箱zyfeimail@163.com)
0 引言
事件检测是信息抽取中一项重要而具有挑战性的任务,事件检测任务旨在识别句子中的事件触发词并将其分类为特定类型。触发词是指在句子中能够清楚地表示事件发生的核心单词,通常是动词或名词短语。
大多数现有的事件检测方法需要带标注的事件触发词和事件类型进行训练。这些方法根据输入的不同,可以分为基于语义表示[1-3]的方法和基于句法依存表示[4-6]的方法。其中,基于语义表示的方法只使用给定的句子作为模型的输入,在长距离依赖方面存在着低效率的问题。基于句法依存表示的方法通过在模型中融入句法信息能够准确定位与触发词最相关的信息,以及在单个句子中存在多个事件时,增强事件之间的信息流动性。现有的基于句法依存表示的方法通常采用邻接矩阵来表示原始的句法依赖关系[4-6],但邻接矩阵表示范围有限,只能捕获当前节点与相邻节点的关系。同时,邻接矩阵需要图卷积网络(Graph Convolutional Network,GCN)对其进行编码以获取句法信息。但是,利用GCN 编码会引入额外的训练参数,增加了模型的复杂度。此外,这些方法对触发词的标注会耗费大量的人力工程。
为解决以上问题,受Okazaki 等[7]提出的采用父词信息来表示句法依赖关系思想的启发,本文提出了融合句法信息的无触发词事件检测方法。将依存句法解析中的依赖父词(下文简称为父词)及其上下文转换为位置标记向量后融入依赖子词中,不需要借助GCN 的编码便能获取句法信息,并提高事件检测的准确性。具体地,在Transformer 的局部自注意力机制中以一种无参的方式将父词信息融入依赖子词的单词嵌入,使模型在编码源句子时关注到每个单词的父级依赖项及其上下文;同时,针对触发词的标注费时费力,提出了基于多头注意力机制的类型感知器对句子中隐藏的触发词进行建模,以实现无触发词的事件检测。
通过在ACE2005 数据集上的实验表明,本文采用的方法在事件检测任务上取得的性能超过了以往的方法;另外,通过在低资源越南语数据集上的实验表明本文方法也适用于少样本的低资源情况。
1 相关工作
在早期的工作中,事件检测的方法包括基于特征的方法,该方法在不同的统计模型[8]中采用手工设计的特征。在过去的几年里,神经网络模型成功地用于事件检测。其中,典型模型采用了卷积神经网络(Convolutional Neural Network,CNN)[1]、循环神经网络(Recurrent Neural Network,RNN)[2]、双向长短时记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)循环神经网络[3],虽然这些方法能有效地捕获局部的语义关系,但对于非局部以及非结构化的句法信息却能力有限。然而,在许多应用中,这种非局部的句法信息可以显著地加强句子的语义表征并提高整体性能。为了将句法信息融入神经网络模型以提高事件检测性能,Yan等[4]将邻接矩阵输入到具有聚合注意的图卷积网络中,来对句子中的句法表示进行显式建模和聚合;陈佳丽等[5]将GCN 编码后的句法信息与文本的语义信息通过门控机制进行融合;Li 等[6]通过GCN 生成多个潜在的上下文感知图结构来选择有用的句法信息;Dutta等[9]将句法解析树中单词之间的依赖关系以及依赖标签整合到图变换网络(Graph Transformer Network,GTN)[10]中以实现事件检测。
以上基于句法依存表示的方法采用邻接矩阵来表示原始的句法依赖关系,需要经过GCN 编码为高阶的句法表征后,再融合到文本的语义信息中,由此增加了模型的复杂度。因此,本文将父词信息连接到依赖子词来表征句法依存树中的依赖关系,并在Transformer 的编码器中将非结构化的句法信息与结构化的语义信息进行融合,不破坏Transformer 原本的结构性、减少了GCN 单独编码的额外参数,并且更加简便有效。
2 融合句法信息的无触发词事件检测模型
首先,文本采用Transformer 编码器获取句子的上下文语义表征,然后使用多头注意力机制来建模句子中潜在的触发词,最后将获取的触发词信息连接到句子的语义表征来获取全局的事件信息。模型的基本架构如图1所示,由4个部分组成:输入层、语义表示层、类型感知器层以及输出层。
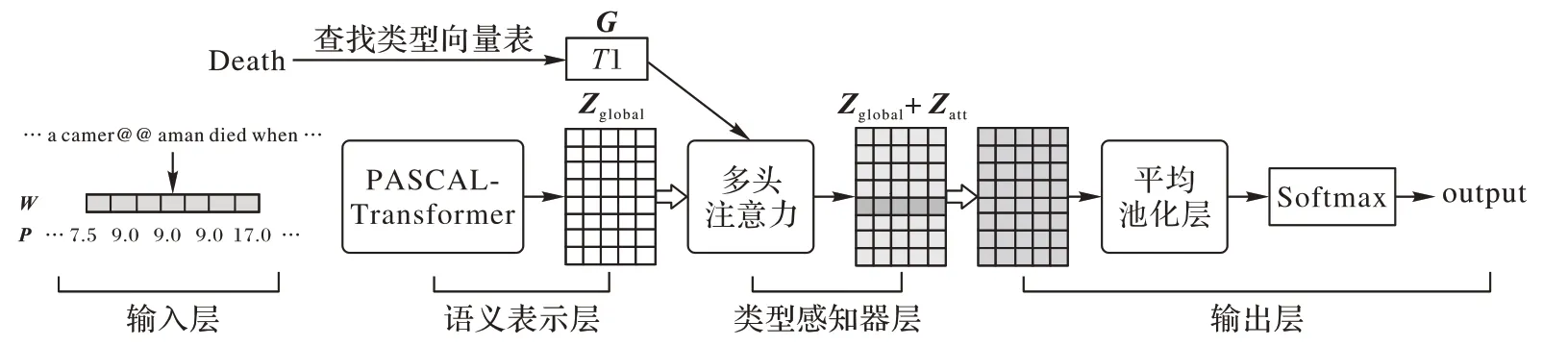
图1 融合句法信息的无触发词事件检测模型的基本架构Fig.1 Basic structure of no trigger word event detection model incorporating syntactic information
2.1 输入层
本文以目标句子以及由外部解析器提供的句法依存关系作为模型的输入,此外还使用BPE(Byte Pair Encoding)子词单元来缓解未登录词与罕见词问题。将输入的文本序列进行BPE 编码后以补全或截断的方式固定句子长度,将其表示为X={x1,x2,…,xi,…,xn},n为句子长度。对X进行随机初始化后获得词向量W={w1,w2,…,wi,…,wn},其中,wi为xi的向量表示。
还根据单词经过BPE编码后的子词数量来计算出每个单词的中间位置,以及将每个单词映射为其父词的中间位置表示。如图2所示,S1中的married经过BPE编码后获得S2中的3 个子词单元“mar@@”“ri@@”“ed@@”,位置分别为3、4、5,则married 的中间位置为4.0;然后将S2 的每个子词单元映射为其父词(句中所有单词的父词为married)的中间位置;从而为目标句子S2产生一个由父词的中间位置组成的向量表示P;最后以词向量W和父词的位置向量P作为语义表示层的输入。

图2 句法信息处理实例Fig.2 Examples of syntactic information processing
2.2 语义表示层
图1 中的语义表示层由12 层的Transformer 编码端组成。本文在第li层Transformer 的局部自注意力层中融入了句法信息,而其他层的Transformer 则采用普通的自注意力层。融入句法信息的局部自注意力称为依赖缩放自注意力(PArent-SCALed self-attention,PASCAL),结构如图3所示。

图3 依赖缩放自注意力(PASCAL)结构Fig.3 Structure of Parent-Scaled Self-Attention(PASCAL)
在图3 的PASCAL 结构图中,词向量W经过线性变换后,获得查询Qh、键Kh和值Vh。先计算Qh和所有Kh之间的点积,给出句子中每个单词对输入的其他部分放置多少焦点的分数。然后,这个分数除以,以缓解如果点积很大时出现的梯度消失问题,d的大小为W的大小dmodel除以多头注意力机制的头数h。最后获得相似度权重Sh∈Rn×n,如式(1)所示。

然后,通过父词的位置向量P将句子中的每一个词关联到其父级依赖项。以xi作为当前词,通过计算出所有xj到xi的父词的距离来衡量xi位于位置i的得分。如式(2)所示,pi表示xi的父词的中间位置,j表示句子所有词的绝对位置,输出的句法关联矩阵D∈Rn×n,D的每一行表示任意j到xi的父词的中间位置pi的距离。
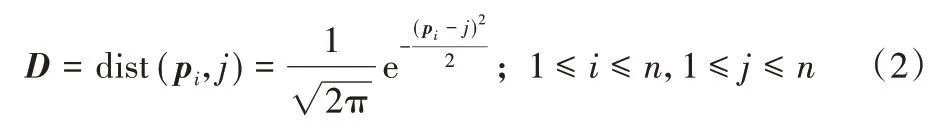
之后,将相似度矩阵Sh、值vh与句法关联矩阵D通过向量运算的方式进行融合。如式(3)、(4)所示,序列相似度矩阵Sh与关联矩阵D对应元素相乘后得到中间向量Nh,对Nh应用Softmax 后再与值vh相乘,获得PASCAL 每个头的输出Mh。这样便实现了以局部无参的方式将句法依赖信息融入缺乏任何上下文的词嵌入中。

将Mh拼接后获得PASCAL 的最终输出M,M经过Transformer 后续的残差连接、归一化以及全连接层后获得M′。然后M′经过剩下的11 层Transformer 编码器后获得句子的全局特征表示Zglobal,如式(5)~(7)所示。

2.3 类型感知器层
由于本文任务没有标注触发词,为了对隐藏的触发词进行建模,通过在多头注意力机制中引入候选事件类型来发现句子中隐藏的触发词。
如式(8)、(9)所示,对全局特征Zglobal和候选事件类型的词嵌入G进行头数为8 的多头注意力机制,为Zglobal中潜在的触发词分配更高的权重。

其中:Zglobal为语义表示层的输出;G为候选事件类型的词嵌入;是在输入向量上执行线性投影的参数;At表示多头注意力机制中每个头的最终输出;Zatt为At的拼接,表示包含触发词信息的局部特征。
2.4 输出层
为了获取全局的事件信息,将全局特征Zglobal和局部特征Zatt进行加权求和后再执行平均池化操作,然后经过一个线性层后获得向量H;最后,对H执行Softmax 获取对应类别的分布概率,并根据概率分布的值来判断输入句子的事件类型,如式(10)~(12)所示。

其中:H表示全局事件信息;W和b为权重和偏置;y′表示输入句子是否为预标注类型的概率;y表示最终的预测值。
2.5 模型训练
为了解决机器学习中的多标签问题——一个句子可能包含零个或多个事件[11],本文在模型中将多标签分类转化为多个二分类。如表1所示,假设句子s共有三个预定义的事件类型t1、t2和t3,而句子s包含事件类型t1和t3,则事件句s可以转化为以表1所示的三个实例。

表1 事件句s的二分类举例Tab.1 Example of binary classifications of sentence s
这样的话,如果一个句子中包含多个事件,则可以产生多个正对,从而很好地解决了多标签问题。此外,模型训练的目标函数采用交叉熵损失,如式(13)所示:

其中:θ表示模型中需要更新的参数;N表示一个batch 的样本数;K表示类别数,本文将其设置为2,即每个句子属于预标注类型或无类型(NA);y代表真实标签,值为0 或1;ŷ表示候选事件的预测概率。本文使用Adam优化函数来更新参数θ。
3 实验与分析
3.1 数据集及评价指标
3.1.1 数据集
本文在ACE2005 数据集上进行了大量的实验,并对ACE数据集进行了预处理:删除数据集中触发词的标注,使用Stanford CoreNLP 工具获取句法依存信息,并为每一个句子分配一组标签,不包含任何事件时标注为NA。为了方便比较,划分数据集的方式与文献[4-6]一致,将40 篇文章作为测试集,30篇文章作为开发集,剩余的529篇文章作为训练集。
此外,本文还构建了一个小型的越南语数据集,用于验证本文方法在少样本的低资源语言上的泛化能力。构建的数据集总共有5 317 条样本数据,正样本2 913 条,负样本2 404 条。纯文本数据来自多个公开的越南语新闻网站。经过人工排查去除大部分非事件句后,以ACE 定义的33 种事件类型为基准,采用人工的方式为每一条句子标注候选标签,以及采用VnCoreNLP 工具获取句子的句法依存信息。其中,不包含任何事件的句子被标注为NA,标注后的句子案例见图4。越南语数据集的划分比例和实验设置等同于ACE2005。

图4 越南语数据集标注案例(无触发词)Fig.4 Examples of labeling of Vietnamese dataset(no trigger words)
备注:以下实验,除低样本的对比实验在越南语数据集上进行,其他实验均设置在ACE2005数据集上。
3.1.2 评价指标
评估方法和Liu 等[11-14]的工作一致,使用准确率P(Precision)、召回率R(Recall),F1 值F1作为评价指标。P、R、F1定义如式(14)~(16)所示。

3.2 参数设置
本文选择Pytorch 框架进行开发,采用12层的Transformer编码端作为编码器,本文模型中用到的多头注意力机制的头数均设置为8,具体的超参数设置如表2所示。
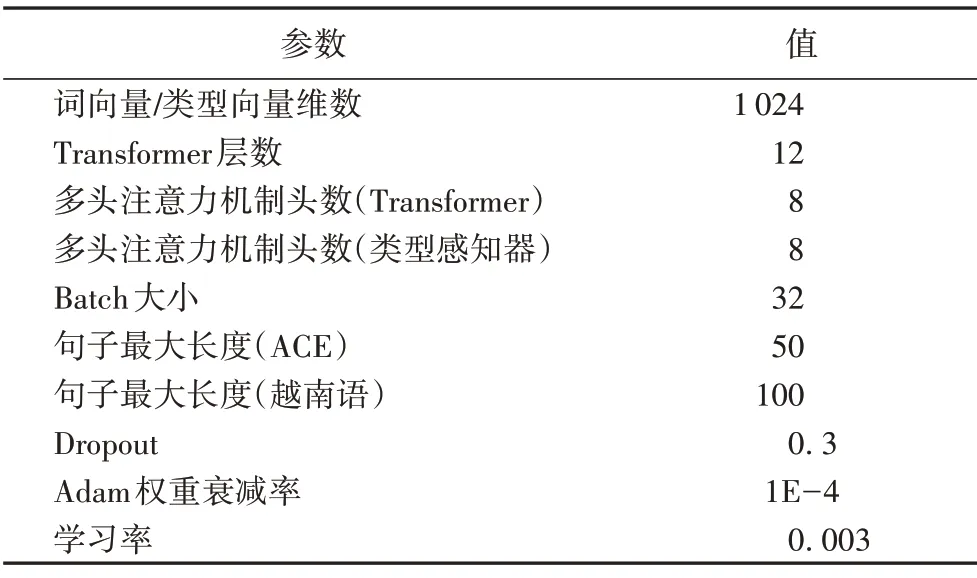
表2 模型超参数Tab.2 Model hyperparameters
3.3 与基线模型的对比实验
3.3.1 基线模型
本文选用以下8个事件检测模型作为基线模型,其中前4种是基于语义表示的事件检测模型,后4 种是基于句法依存表示的事件检测模型,它们都是当前事件检测方面经典或最新的模型,分别如下:
1)基于语义表示的事件检测模型。
动态多池卷积神经网络(Dynamic Multi-Pooling Convolutional Neural Network,DMCNN)[1],使用动态多池层从纯文本中自动提取词汇级和句子级特征。
双向递归神经网络(Joint event extraction via Recurrent Neural Network,JRNN)[2],采用双向递归神经网络的联合框架来进行事件抽取。
混合型神经网络(Hybrid Neural Network,HNN)[3],将双向长短时记忆网络(Bi-LSTM)和卷积神经网络(CNN)相结合,获取来自特定上下文的序列和结构语义信息。
类型感知偏差注意机制神经网络(Type-aware Bias Neural Network with Attention Mechanism,TBNNAM)[11],它根据目标事件类型对句子的表示进行编码。
2)基于句法依存表示的事件检测模型。
多阶图卷积和聚合注意力的事件检测方法(Multi-Order Graph Attention Network based method for Event Detection,MOGANED),由Yan 等[4]提出,使用GCN 对句法信息编码,并使用Attention机制聚合句中多阶的句法信息。
利用门控机制融合依存与语义信息的事件检测方法[5],采用Bi-LSTM 与GCN 分别学习语义表示与句法表示,再利用门控将语义信息与句法信息动态融合。
多个潜在上下文感知图结构上的图卷积网络事件检测方法MH-GCN(Graph Convolution Over Multiple Latent Context-Aware Graph Structures for Event Detection)[6],通过在BERT 表示和邻接矩阵上应用注意力机制,再使用GCN 生成多个潜在的上下文感知图结构,动态保留与事件检测有关的信息而忽略无关信息。
图变换网络事件检测(Event Detection Using Graph Transformer Network,GTN-ED)方法[9],通过在GTN 中融入句法解析树中的依赖标签来完成事件检测任务。
3.3.2 实验结果分析
为了验证本文提出的方法在事件检测任务上具有优势,将本文模型与以上8个基线模型进行了对比,实验结果如表3所示(前人工作的实验性能数据均引入相应参考文献中的公开数据)。
分析表3 可知,本文模型的整体性能优于其他的基线模型,其中与基于语义表示的HNN 模型相比F1值提升了7.1个百分点,与基于句法依存表示的GTN-ED模型相比,F1值提升了3.7个百分点。

表3 事件检测实验结果 单位:%Tab.3 Experimental results of event detection unit:%
原因分析:
1)基于语义表示的方法将文本嵌入作为模型的输入,然而,LSTM等神经网络模型固有的特性并不能很好地解决句子的长距离依赖问题。本文通过引入句法信息加强了事件信息之间的语义关联性以及增强了整个句子的上下文语义表征,因此实验效果得到明显提升。
2)TBNNAM 模型专注于无触发词的事件检测,采用基于类型感知的Attention 去发现句子中潜在的触发词。与TBNNAM 不同的是,本文将LSTM 编码器替换为PASCALTransformer,通过在Transformer 中融入句法信息有效捕获了直接与触发词关联的事件信息以及在单句子包含多个事件时加强了事件之间的信息流动性;此外,还将TBNNAM 中普通的注意力机制替换为多头注意力机制,并在注意力机制之后将句子的全局特征和触发词的局部特征进行加权求和后进一步执行平均池化操作,以获取全局的事件信息。由此实现了超越性的效果,F1值较TBNNAM提高了10.6个百分点。
3)相比之前基于句法依存表示的方法通过采用GCN 来编码邻接矩阵以获取句法信息,本文方法证明通过将父词信息连接到依赖子词也能有效地进行句法信息的表征。此外,相较于之前的模型采用GCN 对句法信息编码后再与文本的语义信息进行融合,本文采用向量运算的方式将句法依赖的位置信息融入句子的单词嵌入,减少了使用GCN 编码的额外参数,一定程度上提升了模型的性能。
3.4 在低资源数据集上的对比实验
为了验证本文模型在低资源数据集上的泛化能力,选取了同为二分类的TBNNAM 模型进行对比分析。此模块仅选取TBNNAM 模型进行对比分析的原因在于:越南语以音节为单位进行分词,即单个触发词由不同的音节组成,分散在句子的不同片段中,导致无法确切地对事件的触发词信息进行标注,而以上基线模型中除TBNNAM 以外的模型都需要确切标注候选事件句中的触发词信息,因此,在面向低资源的越南语数据集时,文本仅在二分类基线模型TBNNAM 上设置实验进行对比分析,实验结果如表4 所示。与基线模型TBNNAM 相比,本文的P、R、F1分别提高了7.9、10.9、9 个百分点,表明在低样本的越南语数据集中融入句法信息能够捕获越南语句子中多音节单词之间的句法关联性。因此,与基于语义表示的TBNNAM 相比,本文的模型在低资源的越南语数据集上具有更好的泛化能力。

表4 越南语数据集上的实验结果 单位:%Tab.4 Experimental results on Vietnamese dataset unit:%
3.5 模块有效性分析实验
3.5.1 在Transformer的某一层融入句法信息
为了验证句法信息中父级依赖词的语境可以丰富句子中孤立的单词嵌入表示,在语义表示层中设置了如下两组实验:不设置PASCAL以及在不同的Transformer层中设置PASCAL。其中,-1_PASCAL 表示不融入句法信息,n_PASCAL 表示在12层Transformer的第n层中融入句法信息。
如表5所示,在第一层设置PASCAL的实验性能比只采用句子进行编码的性能更优越,这说明融入句法解析中的句法依赖关系可以使句中单词关注到语义上与之关联的其他单词。另外,当在不同的Transformer 层中设置PASCAL 时,在底层的效果明显优于高层,这和文献[15]中的结论一致:在底层时,更多的注意力集中于句法关系的编码,而在高层中则偏向于语义任务。因此,可以推断,在第一层执行PASCAL 时能充分利用句法依赖的位置信息来丰富孤立的单词嵌入表示;而在高层时由于已经初步编码到文本的语义表征,将导致模型偏向于文本的语义编码而忽略来自底层的句法位置信息。
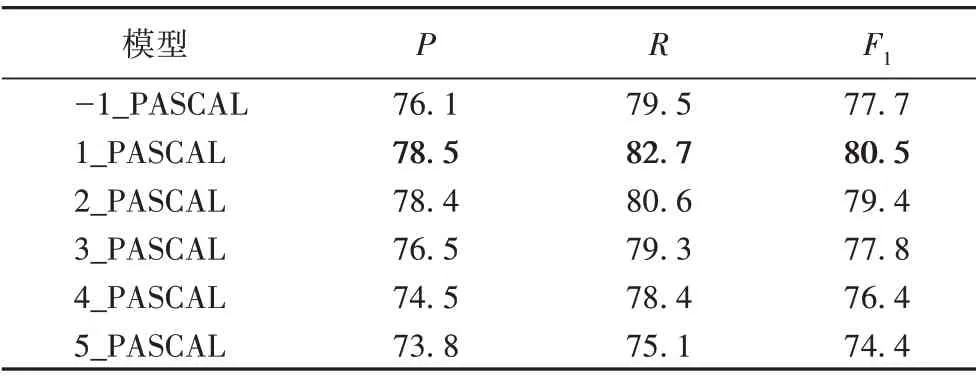
表5 不设置PASCAL以及在不同Transformer层中设置PASCAL的实验结果 单位:%Tab.5 Experimental results of not setting PASCAL and setting PASCAL in different Transformer layers unit:%
3.5.2 在12层Transformer的多层中融入句法信息
为了验证仅在12 层Transformer 的单层中设置句法信息的有效性,设置了在第m(1 ≤m≤12)层的Transformer 中同时融入句法信息的分析实验,结果如图5 所示。可以看出,当m<5 时,随着m的增加F1 值趋于稳定;当5 ≤m≤12 时,随着融入层数的增加,F1 值逐渐下降。由此表明,在少量的Transformer 层中融入句法位置信息能有效捕获句子的句法信息,而在大量的Transformer 层中融入句法位置信息时不可避免地对句子的语义编码造成了噪声,以及大量句法信息的融入一定程度上增加了模型的复杂度,影响了模型的性能。同时,考虑到在少量层中融入句法信息可以降低模型的复杂度,以及结合3.4.1 节的推论即在Transformer 的底层融入句法信息取得的试验效果最佳,因此,本文最终选择了在Transformer的第一层进行句法信息的融入。

图5 在12层Transformer的第m层中融入句法信息的F1值Fig.5 F1 score incorporating syntactic information into m-layer of the 12-layer Transformer
4 结语
本文通过在Transformer的编码器中融入句法信息有效捕获到了候选触发词与相关实体之间的句法关联性,增强了多事件句中不同触发词之间的信息流动性;同时,通过采用类型感知器发现了句子中潜在的触发词,实现了无触发词的事件检测。实验表明,本文模型在ACE2005 数据集上取得了竞争性的效果,在低资源越南语数据集上也取得了较好的性能。另外,针对越南语数据集的实验性能低于公开数据集的情况,在未来的工作中,我们希望引入预训练模型,并利用海量的高资源语言来辅助低资源的越南语来完成事件检测任务。
猜你喜欢
环球时报(2022-09-15)2022-09-15
北京航空航天大学学报(2022年8期)2022-08-31
华文教学与研究(2022年1期)2022-04-27
中国典型病例大全(2022年7期)2022-04-22
中华诗词(2018年3期)2018-08-01
中国房地产业·上旬(2018年1期)2018-05-14
中华诗词(2018年11期)2018-03-26
求知导刊(2016年28期)2016-11-28
科教导刊·电子版(2016年23期)2016-10-31
青年文学家(2015年2期)2016-05-09
