
基于用户传播网络与消息内容融合的谣言检测模型
2022-01-05 02:31薛海涛杨延杰
计算机应用 2021年12期
薛海涛,王 莉*,杨延杰,廉 飚
(1.太原理工大学大数据学院,太原 030600;2.北方自动控制技术研究所,太原 030006)
(∗通信作者电子邮箱wangli@tyut.edu.cn)
0 引言
社交媒体的即时性和便利性使得用户可以便捷获取信息并交流观点,但也为谣言传播提供了便利平台。谣言传播误导公众舆论,破坏社会安定,谣言检测与监管已经成为一个迫切需要解决的社会问题。
谣言检测的早期研究中,研究者一般通过手工构造消息文本的特征,利用决策树、随机森林、支持向量机(Support Vector Machine,SVM)等机器学习的方法进行分类[1-2],以判别真假。这类工作依赖于特征工程,无法适应社会媒体丰富多变的内容表现以及不断演化的特点,而且社交媒体上的消息篇幅普遍较短,其包含的语义特征有限,一定程度限制了算法模型性能。后来一些研究工作利用消息传播过程[3-4]进行谣言检测,性能有所提升,但由于消息转发中存在大量空转发,这类基于转发结构及内容的模型在实际场景中有很大的局限性。还有一些工作将用户属性引入,以用户的权威度、可信度等作为判别所发布消息真伪的证据,但是由于当前谣言更具迷惑性,一些权威用户有时也会被蒙蔽而转发谣言,所以,仅依靠用户权威度评价是不够的。
实际应用中我们发现,虽然消息转发中用户有时会空转发,但是传播链中用户的参与信息在一定程度上表达了对于所转发消息的认同,同时,用户的粉丝数、发表推文数及关注数等属性信息在一定程度上反映了用户的权威度,因此,传播链中的用户属性信息可以帮助判别谣言。同时,消息内容对于检测谣言也非常重要。鉴于以上观察分析,本文提出了一种融合传播链中的用户属性和消息内容的谣言检测模型GMB_GMU。
受上述工作启发,本文使用用户属性、传播结构和消息内容进行谣言检测。首先,构建转发图,节点特征为用户属性,边表示转发关系。结合转发图,利用图注意力网络(Graph Attention neTwork,GAT)获取增强的用户属性表征。在另一部分,使用node2vec算法获取转发图用户的结构表征,而不依赖于节点属性,借助互注意机制以得到增强的结构表征。最后一部分使用源帖文本的BERT(Bidirectional Encoder Representations from Transformers)向量,取得增强的源帖内容表征。将这三种角度的表征输入到多模态门控单元(Gated Multimodal Unit,GMU)进行选择与融合,得到信息的最终表征。在公共数据集上进行实验,结果验证了本文模型的判别精度和泛化能力,并检测了模型在谣言早期检测任务上的表现性能。本文主要工作如下:
1)融合传播链中的用户属性信息和消息内容进行谣言检测,避免了信息传播结构计算中空转发带来的信息缺失问题。
2)引入GAT 生成用户属性表征,采用node2vec 得到结构表征,采用互注意机制建立用户结构增强表征;同时基于BERT 建立源帖内容表征,最终将用户属性表征、结构表征和源帖内容表征表征三者融合得到消息的最终表征,以支持谣言检测。
3)在公共数据集上进行实验,验证了模型的性能,并通过早期检测任务,验证了模型的有效性。
1 相关工作
目前的研究主要可分为基于内容语义和基于传播结构的谣言检测方法。
1.1 基于内容语义的谣言检测
随着深度学习的发展,卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)以及长短期记忆(Long Short-Term Memory,LSTM)网络等被应用到自然语言处理任务中进行文本表征学习[5],以挖掘文本语义。段大高等[6]提出了一种融合用户属性和帖子内容特征的BP 神经网络模型,通过Word2Vec 算法进行表征计算,然后输入到神经网络模型中提取文本特征。刘政等[7]提出了基于CNN 的谣言检测算法,使用句向量结合多层卷积网络,能有效地捕捉到特定范围的上下文语义信息。Mikolov 等[8]将双向RNN 应用到文本特征提取中,获取到了前后语义之间的联系。对于其他神经网络方法,虽然可以准确地把握整体信息,但对于较长的文本,仍然存在上下文信息丢失的情况。
为了最大限度地捕捉到上下文信息,Fang 等[9]将注意力算法引入到谣言检测工作中,取得了较好的检测结果。Vaibhav 等[10]提出了一种基于图神经网络的虚假新闻检测模型,该模型对新闻中所有句子对之间的语义关系进行建模,从而进行谣言检测。Wang 等[11]依赖文本内容,提出了SemSeq4FD 模型来检测虚假信息,该模型同时考虑了新闻中句子之间的全局语义关系和局部上下文顺序特征。上述所有基于内容语义的方法最大的局限性在于这些算法更适用于长文本处理,模型表现优良的前提在于提供大量长文本进行训练,但是,社交媒体上的帖子大多都是短文本,难免造成数据稀疏问题,从而影响了该类方法的检测性能。
1.2 基于传播结构的谣言检测
由于谣言涉及的领域繁杂,普遍存在学科交叉的现象,使得研究谣言传播成为一个复杂的问题。在相关工作中,不仅涉及传播的覆盖范围,还涉及传播的速度。其中较常用的是传染病模型和其变体模型,如SIS 模型和SIR 模型,每个传播结构中的用户可被分为“感染者(S)”“被感染者(I)”以及“停止感染者(R)”状态,由一传多到多传多,可以描述谣言的传播模式。但由于信息传播的时间等特点,传染病相比信息传播在衰退效应、信息内容和联系强度等方面都有明显的区别,不适用于谣言传播。
当前,研究者倾向于关注传播网络本身的拓扑结构,从而揭示其传播特征和规律。Ma 等[4]提出了通过评估不同类型的传播树结构的相似性来捕获新闻事件的高阶表征。Liu等[12]提取了信息传播过程中传播树的宽度与深度等特征。Shu 等[13]利用社交媒体上的新闻分层传播网络进行了假新闻检测,从宏观和微观两个层面建立了一个层次化的传播网络,并比较分析了传播网络的结构特征和时间特征。Bian等[14]提出了一种使用双向GCN 进行谣言检测的方法,该方法结合了谣言的序列传播和横向扩散,捕捉到了传播结构的全局特征,获得了较好的检测结果。现有的基于传播的方法使用消息传播结构信息,但是消息传播中存在大量空转发,导致消息中存在较多噪声,影响模型性能。在另一方面,这些方法没有充分使用源帖信息,在检测性能方面受到了很大限制。
2 问题定义
给定新闻C,其中包含m个参与新闻传播的用户,如图1所示,该新闻的用户集合为U={u1,u2,u3,…,um},其中u1为发布原始文本的用户,u2,u3,…,um为参与转发的用户,包含一阶转发用户、二阶转发用户和更高阶的转发用户,目标为训练一个网络f:(C,U) →y,将新闻C分类为谣言或非谣言。其中,标签值y∈{0,1},0 表示非谣言,1 表示谣言。信息传播一般表现为树型转发扩散的模式。
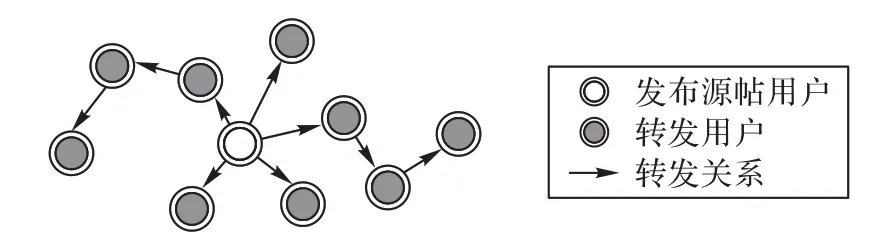
图1 信息传播模式示意图Fig.1 Schematic diagram of information propagation mode
3 谣言检测模型GMB_GMU
本文提出的谣言检测模型GMB_GMU 如图2 所示,由四个部分组成:用户信息编码器、结构信息编码器、源文本编码器和融合分类器,图中FC为全连接神经网络层。

图2 GMB_GMU模型Fig.2 GMB_GMU model
3.1 用户信息编码器
在实际场景下,用户很多时候仅仅转发原始内容,而不发表意见,转发内容不适合作为节点的属性特征。引入用户属性作为节点特征,可以在一定程度上弥补转发结构上信息的缺失。
首先构建新闻C的有向转发图G=(V,E),其中V={u1,u2,u3,…,um}表示新闻传播中的全部用户,E={e1,e2,e3,…,eo}表示用户之间的转发关系,定义H∈Rm×t为节点集V的特征矩阵,用户节点ui的特征向量为hi∈Rt,t为属性个数,包含用户的粉丝数、发表推文数量和关注数等属性信息。定义A∈Rm×m为邻接矩阵,若用户j转发了用户i的推文,邻接矩阵A中元素aij=1;若无转发关系,则aij=0。
由于用户各项属性量纲和变化范围不同,所以往往对特征矩阵进行归一化,使得模型可以快速收敛。具体的,通过以下公式得到H归一化后的特征矩阵Hs:
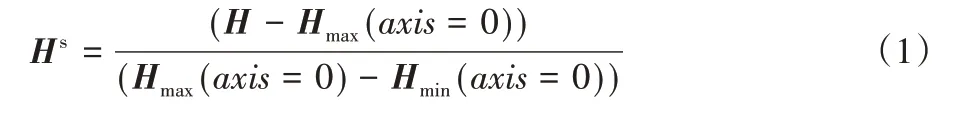
为了保留一定程度的原始信息,将Hs与Hs'对应元素相加,得到用户信息矩阵Hadd。

将Hadd铺平,得到用户信息的最终表征Vadd∈Rm×t,整个用户信息编码器如图3所示。
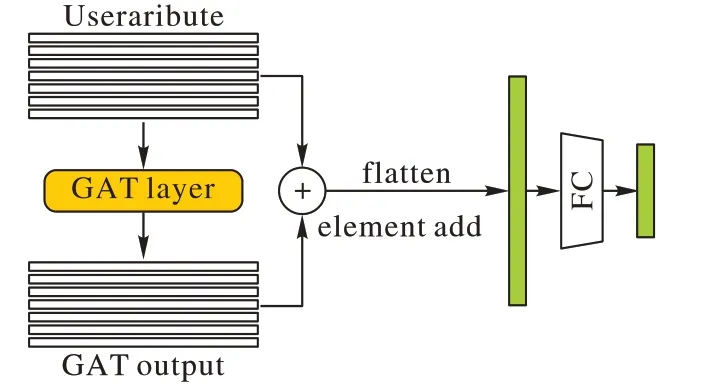
图3 用户信息编码器Fig.3 User information encoder
3.2 结构信息编码器
使用node2vec[16]算法可在不受节点属性干扰的情况下获取转发图结构信息,将node2vec 得到的节点表征作为互注意机制的输入,以增强结构表征。
首先,使用node2vev算法得到转发图中各个节点的表征,其目标函数为:
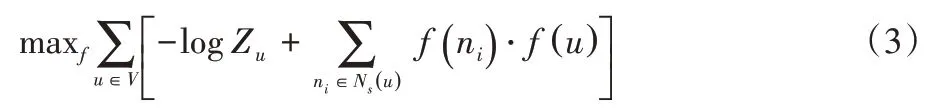
转发图中ui的node2vec表征为pi∈Rd,然后,计算用户之间的相互注意分数,类似于文献[17]中的方法,如图4 所示,使用全连接网络得到两两用户表征之间的注意力分数:
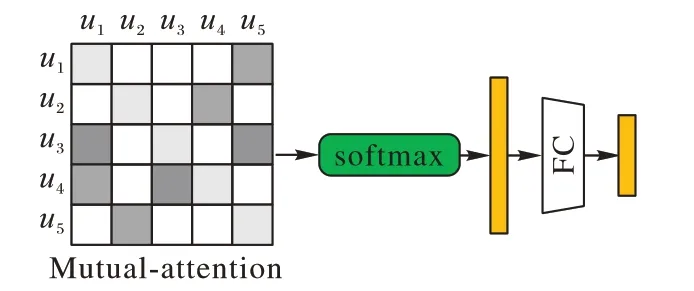
图4 结构信息编码器Fig.4 Structural information encoder

其中:权重矩阵Wcat∈R2d;偏置项bcat∈R;||为拼接操作,依次计算用户之间的注意力分数,得到相互注意分数矩阵MA∈Rm×m,m为转发网络中的节点数。
使用softmax 函数和行最大池化对互注意分数矩阵进行运算,得到节点的互注意分数向量:

3.3 源文本编码器
源文本包含丰富的信息,有助于增强模型表现。为了最大限度提取文本上下文信息,引入BERT[18]算法获取源文本表征,该算法通过双向Transformer编码器[19]生成的字向量,可以完全融合字词左右上下文信息,与CNN或RNN相比,BERT可以更加充分地表征词语的多重含义,由图5所示,BERT生成的词向量由字符向量、句向量和位置向量组成。输入为新闻C,输出源文本表征Xoutput∈Rr,代表源文本的全部语义信息。
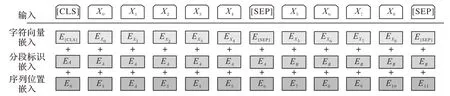
图5 BERT模型的输入表征Fig.5 Input representation of BERT model
3.4 融合分类器
以上三部分计算得到的三个表征分别表示传播模式中的用户属性、结构信息和源帖内容信息,要对这三个表征进行融合,使得最终表征可以最大限度地捕捉到谣言传播的多方面特征。此处通过多模态门控单元[20]对上述三个表征进行融合,在不同来源数据组合基础上找到最优表示。
由于用户属性表征Vadd∈Rm×t,结构表征以及源帖内容表征Xoutput∈Rr的维度不同,首先定义对应权重矩阵,将三个不同维度的表征投影到目标维度g,其过程为:


h1,h2和h3的维度都为g,将三个表征拼接起来:

则h∈R3g为模型的最终表征,将该向量输入到全连接网络(FC)和分类函数中,得到最终分类结果。

3.5 优化器
在本文中,模型训练目标为最小化交叉熵损失函数。

其中:L为损失函数,NS为新闻集合,yC为新闻C的真实标签,为新闻C的预测标签。
4 实验与分析
为了评估本文模型在真实社交场景下的检测性能,在真实世界的数据集进行对比实验。
4.1 实验数据
Weibo 数据集[21]来源于新浪微博。在该数据集中,由帖子、转发和用户构成,有两个标签:{谣言,非谣言},具体介绍如表1所示。

表1 实验数据集统计Tab.1 Experimental dataset statistics
4.2 实验设计
在实验中,使用5 折交叉验证。其中node2vec 训练的节点表征维数d=256,BERT训练的文本信息表征维数r=768,将三种信息表征投影到目标维度g=256。
为了减少模型的运算量,截取了前200 名传播用户,以此构建转发图。若传播网络中用户数不足200,则根据实际状况构建转发图,用户信息最终表征Vadd维数固定为1 800,若不足,则填充0值。在实验中,epoch设置为60,batch size 设置为128,学习率为0.000 1。
在用户信息编码器部分,使用用户常见的9 个特征作为转发图节点的特征,t=9,如表2所示。

表2 节点特征Tab.2 Node features
在用户信息编码器部分,所提出方法具备用户排序不变性,即用户信息编码器的输出与用户排列顺序无关。图注意力网络GAT 作为图神经网络算法,节点表征更新依赖邻接矩阵,满足平移不变性,与节点的顺序无关。将用户信息矩阵Hadd铺平后得到Vadd,目的是能够进入全连接层,填充0 值的作用是补齐向量,使得进入全连接层时规格统一。即使铺平顺序发生变化,全连接层可以灵活地更新权重矩阵,用户铺平顺序对最终结果不会造成影响。综上所述,将Hadd平铺不会对用户排序不变性造成影响。
4.3 对比方法
为了验证本文模型的优越性,与以下6个模型进行比较:
1)DTC(Decision-Tree Classifier)[1]:该模型使用文本的手工特征和其他统计特征,利用决策树模型来得到检测结果。
2)SVM-RBF(SVM classifier with RBF kernel function)[22]:该模型使用基于径向基核函数(Radial Basis Function,RBF)的SVM模型得到新闻的预测标签。
3)TD-RvNN(Tree-structured Recursive Neural Network)[4]:该模型使用递归神经网络处理树结构的新闻传播路径得到分类结果。
4)PPC-RNN+CNN(Propagation Path Classification with RNN and CNN)[3]:模型提出了新闻传播的多元时间序列,使用GRU和CNN的结合模型进行分类。
5)HiMap-HO+Text(Higher-order user to user Mutual-Attention Progression method)[17]:作者使用LSTM 计算转发链的节点表征,并结合用户的互注意表征得到新闻的检测结果。
6)BiGCN(Bi-directional GCN)[14]:利用信息传播时的双向传播结构使用图卷积网络进行谣言检测的模型。
4.4 实验结果
实验结果如表3 所示,显示了本文模型和比较模型在Weibo 数据集上的表现。首先,深度学习算法的表现远超机器学习算法,表明深度学习算法学习到的表征优于人工选择的谣言特征;其次,GMB_GMU 模型在各性能指标上明显优于TD-RvNN 方法,因为TD-RvNN 节点特征为转发文本,但真实场景下存在很多空转发,而本文模型选择使用用户属性作为节点特征,弥补了转发结构上信息的缺失。最后,GMB_GMU模型优于HiMap-HO+Text,在HiMap-HO+Text 中,使用转发链计算节点二到四阶的相互注意力,数据收集和处理有极大的难度,而本文模型仅使用转发图中的一阶用户相互注意力表征,实验表现远超HiMap-HO+Text。

表3 Weibo数据集上的实验结果Tab.3 Experimental results on Weibo dataset
4.5 早期检测实验
为了在谣言传播的早期检测到谣言,及时遏制其传播,分别测试了模型在5 min、10 min 等时间点的谣言检测表现,其实验结果如图6所示。

图6 早期检测实验结果Fig.6 Experimental results of early detection
在源帖发布的5 min 内,GMB_GMU 模型的准确率超过0.9,表现优于其他比较模型,表明仅存在较少用户信息时,GMB_GMU 仍能保持较为准确的早期检测能力。当传播时间增大,转发结构逐渐复杂,信息噪声增多时,不同于BiGCN 等比较模型,GMB_GMU 模型性能呈稳定上升趋势,体现了模型处理复杂数据的能力,具有较好的稳定性和鲁棒性。
4.6 消融实验
为了验证模型中各部分的作用,将模型可拆分为以下子模型:1)用户属性GAT;2)源帖BERT 网络;3)GMB 网络,即基于用户属性GAT-互注意机制-BERT 的简单融合网络;4)互注意机制。实验结果如图7所示。

图7 GMB_GMU的消融实验结果Fig.7 Ablation experimental results of GMB_GMU
用户属性GAT 可以取得0.865 的准确率,结果远低于GMB_GMU,表明仅使用用户属性,不考虑内容语义信息,会严重影响谣言检测效果。使用源帖BERT 网络取得了0.914的准确率,结果仍低于GMB_GMU,仅仅依靠源帖语义信息来检测谣言存在一定的问题。最后,基于用户属性GAT-互注意机制-BERT的简单融合网络将GMU替换为简单拼接方式,达到0.937 的准确率,说明门控多模态单元可以对多个模态信息进行选择组合,更好地表征联合信息。
5 结语
本文提出了一种基于用户传播网络与消息内容融合的谣言检测模型GMB_GMU,引入GAT 增强用户属性表征。在转发图的基础上计算节点的node2vec 表征,并通过互注意机制增强结构信息;另外,引入源帖文本的BERT 向量,增强源帖信息。最后,使用GMU 门控网络将三种角度的谣言表征恰当地结合起来,提取到消息的最终表征,在公共数据集上取得了优异的实验结果,并通过早期检测和消融实验说明了模型在谣言早期传播的有效性和每个部分的重要程度。在谣言的传播过程中,一些有影响力的用户会导致谣言扩散呈指数级增长,加重了谣言负面影响。在未来工作中,通过发现这些有影响力的用户,进而提升谣言检测模型的性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
导航定位学报(2022年4期)2022-08-15
传感器世界(2022年3期)2022-05-24
环球时报(2022-04-13)2022-04-13
现代电子技术(2022年4期)2022-02-21
计算机应用与软件(2021年10期)2021-10-15
数字技术与应用(2021年1期)2021-03-24
小雪花·小学生快乐作文(2020年4期)2020-10-12
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
民生周刊(2017年22期)2017-12-12
